mirror of https://github.com/fluxcd/flagger.git
Format docs markdown
Signed-off-by: Stefan Prodan <stefan.prodan@gmail.com>
This commit is contained in:
parent
f64295bcee
commit
2e10d8bf05
|
|
@ -216,7 +216,6 @@ For more details on how the canary analysis and promotion works please [read the
|
|||
* Migrate Flagger to Kubernetes controller-runtime and [kubebuilder](https://github.com/kubernetes-sigs/kubebuilder)
|
||||
* Make the Canary status compatible with [kstatus](https://github.com/kubernetes-sigs/cli-utils)
|
||||
* Make Flagger emit Kubernetes events compatible with Flux v2 notification API
|
||||
* Migrate CI to GitHub Actions and publish AMD64, ARM64 and ARMv7 container images
|
||||
* Integrate Flagger into Flux v2 as the progressive delivery component
|
||||
|
||||
#### Integrations
|
||||
|
|
|
|||
|
|
@ -4,21 +4,33 @@ description: Flagger is a progressive delivery Kubernetes operator
|
|||
|
||||
# Introduction
|
||||
|
||||
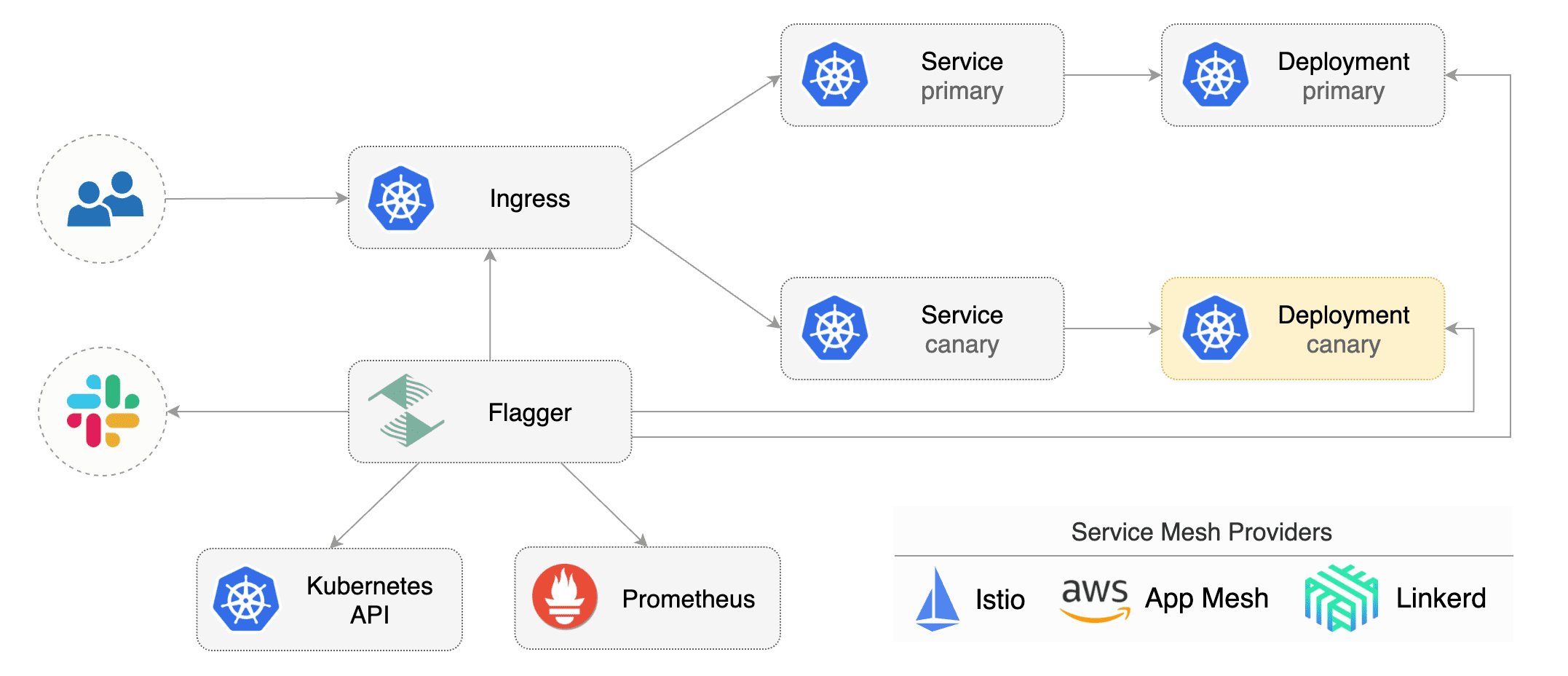
[Flagger](https://github.com/fluxcd/flagger) is a **Kubernetes** operator that automates the promotion of canary deployments using **Istio**, **Linkerd**, **App Mesh**, **NGINX**, **Skipper**, **Contour**, **Gloo** or **Traefik** routing for traffic shifting and **Prometheus** metrics for canary analysis. The canary analysis can be extended with webhooks for running system integration/acceptance tests, load tests, or any other custom validation.
|
||||
[Flagger](https://github.com/fluxcd/flagger) is a **Kubernetes** operator
|
||||
that automates the promotion of canary deployments using
|
||||
**Istio**, **Linkerd**, **App Mesh**, **NGINX**, **Skipper**, **Contour**, **Gloo** or **Traefik**
|
||||
routing for traffic shifting and **Prometheus** metrics for canary analysis.
|
||||
The canary analysis can be extended with webhooks for running
|
||||
system integration/acceptance tests, load tests, or any other custom validation.
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pods health. Based on analysis of the **KPIs** a canary is promoted or aborted, and the analysis result is published to **Slack** or **MS Teams**.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary
|
||||
while measuring key performance indicators like HTTP requests success rate,
|
||||
requests average duration and pods health.
|
||||
Based on analysis of the **KPIs** a canary is promoted or aborted,
|
||||
and the analysis result is published to **Slack** or **MS Teams**.
|
||||
|
||||
|
||||
|
||||
Flagger can be configured with Kubernetes custom resources and is compatible with any CI/CD solutions made for Kubernetes. Since Flagger is declarative and reacts to Kubernetes events, it can be used in **GitOps** pipelines together with Flux CD or JenkinsX.
|
||||
Flagger can be configured with Kubernetes custom resources and is compatible with any CI/CD solutions made for Kubernetes.
|
||||
Since Flagger is declarative and reacts to Kubernetes events,
|
||||
it can be used in **GitOps** pipelines together with Flux CD or JenkinsX.
|
||||
|
||||
This project is sponsored by [Weaveworks](https://www.weave.works/)
|
||||
Flagger is a [Cloud Native Computing Foundation](https://cncf.io/) project.
|
||||
|
||||
## Getting started
|
||||
|
||||
To get started with Flagger, chose one of the supported routing providers and [install](install/flagger-install-on-kubernetes.md) Flagger with Helm or Kustomize.
|
||||
To get started with Flagger, chose one of the supported routing providers and
|
||||
[install](install/flagger-install-on-kubernetes.md) Flagger with Helm or Kustomize.
|
||||
|
||||
After install Flagger, you can follow one of the tutorials:
|
||||
After install Flagger, you can follow one of these tutorials to get started:
|
||||
|
||||
**Service mesh tutorials**
|
||||
|
||||
|
|
@ -39,4 +51,3 @@ After install Flagger, you can follow one of the tutorials:
|
|||
* [Istio](https://github.com/stefanprodan/gitops-istio)
|
||||
* [Linkerd](https://helm.workshop.flagger.dev)
|
||||
* [AWS App Mesh](https://eks.handson.flagger.dev)
|
||||
|
||||
|
|
|
|||
|
|
@ -30,9 +30,7 @@
|
|||
* [Skipper Canary Deployments](tutorials/skipper-progressive-delivery.md)
|
||||
* [Traefik Canary Deployments](tutorials/traefik-progressive-delivery.md)
|
||||
* [Blue/Green Deployments](tutorials/kubernetes-blue-green.md)
|
||||
* [Crossover Canary Deployments](tutorials/crossover-progressive-delivery.md)
|
||||
* [Canary analysis with Prometheus Operator](tutorials/prometheus-operator.md)
|
||||
* [Canaries with Helm charts and GitOps](tutorials/canary-helm-gitops.md)
|
||||
* [Zero downtime deployments](tutorials/zero-downtime-deployments.md)
|
||||
* [Rollout Weights](tutorials/rollout-weights.md)
|
||||
|
||||
|
|
|
|||
|
|
@ -17,7 +17,8 @@ On your dev machine install the following tools:
|
|||
* helm >= 3.0
|
||||
* docker >= 19.03
|
||||
|
||||
You'll also need a Kubernetes cluster for testing Flagger. You can use Minikube, Kind, Docker desktop or any remote cluster \(AKS/EKS/GKE/etc\) Kubernetes version 1.14 or newer.
|
||||
You'll also need a Kubernetes cluster for testing Flagger.
|
||||
You can use Minikube, Kind, Docker desktop or any remote cluster (AKS/EKS/GKE/etc) Kubernetes version 1.16 or newer.
|
||||
|
||||
To start contributing to Flagger, fork the [repository](https://github.com/fluxcd/flagger) on GitHub.
|
||||
|
||||
|
|
@ -126,7 +127,9 @@ Note that any change to the CRDs must be accompanied by an update to the Open AP
|
|||
|
||||
## Manual testing
|
||||
|
||||
Install a service mesh and/or an ingress controller on your cluster and deploy Flagger using one of the install options [listed here](https://docs.flagger.app/install/flagger-install-on-kubernetes).
|
||||
Install a service mesh and/or an ingress controller on your cluster
|
||||
and deploy Flagger using one of the install options
|
||||
[listed here](https://docs.flagger.app/install/flagger-install-on-kubernetes).
|
||||
|
||||
If you made changes to the CRDs, apply your local copy with:
|
||||
|
||||
|
|
@ -201,4 +204,3 @@ For each service mesh and ingress controller there is a dedicated e2e test suite
|
|||
chose one that matches your changes from this [list](https://github.com/fluxcd/flagger/tree/main/test).
|
||||
|
||||
When you open a pull request on Flagger repo, the unit and integration tests will be run in CI.
|
||||
|
||||
|
|
|
|||
|
|
@ -4,12 +4,12 @@ This document describes how to release Flagger.
|
|||
|
||||
## Release
|
||||
|
||||
To release a new Flagger version \(e.g. `2.0.0`\) follow these steps:
|
||||
To release a new Flagger version (e.g. `2.0.0`) follow these steps:
|
||||
|
||||
* create a branch `git checkout -b prep-2.0.0`
|
||||
* set the version in code and manifests `TAG=2.0.0 make version-set`
|
||||
* commit changes and merge PR
|
||||
* checkout master `git checkout master && git pull`
|
||||
* checkout master `git checkout main && git pull`
|
||||
* tag master `make release`
|
||||
|
||||
## CI
|
||||
|
|
@ -28,8 +28,7 @@ The documentation [website](https://docs.flagger.app) is built from the `docs` b
|
|||
|
||||
After a Flagger release, publish the docs with:
|
||||
|
||||
* `git checkout master && git pull`
|
||||
* `git checkout main && git pull`
|
||||
* `git checkout docs`
|
||||
* `git rebase master`
|
||||
* `git rebase main`
|
||||
* `git push origin docs`
|
||||
|
||||
|
|
|
|||
|
|
@ -7,27 +7,33 @@
|
|||
Flagger implements the following deployment strategies:
|
||||
|
||||
* [Canary Release](usage/deployment-strategies.md#canary-release)
|
||||
* [A/B Testing](usage/deployment-strategies.md#a-b-testing)
|
||||
* [Blue/Green](usage/deployment-strategies.md#blue-green-deployments)
|
||||
* [Blue/Green Mirroring](usage/deployment-strategies.md#blue-green-with-traffic-mirroring)
|
||||
* [A/B Testing](usage/deployment-strategies.md#ab-testing)
|
||||
* [Blue/Green](usage/deployment-strategies.md#bluegreen-deployments)
|
||||
* [Blue/Green Mirroring](usage/deployment-strategies.md#bluegreen-with-traffic-mirroring)
|
||||
|
||||
**When should I use A/B testing instead of progressive traffic shifting?**
|
||||
|
||||
For frontend applications that require session affinity you should use HTTP headers or cookies match conditions to ensure a set of users will stay on the same version for the whole duration of the canary analysis.
|
||||
For frontend applications that require session affinity you should use HTTP headers or
|
||||
cookies match conditions to ensure a set of users will stay on the same version for
|
||||
the whole duration of the canary analysis.
|
||||
|
||||
**Can I use Flagger to manage applications that live outside of a service mesh?**
|
||||
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate Blue/Green style deployments with Kubernetes L4 networking.
|
||||
For applications that are not deployed on a service mesh,
|
||||
Flagger can orchestrate Blue/Green style deployments with Kubernetes L4 networking.
|
||||
|
||||
**When can I use traffic mirroring?**
|
||||
|
||||
Traffic mirroring can be used for Blue/Green deployment strategy or a pre-stage in a Canary release. Traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service. Mirroring should be used for requests that are **idempotent** or capable of being processed twice \(once by the primary and once by the canary\).
|
||||
Traffic mirroring can be used for Blue/Green deployment strategy or a pre-stage in a Canary release.
|
||||
Traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service.
|
||||
Mirroring should be used for requests that are **idempotent**
|
||||
or capable of being processed twice (once by the primary and once by the canary).
|
||||
|
||||
**How to retry a failed release?**
|
||||
|
||||
A canary analysis is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment/DaemonSet PodSpec \(metadata, container image, command, ports, env, resources, etc\)
|
||||
* Deployment/DaemonSet PodSpec (metadata, container image, command, ports, env, resources, etc)
|
||||
* ConfigMaps mounted as volumes or mapped to environment variables
|
||||
* Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
|
|
@ -71,7 +77,9 @@ spec:
|
|||
portName: http
|
||||
```
|
||||
|
||||
If the `service.name` is not specified, then `targetRef.name` is used for the apex domain and canary/primary services name prefix. You should treat the service name as an immutable field, changing it could result in routing conflicts.
|
||||
If the `service.name` is not specified, then `targetRef.name` is used for
|
||||
the apex domain and canary/primary services name prefix.
|
||||
You should treat the service name as an immutable field, changing it could result in routing conflicts.
|
||||
|
||||
Based on the canary spec service, Flagger generates the following Kubernetes ClusterIP service:
|
||||
|
||||
|
|
@ -87,7 +95,8 @@ Based on the canary spec service, Flagger generates the following Kubernetes Clu
|
|||
|
||||
selector `app=<name>`
|
||||
|
||||
This ensures that traffic coming from a namespace outside the mesh to `podinfo.test:9898` will be routed to the latest stable release of your app.
|
||||
This ensures that traffic coming from a namespace outside the mesh to `podinfo.test:9898`
|
||||
will be routed to the latest stable release of your app.
