mirror of https://github.com/kubeflow/examples.git
Add files via upload
This commit is contained in:
parent
0870f9157a
commit
76e882ed0b
|
|
@ -0,0 +1,61 @@
|
|||
目的 :
|
||||
|
||||
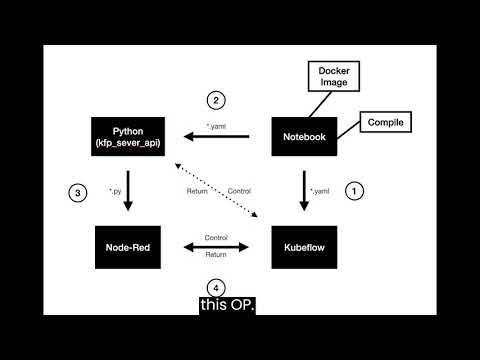
這是一個node-red搭配kubeflow的作品,node-red作為畫面顯示,而kubeflow則是資料處理。在這個作品我將LSTM、mnist節點放在node-red,點擊該節點後,kubeflow則執行對應模型,模型所使用的輸入資料是normal.csv & abnormal.csv,輸出則是資料經模型訓練後的準確度。
|
||||
|
||||
安裝 :
|
||||
|
||||
1. 將檔案 git clone 到 windows/System32
|
||||
2. 執行 Docker
|
||||
3. 執行 Wsl 並依序輸入 cd kube-nodered, cd examples, 最後是 ./run.sh 1.connect-kubeflow
|
||||
4. 查 Docker 是否有生成的容器和映像檔
|
||||
5. 執行 Docker 映像檔並執行 node-red
|
||||
6. 執行 node-red後, 點擊 'intsall dependency', 接著使用者可以在'six pipeline' 頁面執行模型
|
||||
7. 到路徑 kube-nodered\examples\1.connect-kubeflow\py 中調整目錄底下的模型Python檔案,將登錄帳密改為使用者的
|
||||
===============================================================================
|
||||
|
||||
架構 :
|
||||
|
||||
客製化節點的關鍵在於更改.flows.json、加入js.和html到nodepipe資料夾、加入模型python到py資料夾和加入模型pipeline到pipeline資料夾。node-red顯示的部分 : .flow.json更改會影響node-red節點的顯示,nodepipe的js.和html可以客製一個節點的功能欄位,如下拉選單。Kubeflow執行的部分 : 模型的python和pipeline。
|
||||
以下是各個檔案的路徑
|
||||
1. C:\Windows\System32\kube-nodered\examples\1.connect-kubeflo的.flow.json
|
||||
2. C:\Windows\System32\kube-nodered\examples\1.connect-kubeflow\node_modules\nodepipe的js.和html
|
||||
3. C:\Windows\System32\kube-nodered\examples\1.connect-kubeflow\py的模型python
|
||||
4. C:\Windows\System32\kube-nodered\examples\1.connect-kubeflow\py\pipelines的模型pipeline
|
||||
5.
|
||||
================================================================================
|
||||
|
||||
輸入和輸出 :
|
||||
|
||||
輸入資料
|
||||

|
||||
輸出結果
|
||||

|
||||
|
||||
=================================================================================
|
||||
|
||||
操作說明 :
|
||||
|
||||
打開node-red後,先點擊圖中按鈕,安裝所需套件
|
||||

|
||||
點擊圖中圓圈,切換分頁到模型節點
|
||||

|
||||
切換後的分頁
|
||||

|
||||
點擊圖中按鈕,kubeflow會執行對應pipeline
|
||||

|
||||
可在畫面右側確認執行狀況,圖中範例為LSTM pipeline正在執行
|
||||

|
||||
在node-red上點擊執行後,可在kubeflow上看到新增的執行pipeline
|
||||

|
||||
Kubeflow上的執行結果
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,201 @@
|
|||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
|
@ -0,0 +1,354 @@
|
|||
# Kube-node-red(en)
|
||||
[](https://hackmd.io/cocSOGQMR-qzo7DHdwgRsQ)
|
||||
|
||||
Kube-node-red is aiming to integrate Kubeflow/Kubebeters with node-red, leveraging node-red's low-code modules, and using Kubeflow resources (e.g. Kubeflow pipeline, Kserve) to enhance its AI/ML ability.
|
||||
## Table of Contents
|
||||
<!-- toc -->
|
||||
|
||||
- [Installation](#installation)
|
||||
* [Prerequisites](#Prerequisites)
|
||||
* [Building](#Building)
|
||||
* [Install dependencies](#Install-dependencies)
|
||||
- [Using our nodes](#Using-our-nodes)
|
||||
- [Test python files to interact with kubeflow](#Test-python-files-to-interact-with-kubeflow)
|
||||
- [possible problems and solution](#possible-problems-and-solution)
|
||||
- [Modify your own custom nodes/pipeline](#Modify-your-own-custom-nodes/pipeline)
|
||||
* [Kubeflow part](#Kubeflow-part)
|
||||
* [Node-red part](#Node-red-part)
|
||||
- [Architecture](#Architecture)
|
||||
- [Demo](#Demo)
|
||||
- [Reference](#Reference)
|
||||
|
||||
<!-- tocstop -->
|
||||
|
||||
# Installation
|
||||
## Prerequisites
|
||||
- `Kubeflow`
|
||||
As this project focused on the node-red integration with Kubeflow, one running Kubeflow instance should be ready on a publicly available network.
|
||||
(If you need to provision your own Kubeflow instance, you could refer to our [mulitkf](https://github.com/footprintai/multikf) project to allocate one instance for developing.)
|
||||
- [`WSL`](https://learn.microsoft.com/en-us/windows/wsl/install) If you are Windows OS.
|
||||
- [`Docker`](https://www.docker.com)
|
||||
|
||||
## Building
|
||||
|
||||
We organized some examples under examples folder, and make sensitive information pass via environment variables. Please refer the following example to launch an individual example:
|
||||
|
||||
1. In terminal (If you on Windows system, please use WSL)
|
||||
```
|
||||
$ git clone https://github.com/NightLightTw/kube-nodered.git
|
||||
```
|
||||
2. Enter target folder
|
||||
```
|
||||
cd kube-nodered/examples
|
||||
```
|
||||
3. Enter account information and start
|
||||
```
|
||||
KUBEFLOW_HOST=<your-kubeflow-instance-endpoint> \
|
||||
KUBEFLOW_USERNAME=<your-username-account> \
|
||||
KUBEFLOW_PASSWORD=<your-password> \
|
||||
./run.sh <example-index>
|
||||
```
|
||||
> **Info:** Here <example-index> please use 1.connect-kubeflow
|
||||
|
||||
## Install dependencies
|
||||
|
||||
1. Then you can go to UI, check it out: http://127.0.0.1:1880/
|
||||

|
||||
|
||||
2. Click the “install dependency” button to install dependency items such as specific python libraries and wait for its completion
|
||||

|
||||
|
||||
3. Click the “list experiments” button to test the environment work!
|
||||

|
||||
|
||||
## Using our nodes
|
||||
Switch to the "three-pipeline" flow and press the button to trigger the pipeline process
|
||||
|
||||

|
||||
|
||||
On kubeflow:
|
||||

|
||||
|
||||
|
||||
|
||||
> **Info:** If the environment variable does not work, please fill in the account password directly in the python file
|
||||
|
||||
|
||||
## Test python files to interact with kubeflow
|
||||
```
|
||||
# Open another terminal and check docker status
|
||||
docker ps
|
||||
#enter container
|
||||
docker exec -it <containerID> bash
|
||||
#enter document folder
|
||||
cd /data/1.connect-kubeflow/py/api_examples
|
||||
#execute function
|
||||
python3 <file-name>
|
||||
```
|
||||
|
||||
You can test the file in api_example
|
||||
> **Info:** Some of these files require a custom name, description, or assigned id in <change yours>
|
||||
|
||||
## Possible problems and solution
|
||||
Q1: MissingSchema Invalid URL ''
|
||||
|
||||
A1: This problem means that the login information is not accessed correctly, which may be caused by the environment variable not being read.
|
||||
You can directly override the login information of the specified file
|
||||
|
||||
ex:
|
||||
|
||||
Change to your own login information
|
||||
```
|
||||
host = "https://example@test.com"
|
||||
username = "test01"
|
||||
password = "123456"
|
||||
```
|
||||
|
||||
# Modify your own custom nodes/pipeline
|
||||

|
||||
|
||||
## Kubeflow part
|
||||
### Custom make pipeline’s yaml file
|
||||
Please refer to [Kubeflow implementation:add Random Forest algorithm](https://hackmd.io/@Nhi7So-lTz2m5R6pHyCLcA/Sk1eZFTbh)
|
||||
|
||||
### Take changing randomForest.py as an example
|
||||
|
||||
Modify using your own yaml file path
|
||||
> **Info:** Line 66: uploadfile='pipelines/only_randomforest.yaml'
|
||||
|
||||
> **Info:** Line 122~129 use json parser for filtering different outputs from get_run()
|
||||
|
||||
```python=
|
||||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import string
|
||||
import random
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
def random_suffix() -> string:
|
||||
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=10))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the Experiment API class
|
||||
experiment_api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
name="experiment-" + random_suffix()
|
||||
description="This is a experiment for only_randomforest."
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(
|
||||
type=kfp_server_api.models.ApiResourceType.NAMESPACE,
|
||||
id=resource_reference_key_id
|
||||
),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER
|
||||
)]
|
||||
body = kfp_server_api.ApiExperiment(name=name, description=description, resource_references=resource_references) # ApiExperiment | The experiment to be created.
|
||||
try:
|
||||
# Creates a new experiment.
|
||||
experiment_api_response = experiment_api_instance.create_experiment(body)
|
||||
experiment_id = experiment_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->create_experiment: %s\n" % e)
|
||||
|
||||
# Create an instance of the pipeline API class
|
||||
api_instance = kfp_server_api.PipelineUploadServiceApi(api_client)
|
||||
uploadfile='pipelines/only_randomforest.yaml'
|
||||
name='pipeline-' + random_suffix()
|
||||
description="This is a only_randomForest pipline."
|
||||
try:
|
||||
pipeline_api_response = api_instance.upload_pipeline(uploadfile, name=name, description=description)
|
||||
pipeline_id = pipeline_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineUploadServiceApi->upload_pipeline: %s\n" % e)
|
||||
|
||||
# Create an instance of the run API class
|
||||
run_api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
display_name = 'run_only_randomForest' + random_suffix()
|
||||
description = "This is a only_randomForest run."
|
||||
pipeline_spec = kfp_server_api.ApiPipelineSpec(pipeline_id=pipeline_id)
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(id=experiment_id, type=kfp_server_api.models.ApiResourceType.EXPERIMENT),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER )]
|
||||
body = kfp_server_api.ApiRun(name=display_name, description=description, pipeline_spec=pipeline_spec, resource_references=resource_references) # ApiRun |
|
||||
try:
|
||||
# Creates a new run.
|
||||
run_api_response = run_api_instance.create_run(body)
|
||||
run_id = run_api_response.run.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->create_run: %s\n" % e)
|
||||
|
||||
Completed_flag = False
|
||||
polling_interval = 10 # Time in seconds between polls
|
||||
|
||||
while not Completed_flag:
|
||||
try:
|
||||
time.sleep(1)
|
||||
# Finds a specific run by ID.
|
||||
api_instance = run_api_instance.get_run(run_id)
|
||||
output = api_instance.pipeline_runtime.workflow_manifest
|
||||
output = json.loads(output)
|
||||
|
||||
try:
|
||||
nodes = output['status']['nodes']
|
||||
conditions = output['status']['conditions'] # Comfirm completion.
|
||||
|
||||
except KeyError:
|
||||
nodes = {}
|
||||
conditions = []
|
||||
|
||||
output_value = None
|
||||
Completed_flag = conditions[1]['status'] if len(conditions) > 1 else False
|
||||
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->get_run: %s\n" % e)
|
||||
break
|
||||
|
||||
if not Completed_flag:
|
||||
print("Pipeline is still running. Waiting...")
|
||||
time.sleep(polling_interval-1)
|
||||
|
||||
for node_id, node in nodes.items():
|
||||
if 'inputs' in node and 'parameters' in node['inputs']:
|
||||
for parameter in node['inputs']['parameters']:
|
||||
if parameter['name'] == 'random-forest-classifier-Accuracy': #change parameter
|
||||
output_value = parameter['value']
|
||||
|
||||
if output_value is not None:
|
||||
print(f"Random Forest Classifier Accuracy: {output_value}")
|
||||
else:
|
||||
print("Parameter not found.")
|
||||
print(nodes)
|
||||
```
|
||||
|
||||
## Node-red part
|
||||
**Package nodered pyshell node**
|
||||
|
||||
**A node mainly consists of two files**
|
||||
* **Javascript file(.js)**
|
||||
define what the node does
|
||||
* **HTML file(.html)**
|
||||
Define the properties of the node and the windows and help messages in the Node-RED editor
|
||||
|
||||
**When finally package into npm module, will need package.json**
|
||||
|
||||
|
||||
### **package.json**
|
||||
A standard file for describing the content of node.js modules
|
||||
|
||||
A standard package.json can be generated using npm init. This command will ask a series of questions to find a reasonable default value. When asked for the name of the module name:<default value> enter the example name node-red-contrib-<self_defined>
|
||||
|
||||
When it is established, you need to manually add the node-red attribute
|
||||
*p.s. Where the example files need to be changed *
|
||||
|
||||
|
||||
|
||||
```json=
|
||||
{
|
||||
"name": "node-red-contrib-pythonshell-custom",
|
||||
...
|
||||
"node-red": {
|
||||
"nodes": {
|
||||
"decisionTree": "decisiontree.js",
|
||||
"randomForest": "randomforest.js",
|
||||
"logisticRegression": "logisticregression.js"
|
||||
"<self_defined>":"<self_defined.js>"
|
||||
}
|
||||
},
|
||||
...
|
||||
}
|
||||
|
||||
```
|
||||
### **HTML**
|
||||
```javascript=
|
||||
<script type="text/javascript">
|
||||
# Replace the node name displayed/registered in the palette
|
||||
RED.nodes.registerType('decisionTree',{
|
||||
category: 'input',
|
||||
defaults: {
|
||||
name: {required: false},
|
||||
# Replace the .py path to be used
|
||||
pyfile: {value: "/data/1.connect-kubeflow/py/decisionTree.py"},
|
||||
virtualenv: {required: false},
|
||||
continuous: {required: false},
|
||||
stdInData: {required: false},
|
||||
python3: {required: false}
|
||||
},
|
||||
```
|
||||
### **Javascript(main function)**
|
||||
1.Open decisionTree.js
|
||||
```javascript=
|
||||
function PythonshellInNode(config) {
|
||||
if (!config.pyfile){
|
||||
throw 'pyfile not present';
|
||||
}
|
||||
this.pythonExec = config.python3 ? "python3" : "python";
|
||||
# Replace the path or change the following path to config.pyfile
|
||||
this.pyfile = "/data/1.connect-kubeflow/py/decisionTree.py";
|
||||
this.virtualenv = config.virtualenv;
|
||||
```
|
||||
2.Open deccisiontree.js
|
||||
```javascript=
|
||||
var util = require("util");
|
||||
var httpclient;
|
||||
#change the path/file name of the module file
|
||||
var PythonshellNode = require('./decisionTree');
|
||||
|
||||
# To change the name to be registered, it must be consistent with the change of .html
|
||||
RED.nodes.registerType("decisionTree", PythonshellInNode);
|
||||
```
|
||||
|
||||
### Connect nodered
|
||||
Import the folder where the above file is located to the node_modules directory of the container
|
||||
e.g. docker desktop
|
||||

|
||||
e.g. wsl
|
||||

|
||||
|
||||
## Architecture
|
||||

|
||||
|
||||
## Demo
|
||||
[](https://youtu.be/72tXYl6FcvU)
|
||||
|
||||
## Reference
|
||||
https://github.com/NightLightTw/kube-nodered
|
||||
|
||||
https://github.com/kubeflow/pipelines/tree/1.8.21/backend/api/python_http_client
|
||||
|
||||
[Kubeflow implementation:add Random Forest algorithm](https://hackmd.io/@ZJ2023/BJYQGMvJ6)
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
[
|
||||
{
|
||||
"id": "f6f2187d.f17ca8",
|
||||
"type": "tab",
|
||||
"label": "Flow 1",
|
||||
"disabled": false,
|
||||
"info": ""
|
||||
},
|
||||
{
|
||||
"id": "3cc11d24.ff01a2",
|
||||
"type": "comment",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "WARNING: please check you have started this container with a volume that is mounted to /data\\n otherwise any flow changes are lost when you redeploy or upgrade the container\\n (e.g. upgrade to a more recent node-red docker image).\\n If you are using named volumes you can ignore this warning.\\n Double click or see info side panel to learn how to start Node-RED in Docker to save your work",
|
||||
"info": "\nTo start docker with a bind mount volume (-v option), for example:\n\n```\ndocker run -it -p 1880:1880 -v /home/user/node_red_data:/data --name mynodered nodered/node-red\n```\n\nwhere `/home/user/node_red_data` is a directory on your host machine where you want to store your flows.\n\nIf you do not do this then you can experiment and redploy flows, but if you restart or upgrade the container the flows will be disconnected and lost. \n\nThey will still exist in a hidden data volume, which can be recovered using standard docker techniques, but that is much more complex than just starting with a named volume as described above.",
|
||||
"x": 350,
|
||||
"y": 80,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "c228c538ddfd97cc",
|
||||
"type": "inject",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"props": [
|
||||
{
|
||||
"p": "payload"
|
||||
},
|
||||
{
|
||||
"p": "topic",
|
||||
"vt": "str"
|
||||
}
|
||||
],
|
||||
"repeat": "",
|
||||
"crontab": "",
|
||||
"once": false,
|
||||
"onceDelay": 0.1,
|
||||
"topic": "",
|
||||
"payload": "",
|
||||
"payloadType": "date",
|
||||
"x": 300,
|
||||
"y": 440,
|
||||
"wires": [
|
||||
[
|
||||
"fae8437b33358ca0"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "fae8437b33358ca0",
|
||||
"type": "function",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"func": "// Create a Date object from the payload\nvar date = new Date(msg.payload);\n// Change the payload to be a formatted Date string\nmsg.payload = date.toString();\n// Return the message so it can be sent on\nreturn msg;",
|
||||
"outputs": 1,
|
||||
"noerr": 0,
|
||||
"initialize": "",
|
||||
"finalize": "",
|
||||
"libs": [],
|
||||
"x": 480,
|
||||
"y": 440,
|
||||
"wires": [
|
||||
[
|
||||
"7588c855ba3f1c81"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "7588c855ba3f1c81",
|
||||
"type": "pythonshell in",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "hellepython",
|
||||
"pyfile": "/data/0.helloworld/helloworld.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": true,
|
||||
"x": 670,
|
||||
"y": 440,
|
||||
"wires": [
|
||||
[
|
||||
"b126ea03f7d74573"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "b126ea03f7d74573",
|
||||
"type": "debug",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "payload",
|
||||
"targetType": "msg",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 870,
|
||||
"y": 440,
|
||||
"wires": []
|
||||
}
|
||||
]
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
{
|
||||
"$": "debb1e3e4666ba98dd5189a6e20b7e40jk4="
|
||||
}
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
import sys
|
||||
|
||||
while True:
|
||||
line = sys.stdin.readline()
|
||||
print('this is send from python')
|
||||
print(line)
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
{
|
||||
"name": "node-red-project",
|
||||
"description": "A Node-RED Project",
|
||||
"version": "0.0.1",
|
||||
"private": true
|
||||
}
|
||||
|
|
@ -0,0 +1,498 @@
|
|||
/**
|
||||
* This is the default settings file provided by Node-RED.
|
||||
*
|
||||
* It can contain any valid JavaScript code that will get run when Node-RED
|
||||
* is started.
|
||||
*
|
||||
* Lines that start with // are commented out.
|
||||
* Each entry should be separated from the entries above and below by a comma ','
|
||||
*
|
||||
* For more information about individual settings, refer to the documentation:
|
||||
* https://nodered.org/docs/user-guide/runtime/configuration
|
||||
*
|
||||
* The settings are split into the following sections:
|
||||
* - Flow File and User Directory Settings
|
||||
* - Security
|
||||
* - Server Settings
|
||||
* - Runtime Settings
|
||||
* - Editor Settings
|
||||
* - Node Settings
|
||||
*
|
||||
**/
|
||||
|
||||
module.exports = {
|
||||
|
||||
/*******************************************************************************
|
||||
* Flow File and User Directory Settings
|
||||
* - flowFile
|
||||
* - credentialSecret
|
||||
* - flowFilePretty
|
||||
* - userDir
|
||||
* - nodesDir
|
||||
******************************************************************************/
|
||||
|
||||
/** The file containing the flows. If not set, defaults to flows_<hostname>.json **/
|
||||
flowFile: 'flows.json',
|
||||
|
||||
/** By default, credentials are encrypted in storage using a generated key. To
|
||||
* specify your own secret, set the following property.
|
||||
* If you want to disable encryption of credentials, set this property to false.
|
||||
* Note: once you set this property, do not change it - doing so will prevent
|
||||
* node-red from being able to decrypt your existing credentials and they will be
|
||||
* lost.
|
||||
*/
|
||||
//credentialSecret: "a-secret-key",
|
||||
credentialSecret: process.env.NODE_RED_CREDENTIAL_SECRET,
|
||||
|
||||
/** By default, the flow JSON will be formatted over multiple lines making
|
||||
* it easier to compare changes when using version control.
|
||||
* To disable pretty-printing of the JSON set the following property to false.
|
||||
*/
|
||||
flowFilePretty: true,
|
||||
|
||||
/** By default, all user data is stored in a directory called `.node-red` under
|
||||
* the user's home directory. To use a different location, the following
|
||||
* property can be used
|
||||
*/
|
||||
//userDir: '/home/nol/.node-red/',
|
||||
|
||||
/** Node-RED scans the `nodes` directory in the userDir to find local node files.
|
||||
* The following property can be used to specify an additional directory to scan.
|
||||
*/
|
||||
//nodesDir: '/home/nol/.node-red/nodes',
|
||||
|
||||
/*******************************************************************************
|
||||
* Security
|
||||
* - adminAuth
|
||||
* - https
|
||||
* - httpsRefreshInterval
|
||||
* - requireHttps
|
||||
* - httpNodeAuth
|
||||
* - httpStaticAuth
|
||||
******************************************************************************/
|
||||
|
||||
/** To password protect the Node-RED editor and admin API, the following
|
||||
* property can be used. See http://nodered.org/docs/security.html for details.
|
||||
*/
|
||||
//adminAuth: {
|
||||
// type: "credentials",
|
||||
// users: [{
|
||||
// username: "admin",
|
||||
// password: "$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN.",
|
||||
// permissions: "*"
|
||||
// }]
|
||||
//},
|
||||
|
||||
/** The following property can be used to enable HTTPS
|
||||
* This property can be either an object, containing both a (private) key
|
||||
* and a (public) certificate, or a function that returns such an object.
|
||||
* See http://nodejs.org/api/https.html#https_https_createserver_options_requestlistener
|
||||
* for details of its contents.
|
||||
*/
|
||||
|
||||
/** Option 1: static object */
|
||||
//https: {
|
||||
// key: require("fs").readFileSync('privkey.pem'),
|
||||
// cert: require("fs").readFileSync('cert.pem')
|
||||
//},
|
||||
|
||||
/** Option 2: function that returns the HTTP configuration object */
|
||||
// https: function() {
|
||||
// // This function should return the options object, or a Promise
|
||||
// // that resolves to the options object
|
||||
// return {
|
||||
// key: require("fs").readFileSync('privkey.pem'),
|
||||
// cert: require("fs").readFileSync('cert.pem')
|
||||
// }
|
||||
// },
|
||||
|
||||
/** If the `https` setting is a function, the following setting can be used
|
||||
* to set how often, in hours, the function will be called. That can be used
|
||||
* to refresh any certificates.
|
||||
*/
|
||||
//httpsRefreshInterval : 12,
|
||||
|
||||
/** The following property can be used to cause insecure HTTP connections to
|
||||
* be redirected to HTTPS.
|
||||
*/
|
||||
//requireHttps: true,
|
||||
|
||||
/** To password protect the node-defined HTTP endpoints (httpNodeRoot),
|
||||
* including node-red-dashboard, or the static content (httpStatic), the
|
||||
* following properties can be used.
|
||||
* The `pass` field is a bcrypt hash of the password.
|
||||
* See http://nodered.org/docs/security.html#generating-the-password-hash
|
||||
*/
|
||||
//httpNodeAuth: {user:"user",pass:"$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN."},
|
||||
//httpStaticAuth: {user:"user",pass:"$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN."},
|
||||
|
||||
/*******************************************************************************
|
||||
* Server Settings
|
||||
* - uiPort
|
||||
* - uiHost
|
||||
* - apiMaxLength
|
||||
* - httpServerOptions
|
||||
* - httpAdminRoot
|
||||
* - httpAdminMiddleware
|
||||
* - httpNodeRoot
|
||||
* - httpNodeCors
|
||||
* - httpNodeMiddleware
|
||||
* - httpStatic
|
||||
******************************************************************************/
|
||||
|
||||
/** the tcp port that the Node-RED web server is listening on */
|
||||
uiPort: process.env.PORT || 1880,
|
||||
|
||||
/** By default, the Node-RED UI accepts connections on all IPv4 interfaces.
|
||||
* To listen on all IPv6 addresses, set uiHost to "::",
|
||||
* The following property can be used to listen on a specific interface. For
|
||||
* example, the following would only allow connections from the local machine.
|
||||
*/
|
||||
//uiHost: "127.0.0.1",
|
||||
|
||||
/** The maximum size of HTTP request that will be accepted by the runtime api.
|
||||
* Default: 5mb
|
||||
*/
|
||||
//apiMaxLength: '5mb',
|
||||
|
||||
/** The following property can be used to pass custom options to the Express.js
|
||||
* server used by Node-RED. For a full list of available options, refer
|
||||
* to http://expressjs.com/en/api.html#app.settings.table
|
||||
*/
|
||||
//httpServerOptions: { },
|
||||
|
||||
/** By default, the Node-RED UI is available at http://localhost:1880/
|
||||
* The following property can be used to specify a different root path.
|
||||
* If set to false, this is disabled.
|
||||
*/
|
||||
//httpAdminRoot: '/admin',
|
||||
|
||||
/** The following property can be used to add a custom middleware function
|
||||
* in front of all admin http routes. For example, to set custom http
|
||||
* headers. It can be a single function or an array of middleware functions.
|
||||
*/
|
||||
// httpAdminMiddleware: function(req,res,next) {
|
||||
// // Set the X-Frame-Options header to limit where the editor
|
||||
// // can be embedded
|
||||
// //res.set('X-Frame-Options', 'sameorigin');
|
||||
// next();
|
||||
// },
|
||||
|
||||
|
||||
/** Some nodes, such as HTTP In, can be used to listen for incoming http requests.
|
||||
* By default, these are served relative to '/'. The following property
|
||||
* can be used to specifiy a different root path. If set to false, this is
|
||||
* disabled.
|
||||
*/
|
||||
//httpNodeRoot: '/red-nodes',
|
||||
|
||||
/** The following property can be used to configure cross-origin resource sharing
|
||||
* in the HTTP nodes.
|
||||
* See https://github.com/troygoode/node-cors#configuration-options for
|
||||
* details on its contents. The following is a basic permissive set of options:
|
||||
*/
|
||||
//httpNodeCors: {
|
||||
// origin: "*",
|
||||
// methods: "GET,PUT,POST,DELETE"
|
||||
//},
|
||||
|
||||
/** If you need to set an http proxy please set an environment variable
|
||||
* called http_proxy (or HTTP_PROXY) outside of Node-RED in the operating system.
|
||||
* For example - http_proxy=http://myproxy.com:8080
|
||||
* (Setting it here will have no effect)
|
||||
* You may also specify no_proxy (or NO_PROXY) to supply a comma separated
|
||||
* list of domains to not proxy, eg - no_proxy=.acme.co,.acme.co.uk
|
||||
*/
|
||||
|
||||
/** The following property can be used to add a custom middleware function
|
||||
* in front of all http in nodes. This allows custom authentication to be
|
||||
* applied to all http in nodes, or any other sort of common request processing.
|
||||
* It can be a single function or an array of middleware functions.
|
||||
*/
|
||||
//httpNodeMiddleware: function(req,res,next) {
|
||||
// // Handle/reject the request, or pass it on to the http in node by calling next();
|
||||
// // Optionally skip our rawBodyParser by setting this to true;
|
||||
// //req.skipRawBodyParser = true;
|
||||
// next();
|
||||
//},
|
||||
|
||||
/** When httpAdminRoot is used to move the UI to a different root path, the
|
||||
* following property can be used to identify a directory of static content
|
||||
* that should be served at http://localhost:1880/.
|
||||
*/
|
||||
//httpStatic: '/home/nol/node-red-static/',
|
||||
|
||||
/*******************************************************************************
|
||||
* Runtime Settings
|
||||
* - lang
|
||||
* - logging
|
||||
* - contextStorage
|
||||
* - exportGlobalContextKeys
|
||||
* - externalModules
|
||||
******************************************************************************/
|
||||
|
||||
/** Uncomment the following to run node-red in your preferred language.
|
||||
* Available languages include: en-US (default), ja, de, zh-CN, zh-TW, ru, ko
|
||||
* Some languages are more complete than others.
|
||||
*/
|
||||
// lang: "de",
|
||||
|
||||
/** Configure the logging output */
|
||||
logging: {
|
||||
/** Only console logging is currently supported */
|
||||
console: {
|
||||
/** Level of logging to be recorded. Options are:
|
||||
* fatal - only those errors which make the application unusable should be recorded
|
||||
* error - record errors which are deemed fatal for a particular request + fatal errors
|
||||
* warn - record problems which are non fatal + errors + fatal errors
|
||||
* info - record information about the general running of the application + warn + error + fatal errors
|
||||
* debug - record information which is more verbose than info + info + warn + error + fatal errors
|
||||
* trace - record very detailed logging + debug + info + warn + error + fatal errors
|
||||
* off - turn off all logging (doesn't affect metrics or audit)
|
||||
*/
|
||||
level: "info",
|
||||
/** Whether or not to include metric events in the log output */
|
||||
metrics: false,
|
||||
/** Whether or not to include audit events in the log output */
|
||||
audit: false
|
||||
}
|
||||
},
|
||||
|
||||
/** Context Storage
|
||||
* The following property can be used to enable context storage. The configuration
|
||||
* provided here will enable file-based context that flushes to disk every 30 seconds.
|
||||
* Refer to the documentation for further options: https://nodered.org/docs/api/context/
|
||||
*/
|
||||
//contextStorage: {
|
||||
// default: {
|
||||
// module:"localfilesystem"
|
||||
// },
|
||||
//},
|
||||
|
||||
/** `global.keys()` returns a list of all properties set in global context.
|
||||
* This allows them to be displayed in the Context Sidebar within the editor.
|
||||
* In some circumstances it is not desirable to expose them to the editor. The
|
||||
* following property can be used to hide any property set in `functionGlobalContext`
|
||||
* from being list by `global.keys()`.
|
||||
* By default, the property is set to false to avoid accidental exposure of
|
||||
* their values. Setting this to true will cause the keys to be listed.
|
||||
*/
|
||||
exportGlobalContextKeys: false,
|
||||
|
||||
/** Configure how the runtime will handle external npm modules.
|
||||
* This covers:
|
||||
* - whether the editor will allow new node modules to be installed
|
||||
* - whether nodes, such as the Function node are allowed to have their
|
||||
* own dynamically configured dependencies.
|
||||
* The allow/denyList options can be used to limit what modules the runtime
|
||||
* will install/load. It can use '*' as a wildcard that matches anything.
|
||||
*/
|
||||
externalModules: {
|
||||
// autoInstall: false, /** Whether the runtime will attempt to automatically install missing modules */
|
||||
// autoInstallRetry: 30, /** Interval, in seconds, between reinstall attempts */
|
||||
// palette: { /** Configuration for the Palette Manager */
|
||||
// allowInstall: true, /** Enable the Palette Manager in the editor */
|
||||
// allowUpdate: true, /** Allow modules to be updated in the Palette Manager */
|
||||
// allowUpload: true, /** Allow module tgz files to be uploaded and installed */
|
||||
// allowList: ['*'],
|
||||
// denyList: [],
|
||||
// allowUpdateList: ['*'],
|
||||
// denyUpdateList: []
|
||||
// },
|
||||
// modules: { /** Configuration for node-specified modules */
|
||||
// allowInstall: true,
|
||||
// allowList: [],
|
||||
// denyList: []
|
||||
// }
|
||||
},
|
||||
|
||||
|
||||
/*******************************************************************************
|
||||
* Editor Settings
|
||||
* - disableEditor
|
||||
* - editorTheme
|
||||
******************************************************************************/
|
||||
|
||||
/** The following property can be used to disable the editor. The admin API
|
||||
* is not affected by this option. To disable both the editor and the admin
|
||||
* API, use either the httpRoot or httpAdminRoot properties
|
||||
*/
|
||||
//disableEditor: false,
|
||||
|
||||
/** Customising the editor
|
||||
* See https://nodered.org/docs/user-guide/runtime/configuration#editor-themes
|
||||
* for all available options.
|
||||
*/
|
||||
editorTheme: {
|
||||
/** The following property can be used to set a custom theme for the editor.
|
||||
* See https://github.com/node-red-contrib-themes/theme-collection for
|
||||
* a collection of themes to chose from.
|
||||
*/
|
||||
//theme: "",
|
||||
|
||||
/** To disable the 'Welcome to Node-RED' tour that is displayed the first
|
||||
* time you access the editor for each release of Node-RED, set this to false
|
||||
*/
|
||||
//tours: false,
|
||||
|
||||
palette: {
|
||||
/** The following property can be used to order the categories in the editor
|
||||
* palette. If a node's category is not in the list, the category will get
|
||||
* added to the end of the palette.
|
||||
* If not set, the following default order is used:
|
||||
*/
|
||||
//categories: ['subflows', 'common', 'function', 'network', 'sequence', 'parser', 'storage'],
|
||||
},
|
||||
|
||||
projects: {
|
||||
/** To enable the Projects feature, set this value to true */
|
||||
enabled: false,
|
||||
workflow: {
|
||||
/** Set the default projects workflow mode.
|
||||
* - manual - you must manually commit changes
|
||||
* - auto - changes are automatically committed
|
||||
* This can be overridden per-user from the 'Git config'
|
||||
* section of 'User Settings' within the editor
|
||||
*/
|
||||
mode: "manual"
|
||||
}
|
||||
},
|
||||
|
||||
codeEditor: {
|
||||
/** Select the text editor component used by the editor.
|
||||
* Defaults to "ace", but can be set to "ace" or "monaco"
|
||||
*/
|
||||
lib: "ace",
|
||||
options: {
|
||||
/** The follow options only apply if the editor is set to "monaco"
|
||||
*
|
||||
* theme - must match the file name of a theme in
|
||||
* packages/node_modules/@node-red/editor-client/src/vendor/monaco/dist/theme
|
||||
* e.g. "tomorrow-night", "upstream-sunburst", "github", "my-theme"
|
||||
*/
|
||||
theme: "vs",
|
||||
/** other overrides can be set e.g. fontSize, fontFamily, fontLigatures etc.
|
||||
* for the full list, see https://microsoft.github.io/monaco-editor/api/interfaces/monaco.editor.istandaloneeditorconstructionoptions.html
|
||||
*/
|
||||
//fontSize: 14,
|
||||
//fontFamily: "Cascadia Code, Fira Code, Consolas, 'Courier New', monospace",
|
||||
//fontLigatures: true,
|
||||
}
|
||||
}
|
||||
},
|
||||
|
||||
/*******************************************************************************
|
||||
* Node Settings
|
||||
* - fileWorkingDirectory
|
||||
* - functionGlobalContext
|
||||
* - functionExternalModules
|
||||
* - nodeMessageBufferMaxLength
|
||||
* - ui (for use with Node-RED Dashboard)
|
||||
* - debugUseColors
|
||||
* - debugMaxLength
|
||||
* - execMaxBufferSize
|
||||
* - httpRequestTimeout
|
||||
* - mqttReconnectTime
|
||||
* - serialReconnectTime
|
||||
* - socketReconnectTime
|
||||
* - socketTimeout
|
||||
* - tcpMsgQueueSize
|
||||
* - inboundWebSocketTimeout
|
||||
* - tlsConfigDisableLocalFiles
|
||||
* - webSocketNodeVerifyClient
|
||||
******************************************************************************/
|
||||
|
||||
/** The working directory to handle relative file paths from within the File nodes
|
||||
* defaults to the working directory of the Node-RED process.
|
||||
*/
|
||||
//fileWorkingDirectory: "",
|
||||
|
||||
/** Allow the Function node to load additional npm modules directly */
|
||||
functionExternalModules: true,
|
||||
|
||||
/** The following property can be used to set predefined values in Global Context.
|
||||
* This allows extra node modules to be made available with in Function node.
|
||||
* For example, the following:
|
||||
* functionGlobalContext: { os:require('os') }
|
||||
* will allow the `os` module to be accessed in a Function node using:
|
||||
* global.get("os")
|
||||
*/
|
||||
functionGlobalContext: {
|
||||
// os:require('os'),
|
||||
},
|
||||
|
||||
/** The maximum number of messages nodes will buffer internally as part of their
|
||||
* operation. This applies across a range of nodes that operate on message sequences.
|
||||
* defaults to no limit. A value of 0 also means no limit is applied.
|
||||
*/
|
||||
//nodeMessageBufferMaxLength: 0,
|
||||
|
||||
/** If you installed the optional node-red-dashboard you can set it's path
|
||||
* relative to httpNodeRoot
|
||||
* Other optional properties include
|
||||
* readOnly:{boolean},
|
||||
* middleware:{function or array}, (req,res,next) - http middleware
|
||||
* ioMiddleware:{function or array}, (socket,next) - socket.io middleware
|
||||
*/
|
||||
//ui: { path: "ui" },
|
||||
|
||||
/** Colourise the console output of the debug node */
|
||||
//debugUseColors: true,
|
||||
|
||||
/** The maximum length, in characters, of any message sent to the debug sidebar tab */
|
||||
debugMaxLength: 1000,
|
||||
|
||||
/** Maximum buffer size for the exec node. Defaults to 10Mb */
|
||||
//execMaxBufferSize: 10000000,
|
||||
|
||||
/** Timeout in milliseconds for HTTP request connections. Defaults to 120s */
|
||||
//httpRequestTimeout: 120000,
|
||||
|
||||
/** Retry time in milliseconds for MQTT connections */
|
||||
mqttReconnectTime: 15000,
|
||||
|
||||
/** Retry time in milliseconds for Serial port connections */
|
||||
serialReconnectTime: 15000,
|
||||
|
||||
/** Retry time in milliseconds for TCP socket connections */
|
||||
//socketReconnectTime: 10000,
|
||||
|
||||
/** Timeout in milliseconds for TCP server socket connections. Defaults to no timeout */
|
||||
//socketTimeout: 120000,
|
||||
|
||||
/** Maximum number of messages to wait in queue while attempting to connect to TCP socket
|
||||
* defaults to 1000
|
||||
*/
|
||||
//tcpMsgQueueSize: 2000,
|
||||
|
||||
/** Timeout in milliseconds for inbound WebSocket connections that do not
|
||||
* match any configured node. Defaults to 5000
|
||||
*/
|
||||
//inboundWebSocketTimeout: 5000,
|
||||
|
||||
/** To disable the option for using local files for storing keys and
|
||||
* certificates in the TLS configuration node, set this to true.
|
||||
*/
|
||||
//tlsConfigDisableLocalFiles: true,
|
||||
|
||||
/** The following property can be used to verify websocket connection attempts.
|
||||
* This allows, for example, the HTTP request headers to be checked to ensure
|
||||
* they include valid authentication information.
|
||||
*/
|
||||
//webSocketNodeVerifyClient: function(info) {
|
||||
// /** 'info' has three properties:
|
||||
// * - origin : the value in the Origin header
|
||||
// * - req : the HTTP request
|
||||
// * - secure : true if req.connection.authorized or req.connection.encrypted is set
|
||||
// *
|
||||
// * The function should return true if the connection should be accepted, false otherwise.
|
||||
// *
|
||||
// * Alternatively, if this function is defined to accept a second argument, callback,
|
||||
// * it can be used to verify the client asynchronously.
|
||||
// * The callback takes three arguments:
|
||||
// * - result : boolean, whether to accept the connection or not
|
||||
// * - code : if result is false, the HTTP error status to return
|
||||
// * - reason: if result is false, the HTTP reason string to return
|
||||
// */
|
||||
//},
|
||||
}
|
||||
|
|
@ -0,0 +1,368 @@
|
|||
[
|
||||
{
|
||||
"id": "f6f2187d.f17ca8",
|
||||
"type": "tab",
|
||||
"label": "Flow 1",
|
||||
"disabled": false,
|
||||
"info": ""
|
||||
},
|
||||
{
|
||||
"id": "34d396e7c091c5fd",
|
||||
"type": "tab",
|
||||
"label": "six-pipelines",
|
||||
"disabled": false,
|
||||
"info": "",
|
||||
"env": []
|
||||
},
|
||||
{
|
||||
"id": "3cc11d24.ff01a2",
|
||||
"type": "comment",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "WARNING: please check you have started this container with a volume that is mounted to /data\\n otherwise any flow changes are lost when you redeploy or upgrade the container\\n (e.g. upgrade to a more recent node-red docker image).\\n If you are using named volumes you can ignore this warning.\\n Double click or see info side panel to learn how to start Node-RED in Docker to save your work",
|
||||
"info": "\nTo start docker with a bind mount volume (-v option), for example:\n\n```\ndocker run -it -p 1880:1880 -v /home/user/node_red_data:/data --name mynodered nodered/node-red\n```\n\nwhere `/home/user/node_red_data` is a directory on your host machine where you want to store your flows.\n\nIf you do not do this then you can experiment and redploy flows, but if you restart or upgrade the container the flows will be disconnected and lost. \n\nThey will still exist in a hidden data volume, which can be recovered using standard docker techniques, but that is much more complex than just starting with a named volume as described above.",
|
||||
"x": 350,
|
||||
"y": 80,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "c228c538ddfd97cc",
|
||||
"type": "inject",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"props": [
|
||||
{
|
||||
"p": "payload"
|
||||
},
|
||||
{
|
||||
"p": "topic",
|
||||
"vt": "str"
|
||||
}
|
||||
],
|
||||
"repeat": "",
|
||||
"crontab": "",
|
||||
"once": false,
|
||||
"onceDelay": 0.1,
|
||||
"topic": "",
|
||||
"payload": "",
|
||||
"payloadType": "date",
|
||||
"x": 300,
|
||||
"y": 440,
|
||||
"wires": [
|
||||
[
|
||||
"fae8437b33358ca0"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "fae8437b33358ca0",
|
||||
"type": "function",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"func": "// Create a Date object from the payload\nvar date = new Date(msg.payload);\n// Change the payload to be a formatted Date string\nmsg.payload = date.toString();\n// Return the message so it can be sent on\nreturn msg;",
|
||||
"outputs": 1,
|
||||
"noerr": 0,
|
||||
"initialize": "",
|
||||
"finalize": "",
|
||||
"libs": [],
|
||||
"x": 480,
|
||||
"y": 440,
|
||||
"wires": [
|
||||
[]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "7588c855ba3f1c81",
|
||||
"type": "pythonshell in",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "kfp python",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/kfp_example.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": false,
|
||||
"python3": true,
|
||||
"x": 670,
|
||||
"y": 440,
|
||||
"wires": [
|
||||
[
|
||||
"b126ea03f7d74573"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "b126ea03f7d74573",
|
||||
"type": "debug",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "payload",
|
||||
"targetType": "msg",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 870,
|
||||
"y": 440,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "692c86b087eed4a0",
|
||||
"type": "pythonshell in",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "install dependency",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/install.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": false,
|
||||
"python3": true,
|
||||
"x": 570,
|
||||
"y": 300,
|
||||
"wires": [
|
||||
[
|
||||
"0b5c3b39a424dc6a"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "0b5c3b39a424dc6a",
|
||||
"type": "debug",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": true,
|
||||
"complete": "payload",
|
||||
"targetType": "msg",
|
||||
"statusVal": "payload",
|
||||
"statusType": "auto",
|
||||
"x": 770,
|
||||
"y": 300,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "3b1a0675389769a1",
|
||||
"type": "comment",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "install python dependency",
|
||||
"info": "",
|
||||
"x": 590,
|
||||
"y": 240,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "04e11dfd70107dcf",
|
||||
"type": "comment",
|
||||
"z": "f6f2187d.f17ca8",
|
||||
"name": "read experiemnt data from kfp",
|
||||
"info": "",
|
||||
"x": 600,
|
||||
"y": 380,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "ba8b7060f34ca920",
|
||||
"type": "decisionTree",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/decisionTree.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": "",
|
||||
"python3": true,
|
||||
"x": 330,
|
||||
"y": 200,
|
||||
"wires": [
|
||||
[
|
||||
"4fe06d66df1b4abc"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "0d9bc06821e4baee",
|
||||
"type": "randomForest",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/randomForest.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": "",
|
||||
"python3": true,
|
||||
"x": 340,
|
||||
"y": 320,
|
||||
"wires": [
|
||||
[
|
||||
"f70f04576107ff77"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "4fe06d66df1b4abc",
|
||||
"type": "debug",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "false",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 570,
|
||||
"y": 200,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "25502edaaffdbc08",
|
||||
"type": "debug",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "false",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 570,
|
||||
"y": 260,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "qf33kqombln4sqaw",
|
||||
"type": "debug",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "false",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 570,
|
||||
"y": 140,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "4l169z017wd7wxyue",
|
||||
"type": "debug",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "false",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 570,
|
||||
"y": 80,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "2l170z017wd8wxyue",
|
||||
"type": "debug",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "false",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 570,
|
||||
"y": 20,
|
||||
"wires": []
|
||||
|
||||
},
|
||||
{