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
|
|
@ -133,13 +142,16 @@ spec:
|
|||
targetPort: http
|
||||
```
|
||||
|
||||
The `podinfo-canary.test:9898` address is available only during the canary analysis and can be used for conformance testing or load testing.
|
||||
The `podinfo-canary.test:9898` address is available only during the canary analysis
|
||||
and can be used for conformance testing or load testing.
|
||||
|
||||
## Multiple ports
|
||||
|
||||
**My application listens on multiple ports, how can I expose them inside the cluster?**
|
||||
|
||||
If port discovery is enabled, Flagger scans the deployment spec and extracts the containers ports excluding the port specified in the canary service and Envoy sidecar ports. These ports will be used when generating the ClusterIP services.
|
||||
If port discovery is enabled, Flagger scans the deployment spec and extracts the containers ports excluding
|
||||
the port specified in the canary service and Envoy sidecar ports.
|
||||
These ports will be used when generating the ClusterIP services.
|
||||
|
||||
For a deployment that exposes two ports:
|
||||
|
||||
|
|
@ -202,7 +214,8 @@ spec:
|
|||
app: podinfo
|
||||
```
|
||||
|
||||
Besides `app` Flagger supports `name` and `app.kubernetes.io/name` selectors. If you use a different convention you can specify your label with the `-selector-labels` flag.
|
||||
Besides `app` Flagger supports `name` and `app.kubernetes.io/name` selectors.
|
||||
If you use a different convention you can specify your label with the `-selector-labels` flag.
|
||||
|
||||
**Is pod affinity and anti affinity supported?**
|
||||
|
||||
|
|
@ -239,7 +252,7 @@ spec:
|
|||
|
||||
## Metrics
|
||||
|
||||
**How does Flagger measures the request success rate and duration?**
|
||||
**How does Flagger measure the request success rate and duration?**
|
||||
|
||||
Flagger measures the request success rate and duration using Prometheus queries.
|
||||
|
||||
|
|
@ -283,7 +296,7 @@ sum(
|
|||
)
|
||||
```
|
||||
|
||||
Envoy query \(App Mesh\):
|
||||
Envoy query (App Mesh):
|
||||
|
||||
```javascript
|
||||
sum(
|
||||
|
|
@ -306,7 +319,7 @@ sum(
|
|||
)
|
||||
```
|
||||
|
||||
Envoy query \(Contour or Gloo\):
|
||||
Envoy query (Contour and Gloo):
|
||||
|
||||
```javascript
|
||||
sum(
|
||||
|
|
@ -358,7 +371,7 @@ histogram_quantile(0.99,
|
|||
)
|
||||
```
|
||||
|
||||
Envoy query \(App Mesh, Contour or Gloo\):
|
||||
Envoy query (App Mesh, Contour and Gloo):
|
||||
|
||||
```javascript
|
||||
histogram_quantile(0.99,
|
||||
|
|
@ -377,15 +390,19 @@ histogram_quantile(0.99,
|
|||
|
||||
**Can I use custom metrics?**
|
||||
|
||||
The analysis can be extended with metrics provided by Prometheus, Datadog and AWS CloudWatch. For more details on how custom metrics can be used please read the [metrics docs](usage/metrics.md).
|
||||
The analysis can be extended with metrics provided by Prometheus, Datadog and AWS CloudWatch.
|
||||
For more details on how custom metrics can be used please read the [metrics docs](usage/metrics.md).
|
||||
|
||||
## Istio routing
|
||||
|
||||
**How does Flagger interact with Istio?**
|
||||
|
||||
Flagger creates an Istio Virtual Service and Destination Rules based on the Canary service spec. The service configuration lets you expose an app inside or outside the mesh. You can also define traffic policies, HTTP match conditions, URI rewrite rules, CORS policies, timeout and retries.
|
||||
Flagger creates an Istio Virtual Service and Destination Rules based on the Canary service spec.
|
||||
The service configuration lets you expose an app inside or outside the mesh. You can also define traffic policies,
|
||||
HTTP match conditions, URI rewrite rules, CORS policies, timeout and retries.
|
||||
|
||||
The following spec exposes the `frontend` workload inside the mesh on `frontend.test.svc.cluster.local:9898` and outside the mesh on `frontend.example.com`. You'll have to specify an Istio ingress gateway for external hosts.
|
||||
The following spec exposes the `frontend` workload inside the mesh on `frontend.test.svc.cluster.local:9898`
|
||||
and outside the mesh on `frontend.example.com`. You'll have to specify an Istio ingress gateway for external hosts.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
|
|
@ -519,9 +536,11 @@ spec:
|
|||
mode: DISABLE
|
||||
```
|
||||
|
||||
Flagger keeps in sync the virtual service and destination rules with the canary service spec. Any direct modification to the virtual service spec will be overwritten.
|
||||
Flagger keeps in sync the virtual service and destination rules with the canary service spec.
|
||||
Any direct modification to the virtual service spec will be overwritten.
|
||||
|
||||
To expose a workload inside the mesh on `http://backend.test.svc.cluster.local:9898`, the service spec can contain only the container port and the traffic policy:
|
||||
To expose a workload inside the mesh on `http://backend.test.svc.cluster.local:9898`,
|
||||
the service spec can contain only the container port and the traffic policy:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
|
|
@ -562,9 +581,11 @@ spec:
|
|||
app: backend-primary
|
||||
```
|
||||
|
||||
Flagger works for user facing apps exposed outside the cluster via an ingress gateway and for backend HTTP APIs that are accessible only from inside the mesh.
|
||||
Flagger works for user facing apps exposed outside the cluster via an ingress gateway and for backend HTTP APIs
|
||||
that are accessible only from inside the mesh.
|
||||
|
||||
If `Delegation` is enabled, Flagger would generate Istio VirtualService without hosts and gateway, making the service compatible with Istio delegation.
|
||||
If `Delegation` is enabled, Flagger would generate Istio VirtualService without hosts and gateway,
|
||||
making the service compatible with Istio delegation.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
|
|
@ -639,13 +660,17 @@ spec:
|
|||
namespace: test
|
||||
```
|
||||
|
||||
Note that pilot env `PILOT_ENABLE_VIRTUAL_SERVICE_DELEGATE` must also be set. \(For the use of Istio Delegation, you can refer to the documentation of [Virtual Service](https://istio.io/latest/docs/reference/config/networking/virtual-service/#Delegate) and [pilot environment variables](https://istio.io/latest/docs/reference/commands/pilot-discovery/#envvars).\)
|
||||
Note that pilot env `PILOT_ENABLE_VIRTUAL_SERVICE_DELEGATE` must also be set.
|
||||
For the use of Istio Delegation, you can refer to the documentation of
|
||||
[Virtual Service](https://istio.io/latest/docs/reference/config/networking/virtual-service/#Delegate)
|
||||
and [pilot environment variables](https://istio.io/latest/docs/reference/commands/pilot-discovery/#envvars).
|
||||
|
||||
## Istio Ingress Gateway
|
||||
|
||||
**How can I expose multiple canaries on the same external domain?**
|
||||
|
||||
Assuming you have two apps, one that servers the main website and one that serves the REST API. For each app you can define a canary object as:
|
||||
Assuming you have two apps, one that servers the main website and one that serves the REST API.
|
||||
For each app you can define a canary object as:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
|
|
@ -683,7 +708,11 @@ spec:
|
|||
uri: /
|
||||
```
|
||||
|
||||
Based on the above configuration, Flagger will create two virtual services bounded to the same ingress gateway and external host. Istio Pilot will [merge](https://istio.io/help/ops/traffic-management/deploy-guidelines/#multiple-virtual-services-and-destination-rules-for-the-same-host) the two services and the website rule will be moved to the end of the list in the merged configuration.
|
||||
Based on the above configuration, Flagger will create two virtual services bounded
|
||||
to the same ingress gateway and external host.
|
||||
Istio Pilot will
|
||||
[merge](https://istio.io/help/ops/traffic-management/deploy-guidelines/#multiple-virtual-services-and-destination-rules-for-the-same-host)
|
||||
the two services and the website rule will be moved to the end of the list in the merged configuration.
|
||||
|
||||
Note that host merging only works if the canaries are bounded to a ingress gateway other than the `mesh` gateway.
|
||||
|
||||
|
|
@ -717,7 +746,8 @@ spec:
|
|||
|
||||
**If Flagger is outside of the mesh, how can it start the load test?**
|
||||
|
||||
In order for Flagger to be able to call the load tester service from outside the mesh, you need to disable mTLS on port 80:
|
||||
In order for Flagger to be able to call the load tester service from outside the mesh,
|
||||
you need to disable mTLS on port 80:
|
||||
|
||||
```yaml
|
||||
apiVersion: networking.istio.io/v1alpha3
|
||||
|
|
@ -742,4 +772,3 @@ spec:
|
|||
ports:
|
||||
- number: 80
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -1,349 +0,0 @@
|
|||
# Crossover Canary Deployments
|
||||
|
||||
This guide shows you how to use Envoy, [Crossover](https://github.com/mumoshu/crossover) and Flagger to automate canary deployments.
|
||||
|
||||
Crossover is a minimal Envoy xDS implementation supports [Service Mesh Interface](https://smi-spec.io/).
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.16** or newer and Envoy paired with [Crossover](https://github.com/mumoshu/crossover) sidecar.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
```bash
|
||||
kubectl create ns test
|
||||
```
|
||||
|
||||
Install Envoy along with the Crossover sidecar with Helm:
|
||||
|
||||
```bash
|
||||
helm repo add crossover https://mumoshu.github.io/crossover
|
||||
|
||||
helm upgrade --install envoy crossover/envoy \
|
||||
--namespace test \
|
||||
-f <(cat <<EOF
|
||||
smi:
|
||||
apiVersions:
|
||||
trafficSplits: v1alpha1
|
||||
upstreams:
|
||||
podinfo:
|
||||
smi:
|
||||
enabled: true
|
||||
backends:
|
||||
podinfo-primary:
|
||||
port: 9898
|
||||
weight: 100
|
||||
podinfo-canary:
|
||||
port: 9898
|
||||
weight: 0
|
||||
EOF
|
||||
)
|
||||
```
|
||||
|
||||
Install Flagger and the Prometheus add-on in the same namespace as Envoy:
|
||||
|
||||
```bash
|
||||
helm repo add flagger https://flagger.app
|
||||
|
||||
helm upgrade -i flagger flagger/flagger \
|
||||
--namespace test \
|
||||
--set prometheus.install=true \
|
||||
--set meshProvider=smi:crossover
|
||||
```
|
||||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services, SMI traffic splits\). These objects expose the application on the mesh and drive the canary analysis and promotion. There's no SMI object you need to create by yourself.