|
||||
"id": "f70f04576107ff77",
|
||||
"type": "debug",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"active": true,
|
||||
"tosidebar": true,
|
||||
"console": false,
|
||||
"tostatus": false,
|
||||
"complete": "false",
|
||||
"statusVal": "",
|
||||
"statusType": "auto",
|
||||
"x": 570,
|
||||
"y": 320,
|
||||
"wires": []
|
||||
},
|
||||
{
|
||||
"id": "7b45b43be009954d",
|
||||
"type": "logisticRegression",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/logisticRegression.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": "",
|
||||
"python3": true,
|
||||
"x": 310,
|
||||
"y": 260,
|
||||
"wires": [
|
||||
[
|
||||
"25502edaaffdbc08"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "0i3c0sd8y2rwgums",
|
||||
"type": "fl",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/fl.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": "",
|
||||
"python3": true,
|
||||
"x": 300,
|
||||
"y": 140,
|
||||
"wires": [
|
||||
[
|
||||
"qf33kqombln4sqaw"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "o16lwowjyp6ee0hrg",
|
||||
"type": "mnist",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/mnist.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": "",
|
||||
"python3": true,
|
||||
"x": 290,
|
||||
"y": 80,
|
||||
"wires": [
|
||||
[
|
||||
"4l169z017wd7wxyue"
|
||||
]
|
||||
]
|
||||
},
|
||||
{
|
||||
"id": "c172wowjyp6ed0hrg",
|
||||
"type": "LSTM",
|
||||
"z": "34d396e7c091c5fd",
|
||||
"name": "",
|
||||
"pyfile": "/data/1.connect-kubeflow/py/LSTM.py",
|
||||
"virtualenv": "",
|
||||
"continuous": true,
|
||||
"stdInData": "",
|
||||
"python3": true,
|
||||
"x": 280,
|
||||
"y": 20,
|
||||
"wires": [
|
||||
[
|
||||
"2l170z017wd8wxyue"
|
||||
]
|
||||
]
|
||||
}
|
||||
]
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
{
|
||||
"$": "debb1e3e4666ba98dd5189a6e20b7e40jk4="
|
||||
}
|
||||
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/LSTM.html
generated
vendored
Normal file
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/LSTM.html
generated
vendored
Normal file
|
|
@ -0,0 +1,149 @@
|
|||
f<!--
|
||||
Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
<script type="text/x-red" data-template-name="LSTM">
|
||||
<div class="form-tips"><p>Provide a python file with full path</p>
|
||||
|
||||
<div class="form-row">
|
||||
<label for="node-input-name"><i class="fa fa-tag"></i> Name </label>
|
||||
<input type="text" id="node-input-name">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-pyfile"><i class="fa fa-tag"></i> Py file </label>
|
||||
<input type="text" id="node-input-pyfile" value="/data/1.connect-kubeflow/py/LSTM.py" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-virtualenv"><i class="fa fa-tag"></i> Virtual Environment Path </label>
|
||||
<input type="text" id="node-input-virtualenv" placeholder="/home/user/venv">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Use Python 3?</label>
|
||||
<input type="checkbox" id="node-input-python3" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Continuous?</label>
|
||||
<input type="checkbox" id="node-input-continuous" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<input type="hidden" id="node-input-stdInData" value="false">
|
||||
</div>
|
||||
|
||||
<div class="form-tips">
|
||||
<p>
|
||||
<b>Continuous:</b> this means the script will continuously produce data (good for trigger once, run forever scripts). This option will always be checked if Stdin Input is checked.
|
||||
</p>
|
||||
<p>
|
||||
<b>Stdin Input:</b> when this is checked, input to the node will be fed to the stdin of the scripts. That is, one the very first input, the script will be launched and wait for data from its stdin.
|
||||
</p>
|
||||
</div>
|
||||
|
||||
</script>
|
||||
|
||||
<script type="text/x-red" data-help-name="LSTM">
|
||||
<p>This node interacts with a python process, it run a python script and treats input payload as the arguments of the script. Script output will be forwarded to the node output</p>
|
||||
|
||||
<p>
|
||||
Virtual environment can be used, please specify the path to it.
|
||||
</p>
|
||||
|
||||
<p>
|
||||
<b>
|
||||
Note:
|
||||
</b>
|
||||
If <b>Continuous</b> mode is checked, clicking on the trigger of the node itself will terminate the script. Also, when the script is producing data, any new input will be ignored
|
||||
</p>
|
||||
</script>
|
||||
|
||||
<style type="text/css">
|
||||
.node_label_white {
|
||||
fill: white;
|
||||
}
|
||||
|
||||
.node_label_white_italic {
|
||||
fill: white;
|
||||
font-style: italic;
|
||||
}
|
||||
#palette_node_pythonshell_in > div.palette_label {
|
||||
color: white;
|
||||
}
|
||||
</style>
|
||||
|
||||
<script type="text/javascript">
|
||||
|
||||
RED.nodes.registerType('LSTM',{
|
||||
category: 'input',
|
||||
defaults: {
|
||||
name: {required: false},
|
||||
pyfile: {value: "/data/1.connect-kubeflow/py/LSTM.py"},
|
||||
virtualenv: {required: false},
|
||||
continuous: {required: false},
|
||||
stdInData: {required: false},
|
||||
python3: {required: false}
|
||||
},
|
||||
color:"#1c4e63",
|
||||
inputs: 1,
|
||||
outputs:1,
|
||||
icon: "bridge.png",
|
||||
align: "left",
|
||||
label: function() {
|
||||
return this.name || "LSTM";
|
||||
},
|
||||
labelStyle: function() {
|
||||
return this.name ? "node_label_white_italic" : "node_label_white";
|
||||
},
|
||||
oneditprepare: function() {
|
||||
$("#node-input-stdInData").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-python3").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-python3').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-continuous").change(function(e) {
|
||||
if(!e.target.checked && $('#node-input-stdInData').is(':checked')) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
},
|
||||
oneditsave: function(){
|
||||
if ($('#node-input-continuous').is(':checked') && !$('#node-input-stdInData').is(':checked')){
|
||||
this.inputs = 0;
|
||||
}
|
||||
},
|
||||
button: {
|
||||
onclick: function() {
|
||||
var node = this;
|
||||
$.ajax({
|
||||
url: "pythonshell/"+this.id,
|
||||
type:"POST",
|
||||
success: function(resp) {
|
||||
RED.notify(node._("success"),"success");
|
||||
},
|
||||
error: function(jqXHR,textStatus,errorThrown) {
|
||||
if (jqXHR.status == 404) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.not-deployed")}),"error");
|
||||
} else if (jqXHR.status == 500) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("pythonshell.errors.failed")}),"error");
|
||||
} else if (jqXHR.status == 0) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.no-response")}),"error");
|
||||
} else {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.unexpected",{status:jqXHR.status,message:textStatus})}),"error");
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
}
|
||||
});
|
||||
</script>
|
||||
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/LSTM.js
generated
vendored
Normal file
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/LSTM.js
generated
vendored
Normal file
|
|
@ -0,0 +1,66 @@
|
|||
/**
|
||||
* Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
**/
|
||||
|
||||
var util = require("util");
|
||||
var httpclient;
|
||||
var PythonshellNode = require('./LSTM0');
|
||||
|
||||
module.exports = function(RED) {
|
||||
"use strict";
|
||||
|
||||
function PythonshellInNode(n) {
|
||||
RED.nodes.createNode(this,n);
|
||||
|
||||
var node = this;
|
||||
node.config = n; // copy config to the backend so that down bellow we can have a reference
|
||||
|
||||
var pyNode = new PythonshellNode(n);
|
||||
|
||||
pyNode.setStatusCallback(node.status.bind(node))
|
||||
|
||||
node.on("input",function(msg) {
|
||||
pyNode.onInput(msg, function(result){
|
||||
node.send(result);
|
||||
}, function(err){
|
||||
node.error(err);
|
||||
});
|
||||
});
|
||||
|
||||
node.on('close', ()=>pyNode.onClose());
|
||||
}
|
||||
|
||||
RED.nodes.registerType("LSTM", PythonshellInNode);
|
||||
|
||||
RED.httpAdmin.post("/pythonshell/:id", RED.auth.needsPermission("pythonshell.query"), function(req,res) {
|
||||
var node = RED.nodes.getNode(req.params.id);
|
||||
if (node != null) {
|
||||
try {
|
||||
if (node.config.continuous){// see above comment
|
||||
node.receive({payload: 'pythonshell@close'})
|
||||
} else {
|
||||
node.receive();
|
||||
}
|
||||
res.sendStatus(200);
|
||||
} catch(err) {
|
||||
res.sendStatus(500);
|
||||
node.error(RED._("pythonshell.failed",{error:err.toString()}));
|
||||
}
|
||||
} else {
|
||||
res.sendStatus(404);
|
||||
}
|
||||
});
|
||||
|
||||
}
|
||||
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/LSTM0.js
generated
vendored
Normal file
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/LSTM0.js
generated
vendored
Normal file
|
|
@ -0,0 +1,147 @@
|
|||
var fs = require("fs");
|
||||
|
||||
function PythonshellInNode(config) {
|
||||
if (!config.pyfile){
|
||||
throw 'pyfile not present';
|
||||
}
|
||||
this.pythonExec = config.python3 ? "python3" : "python";
|
||||
this.pyfile = '/data/1.connect-kubeflow/py/LSTM.py';
|
||||
this.virtualenv = config.virtualenv;
|
||||
|
||||
if (!fs.existsSync(this.pyfile)) {
|
||||
throw 'pyfile not exist';
|
||||
}
|
||||
|
||||
if (this.virtualenv && !fs.existsSync(this.virtualenv)){
|
||||
throw 'configured virtualenv not exist, consider remove or change';
|
||||
}
|
||||
|
||||
this.stdInData = config.stdInData;
|
||||
this.continuous = this.stdInData ? true : config.continuous;
|
||||
this.pydir = this.pyfile.substring(0, this.pyfile.lastIndexOf('/'));
|
||||
this.pyfile = this.pyfile.substring(this.pyfile.lastIndexOf('/') + 1, this.pyfile.length);
|
||||
this.spawn = require('child_process').spawn;
|
||||
this.onStatus = ()=>{}
|
||||
}
|
||||
|
||||
PythonshellInNode.prototype.onInput = function(msg, out, err) {
|
||||
payload = msg.payload || '';
|
||||
if (typeof payload === 'object'){
|
||||
payload = JSON.stringify(payload);
|
||||
} else if (typeof payload !== 'string'){
|
||||
payload = payload.toString();
|
||||
}
|
||||
|
||||
if (payload === 'pythonshell@close'){
|
||||
if (this.py != null){
|
||||
this.onClose()
|
||||
return
|
||||
} else {
|
||||
// trigger new execution
|
||||
payload = ''
|
||||
}
|
||||
}
|
||||
|
||||
if (this.continuous && !this.stdInData && this.py != null){
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Not accepting input"})
|
||||
return
|
||||
}
|
||||
|
||||
var spawnCmd = (this.virtualenv ? this.virtualenv + '/bin/' : '') + this.pythonExec
|
||||
|
||||
if (this.stdInData){
|
||||
if (!this.py){
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile], {
|
||||
cwd: this.pydir,
|
||||
detached: true
|
||||
});
|
||||
this.firstExecution = true
|
||||
} else {
|
||||
this.firstExecution = false
|
||||
}
|
||||
} else {
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile, payload], {
|
||||
cwd: this.pydir
|
||||
});
|
||||
}
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
|
||||
// subsequence message, no need to setup callbacks
|
||||
if (this.stdInData && !this.firstExecution){
|
||||
this.py.stdin.write(payload + '\n')
|
||||
return
|
||||
}
|
||||
|
||||
var py = this.py;
|
||||
var dataString = '';
|
||||
var errString = '';
|
||||
|
||||
py.stdout.on('data', data => {
|
||||
clearTimeout(this.standbyTimer)
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Processing data"})
|
||||
|
||||
let dataStr = data.toString();
|
||||
|
||||
dataString += dataStr;
|
||||
|
||||
if (dataString.endsWith("\n")){
|
||||
if (this.continuous){
|
||||
msg.payload = dataString;
|
||||
out(msg);
|
||||
dataString = ''
|
||||
}
|
||||
}
|
||||
|
||||
this.standbyTimer = setTimeout(()=>{
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
}, 2000)
|
||||
|
||||
});
|
||||
|
||||
py.stderr.on('data', data => {
|
||||
errString += String(data);// just a different way to do it
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Error: " + errString})
|
||||
});
|
||||
|
||||
py.stderr.on('error', console.log)
|
||||
py.stdout.on('error', console.log)
|
||||
py.stdin.on('error', console.log)
|
||||
py.on('error', console.log)
|
||||
|
||||
py.on('close', code =>{
|
||||
if (code){
|
||||
err('exit code: ' + code + ', ' + errString);
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Exited: " + code})
|
||||
} else if (!this.continuous){
|
||||
msg.payload = dataString.trim();
|
||||
out(msg);
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Done"})
|
||||
} else {
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Script Closed"})
|
||||
}
|
||||
this.py = null
|
||||
setTimeout(()=>{
|
||||
this.onStatus({})
|
||||
}, 2000)
|
||||
});
|
||||
|
||||
if (this.stdInData){
|
||||
py.stdin.write(payload + '\n')
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.onClose = function() {
|
||||
if (this.py){
|
||||
this.py.kill()
|
||||
this.py = null
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.setStatusCallback = function(callback) {
|
||||
this.onStatus = callback
|
||||
};
|
||||
|
||||
|
||||
module.exports = PythonshellInNode
|
||||
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/decisionTree0.js
generated
vendored
Normal file
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/decisionTree0.js
generated
vendored
Normal file
|
|
@ -0,0 +1,147 @@
|
|||
var fs = require("fs");
|
||||
|
||||
function PythonshellInNode(config) {
|
||||
if (!config.pyfile){
|
||||
throw 'pyfile not present';
|
||||
}
|
||||
this.pythonExec = config.python3 ? "python3" : "python";
|
||||
this.pyfile = "/data/1.connect-kubeflow/py/decisionTree.py";
|
||||
this.virtualenv = config.virtualenv;
|
||||
|
||||
if (!fs.existsSync(this.pyfile)) {
|
||||
throw 'pyfile not exist';
|
||||
}
|
||||
|
||||
if (this.virtualenv && !fs.existsSync(this.virtualenv)){
|
||||
throw 'configured virtualenv not exist, consider remove or change';
|
||||
}
|
||||
|
||||
this.stdInData = config.stdInData;
|
||||
this.continuous = this.stdInData ? true : config.continuous;
|
||||
this.pydir = this.pyfile.substring(0, this.pyfile.lastIndexOf('/'));
|
||||
this.pyfile = this.pyfile.substring(this.pyfile.lastIndexOf('/') + 1, this.pyfile.length);
|
||||
this.spawn = require('child_process').spawn;
|
||||
this.onStatus = ()=>{}
|
||||
}
|
||||
|
||||
PythonshellInNode.prototype.onInput = function(msg, out, err) {
|
||||
payload = msg.payload || '';
|
||||
if (typeof payload === 'object'){
|
||||
payload = JSON.stringify(payload);
|
||||
} else if (typeof payload !== 'string'){
|
||||
payload = payload.toString();
|
||||
}
|
||||
|
||||
if (payload === 'pythonshell@close'){
|
||||
if (this.py != null){
|
||||
this.onClose()
|
||||
return
|
||||
} else {
|
||||
// trigger new execution
|
||||
payload = ''
|
||||
}
|
||||
}
|
||||
|
||||
if (this.continuous && !this.stdInData && this.py != null){
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Not accepting input"})
|
||||
return
|
||||
}
|
||||
|
||||
var spawnCmd = (this.virtualenv ? this.virtualenv + '/bin/' : '') + this.pythonExec
|
||||
|
||||
if (this.stdInData){
|
||||
if (!this.py){
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile], {
|
||||
cwd: this.pydir,
|
||||
detached: true
|
||||
});
|
||||
this.firstExecution = true
|
||||
} else {
|
||||
this.firstExecution = false
|
||||
}
|
||||
} else {
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile, payload], {
|
||||
cwd: this.pydir
|
||||
});
|
||||
}
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
|
||||
// subsequence message, no need to setup callbacks
|
||||
if (this.stdInData && !this.firstExecution){
|
||||
this.py.stdin.write(payload + '\n')
|
||||
return
|
||||
}
|
||||
|
||||
var py = this.py;
|
||||
var dataString = '';
|
||||
var errString = '';
|
||||
|
||||
py.stdout.on('data', data => {
|
||||
clearTimeout(this.standbyTimer)
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Processing data"})
|
||||
|
||||
let dataStr = data.toString();
|
||||
|
||||
dataString += dataStr;
|
||||
|
||||
if (dataString.endsWith("\n")){
|
||||
if (this.continuous){
|
||||
msg.payload = dataString;
|
||||
out(msg);
|
||||
dataString = ''
|
||||
}
|
||||
}
|
||||
|
||||
this.standbyTimer = setTimeout(()=>{
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
}, 2000)
|
||||
|
||||
});
|
||||
|
||||
py.stderr.on('data', data => {
|
||||
errString += String(data);// just a different way to do it
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Error: " + errString})
|
||||
});
|
||||
|
||||
py.stderr.on('error', console.log)
|
||||
py.stdout.on('error', console.log)
|
||||
py.stdin.on('error', console.log)
|
||||
py.on('error', console.log)
|
||||
|
||||
py.on('close', code =>{
|
||||
if (code){
|
||||
err('exit code: ' + code + ', ' + errString);
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Exited: " + code})
|
||||
} else if (!this.continuous){
|
||||
msg.payload = dataString.trim();
|
||||
out(msg);
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Done"})
|
||||
} else {
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Script Closed"})
|
||||
}
|
||||
this.py = null
|
||||
setTimeout(()=>{
|
||||
this.onStatus({})
|
||||
}, 2000)
|
||||
});
|
||||
|
||||
if (this.stdInData){
|
||||
py.stdin.write(payload + '\n')
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.onClose = function() {
|
||||
if (this.py){
|
||||
this.py.kill()
|
||||
this.py = null
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.setStatusCallback = function(callback) {
|
||||
this.onStatus = callback
|
||||
};
|
||||
|
||||
|
||||
module.exports = PythonshellInNode
|
||||
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/decisiontree.html
generated
vendored
Normal file
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/decisiontree.html
generated
vendored
Normal file
|
|
@ -0,0 +1,149 @@
|
|||
f<!--
|
||||
Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
<script type="text/x-red" data-template-name="decisionTree">
|
||||
<div class="form-tips"><p>Provide a python file with full path</p>
|
||||
|
||||
<div class="form-row">
|
||||
<label for="node-input-name"><i class="fa fa-tag"></i> Name </label>
|
||||
<input type="text" id="node-input-name" value="/data/1.connect-kubeflow/py/decisionTree.py" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-pyfile"><i class="fa fa-tag"></i> Py file </label>
|
||||
<input type="text" id="node-input-pyfile" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-virtualenv"><i class="fa fa-tag"></i> Virtual Environment Path </label>
|
||||
<input type="text" id="node-input-virtualenv" placeholder="/home/user/venv">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Use Python 3?</label>
|
||||
<input type="checkbox" id="node-input-python3" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Continuous?</label>
|
||||
<input type="checkbox" id="node-input-continuous" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<input type="hidden" id="node-input-stdInData" value="false">
|
||||
</div>
|
||||
|
||||
<div class="form-tips">
|
||||
<p>
|
||||
<b>Continuous:</b> this means the script will continuously produce data (good for trigger once, run forever scripts). This option will always be checked if Stdin Input is checked.
|
||||
</p>
|
||||
<p>
|
||||
<b>Stdin Input:</b> when this is checked, input to the node will be fed to the stdin of the scripts. That is, one the very first input, the script will be launched and wait for data from its stdin.
|
||||
</p>
|
||||
</div>
|
||||
|
||||
</script>
|
||||
|
||||
<script type="text/x-red" data-help-name="decisionTree">
|
||||
<p>This node interacts with a python process, it run a python script and treats input payload as the arguments of the script. Script output will be forwarded to the node output</p>
|
||||
|
||||
<p>
|
||||
Virtual environment can be used, please specify the path to it.
|
||||
</p>
|
||||
|
||||
<p>
|
||||
<b>
|
||||
Note:
|
||||
</b>
|
||||
If <b>Continuous</b> mode is checked, clicking on the trigger of the node itself will terminate the script. Also, when the script is producing data, any new input will be ignored
|
||||
</p>
|
||||
</script>
|
||||
|
||||
<style type="text/css">
|
||||
.node_label_white {
|
||||
fill: white;
|
||||
}
|
||||
|
||||
.node_label_white_italic {
|
||||
fill: white;
|
||||
font-style: italic;
|
||||
}
|
||||
#palette_node_pythonshell_in > div.palette_label {
|
||||
color: white;
|
||||
}
|
||||
</style>
|
||||
|
||||
<script type="text/javascript">
|
||||
|
||||
RED.nodes.registerType('decisionTree',{
|
||||
category: 'input',
|
||||
defaults: {
|
||||
name: {required: false},
|
||||
pyfile: {value:"/data/1.connect-kubeflow/py/decisionTree.py"},
|
||||
virtualenv: {required: false},
|
||||
continuous: {required: false},
|
||||
stdInData: {required: false},
|
||||
python3: {required: false}
|
||||
},
|
||||
color:"#1c4e63",
|
||||
inputs: 1,
|
||||
outputs:1,
|
||||
icon: "bridge.png",
|
||||
align: "left",
|
||||
label: function() {
|
||||
return this.name || "decisionTree";
|
||||
},
|
||||
labelStyle: function() {
|
||||
return this.name ? "node_label_white_italic" : "node_label_white";
|
||||
},
|
||||
oneditprepare: function() {
|
||||
$("#node-input-stdInData").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-python3").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-python3').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-continuous").change(function(e) {
|
||||
if(!e.target.checked && $('#node-input-stdInData').is(':checked')) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
},
|
||||
oneditsave: function(){
|
||||
if ($('#node-input-continuous').is(':checked') && !$('#node-input-stdInData').is(':checked')){
|
||||
this.inputs = 0;
|
||||
}
|
||||
},
|
||||
button: {
|
||||
onclick: function() {
|
||||
var node = this;
|
||||
$.ajax({
|
||||
url: "pythonshell/"+this.id,
|
||||
type:"POST",
|
||||
success: function(resp) {
|
||||
RED.notify(node._("success"),"success");
|
||||
},
|
||||
error: function(jqXHR,textStatus,errorThrown) {
|
||||
if (jqXHR.status == 404) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.not-deployed")}),"error");
|
||||
} else if (jqXHR.status == 500) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("pythonshell.errors.failed")}),"error");
|
||||
} else if (jqXHR.status == 0) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.no-response")}),"error");
|
||||
} else {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.unexpected",{status:jqXHR.status,message:textStatus})}),"error");
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
}
|
||||
});
|
||||
</script>
|
||||
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/decisiontree.js
generated
vendored
Normal file
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/decisiontree.js
generated
vendored
Normal file
|
|
@ -0,0 +1,66 @@
|
|||
/**
|
||||
* Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
**/
|
||||
|
||||
var util = require("util");
|
||||
var httpclient;
|
||||
var PythonshellNode = require('./decisionTree0');
|
||||
|
||||
module.exports = function(RED) {
|
||||
"use strict";
|
||||
|
||||
function PythonshellInNode(n) {
|
||||
RED.nodes.createNode(this,n);
|
||||
|
||||
var node = this;
|
||||
node.config = n; // copy config to the backend so that down bellow we can have a reference
|
||||
|
||||
var pyNode = new PythonshellNode(n);
|
||||
|
||||
pyNode.setStatusCallback(node.status.bind(node))
|
||||
|
||||
node.on("input",function(msg) {
|
||||
pyNode.onInput(msg, function(result){
|
||||
node.send(result);
|
||||
}, function(err){
|
||||
node.error(err);
|
||||
});
|
||||
});
|
||||
|
||||
node.on('close', ()=>pyNode.onClose());
|
||||
}
|
||||
|
||||
RED.nodes.registerType("decisionTree", PythonshellInNode);
|
||||
|
||||
RED.httpAdmin.post("/pythonshell/:id", RED.auth.needsPermission("pythonshell.query"), function(req,res) {
|
||||
var node = RED.nodes.getNode(req.params.id);
|
||||
if (node != null) {
|
||||
try {
|
||||
if (node.config.continuous){// see above comment
|
||||
node.receive({payload: 'pythonshell@close'})
|
||||
} else {
|
||||
node.receive();
|
||||
}
|
||||
res.sendStatus(200);
|
||||
} catch(err) {
|
||||
res.sendStatus(500);
|
||||
node.error(RED._("pythonshell.failed",{error:err.toString()}));
|
||||
}
|
||||
} else {
|
||||
res.sendStatus(404);
|
||||
}
|
||||
});
|
||||
|
||||
}
|
||||
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/fl.html
generated
vendored
Normal file
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/fl.html
generated
vendored
Normal file
|
|
@ -0,0 +1,149 @@
|
|||
f<!--
|
||||
Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
<script type="text/x-red" data-template-name="fl">
|
||||
<div class="form-tips"><p>Provide a python file with full path</p>
|
||||
|
||||
<div class="form-row">
|
||||
<label for="node-input-name"><i class="fa fa-tag"></i> Name </label>
|
||||
<input type="text" id="node-input-name" value="/data/1.connect-kubeflow/py/fl.py" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-pyfile"><i class="fa fa-tag"></i> Py file </label>
|
||||
<input type="text" id="node-input-pyfile" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-virtualenv"><i class="fa fa-tag"></i> Virtual Environment Path </label>
|
||||
<input type="text" id="node-input-virtualenv" placeholder="/home/user/venv">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Use Python 3?</label>
|
||||
<input type="checkbox" id="node-input-python3" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Continuous?</label>
|
||||
<input type="checkbox" id="node-input-continuous" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<input type="hidden" id="node-input-stdInData" value="false">
|
||||
</div>
|
||||
|
||||
<div class="form-tips">
|
||||
<p>
|
||||
<b>Continuous:</b> this means the script will continuously produce data (good for trigger once, run forever scripts). This option will always be checked if Stdin Input is checked.
|
||||
</p>
|
||||
<p>
|
||||
<b>Stdin Input:</b> when this is checked, input to the node will be fed to the stdin of the scripts. That is, one the very first input, the script will be launched and wait for data from its stdin.
|
||||
</p>
|
||||
</div>
|
||||
|
||||
</script>
|
||||
|
||||
<script type="text/x-red" data-help-name="fl">
|
||||
<p>This node interacts with a python process, it run a python script and treats input payload as the arguments of the script. Script output will be forwarded to the node output</p>
|
||||
|
||||
<p>
|
||||
Virtual environment can be used, please specify the path to it.
|
||||
</p>
|
||||
|
||||
<p>
|
||||
<b>
|
||||
Note:
|
||||
</b>
|
||||
If <b>Continuous</b> mode is checked, clicking on the trigger of the node itself will terminate the script. Also, when the script is producing data, any new input will be ignored
|
||||
</p>
|
||||
</script>
|
||||
|
||||
<style type="text/css">
|
||||
.node_label_white {
|
||||
fill: white;
|
||||
}
|
||||
|
||||
.node_label_white_italic {
|
||||
fill: white;
|
||||
font-style: italic;
|
||||
}
|
||||
#palette_node_pythonshell_in > div.palette_label {
|
||||
color: white;
|
||||
}
|
||||
</style>
|
||||
|
||||
<script type="text/javascript">
|
||||
|
||||
RED.nodes.registerType('fl',{
|
||||
category: 'input',
|
||||
defaults: {
|
||||
name: {required: false},
|
||||
pyfile: {value:"/data/1.connect-kubeflow/py/fl.py"},
|
||||
virtualenv: {required: false},
|
||||
continuous: {required: false},
|
||||
stdInData: {required: false},
|
||||
python3: {required: false}
|
||||
},
|
||||
color:"#1c4e63",
|
||||
inputs: 1,
|
||||
outputs:1,
|
||||
icon: "bridge.png",
|
||||
align: "left",
|
||||
label: function() {
|
||||
return this.name || "fl";
|
||||
},
|
||||
labelStyle: function() {
|
||||
return this.name ? "node_label_white_italic" : "node_label_white";
|
||||
},
|
||||
oneditprepare: function() {
|
||||
$("#node-input-stdInData").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-python3").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-python3').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-continuous").change(function(e) {
|
||||
if(!e.target.checked && $('#node-input-stdInData').is(':checked')) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
},
|
||||
oneditsave: function(){
|
||||
if ($('#node-input-continuous').is(':checked') && !$('#node-input-stdInData').is(':checked')){
|
||||
this.inputs = 0;
|
||||
}
|
||||
},
|
||||
button: {
|
||||
onclick: function() {
|
||||
var node = this;
|
||||
$.ajax({
|
||||
url: "pythonshell/"+this.id,
|
||||
type:"POST",
|
||||
success: function(resp) {
|
||||
RED.notify(node._("success"),"success");
|
||||
},
|
||||
error: function(jqXHR,textStatus,errorThrown) {
|
||||
if (jqXHR.status == 404) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.not-deployed")}),"error");
|
||||
} else if (jqXHR.status == 500) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("pythonshell.errors.failed")}),"error");
|
||||
} else if (jqXHR.status == 0) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.no-response")}),"error");
|
||||
} else {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.unexpected",{status:jqXHR.status,message:textStatus})}),"error");
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
}
|
||||
});
|
||||
</script>
|
||||
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/fl.js
generated
vendored
Normal file
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/fl.js
generated
vendored
Normal file
|
|
@ -0,0 +1,66 @@
|
|||
/**
|
||||
* Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
**/
|
||||
|
||||
var util = require("util");
|
||||
var httpclient;
|
||||
var PythonshellNode = require('./fl0');
|
||||
|
||||
module.exports = function(RED) {
|
||||
"use strict";
|
||||
|
||||
function PythonshellInNode(n) {
|
||||
RED.nodes.createNode(this,n);
|
||||
|
||||
var node = this;
|
||||
node.config = n; // copy config to the backend so that down bellow we can have a reference
|
||||
|
||||
var pyNode = new PythonshellNode(n);
|
||||
|
||||
pyNode.setStatusCallback(node.status.bind(node))
|
||||
|
||||
node.on("input",function(msg) {
|
||||
pyNode.onInput(msg, function(result){
|
||||
node.send(result);
|
||||
}, function(err){
|
||||
node.error(err);
|
||||
});
|
||||
});
|
||||
|
||||
node.on('close', ()=>pyNode.onClose());
|
||||
}
|
||||
|
||||
RED.nodes.registerType("fl", PythonshellInNode);
|
||||
|
||||
RED.httpAdmin.post("/pythonshell/:id", RED.auth.needsPermission("pythonshell.query"), function(req,res) {
|
||||
var node = RED.nodes.getNode(req.params.id);
|
||||
if (node != null) {
|
||||
try {
|
||||
if (node.config.continuous){// see above comment
|
||||
node.receive({payload: 'pythonshell@close'})
|
||||
} else {
|
||||
node.receive();
|
||||
}
|
||||
res.sendStatus(200);
|
||||
} catch(err) {
|
||||
res.sendStatus(500);
|
||||
node.error(RED._("pythonshell.failed",{error:err.toString()}));
|
||||
}
|
||||
} else {
|
||||
res.sendStatus(404);
|
||||
}
|
||||
});
|
||||
|
||||
}
|
||||
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/fl0.js
generated
vendored
Normal file
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/fl0.js
generated
vendored
Normal file
|
|
@ -0,0 +1,147 @@
|
|||
var fs = require("fs");
|
||||
|
||||
function PythonshellInNode(config) {
|
||||
if (!config.pyfile){
|
||||
throw 'pyfile not present';
|
||||
}
|
||||
this.pythonExec = config.python3 ? "python3" : "python";
|
||||
this.pyfile = "/data/1.connect-kubeflow/py/fl.py";
|
||||
this.virtualenv = config.virtualenv;
|
||||
|
||||
if (!fs.existsSync(this.pyfile)) {
|
||||
throw 'pyfile not exist';
|
||||
}
|
||||
|
||||
if (this.virtualenv && !fs.existsSync(this.virtualenv)){
|
||||
throw 'configured virtualenv not exist, consider remove or change';
|
||||
}
|
||||
|
||||
this.stdInData = config.stdInData;
|
||||
this.continuous = this.stdInData ? true : config.continuous;