|
||||
|
||||
Create a deployment and a horizontal pod autoscaler:
|
||||
|
||||
```bash
|
||||
kubectl apply -k https://github.com/fluxcd/flagger//kustomize/podinfo?ref=main
|
||||
```
|
||||
|
||||
Deploy the load testing service to generate traffic during the canary analysis:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-loadtester flagger/loadtester \
|
||||
--namespace=test
|
||||
```
|
||||
|
||||
Create a metric template to measure the HTTP requests error rate:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: error-rate
|
||||
namespace: test
|
||||
spec:
|
||||
provider:
|
||||
address: http://flagger-prometheus:9090
|
||||
type: prometheus
|
||||
query: |
|
||||
100 - rate(
|
||||
envoy_cluster_upstream_rq{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
envoy_cluster_name="{{ target }}-canary",
|
||||
envoy_response_code!~"5.*"
|
||||
}[{{ interval }}])
|
||||
/
|
||||
rate(
|
||||
envoy_cluster_upstream_rq{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
envoy_cluster_name="{{ target }}-canary"
|
||||
}[{{ interval }}]
|
||||
) * 100
|
||||
```
|
||||
|
||||
Create a metric template to measure the HTTP requests average duration:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: MetricTemplate
|
||||
metadata:
|
||||
name: latency
|
||||
namespace: test
|
||||
spec:
|
||||
provider:
|
||||
address: http://flagger-prometheus:9090
|
||||
type: prometheus
|
||||
query: |
|
||||
histogram_quantile(0.99,
|
||||
sum(
|
||||
rate(
|
||||
envoy_cluster_upstream_rq_time_bucket{
|
||||
kubernetes_namespace="{{ namespace }}",
|
||||
envoy_cluster_name="{{ target }}-canary"
|
||||
}[{{ interval }}]
|
||||
)
|
||||
) by (le)
|
||||
)
|
||||
```
|
||||
|
||||
Create a canary custom resource:
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
kind: Canary
|
||||
metadata:
|
||||
name: podinfo
|
||||
namespace: test
|
||||
spec:
|
||||
provider: "smi:crossover"
|
||||
# deployment reference
|
||||
targetRef:
|
||||
apiVersion: apps/v1
|
||||
kind: Deployment
|
||||
name: podinfo
|
||||
progressDeadlineSeconds: 60
|
||||
# HPA reference (optional)
|
||||
autoscalerRef:
|
||||
apiVersion: autoscaling/v2beta2
|
||||
kind: HorizontalPodAutoscaler
|
||||
name: podinfo
|
||||
service:
|
||||
port: 9898
|
||||
# define the canary analysis timing and KPIs
|
||||
analysis:
|
||||
# schedule interval (default 60s)
|
||||
interval: 1m
|
||||
# max number of failed metric checks before rollback
|
||||
threshold: 5
|
||||
# max traffic percentage routed to canary
|
||||
# percentage (0-100)
|
||||
maxWeight: 50
|
||||
# canary increment step
|
||||
# percentage (0-100)
|
||||
stepWeight: 5
|
||||
metrics:
|
||||
- name: error-rate
|
||||
templateRef:
|
||||
name: error-rate
|
||||
thresholdRange:
|
||||
max: 1
|
||||
interval: 30s
|
||||
- name: latency
|
||||
templateRef:
|
||||
name: latency
|
||||
thresholdRange:
|
||||
max: 0.5
|
||||
interval: 30s
|
||||
webhooks:
|
||||
- name: acceptance-test
|
||||
type: pre-rollout
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 30s
|
||||
metadata:
|
||||
type: bash
|
||||
cmd: "curl -sd 'test' http://podinfo-canary.test:9898/token | grep token"
|
||||
- name: load-test
|
||||
url: http://flagger-loadtester.test/
|
||||
timeout: 5s
|
||||
metadata:
|
||||
cmd: "hey -z 1m -q 10 -c 2 -H 'Host: podinfo.test' http://envoy.test:10000/"
|
||||
```
|
||||
|
||||
Save the above resource as podinfo-canary.yaml and then apply it:
|
||||
|
||||
```bash
|
||||
kubectl apply -f ./podinfo-canary.yaml
|
||||
```
|
||||
|
||||
After a couple of seconds Flagger will create the canary objects:
|
||||
|
||||
```bash
|
||||
# applied
|
||||
deployment.apps/podinfo
|
||||
horizontalpodautoscaler.autoscaling/podinfo
|
||||
canary.flagger.app/podinfo
|
||||
|
||||
# generated
|
||||
deployment.apps/podinfo-primary
|
||||
horizontalpodautoscaler.autoscaling/podinfo-primary
|
||||
service/podinfo
|
||||
service/podinfo-canary
|
||||
service/podinfo-primary
|
||||
trafficsplits.split.smi-spec.io/podinfo
|
||||
```
|
||||
|
||||
After the boostrap, the podinfo deployment will be scaled to zero and the traffic to `podinfo.test` will be routed to the primary pods. During the canary analysis, the `podinfo-canary.test` address can be used to target directly the canary pods.
|
||||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||
|
||||
A canary deployment is triggered by changes in any of the following objects:
|
||||
|
||||
* Deployment PodSpec \(container image, command, ports, env, resources, etc\)
|
||||
* ConfigMaps and Secrets mounted as volumes or mapped to environment variables
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.5
|
||||
```
|
||||
|
||||
Flagger detects that the deployment revision changed and starts a new rollout:
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
||||
Status:
|
||||
Canary Weight: 0
|
||||
Failed Checks: 0
|
||||
Phase: Succeeded
|
||||
Events:
|
||||
New revision detected! Scaling up podinfo.test
|
||||
Waiting for podinfo.test rollout to finish: 0 of 1 updated replicas are available
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Advance podinfo.test canary weight 20
|
||||
Advance podinfo.test canary weight 25
|
||||
Advance podinfo.test canary weight 30
|
||||
Advance podinfo.test canary weight 35
|
||||
Advance podinfo.test canary weight 40
|
||||
Advance podinfo.test canary weight 45
|
||||
Advance podinfo.test canary weight 50
|
||||
Copying podinfo.test template spec to podinfo-primary.test
|
||||
Waiting for podinfo-primary.test rollout to finish: 1 of 2 updated replicas are available
|
||||
Routing all traffic to primary
|
||||
Promotion completed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
|
||||
**Note** that if you apply new changes to the deployment during the canary analysis, Flagger will restart the analysis.
|
||||
|
||||
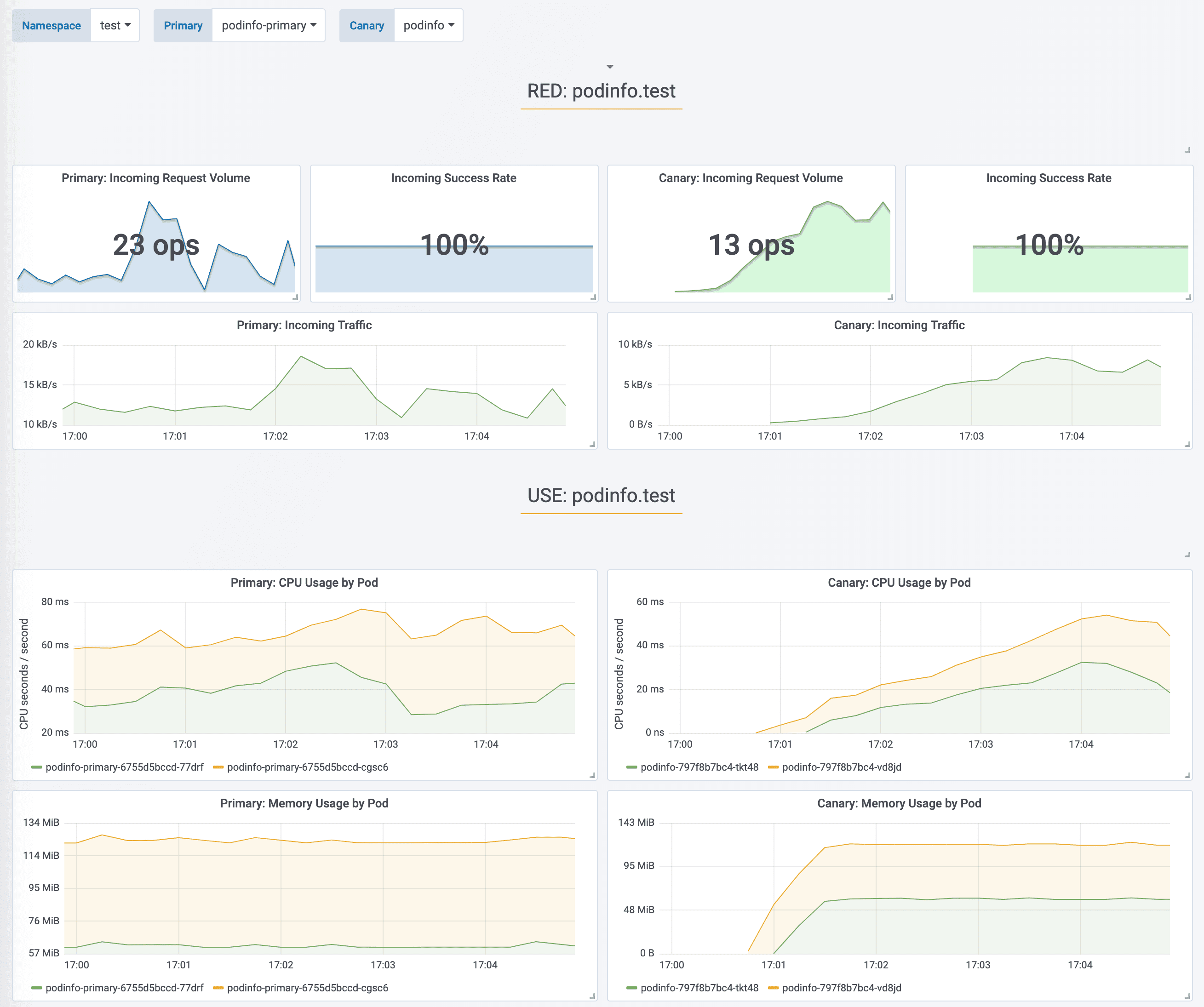
During the analysis the canary’s progress can be monitored with Grafana.
|
||||
|
||||
Flagger comes with a Grafana dashboard made for canary analysis. Install Grafana with Helm:
|
||||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=test \
|
||||
--set url=http://flagger-prometheus:9090
|
||||
```
|
||||
|
||||
Run:
|
||||
|
||||
```bash
|
||||
kubectl port-forward --namespace test svc/flagger-grafana 3000:80
|
||||
```
|
||||
|
||||
The Envoy dashboard URL is [http://localhost:3000/d/flagger-envoy/envoy-canary?refresh=10s&orgId=1&var-namespace=test&var-target=podinfo](http://localhost:3000/d/flagger-envoy/envoy-canary?refresh=10s&orgId=1&var-namespace=test&var-target=podinfo)
|
||||
|
||||
|
||||
|
||||
You can monitor all canaries with:
|
||||
|
||||
```bash
|
||||
watch kubectl get canaries --all-namespaces
|
||||
|
||||
NAMESPACE NAME STATUS WEIGHT LASTTRANSITIONTIME
|
||||
test podinfo Progressing 15 2019-10-02T14:05:07Z
|
||||
prod frontend Succeeded 0 2019-10-02T16:15:07Z
|
||||
prod backend Failed 0 2019-10-02T17:05:07Z
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you should receive the following messages:
|
||||
|
||||

|
||||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors or high latency to test if Flagger pauses the rollout.
|
||||
|
||||
Trigger a canary deployment:
|
||||
|
||||
```bash
|
||||
kubectl -n test set image deployment/podinfo \
|
||||
podinfod=stefanprodan/podinfo:3.1.2
|
||||
```
|
||||
|
||||
Exec into the load tester pod with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it deploy/flagger-loadtester bash
|
||||
```
|
||||
|
||||
Generate HTTP 500 errors:
|
||||
|
||||
```bash
|
||||
hey -z 1m -c 5 -q 5 -H 'Host: podinfo.test' http://envoy.test:10000/status/500
|
||||
```
|
||||
|
||||
Generate latency:
|
||||
|
||||
```bash
|
||||
watch -n 1 curl -H 'Host: podinfo.test' http://envoy.test:10000/delay/1
|
||||
```
|
||||
|
||||
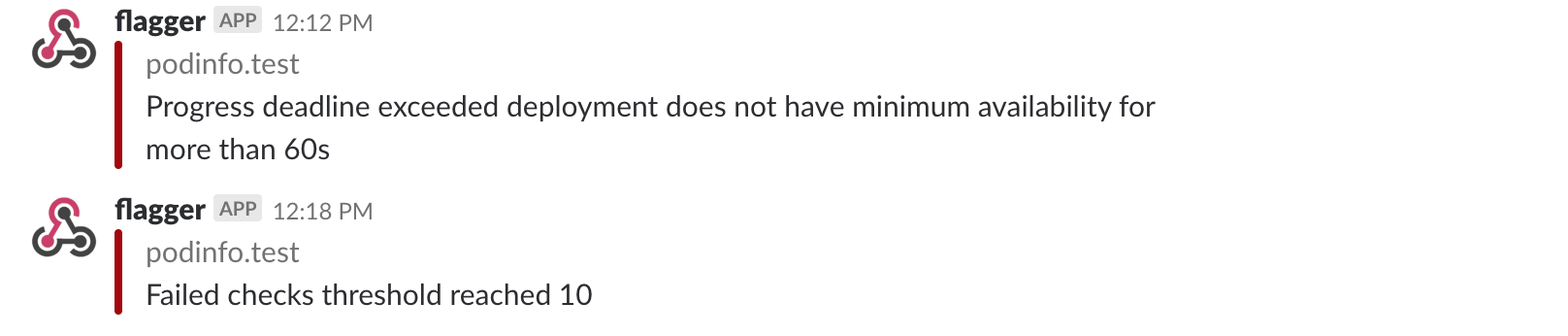
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test logs deploy/flagger -f | jq .msg
|
||||
|
||||
New revision detected! progressing canary analysis for podinfo.test
|
||||
Pre-rollout check acceptance-test passed
|
||||
Advance podinfo.test canary weight 5
|
||||
Advance podinfo.test canary weight 10
|
||||
Advance podinfo.test canary weight 15
|
||||
Halt podinfo.test advancement success rate 69.17% < 99%
|
||||
Halt podinfo.test advancement success rate 61.39% < 99%
|
||||
Halt podinfo.test advancement success rate 55.06% < 99%
|
||||
Halt podinfo.test advancement request duration 1.20s > 0.5s
|
||||
Halt podinfo.test advancement request duration 1.45s > 0.5s
|
||||
Rolling back podinfo.test failed checks threshold reached 5
|
||||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you’ve enabled the Slack notifications, you’ll receive a message if the progress deadline is exceeded, or if the analysis reached the maximum number of failed checks:
|
||||
|
||||
|
||||
|
||||
|
|
@ -1,16 +1,18 @@
|
|||
# Gloo Canary Deployments
|
||||
|
||||
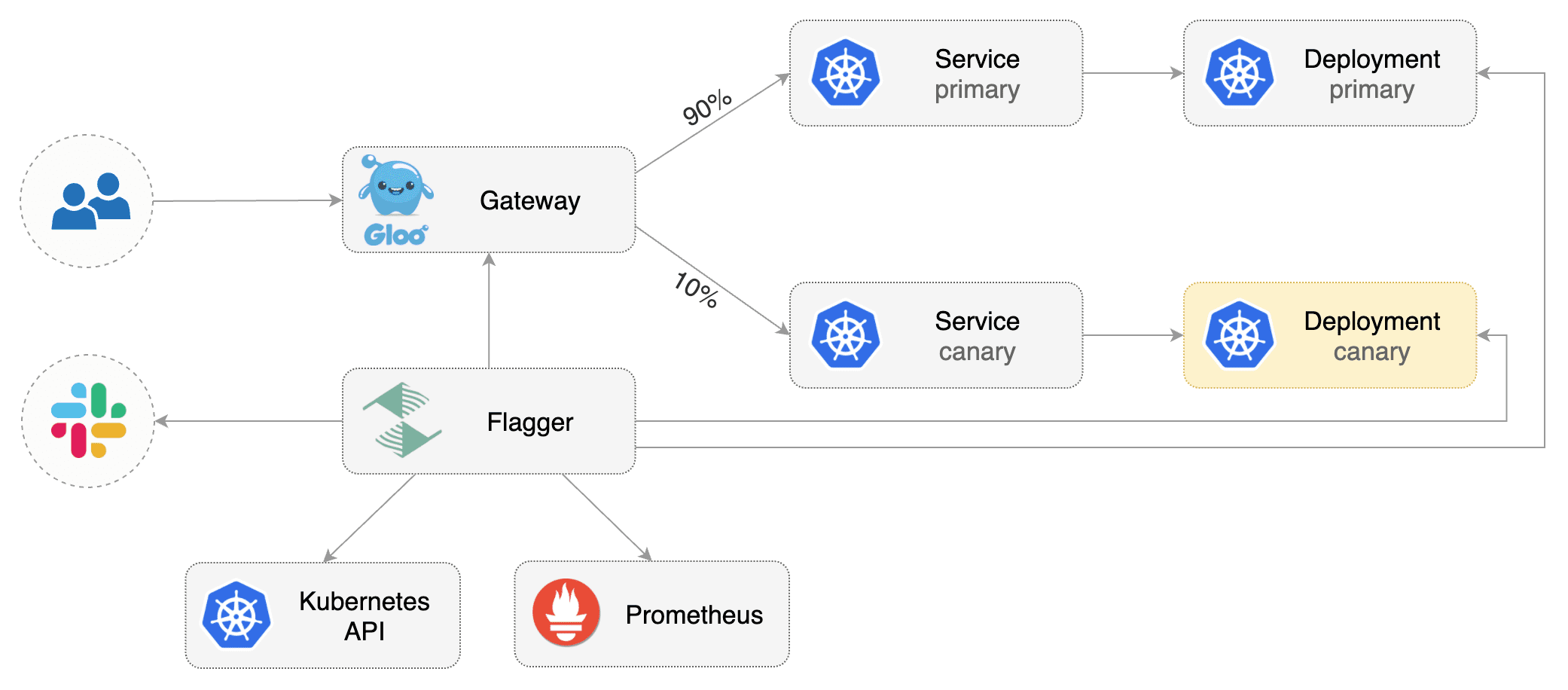
This guide shows you how to use the [Gloo Edge](https://gloo.solo.io/) ingress controller and Flagger to automate canary deployments.
|
||||
This guide shows you how to use the [Gloo Edge](https://gloo.solo.io/) ingress controller
|
||||
and Flagger to automate canary releases and A/B testing.
|
||||
|
||||
|
||||
|
||||
## Prerequisites
|
||||
|
||||
This guide was written for Flagger version **1.5.0** or higher. Prior versions of Flagger used Gloo upstream groups to handle
|
||||
canaries, but newer versions of Flagger use Gloo route tables to handle canaries as well as A/B testing.
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.16** or newer and Gloo Edge ingress **1.6.0** or newer.
|
||||
|
||||
This guide was written for Flagger version **1.6.0** or higher. Prior versions of Flagger
|
||||
used Gloo upstream groups to handle canaries, but newer versions of Flagger use Gloo
|
||||
route tables to handle canaries as well as A/B testing.
|
||||
|
||||
Install Gloo with Helm v3:
|
||||
|
||||
```bash
|
||||
|
|
@ -33,7 +35,9 @@ helm upgrade -i flagger flagger/flagger \
|
|||
|
||||
## Bootstrap
|
||||
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler \(HPA\), then creates a series of objects \(Kubernetes deployments, ClusterIP services and Gloo route tables groups\). These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
Flagger takes a Kubernetes deployment and optionally a horizontal pod autoscaler (HPA),
|
||||
then creates a series of objects (Kubernetes deployments, ClusterIP services and Gloo route tables groups).
|
||||
These objects expose the application outside the cluster and drive the canary analysis and promotion.
|
||||
|
||||
Create a test namespace:
|
||||
|
||||
|
|
@ -53,7 +57,8 @@ Deploy the load testing service to generate traffic during the canary analysis:
|
|||
kubectl -n test apply -k https://github.com/fluxcd/flagger//kustomize/tester?ref=main
|
||||
```
|
||||
|
||||
Create a virtual service definition that references a route table that will be generated by Flagger \(replace `app.example.com` with your own domain\):
|
||||
Create a virtual service definition that references a route table that will be generated by Flagger
|
||||
(replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: gateway.solo.io/v1
|
||||
|
|
@ -80,7 +85,7 @@ Save the above resource as podinfo-virtualservice.yaml and then apply it:
|
|||
kubectl apply -f ./podinfo-virtualservice.yaml
|
||||
```
|
||||
|
||||
Create a canary custom resource \(replace `app.example.com` with your own domain\):
|
||||
Create a canary custom resource (replace `app.example.com` with your own domain):
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
|
|
@ -182,7 +187,9 @@ podinfo Initialized 0 2019-05-17T08:09:51Z
|
|||
|
||||
## Automated canary promotion
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack.
|
||||
|
||||

|
||||
|
||||
|
|
@ -238,7 +245,8 @@ prod backend Failed 0 2019-05-17T17:05:07Z
|
|||
|
||||
## Automated rollback
|
||||
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if Flagger pauses and rolls back the faulted version.
|
||||
During the canary analysis you can generate HTTP 500 errors and high latency to test if
|
||||
Flagger pauses and rolls back the faulted version.
|
||||
|
||||
Trigger another canary deployment:
|
||||
|
||||
|
|
@ -259,7 +267,8 @@ Generate high latency:
|
|||
watch curl -H 'Host: app.example.com' http://gateway-proxy.gloo-system/delay/2
|
||||
```
|
||||
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary, the canary is scaled to zero and the rollout is marked as failed.
|
||||
When the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
||||
the canary is scaled to zero and the rollout is marked as failed.
|
||||
|
||||
```text
|
||||
kubectl -n test describe canary/podinfo
|
||||
|
|
@ -288,7 +297,8 @@ Events:
|
|||
|
||||
The canary analysis can be extended with Prometheus queries.
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the HTTP request duration histogram to validate the canary.
|
||||
The demo app is instrumented with Prometheus so you can create a custom check that will use the HTTP request
|
||||
duration histogram to validate the canary.
|
||||
|
||||
Create a metric template and apply it on the cluster:
|
||||
|
||||
|
|
@ -336,7 +346,8 @@ Edit the canary analysis and add the following metric:
|
|||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage
|
||||
is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
Trigger a canary deployment by updating the container image:
|
||||
|
||||
|
|
@ -369,7 +380,8 @@ Rolling back podinfo.test failed checks threshold reached 5
|
|||
Canary failed! Scaling down podinfo.test
|
||||
```
|
||||
|
||||
If you have [alerting](../usage/alerting.md) configured, Flagger will send a notification with the reason why the canary failed.
|
||||
If you have [alerting](../usage/alerting.md) configured,
|
||||
Flagger will send a notification with the reason why the canary failed.
|
||||
|
||||
For an in-depth look at the analysis process read the [usage docs](../usage/how-it-works.md).
|
||||
|
||||
|
|
|
|||
|
|
@ -1,10 +1,11 @@
|
|||
# Canary analysis with Prometheus Operator
|
||||
|
||||
This guide show you how to use Prometheus Operator for canary analysis.
|
||||
This guide show you how to use
|
||||
[Prometheus Operator](https://github.com/prometheus-operator/prometheus-operator) for canary analysis.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Flagger requires a Kubernetes cluster **v1.16** or newer.
|
||||
Flagger requires a Kubernetes cluster **v1.16** or newer and Prometheus Operator **v0.40** or newer.
|
||||
|
||||
Install Prometheus Operator with Helm v3:
|
||||
|
||||
|
|
@ -19,7 +20,7 @@ helm upgrade -i prometheus prometheus-community/kube-prometheus-stack \
|
|||
```
|
||||
|
||||
The `prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false`
|
||||
option allows Prometheus operator to watch serviceMonitors outside of his namespace.
|
||||
option allows Prometheus Operator to watch serviceMonitors outside of its namespace.
|
||||
|
||||
Install Flagger by setting the metrics server to Prometheus:
|
||||
|
||||
|
|
@ -40,7 +41,7 @@ helm upgrade -i loadtester flagger/loadtester \
|
|||
--namespace flagger-system
|
||||
```
|
||||
|
||||
Install podinfo demo app:
|
||||
Install [podinfo](https://github.com/stefanprodan/podinfo) demo app:
|
||||
|
||||
```bash
|
||||
helm repo add podinfo https://stefanprodan.github.io/podinfo
|
||||
|
|
@ -53,23 +54,8 @@ helm upgrade -i podinfo podinfo/podinfo \
|
|||
|
||||
## Service monitors
|
||||
|
||||
The demo app is instrumented with Prometheus so you can create service monitors to scrape podinfo's metrics endpoint:
|
||||
|
||||
```yaml
|
||||
apiVersion: monitoring.coreos.com/v1
|
||||
kind: ServiceMonitor
|
||||
metadata:
|
||||
name: podinfo-primary
|
||||
namespace: test
|
||||
spec:
|
||||
endpoints:
|
||||
- path: /metrics
|
||||
port: http
|
||||
interval: 5s
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
```
|
||||
The demo app is instrumented with Prometheus,
|
||||
so you can create a `ServiceMonitor` objects to scrape podinfo's metrics endpoint:
|
||||
|
||||
```yaml
|
||||
apiVersion: monitoring.coreos.com/v1
|
||||
|
|
@ -85,10 +71,24 @@ spec:
|
|||
selector:
|
||||
matchLabels:
|
||||
app: podinfo-canary
|
||||
---
|
||||
apiVersion: monitoring.coreos.com/v1
|
||||
kind: ServiceMonitor
|
||||
metadata:
|
||||
name: podinfo-primary
|
||||
namespace: test
|
||||
spec:
|
||||
endpoints:
|
||||
- path: /metrics
|
||||
port: http
|
||||
interval: 5s
|
||||
selector:
|
||||
matchLabels:
|
||||
app: podinfo
|
||||
```
|
||||
|
||||
We are setting `interval: 5s` to have a more aggressive scraping.
|
||||
If you do not define it, you must to use a longer interval in the Canary object.
|
||||
If you do not define it, you should use a longer interval in the Canary object.
|
||||
|
||||
## Metric templates
|
||||
|
||||
|
|
@ -197,4 +197,3 @@ Based on the above specification, Flagger creates the primary and canary Kuberne
|
|||
|
||||
During the canary analysis, Prometheus will scrape the canary service and Flagger will use the HTTP error rate
|
||||
and latency queries to determine if the release should be promoted or rolled back.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,2 +0,0 @@
|
|||
# Rollout Weights
|
||||
|
||||
|
|
@ -1,6 +1,7 @@
|
|||
# Alerting
|
||||
|
||||
Flagger can be configured to send alerts to various chat platforms. You can define a global alert provider at install time or configure alerts on a per canary basis.
|
||||
Flagger can be configured to send alerts to various chat platforms.
|
||||
You can define a global alert provider at install time or configure alerts on a per canary basis.
|
||||
|
||||
## Global configuration
|
||||
|
||||
|
|
@ -13,11 +14,14 @@ helm upgrade -i flagger flagger/flagger \
|
|||
--set slack.user=flagger
|
||||
```
|
||||
|
||||
Once configured with a Slack incoming **webhook**, Flagger will post messages when a canary deployment has been initialised, when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
Once configured with a Slack incoming **webhook**,
|
||||
Flagger will post messages when a canary deployment has been initialised,
|
||||
when a new revision has been detected and if the canary analysis failed or succeeded.
|
||||
|
||||

|
||||
|
||||
A canary deployment will be rolled back if the progress deadline exceeded or if the analysis reached the maximum number of failed checks:
|
||||
A canary deployment will be rolled back if the progress deadline exceeded
|
||||
or if the analysis reached the maximum number of failed checks:
|
||||
|
||||

|
||||
|
||||
|
|
@ -36,7 +40,10 @@ Similar to Slack, Flagger alerts on canary analysis events:
|
|||
|
||||
## Canary configuration
|
||||
|
||||
Configuring alerting globally has several limitations as it's not possible to specify different channels or configure the verbosity on a per canary basis. To make the alerting move flexible, the canary analysis can be extended with a list of alerts that reference an alert provider. For each alert, users can configure the severity level. The alerts section overrides the global setting.
|
||||
Configuring alerting globally has several limitations as it's not possible to specify different channels
|
||||
or configure the verbosity on a per canary basis. To make the alerting move flexible,
|
||||
the canary analysis can be extended with a list of alerts that reference an alert provider.
|
||||
For each alert, users can configure the severity level. The alerts section overrides the global setting.
|
||||
|
||||
Slack example:
|
||||
|
||||
|
|
@ -65,11 +72,14 @@ data:
|
|||
address: <encoded-url>
|
||||
```
|
||||
|
||||
The alert provider **type** can be: `slack`, `msteams`, `rocket` or `discord`. When set to `discord`, Flagger will use [Slack formatting](https://birdie0.github.io/discord-webhooks-guide/other/slack_formatting.html) and will append `/slack` to the Discord address.