|
||||
this.pydir = this.pyfile.substring(0, this.pyfile.lastIndexOf('/'));
|
||||
this.pyfile = this.pyfile.substring(this.pyfile.lastIndexOf('/') + 1, this.pyfile.length);
|
||||
this.spawn = require('child_process').spawn;
|
||||
this.onStatus = ()=>{}
|
||||
}
|
||||
|
||||
PythonshellInNode.prototype.onInput = function(msg, out, err) {
|
||||
payload = msg.payload || '';
|
||||
if (typeof payload === 'object'){
|
||||
payload = JSON.stringify(payload);
|
||||
} else if (typeof payload !== 'string'){
|
||||
payload = payload.toString();
|
||||
}
|
||||
|
||||
if (payload === 'pythonshell@close'){
|
||||
if (this.py != null){
|
||||
this.onClose()
|
||||
return
|
||||
} else {
|
||||
// trigger new execution
|
||||
payload = ''
|
||||
}
|
||||
}
|
||||
|
||||
if (this.continuous && !this.stdInData && this.py != null){
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Not accepting input"})
|
||||
return
|
||||
}
|
||||
|
||||
var spawnCmd = (this.virtualenv ? this.virtualenv + '/bin/' : '') + this.pythonExec
|
||||
|
||||
if (this.stdInData){
|
||||
if (!this.py){
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile], {
|
||||
cwd: this.pydir,
|
||||
detached: true
|
||||
});
|
||||
this.firstExecution = true
|
||||
} else {
|
||||
this.firstExecution = false
|
||||
}
|
||||
} else {
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile, payload], {
|
||||
cwd: this.pydir
|
||||
});
|
||||
}
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
|
||||
// subsequence message, no need to setup callbacks
|
||||
if (this.stdInData && !this.firstExecution){
|
||||
this.py.stdin.write(payload + '\n')
|
||||
return
|
||||
}
|
||||
|
||||
var py = this.py;
|
||||
var dataString = '';
|
||||
var errString = '';
|
||||
|
||||
py.stdout.on('data', data => {
|
||||
clearTimeout(this.standbyTimer)
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Processing data"})
|
||||
|
||||
let dataStr = data.toString();
|
||||
|
||||
dataString += dataStr;
|
||||
|
||||
if (dataString.endsWith("\n")){
|
||||
if (this.continuous){
|
||||
msg.payload = dataString;
|
||||
out(msg);
|
||||
dataString = ''
|
||||
}
|
||||
}
|
||||
|
||||
this.standbyTimer = setTimeout(()=>{
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
}, 2000)
|
||||
|
||||
});
|
||||
|
||||
py.stderr.on('data', data => {
|
||||
errString += String(data);// just a different way to do it
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Error: " + errString})
|
||||
});
|
||||
|
||||
py.stderr.on('error', console.log)
|
||||
py.stdout.on('error', console.log)
|
||||
py.stdin.on('error', console.log)
|
||||
py.on('error', console.log)
|
||||
|
||||
py.on('close', code =>{
|
||||
if (code){
|
||||
err('exit code: ' + code + ', ' + errString);
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Exited: " + code})
|
||||
} else if (!this.continuous){
|
||||
msg.payload = dataString.trim();
|
||||
out(msg);
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Done"})
|
||||
} else {
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Script Closed"})
|
||||
}
|
||||
this.py = null
|
||||
setTimeout(()=>{
|
||||
this.onStatus({})
|
||||
}, 2000)
|
||||
});
|
||||
|
||||
if (this.stdInData){
|
||||
py.stdin.write(payload + '\n')
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.onClose = function() {
|
||||
if (this.py){
|
||||
this.py.kill()
|
||||
this.py = null
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.setStatusCallback = function(callback) {
|
||||
this.onStatus = callback
|
||||
};
|
||||
|
||||
|
||||
module.exports = PythonshellInNode
|
||||
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/mnist.html
generated
vendored
Normal file
149
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/mnist.html
generated
vendored
Normal file
|
|
@ -0,0 +1,149 @@
|
|||
f<!--
|
||||
Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
<script type="text/x-red" data-template-name="mnist">
|
||||
<div class="form-tips"><p>Provide a python file with full path</p>
|
||||
|
||||
<div class="form-row">
|
||||
<label for="node-input-name"><i class="fa fa-tag"></i> Name </label>
|
||||
<input type="text" id="node-input-name" value="/data/1.connect-kubeflow/py/mnist.py" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-pyfile"><i class="fa fa-tag"></i> Py file </label>
|
||||
<input type="text" id="node-input-pyfile" readonly>
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label for="node-input-virtualenv"><i class="fa fa-tag"></i> Virtual Environment Path </label>
|
||||
<input type="text" id="node-input-virtualenv" placeholder="/home/user/venv">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Use Python 3?</label>
|
||||
<input type="checkbox" id="node-input-python3" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<label>Continuous?</label>
|
||||
<input type="checkbox" id="node-input-continuous" style="display: inline-block; width: auto; vertical-align: top;">
|
||||
</div>
|
||||
<div class="form-row">
|
||||
<input type="hidden" id="node-input-stdInData" value="false">
|
||||
</div>
|
||||
|
||||
<div class="form-tips">
|
||||
<p>
|
||||
<b>Continuous:</b> this means the script will continuously produce data (good for trigger once, run forever scripts). This option will always be checked if Stdin Input is checked.
|
||||
</p>
|
||||
<p>
|
||||
<b>Stdin Input:</b> when this is checked, input to the node will be fed to the stdin of the scripts. That is, one the very first input, the script will be launched and wait for data from its stdin.
|
||||
</p>
|
||||
</div>
|
||||
|
||||
</script>
|
||||
|
||||
<script type="text/x-red" data-help-name="mnist">
|
||||
<p>This node interacts with a python process, it run a python script and treats input payload as the arguments of the script. Script output will be forwarded to the node output</p>
|
||||
|
||||
<p>
|
||||
Virtual environment can be used, please specify the path to it.
|
||||
</p>
|
||||
|
||||
<p>
|
||||
<b>
|
||||
Note:
|
||||
</b>
|
||||
If <b>Continuous</b> mode is checked, clicking on the trigger of the node itself will terminate the script. Also, when the script is producing data, any new input will be ignored
|
||||
</p>
|
||||
</script>
|
||||
|
||||
<style type="text/css">
|
||||
.node_label_white {
|
||||
fill: white;
|
||||
}
|
||||
|
||||
.node_label_white_italic {
|
||||
fill: white;
|
||||
font-style: italic;
|
||||
}
|
||||
#palette_node_pythonshell_in > div.palette_label {
|
||||
color: white;
|
||||
}
|
||||
</style>
|
||||
|
||||
<script type="text/javascript">
|
||||
|
||||
RED.nodes.registerType('mnist',{
|
||||
category: 'input',
|
||||
defaults: {
|
||||
name: {required: false},
|
||||
pyfile: {value:"/data/1.connect-kubeflow/py/mnist.py"},
|
||||
virtualenv: {required: false},
|
||||
continuous: {required: false},
|
||||
stdInData: {required: false},
|
||||
python3: {required: false}
|
||||
},
|
||||
color:"#1c4e63",
|
||||
inputs: 1,
|
||||
outputs:1,
|
||||
icon: "bridge.png",
|
||||
align: "left",
|
||||
label: function() {
|
||||
return this.name || "mnist";
|
||||
},
|
||||
labelStyle: function() {
|
||||
return this.name ? "node_label_white_italic" : "node_label_white";
|
||||
},
|
||||
oneditprepare: function() {
|
||||
$("#node-input-stdInData").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-python3").change(function(e) {
|
||||
if(e.target.checked) {
|
||||
$('#node-input-python3').prop('checked', true);
|
||||
}
|
||||
});
|
||||
$("#node-input-continuous").change(function(e) {
|
||||
if(!e.target.checked && $('#node-input-stdInData').is(':checked')) {
|
||||
$('#node-input-continuous').prop('checked', true);
|
||||
}
|
||||
});
|
||||
},
|
||||
oneditsave: function(){
|
||||
if ($('#node-input-continuous').is(':checked') && !$('#node-input-stdInData').is(':checked')){
|
||||
this.inputs = 0;
|
||||
}
|
||||
},
|
||||
button: {
|
||||
onclick: function() {
|
||||
var node = this;
|
||||
$.ajax({
|
||||
url: "pythonshell/"+this.id,
|
||||
type:"POST",
|
||||
success: function(resp) {
|
||||
RED.notify(node._("success"),"success");
|
||||
},
|
||||
error: function(jqXHR,textStatus,errorThrown) {
|
||||
if (jqXHR.status == 404) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.not-deployed")}),"error");
|
||||
} else if (jqXHR.status == 500) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("pythonshell.errors.failed")}),"error");
|
||||
} else if (jqXHR.status == 0) {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.no-response")}),"error");
|
||||
} else {
|
||||
RED.notify(node._("common.notification.error",{message:node._("common.notification.errors.unexpected",{status:jqXHR.status,message:textStatus})}),"error");
|
||||
}
|
||||
}
|
||||
});
|
||||
}
|
||||
}
|
||||
});
|
||||
</script>
|
||||
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/mnist.js
generated
vendored
Normal file
66
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/mnist.js
generated
vendored
Normal file
|
|
@ -0,0 +1,66 @@
|
|||
/**
|
||||
* Copyright 2014 Sense Tecnic Systems, Inc.
|
||||
*
|
||||
* Licensed under the Apache License, Version 2.0 (the "License");
|
||||
* you may not use this file except in compliance with the License.
|
||||
* You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
**/
|
||||
|
||||
var util = require("util");
|
||||
var httpclient;
|
||||
var PythonshellNode = require('./mnist0');
|
||||
|
||||
module.exports = function(RED) {
|
||||
"use strict";
|
||||
|
||||
function PythonshellInNode(n) {
|
||||
RED.nodes.createNode(this,n);
|
||||
|
||||
var node = this;
|
||||
node.config = n; // copy config to the backend so that down bellow we can have a reference
|
||||
|
||||
var pyNode = new PythonshellNode(n);
|
||||
|
||||
pyNode.setStatusCallback(node.status.bind(node))
|
||||
|
||||
node.on("input",function(msg) {
|
||||
pyNode.onInput(msg, function(result){
|
||||
node.send(result);
|
||||
}, function(err){
|
||||
node.error(err);
|
||||
});
|
||||
});
|
||||
|
||||
node.on('close', ()=>pyNode.onClose());
|
||||
}
|
||||
|
||||
RED.nodes.registerType("mnist", PythonshellInNode);
|
||||
|
||||
RED.httpAdmin.post("/pythonshell/:id", RED.auth.needsPermission("pythonshell.query"), function(req,res) {
|
||||
var node = RED.nodes.getNode(req.params.id);
|
||||
if (node != null) {
|
||||
try {
|
||||
if (node.config.continuous){// see above comment
|
||||
node.receive({payload: 'pythonshell@close'})
|
||||
} else {
|
||||
node.receive();
|
||||
}
|
||||
res.sendStatus(200);
|
||||
} catch(err) {
|
||||
res.sendStatus(500);
|
||||
node.error(RED._("pythonshell.failed",{error:err.toString()}));
|
||||
}
|
||||
} else {
|
||||
res.sendStatus(404);
|
||||
}
|
||||
});
|
||||
|
||||
}
|
||||
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/mnist0.js
generated
vendored
Normal file
147
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/mnist0.js
generated
vendored
Normal file
|
|
@ -0,0 +1,147 @@
|
|||
var fs = require("fs");
|
||||
|
||||
function PythonshellInNode(config) {
|
||||
if (!config.pyfile){
|
||||
throw 'pyfile not present';
|
||||
}
|
||||
this.pythonExec = config.python3 ? "python3" : "python";
|
||||
this.pyfile = "/data/1.connect-kubeflow/py/mnist.py";
|
||||
this.virtualenv = config.virtualenv;
|
||||
|
||||
if (!fs.existsSync(this.pyfile)) {
|
||||
throw 'pyfile not exist';
|
||||
}
|
||||
|
||||
if (this.virtualenv && !fs.existsSync(this.virtualenv)){
|
||||
throw 'configured virtualenv not exist, consider remove or change';
|
||||
}
|
||||
|
||||
this.stdInData = config.stdInData;
|
||||
this.continuous = this.stdInData ? true : config.continuous;
|
||||
this.pydir = this.pyfile.substring(0, this.pyfile.lastIndexOf('/'));
|
||||
this.pyfile = this.pyfile.substring(this.pyfile.lastIndexOf('/') + 1, this.pyfile.length);
|
||||
this.spawn = require('child_process').spawn;
|
||||
this.onStatus = ()=>{}
|
||||
}
|
||||
|
||||
PythonshellInNode.prototype.onInput = function(msg, out, err) {
|
||||
payload = msg.payload || '';
|
||||
if (typeof payload === 'object'){
|
||||
payload = JSON.stringify(payload);
|
||||
} else if (typeof payload !== 'string'){
|
||||
payload = payload.toString();
|
||||
}
|
||||
|
||||
if (payload === 'pythonshell@close'){
|
||||
if (this.py != null){
|
||||
this.onClose()
|
||||
return
|
||||
} else {
|
||||
// trigger new execution
|
||||
payload = ''
|
||||
}
|
||||
}
|
||||
|
||||
if (this.continuous && !this.stdInData && this.py != null){
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Not accepting input"})
|
||||
return
|
||||
}
|
||||
|
||||
var spawnCmd = (this.virtualenv ? this.virtualenv + '/bin/' : '') + this.pythonExec
|
||||
|
||||
if (this.stdInData){
|
||||
if (!this.py){
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile], {
|
||||
cwd: this.pydir,
|
||||
detached: true
|
||||
});
|
||||
this.firstExecution = true
|
||||
} else {
|
||||
this.firstExecution = false
|
||||
}
|
||||
} else {
|
||||
this.py = this.spawn(spawnCmd, ['-u', this.pyfile, payload], {
|
||||
cwd: this.pydir
|
||||
});
|
||||
}
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
|
||||
// subsequence message, no need to setup callbacks
|
||||
if (this.stdInData && !this.firstExecution){
|
||||
this.py.stdin.write(payload + '\n')
|
||||
return
|
||||
}
|
||||
|
||||
var py = this.py;
|
||||
var dataString = '';
|
||||
var errString = '';
|
||||
|
||||
py.stdout.on('data', data => {
|
||||
clearTimeout(this.standbyTimer)
|
||||
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Processing data"})
|
||||
|
||||
let dataStr = data.toString();
|
||||
|
||||
dataString += dataStr;
|
||||
|
||||
if (dataString.endsWith("\n")){
|
||||
if (this.continuous){
|
||||
msg.payload = dataString;
|
||||
out(msg);
|
||||
dataString = ''
|
||||
}
|
||||
}
|
||||
|
||||
this.standbyTimer = setTimeout(()=>{
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Standby"})
|
||||
}, 2000)
|
||||
|
||||
});
|
||||
|
||||
py.stderr.on('data', data => {
|
||||
errString += String(data);// just a different way to do it
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Error: " + errString})
|
||||
});
|
||||
|
||||
py.stderr.on('error', console.log)
|
||||
py.stdout.on('error', console.log)
|
||||
py.stdin.on('error', console.log)
|
||||
py.on('error', console.log)
|
||||
|
||||
py.on('close', code =>{
|
||||
if (code){
|
||||
err('exit code: ' + code + ', ' + errString);
|
||||
this.onStatus({fill:"red",shape:"dot",text:"Exited: " + code})
|
||||
} else if (!this.continuous){
|
||||
msg.payload = dataString.trim();
|
||||
out(msg);
|
||||
this.onStatus({fill:"green",shape:"dot",text:"Done"})
|
||||
} else {
|
||||
this.onStatus({fill:"yellow",shape:"dot",text:"Script Closed"})
|
||||
}
|
||||
this.py = null
|
||||
setTimeout(()=>{
|
||||
this.onStatus({})
|
||||
}, 2000)
|
||||
});
|
||||
|
||||
if (this.stdInData){
|
||||
py.stdin.write(payload + '\n')
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.onClose = function() {
|
||||
if (this.py){
|
||||
this.py.kill()
|
||||
this.py = null
|
||||
}
|
||||
};
|
||||
|
||||
PythonshellInNode.prototype.setStatusCallback = function(callback) {
|
||||
this.onStatus = callback
|
||||
};
|
||||
|
||||
|
||||
module.exports = PythonshellInNode
|
||||
30
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/package.json
generated
vendored
Normal file
30
Tunghai-CS-project-main/kubeflow/examples/1.connect-kubeflow/node_modules/nodepipe/package.json
generated
vendored
Normal file
|
|
@ -0,0 +1,30 @@
|
|||
{
|
||||
"name": "node-red-contrib-pythonshell-custom",
|
||||
"version": "1.0.0",
|
||||
"description": "modified version of node-red-contrib-pythonshell with additional features",
|
||||
"scripts": {
|
||||
"test": "./node_modules/mocha/bin/mocha"
|
||||
},
|
||||
"keywords": [
|
||||
"distributed",
|
||||
"python",
|
||||
"node",
|
||||
"node-red"
|
||||
],
|
||||
"author": "WuChunYen",
|
||||
"license": "ISC",
|
||||
"dependencies": {},
|
||||
"node-red": {
|
||||
"nodes": {
|
||||
"decisionTree": "decisiontree.js",
|
||||
"randomForest": "randomforest.js",
|
||||
"logisticRegression": "logisticregression.js",
|
||||
"fl": "fl.js",
|
||||
"mnist": "mnist.js",
|
||||
"LSTM": "LSTM.js"
|
||||
}
|
||||
},
|
||||
"devDependencies": {
|
||||
"mocha": "^5.0.4"
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
{
|
||||
"name": "node-red-project",
|
||||
"description": "A Node-RED Project",
|
||||
"version": "0.0.1",
|
||||
"private": true
|
||||
}
|
||||
|
|
@ -0,0 +1,132 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import string
|
||||
import random
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = "https://ai4edu.thu01.footprint-ai.com"
|
||||
username = "thu02"
|
||||
password = "M*$3sNF7"
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
def random_suffix() -> string:
|
||||
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=10))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the Experiment API class
|
||||
experiment_api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
name="experiment-" + random_suffix()
|
||||
description="This is a experiment for LSTM."
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(
|
||||
type=kfp_server_api.models.ApiResourceType.NAMESPACE,
|
||||
id=resource_reference_key_id
|
||||
),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER
|
||||
)]
|
||||
body = kfp_server_api.ApiExperiment(name=name, description=description, resource_references=resource_references) # ApiExperiment | The experiment to be created.
|
||||
try:
|
||||
# Creates a new experiment.
|
||||
experiment_api_response = experiment_api_instance.create_experiment(body)
|
||||
experiment_id = experiment_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->create_experiment: %s\n" % e)
|
||||
|
||||
# Create an instance of the pipeline API class
|
||||
api_instance = kfp_server_api.PipelineUploadServiceApi(api_client)
|
||||
uploadfile='pipelines/LSTM_pipeline.yaml'
|
||||
name='pipeline-' + random_suffix()
|
||||
description="This is a LSTM pipline."
|
||||
try:
|
||||
pipeline_api_response = api_instance.upload_pipeline(uploadfile, name=name, description=description)
|
||||
pipeline_id = pipeline_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineUploadServiceApi->upload_pipeline: %s\n" % e)
|
||||
|
||||
# Create an instance of the run API class
|
||||
run_api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
display_name = 'LSTM' + random_suffix()
|
||||
description = "This is a LSTM run."
|
||||
pipeline_spec = kfp_server_api.ApiPipelineSpec(pipeline_id=pipeline_id)
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(id=experiment_id, type=kfp_server_api.models.ApiResourceType.EXPERIMENT),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER )]
|
||||
body = kfp_server_api.ApiRun(name=display_name, description=description, pipeline_spec=pipeline_spec, resource_references=resource_references) # ApiRun |
|
||||
try:
|
||||
# Creates a new run.
|
||||
run_api_response = run_api_instance.create_run(body)
|
||||
run_id = run_api_response.run.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->create_run: %s\n" % e)
|
||||
|
||||
Completed_flag = False
|
||||
polling_interval = 10 # Time in seconds between polls
|
||||
|
||||
while not Completed_flag:
|
||||
try:
|
||||
time.sleep(1)
|
||||
# Finds a specific run by ID.
|
||||
api_instance = run_api_instance.get_run(run_id)
|
||||
output = api_instance.pipeline_runtime.workflow_manifest
|
||||
output = json.loads(output)
|
||||
|
||||
try:
|
||||
nodes = output['status']['nodes']
|
||||
conditions = output['status']['conditions'] # Comfirm completion.
|
||||
|
||||
except KeyError:
|
||||
nodes = {}
|
||||
conditions = []
|
||||
|
||||
output_value = None
|
||||
Completed_flag = conditions[1]['status'] if len(conditions) > 1 else False
|
||||
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->get_run: %s\n" % e)
|
||||
break
|
||||
|
||||
if not Completed_flag:
|
||||
print("Pipeline is still running. Waiting...")
|
||||
time.sleep(polling_interval-1)
|
||||
|
||||
for node_id, node in nodes.items():
|
||||
if 'inputs' in node and 'parameters' in node['inputs']:
|
||||
for parameter in node['inputs']['parameters']:
|
||||
if parameter['name'] == 'random-forest-classifier-Accuracy': #change parameter
|
||||
output_value = parameter['value']
|
||||
|
||||
if output_value is not None:
|
||||
print(f"Random Forest Classifier Accuracy: {output_value}")
|
||||
else:
|
||||
print("Parameter not found.")
|
||||
print(nodes)
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
## How to use
|
||||
```
|
||||
KUBEFLOW_HOST=<your-kubeflow-instance-endpoint> \
|
||||
KUBEFLOW_USERNAME=<your-username-account> \
|
||||
KUBEFLOW_PASSWORD=<your-password> \
|
||||
python3 <file-index>
|
||||
```
|
||||
## three pipelines
|
||||
流程架構:
|
||||
create_experiment -> upload_pipeline -> create_run -> get_run -> filter -> result
|
||||
### decisionTree.py
|
||||
功能:以乳癌資料集訓練decisionTree模型並回傳準確率
|
||||
|
||||
### logisticRegression.py
|
||||
功能:以乳癌資料集訓練logisticRegression模型並回傳準確率
|
||||
|
||||
### randomForest.py
|
||||
功能:以乳癌資料集訓練randomForest模型並回傳準確率
|
||||
Binary file not shown.
Binary file not shown.
Binary file not shown.
Binary file not shown.
|
|
@ -0,0 +1,59 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import random
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import kfp
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
name="<change yours>" # str | The ID of the name to be create.
|
||||
description='<change yours>' # str | The description experiment.
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(
|
||||
type=kfp_server_api.models.ApiResourceType.NAMESPACE,
|
||||
id=resource_reference_key_id
|
||||
),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER
|
||||
)]
|
||||
body = kfp_server_api.ApiExperiment(name=name, description=description, resource_references=resource_references) # ApiExperiment | The experiment to be created.
|
||||
try:
|
||||
# Creates a new experiment.
|
||||
api_response = api_instance.create_experiment(body)
|
||||
pprint(api_response)
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->create_experiment: %s\n" % e)
|
||||
|
|
@ -0,0 +1,58 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import random
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import kfp
|
||||
import json
|
||||
from pprint import pprint
|
||||
from kfp_server_api.rest import ApiException
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
pipeline_id = '<change yours>' # str | The ID of the pipeline.
|
||||
experiment_id = '<change yours>' # str | The ID of the experiment.
|
||||
display_name = '<change yours>' # str | The name of the run to be create.
|
||||
description = '<change yours>' # str | The description of run.
|
||||
pipeline_spec = kfp_server_api.ApiPipelineSpec(pipeline_id=pipeline_id)
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(id=experiment_id, type=kfp_server_api.models.ApiResourceType.EXPERIMENT),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER )]
|
||||
body = kfp_server_api.ApiRun(name=display_name, description=description, pipeline_spec=pipeline_spec, resource_references=resource_references) # ApiRun |
|
||||
|
||||
try:
|
||||
# Creates a new run.
|
||||
api_response = api_instance.create_run(body)
|
||||
pprint(api_response)
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->create_run: %s\n" % e)
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import random
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import kfp
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
experiment_id = '<change yours>' # str | The ID of the experiment to be deleted.
|
||||
|
||||
try:
|
||||
# Deletes an experiment without deleting the experiment's runs and recurring runs.
|
||||
# To avoid unexpected behaviors, delete an experiment's runs and recurring runs before deleting the experiment.
|
||||
api_response = api_instance.delete_experiment(experiment_id)
|
||||
pprint(api_response)
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->delete_experiment: %s\n" % e)
|
||||
|
|
@ -0,0 +1,50 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import random
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import kfp
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.PipelineServiceApi(api_client)
|
||||
id = '<change yours>' # str | The ID of the pipeline to be deleted.
|
||||
|
||||
try:
|
||||
# Deletes a pipeline and its pipeline versions.
|
||||
api_response = api_instance.delete_pipeline(id)
|
||||
pprint(api_response)
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineServiceApi->delete_pipeline: %s\n" % e)
|
||||
|
|
@ -0,0 +1,50 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import random
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import kfp
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
id = '<change yours>' # str | The ID of the run to be deleted.
|
||||
|
||||
try:
|
||||
# Deletes a run.
|
||||
api_response = api_instance.delete_run(id)
|
||||
pprint(api_response)
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->delete_run: %s\n" % e)
|
||||
|
|
@ -0,0 +1,64 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
import json
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
run_id = '<change yours>' # str | The ID of the run to be retrieved.
|
||||
|
||||
try:
|
||||
# Finds a specific run by ID.
|
||||
api_response = api_instance.get_run(run_id)
|
||||
output = api_response.pipeline_runtime.workflow_manifest
|
||||
output = json.loads(output)
|
||||
nodes = output['status']['nodes']
|
||||
conditions = output['status']['conditions'] # Comfirm completion.
|
||||
output_value = None
|
||||
|
||||
for node_id, node in nodes.items():
|
||||
if 'inputs' in node and 'parameters' in node['inputs']:
|
||||
for parameter in node['inputs']['parameters']:
|
||||
if parameter['name'] == 'decision-tree-classifier-Accuracy':
|
||||
output_value = parameter['value']
|
||||
break
|
||||
|
||||
if output_value is not None:
|
||||
print(f"Decision Tree Classifier Accuracy: {output_value}")
|
||||
else:
|
||||
print("Parameter not found.")
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->get_run: %s\n" % e)
|
||||
|
|
@ -0,0 +1,93 @@
|
|||
import re
|
||||
from urllib.parse import urlsplit
|
||||
|
||||
import requests
|
||||
|
||||
# NOTE: the following code is referred from https://github.com/kubeflow/website/issues/2916
|
||||
def get_istio_auth_session(url: str, username: str, password: str) -> dict:
|
||||
"""
|
||||
Determine if the specified URL is secured by Dex and try to obtain a session cookie.
|
||||
WARNING: only Dex `staticPasswords` and `LDAP` authentication are currently supported
|
||||
(we default default to using `staticPasswords` if both are enabled)
|
||||
|
||||
:param url: Kubeflow server URL, including protocol
|
||||
:param username: Dex `staticPasswords` or `LDAP` username
|
||||
:param password: Dex `staticPasswords` or `LDAP` password
|
||||
:return: auth session information
|
||||
"""
|
||||
# define the default return object
|
||||
auth_session = {
|
||||
"endpoint_url": url, # KF endpoint URL
|
||||
"redirect_url": None, # KF redirect URL, if applicable
|
||||
"dex_login_url": None, # Dex login URL (for POST of credentials)
|
||||
"is_secured": None, # True if KF endpoint is secured
|
||||
"session_cookie": None # Resulting session cookies in the form "key1=value1; key2=value2"
|
||||
}
|
||||
|
||||
# use a persistent session (for cookies)
|
||||
with requests.Session() as s:
|
||||
|
||||
################
|
||||
# Determine if Endpoint is Secured
|
||||
################
|
||||
resp = s.get(url, allow_redirects=True)
|
||||
if resp.status_code != 200:
|
||||
raise RuntimeError(
|
||||
f"HTTP status code '{resp.status_code}' for GET against: {url}"
|
||||
)
|
||||
|
||||
auth_session["redirect_url"] = resp.url
|
||||
|
||||
# if we were NOT redirected, then the endpoint is UNSECURED
|
||||
if len(resp.history) == 0:
|
||||
auth_session["is_secured"] = False
|
||||
return auth_session
|
||||
else:
|
||||
auth_session["is_secured"] = True
|
||||
|
||||
################
|
||||
# Get Dex Login URL
|
||||
################
|
||||
redirect_url_obj = urlsplit(auth_session["redirect_url"])
|
||||
|
||||
# if we are at `/auth?=xxxx` path, we need to select an auth type
|
||||
if re.search(r"/auth$", redirect_url_obj.path):
|
||||
# default to "staticPasswords" auth type
|
||||
redirect_url_obj = redirect_url_obj._replace(
|
||||
path=re.sub(r"/auth$", "/auth/local", redirect_url_obj.path)
|
||||
)
|
||||
|
||||
# if we are at `/auth/xxxx/login` path, then no further action is needed (we can use it for login POST)
|
||||
if re.search(r"/auth/.*/login$", redirect_url_obj.path):
|
||||
auth_session["dex_login_url"] = redirect_url_obj.geturl()
|
||||
|
||||
# else, we need to be redirected to the actual login page
|
||||
else:
|
||||
# this GET should redirect us to the `/auth/xxxx/login` path
|
||||
resp = s.get(redirect_url_obj.geturl(), allow_redirects=True)
|
||||
if resp.status_code != 200:
|
||||
raise RuntimeError(
|
||||
f"HTTP status code '{resp.status_code}' for GET against: {redirect_url_obj.geturl()}"
|
||||
)
|
||||
|
||||
# set the login url
|
||||
auth_session["dex_login_url"] = resp.url
|
||||
|
||||
################
|
||||
# Attempt Dex Login
|
||||
################
|
||||
resp = s.post(
|
||||
auth_session["dex_login_url"],
|
||||
data={"login": username, "password": password},
|
||||
allow_redirects=True
|
||||
)
|
||||
if len(resp.history) == 0:
|
||||
raise RuntimeError(
|
||||
f"Login credentials were probably invalid - "
|
||||
f"No redirect after POST to: {auth_session['dex_login_url']}"
|
||||
)
|
||||
|
||||
# store the session cookies in a "key1=value1; key2=value2" string
|
||||
auth_session["session_cookie"] = "; ".join([f"{c.name}={c.value}" for c in s.cookies])
|
||||
|
||||
return auth_session
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
import os
|
||||
import requests
|
||||
|
||||
from typing import TypedDict
|
||||
|
||||
def retrieve_namespaces(host: str, auth_session: TypedDict) -> str:
|
||||
workgroup_endpoint = os.path.join(host, "api/workgroup/env-info")
|
||||
|
||||
cookies = {}
|
||||
cookie_tokens = auth_session["session_cookie"].split("=")
|
||||
print(cookie_tokens[0])
|
||||
cookies[cookie_tokens[0]]=cookie_tokens[1]
|
||||
resp = requests.get(workgroup_endpoint, cookies=cookies)
|
||||
if resp.status_code != 200:
|
||||
raise RuntimeError(
|
||||
f"HTTP status code '{resp.status_code}' for GET against: {workgroup_endpoint}"
|
||||
)
|
||||
return [ns["namespace"] for ns in resp.json()["namespaces"] if
|
||||
ns["role"]=="owner"]
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
resource_reference_key_type = "NAMESPACE"
|
||||
resource_reference_key_id = namespaces[0]
|
||||
list_experiment_response = api_instance.list_experiment(resource_reference_key_type=resource_reference_key_type, resource_reference_key_id=resource_reference_key_id)
|
||||
for experiment in list_experiment_response.experiments:
|
||||
pprint(experiment)
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import kfp
|
||||
import json
|
||||
from pprint import pprint
|
||||
from kfp_server_api.rest import ApiException
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
api_instance = kfp_server_api.PipelineServiceApi(api_client)
|
||||
list_pipeline_response = api_instance.list_pipelines()
|
||||
for pipelines in list_pipeline_response.pipelines:
|
||||
print(pipelines)
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
from __future__ import print_function
|
||||
import string
|
||||
import random
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
from kfp_server_api.rest import ApiException
|
||||
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
|
||||