|
||||
The alert provider **type** can be: `slack`, `msteams`, `rocket` or `discord`. When set to `discord`,
|
||||
Flagger will use [Slack formatting](https://birdie0.github.io/discord-webhooks-guide/other/slack_formatting.html)
|
||||
and will append `/slack` to the Discord address.
|
||||
|
||||
When not specified, **channel** defaults to `general` and **username** defaults to `flagger`.
|
||||
|
||||
When **secretRef** is specified, the Kubernetes secret must contain a data field named `address`, the address in the secret will take precedence over the **address** field in the provider spec.
|
||||
When **secretRef** is specified, the Kubernetes secret must contain a data field named `address`,
|
||||
the address in the secret will take precedence over the **address** field in the provider spec.
|
||||
|
||||
The canary analysis can have a list of alerts, each alert referencing an alert provider:
|
||||
|
||||
|
|
@ -94,11 +104,12 @@ The canary analysis can have a list of alerts, each alert referencing an alert p
|
|||
Alert fields:
|
||||
|
||||
* **name** \(required\)
|
||||
* **severity** levels: `info`, `warn`, `error` \(default info\)
|
||||
* **providerRef.name** alert provider name \(required\)
|
||||
* **providerRef.namespace** alert provider namespace \(defaults to the canary namespace\)
|
||||
* **severity** levels: `info`, `warn`, `error` (default info)
|
||||
* **providerRef.name** alert provider name (required)
|
||||
* **providerRef.namespace** alert provider namespace (defaults to the canary namespace)
|
||||
|
||||
When the severity is set to `warn`, Flagger will alert when waiting on manual confirmation or if the analysis fails. When the severity is set to `error`, Flagger will alert only if the canary analysis fails.
|
||||
When the severity is set to `warn`, Flagger will alert when waiting on manual confirmation or if the analysis fails.
|
||||
When the severity is set to `error`, Flagger will alert only if the canary analysis fails.
|
||||
|
||||
## Prometheus Alert Manager
|
||||
|
||||
|
|
@ -114,4 +125,3 @@ You can use Alertmanager to trigger alerts when a canary deployment failed:
|
|||
summary: "Canary failed"
|
||||
description: "Workload {{ $labels.name }} namespace {{ $labels.namespace }}"
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -11,7 +11,8 @@ Flagger can run automated application analysis, promotion and rollback for the f
|
|||
* **Blue/Green Mirroring** \(traffic shadowing\)
|
||||
* Istio
|
||||
|
||||
For Canary releases and A/B testing you'll need a Layer 7 traffic management solution like a service mesh or an ingress controller. For Blue/Green deployments no service mesh or ingress controller is required.
|
||||
For Canary releases and A/B testing you'll need a Layer 7 traffic management solution like
|
||||
a service mesh or an ingress controller. For Blue/Green deployments no service mesh or ingress controller is required.
|
||||
|
||||
A canary analysis is triggered by changes in any of the following objects:
|
||||
|
||||
|
|
@ -21,7 +22,9 @@ A canary analysis is triggered by changes in any of the following objects:
|
|||
|
||||
## Canary Release
|
||||
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pod health. Based on analysis of the KPIs a canary is promoted or aborted.
|
||||
Flagger implements a control loop that gradually shifts traffic to the canary while measuring
|
||||
key performance indicators like HTTP requests success rate, requests average duration and pod health.
|
||||
Based on analysis of the KPIs a canary is promoted or aborted.
|
||||
|
||||

|
||||
|
||||
|
|
@ -49,7 +52,8 @@ Spec:
|
|||
skipAnalysis: false
|
||||
```
|
||||
|
||||
The above analysis, if it succeeds, will run for 25 minutes while validating the HTTP metrics and webhooks every minute. You can determine the minimum time it takes to validate and promote a canary deployment using this formula:
|
||||
The above analysis, if it succeeds, will run for 25 minutes while validating the HTTP metrics and webhooks every minute.
|
||||
You can determine the minimum time it takes to validate and promote a canary deployment using this formula:
|
||||
|
||||
```text
|
||||
interval * (maxWeight / stepWeight)
|
||||
|
|
@ -61,9 +65,13 @@ And the time it takes for a canary to be rollback when the metrics or webhook ch
|
|||
interval * threshold
|
||||
```
|
||||
|
||||
When `stepWeightPromotion` is specified, the promotion phase happens in stages, the traffic is routed back to the primary pods in a progressive manner, the primary weight is increased until it reaches 100%.
|
||||
When `stepWeightPromotion` is specified, the promotion phase happens in stages, the traffic is routed back
|
||||
to the primary pods in a progressive manner, the primary weight is increased until it reaches 100%.
|
||||
|
||||
In emergency cases, you may want to skip the analysis phase and ship changes directly to production. At any time you can set the `spec.skipAnalysis: true`. When skip analysis is enabled, Flagger checks if the canary deployment is healthy and promotes it without analysing it. If an analysis is underway, Flagger cancels it and runs the promotion.
|
||||
In emergency cases, you may want to skip the analysis phase and ship changes directly to production.
|
||||
At any time you can set the `spec.skipAnalysis: true`. When skip analysis is enabled,
|
||||
Flagger checks if the canary deployment is healthy and promotes it without analysing it.
|
||||
If an analysis is underway, Flagger cancels it and runs the promotion.
|
||||
|
||||
Gated canary promotion stages:
|
||||
|
||||
|
|
@ -110,7 +118,8 @@ Gated canary promotion stages:
|
|||
|
||||
### Rollout Weights
|
||||
|
||||
By default Flagger uses linear weight values for the promotion, with the start value, the step and the maximum weight value in 0 to 100 range.
|
||||
By default Flagger uses linear weight values for the promotion, with the start value,
|
||||
the step and the maximum weight value in 0 to 100 range.
|
||||
|
||||
Example:
|
||||
|
||||
|
|
@ -123,11 +132,11 @@ canary:
|
|||
```
|
||||
|
||||
This configuration performs analysis starting from 20, increasing by 20 until weight goes above 50.
|
||||
We would have steps \(canary weight : primary weight\):
|
||||
We would have steps (canary weight : primary weight):
|
||||
|
||||
* 20 \(20 : 80\)
|
||||
* 40 \(40 : 60\)
|
||||
* 60 \(60 : 40\)
|
||||
* 20 (20 : 80)
|
||||
* 40 (40 : 60)
|
||||
* 60 (60 : 40)
|
||||
* promotion
|
||||
|
||||
In order to enable non-linear promotion a new parameter was introduced:
|
||||
|
|
@ -144,21 +153,24 @@ canary:
|
|||
```
|
||||
|
||||
This configuration performs analysis starting from 1, going through `stepWeights` values till 80.
|
||||
We would have steps \(canary weight : primary weight\):
|
||||
We would have steps (canary weight : primary weight):
|
||||
|
||||
* 1 \(1 : 99\)
|
||||
* 2 \(2 : 98\)
|
||||
* 10 \(10 : 90\)
|
||||
* 80 \(20 : 60\)
|
||||
* 1 (1 : 99)
|
||||
* 2 (2 : 98)
|
||||
* 10 (10 : 90)
|
||||
* 80 (20 : 60)
|
||||
* promotion
|
||||
|
||||
## A/B Testing
|
||||
|
||||
For frontend applications that require session affinity you should use HTTP headers or cookies match conditions to ensure a set of users will stay on the same version for the whole duration of the canary analysis.
|
||||
For frontend applications that require session affinity you should use
|
||||
HTTP headers or cookies match conditions to ensure a set of users
|
||||
will stay on the same version for the whole duration of the canary analysis.
|
||||
|
||||
|
||||
|
||||
You can enable A/B testing by specifying the HTTP match conditions and the number of iterations. If Flagger finds a HTTP match condition, it will ignore the `maxWeight` and `stepWeight` settings.
|
||||
You can enable A/B testing by specifying the HTTP match conditions and the number of iterations.
|
||||
If Flagger finds a HTTP match condition, it will ignore the `maxWeight` and `stepWeight` settings.
|
||||
|
||||
Istio example:
|
||||
|
||||
|
|
@ -180,7 +192,8 @@ Istio example:
|
|||
regex: "^(.*?;)?(canary=always)(;.*)?$"
|
||||
```
|
||||
|
||||
The above configuration will run an analysis for ten minutes targeting the Safari users and those that have a test cookie. You can determine the minimum time that it takes to validate and promote a canary deployment using this formula:
|
||||
The above configuration will run an analysis for ten minutes targeting the Safari users and those that have a test cookie.
|
||||
You can determine the minimum time that it takes to validate and promote a canary deployment using this formula:
|
||||
|
||||
```text
|
||||
interval * iterations
|
||||
|
|
@ -210,14 +223,16 @@ Istio example:
|
|||
app.kubernetes.io/name: "scheduler"
|
||||
```
|
||||
|
||||
The header keys must be lowercase and use hyphen as the separator. Header values are case-sensitive and formatted as follows:
|
||||
The header keys must be lowercase and use hyphen as the separator.
|
||||
Header values are case-sensitive and formatted as follows:
|
||||
|
||||
* `exact: "value"` for exact string match
|
||||
* `prefix: "value"` for prefix-based match
|
||||
* `suffix: "value"` for suffix-based match
|
||||
* `regex: "value"` for [RE2](https://github.com/google/re2/wiki/Syntax) style regex-based match
|
||||
|
||||
Note that the `sourceLabels` match conditions are applicable only when the `mesh` gateway is included in the `canary.service.gateways` list.
|
||||
Note that the `sourceLabels` match conditions are applicable only when
|
||||
the `mesh` gateway is included in the `canary.service.gateways` list.
|
||||
|
||||
App Mesh example:
|
||||
|
||||
|
|
@ -265,9 +280,12 @@ NGINX example:
|
|||
exact: "canary"
|
||||
```
|
||||
|
||||
Note that the NGINX ingress controller supports only exact matching for cookies names where the value must be set to `always`. Starting with NGINX ingress v0.31, regex matching is supported for header values.
|
||||
Note that the NGINX ingress controller supports only exact matching for
|
||||
cookies names where the value must be set to `always`.
|
||||
Starting with NGINX ingress v0.31, regex matching is supported for header values.
|
||||
|
||||
The above configurations will route users with the x-canary header or canary cookie to the canary instance during analysis:
|
||||
The above configurations will route users with the x-canary header
|
||||
or canary cookie to the canary instance during analysis:
|
||||
|
||||
```bash
|
||||
curl -H 'X-Canary: insider' http://app.example.com
|
||||
|
|
@ -276,11 +294,14 @@ curl -b 'canary=always' http://app.example.com
|
|||
|
||||
## Blue/Green Deployments
|
||||
|
||||
For applications that are not deployed on a service mesh, Flagger can orchestrate blue/green style deployments with Kubernetes L4 networking. When using Istio you have the option to mirror traffic between blue and green.
|
||||
For applications that are not deployed on a service mesh,
|
||||
Flagger can orchestrate blue/green style deployments with Kubernetes L4 networking.
|
||||
When using Istio you have the option to mirror traffic between blue and green.
|
||||
|
||||

|
||||
|
||||
You can use the blue/green deployment strategy by replacing `stepWeight/maxWeight` with `iterations` in the `analysis` spec:
|
||||
You can use the blue/green deployment strategy by replacing
|
||||
`stepWeight/maxWeight` with `iterations` in the `analysis` spec:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
|
|
@ -292,30 +313,41 @@ You can use the blue/green deployment strategy by replacing `stepWeight/maxWeigh
|
|||
threshold: 2
|
||||
```
|
||||
|
||||
With the above configuration Flagger will run conformance and load tests on the canary pods for ten minutes. If the metrics analysis succeeds, live traffic will be switched from the old version to the new one when the canary is promoted.
|
||||
With the above configuration Flagger will run conformance and load tests on the canary pods for ten minutes.
|
||||
If the metrics analysis succeeds, live traffic will be switched from
|
||||
the old version to the new one when the canary is promoted.
|
||||
|
||||
The blue/green deployment strategy is supported for all service mesh providers.
|
||||
|
||||
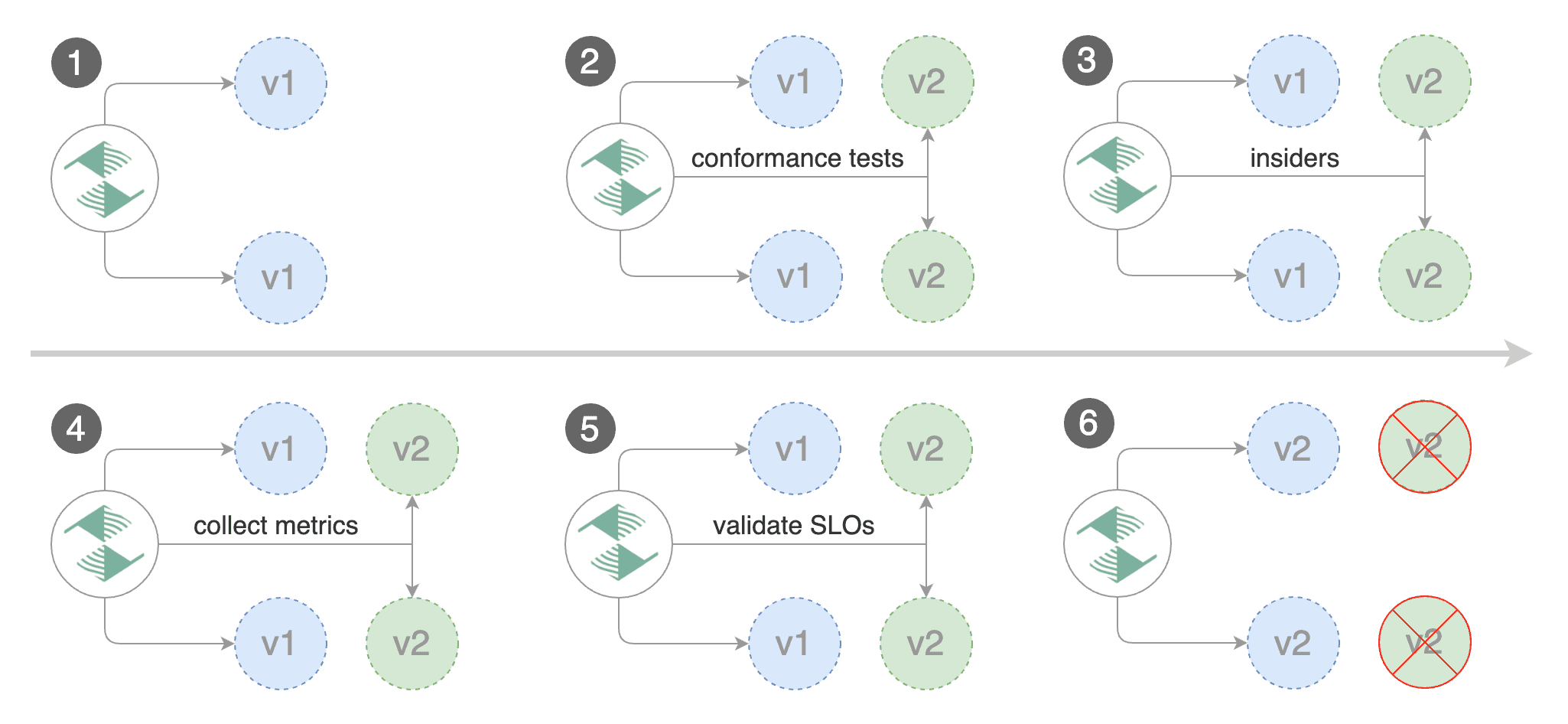
Blue/Green rollout steps for service mesh:
|
||||
|
||||
* detect new revision \(deployment spec, secrets or configmaps changes\)
|
||||
* scale up the canary \(green\)
|
||||
* detect new revision (deployment spec, secrets or configmaps changes)
|
||||
* scale up the canary (green)
|
||||
* run conformance tests for the canary pods
|
||||
* run load tests and metric checks for the canary pods every minute
|
||||
* abort the canary release if the failure threshold is reached
|
||||
* route traffic to canary
|
||||
* promote canary spec over primary \(blue\)
|
||||
* promote canary spec over primary (blue)
|
||||
* wait for primary rollout
|
||||
* route traffic to primary
|
||||
* scale down canary
|
||||
|
||||
After the analysis finishes, the traffic is routed to the canary \(green\) before triggering the primary \(blue\) rolling update, this ensures a smooth transition to the new version avoiding dropping in-flight requests during the Kubernetes deployment rollout.
|
||||
After the analysis finishes, the traffic is routed to the canary (green) before
|
||||
triggering the primary (blue) rolling update,
|
||||
this ensures a smooth transition to the new version avoiding dropping
|
||||
in-flight requests during the Kubernetes deployment rollout.
|
||||
|
||||
## Blue/Green with Traffic Mirroring
|
||||
|
||||
Traffic Mirroring is a pre-stage in a Canary \(progressive traffic shifting\) or Blue/Green deployment strategy. Traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service. The response from the primary is sent back to the user. The response from the canary is discarded. Metrics are collected on both requests so that the deployment will only proceed if the canary metrics are healthy.
|
||||
Traffic Mirroring is a pre-stage in a Canary (progressive traffic shifting) or Blue/Green deployment strategy.
|
||||
Traffic mirroring will copy each incoming request, sending one request to the primary and one to the canary service.
|
||||
The response from the primary is sent back to the user. The response from the canary is discarded.
|
||||
Metrics are collected on both requests so that the deployment will only proceed if the canary metrics are healthy.
|
||||
|
||||
Mirroring should be used for requests that are **idempotent** or capable of being processed twice \(once by the primary and once by the canary\). Reads are idempotent. Before using mirroring on requests that may be writes, you should consider what will happen if a write is duplicated and handled by the primary and canary.
|
||||
Mirroring should be used for requests that are **idempotent** or capable of being processed
|
||||
twice (once by the primary and once by the canary).
|
||||
Reads are idempotent. Before using mirroring on requests that may be writes,
|
||||
you should consider what will happen if a write is duplicated and handled by the primary and canary.
|
||||
|
||||
To use mirroring, set `spec.analysis.mirror` to `true`.
|
||||
|
||||
|
|
@ -337,7 +369,7 @@ Istio example:
|
|||
|
||||
Mirroring rollout steps for service mesh:
|
||||
|
||||
* detect new revision \(deployment spec, secrets or configmaps changes\)
|
||||
* detect new revision (deployment spec, secrets or configmaps changes)
|
||||
* scale from zero the canary deployment
|
||||
* wait for the HPA to set the canary minimum replicas
|
||||
* check canary pods health
|
||||
|
|
@ -357,5 +389,7 @@ Mirroring rollout steps for service mesh:
|
|||
* scale to zero the canary
|
||||
* send notification with the canary analysis result
|
||||
|
||||
After the analysis finishes, the traffic is routed to the canary \(green\) before triggering the primary \(blue\) rolling update, this ensures a smooth transition to the new version avoiding dropping in-flight requests during the Kubernetes deployment rollout.
|
||||
After the analysis finishes, the traffic is routed to the canary (green) before
|
||||
triggering the primary (blue) rolling update, this ensures a smooth transition
|
||||
to the new version avoiding dropping in-flight requests during the Kubernetes deployment rollout.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,10 +1,12 @@
|
|||
# How it works
|
||||
|
||||
[Flagger](https://github.com/fluxcd/flagger) can be configured to automate the release process for Kubernetes workloads with a custom resource named canary.
|
||||
[Flagger](https://github.com/fluxcd/flagger) can be configured to automate the release process for
|
||||
Kubernetes workloads with a custom resource named canary.
|
||||
|
||||
## Canary resource
|
||||
|
||||
The canary custom resource defines the release process of an application running on Kubernetes and is portable across clusters, service meshes and ingress providers.
|
||||
The canary custom resource defines the release process of an application running on Kubernetes and is
|
||||
portable across clusters, service meshes and ingress providers.
|
||||
|
||||
For a deployment named _podinfo_, a canary release with progressive traffic shifting can be defined as:
|
||||
|
||||
|
|
@ -41,9 +43,13 @@ spec:
|
|||
cmd: "hey -z 1m -q 10 -c 2 http://podinfo-canary.test:9898/"
|
||||
```
|
||||
|
||||
When you deploy a new version of an app, Flagger gradually shifts traffic to the canary, and at the same time, measures the requests success rate as well as the average response duration. You can extend the canary analysis with custom metrics, acceptance and load testing to harden the validation process of your app release process.
|
||||
When you deploy a new version of an app, Flagger gradually shifts traffic to the canary, and at the same time,
|
||||
measures the requests success rate as well as the average response duration.
|
||||
You can extend the canary analysis with custom metrics,
|
||||
acceptance and load testing to harden the validation process of your app release process.
|
||||
|
||||
If you are running multiple service meshes or ingress controllers in the same cluster, you can override the global provider for a specific canary with `spec.provider`.
|
||||
If you are running multiple service meshes or ingress controllers in the same cluster,
|
||||
you can override the global provider for a specific canary with `spec.provider`.
|
||||
|
||||
## Canary target
|
||||
|
||||
|
|
@ -69,7 +75,10 @@ Based on the above configuration, Flagger generates the following Kubernetes obj
|
|||
* `deployment/<targetRef.name>-primary`
|
||||
* `hpa/<autoscalerRef.name>-primary`
|
||||
|
||||
The primary deployment is considered the stable release of your app, by default all traffic is routed to this version and the target deployment is scaled to zero. Flagger will detect changes to the target deployment \(including secrets and configmaps\) and will perform a canary analysis before promoting the new version as primary.
|
||||
The primary deployment is considered the stable release of your app,
|
||||
by default all traffic is routed to this version and the target deployment is scaled to zero.
|
||||
Flagger will detect changes to the target deployment (including secrets and configmaps)
|
||||
and will perform a canary analysis before promoting the new version as primary.
|
||||
|
||||
**Note** that the target deployment must have a single label selector in the format `app: <DEPLOYMENT-NAME>`:
|
||||
|
||||
|
|
@ -88,17 +97,32 @@ spec:
|
|||
app: podinfo
|
||||
```
|
||||
|
||||
In addition to `app`, Flagger supports `name` and `app.kubernetes.io/name` selectors. If you use a different convention you can specify your label with the `-selector-labels=my-app-label` command flag in the Flagger deployment manifest under containers args or by setting `--set selectorLabels=my-app-label` when installing Flagger with Helm.
|
||||
In addition to `app`, Flagger supports `name` and `app.kubernetes.io/name` selectors.
|
||||
If you use a different convention you can specify your label with the `-selector-labels=my-app-label`
|
||||
command flag in the Flagger deployment manifest under containers args
|
||||
or by setting `--set selectorLabels=my-app-label` when installing Flagger with Helm.
|
||||
|
||||
If the target deployment uses secrets and/or configmaps, Flagger will create a copy of each object using the `-primary` suffix and will reference these objects in the primary deployment. If you annotate your ConfigMap or Secret with `flagger.app/config-tracking: disabled`, Flagger will use the same object for the primary deployment instead of making a primary copy. You can disable the secrets/configmaps tracking globally with the `-enable-config-tracking=false` command flag in the Flagger deployment manifest under containers args or by setting `--set configTracking.enabled=false` when installing Flagger with Helm, but disabling config-tracking using the the per Secret/ConfigMap annotation may fit your use-case better.
|
||||
If the target deployment uses secrets and/or configmaps,
|
||||
Flagger will create a copy of each object using the `-primary` suffix
|
||||
and will reference these objects in the primary deployment.
|
||||
If you annotate your ConfigMap or Secret with `flagger.app/config-tracking: disabled`,
|
||||
Flagger will use the same object for the primary deployment instead of making a primary copy.
|
||||
You can disable the secrets/configmaps tracking globally with the `-enable-config-tracking=false`
|
||||
command flag in the Flagger deployment manifest under containers args
|
||||
or by setting `--set configTracking.enabled=false` when installing Flagger with Helm,
|
||||
but disabling config-tracking using the per Secret/ConfigMap annotation may fit your use-case better.
|
||||
|
||||
The autoscaler reference is optional, when specified, Flagger will pause the traffic increase while the target and primary deployments are scaled up or down. HPA can help reduce the resource usage during the canary analysis.
|
||||
The autoscaler reference is optional, when specified,
|
||||
Flagger will pause the traffic increase while the target and primary deployments are scaled up or down.
|
||||
HPA can help reduce the resource usage during the canary analysis.
|
||||
|
||||
The progress deadline represents the maximum time in seconds for the canary deployment to make progress before it is rolled back, defaults to ten minutes.
|
||||
The progress deadline represents the maximum time in seconds for the canary deployment to
|
||||
make progress before it is rolled back, defaults to ten minutes.
|
||||
|
||||
## Canary service
|
||||
|
||||
A canary resource dictates how the target workload is exposed inside the cluster. The canary target should expose a TCP port that will be used by Flagger to create the ClusterIP Services.
|
||||
A canary resource dictates how the target workload is exposed inside the cluster.
|
||||
The canary target should expose a TCP port that will be used by Flagger to create the ClusterIP Services.
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
|
|
@ -110,9 +134,14 @@ spec:
|
|||
portDiscovery: true
|
||||
```
|
||||
|
||||
The container port from the target workload should match the `service.port` or `service.targetPort`. The `service.name` is optional, defaults to `spec.targetRef.name`. The `service.targetPort` can be a container port number or name. The `service.portName` is optional \(defaults to `http`\), if your workload uses gRPC then set the port name to `grpc`.
|
||||
The container port from the target workload should match the `service.port` or `service.targetPort`.
|
||||
The `service.name` is optional, defaults to `spec.targetRef.name`.
|
||||
The `service.targetPort` can be a container port number or name.
|
||||
The `service.portName` is optional (defaults to `http`), if your workload uses gRPC then set the port name to `grpc`.
|
||||
|
||||
If port discovery is enabled, Flagger scans the target workload and extracts the containers ports excluding the port specified in the canary service and service mesh sidecar ports. These ports will be used when generating the ClusterIP services.
|
||||
If port discovery is enabled, Flagger scans the target workload and extracts the containers ports
|
||||
excluding the port specified in the canary service and service mesh sidecar ports.
|
||||
These ports will be used when generating the ClusterIP services.
|
||||
|
||||
Based on the canary spec service, Flagger creates the following Kubernetes ClusterIP service:
|
||||
|
||||
|
|
@ -128,7 +157,9 @@ Based on the canary spec service, Flagger creates the following Kubernetes Clust
|
|||
|
||||
selector `app=<name>`
|
||||
|
||||
This ensures that traffic to `podinfo.test:9898` will be routed to the latest stable release of your app. The `podinfo-canary.test:9898` address is available only during the canary analysis and can be used for conformance testing or load testing.
|
||||
This ensures that traffic to `podinfo.test:9898` will be routed to the latest stable release of your app.
|
||||
The `podinfo-canary.test:9898` address is available only during the canary analysis
|
||||
and can be used for conformance testing or load testing.