host = os.getenv("KUBEFLOW_HOST")
|
||||
username = os.getenv("KUBEFLOW_USERNAME")
|
||||
password = os.getenv("KUBEFLOW_PASSWORD")
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
print("available namespace: {}".format(namespaces))
|
||||
|
||||
def random_suffix() -> string:
|
||||
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=10))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.PipelineUploadServiceApi(api_client)
|
||||
uploadfile='<change yours>' # The yaml file in your local path.
|
||||
name='pipeline-' + random_suffix()
|
||||
description='<change yours>' # str | The description of pipeline.
|
||||
try:
|
||||
api_response = api_instance.upload_pipeline(uploadfile, name=name, description=description)
|
||||
print(api_response)
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineUploadServiceApi->upload_pipeline: %s\n" % e)
|
||||
|
|
@ -0,0 +1,132 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import string
|
||||
import random
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = "http://ai4edu.thu01.footprint-ai.com"
|
||||
username = "thu02"
|
||||
password = "M*$3sNF7"
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
def random_suffix() -> string:
|
||||
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=10))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the Experiment API class
|
||||
experiment_api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
name="experiment-" + random_suffix()
|
||||
description="This is a experiment for only_decision_tree."
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(
|
||||
type=kfp_server_api.models.ApiResourceType.NAMESPACE,
|
||||
id=resource_reference_key_id
|
||||
),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER
|
||||
)]
|
||||
body = kfp_server_api.ApiExperiment(name=name, description=description, resource_references=resource_references) # ApiExperiment | The experiment to be created.
|
||||
try:
|
||||
# Creates a new experiment.
|
||||
experiment_api_response = experiment_api_instance.create_experiment(body)
|
||||
experiment_id = experiment_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->create_experiment: %s\n" % e)
|
||||
|
||||
# Create an instance of the pipeline API class
|
||||
api_instance = kfp_server_api.PipelineUploadServiceApi(api_client)
|
||||
uploadfile='pipelines/only_decision_tree.yaml'
|
||||
name='pipeline-' + random_suffix()
|
||||
description="This is a only_decision_tree pipline."
|
||||
try:
|
||||
pipeline_api_response = api_instance.upload_pipeline(uploadfile, name=name, description=description)
|
||||
pipeline_id = pipeline_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineUploadServiceApi->upload_pipeline: %s\n" % e)
|
||||
|
||||
# Create an instance of the run API class
|
||||
run_api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
display_name = 'run_only_decision_tree' + random_suffix()
|
||||
description = "This is a only_decision_tree run."
|
||||
pipeline_spec = kfp_server_api.ApiPipelineSpec(pipeline_id=pipeline_id)
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(id=experiment_id, type=kfp_server_api.models.ApiResourceType.EXPERIMENT),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER )]
|
||||
body = kfp_server_api.ApiRun(name=display_name, description=description, pipeline_spec=pipeline_spec, resource_references=resource_references) # ApiRun |
|
||||
try:
|
||||
# Creates a new run.
|
||||
run_api_response = run_api_instance.create_run(body)
|
||||
run_id = run_api_response.run.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->create_run: %s\n" % e)
|
||||
|
||||
Completed_flag = False
|
||||
polling_interval = 10 # Time in seconds between polls
|
||||
|
||||
while not Completed_flag:
|
||||
try:
|
||||
time.sleep(1)
|
||||
# Finds a specific run by ID.
|
||||
api_instance = run_api_instance.get_run(run_id)
|
||||
output = api_instance.pipeline_runtime.workflow_manifest
|
||||
output = json.loads(output)
|
||||
|
||||
try:
|
||||
nodes = output['status']['nodes']
|
||||
conditions = output['status']['conditions'] # Comfirm completion.
|
||||
|
||||
except KeyError:
|
||||
nodes = {}
|
||||
conditions = []
|
||||
|
||||
output_value = None
|
||||
Completed_flag = conditions[1]['status'] if len(conditions) > 1 else False
|
||||
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->get_run: %s\n" % e)
|
||||
break
|
||||
|
||||
if not Completed_flag:
|
||||
print("Pipeline is still running. Waiting...")
|
||||
time.sleep(polling_interval-1)
|
||||
|
||||
for node_id, node in nodes.items():
|
||||
if 'inputs' in node and 'parameters' in node['inputs']:
|
||||
for parameter in node['inputs']['parameters']:
|
||||
if parameter['name'] == 'decision-tree-classifier-Accuracy':
|
||||
output_value = parameter['value']
|
||||
|
||||
if output_value is not None:
|
||||
print(f"Decision Tree Classifier Accuracy: {output_value}")
|
||||
else:
|
||||
print("Parameter not found.")
|
||||
print(nodes)
|
||||
|
|
@ -0,0 +1,132 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import string
|
||||
import random
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = "https://ai4edu.thu01.footprint-ai.com"
|
||||
username = "thu02"
|
||||
password = "M*$3sNF7"
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
def random_suffix() -> string:
|
||||
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=10))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the Experiment API class
|
||||
experiment_api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
name="experiment-" + random_suffix()
|
||||
description="This is a experiment for fl."
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(
|
||||
type=kfp_server_api.models.ApiResourceType.NAMESPACE,
|
||||
id=resource_reference_key_id
|
||||
),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER
|
||||
)]
|
||||
body = kfp_server_api.ApiExperiment(name=name, description=description, resource_references=resource_references) # ApiExperiment | The experiment to be created.
|
||||
try:
|
||||
# Creates a new experiment.
|
||||
experiment_api_response = experiment_api_instance.create_experiment(body)
|
||||
experiment_id = experiment_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->create_experiment: %s\n" % e)
|
||||
|
||||
# Create an instance of the pipeline API class
|
||||
api_instance = kfp_server_api.PipelineUploadServiceApi(api_client)
|
||||
uploadfile='pipelines/fl_pipeline.yaml'
|
||||
name='pipeline-' + random_suffix()
|
||||
description="This is a fl pipline."
|
||||
try:
|
||||
pipeline_api_response = api_instance.upload_pipeline(uploadfile, name=name, description=description)
|
||||
pipeline_id = pipeline_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineUploadServiceApi->upload_pipeline: %s\n" % e)
|
||||
|
||||
# Create an instance of the run API class
|
||||
run_api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
display_name = 'fl' + random_suffix()
|
||||
description = "This is a fl run."
|
||||
pipeline_spec = kfp_server_api.ApiPipelineSpec(pipeline_id=pipeline_id)
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(id=experiment_id, type=kfp_server_api.models.ApiResourceType.EXPERIMENT),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER )]
|
||||
body = kfp_server_api.ApiRun(name=display_name, description=description, pipeline_spec=pipeline_spec, resource_references=resource_references) # ApiRun |
|
||||
try:
|
||||
# Creates a new run.
|
||||
run_api_response = run_api_instance.create_run(body)
|
||||
run_id = run_api_response.run.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->create_run: %s\n" % e)
|
||||
|
||||
Completed_flag = False
|
||||
polling_interval = 10 # Time in seconds between polls
|
||||
|
||||
while not Completed_flag:
|
||||
try:
|
||||
time.sleep(1)
|
||||
# Finds a specific run by ID.
|
||||
api_instance = run_api_instance.get_run(run_id)
|
||||
output = api_instance.pipeline_runtime.workflow_manifest
|
||||
output = json.loads(output)
|
||||
|
||||
try:
|
||||
nodes = output['status']['nodes']
|
||||
conditions = output['status']['conditions'] # Comfirm completion.
|
||||
|
||||
except KeyError:
|
||||
nodes = {}
|
||||
conditions = []
|
||||
|
||||
output_value = None
|
||||
Completed_flag = conditions[1]['status'] if len(conditions) > 1 else False
|
||||
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->get_run: %s\n" % e)
|
||||
break
|
||||
|
||||
if not Completed_flag:
|
||||
print("Pipeline is still running. Waiting...")
|
||||
time.sleep(polling_interval-1)
|
||||
|
||||
for node_id, node in nodes.items():
|
||||
if 'inputs' in node and 'parameters' in node['inputs']:
|
||||
for parameter in node['inputs']['parameters']:
|
||||
if parameter['name'] == 'client-last_accuracy':
|
||||
output_value = parameter['value']
|
||||
|
||||
if output_value is not None:
|
||||
print(f"fl Accuracy: {output_value}")
|
||||
else:
|
||||
print("Parameter not found.")
|
||||
print(nodes)
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
import sys
|
||||
|
||||
while True:
|
||||
line = sys.stdin.readline()
|
||||
print('this is send from python')
|
||||
print(line)
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
import os
|
||||
import subprocess
|
||||
|
||||
def python3_version():
|
||||
return subprocess.check_call(["python3", "--version"])
|
||||
|
||||
def which(command):
|
||||
return subprocess.check_call(["which", command])
|
||||
|
||||
def pip3_install_requirements():
|
||||
return subprocess.check_call(["pip3", "install", "-r", "requirements.txt",
|
||||
"--user"])
|
||||
|
||||
def pip3_install_kfp():
|
||||
return subprocess.check_call(["pip3", "install",
|
||||
"git+https://github.com/kubeflow/pipelines.git@1.8.19#subdirectory=backend/api/python_http_client",
|
||||
"--user"])
|
||||
|
||||
python3_version()
|
||||
pip3_install_requirements()
|
||||
pip3_install_kfp()
|
||||
|
||||
print("done")
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
from kfp_server_api.rest import ApiException
|
||||
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = "http://ai4edu.thu01.footprint-ai.com"
|
||||
username = "thu02"
|
||||
password = "M*$3sNF7"
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
print("available namespace: {}".format(namespaces))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the API class
|
||||
api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
resource_reference_key_type = "NAMESPACE"
|
||||
resource_reference_key_id = namespaces[0]
|
||||
list_experiment_response = api_instance.list_experiment(resource_reference_key_type=resource_reference_key_type, resource_reference_key_id=resource_reference_key_id)
|
||||
for experiment in list_experiment_response.experiments:
|
||||
print(experiment)
|
||||
|
|
@ -0,0 +1,93 @@
|
|||
import re
|
||||
from urllib.parse import urlsplit
|
||||
|
||||
import requests
|
||||
|
||||
# NOTE: the following code is referred from https://github.com/kubeflow/website/issues/2916
|
||||
def get_istio_auth_session(url: str, username: str, password: str) -> dict:
|
||||
"""
|
||||
Determine if the specified URL is secured by Dex and try to obtain a session cookie.
|
||||
WARNING: only Dex `staticPasswords` and `LDAP` authentication are currently supported
|
||||
(we default default to using `staticPasswords` if both are enabled)
|
||||
|
||||
:param url: Kubeflow server URL, including protocol
|
||||
:param username: Dex `staticPasswords` or `LDAP` username
|
||||
:param password: Dex `staticPasswords` or `LDAP` password
|
||||
:return: auth session information
|
||||
"""
|
||||
# define the default return object
|
||||
auth_session = {
|
||||
"endpoint_url": url, # KF endpoint URL
|
||||
"redirect_url": None, # KF redirect URL, if applicable
|
||||
"dex_login_url": None, # Dex login URL (for POST of credentials)
|
||||
"is_secured": None, # True if KF endpoint is secured
|
||||
"session_cookie": None # Resulting session cookies in the form "key1=value1; key2=value2"
|
||||
}
|
||||
|
||||
# use a persistent session (for cookies)
|
||||
with requests.Session() as s:
|
||||
|
||||
################
|
||||
# Determine if Endpoint is Secured
|
||||
################
|
||||
resp = s.get(url, allow_redirects=True)
|
||||
if resp.status_code != 200:
|
||||
raise RuntimeError(
|
||||
f"HTTP status code '{resp.status_code}' for GET against: {url}"
|
||||
)
|
||||
|
||||
auth_session["redirect_url"] = resp.url
|
||||
|
||||
# if we were NOT redirected, then the endpoint is UNSECURED
|
||||
if len(resp.history) == 0:
|
||||
auth_session["is_secured"] = False
|
||||
return auth_session
|
||||
else:
|
||||
auth_session["is_secured"] = True
|
||||
|
||||
################
|
||||
# Get Dex Login URL
|
||||
################
|
||||
redirect_url_obj = urlsplit(auth_session["redirect_url"])
|
||||
|
||||
# if we are at `/auth?=xxxx` path, we need to select an auth type
|
||||
if re.search(r"/auth$", redirect_url_obj.path):
|
||||
# default to "staticPasswords" auth type
|
||||
redirect_url_obj = redirect_url_obj._replace(
|
||||
path=re.sub(r"/auth$", "/auth/local", redirect_url_obj.path)
|
||||
)
|
||||
|
||||
# if we are at `/auth/xxxx/login` path, then no further action is needed (we can use it for login POST)
|
||||
if re.search(r"/auth/.*/login$", redirect_url_obj.path):
|
||||
auth_session["dex_login_url"] = redirect_url_obj.geturl()
|
||||
|
||||
# else, we need to be redirected to the actual login page
|
||||
else:
|
||||
# this GET should redirect us to the `/auth/xxxx/login` path
|
||||
resp = s.get(redirect_url_obj.geturl(), allow_redirects=True)
|
||||
if resp.status_code != 200:
|
||||
raise RuntimeError(
|
||||
f"HTTP status code '{resp.status_code}' for GET against: {redirect_url_obj.geturl()}"
|
||||
)
|
||||
|
||||
# set the login url
|
||||
auth_session["dex_login_url"] = resp.url
|
||||
|
||||
################
|
||||
# Attempt Dex Login
|
||||
################
|
||||
resp = s.post(
|
||||
auth_session["dex_login_url"],
|
||||
data={"login": username, "password": password},
|
||||
allow_redirects=True
|
||||
)
|
||||
if len(resp.history) == 0:
|
||||
raise RuntimeError(
|
||||
f"Login credentials were probably invalid - "
|
||||
f"No redirect after POST to: {auth_session['dex_login_url']}"
|
||||
)
|
||||
|
||||
# store the session cookies in a "key1=value1; key2=value2" string
|
||||
auth_session["session_cookie"] = "; ".join([f"{c.name}={c.value}" for c in s.cookies])
|
||||
|
||||
return auth_session
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
import os
|
||||
import requests
|
||||
|
||||
from typing import TypedDict
|
||||
|
||||
def retrieve_namespaces(host: str, auth_session: TypedDict) -> str:
|
||||
workgroup_endpoint = os.path.join(host, "api/workgroup/env-info")
|
||||
|
||||
cookies = {}
|
||||
cookie_tokens = auth_session["session_cookie"].split("=")
|
||||
print(cookie_tokens[0])
|
||||
cookies[cookie_tokens[0]]=cookie_tokens[1]
|
||||
resp = requests.get(workgroup_endpoint, cookies=cookies)
|
||||
if resp.status_code != 200:
|
||||
raise RuntimeError(
|
||||
f"HTTP status code '{resp.status_code}' for GET against: {workgroup_endpoint}"
|
||||
)
|
||||
return [ns["namespace"] for ns in resp.json()["namespaces"] if
|
||||
ns["role"]=="owner"]
|
||||
|
|
@ -0,0 +1,132 @@
|
|||
from __future__ import print_function
|
||||
|
||||
import time
|
||||
import kfp_server_api
|
||||
import os
|
||||
import requests
|
||||
import string
|
||||
import random
|
||||
import json
|
||||
from kfp_server_api.rest import ApiException
|
||||
from pprint import pprint
|
||||
from kfp_login import get_istio_auth_session
|
||||
from kfp_namespace import retrieve_namespaces
|
||||
|
||||
host = "https://ai4edu.thu01.footprint-ai.com"
|
||||
username = "thu02"
|
||||
password = "M*$3sNF7"
|
||||
|
||||
auth_session = get_istio_auth_session(
|
||||
url=host,
|
||||
username=username,
|
||||
password=password
|
||||
)
|
||||
|
||||
# The client must configure the authentication and authorization parameters
|
||||
# in accordance with the API server security policy.
|
||||
# Examples for each auth method are provided below, use the example that
|
||||
# satisfies your auth use case.
|
||||
|
||||
# Configure API key authorization: Bearer
|
||||
configuration = kfp_server_api.Configuration(
|
||||
host = os.path.join(host, "pipeline"),
|
||||
)
|
||||
configuration.debug = True
|
||||
|
||||
namespaces = retrieve_namespaces(host, auth_session)
|
||||
#print("available namespace: {}".format(namespaces))
|
||||
|
||||
def random_suffix() -> string:
|
||||
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=10))
|
||||
|
||||
# Enter a context with an instance of the API client
|
||||
with kfp_server_api.ApiClient(configuration, cookie=auth_session["session_cookie"]) as api_client:
|
||||
# Create an instance of the Experiment API class
|
||||
experiment_api_instance = kfp_server_api.ExperimentServiceApi(api_client)
|
||||
name="experiment-" + random_suffix()
|
||||
description="This is a experiment for mnist."
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(
|
||||
type=kfp_server_api.models.ApiResourceType.NAMESPACE,
|
||||
id=resource_reference_key_id
|
||||
),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER
|
||||
)]
|
||||
body = kfp_server_api.ApiExperiment(name=name, description=description, resource_references=resource_references) # ApiExperiment | The experiment to be created.
|
||||
try:
|
||||
# Creates a new experiment.
|
||||
experiment_api_response = experiment_api_instance.create_experiment(body)
|
||||
experiment_id = experiment_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling ExperimentServiceApi->create_experiment: %s\n" % e)
|
||||
|
||||
# Create an instance of the pipeline API class
|
||||
api_instance = kfp_server_api.PipelineUploadServiceApi(api_client)
|
||||
uploadfile='pipelines/mnist_pipeline.yaml'
|
||||
name='pipeline-' + random_suffix()
|
||||
description="This is a mnist pipline."
|
||||
try:
|
||||
pipeline_api_response = api_instance.upload_pipeline(uploadfile, name=name, description=description)
|
||||
pipeline_id = pipeline_api_response.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling PipelineUploadServiceApi->upload_pipeline: %s\n" % e)
|
||||
|
||||
# Create an instance of the run API class
|
||||
run_api_instance = kfp_server_api.RunServiceApi(api_client)
|
||||
display_name = 'mnist' + random_suffix()
|
||||
description = "This is a mnist run."
|
||||
pipeline_spec = kfp_server_api.ApiPipelineSpec(pipeline_id=pipeline_id)
|
||||
resource_reference_key_id = namespaces[0]
|
||||
resource_references=[kfp_server_api.models.ApiResourceReference(
|
||||
key=kfp_server_api.models.ApiResourceKey(id=experiment_id, type=kfp_server_api.models.ApiResourceType.EXPERIMENT),
|
||||
relationship=kfp_server_api.models.ApiRelationship.OWNER )]
|
||||
body = kfp_server_api.ApiRun(name=display_name, description=description, pipeline_spec=pipeline_spec, resource_references=resource_references) # ApiRun |
|
||||
try:
|
||||
# Creates a new run.
|
||||
run_api_response = run_api_instance.create_run(body)
|
||||
run_id = run_api_response.run.id # str | The ID of the run to be retrieved.
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->create_run: %s\n" % e)
|
||||
|
||||
Completed_flag = False
|
||||
polling_interval = 10 # Time in seconds between polls
|
||||
|
||||
while not Completed_flag:
|
||||
try:
|
||||
time.sleep(1)
|
||||
# Finds a specific run by ID.
|
||||
api_instance = run_api_instance.get_run(run_id)
|
||||
output = api_instance.pipeline_runtime.workflow_manifest
|
||||
output = json.loads(output)
|
||||
|
||||
try:
|
||||
nodes = output['status']['nodes']
|
||||
conditions = output['status']['conditions'] # Comfirm completion.
|
||||
|
||||
except KeyError:
|
||||
nodes = {}
|
||||
conditions = []
|
||||
|
||||
output_value = None
|
||||
Completed_flag = conditions[1]['status'] if len(conditions) > 1 else False
|
||||
|
||||
except ApiException as e:
|
||||
print("Exception when calling RunServiceApi->get_run: %s\n" % e)
|
||||
break
|
||||
|
||||
if not Completed_flag:
|
||||
print("Pipeline is still running. Waiting...")
|
||||
time.sleep(polling_interval-1)
|
||||
|
||||
for node_id, node in nodes.items():
|
||||
if 'inputs' in node and 'parameters' in node['inputs']:
|
||||
for parameter in node['inputs']['parameters']:
|
||||
if parameter['name'] == 'client-last_accuracy':
|
||||
output_value = parameter['value']
|
||||
|
||||
if output_value is not None:
|
||||
print(f"fl Accuracy: {output_value}")
|
||||
else:
|
||||
print("Parameter not found.")
|
||||
print(nodes)
|
||||
|
|
@ -0,0 +1,651 @@
|
|||
apiVersion: argoproj.io/v1alpha1
|
||||
kind: Workflow
|
||||
metadata:
|
||||
generateName: fl-test-
|
||||
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9, pipelines.kubeflow.org/pipeline_compilation_time: '2024-01-02T05:53:41.650368',
|
||||
pipelines.kubeflow.org/pipeline_spec: '{"inputs": [{"default": "kubeflow-user-thu01",
|
||||
"name": "namespace", "optional": true}], "name": "FL test"}'}
|
||||
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9}
|
||||
spec:
|
||||
entrypoint: fl-test
|
||||
templates:
|
||||
- name: client
|
||||
container:
|
||||
args: [--batch, '1', '----output-paths', /tmp/outputs/last_accuracy/data]
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
'requests' 'pandas' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
|
||||
--quiet --no-warn-script-location 'requests' 'pandas' --user) && "$0" "$@"
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def client(batch):\n import json\n import requests\n import time\n\
|
||||
\ import pandas as pd\n import numpy as np\n import tensorflow as\
|
||||
\ tf\n from tensorflow.keras.models import Sequential\n from tensorflow.keras.layers\
|
||||
\ import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n \
|
||||
\ from tensorflow.keras.layers import Activation\n from tensorflow.keras.layers\
|
||||
\ import Flatten\n from tensorflow.keras.layers import Dense\n from\
|
||||
\ tensorflow.keras.layers import LSTM\n from tensorflow.keras.layers import\
|
||||
\ Dropout\n from tensorflow.keras.optimizers import SGD\n from tensorflow.keras\
|
||||
\ import backend as K\n\n normal_url='https://drive.google.com/uc?id=16SaNuh7P_UTIMKLX-7umTnDe27uKYRsK&export=download'\
|
||||
\ \n abnormal_url='https://drive.google.com/uc?id=1INzlvIOGcLAgXwSL-0ktN6hhy--gjtwp&export=download'\n\
|
||||
\ normal_data = pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n\
|
||||
\ num_features = len(normal_data.columns)\n print(num_features)\n \
|
||||
\ normal_label = np.array([[1, 0]] * len(normal_data))\n abnormal_label\
|
||||
\ = np.array([[0, 1]] * len(abnormal_data))\n\n data = np.vstack((normal_data,\
|
||||
\ abnormal_data))\n data_label = np.vstack((normal_label, abnormal_label))\n\
|
||||
\n shuffler = np.random.permutation(len(data))\n data = data[shuffler]\n\
|
||||
\ data_label = data_label[shuffler]\n\n data = data.reshape(len(data),\
|
||||
\ num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\
|
||||
\n full_data = list(zip(data, data_label))\n data_length=len(full_data)\n\
|
||||
\n input_shape = (17, 1)\n num_classes = 2\n\n class SimpleMLP:\n\
|
||||
\ @staticmethod\n def build(shape, classes):\n model\
|
||||
\ = Sequential()\n model.add(LSTM(units=64, input_shape=input_shape,\
|
||||
\ return_sequences=True))\n model.add(Dropout(0.2))\n \
|
||||
\ model.add(LSTM(units=64))\n model.add(Dropout(0.2))\n \
|
||||
\ model.add(Dense(units=num_classes, activation='softmax'))\n\n \
|
||||
\ return model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]\
|
||||
\ #batch data\n else:\n full_data=full_data[int(data_length/2):data_length]\
|
||||
\ #The client should have its own data, not like this. It's a lazy method.\n\
|
||||
\n print('data len= ',len(full_data))\n def batch_data(data_shard, bs=32):\n\
|
||||
\n #seperate shard into data and labels lists\n data, label\
|
||||
\ = zip(*data_shard)\n dataset = tf.data.Dataset.from_tensor_slices((list(data),\
|
||||
\ list(label)))\n return dataset.shuffle(len(label)).batch(bs)\n\n\
|
||||
\ dataset=batch_data(full_data)\n #print(dataset)\n\n bs = next(iter(dataset))[0].shape[0]\n\
|
||||
\ local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n\
|
||||
\ loss='categorical_crossentropy'\n metrics = ['accuracy']\n optimizer\
|
||||
\ = 'adam'\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\
|
||||
\n for comm_round in range(1):\n print('The ',comm_round+1, 'round')\n\
|
||||
\ client_model = smlp_model.build(17, 1)\n client_model.compile(loss=loss,\
|
||||
\ \n optimizer=optimizer, \n metrics=metrics)\n\
|
||||
\n if(comm_round == 0):\n history = client_model.fit(dataset,\
|
||||
\ epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n\
|
||||
\ history = client_model.fit(dataset, epochs=5, verbose=1)\n\n\
|
||||
\ test_loss, test_accuracy = client_model.evaluate(dataset)\n \
|
||||
\ print(f'Test accuracy: {test_accuracy}')\n\n local_weight = client_model.get_weights()\n\
|
||||
\ local_weight = [np.array(w).tolist() for w in local_weight]\n\n \
|
||||
\ client_data = {\"local_count\": local_count,'bs': bs, 'local_weight':\
|
||||
\ json.dumps(local_weight)}\n\n while True:\n try:\n \
|
||||
\ weight = (requests.post(server_url,data=client_data))\n\n \
|
||||
\ if weight.status_code == 200:\n print(f\"\
|
||||
exist\")\n\n break\n else:\n \
|
||||
\ print(f\"server error\")\n\n except requests.exceptions.RequestException:\n\
|
||||
\n print(f\"not exist\")\n\n time.sleep(5)\n\n \
|
||||
\ data = weight.json()\n avg_weight = data.get('result')\n \
|
||||
\ avg_weight = json.loads(avg_weight)\n avg_weight = [np.array(lst)\
|
||||
\ for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\"\
|
||||
\ \n try:\n response = requests.get(shutdown_url)\n except\
|
||||
\ requests.exceptions.ConnectionError:\n print('already shutdown')\n\
|
||||
\ last_accuracy = history.history['accuracy'][-1]\n print(last_accuracy)\n\
|
||||
\ return([last_accuracy])\n\ndef _serialize_float(float_value: float) ->\
|
||||
\ str:\n if isinstance(float_value, str):\n return float_value\n\
|
||||
\ if not isinstance(float_value, (float, int)):\n raise TypeError('Value\
|
||||
\ \"{}\" has type \"{}\" instead of float.'.format(\n str(float_value),\
|
||||
\ str(type(float_value))))\n return str(float_value)\n\nimport argparse\n\
|
||||
_parser = argparse.ArgumentParser(prog='Client', description='')\n_parser.add_argument(\"\
|
||||
--batch\", dest=\"batch\", type=int, required=True, default=argparse.SUPPRESS)\n\
|
||||
_parser.add_argument(\"----output-paths\", dest=\"_output_paths\", type=str,\
|
||||
\ nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files = _parsed_args.pop(\"\
|
||||
_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers\
|
||||
\ = [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n\
|
||||
\ try:\n os.makedirs(os.path.dirname(output_file))\n except OSError:\n\
|
||||
\ pass\n with open(output_file, 'w') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"
|
||||
image: tensorflow/tensorflow
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
outputs:
|
||||
parameters:
|
||||
- name: client-last_accuracy
|
||||
valueFrom: {path: /tmp/outputs/last_accuracy/data}
|
||||
artifacts:
|
||||
- {name: client-last_accuracy, path: /tmp/outputs/last_accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--batch", {"inputValue": "batch"}, "----output-paths", {"outputPath":
|
||||
"last_accuracy"}], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1
|
||||
python3 -m pip install --quiet --no-warn-script-location ''requests'' ''pandas''
|
||||
|| PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
''requests'' ''pandas'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def client(batch):\n import json\n import requests\n import time\n import
|
||||
pandas as pd\n import numpy as np\n import tensorflow as tf\n from
|
||||
tensorflow.keras.models import Sequential\n from tensorflow.keras.layers
|
||||
import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n from
|
||||
tensorflow.keras.layers import Activation\n from tensorflow.keras.layers
|
||||
import Flatten\n from tensorflow.keras.layers import Dense\n from
|
||||
tensorflow.keras.layers import LSTM\n from tensorflow.keras.layers import
|
||||
Dropout\n from tensorflow.keras.optimizers import SGD\n from tensorflow.keras
|
||||
import backend as K\n\n normal_url=''https://drive.google.com/uc?id=16SaNuh7P_UTIMKLX-7umTnDe27uKYRsK&export=download''
|
||||
\n abnormal_url=''https://drive.google.com/uc?id=1INzlvIOGcLAgXwSL-0ktN6hhy--gjtwp&export=download''\n normal_data
|
||||
= pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n num_features
|
||||
= len(normal_data.columns)\n print(num_features)\n normal_label =
|
||||
np.array([[1, 0]] * len(normal_data))\n abnormal_label = np.array([[0,
|
||||
1]] * len(abnormal_data))\n\n data = np.vstack((normal_data, abnormal_data))\n data_label
|
||||
= np.vstack((normal_label, abnormal_label))\n\n shuffler = np.random.permutation(len(data))\n data
|
||||
= data[shuffler]\n data_label = data_label[shuffler]\n\n data = data.reshape(len(data),
|
||||
num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\n full_data
|
||||
= list(zip(data, data_label))\n data_length=len(full_data)\n\n input_shape
|
||||
= (17, 1)\n num_classes = 2\n\n class SimpleMLP:\n @staticmethod\n def
|
||||
build(shape, classes):\n model = Sequential()\n model.add(LSTM(units=64,
|
||||
input_shape=input_shape, return_sequences=True))\n model.add(Dropout(0.2))\n model.add(LSTM(units=64))\n model.add(Dropout(0.2))\n model.add(Dense(units=num_classes,
|
||||
activation=''softmax''))\n\n return model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]
|
||||
#batch data\n else:\n full_data=full_data[int(data_length/2):data_length]
|
||||
#The client should have its own data, not like this. It''s a lazy method.\n\n print(''data
|
||||
len= '',len(full_data))\n def batch_data(data_shard, bs=32):\n\n #seperate
|
||||
shard into data and labels lists\n data, label = zip(*data_shard)\n dataset
|
||||
= tf.data.Dataset.from_tensor_slices((list(data), list(label)))\n return
|
||||
dataset.shuffle(len(label)).batch(bs)\n\n dataset=batch_data(full_data)\n #print(dataset)\n\n bs
|
||||
= next(iter(dataset))[0].shape[0]\n local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n loss=''categorical_crossentropy''\n metrics
|
||||
= [''accuracy'']\n optimizer = ''adam''\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\n for
|
||||
comm_round in range(1):\n print(''The '',comm_round+1, ''round'')\n client_model
|
||||
= smlp_model.build(17, 1)\n client_model.compile(loss=loss, \n optimizer=optimizer,
|
||||
\n metrics=metrics)\n\n if(comm_round == 0):\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n\n test_loss, test_accuracy
|
||||
= client_model.evaluate(dataset)\n print(f''Test accuracy: {test_accuracy}'')\n\n local_weight
|
||||
= client_model.get_weights()\n local_weight = [np.array(w).tolist()
|
||||
for w in local_weight]\n\n client_data = {\"local_count\": local_count,''bs'':
|
||||
bs, ''local_weight'': json.dumps(local_weight)}\n\n while True:\n try:\n weight
|
||||
= (requests.post(server_url,data=client_data))\n\n if weight.status_code
|
||||
== 200:\n print(f\"exist\")\n\n break\n else:\n print(f\"server
|
||||
error\")\n\n except requests.exceptions.RequestException:\n\n print(f\"not
|
||||
exist\")\n\n time.sleep(5)\n\n data = weight.json()\n avg_weight
|
||||
= data.get(''result'')\n avg_weight = json.loads(avg_weight)\n avg_weight
|
||||
= [np.array(lst) for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\" \n try:\n response
|
||||
= requests.get(shutdown_url)\n except requests.exceptions.ConnectionError:\n print(''already
|
||||
shutdown'')\n last_accuracy = history.history[''accuracy''][-1]\n print(last_accuracy)\n return([last_accuracy])\n\ndef
|
||||
_serialize_float(float_value: float) -> str:\n if isinstance(float_value,
|
||||
str):\n return float_value\n if not isinstance(float_value, (float,
|
||||
int)):\n raise TypeError(''Value \"{}\" has type \"{}\" instead of
|
||||
float.''.format(\n str(float_value), str(type(float_value))))\n return
|
||||
str(float_value)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Client'',
|
||||
description='''')\n_parser.add_argument(\"--batch\", dest=\"batch\", type=int,
|
||||
required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "tensorflow/tensorflow"}}, "inputs": [{"name": "batch", "type":
|
||||
"Integer"}], "name": "Client", "outputs": [{"name": "last_accuracy", "type":
|
||||
"Float"}]}', pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"batch":
|
||||
"1"}'}
|
||||
- name: client-2
|
||||
container:
|
||||
args: [--batch, '2', '----output-paths', /tmp/outputs/last_accuracy/data]
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
'requests' 'pandas' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
|
||||
--quiet --no-warn-script-location 'requests' 'pandas' --user) && "$0" "$@"
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def client(batch):\n import json\n import requests\n import time\n\
|
||||
\ import pandas as pd\n import numpy as np\n import tensorflow as\
|
||||
\ tf\n from tensorflow.keras.models import Sequential\n from tensorflow.keras.layers\
|
||||
\ import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n \
|
||||
\ from tensorflow.keras.layers import Activation\n from tensorflow.keras.layers\
|
||||
\ import Flatten\n from tensorflow.keras.layers import Dense\n from\
|
||||
\ tensorflow.keras.layers import LSTM\n from tensorflow.keras.layers import\
|
||||
\ Dropout\n from tensorflow.keras.optimizers import SGD\n from tensorflow.keras\
|
||||
\ import backend as K\n\n normal_url='https://drive.google.com/uc?id=16SaNuh7P_UTIMKLX-7umTnDe27uKYRsK&export=download'\
|
||||
\ \n abnormal_url='https://drive.google.com/uc?id=1INzlvIOGcLAgXwSL-0ktN6hhy--gjtwp&export=download'\n\
|
||||
\ normal_data = pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n\
|
||||
\ num_features = len(normal_data.columns)\n print(num_features)\n \
|
||||
\ normal_label = np.array([[1, 0]] * len(normal_data))\n abnormal_label\
|
||||
\ = np.array([[0, 1]] * len(abnormal_data))\n\n data = np.vstack((normal_data,\
|
||||
\ abnormal_data))\n data_label = np.vstack((normal_label, abnormal_label))\n\
|
||||
\n shuffler = np.random.permutation(len(data))\n data = data[shuffler]\n\
|
||||
\ data_label = data_label[shuffler]\n\n data = data.reshape(len(data),\
|
||||
\ num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\
|
||||
\n full_data = list(zip(data, data_label))\n data_length=len(full_data)\n\
|
||||
\n input_shape = (17, 1)\n num_classes = 2\n\n class SimpleMLP:\n\
|
||||
\ @staticmethod\n def build(shape, classes):\n model\
|
||||
\ = Sequential()\n model.add(LSTM(units=64, input_shape=input_shape,\
|
||||
\ return_sequences=True))\n model.add(Dropout(0.2))\n \
|
||||
\ model.add(LSTM(units=64))\n model.add(Dropout(0.2))\n \
|
||||
\ model.add(Dense(units=num_classes, activation='softmax'))\n\n \
|
||||
\ return model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]\
|
||||
\ #batch data\n else:\n full_data=full_data[int(data_length/2):data_length]\
|
||||
\ #The client should have its own data, not like this. It's a lazy method.\n\
|
||||
\n print('data len= ',len(full_data))\n def batch_data(data_shard, bs=32):\n\
|
||||
\n #seperate shard into data and labels lists\n data, label\
|
||||
\ = zip(*data_shard)\n dataset = tf.data.Dataset.from_tensor_slices((list(data),\
|
||||
\ list(label)))\n return dataset.shuffle(len(label)).batch(bs)\n\n\
|
||||
\ dataset=batch_data(full_data)\n #print(dataset)\n\n bs = next(iter(dataset))[0].shape[0]\n\
|
||||
\ local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n\
|
||||
\ loss='categorical_crossentropy'\n metrics = ['accuracy']\n optimizer\
|
||||
\ = 'adam'\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\
|
||||
\n for comm_round in range(1):\n print('The ',comm_round+1, 'round')\n\
|
||||
\ client_model = smlp_model.build(17, 1)\n client_model.compile(loss=loss,\
|
||||
\ \n optimizer=optimizer, \n metrics=metrics)\n\
|
||||
\n if(comm_round == 0):\n history = client_model.fit(dataset,\
|
||||
\ epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n\
|
||||
\ history = client_model.fit(dataset, epochs=5, verbose=1)\n\n\
|
||||
\ test_loss, test_accuracy = client_model.evaluate(dataset)\n \
|
||||
\ print(f'Test accuracy: {test_accuracy}')\n\n local_weight = client_model.get_weights()\n\
|
||||
\ local_weight = [np.array(w).tolist() for w in local_weight]\n\n \
|
||||
\ client_data = {\"local_count\": local_count,'bs': bs, 'local_weight':\
|
||||
\ json.dumps(local_weight)}\n\n while True:\n try:\n \
|
||||
\ weight = (requests.post(server_url,data=client_data))\n\n \
|
||||
\ if weight.status_code == 200:\n print(f\"\
|
||||
exist\")\n\n break\n else:\n \
|
||||
\ print(f\"server error\")\n\n except requests.exceptions.RequestException:\n\
|
||||
\n print(f\"not exist\")\n\n time.sleep(5)\n\n \
|
||||
\ data = weight.json()\n avg_weight = data.get('result')\n \
|
||||
\ avg_weight = json.loads(avg_weight)\n avg_weight = [np.array(lst)\
|
||||
\ for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\"\
|
||||
\ \n try:\n response = requests.get(shutdown_url)\n except\
|
||||
\ requests.exceptions.ConnectionError:\n print('already shutdown')\n\
|
||||
\ last_accuracy = history.history['accuracy'][-1]\n print(last_accuracy)\n\
|
||||
\ return([last_accuracy])\n\ndef _serialize_float(float_value: float) ->\
|
||||
\ str:\n if isinstance(float_value, str):\n return float_value\n\
|
||||
\ if not isinstance(float_value, (float, int)):\n raise TypeError('Value\
|
||||
\ \"{}\" has type \"{}\" instead of float.'.format(\n str(float_value),\
|
||||
\ str(type(float_value))))\n return str(float_value)\n\nimport argparse\n\
|
||||
_parser = argparse.ArgumentParser(prog='Client', description='')\n_parser.add_argument(\"\
|
||||
--batch\", dest=\"batch\", type=int, required=True, default=argparse.SUPPRESS)\n\
|
||||
_parser.add_argument(\"----output-paths\", dest=\"_output_paths\", type=str,\
|
||||
\ nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files = _parsed_args.pop(\"\
|
||||
_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers\
|
||||
\ = [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n\
|
||||
\ try:\n os.makedirs(os.path.dirname(output_file))\n except OSError:\n\
|
||||
\ pass\n with open(output_file, 'w') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"
|
||||
image: tensorflow/tensorflow
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: client-2-last_accuracy, path: /tmp/outputs/last_accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--batch", {"inputValue": "batch"}, "----output-paths", {"outputPath":
|
||||
"last_accuracy"}], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1
|
||||
python3 -m pip install --quiet --no-warn-script-location ''requests'' ''pandas''
|
||||
|| PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
''requests'' ''pandas'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def client(batch):\n import json\n import requests\n import time\n import
|
||||
pandas as pd\n import numpy as np\n import tensorflow as tf\n from
|
||||
tensorflow.keras.models import Sequential\n from tensorflow.keras.layers
|
||||
import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n from
|
||||
tensorflow.keras.layers import Activation\n from tensorflow.keras.layers
|
||||
import Flatten\n from tensorflow.keras.layers import Dense\n from
|
||||
tensorflow.keras.layers import LSTM\n from tensorflow.keras.layers import
|
||||
Dropout\n from tensorflow.keras.optimizers import SGD\n from tensorflow.keras
|
||||
import backend as K\n\n normal_url=''https://drive.google.com/uc?id=16SaNuh7P_UTIMKLX-7umTnDe27uKYRsK&export=download''
|
||||
\n abnormal_url=''https://drive.google.com/uc?id=1INzlvIOGcLAgXwSL-0ktN6hhy--gjtwp&export=download''\n normal_data
|
||||
= pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n num_features
|
||||
= len(normal_data.columns)\n print(num_features)\n normal_label =
|
||||
np.array([[1, 0]] * len(normal_data))\n abnormal_label = np.array([[0,
|
||||
1]] * len(abnormal_data))\n\n data = np.vstack((normal_data, abnormal_data))\n data_label
|
||||
= np.vstack((normal_label, abnormal_label))\n\n shuffler = np.random.permutation(len(data))\n data
|
||||
= data[shuffler]\n data_label = data_label[shuffler]\n\n data = data.reshape(len(data),
|
||||
num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\n full_data
|
||||
= list(zip(data, data_label))\n data_length=len(full_data)\n\n input_shape
|
||||
= (17, 1)\n num_classes = 2\n\n class SimpleMLP:\n @staticmethod\n def
|
||||
build(shape, classes):\n model = Sequential()\n model.add(LSTM(units=64,
|
||||
input_shape=input_shape, return_sequences=True))\n model.add(Dropout(0.2))\n model.add(LSTM(units=64))\n model.add(Dropout(0.2))\n model.add(Dense(units=num_classes,
|
||||
activation=''softmax''))\n\n return model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]
|
||||
#batch data\n else:\n full_data=full_data[int(data_length/2):data_length]
|
||||
#The client should have its own data, not like this. It''s a lazy method.\n\n print(''data
|
||||
len= '',len(full_data))\n def batch_data(data_shard, bs=32):\n\n #seperate
|
||||
shard into data and labels lists\n data, label = zip(*data_shard)\n dataset
|
||||
= tf.data.Dataset.from_tensor_slices((list(data), list(label)))\n return
|
||||
dataset.shuffle(len(label)).batch(bs)\n\n dataset=batch_data(full_data)\n #print(dataset)\n\n bs
|
||||
= next(iter(dataset))[0].shape[0]\n local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n loss=''categorical_crossentropy''\n metrics
|
||||
= [''accuracy'']\n optimizer = ''adam''\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\n for
|
||||
comm_round in range(1):\n print(''The '',comm_round+1, ''round'')\n client_model
|
||||
= smlp_model.build(17, 1)\n client_model.compile(loss=loss, \n optimizer=optimizer,
|
||||
\n metrics=metrics)\n\n if(comm_round == 0):\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n\n test_loss, test_accuracy
|
||||
= client_model.evaluate(dataset)\n print(f''Test accuracy: {test_accuracy}'')\n\n local_weight
|
||||
= client_model.get_weights()\n local_weight = [np.array(w).tolist()
|
||||
for w in local_weight]\n\n client_data = {\"local_count\": local_count,''bs'':
|
||||
bs, ''local_weight'': json.dumps(local_weight)}\n\n while True:\n try:\n weight
|
||||
= (requests.post(server_url,data=client_data))\n\n if weight.status_code
|
||||
== 200:\n print(f\"exist\")\n\n break\n else:\n print(f\"server
|
||||
error\")\n\n except requests.exceptions.RequestException:\n\n print(f\"not
|
||||
exist\")\n\n time.sleep(5)\n\n data = weight.json()\n avg_weight
|
||||
= data.get(''result'')\n avg_weight = json.loads(avg_weight)\n avg_weight
|
||||
= [np.array(lst) for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\" \n try:\n response
|
||||
= requests.get(shutdown_url)\n except requests.exceptions.ConnectionError:\n print(''already
|
||||
shutdown'')\n last_accuracy = history.history[''accuracy''][-1]\n print(last_accuracy)\n return([last_accuracy])\n\ndef
|
||||
_serialize_float(float_value: float) -> str:\n if isinstance(float_value,
|
||||
str):\n return float_value\n if not isinstance(float_value, (float,
|
||||
int)):\n raise TypeError(''Value \"{}\" has type \"{}\" instead of
|
||||
float.''.format(\n str(float_value), str(type(float_value))))\n return
|
||||
str(float_value)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Client'',
|
||||
description='''')\n_parser.add_argument(\"--batch\", dest=\"batch\", type=int,
|
||||
required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "tensorflow/tensorflow"}}, "inputs": [{"name": "batch", "type":
|
||||
"Integer"}], "name": "Client", "outputs": [{"name": "last_accuracy", "type":
|
||||
"Float"}]}', pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"batch":
|
||||
"2"}'}
|
||||
- name: delete-service
|
||||
resource:
|
||||
action: delete
|
||||
flags: [--wait=false]
|
||||
manifest: |
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: http-service
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 8080
|
||||
selector:
|
||||
app: http-service
|
||||
type: NodePort
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
- name: fl-test
|
||||
dag:
|
||||
tasks:
|
||||
- {name: client, template: client}
|
||||
- {name: client-2, template: client-2}
|
||||
- name: delete-service
|
||||
template: delete-service
|
||||
dependencies: [server]
|
||||
- {name: http-service, template: http-service}
|
||||
- name: server
|
||||
template: server
|
||||
dependencies: [http-service]
|
||||
- name: show-results
|
||||
template: show-results
|
||||
dependencies: [client]
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: client-last_accuracy, value: '{{tasks.client.outputs.parameters.client-last_accuracy}}'}
|
||||
- name: http-service
|
||||
resource:
|
||||
action: create
|
||||
manifest: |
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: http-service
|
||||
spec:
|
||||
ports:
|
||||
- port: 5000
|
||||
protocol: TCP
|
||||
targetPort: 8080
|
||||
selector:
|
||||
app: http-service
|
||||
outputs:
|
||||
parameters:
|
||||
- name: http-service-manifest
|
||||
valueFrom: {jsonPath: '{}'}
|
||||
- name: http-service-name
|
||||
valueFrom: {jsonPath: '{.metadata.name}'}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
- name: server
|
||||
container:
|
||||
args: []
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
'flask' 'pandas' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
|
||||
--quiet --no-warn-script-location 'flask' 'pandas' --user) && "$0" "$@"
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def server():\n import json\n import pandas as pd\n import numpy\
|
||||
\ as np\n import pickle\n import threading\n import time\n import\
|
||||
\ tensorflow as tf\n from flask import Flask, jsonify,request\n import\
|
||||
\ os\n\n app = Flask(__name__)\n clients_local_count = []\n scaled_local_weight_list\
|
||||
\ = []\n global_value = { #Share variable\n 'last_run_statue'\
|
||||
\ : False, #last run finish or not\n 'data_statue' : None,\
|
||||
\ #global_count finish or not\n 'global_count' : None,\n\
|
||||
\ 'scale_statue' : None,\n 'weight_statue'\
|
||||
\ : None,\n 'average_weights' : None,\n \
|
||||
\ 'shutdown' : 0}\n\n NUM_OF_CLIENTS = 2 #number of clients\n\n \
|
||||
\ init_lock = threading.Lock()\n clients_local_count_lock = threading.Lock()\n\
|
||||
\ scaled_local_weight_list_lock = threading.Lock()\n cal_weight_lock\
|
||||
\ = threading.Lock()\n shutdown_lock = threading.Lock()\n\n @app.before_request\n\
|
||||
\ def before_request():\n print('get request')\n\n @app.route('/data',\
|
||||
\ methods=['POST'])\n def flask_server():\n with init_lock: #check\
|
||||
\ last run is finish and init varible\n\n while True:\n\n \
|
||||
\ if(len(clients_local_count)==0 and global_value['last_run_statue']\
|
||||
\ == False):#init the variable by first client enter\n \
|
||||
\ global_value['last_run_statue'] = True\n global_value['data_statue']\
|
||||
\ = False\n global_value['scale_statue'] = False\n \
|
||||
\ global_value['weight_statue'] = False\n \
|
||||
\ break\n\n elif(global_value['last_run_statue'] == True):\n\
|
||||
\ break\n time.sleep(3)\n\n local_count\
|
||||
\ = int(request.form.get('local_count')) #get data\n bs =\
|
||||
\ int(request.form.get('bs'))\n local_weight = json.loads(request.form.get('local_weight'))\n\
|
||||
\ local_weight = [np.array(lst) for lst in local_weight]\n\n \
|
||||
\ def scale_model_weights(weight, scalar):\n weight_final = []\n\
|
||||
\ steps = len(weight)\n for i in range(steps):\n \
|
||||
\ weight_final.append(scalar * weight[i])\n return\
|
||||
\ weight_final\n def sum_scaled_weights(scaled_weight_list):\n\n \
|
||||
\ avg_grad = list()\n #get the average grad accross all\
|
||||
\ client gradients\n for grad_list_tuple in zip(*scaled_weight_list):\n\
|
||||
\ layer_mean = tf.math.reduce_sum(grad_list_tuple, axis=0)\n\
|
||||
\ avg_grad.append(layer_mean)\n\n return avg_grad\n\
|
||||
\n with clients_local_count_lock:\n clients_local_count.append(int(local_count))\n\
|
||||
\n with scaled_local_weight_list_lock:\n while True:\n\n\
|
||||
\ if (len(clients_local_count) == NUM_OF_CLIENTS and global_value['data_statue']\
|
||||
\ != True):\n global_value['last_run_statue'] = False\n\
|
||||
\ sum_of_local_count=sum(clients_local_count)\n\n \
|
||||
\ global_value['global_count'] = sum_of_local_count \n\n\
|
||||
\ scaling_factor=local_count/global_value['global_count']\n\
|
||||
\ scaled_weights = scale_model_weights(local_weight, scaling_factor)\n\
|
||||
\ scaled_local_weight_list.append(scaled_weights)\n\n \
|
||||
\ global_value['scale_statue'] = True \n \
|
||||
\ global_value['data_statue'] = True\n break\n \
|
||||
\ elif (global_value['data_statue'] == True and global_value['scale_statue']\
|
||||
\ == True):\n scaling_factor=local_count/global_value['global_count']\n\
|
||||
\ scaled_weights =scale_model_weights(local_weight, scaling_factor)\n\
|
||||
\ scaled_local_weight_list.append(scaled_weights)\n\n \
|
||||
\ break\n time.sleep(1)\n\n with cal_weight_lock:\n\
|
||||
\n while True:\n if(len(scaled_local_weight_list)\
|
||||
\ == NUM_OF_CLIENTS and global_value['weight_statue'] != True):\n\n \
|
||||
\ global_value['average_weights'] = sum_scaled_weights(scaled_local_weight_list)\n\
|
||||
\ global_value['weight_statue'] = True\n \
|
||||
\ global_value['average_weights'] = json.dumps([np.array(w).tolist()\
|
||||
\ for w in global_value['average_weights']])\n\n break\n\
|
||||
\n elif(global_value['weight_statue'] == True):\n\n \
|
||||
\ break\n\n time.sleep(1)\n\n clients_local_count.clear()\n\
|
||||
\ scaled_local_weight_list.clear()\n\n return jsonify({'result':\
|
||||
\ (global_value['average_weights'])})\n\n @app.route('/shutdown', methods=['GET'])\n\
|
||||
\ def shutdown_server():\n global_value['shutdown'] +=1 \n \
|
||||
\ with shutdown_lock:\n while True:\n if(global_value['shutdown']\
|
||||
\ == NUM_OF_CLIENTS):\n os._exit(0)\n \
|
||||
\ return 'Server shutting down...'\n time.sleep(1)\n\n \
|
||||
\ app.run(host=\"0.0.0.0\", port=8080)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog='Server',\
|
||||
\ description='')\n_parsed_args = vars(_parser.parse_args())\n\n_outputs =\
|
||||
\ server(**_parsed_args)\n"
|
||||
image: tensorflow/tensorflow
|
||||
ports:
|
||||
- {containerPort: 8080, name: my-port}
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
metadata:
|
||||
labels:
|
||||
app: http-service
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": [], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1 python3
|
||||
-m pip install --quiet --no-warn-script-location ''flask'' ''pandas'' ||
|
||||
PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
''flask'' ''pandas'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def server():\n import json\n import pandas as pd\n import numpy
|
||||
as np\n import pickle\n import threading\n import time\n import
|
||||
tensorflow as tf\n from flask import Flask, jsonify,request\n import
|
||||
os\n\n app = Flask(__name__)\n clients_local_count = []\n scaled_local_weight_list
|
||||
= []\n global_value = { #Share variable\n ''last_run_statue''
|
||||
: False, #last run finish or not\n ''data_statue'' :
|
||||
None, #global_count finish or not\n ''global_count''
|
||||
: None,\n ''scale_statue'' : None,\n ''weight_statue''
|
||||
: None,\n ''average_weights'' : None,\n ''shutdown''
|
||||
: 0}\n\n NUM_OF_CLIENTS = 2 #number of clients\n\n init_lock = threading.Lock()\n clients_local_count_lock
|
||||
= threading.Lock()\n scaled_local_weight_list_lock = threading.Lock()\n cal_weight_lock
|
||||
= threading.Lock()\n shutdown_lock = threading.Lock()\n\n @app.before_request\n def
|
||||
before_request():\n print(''get request'')\n\n @app.route(''/data'',
|
||||
methods=[''POST''])\n def flask_server():\n with init_lock: #check
|
||||
last run is finish and init varible\n\n while True:\n\n if(len(clients_local_count)==0
|
||||
and global_value[''last_run_statue''] == False):#init the variable by first
|
||||
client enter\n global_value[''last_run_statue''] = True\n global_value[''data_statue'']
|
||||
= False\n global_value[''scale_statue''] = False\n global_value[''weight_statue'']
|
||||
= False\n break\n\n elif(global_value[''last_run_statue'']
|
||||
== True):\n break\n time.sleep(3)\n\n local_count
|
||||
= int(request.form.get(''local_count'')) #get data\n bs
|
||||
= int(request.form.get(''bs''))\n local_weight = json.loads(request.form.get(''local_weight''))\n local_weight
|
||||
= [np.array(lst) for lst in local_weight]\n\n def scale_model_weights(weight,
|
||||
scalar):\n weight_final = []\n steps = len(weight)\n for
|
||||
i in range(steps):\n weight_final.append(scalar * weight[i])\n return
|
||||
weight_final\n def sum_scaled_weights(scaled_weight_list):\n\n avg_grad
|
||||
= list()\n #get the average grad accross all client gradients\n for
|
||||
grad_list_tuple in zip(*scaled_weight_list):\n layer_mean
|
||||
= tf.math.reduce_sum(grad_list_tuple, axis=0)\n avg_grad.append(layer_mean)\n\n return
|
||||
avg_grad\n\n with clients_local_count_lock:\n clients_local_count.append(int(local_count))\n\n with
|
||||
scaled_local_weight_list_lock:\n while True:\n\n if
|
||||
(len(clients_local_count) == NUM_OF_CLIENTS and global_value[''data_statue'']
|
||||
!= True):\n global_value[''last_run_statue''] = False\n sum_of_local_count=sum(clients_local_count)\n\n global_value[''global_count'']
|
||||
= sum_of_local_count \n\n scaling_factor=local_count/global_value[''global_count'']\n scaled_weights
|
||||
= scale_model_weights(local_weight, scaling_factor)\n scaled_local_weight_list.append(scaled_weights)\n\n global_value[''scale_statue'']
|
||||
= True \n global_value[''data_statue''] = True\n break\n elif
|
||||
(global_value[''data_statue''] == True and global_value[''scale_statue'']
|
||||
== True):\n scaling_factor=local_count/global_value[''global_count'']\n scaled_weights
|
||||
=scale_model_weights(local_weight, scaling_factor)\n scaled_local_weight_list.append(scaled_weights)\n\n break\n time.sleep(1)\n\n with
|
||||
cal_weight_lock:\n\n while True:\n if(len(scaled_local_weight_list)
|
||||
== NUM_OF_CLIENTS and global_value[''weight_statue''] != True):\n\n global_value[''average_weights'']
|
||||
= sum_scaled_weights(scaled_local_weight_list)\n global_value[''weight_statue'']
|
||||
= True\n global_value[''average_weights''] = json.dumps([np.array(w).tolist()
|
||||
for w in global_value[''average_weights'']])\n\n break\n\n elif(global_value[''weight_statue'']
|
||||
== True):\n\n break\n\n time.sleep(1)\n\n clients_local_count.clear()\n scaled_local_weight_list.clear()\n\n return
|
||||
jsonify({''result'': (global_value[''average_weights''])})\n\n @app.route(''/shutdown'',
|
||||
methods=[''GET''])\n def shutdown_server():\n global_value[''shutdown'']
|
||||
+=1 \n with shutdown_lock:\n while True:\n if(global_value[''shutdown'']
|
||||
== NUM_OF_CLIENTS):\n os._exit(0)\n return
|
||||
''Server shutting down...''\n time.sleep(1)\n\n app.run(host=\"0.0.0.0\",
|
||||
port=8080)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Server'',
|
||||
description='''')\n_parsed_args = vars(_parser.parse_args())\n\n_outputs
|
||||
= server(**_parsed_args)\n"], "image": "tensorflow/tensorflow"}}, "name":
|
||||
"Server"}', pipelines.kubeflow.org/component_ref: '{}'}
|
||||
- name: show-results
|
||||
container:
|
||||
args: [--test-acc, '{{inputs.parameters.client-last_accuracy}}', '----output-paths',
|
||||
/tmp/outputs/test_accuracy/data]
|
||||
command:
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- |
|
||||
def show_results(test_acc):
|
||||
return([test_acc])
|
||||
|
||||
def _serialize_float(float_value: float) -> str:
|
||||
if isinstance(float_value, str):
|
||||
return float_value
|
||||
if not isinstance(float_value, (float, int)):
|
||||
raise TypeError('Value "{}" has type "{}" instead of float.'.format(
|
||||
str(float_value), str(type(float_value))))
|
||||
return str(float_value)
|
||||
|
||||
import argparse
|
||||
_parser = argparse.ArgumentParser(prog='Show results', description='')
|
||||
_parser.add_argument("--test-acc", dest="test_acc", type=float, required=True, default=argparse.SUPPRESS)
|
||||
_parser.add_argument("----output-paths", dest="_output_paths", type=str, nargs=1)
|
||||
_parsed_args = vars(_parser.parse_args())
|
||||
_output_files = _parsed_args.pop("_output_paths", [])
|
||||
|
||||
_outputs = show_results(**_parsed_args)
|
||||
|
||||
_output_serializers = [
|
||||
_serialize_float,
|
||||
|
||||
]
|
||||
|
||||
import os
|
||||
for idx, output_file in enumerate(_output_files):
|
||||
try:
|
||||
os.makedirs(os.path.dirname(output_file))
|
||||
except OSError:
|
||||
pass
|
||||
with open(output_file, 'w') as f:
|
||||
f.write(_output_serializers[idx](_outputs[idx]))
|
||||
image: python:3.7
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
inputs:
|
||||
parameters:
|
||||
- {name: client-last_accuracy}
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: show-results-test_accuracy, path: /tmp/outputs/test_accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--test-acc", {"inputValue": "test_acc"}, "----output-paths",
|
||||
{"outputPath": "test_accuracy"}], "command": ["sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def show_results(test_acc):\n return([test_acc])\n\ndef _serialize_float(float_value:
|
||||
float) -> str:\n if isinstance(float_value, str):\n return float_value\n if
|
||||
not isinstance(float_value, (float, int)):\n raise TypeError(''Value
|
||||
\"{}\" has type \"{}\" instead of float.''.format(\n str(float_value),
|
||||
str(type(float_value))))\n return str(float_value)\n\nimport argparse\n_parser
|
||||
= argparse.ArgumentParser(prog=''Show results'', description='''')\n_parser.add_argument(\"--test-acc\",
|
||||
dest=\"test_acc\", type=float, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = show_results(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "python:3.7"}}, "inputs": [{"name": "test_acc", "type": "Float"}],
|
||||
"name": "Show results", "outputs": [{"name": "test_accuracy", "type": "Float"}]}',
|
||||
pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"test_acc":
|
||||
"{{inputs.parameters.client-last_accuracy}}"}'}
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: namespace, value: kubeflow-user-thu01}
|
||||
serviceAccountName: pipeline-runner
|
||||
|
|
@ -0,0 +1,639 @@
|
|||
apiVersion: argoproj.io/v1alpha1
|
||||
kind: Workflow
|
||||
metadata:
|
||||
generateName: fl-test-
|
||||
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9, pipelines.kubeflow.org/pipeline_compilation_time: '2023-12-13T03:33:40.267552',
|
||||
pipelines.kubeflow.org/pipeline_spec: '{"inputs": [{"default": "kubeflow-user-thu01",
|
||||
"name": "namespace", "optional": true}], "name": "FL test"}'}
|
||||
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9}
|
||||
spec:
|
||||
entrypoint: fl-test
|
||||
templates:
|
||||
- name: client
|
||||
container:
|
||||
args: [--batch, '1', '----output-paths', /tmp/outputs/last_accuracy/data]
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
'requests' 'pandas' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
|
||||
--quiet --no-warn-script-location 'requests' 'pandas' --user) && "$0" "$@"
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def client(batch):\n import json\n import requests\n import time\n\
|
||||
\ import pandas as pd\n import numpy as np\n import tensorflow as\
|
||||
\ tf\n from tensorflow.keras.models import Sequential\n from tensorflow.keras.layers\
|
||||
\ import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n \
|
||||
\ from tensorflow.keras.layers import Activation\n from tensorflow.keras.layers\
|
||||
\ import Flatten\n from tensorflow.keras.layers import Dense\n from\
|
||||
\ tensorflow.keras.optimizers import SGD\n from tensorflow.keras import\
|
||||
\ backend as K\n\n normal_url='https://drive.google.com/u/0/uc?id=1TQHKkP6yzuhcxw_JCtby9jQwY2AMLiNi&export=download'\
|
||||
\ \n abnormal_url='https://drive.google.com/uc?export=download&id=1i22tQI2vib0fsd1wwVP1tEydmGEksmpy'\n\
|
||||
\ normal_data = pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n\
|
||||
\ num_features = len(normal_data.columns)\n print(num_features)\n \
|
||||
\ normal_label = np.array([[1, 0]] * len(normal_data))\n abnormal_label\
|
||||
\ = np.array([[0, 1]] * len(abnormal_data))\n\n data = np.vstack((normal_data,\
|
||||
\ abnormal_data))\n data_label = np.vstack((normal_label, abnormal_label))\n\
|
||||
\n shuffler = np.random.permutation(len(data))\n data = data[shuffler]\n\
|
||||
\ data_label = data_label[shuffler]\n\n data = data.reshape(len(data),\
|
||||
\ num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\
|
||||
\n full_data = list(zip(data, data_label))\n data_length=len(full_data)\n\
|
||||
\n class SimpleMLP:\n @staticmethod\n def build(shape, classes):\n\
|
||||
\ model = Sequential()\n model.add(Conv1D(filters=4,\
|
||||
\ kernel_size=3, input_shape=(17,1)))\n model.add(MaxPooling1D(3))\n\
|
||||
\ model.add(Flatten())\n model.add(Dense(8, activation=\"\
|
||||
relu\"))\n model.add(Dense(2, activation = 'softmax'))\n\n \
|
||||
\ return model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]\
|
||||
\ #batch data\n else:\n full_data=full_data[int(data_length/2):data_length]\
|
||||
\ #The client should have its own data, not like this. It's a lazy method.\n\
|
||||
\n print('data len= ',len(full_data))\n def batch_data(data_shard, bs=32):\n\
|
||||
\n #seperate shard into data and labels lists\n data, label\
|
||||
\ = zip(*data_shard)\n dataset = tf.data.Dataset.from_tensor_slices((list(data),\
|
||||
\ list(label)))\n return dataset.shuffle(len(label)).batch(bs)\n\n\
|
||||
\ dataset=batch_data(full_data)\n #print(dataset)\n\n bs = next(iter(dataset))[0].shape[0]\n\
|
||||
\ local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n\
|
||||
\ loss='categorical_crossentropy'\n metrics = ['accuracy']\n optimizer\
|
||||
\ = 'adam'\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\
|
||||
\n for comm_round in range(1):\n print('The ',comm_round+1, 'round')\n\
|
||||
\ client_model = smlp_model.build(17, 1)\n client_model.compile(loss=loss,\
|
||||
\ \n optimizer=optimizer, \n metrics=metrics)\n\
|
||||
\n if(comm_round == 0):\n history = client_model.fit(dataset,\
|
||||
\ epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n\
|
||||
\ history = client_model.fit(dataset, epochs=5, verbose=1)\n\n\
|
||||
\ local_weight = client_model.get_weights()\n local_weight =\
|
||||
\ [np.array(w).tolist() for w in local_weight]\n\n client_data = {\"\
|
||||
local_count\": local_count,'bs': bs, 'local_weight': json.dumps(local_weight)}\n\
|
||||
\n while True:\n try:\n weight = (requests.post(server_url,data=client_data))\n\
|
||||
\n if weight.status_code == 200:\n print(f\"\
|
||||
exist\")\n\n break\n else:\n \
|
||||
\ print(f\"server error\")\n\n except requests.exceptions.RequestException:\n\
|
||||
\n print(f\"not exist\")\n\n time.sleep(5)\n\n \
|
||||
\ data = weight.json()\n avg_weight = data.get('result')\n \
|
||||
\ avg_weight = json.loads(avg_weight)\n avg_weight = [np.array(lst)\
|
||||
\ for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\"\
|
||||
\ \n try:\n response = requests.get(shutdown_url)\n except\
|
||||
\ requests.exceptions.ConnectionError:\n print('already shutdown')\n\
|
||||
\ last_accuracy = history.history['accuracy'][-1]\n print(last_accuracy)\n\
|
||||
\ return([last_accuracy])\n\ndef _serialize_float(float_value: float) ->\
|
||||
\ str:\n if isinstance(float_value, str):\n return float_value\n\
|
||||
\ if not isinstance(float_value, (float, int)):\n raise TypeError('Value\
|
||||
\ \"{}\" has type \"{}\" instead of float.'.format(\n str(float_value),\
|
||||
\ str(type(float_value))))\n return str(float_value)\n\nimport argparse\n\
|
||||
_parser = argparse.ArgumentParser(prog='Client', description='')\n_parser.add_argument(\"\
|
||||
--batch\", dest=\"batch\", type=int, required=True, default=argparse.SUPPRESS)\n\
|
||||
_parser.add_argument(\"----output-paths\", dest=\"_output_paths\", type=str,\
|
||||
\ nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files = _parsed_args.pop(\"\
|
||||
_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers\
|
||||
\ = [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n\
|
||||
\ try:\n os.makedirs(os.path.dirname(output_file))\n except OSError:\n\
|
||||
\ pass\n with open(output_file, 'w') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"
|
||||
image: tensorflow/tensorflow
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
outputs:
|
||||
parameters:
|
||||
- name: client-last_accuracy
|
||||
valueFrom: {path: /tmp/outputs/last_accuracy/data}
|
||||
artifacts:
|
||||
- {name: client-last_accuracy, path: /tmp/outputs/last_accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--batch", {"inputValue": "batch"}, "----output-paths", {"outputPath":
|
||||
"last_accuracy"}], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1
|
||||
python3 -m pip install --quiet --no-warn-script-location ''requests'' ''pandas''
|
||||
|| PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
''requests'' ''pandas'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def client(batch):\n import json\n import requests\n import time\n import
|
||||
pandas as pd\n import numpy as np\n import tensorflow as tf\n from
|
||||
tensorflow.keras.models import Sequential\n from tensorflow.keras.layers
|
||||
import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n from
|
||||
tensorflow.keras.layers import Activation\n from tensorflow.keras.layers
|
||||
import Flatten\n from tensorflow.keras.layers import Dense\n from
|
||||
tensorflow.keras.optimizers import SGD\n from tensorflow.keras import
|
||||
backend as K\n\n normal_url=''https://drive.google.com/u/0/uc?id=1TQHKkP6yzuhcxw_JCtby9jQwY2AMLiNi&export=download''
|
||||
\n abnormal_url=''https://drive.google.com/uc?export=download&id=1i22tQI2vib0fsd1wwVP1tEydmGEksmpy''\n normal_data
|
||||
= pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n num_features
|
||||
= len(normal_data.columns)\n print(num_features)\n normal_label =
|
||||
np.array([[1, 0]] * len(normal_data))\n abnormal_label = np.array([[0,
|
||||
1]] * len(abnormal_data))\n\n data = np.vstack((normal_data, abnormal_data))\n data_label
|
||||
= np.vstack((normal_label, abnormal_label))\n\n shuffler = np.random.permutation(len(data))\n data
|
||||
= data[shuffler]\n data_label = data_label[shuffler]\n\n data = data.reshape(len(data),
|
||||
num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\n full_data
|
||||
= list(zip(data, data_label))\n data_length=len(full_data)\n\n class
|
||||
SimpleMLP:\n @staticmethod\n def build(shape, classes):\n model
|
||||
= Sequential()\n model.add(Conv1D(filters=4, kernel_size=3, input_shape=(17,1)))\n model.add(MaxPooling1D(3))\n model.add(Flatten())\n model.add(Dense(8,
|
||||
activation=\"relu\"))\n model.add(Dense(2, activation = ''softmax''))\n\n return
|
||||
model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]
|
||||
#batch data\n else:\n full_data=full_data[int(data_length/2):data_length]
|
||||
#The client should have its own data, not like this. It''s a lazy method.\n\n print(''data
|
||||
len= '',len(full_data))\n def batch_data(data_shard, bs=32):\n\n #seperate
|
||||
shard into data and labels lists\n data, label = zip(*data_shard)\n dataset
|
||||
= tf.data.Dataset.from_tensor_slices((list(data), list(label)))\n return
|
||||
dataset.shuffle(len(label)).batch(bs)\n\n dataset=batch_data(full_data)\n #print(dataset)\n\n bs
|
||||
= next(iter(dataset))[0].shape[0]\n local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n loss=''categorical_crossentropy''\n metrics
|
||||
= [''accuracy'']\n optimizer = ''adam''\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\n for
|
||||
comm_round in range(1):\n print(''The '',comm_round+1, ''round'')\n client_model
|
||||
= smlp_model.build(17, 1)\n client_model.compile(loss=loss, \n optimizer=optimizer,
|
||||
\n metrics=metrics)\n\n if(comm_round == 0):\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n\n local_weight
|
||||
= client_model.get_weights()\n local_weight = [np.array(w).tolist()
|
||||
for w in local_weight]\n\n client_data = {\"local_count\": local_count,''bs'':
|
||||
bs, ''local_weight'': json.dumps(local_weight)}\n\n while True:\n try:\n weight
|
||||
= (requests.post(server_url,data=client_data))\n\n if weight.status_code
|
||||
== 200:\n print(f\"exist\")\n\n break\n else:\n print(f\"server
|
||||
error\")\n\n except requests.exceptions.RequestException:\n\n print(f\"not
|
||||
exist\")\n\n time.sleep(5)\n\n data = weight.json()\n avg_weight
|
||||
= data.get(''result'')\n avg_weight = json.loads(avg_weight)\n avg_weight
|
||||
= [np.array(lst) for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\" \n try:\n response
|
||||
= requests.get(shutdown_url)\n except requests.exceptions.ConnectionError:\n print(''already
|
||||
shutdown'')\n last_accuracy = history.history[''accuracy''][-1]\n print(last_accuracy)\n return([last_accuracy])\n\ndef
|
||||
_serialize_float(float_value: float) -> str:\n if isinstance(float_value,
|
||||
str):\n return float_value\n if not isinstance(float_value, (float,
|
||||
int)):\n raise TypeError(''Value \"{}\" has type \"{}\" instead of
|
||||
float.''.format(\n str(float_value), str(type(float_value))))\n return
|
||||
str(float_value)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Client'',
|
||||
description='''')\n_parser.add_argument(\"--batch\", dest=\"batch\", type=int,
|
||||
required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "tensorflow/tensorflow"}}, "inputs": [{"name": "batch", "type":
|
||||
"Integer"}], "name": "Client", "outputs": [{"name": "last_accuracy", "type":
|
||||
"Float"}]}', pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"batch":
|
||||
"1"}'}
|
||||
- name: client-2
|
||||
container:
|
||||
args: [--batch, '2', '----output-paths', /tmp/outputs/last_accuracy/data]
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
'requests' 'pandas' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
|
||||
--quiet --no-warn-script-location 'requests' 'pandas' --user) && "$0" "$@"
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def client(batch):\n import json\n import requests\n import time\n\
|
||||
\ import pandas as pd\n import numpy as np\n import tensorflow as\
|
||||
\ tf\n from tensorflow.keras.models import Sequential\n from tensorflow.keras.layers\
|
||||
\ import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n \
|
||||
\ from tensorflow.keras.layers import Activation\n from tensorflow.keras.layers\
|
||||
\ import Flatten\n from tensorflow.keras.layers import Dense\n from\
|
||||
\ tensorflow.keras.optimizers import SGD\n from tensorflow.keras import\
|
||||
\ backend as K\n\n normal_url='https://drive.google.com/u/0/uc?id=1TQHKkP6yzuhcxw_JCtby9jQwY2AMLiNi&export=download'\
|
||||
\ \n abnormal_url='https://drive.google.com/uc?export=download&id=1i22tQI2vib0fsd1wwVP1tEydmGEksmpy'\n\
|
||||
\ normal_data = pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n\
|
||||
\ num_features = len(normal_data.columns)\n print(num_features)\n \
|
||||
\ normal_label = np.array([[1, 0]] * len(normal_data))\n abnormal_label\
|
||||
\ = np.array([[0, 1]] * len(abnormal_data))\n\n data = np.vstack((normal_data,\
|
||||
\ abnormal_data))\n data_label = np.vstack((normal_label, abnormal_label))\n\
|
||||
\n shuffler = np.random.permutation(len(data))\n data = data[shuffler]\n\
|
||||
\ data_label = data_label[shuffler]\n\n data = data.reshape(len(data),\
|
||||
\ num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\
|
||||
\n full_data = list(zip(data, data_label))\n data_length=len(full_data)\n\
|
||||
\n class SimpleMLP:\n @staticmethod\n def build(shape, classes):\n\
|
||||
\ model = Sequential()\n model.add(Conv1D(filters=4,\
|
||||
\ kernel_size=3, input_shape=(17,1)))\n model.add(MaxPooling1D(3))\n\
|
||||
\ model.add(Flatten())\n model.add(Dense(8, activation=\"\
|
||||
relu\"))\n model.add(Dense(2, activation = 'softmax'))\n\n \
|
||||
\ return model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]\
|
||||
\ #batch data\n else:\n full_data=full_data[int(data_length/2):data_length]\
|
||||
\ #The client should have its own data, not like this. It's a lazy method.\n\
|
||||
\n print('data len= ',len(full_data))\n def batch_data(data_shard, bs=32):\n\
|
||||
\n #seperate shard into data and labels lists\n data, label\
|
||||
\ = zip(*data_shard)\n dataset = tf.data.Dataset.from_tensor_slices((list(data),\
|
||||
\ list(label)))\n return dataset.shuffle(len(label)).batch(bs)\n\n\
|
||||
\ dataset=batch_data(full_data)\n #print(dataset)\n\n bs = next(iter(dataset))[0].shape[0]\n\
|
||||
\ local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n\
|
||||
\ loss='categorical_crossentropy'\n metrics = ['accuracy']\n optimizer\
|
||||
\ = 'adam'\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\
|
||||
\n for comm_round in range(1):\n print('The ',comm_round+1, 'round')\n\
|
||||
\ client_model = smlp_model.build(17, 1)\n client_model.compile(loss=loss,\
|
||||
\ \n optimizer=optimizer, \n metrics=metrics)\n\
|
||||
\n if(comm_round == 0):\n history = client_model.fit(dataset,\
|
||||
\ epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n\
|
||||
\ history = client_model.fit(dataset, epochs=5, verbose=1)\n\n\
|
||||
\ local_weight = client_model.get_weights()\n local_weight =\
|
||||
\ [np.array(w).tolist() for w in local_weight]\n\n client_data = {\"\
|
||||
local_count\": local_count,'bs': bs, 'local_weight': json.dumps(local_weight)}\n\
|
||||
\n while True:\n try:\n weight = (requests.post(server_url,data=client_data))\n\
|
||||
\n if weight.status_code == 200:\n print(f\"\
|
||||
exist\")\n\n break\n else:\n \
|
||||
\ print(f\"server error\")\n\n except requests.exceptions.RequestException:\n\
|
||||
\n print(f\"not exist\")\n\n time.sleep(5)\n\n \
|
||||
\ data = weight.json()\n avg_weight = data.get('result')\n \
|
||||
\ avg_weight = json.loads(avg_weight)\n avg_weight = [np.array(lst)\
|
||||
\ for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\"\
|
||||
\ \n try:\n response = requests.get(shutdown_url)\n except\
|
||||
\ requests.exceptions.ConnectionError:\n print('already shutdown')\n\
|
||||
\ last_accuracy = history.history['accuracy'][-1]\n print(last_accuracy)\n\
|
||||
\ return([last_accuracy])\n\ndef _serialize_float(float_value: float) ->\
|
||||
\ str:\n if isinstance(float_value, str):\n return float_value\n\
|
||||
\ if not isinstance(float_value, (float, int)):\n raise TypeError('Value\
|
||||
\ \"{}\" has type \"{}\" instead of float.'.format(\n str(float_value),\
|
||||
\ str(type(float_value))))\n return str(float_value)\n\nimport argparse\n\
|
||||
_parser = argparse.ArgumentParser(prog='Client', description='')\n_parser.add_argument(\"\
|
||||
--batch\", dest=\"batch\", type=int, required=True, default=argparse.SUPPRESS)\n\
|
||||
_parser.add_argument(\"----output-paths\", dest=\"_output_paths\", type=str,\
|
||||
\ nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files = _parsed_args.pop(\"\
|
||||
_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers\
|
||||
\ = [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n\
|
||||
\ try:\n os.makedirs(os.path.dirname(output_file))\n except OSError:\n\
|
||||
\ pass\n with open(output_file, 'w') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"
|
||||
image: tensorflow/tensorflow
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: client-2-last_accuracy, path: /tmp/outputs/last_accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--batch", {"inputValue": "batch"}, "----output-paths", {"outputPath":
|
||||
"last_accuracy"}], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1
|
||||
python3 -m pip install --quiet --no-warn-script-location ''requests'' ''pandas''
|
||||
|| PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
''requests'' ''pandas'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def client(batch):\n import json\n import requests\n import time\n import
|
||||
pandas as pd\n import numpy as np\n import tensorflow as tf\n from
|
||||
tensorflow.keras.models import Sequential\n from tensorflow.keras.layers
|
||||
import Conv1D\n from tensorflow.keras.layers import MaxPooling1D\n from
|
||||
tensorflow.keras.layers import Activation\n from tensorflow.keras.layers
|
||||
import Flatten\n from tensorflow.keras.layers import Dense\n from
|
||||
tensorflow.keras.optimizers import SGD\n from tensorflow.keras import
|
||||
backend as K\n\n normal_url=''https://drive.google.com/u/0/uc?id=1TQHKkP6yzuhcxw_JCtby9jQwY2AMLiNi&export=download''
|
||||
\n abnormal_url=''https://drive.google.com/uc?export=download&id=1i22tQI2vib0fsd1wwVP1tEydmGEksmpy''\n normal_data
|
||||
= pd.read_csv(normal_url)\n abnormal_data = pd.read_csv(abnormal_url)\n num_features
|
||||
= len(normal_data.columns)\n print(num_features)\n normal_label =
|
||||
np.array([[1, 0]] * len(normal_data))\n abnormal_label = np.array([[0,
|
||||
1]] * len(abnormal_data))\n\n data = np.vstack((normal_data, abnormal_data))\n data_label
|
||||
= np.vstack((normal_label, abnormal_label))\n\n shuffler = np.random.permutation(len(data))\n data
|
||||
= data[shuffler]\n data_label = data_label[shuffler]\n\n data = data.reshape(len(data),
|
||||
num_features, 1)\n data_label = data_label.reshape(len(data_label), 2)\n\n full_data
|
||||
= list(zip(data, data_label))\n data_length=len(full_data)\n\n class
|
||||
SimpleMLP:\n @staticmethod\n def build(shape, classes):\n model
|
||||
= Sequential()\n model.add(Conv1D(filters=4, kernel_size=3, input_shape=(17,1)))\n model.add(MaxPooling1D(3))\n model.add(Flatten())\n model.add(Dense(8,
|
||||
activation=\"relu\"))\n model.add(Dense(2, activation = ''softmax''))\n\n return
|
||||
model\n\n if(batch==1):\n full_data=full_data[0:int(data_length/2)]
|
||||
#batch data\n else:\n full_data=full_data[int(data_length/2):data_length]
|
||||
#The client should have its own data, not like this. It''s a lazy method.\n\n print(''data
|
||||
len= '',len(full_data))\n def batch_data(data_shard, bs=32):\n\n #seperate
|
||||
shard into data and labels lists\n data, label = zip(*data_shard)\n dataset
|
||||
= tf.data.Dataset.from_tensor_slices((list(data), list(label)))\n return
|
||||
dataset.shuffle(len(label)).batch(bs)\n\n dataset=batch_data(full_data)\n #print(dataset)\n\n bs
|
||||
= next(iter(dataset))[0].shape[0]\n local_count = tf.data.experimental.cardinality(dataset).numpy()*bs\n\n loss=''categorical_crossentropy''\n metrics
|
||||
= [''accuracy'']\n optimizer = ''adam''\n\n smlp_model = SimpleMLP()\n\n server_url=\"http://http-service:5000/data\"\n for
|
||||
comm_round in range(1):\n print(''The '',comm_round+1, ''round'')\n client_model
|
||||
= smlp_model.build(17, 1)\n client_model.compile(loss=loss, \n optimizer=optimizer,
|
||||
\n metrics=metrics)\n\n if(comm_round == 0):\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n else:\n client_model.set_weights(avg_weight)\n history
|
||||
= client_model.fit(dataset, epochs=5, verbose=1)\n\n local_weight
|
||||
= client_model.get_weights()\n local_weight = [np.array(w).tolist()
|
||||
for w in local_weight]\n\n client_data = {\"local_count\": local_count,''bs'':
|
||||
bs, ''local_weight'': json.dumps(local_weight)}\n\n while True:\n try:\n weight
|
||||
= (requests.post(server_url,data=client_data))\n\n if weight.status_code
|
||||
== 200:\n print(f\"exist\")\n\n break\n else:\n print(f\"server
|
||||
error\")\n\n except requests.exceptions.RequestException:\n\n print(f\"not
|
||||
exist\")\n\n time.sleep(5)\n\n data = weight.json()\n avg_weight
|
||||
= data.get(''result'')\n avg_weight = json.loads(avg_weight)\n avg_weight
|
||||
= [np.array(lst) for lst in avg_weight]\n\n shutdown_url=\"http://http-service:5000/shutdown\" \n try:\n response
|
||||
= requests.get(shutdown_url)\n except requests.exceptions.ConnectionError:\n print(''already
|
||||
shutdown'')\n last_accuracy = history.history[''accuracy''][-1]\n print(last_accuracy)\n return([last_accuracy])\n\ndef
|
||||
_serialize_float(float_value: float) -> str:\n if isinstance(float_value,
|
||||
str):\n return float_value\n if not isinstance(float_value, (float,
|
||||
int)):\n raise TypeError(''Value \"{}\" has type \"{}\" instead of
|
||||
float.''.format(\n str(float_value), str(type(float_value))))\n return
|
||||
str(float_value)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Client'',
|
||||
description='''')\n_parser.add_argument(\"--batch\", dest=\"batch\", type=int,
|
||||
required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = client(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "tensorflow/tensorflow"}}, "inputs": [{"name": "batch", "type":
|
||||
"Integer"}], "name": "Client", "outputs": [{"name": "last_accuracy", "type":
|
||||
"Float"}]}', pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"batch":
|
||||
"2"}'}
|
||||
- name: delete-service
|
||||
resource:
|
||||
action: delete
|
||||
flags: [--wait=false]
|
||||
manifest: |
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: http-service
|
||||
spec:
|
||||
ports:
|
||||
- port: 80
|
||||
protocol: TCP
|
||||
targetPort: 8080
|
||||
selector:
|
||||
app: http-service
|
||||
type: NodePort
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
- name: fl-test
|
||||
dag:
|
||||
tasks:
|
||||
- {name: client, template: client}
|
||||
- {name: client-2, template: client-2}
|
||||
- name: delete-service
|
||||
template: delete-service
|
||||
dependencies: [server]
|
||||
- {name: http-service, template: http-service}
|
||||
- name: server
|
||||
template: server
|
||||
dependencies: [http-service]
|
||||
- name: show-results
|
||||
template: show-results
|
||||
dependencies: [client]
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: client-last_accuracy, value: '{{tasks.client.outputs.parameters.client-last_accuracy}}'}
|
||||
- name: http-service
|
||||
resource:
|
||||
action: create
|
||||
manifest: |
|
||||
apiVersion: v1
|
||||
kind: Service
|
||||
metadata:
|
||||
name: http-service
|
||||
spec:
|
||||
ports:
|
||||
- port: 5000
|
||||
protocol: TCP
|
||||
targetPort: 8080
|
||||
selector:
|
||||
app: http-service
|
||||
outputs:
|
||||
parameters:
|
||||
- name: http-service-manifest
|
||||
valueFrom: {jsonPath: '{}'}
|
||||
- name: http-service-name
|
||||
valueFrom: {jsonPath: '{.metadata.name}'}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
- name: server
|
||||
container:
|
||||
args: []
|
||||
command:
|
||||
- sh
|
||||
- -c
|
||||
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
'flask' 'pandas' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
|
||||
--quiet --no-warn-script-location 'flask' 'pandas' --user) && "$0" "$@"
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def server():\n import json\n import pandas as pd\n import numpy\
|
||||
\ as np\n import pickle\n import threading\n import time\n import\
|
||||
\ tensorflow as tf\n from flask import Flask, jsonify,request\n import\
|
||||
\ os\n\n app = Flask(__name__)\n clients_local_count = []\n scaled_local_weight_list\
|
||||
\ = []\n global_value = { #Share variable\n 'last_run_statue'\
|
||||
\ : False, #last run finish or not\n 'data_statue' : None,\
|
||||
\ #global_count finish or not\n 'global_count' : None,\n\
|
||||
\ 'scale_statue' : None,\n 'weight_statue'\
|
||||
\ : None,\n 'average_weights' : None,\n \
|
||||
\ 'shutdown' : 0}\n\n NUM_OF_CLIENTS = 2 #number of clients\n\n \
|
||||
\ init_lock = threading.Lock()\n clients_local_count_lock = threading.Lock()\n\
|
||||
\ scaled_local_weight_list_lock = threading.Lock()\n cal_weight_lock\
|
||||
\ = threading.Lock()\n shutdown_lock = threading.Lock()\n\n @app.before_request\n\
|
||||
\ def before_request():\n print('get request')\n\n @app.route('/data',\
|
||||
\ methods=['POST'])\n def flask_server():\n with init_lock: #check\
|
||||
\ last run is finish and init varible\n\n while True:\n\n \
|
||||
\ if(len(clients_local_count)==0 and global_value['last_run_statue']\
|
||||
\ == False):#init the variable by first client enter\n \
|
||||
\ global_value['last_run_statue'] = True\n global_value['data_statue']\
|
||||
\ = False\n global_value['scale_statue'] = False\n \
|
||||
\ global_value['weight_statue'] = False\n \
|
||||
\ break\n\n elif(global_value['last_run_statue'] == True):\n\
|
||||
\ break\n time.sleep(3)\n\n local_count\
|
||||
\ = int(request.form.get('local_count')) #get data\n bs =\
|
||||
\ int(request.form.get('bs'))\n local_weight = json.loads(request.form.get('local_weight'))\n\
|
||||
\ local_weight = [np.array(lst) for lst in local_weight]\n\n \
|
||||
\ def scale_model_weights(weight, scalar):\n weight_final = []\n\
|
||||
\ steps = len(weight)\n for i in range(steps):\n \
|
||||
\ weight_final.append(scalar * weight[i])\n return\
|
||||
\ weight_final\n def sum_scaled_weights(scaled_weight_list):\n\n \
|
||||
\ avg_grad = list()\n #get the average grad accross all\
|
||||
\ client gradients\n for grad_list_tuple in zip(*scaled_weight_list):\n\
|
||||
\ layer_mean = tf.math.reduce_sum(grad_list_tuple, axis=0)\n\
|
||||
\ avg_grad.append(layer_mean)\n\n return avg_grad\n\
|
||||
\n with clients_local_count_lock:\n clients_local_count.append(int(local_count))\n\
|
||||
\n with scaled_local_weight_list_lock:\n while True:\n\n\
|
||||
\ if (len(clients_local_count) == NUM_OF_CLIENTS and global_value['data_statue']\
|
||||
\ != True):\n global_value['last_run_statue'] = False\n\
|
||||
\ sum_of_local_count=sum(clients_local_count)\n\n \
|
||||
\ global_value['global_count'] = sum_of_local_count \n\n\
|
||||
\ scaling_factor=local_count/global_value['global_count']\n\
|
||||
\ scaled_weights = scale_model_weights(local_weight, scaling_factor)\n\
|
||||
\ scaled_local_weight_list.append(scaled_weights)\n\n \
|
||||
\ global_value['scale_statue'] = True \n \
|
||||
\ global_value['data_statue'] = True\n break\n \
|
||||
\ elif (global_value['data_statue'] == True and global_value['scale_statue']\
|
||||
\ == True):\n scaling_factor=local_count/global_value['global_count']\n\
|
||||
\ scaled_weights =scale_model_weights(local_weight, scaling_factor)\n\
|
||||
\ scaled_local_weight_list.append(scaled_weights)\n\n \
|
||||
\ break\n time.sleep(1)\n\n with cal_weight_lock:\n\
|
||||
\n while True:\n if(len(scaled_local_weight_list)\
|
||||
\ == NUM_OF_CLIENTS and global_value['weight_statue'] != True):\n\n \
|
||||
\ global_value['average_weights'] = sum_scaled_weights(scaled_local_weight_list)\n\
|
||||
\ global_value['weight_statue'] = True\n \
|
||||
\ global_value['average_weights'] = json.dumps([np.array(w).tolist()\
|
||||
\ for w in global_value['average_weights']])\n\n break\n\
|
||||
\n elif(global_value['weight_statue'] == True):\n\n \
|
||||
\ break\n\n time.sleep(1)\n\n clients_local_count.clear()\n\
|
||||
\ scaled_local_weight_list.clear()\n\n return jsonify({'result':\
|
||||
\ (global_value['average_weights'])})\n\n @app.route('/shutdown', methods=['GET'])\n\
|
||||
\ def shutdown_server():\n global_value['shutdown'] +=1 \n \
|
||||
\ with shutdown_lock:\n while True:\n if(global_value['shutdown']\
|
||||
\ == NUM_OF_CLIENTS):\n os._exit(0)\n \
|
||||
\ return 'Server shutting down...'\n time.sleep(1)\n\n \
|
||||
\ app.run(host=\"0.0.0.0\", port=8080)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog='Server',\
|
||||
\ description='')\n_parsed_args = vars(_parser.parse_args())\n\n_outputs =\
|
||||
\ server(**_parsed_args)\n"
|
||||
image: tensorflow/tensorflow
|
||||
ports:
|
||||
- {containerPort: 8080, name: my-port}
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
metadata:
|
||||
labels:
|
||||
app: http-service
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": [], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1 python3
|
||||
-m pip install --quiet --no-warn-script-location ''flask'' ''pandas'' ||
|
||||
PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
|
||||
''flask'' ''pandas'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def server():\n import json\n import pandas as pd\n import numpy
|
||||
as np\n import pickle\n import threading\n import time\n import
|
||||
tensorflow as tf\n from flask import Flask, jsonify,request\n import
|
||||
os\n\n app = Flask(__name__)\n clients_local_count = []\n scaled_local_weight_list
|
||||
= []\n global_value = { #Share variable\n ''last_run_statue''
|
||||
: False, #last run finish or not\n ''data_statue'' :
|
||||
None, #global_count finish or not\n ''global_count''
|
||||
: None,\n ''scale_statue'' : None,\n ''weight_statue''
|
||||
: None,\n ''average_weights'' : None,\n ''shutdown''
|
||||
: 0}\n\n NUM_OF_CLIENTS = 2 #number of clients\n\n init_lock = threading.Lock()\n clients_local_count_lock
|
||||
= threading.Lock()\n scaled_local_weight_list_lock = threading.Lock()\n cal_weight_lock
|
||||
= threading.Lock()\n shutdown_lock = threading.Lock()\n\n @app.before_request\n def
|
||||
before_request():\n print(''get request'')\n\n @app.route(''/data'',
|
||||
methods=[''POST''])\n def flask_server():\n with init_lock: #check
|
||||
last run is finish and init varible\n\n while True:\n\n if(len(clients_local_count)==0
|
||||
and global_value[''last_run_statue''] == False):#init the variable by first
|
||||
client enter\n global_value[''last_run_statue''] = True\n global_value[''data_statue'']
|
||||
= False\n global_value[''scale_statue''] = False\n global_value[''weight_statue'']
|
||||
= False\n break\n\n elif(global_value[''last_run_statue'']
|
||||
== True):\n break\n time.sleep(3)\n\n local_count
|
||||
= int(request.form.get(''local_count'')) #get data\n bs
|
||||
= int(request.form.get(''bs''))\n local_weight = json.loads(request.form.get(''local_weight''))\n local_weight
|
||||
= [np.array(lst) for lst in local_weight]\n\n def scale_model_weights(weight,
|
||||
scalar):\n weight_final = []\n steps = len(weight)\n for
|
||||
i in range(steps):\n weight_final.append(scalar * weight[i])\n return
|
||||
weight_final\n def sum_scaled_weights(scaled_weight_list):\n\n avg_grad
|
||||
= list()\n #get the average grad accross all client gradients\n for
|
||||
grad_list_tuple in zip(*scaled_weight_list):\n layer_mean
|
||||
= tf.math.reduce_sum(grad_list_tuple, axis=0)\n avg_grad.append(layer_mean)\n\n return
|
||||
avg_grad\n\n with clients_local_count_lock:\n clients_local_count.append(int(local_count))\n\n with
|
||||
scaled_local_weight_list_lock:\n while True:\n\n if
|
||||
(len(clients_local_count) == NUM_OF_CLIENTS and global_value[''data_statue'']
|
||||
!= True):\n global_value[''last_run_statue''] = False\n sum_of_local_count=sum(clients_local_count)\n\n global_value[''global_count'']
|
||||
= sum_of_local_count \n\n scaling_factor=local_count/global_value[''global_count'']\n scaled_weights
|
||||
= scale_model_weights(local_weight, scaling_factor)\n scaled_local_weight_list.append(scaled_weights)\n\n global_value[''scale_statue'']
|
||||
= True \n global_value[''data_statue''] = True\n break\n elif
|
||||
(global_value[''data_statue''] == True and global_value[''scale_statue'']
|
||||
== True):\n scaling_factor=local_count/global_value[''global_count'']\n scaled_weights
|
||||
=scale_model_weights(local_weight, scaling_factor)\n scaled_local_weight_list.append(scaled_weights)\n\n break\n time.sleep(1)\n\n with
|
||||
cal_weight_lock:\n\n while True:\n if(len(scaled_local_weight_list)
|
||||
== NUM_OF_CLIENTS and global_value[''weight_statue''] != True):\n\n global_value[''average_weights'']
|
||||
= sum_scaled_weights(scaled_local_weight_list)\n global_value[''weight_statue'']
|
||||
= True\n global_value[''average_weights''] = json.dumps([np.array(w).tolist()
|
||||
for w in global_value[''average_weights'']])\n\n break\n\n elif(global_value[''weight_statue'']
|
||||
== True):\n\n break\n\n time.sleep(1)\n\n clients_local_count.clear()\n scaled_local_weight_list.clear()\n\n return
|
||||
jsonify({''result'': (global_value[''average_weights''])})\n\n @app.route(''/shutdown'',
|
||||
methods=[''GET''])\n def shutdown_server():\n global_value[''shutdown'']
|
||||
+=1 \n with shutdown_lock:\n while True:\n if(global_value[''shutdown'']
|
||||
== NUM_OF_CLIENTS):\n os._exit(0)\n return
|
||||
''Server shutting down...''\n time.sleep(1)\n\n app.run(host=\"0.0.0.0\",
|
||||
port=8080)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Server'',
|
||||
description='''')\n_parsed_args = vars(_parser.parse_args())\n\n_outputs
|
||||
= server(**_parsed_args)\n"], "image": "tensorflow/tensorflow"}}, "name":
|
||||
"Server"}', pipelines.kubeflow.org/component_ref: '{}'}
|
||||
- name: show-results
|
||||
container:
|
||||
args: [--test-acc, '{{inputs.parameters.client-last_accuracy}}', '----output-paths',
|
||||
/tmp/outputs/test_accuracy/data]
|
||||
command:
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- |
|
||||
def show_results(test_acc):
|
||||
return([test_acc])
|
||||
|
||||
def _serialize_float(float_value: float) -> str:
|
||||
if isinstance(float_value, str):
|
||||
return float_value
|
||||
if not isinstance(float_value, (float, int)):
|
||||
raise TypeError('Value "{}" has type "{}" instead of float.'.format(
|
||||
str(float_value), str(type(float_value))))
|
||||
return str(float_value)
|
||||
|
||||
import argparse
|
||||
_parser = argparse.ArgumentParser(prog='Show results', description='')
|
||||
_parser.add_argument("--test-acc", dest="test_acc", type=float, required=True, default=argparse.SUPPRESS)
|
||||
_parser.add_argument("----output-paths", dest="_output_paths", type=str, nargs=1)
|
||||
_parsed_args = vars(_parser.parse_args())
|
||||
_output_files = _parsed_args.pop("_output_paths", [])
|
||||
|
||||
_outputs = show_results(**_parsed_args)
|
||||
|
||||
_output_serializers = [
|
||||
_serialize_float,
|
||||
|
||||
]
|
||||
|
||||
import os
|
||||
for idx, output_file in enumerate(_output_files):
|
||||
try:
|
||||
os.makedirs(os.path.dirname(output_file))
|
||||
except OSError:
|
||||
pass
|
||||
with open(output_file, 'w') as f:
|
||||
f.write(_output_serializers[idx](_outputs[idx]))
|
||||
image: python:3.7
|
||||
resources:
|
||||
limits: {cpu: '0.2'}
|
||||
requests: {cpu: '0.2'}
|
||||
inputs:
|
||||
parameters:
|
||||
- {name: client-last_accuracy}
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: show-results-test_accuracy, path: /tmp/outputs/test_accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--test-acc", {"inputValue": "test_acc"}, "----output-paths",
|
||||
{"outputPath": "test_accuracy"}], "command": ["sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def show_results(test_acc):\n return([test_acc])\n\ndef _serialize_float(float_value:
|
||||
float) -> str:\n if isinstance(float_value, str):\n return float_value\n if
|
||||
not isinstance(float_value, (float, int)):\n raise TypeError(''Value
|
||||
\"{}\" has type \"{}\" instead of float.''.format(\n str(float_value),
|
||||
str(type(float_value))))\n return str(float_value)\n\nimport argparse\n_parser
|
||||
= argparse.ArgumentParser(prog=''Show results'', description='''')\n_parser.add_argument(\"--test-acc\",
|
||||
dest=\"test_acc\", type=float, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = show_results(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_float,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "python:3.7"}}, "inputs": [{"name": "test_acc", "type": "Float"}],
|
||||
"name": "Show results", "outputs": [{"name": "test_accuracy", "type": "Float"}]}',
|
||||
pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"test_acc":
|
||||
"{{inputs.parameters.client-last_accuracy}}"}'}
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: namespace, value: kubeflow-user-thu01}
|
||||
serviceAccountName: pipeline-runner
|
||||
|
|
@ -0,0 +1,211 @@
|
|||
apiVersion: argoproj.io/v1alpha1
|
||||
kind: Workflow
|
||||
metadata:
|
||||
generateName: mnist-pipeline-
|
||||
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9, pipelines.kubeflow.org/pipeline_compilation_time: '2023-12-26T13:06:02.352865',
|
||||
pipelines.kubeflow.org/pipeline_spec: '{"description": "A pipeline to train a
|
||||
model on mnist dataset and start a tensorboard.", "name": "mnist pipeline"}'}
|
||||
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9}
|
||||
spec:
|
||||
entrypoint: mnist-pipeline
|
||||
templates:
|
||||
- name: create-tensorboard-visualization
|
||||
container:
|
||||
args: []
|
||||
command:
|
||||
- sh
|
||||
- -ex
|
||||
- -c
|
||||
- |
|
||||
log_dir="$0"
|
||||
output_metadata_path="$1"
|
||||
pod_template_spec="$2"
|
||||
image="$3"
|
||||
|
||||
mkdir -p "$(dirname "$output_metadata_path")"
|
||||
|
||||
echo '
|
||||
{
|
||||
"outputs" : [{
|
||||
"type": "tensorboard",
|
||||
"source": "'"$log_dir"'",
|
||||
"image": "'"$image"'",
|
||||
"pod_template_spec": '"$pod_template_spec"'
|
||||
}]
|
||||
}
|
||||
' >"$output_metadata_path"
|
||||
- volume://mypvc/logs
|
||||
- /tmp/outputs/mlpipeline-ui-metadata/data
|
||||
- '{"spec": {"containers": [{"volumeMounts": [{"mountPath": "/data", "name":
|
||||
"mypvc"}], "resources": {"requests": {"cpu": "250m"}, "limits": {"cpu": "500m"}}}],
|
||||
"serviceAccountName": "default-editor", "volumes": [{"name": "mypvc", "persistentVolumeClaim":
|
||||
{"claimName": "my-awesome-kf-workshop-1703595962"}}]}}'
|
||||
- footprintai/tensorboard:2.7.0
|
||||
image: alpine
|
||||
resources:
|
||||
limits: {cpu: '1'}
|
||||
requests: {cpu: '1'}
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: mlpipeline-ui-metadata, path: /tmp/outputs/mlpipeline-ui-metadata/data}
|
||||
metadata:
|
||||
annotations: {author: Alexey Volkov <alexey.volkov@ark-kun.com>, canonical_location: 'https://raw.githubusercontent.com/Ark-kun/pipeline_components/master/components/tensorflow/tensorboard/prepare_tensorboard/component.yaml',
|
||||
pipelines.kubeflow.org/component_spec: '{"description": "Pre-creates Tensorboard
|
||||
visualization for a given Log dir URI.\nThis way the Tensorboard can be
|
||||
viewed before the training completes.\nThe output Log dir URI should be
|
||||
passed to a trainer component that will write Tensorboard logs to that directory.\n",
|
||||
"implementation": {"container": {"command": ["sh", "-ex", "-c", "log_dir=\"$0\"\noutput_metadata_path=\"$1\"\npod_template_spec=\"$2\"\nimage=\"$3\"\n\nmkdir
|
||||
-p \"$(dirname \"$output_metadata_path\")\"\n\necho ''\n {\n \"outputs\"
|
||||
: [{\n \"type\": \"tensorboard\",\n \"source\": \"''\"$log_dir\"''\",\n \"image\":
|
||||
\"''\"$image\"''\",\n \"pod_template_spec\": ''\"$pod_template_spec\"''\n }]\n }\n''
|
||||
>\"$output_metadata_path\"\n", {"inputValue": "Log dir URI"}, {"outputPath":
|
||||
"mlpipeline-ui-metadata"}, {"inputValue": "Pod Template Spec"}, {"inputValue":
|
||||
"Image"}], "image": "alpine"}}, "inputs": [{"name": "Log dir URI", "type":
|
||||
"String"}, {"default": "", "name": "Image", "type": "String"}, {"default":
|
||||
"null", "name": "Pod Template Spec", "type": "String"}], "metadata": {"annotations":
|
||||
{"author": "Alexey Volkov <alexey.volkov@ark-kun.com>", "canonical_location":
|
||||
"https://raw.githubusercontent.com/Ark-kun/pipeline_components/master/components/tensorflow/tensorboard/prepare_tensorboard/component.yaml"}},
|
||||
"name": "Create Tensorboard visualization", "outputs": [{"name": "mlpipeline-ui-metadata",
|
||||
"type": "kfp.v1.ui-metadata"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
|
||||
"cc3c37c54619129e4f57e4564bc5df0ba9719a305e6145238f2ae7e54d87f2ef", "url":
|
||||
"https://raw.githubusercontent.com/kubeflow/pipelines/1b107eb4bb2510ecb99fd5f4fb438cbf7c96a87a/components/contrib/tensorflow/tensorboard/prepare_tensorboard/component.yaml"}',
|
||||
pipelines.kubeflow.org/arguments.parameters: '{"Image": "footprintai/tensorboard:2.7.0",
|
||||
"Log dir URI": "volume://mypvc/logs", "Pod Template Spec": "{\"spec\": {\"containers\":
|
||||
[{\"volumeMounts\": [{\"mountPath\": \"/data\", \"name\": \"mypvc\"}], \"resources\":
|
||||
{\"requests\": {\"cpu\": \"250m\"}, \"limits\": {\"cpu\": \"500m\"}}}],
|
||||
\"serviceAccountName\": \"default-editor\", \"volumes\": [{\"name\": \"mypvc\",
|
||||
\"persistentVolumeClaim\": {\"claimName\": \"my-awesome-kf-workshop-1703595962\"}}]}}"}'}
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
- name: mnist-func
|
||||
container:
|
||||
args: [--log-folder, /data, '----output-paths', /tmp/outputs/logdir/data]
|
||||
command:
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- "def mnist_func(log_folder):\n\n print('mnist_func:', log_folder)\n \
|
||||
\ import tensorflow as tf\n import json\n mnist = tf.keras.datasets.mnist\n\
|
||||
\ (x_train,y_train), (x_test, y_test) = mnist.load_data()\n x_train,\
|
||||
\ x_test = x_train/255.0, x_test/255.0\n\n def create_model():\n \
|
||||
\ return tf.keras.models.Sequential([\n tf.keras.layers.Flatten(input_shape\
|
||||
\ = (28,28)),\n tf.keras.layers.Dense(512, activation = 'relu'),\n\
|
||||
\ tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(10,\
|
||||
\ activation = 'softmax')\n ])\n model = create_model()\n model.compile(optimizer='adam',\n\
|
||||
\ loss='sparse_categorical_crossentropy',\n \
|
||||
\ metrics=['accuracy'])\n import datetime\n import os\n\n ###\
|
||||
\ add tensorboard logout callback\n log_dir = os.path.join(log_folder,\
|
||||
\ \"logs\", datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\"))\n tensorboard_callback\
|
||||
\ = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)\n \
|
||||
\ ######\n\n model.fit(x=x_train, \n y=y_train, \n \
|
||||
\ epochs=5, \n validation_data=(x_test, y_test), \n \
|
||||
\ callbacks=[tensorboard_callback])\n\n print('At least tensorboard\
|
||||
\ callbacks are correct')\n print('logdir:', log_dir)\n return ([log_dir])\n\
|
||||
\ndef _serialize_str(str_value: str) -> str:\n if not isinstance(str_value,\
|
||||
\ str):\n raise TypeError('Value \"{}\" has type \"{}\" instead of\
|
||||
\ str.'.format(\n str(str_value), str(type(str_value))))\n return\
|
||||
\ str_value\n\nimport argparse\n_parser = argparse.ArgumentParser(prog='Mnist\
|
||||
\ func', description='')\n_parser.add_argument(\"--log-folder\", dest=\"log_folder\"\
|
||||
, type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"\
|
||||
----output-paths\", dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args\
|
||||
\ = vars(_parser.parse_args())\n_output_files = _parsed_args.pop(\"_output_paths\"\
|
||||
, [])\n\n_outputs = mnist_func(**_parsed_args)\n\n_output_serializers = [\n\
|
||||
\ _serialize_str,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n\
|
||||
\ try:\n os.makedirs(os.path.dirname(output_file))\n except OSError:\n\
|
||||
\ pass\n with open(output_file, 'w') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"
|
||||
image: tensorflow/tensorflow:2.0.0-py3
|
||||
resources:
|
||||
limits: {cpu: '1'}
|
||||
requests: {cpu: '1'}
|
||||
volumeMounts:
|
||||
- {mountPath: /data, name: mypvc}
|
||||
inputs:
|
||||
parameters:
|
||||
- {name: mypvc-name}
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: mnist-func-logdir, path: /tmp/outputs/logdir/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--log-folder", {"inputValue": "log_folder"}, "----output-paths",
|
||||
{"outputPath": "logdir"}], "command": ["sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def mnist_func(log_folder):\n\n print(''mnist_func:'', log_folder)\n import
|
||||
tensorflow as tf\n import json\n mnist = tf.keras.datasets.mnist\n (x_train,y_train),
|
||||
(x_test, y_test) = mnist.load_data()\n x_train, x_test = x_train/255.0,
|
||||
x_test/255.0\n\n def create_model():\n return tf.keras.models.Sequential([\n tf.keras.layers.Flatten(input_shape
|
||||
= (28,28)),\n tf.keras.layers.Dense(512, activation = ''relu''),\n tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(10,
|
||||
activation = ''softmax'')\n ])\n model = create_model()\n model.compile(optimizer=''adam'',\n loss=''sparse_categorical_crossentropy'',\n metrics=[''accuracy''])\n import
|
||||
datetime\n import os\n\n ### add tensorboard logout callback\n log_dir
|
||||
= os.path.join(log_folder, \"logs\", datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\"))\n tensorboard_callback
|
||||
= tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)\n ######\n\n model.fit(x=x_train,
|
||||
\n y=y_train, \n epochs=5, \n validation_data=(x_test,
|
||||
y_test), \n callbacks=[tensorboard_callback])\n\n print(''At
|
||||
least tensorboard callbacks are correct'')\n print(''logdir:'', log_dir)\n return
|
||||
([log_dir])\n\ndef _serialize_str(str_value: str) -> str:\n if not isinstance(str_value,
|
||||
str):\n raise TypeError(''Value \"{}\" has type \"{}\" instead of
|
||||
str.''.format(\n str(str_value), str(type(str_value))))\n return
|
||||
str_value\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Mnist
|
||||
func'', description='''')\n_parser.add_argument(\"--log-folder\", dest=\"log_folder\",
|
||||
type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"----output-paths\",
|
||||
dest=\"_output_paths\", type=str, nargs=1)\n_parsed_args = vars(_parser.parse_args())\n_output_files
|
||||
= _parsed_args.pop(\"_output_paths\", [])\n\n_outputs = mnist_func(**_parsed_args)\n\n_output_serializers
|
||||
= [\n _serialize_str,\n\n]\n\nimport os\nfor idx, output_file in enumerate(_output_files):\n try:\n os.makedirs(os.path.dirname(output_file))\n except
|
||||
OSError:\n pass\n with open(output_file, ''w'') as f:\n f.write(_output_serializers[idx](_outputs[idx]))\n"],
|
||||
"image": "tensorflow/tensorflow:2.0.0-py3"}}, "inputs": [{"name": "log_folder",
|
||||
"type": "String"}], "name": "Mnist func", "outputs": [{"name": "logdir",
|
||||
"type": "String"}]}', pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"log_folder":
|
||||
"/data"}'}
|
||||
volumes:
|
||||
- name: mypvc
|
||||
persistentVolumeClaim: {claimName: '{{inputs.parameters.mypvc-name}}'}
|
||||
- name: mnist-pipeline
|
||||
dag:
|
||||
tasks:
|
||||
- {name: create-tensorboard-visualization, template: create-tensorboard-visualization}
|
||||
- name: mnist-func
|
||||
template: mnist-func
|
||||
dependencies: [create-tensorboard-visualization, mypvc]
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: mypvc-name, value: '{{tasks.mypvc.outputs.parameters.mypvc-name}}'}
|
||||
- {name: mypvc, template: mypvc}
|
||||
- name: mypvc
|
||||
resource:
|
||||
action: create
|
||||
manifest: |
|
||||
apiVersion: v1
|
||||
kind: PersistentVolumeClaim
|
||||
metadata:
|
||||
name: '{{workflow.name}}-my-awesome-kf-workshop-1703595962'
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
outputs:
|
||||
parameters:
|
||||
- name: mypvc-manifest
|
||||
valueFrom: {jsonPath: '{}'}
|
||||
- name: mypvc-name
|
||||
valueFrom: {jsonPath: '{.metadata.name}'}
|
||||
- name: mypvc-size
|
||||
valueFrom: {jsonPath: '{.status.capacity.storage}'}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
arguments:
|
||||
parameters: []
|
||||
serviceAccountName: pipeline-runner
|
||||
|
|
@ -0,0 +1,131 @@
|
|||
apiVersion: argoproj.io/v1alpha1
|
||||
kind: Workflow
|
||||
metadata:
|
||||
generateName: only-decision-tree-
|
||||
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.20, pipelines.kubeflow.org/pipeline_compilation_time: '2023-04-28T21:42:00.682134',
|
||||
pipelines.kubeflow.org/pipeline_spec: '{"description": "Applies Decision Tree
|
||||
for classification problem.", "name": "only_decision_tree"}'}
|
||||
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.20}
|
||||
spec:
|
||||
entrypoint: only-decision-tree
|
||||
templates:
|
||||
- name: decision-tree-classifier
|
||||
container:
|
||||
args: []
|
||||
command: [python, decision_tree.py, --data, /tmp/inputs/Data/data, --accuracy,
|
||||
/tmp/outputs/Accuracy/data]
|
||||
image: lightnighttw/kubeflow:decision_tree_v2
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
inputs:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, path: /tmp/inputs/Data/data}
|
||||
outputs:
|
||||
parameters:
|
||||
- name: decision-tree-classifier-Accuracy
|
||||
valueFrom: {path: /tmp/outputs/Accuracy/data}
|
||||
artifacts:
|
||||
- {name: decision-tree-classifier-Accuracy, path: /tmp/outputs/Accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.20
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Trains
|
||||
a decision tree classifier", "implementation": {"container": {"command":
|
||||
["python", "decision_tree.py", "--data", {"inputPath": "Data"}, "--accuracy",
|
||||
{"outputPath": "Accuracy"}], "image": "lightnighttw/kubeflow:decision_tree_v2"}},
|
||||
"inputs": [{"description": "Path where data is stored.", "name": "Data",
|
||||
"type": "LocalPath"}], "name": "Decision Tree classifier", "outputs": [{"description":
|
||||
"Accuracy metric", "name": "Accuracy", "type": "Float"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
|
||||
"c5c232a9654213b3b222693949b71a5d561d04ed09543c20b6f8f2eab651ae0b", "url":
|
||||
"decision_tree/decision_tree.yaml"}'}
|
||||
- name: download-data-function
|
||||
container:
|
||||
args: []
|
||||
command: [python, download_data.py, --data, /tmp/outputs/Data/data]
|
||||
image: lightnighttw/kubeflow:download_data
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, path: /tmp/outputs/Data/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.20
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Download
|
||||
toy data from sklearn datasets", "implementation": {"container": {"command":
|
||||
["python", "download_data.py", "--data", {"outputPath": "Data"}], "image":
|
||||
"lightnighttw/kubeflow:download_data"}}, "name": "Download Data Function",
|
||||
"outputs": [{"description": "Path where data will be stored.", "name": "Data",
|
||||
"type": "LocalPath"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
|
||||
"467750defdccfec51c3af2a7eb853f74235f5f97329006d72bf33ff6e15ed02d", "url":
|
||||
"download_data/download_data.yaml"}'}
|
||||
- name: only-decision-tree
|
||||
dag:
|
||||
tasks:
|
||||
- name: decision-tree-classifier
|
||||
template: decision-tree-classifier
|
||||
dependencies: [download-data-function]
|
||||
arguments:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, from: '{{tasks.download-data-function.outputs.artifacts.download-data-function-Data}}'}
|
||||
- {name: download-data-function, template: download-data-function}
|
||||
- name: show-results
|
||||
template: show-results
|
||||
dependencies: [decision-tree-classifier]
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: decision-tree-classifier-Accuracy, value: '{{tasks.decision-tree-classifier.outputs.parameters.decision-tree-classifier-Accuracy}}'}
|
||||
- name: show-results
|
||||
container:
|
||||
args: [--decision-tree, '{{inputs.parameters.decision-tree-classifier-Accuracy}}']
|
||||
command:
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- |
|
||||
def show_results(decision_tree):
|
||||
# the results are shown.
|
||||
|
||||
print(f"Decision tree (accuracy): {decision_tree}")
|
||||
|
||||
import argparse
|
||||
_parser = argparse.ArgumentParser(prog='Show results', description='')
|
||||
_parser.add_argument("--decision-tree", dest="decision_tree", type=float, required=True, default=argparse.SUPPRESS)
|
||||
_parsed_args = vars(_parser.parse_args())
|
||||
|
||||
_outputs = show_results(**_parsed_args)
|
||||
image: python:3.7
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
inputs:
|
||||
parameters:
|
||||
- {name: decision-tree-classifier-Accuracy}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.20
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--decision-tree", {"inputValue": "decision_tree"}], "command":
|
||||
["sh", "-ec", "program_path=$(mktemp)\nprintf \"%s\" \"$0\" > \"$program_path\"\npython3
|
||||
-u \"$program_path\" \"$@\"\n", "def show_results(decision_tree):\n #
|
||||
the results are shown.\n\n print(f\"Decision tree (accuracy): {decision_tree}\")\n\nimport
|
||||
argparse\n_parser = argparse.ArgumentParser(prog=''Show results'', description='''')\n_parser.add_argument(\"--decision-tree\",
|
||||
dest=\"decision_tree\", type=float, required=True, default=argparse.SUPPRESS)\n_parsed_args
|
||||
= vars(_parser.parse_args())\n\n_outputs = show_results(**_parsed_args)\n"],
|
||||
"image": "python:3.7"}}, "inputs": [{"name": "decision_tree", "type": "Float"}],
|
||||
"name": "Show results"}', pipelines.kubeflow.org/component_ref: '{}', pipelines.kubeflow.org/arguments.parameters: '{"decision_tree":
|
||||
"{{inputs.parameters.decision-tree-classifier-Accuracy}}"}'}
|
||||
arguments:
|
||||
parameters: []
|
||||
serviceAccountName: pipeline-runner
|
||||
|
|
@ -0,0 +1,229 @@
|
|||
apiVersion: argoproj.io/v1alpha1
|
||||
kind: Workflow
|
||||
metadata:
|
||||
generateName: three-pipeline-
|
||||
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9, pipelines.kubeflow.org/pipeline_compilation_time: '2023-04-28T12:05:44.365082',
|
||||
pipelines.kubeflow.org/pipeline_spec: '{"description": "Applies Decision Tree,
|
||||
random forest and Logistic Regression for classification problem.", "name":
|
||||
"Three Pipeline"}'}
|
||||
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.9}
|
||||
spec:
|
||||
entrypoint: three-pipeline
|
||||
templates:
|
||||
- name: decision-tree-classifier
|
||||
container:
|
||||
args: []
|
||||
command: [python, decision_tree.py, --data, /tmp/inputs/Data/data, --accuracy,
|
||||
/tmp/outputs/Accuracy/data]
|
||||
image: lightnighttw/kubeflow:decision_tree_v2
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
inputs:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, path: /tmp/inputs/Data/data}
|
||||
outputs:
|
||||
parameters:
|
||||
- name: decision-tree-classifier-Accuracy
|
||||
valueFrom: {path: /tmp/outputs/Accuracy/data}
|
||||
artifacts:
|
||||
- {name: decision-tree-classifier-Accuracy, path: /tmp/outputs/Accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Trains
|
||||
a decision tree classifier", "implementation": {"container": {"command":
|
||||
["python", "decision_tree.py", "--data", {"inputPath": "Data"}, "--accuracy",
|
||||
{"outputPath": "Accuracy"}], "image": "lightnighttw/kubeflow:decision_tree_v2"}},
|
||||
"inputs": [{"description": "Path where data is stored.", "name": "Data",
|
||||
"type": "LocalPath"}], "name": "Decision Tree classifier", "outputs": [{"description":
|
||||
"Accuracy metric", "name": "Accuracy", "type": "Float"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
|
||||
"c5c232a9654213b3b222693949b71a5d561d04ed09543c20b6f8f2eab651ae0b", "url":
|
||||
"decision_tree/decision_tree.yaml"}'}
|
||||
- name: download-data-function
|
||||
container:
|
||||
args: []
|
||||
command: [python, download_data.py, --data, /tmp/outputs/Data/data]
|
||||
image: lightnighttw/kubeflow:download_data
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
outputs:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, path: /tmp/outputs/Data/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Download
|
||||
toy data from sklearn datasets", "implementation": {"container": {"command":
|
||||
["python", "download_data.py", "--data", {"outputPath": "Data"}], "image":
|
||||
"lightnighttw/kubeflow:download_data"}}, "name": "Download Data Function",
|
||||
"outputs": [{"description": "Path where data will be stored.", "name": "Data",
|
||||
"type": "LocalPath"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
|
||||
"467750defdccfec51c3af2a7eb853f74235f5f97329006d72bf33ff6e15ed02d", "url":
|
||||
"download_data/download_data.yaml"}'}
|
||||
- name: logistic-regression-classifier
|
||||
container:
|
||||
args: []
|
||||
command: [python, logistic_regression.py, --data, /tmp/inputs/Data/data, --accuracy,
|
||||
/tmp/outputs/Accuracy/data]
|
||||
image: lightnighttw/kubeflow:logistic_regression
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
inputs:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, path: /tmp/inputs/Data/data}
|
||||
outputs:
|
||||
parameters:
|
||||
- name: logistic-regression-classifier-Accuracy
|
||||
valueFrom: {path: /tmp/outputs/Accuracy/data}
|
||||
artifacts:
|
||||
- {name: logistic-regression-classifier-Accuracy, path: /tmp/outputs/Accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Trains
|
||||
a Logistic Regression Classifier", "implementation": {"container": {"command":
|
||||
["python", "logistic_regression.py", "--data", {"inputPath": "Data"}, "--accuracy",
|
||||
{"outputPath": "Accuracy"}], "image": "lightnighttw/kubeflow:logistic_regression"}},
|
||||
"inputs": [{"description": "Path where data is stored.", "name": "Data",
|
||||
"type": "LocalPath"}], "name": "Logistic Regression Classifier", "outputs":
|
||||
[{"description": "Accuracy metric", "name": "Accuracy", "type": "Float"}]}',
|
||||
pipelines.kubeflow.org/component_ref: '{"digest": "a8d1e77d07d18a75bef200aee96f35136833fc4bb535f33fd949a307beb094c2",
|
||||
"url": "logistic_regression/logistic_regression.yaml"}'}
|
||||
- name: random-forest-classifier
|
||||
container:
|
||||
args: []
|
||||
command: [python, randomforest.py, --data, /tmp/inputs/Data/data, --accuracy,
|
||||
/tmp/outputs/Accuracy/data]
|
||||
image: lightnighttw/kubeflow:random_forest_v4
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
inputs:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, path: /tmp/inputs/Data/data}
|
||||
outputs:
|
||||
parameters:
|
||||
- name: random-forest-classifier-Accuracy
|
||||
valueFrom: {path: /tmp/outputs/Accuracy/data}
|
||||
artifacts:
|
||||
- {name: random-forest-classifier-Accuracy, path: /tmp/outputs/Accuracy/data}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Train
|
||||
a random forest classifier", "implementation": {"container": {"command":
|
||||
["python", "randomforest.py", "--data", {"inputPath": "Data"}, "--accuracy",
|
||||
{"outputPath": "Accuracy"}], "image": "lightnighttw/kubeflow:random_forest_v4"}},
|
||||
"inputs": [{"description": "Path where data is stored.", "name": "Data",
|
||||
"type": "LocalPath"}], "name": "Random Forest classifier", "outputs": [{"description":
|
||||
"Accuracy metric", "name": "Accuracy", "type": "Float"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
|
||||
"b49b12da3371976eddf41d662685bb49d71b419d516de65efdd90938d2c706bc", "url":
|
||||
"randomForest/random_forest.yaml"}'}
|
||||
- name: show-results
|
||||
container:
|
||||
args: [--decision-tree, '{{inputs.parameters.decision-tree-classifier-Accuracy}}',
|
||||
--logistic-regression, '{{inputs.parameters.logistic-regression-classifier-Accuracy}}',
|
||||
--random-forest, '{{inputs.parameters.random-forest-classifier-Accuracy}}']
|
||||
command:
|
||||
- sh
|
||||
- -ec
|
||||
- |
|
||||
program_path=$(mktemp)
|
||||
printf "%s" "$0" > "$program_path"
|
||||
python3 -u "$program_path" "$@"
|
||||
- |
|
||||
def show_results(decision_tree, logistic_regression, random_forest):
|
||||
# Given the outputs from decision_tree and logistic regression components
|
||||
# the results are shown.
|
||||
|
||||
print(f"Decision tree (accuracy): {decision_tree}")
|
||||
print(f"Logistic regression (accuracy): {logistic_regression}")
|
||||
print(f"Random forest (accuracy): {random_forest}")
|
||||
|
||||
import argparse
|
||||
_parser = argparse.ArgumentParser(prog='Show results', description='')
|
||||
_parser.add_argument("--decision-tree", dest="decision_tree", type=float, required=True, default=argparse.SUPPRESS)
|
||||
_parser.add_argument("--logistic-regression", dest="logistic_regression", type=float, required=True, default=argparse.SUPPRESS)
|
||||
_parser.add_argument("--random-forest", dest="random_forest", type=float, required=True, default=argparse.SUPPRESS)
|
||||
_parsed_args = vars(_parser.parse_args())
|
||||
|
||||
_outputs = show_results(**_parsed_args)
|
||||
image: python:3.7
|
||||
resources:
|
||||
limits:
|
||||
cpu: 2
|
||||
inputs:
|
||||
parameters:
|
||||
- {name: decision-tree-classifier-Accuracy}
|
||||
- {name: logistic-regression-classifier-Accuracy}
|
||||
- {name: random-forest-classifier-Accuracy}
|
||||
metadata:
|
||||
labels:
|
||||
pipelines.kubeflow.org/kfp_sdk_version: 1.8.9
|
||||
pipelines.kubeflow.org/pipeline-sdk-type: kfp
|
||||
pipelines.kubeflow.org/enable_caching: "true"
|
||||
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
|
||||
{"args": ["--decision-tree", {"inputValue": "decision_tree"}, "--logistic-regression",
|
||||
{"inputValue": "logistic_regression"}, "--random-forest", {"inputValue":
|
||||
"random_forest"}], "command": ["sh", "-ec", "program_path=$(mktemp)\nprintf
|
||||
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
|
||||
"def show_results(decision_tree, logistic_regression, random_forest):\n #
|
||||
Given the outputs from decision_tree and logistic regression components\n #
|
||||
the results are shown.\n\n print(f\"Decision tree (accuracy): {decision_tree}\")\n print(f\"Logistic
|
||||
regression (accuracy): {logistic_regression}\")\n print(f\"Random forest
|
||||
(accuracy): {random_forest}\")\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Show
|
||||
results'', description='''')\n_parser.add_argument(\"--decision-tree\",
|
||||
dest=\"decision_tree\", type=float, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--logistic-regression\",
|
||||
dest=\"logistic_regression\", type=float, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--random-forest\",
|
||||
dest=\"random_forest\", type=float, required=True, default=argparse.SUPPRESS)\n_parsed_args
|
||||
= vars(_parser.parse_args())\n\n_outputs = show_results(**_parsed_args)\n"],
|
||||
"image": "python:3.7"}}, "inputs": [{"name": "decision_tree", "type": "Float"},
|
||||
{"name": "logistic_regression", "type": "Float"}, {"name": "random_forest",
|
||||
"type": "Float"}], "name": "Show results"}', pipelines.kubeflow.org/component_ref: '{}',
|
||||
pipelines.kubeflow.org/arguments.parameters: '{"decision_tree": "{{inputs.parameters.decision-tree-classifier-Accuracy}}",
|
||||
"logistic_regression": "{{inputs.parameters.logistic-regression-classifier-Accuracy}}",
|
||||
"random_forest": "{{inputs.parameters.random-forest-classifier-Accuracy}}"}'}
|
||||
- name: three-pipeline
|
||||
dag:
|
||||
tasks:
|
||||
- name: decision-tree-classifier
|
||||
template: decision-tree-classifier
|
||||
dependencies: [download-data-function]
|
||||
arguments:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, from: '{{tasks.download-data-function.outputs.artifacts.download-data-function-Data}}'}
|
||||
- {name: download-data-function, template: download-data-function}
|
||||
- name: logistic-regression-classifier
|
||||
template: logistic-regression-classifier
|
||||
dependencies: [download-data-function]
|
||||
arguments:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, from: '{{tasks.download-data-function.outputs.artifacts.download-data-function-Data}}'}
|
||||
- name: random-forest-classifier
|
||||
template: random-forest-classifier
|
||||
dependencies: [download-data-function]
|
||||
arguments:
|
||||
artifacts:
|
||||
- {name: download-data-function-Data, from: '{{tasks.download-data-function.outputs.artifacts.download-data-function-Data}}'}
|
||||
- name: show-results
|
||||
template: show-results
|
||||
dependencies: [decision-tree-classifier, logistic-regression-classifier, random-forest-classifier]
|
||||
arguments:
|
||||
parameters:
|
||||
- {name: decision-tree-classifier-Accuracy, value: '{{tasks.decision-tree-classifier.outputs.parameters.decision-tree-classifier-Accuracy}}'}
|
||||
- {name: logistic-regression-classifier-Accuracy, value: '{{tasks.logistic-regression-classifier.outputs.parameters.logistic-regression-classifier-Accuracy}}'}
|
||||
- {name: random-forest-classifier-Accuracy, value: '{{tasks.random-forest-classifier.outputs.parameters.random-forest-classifier-Accuracy}}'}
|
||||
arguments:
|
||||
parameters: []
|
||||
serviceAccountName: pipeline-runner
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
setuptools
|
||||
wheel
|
||||
|
|
@ -0,0 +1,498 @@
|
|||
/**
|
||||
* This is the default settings file provided by Node-RED.
|
||||
*
|
||||
* It can contain any valid JavaScript code that will get run when Node-RED
|
||||
* is started.
|
||||
*
|
||||
* Lines that start with // are commented out.
|
||||
* Each entry should be separated from the entries above and below by a comma ','
|
||||
*
|
||||
* For more information about individual settings, refer to the documentation:
|
||||
* https://nodered.org/docs/user-guide/runtime/configuration
|
||||
*
|
||||
* The settings are split into the following sections:
|
||||
* - Flow File and User Directory Settings
|
||||
* - Security
|
||||
* - Server Settings
|
||||
* - Runtime Settings
|
||||
* - Editor Settings
|
||||
* - Node Settings
|
||||
*
|
||||
**/
|
||||
|
||||
module.exports = {
|
||||
|
||||
/*******************************************************************************
|
||||
* Flow File and User Directory Settings
|
||||
* - flowFile
|
||||
* - credentialSecret
|
||||
* - flowFilePretty
|
||||
* - userDir
|
||||
* - nodesDir
|
||||
******************************************************************************/
|
||||
|
||||
/** The file containing the flows. If not set, defaults to flows_<hostname>.json **/
|
||||
flowFile: 'flows.json',
|
||||
|
||||
/** By default, credentials are encrypted in storage using a generated key. To
|
||||
* specify your own secret, set the following property.
|
||||
* If you want to disable encryption of credentials, set this property to false.
|
||||
* Note: once you set this property, do not change it - doing so will prevent
|
||||
* node-red from being able to decrypt your existing credentials and they will be
|
||||
* lost.
|
||||
*/
|
||||
//credentialSecret: "a-secret-key",
|
||||
credentialSecret: process.env.NODE_RED_CREDENTIAL_SECRET,
|
||||
|
||||
/** By default, the flow JSON will be formatted over multiple lines making
|
||||
* it easier to compare changes when using version control.
|
||||
* To disable pretty-printing of the JSON set the following property to false.
|
||||
*/
|
||||
flowFilePretty: true,
|
||||
|
||||
/** By default, all user data is stored in a directory called `.node-red` under
|
||||
* the user's home directory. To use a different location, the following
|
||||
* property can be used
|
||||
*/
|
||||
//userDir: '/home/nol/.node-red/',
|
||||
|
||||
/** Node-RED scans the `nodes` directory in the userDir to find local node files.
|
||||
* The following property can be used to specify an additional directory to scan.
|
||||
*/
|
||||
//nodesDir: '/home