|
||||
|
||||
You can configure Flagger to set annotations and labels for the generated services with:
|
||||
|
||||
|
|
@ -153,7 +184,8 @@ spec:
|
|||
test: "test"
|
||||
```
|
||||
|
||||
Besides port mapping and metadata, the service specification can contain URI match and rewrite rules, timeout and retry polices:
|
||||
Besides port mapping and metadata, the service specification can
|
||||
contain URI match and rewrite rules, timeout and retry polices:
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
|
|
@ -170,7 +202,9 @@ spec:
|
|||
timeout: 5s
|
||||
```
|
||||
|
||||
When using **Istio** as the mesh provider, you can also specify HTTP header operations, CORS and traffic policies, Istio gateways and hosts. The Istio routing configuration can be found [here](../faq.md#istio-routing).
|
||||
When using **Istio** as the mesh provider, you can also specify HTTP header operations,
|
||||
CORS and traffic policies, Istio gateways and hosts.
|
||||
The Istio routing configuration can be found [here](../faq.md#istio-routing).
|
||||
|
||||
## Canary status
|
||||
|
||||
|
|
@ -209,7 +243,10 @@ status:
|
|||
type: Promoted
|
||||
```
|
||||
|
||||
The `Promoted` status condition can have one of the following reasons: Initialized, Waiting, Progressing, Promoting, Finalising, Succeeded or Failed. A failed canary will have the promoted status set to `false`, the reason to `failed` and the last applied spec will be different to the last promoted one.
|
||||
The `Promoted` status condition can have one of the following reasons:
|
||||
Initialized, Waiting, Progressing, Promoting, Finalising, Succeeded or Failed.
|
||||
A failed canary will have the promoted status set to `false`,
|
||||
the reason to `failed` and the last applied spec will be different to the last promoted one.
|
||||
|
||||
Wait for a successful rollout:
|
||||
|
||||
|
|
@ -239,7 +276,13 @@ kubectl get canary/podinfo | grep Succeeded
|
|||
|
||||
## Canary finalizers
|
||||
|
||||
The default behavior of Flagger on canary deletion is to leave resources that aren't owned by the controller in their current state. This simplifies the deletion action and avoids possible deadlocks during resource finalization. In the event the canary was introduced with existing resource\(s\) \(i.e. service, virtual service, etc.\), they would be mutated during the initialization phase and no longer reflect their initial state. If the desired functionality upon deletion is to revert the resources to their initial state, the `revertOnDeletion` attribute can be enabled.
|
||||
The default behavior of Flagger on canary deletion is to leave resources that aren't owned
|
||||
by the controller in their current state.
|
||||
This simplifies the deletion action and avoids possible deadlocks during resource finalization.
|
||||
In the event the canary was introduced with existing resource(s) (i.e. service, virtual service, etc.),
|
||||
they would be mutated during the initialization phase and no longer reflect their initial state.
|
||||
If the desired functionality upon deletion is to revert the resources to their initial state,
|
||||
the `revertOnDeletion` attribute can be enabled.
|
||||
|
||||
```yaml
|
||||
spec:
|
||||
|
|
@ -252,7 +295,10 @@ When a deletion action is submitted to the cluster, Flagger will attempt to reve
|
|||
* [Canary service](how-it-works.md#canary-service) selector will be reverted
|
||||
* Mesh/Ingress traffic routed to the target
|
||||
|
||||
The recommended approach to disable canary analysis would be utilization of the `skipAnalysis` attribute, which limits the need for resource reconciliation. Utilizing the `revertOnDeletion` attribute should be enabled when you no longer plan to rely on Flagger for deployment management.
|
||||
The recommended approach to disable canary analysis would be utilization of the `skipAnalysis` attribute,
|
||||
which limits the need for resource reconciliation.
|
||||
Utilizing the `revertOnDeletion` attribute should be enabled when
|
||||
you no longer plan to rely on Flagger for deployment management.
|
||||
|
||||
**Note** When this feature is enabled expect a delay in the delete action due to the reconciliation.
|
||||
|
||||
|
|
@ -300,5 +346,8 @@ Spec:
|
|||
- # hook
|
||||
```
|
||||
|
||||
The canary analysis runs periodically until it reaches the maximum traffic weight or the number of iterations. On each run, Flagger calls the webhooks, checks the metrics and if the failed checks threshold is reached, stops the analysis and rolls back the canary. If alerting is configured, Flagger will post the analysis result using the alert providers.
|
||||
The canary analysis runs periodically until it reaches the maximum traffic weight or the number of iterations.
|
||||
On each run, Flagger calls the webhooks, checks the metrics and if the failed checks threshold is reached,
|
||||
stops the analysis and rolls back the canary.
|
||||
If alerting is configured, Flagger will post the analysis result using the alert providers.
|
||||
|
||||
|
|
|
|||
|
|
@ -1,6 +1,10 @@
|
|||
# Metrics Analysis
|
||||
|
||||
As part of the analysis process, Flagger can validate service level objectives \(SLOs\) like availability, error rate percentage, average response time and any other objective based on app specific metrics. If a drop in performance is noticed during the SLOs analysis, the release will be automatically rolled back with minimum impact to end-users.
|
||||
As part of the analysis process, Flagger can validate service level objectives
|
||||
(SLOs) like availability, error rate percentage, average response time and any other objective
|
||||
based on app specific metrics.
|
||||
If a drop in performance is noticed during the SLOs analysis,
|
||||
the release will be automatically rolled back with minimum impact to end-users.
|
||||
|
||||
## Builtin metrics
|
||||
|
||||
|
|
@ -23,11 +27,17 @@ Flagger comes with two builtin metric checks: HTTP request success rate and dura
|
|||
max: 500
|
||||
```
|
||||
|
||||
For each metric you can specify a range of accepted values with `thresholdRange` and the window size or the time series with `interval`. The builtin checks are available for every service mesh / ingress controller and are implemented with [Prometheus queries](../faq.md#metrics).
|
||||
For each metric you can specify a range of accepted values with `thresholdRange` and
|
||||
the window size or the time series with `interval`.
|
||||
The builtin checks are available for every service mesh / ingress controlle
|
||||
and are implemented with [Prometheus queries](../faq.md#metrics).
|
||||
|
||||
## Custom metrics
|
||||
|
||||
The canary analysis can be extended with custom metric checks. Using a `MetricTemplate` custom resource, you configure Flagger to connect to a metric provider and run a query that returns a `float64` value. The query result is used to validate the canary based on the specified threshold range.
|
||||
The canary analysis can be extended with custom metric checks.
|
||||
Using a `MetricTemplate` custom resource,
|
||||
you configure Flagger to connect to a metric provider and run a query that returns a `float64` value.
|
||||
The query result is used to validate the canary based on the specified threshold range.
|
||||
|
||||
```yaml
|
||||
apiVersion: flagger.app/v1beta1
|
||||
|
|
@ -45,12 +55,12 @@ spec:
|
|||
|
||||
The following variables are available in query templates:
|
||||
|
||||
* `name` \(canary.metadata.name\)
|
||||
* `namespace` \(canary.metadata.namespace\)
|
||||
* `target` \(canary.spec.targetRef.name\)
|
||||
* `service` \(canary.spec.service.name\)
|
||||
* `ingress` \(canary.spec.ingresRef.name\)
|
||||
* `interval` \(canary.spec.analysis.metrics\[\].interval\)
|
||||
* `name` (canary.metadata.name)
|
||||
* `namespace` (canary.metadata.namespace)
|
||||
* `target` (canary.spec.targetRef.name)
|
||||
* `service` (canary.spec.service.name)
|
||||
* `ingress` (canary.spec.ingresRef.name)
|
||||
* `interval` (canary.spec.analysis.metrics[].interval)
|
||||
|
||||
A canary analysis metric can reference a template with `templateRef`:
|
||||
|
||||
|
|
@ -73,7 +83,8 @@ A canary analysis metric can reference a template with `templateRef`:
|
|||
|
||||
## Prometheus
|
||||
|
||||
You can create custom metric checks targeting a Prometheus server by setting the provider type to `prometheus` and writing the query in PromQL.
|
||||
You can create custom metric checks targeting a Prometheus server by
|
||||
setting the provider type to `prometheus` and writing the query in PromQL.
|
||||
|
||||
Prometheus template example:
|
||||
|
||||
|
|
@ -124,7 +135,8 @@ Reference the template in the canary analysis:
|
|||
interval: 1m
|
||||
```
|
||||
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
The above configuration validates the canary by checking if the HTTP 404 req/sec percentage
|
||||
is below 5 percent of the total traffic. If the 404s rate reaches the 5% threshold, then the canary fails.
|
||||
|
||||
Prometheus gRPC error rate example:
|
||||
|
||||
|
|
@ -159,11 +171,13 @@ spec:
|
|||
) * 100
|
||||
```
|
||||
|
||||
The above template is for gRPC services instrumented with [go-grpc-prometheus](https://github.com/grpc-ecosystem/go-grpc-prometheus).
|
||||
The above template is for gRPC services instrumented with
|
||||
[go-grpc-prometheus](https://github.com/grpc-ecosystem/go-grpc-prometheus).
|
||||
|
||||
## Prometheus authentication
|
||||
|
||||
If your Prometheus API requires basic authentication, you can create a secret in the same namespace as the `MetricTemplate` with the basic-auth credentials:
|
||||
If your Prometheus API requires basic authentication, you can create a secret in the same namespace
|
||||
as the `MetricTemplate` with the basic-auth credentials:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
|
|
@ -317,7 +331,8 @@ spec:
|
|||
]
|
||||
```
|
||||
|
||||
The query format documentation can be found [here](https://aws.amazon.com/premiumsupport/knowledge-center/cloudwatch-getmetricdata-api/).
|
||||
The query format documentation can be found
|
||||
[here](https://aws.amazon.com/premiumsupport/knowledge-center/cloudwatch-getmetricdata-api/).
|
||||
|
||||
Reference the template in the canary analysis:
|
||||
|
||||
|
|
@ -386,4 +401,3 @@ Reference the template in the canary analysis:
|
|||
max: 5
|
||||
interval: 1m
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -6,7 +6,6 @@ Flagger comes with a Grafana dashboard made for canary analysis. Install Grafana
|
|||
|
||||
```bash
|
||||
helm upgrade -i flagger-grafana flagger/grafana \
|
||||
--namespace=istio-system \ # or appmesh-system
|
||||
--set url=http://prometheus:9090
|
||||
```
|
||||
|
||||
|
|
@ -49,9 +48,11 @@ helm upgrade -i flagger flagger/flagger \
|
|||
--set eventWebhook=https://example.com/flagger-canary-event-webhook
|
||||
```
|
||||
|
||||
The environment variable _EVENT\_WEBHOOK\_URL_ can be used for activating the event-webhook, too. This is handy for using a secret to store a sensible value that could contain api keys for example.
|
||||
The environment variable _EVENT\_WEBHOOK\_URL_ can be used for activating the event-webhook, too.
|
||||
This is handy for using a secret to store a sensible value that could contain api keys for example.
|
||||
|
||||
When configured, every action that Flagger takes during a canary deployment will be sent as JSON via an HTTP POST request. The JSON payload has the following schema:
|
||||
When configured, every action that Flagger takes during a canary deployment
|
||||
will be sent as JSON via an HTTP POST request. The JSON payload has the following schema:
|
||||
|
||||
```javascript
|
||||
{
|
||||
|
|
@ -93,7 +94,8 @@ The event webhook can be overwritten at canary level with:
|
|||
|
||||
## Metrics
|
||||
|
||||
Flagger exposes Prometheus metrics that can be used to determine the canary analysis status and the destination weight values:
|
||||
Flagger exposes Prometheus metrics that can be used to determine
|
||||
the canary analysis status and the destination weight values:
|
||||
|
||||
```bash
|
||||
# Flagger version and mesh provider gauge
|
||||
|
|
@ -116,4 +118,3 @@ flagger_canary_duration_seconds_bucket{name="podinfo",namespace="test",le="+Inf"
|
|||
flagger_canary_duration_seconds_sum{name="podinfo",namespace="test"} 17.3561329
|
||||
flagger_canary_duration_seconds_count{name="podinfo",namespace="test"} 6
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -1,41 +1,33 @@
|
|||
# Webhooks
|
||||
|
||||
The canary analysis can be extended with webhooks. Flagger will call each webhook URL and determine from the response status code \(HTTP 2xx\) if the canary is failing or not.
|
||||
The canary analysis can be extended with webhooks.
|
||||
Flagger will call each webhook URL and determine from the response status code
|
||||
(HTTP 2xx) if the canary is failing or not.
|
||||
|
||||
There are several types of hooks:
|
||||
|
||||
* **confirm-rollout** hooks are executed before scaling up the canary deployment and can be used for manual approval.
|
||||
|
||||
The rollout is paused until the hook returns a successful HTTP status code.
|
||||
|
||||
* **pre-rollout** hooks are executed before routing traffic to canary.
|
||||
|
||||
The canary advancement is paused if a pre-rollout hook fails and if the number of failures reach the
|
||||
|
||||
* **pre-rollout** hooks are executed before routing traffic to canary.
|
||||
The canary advancement is paused if a pre-rollout hook fails and if the number of failures reach the
|
||||
threshold the canary will be rollback.
|
||||
|
||||
* **rollout** hooks are executed during the analysis on each iteration before the metric checks.
|
||||
|
||||
* **rollout** hooks are executed during the analysis on each iteration before the metric checks.
|
||||
If a rollout hook call fails the canary advancement is paused and eventfully rolled back.
|
||||
|
||||
* **confirm-promotion** hooks are executed before the promotion step.
|
||||
|
||||
The canary promotion is paused until the hooks return HTTP 200.
|
||||
|
||||
While the promotion is paused, Flagger will continue to run the metrics checks and rollout hooks.
|
||||
|
||||
* **post-rollout** hooks are executed after the canary has been promoted or rolled back.
|
||||
|
||||
* **post-rollout** hooks are executed after the canary has been promoted or rolled back.
|
||||
If a post rollout hook fails the error is logged.
|
||||
|
||||
* **rollback** hooks are executed while a canary deployment is in either Progressing or Waiting status.
|
||||
|
||||
This provides the ability to rollback during analysis or while waiting for a confirmation. If a rollback hook
|
||||
|
||||
returns a successful HTTP status code, Flagger will stop the analysis and mark the canary release as failed.
|
||||
|
||||
* **event** hooks are executed every time Flagger emits a Kubernetes event. When configured,
|
||||
|
||||
every action that Flagger takes during a canary deployment will be sent as JSON via an HTTP POST request.
|
||||
|
||||
Spec:
|
||||
|
|
@ -78,7 +70,7 @@ Spec:
|
|||
|
||||
> **Note** that the sum of all rollout webhooks timeouts should be lower than the analysis interval.
|
||||
|
||||
Webhook payload \(HTTP POST\):
|
||||
Webhook payload (HTTP POST):
|
||||
|
||||
```javascript
|
||||
{
|
||||
|
|
@ -97,9 +89,9 @@ Response status codes:
|
|||
* 200-202 - advance canary by increasing the traffic weight
|
||||
* timeout or non-2xx - halt advancement and increment failed checks
|
||||
|
||||
On a non-2xx response Flagger will include the response body \(if any\) in the failed checks log and Kubernetes events.
|
||||
On a non-2xx response Flagger will include the response body (if any) in the failed checks log and Kubernetes events.
|
||||
|
||||
Event payload \(HTTP POST\):
|
||||
Event payload (HTTP POST):
|
||||
|
||||
```javascript
|
||||
{
|
||||
|
|
@ -114,13 +106,18 @@ Event payload \(HTTP POST\):
|
|||
}
|
||||
```
|
||||
|
||||
The event receiver can create alerts based on the received phase \(possible values: `Initialized`, `Waiting`, `Progressing`, `Promoting`, `Finalising`, `Succeeded` or `Failed`\).
|
||||
The event receiver can create alerts based on the received phase
|
||||
(possible values: `Initialized`, `Waiting`, `Progressing`, `Promoting`, `Finalising`, `Succeeded` or `Failed`).
|
||||
|
||||
## Load Testing
|
||||
|
||||
For workloads that are not receiving constant traffic Flagger can be configured with a webhook, that when called, will start a load test for the target workload. If the target workload doesn't receive any traffic during the canary analysis, Flagger metric checks will fail with "no values found for metric request-success-rate".
|
||||
For workloads that are not receiving constant traffic Flagger can be configured with a webhook,
|
||||
that when called, will start a load test for the target workload.
|
||||
If the target workload doesn't receive any traffic during the canary analysis,
|
||||
Flagger metric checks will fail with "no values found for metric request-success-rate".
|
||||
|
||||
Flagger comes with a load testing service based on [rakyll/hey](https://github.com/rakyll/hey) that generates traffic during analysis when configured as a webhook.
|
||||
Flagger comes with a load testing service based on [rakyll/hey](https://github.com/rakyll/hey)
|
||||
that generates traffic during analysis when configured as a webhook.
|
||||
|
||||
|
||||
|
||||
|
|
@ -160,7 +157,10 @@ webhooks:
|
|||
cmd: "hey -z 1m -q 10 -c 2 -m POST -d '{test: 2}' http://podinfo-canary.test:9898/echo"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the webhooks and the load tester will run the `hey` commands in the background, if they are not already running. This will ensure that during the analysis, the `podinfo-canary.test` service will receive a steady stream of GET and POST requests.
|
||||
When the canary analysis starts, Flagger will call the webhooks and the load tester will
|
||||
run the `hey` commands in the background, if they are not already running.
|
||||
This will ensure that during the analysis, the `podinfo-canary.test`
|
||||
service will receive a steady stream of GET and POST requests.
|
||||
|
||||
If your workload is exposed outside the mesh you can point `hey` to the public URL and use HTTP2.
|
||||
|
||||
|
|
@ -186,7 +186,11 @@ webhooks:
|
|||
cmd: "ghz -z 1m -q 10 -c 2 --insecure podinfo.test:9898"
|
||||
```
|
||||
|
||||
`ghz` uses reflection to identify which gRPC method to call. If you do not wish to enable reflection for your gRPC service you can implement a standardized health check from the [grpc-proto](https://github.com/grpc/grpc-proto) library. To use this [health check schema](https://github.com/grpc/grpc-proto/blob/master/grpc/health/v1/health.proto) without reflection you can pass a parameter to `ghz` like this
|
||||
`ghz` uses reflection to identify which gRPC method to call.
|
||||
If you do not wish to enable reflection for your gRPC service you can implement a standardized
|
||||
health check from the [grpc-proto](https://github.com/grpc/grpc-proto) library.
|
||||
To use this [health check schema](https://github.com/grpc/grpc-proto/blob/master/grpc/health/v1/health.proto)
|
||||
without reflection you can pass a parameter to `ghz` like this
|
||||
|
||||
```yaml
|
||||
webhooks:
|
||||
|
|
@ -198,7 +202,8 @@ webhooks:
|
|||
cmd: "ghz --insecure --proto=/tmp/ghz/health.proto --call=grpc.health.v1.Health/Check podinfo.test:9898"
|
||||
```
|
||||
|
||||
The load tester can run arbitrary commands as long as the binary is present in the container image. For example if you you want to replace `hey` with another CLI, you can create your own Docker image:
|
||||
The load tester can run arbitrary commands as long as the binary is present in the container image.
|
||||
For example if you want to replace `hey` with another CLI, you can create your own Docker image:
|
||||
|
||||
```text
|
||||
FROM weaveworks/flagger-loadtester:<VER>
|
||||
|
|
@ -209,7 +214,8 @@ RUN curl -Lo /usr/local/bin/my-cli https://github.com/user/repo/releases/downloa
|
|||
|
||||
## Load Testing Delegation
|
||||
|
||||
The load tester can also forward testing tasks to external tools, by now [nGrinder](https://github.com/naver/ngrinder) is supported.
|
||||
The load tester can also forward testing tasks to external tools,
|
||||
by now [nGrinder](https://github.com/naver/ngrinder) is supported.
|
||||
|
||||
To use this feature, add a load test task of type 'ngrinder' to the canary analysis spec:
|
||||
|
||||
|
|
@ -232,7 +238,11 @@ webhooks:
|
|||
pollInterval: 5s
|
||||
```
|
||||
|
||||
When the canary analysis starts, the load tester will initiate a [clone\_and\_start request](https://github.com/naver/ngrinder/wiki/REST-API-PerfTest) to the nGrinder server and start a new performance test. the load tester will periodically poll the nGrinder server for the status of the test, and prevent duplicate requests from being sent in subsequent analysis loops.
|
||||
When the canary analysis starts, the load tester will initiate a
|
||||
[clone_and_start request](https://github.com/naver/ngrinder/wiki/REST-API-PerfTest)
|
||||
to the nGrinder server and start a new performance test. the load tester will periodically
|
||||
poll the nGrinder server for the status of the test,
|
||||
and prevent duplicate requests from being sent in subsequent analysis loops.
|
||||
|
||||
## Integration Testing
|
||||
|
||||
|
|
@ -264,9 +274,11 @@ Now you can add pre-rollout webhooks to the canary analysis spec:
|
|||
cmd: "test {{ .Release.Name }} --cleanup"
|
||||
```
|
||||
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary. If the helm test fails, Flagger will retry until the analysis threshold is reached and the canary is rolled back.
|
||||
When the canary analysis starts, Flagger will call the pre-rollout webhooks before routing traffic to the canary.
|
||||
If the helm test fails, Flagger will retry until the analysis threshold is reached and the canary is rolled back.
|
||||
|
||||
If you are using Helm v3, you'll have to create a dedicated service account and add the release namespace to the test command:
|
||||
If you are using Helm v3,
|
||||
you'll have to create a dedicated service account and add the release namespace to the test command:
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
|
|
@ -280,9 +292,11 @@ If you are using Helm v3, you'll have to create a dedicated service account and
|
|||
cmd: "test {{ .Release.Name }} --timeout 3m -n {{ .Release.Namespace }}"
|
||||
```
|
||||
|
||||
If the test hangs or logs error messages hinting to insufficient permissions it can be related to RBAC, check the [Troubleshooting](webhooks.md#Troubleshooting) section for an example configuration.
|
||||
If the test hangs or logs error messages hinting to insufficient permissions it can be related to RBAC,
|
||||
check the [Troubleshooting](webhooks.md#Troubleshooting) section for an example configuration.
|
||||
|
||||
As an alternative to Helm you can use the [Bash Automated Testing System](https://github.com/bats-core/bats-core) to run your tests.
|
||||
As an alternative to Helm you can use the
|
||||
[Bash Automated Testing System](https://github.com/bats-core/bats-core) to run your tests.
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
|
|
@ -319,13 +333,24 @@ You can also configure the test runner to start a [Concord](https://concord.walm
|
|||
pollTimeout: "60"
|
||||
```
|
||||
|
||||
`org`, `project`, `repo` and `entrypoint` represents where your test process runs in Concord. In order to authenticate to Concord, you need to set `apiKeyPath` to a path of a file containing a valid Concord API key on the `flagger-helmtester` container. This can be done via mounting a Kubernetes secret in the tester's Deployment. `pollInterval` represents the interval in seconds the web-hook will call Concord to see if the process has finished \(Default is 5s\). `pollTimeout` represents the time in seconds the web-hook will try to call Concord before timing out \(Default is 30s\).
|
||||
`org`, `project`, `repo` and `entrypoint` represents where your test process runs in Concord.
|
||||
In order to authenticate to Concord, you need to set `apiKeyPath`
|
||||
to a path of a file containing a valid Concord API key on the `flagger-helmtester` container.
|
||||
This can be done via mounting a Kubernetes secret in the tester's Deployment.
|
||||
`pollInterval` represents the interval in seconds the web-hook will call Concord
|
||||
to see if the process has finished (Default is 5s). `pollTimeout` represents the time in seconds
|
||||
the web-hook will try to call Concord before timing out (Default is 30s).
|
||||
|
||||
## Manual Gating
|
||||
|
||||
For manual approval of a canary deployment you can use the `confirm-rollout` and `confirm-promotion` webhooks. The confirmation rollout hooks are executed before the pre-rollout hooks. Flagger will halt the canary traffic shifting and analysis until the confirm webhook returns HTTP status 200.
|
||||
For manual approval of a canary deployment you can use the `confirm-rollout` and `confirm-promotion` webhooks.
|
||||
The confirmation rollout hooks are executed before the pre-rollout hooks.
|
||||
Flagger will halt the canary traffic shifting and analysis until the confirm webhook returns HTTP status 200.
|
||||
|
||||
For manual rollback of a canary deployment you can use the `rollback` webhook. The rollback hook will be called during the analysis and confirmation states. If a rollback webhook returns a successful HTTP status code, Flagger will shift all traffic back to the primary instance and fail the canary.
|
||||
For manual rollback of a canary deployment you can use the `rollback` webhook.
|
||||
The rollback hook will be called during the analysis and confirmation states.
|
||||
If a rollback webhook returns a successful HTTP status code,
|
||||
Flagger will shift all traffic back to the primary instance and fail the canary.
|
||||
|
||||
Manual gating with Flagger's tester:
|
||||
|
||||
|
|
@ -339,7 +364,8 @@ Manual gating with Flagger's tester:
|
|||
|
||||
The `/gate/halt` returns HTTP 403 thus blocking the rollout.
|
||||
|
||||
If you have notifications enabled, Flagger will post a message to Slack or MS Teams if a canary rollout is waiting for approval.
|
||||
If you have notifications enabled, Flagger will post a message to
|
||||
Slack or MS Teams if a canary rollout is waiting for approval.
|
||||
|
||||
Change the URL to `/gate/approve` to start the canary analysis:
|
||||
|
||||
|
|
@ -384,7 +410,8 @@ NAME STATUS WEIGHT
|
|||
podinfo Waiting 0
|
||||
```
|
||||
|
||||
The `confirm-promotion` hook type can be used to manually approve the canary promotion. While the promotion is paused, Flagger will continue to run the metrics checks and load tests.
|
||||
The `confirm-promotion` hook type can be used to manually approve the canary promotion.
|
||||
While the promotion is paused, Flagger will continue to run the metrics checks and load tests.
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
|
|
@ -394,7 +421,8 @@ The `confirm-promotion` hook type can be used to manually approve the canary pro
|
|||
url: http://flagger-loadtester.test/gate/halt
|
||||
```
|
||||
|
||||
The `rollback` hook type can be used to manually rollback the canary promotion. As with gating, rollbacks can be driven with Flagger's tester API by setting the rollback URL to `/rollback/check`
|
||||
The `rollback` hook type can be used to manually rollback the canary promotion.
|
||||
As with gating, rollbacks can be driven with Flagger's tester API by setting the rollback URL to `/rollback/check`
|
||||
|
||||
```yaml
|
||||
analysis:
|
||||
|
|
@ -404,7 +432,7 @@ The `rollback` hook type can be used to manually rollback the canary promotion.
|
|||
url: http://flagger-loadtester.test/rollback/check
|
||||
```
|
||||
|
||||
By default rollback is closed, you can rollback a canary rollout with:
|
||||
By default, rollback is closed, you can rollback a canary rollout with:
|
||||
|
||||
```bash
|
||||
kubectl -n test exec -it flagger-loadtester-xxxx-xxxx sh
|
||||
|
|
@ -468,4 +496,3 @@ roleRef:
|
|||
name: helm-smoke-tester
|
||||
apiGroup: rbac.authorization.k8s.io
|
||||
```
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue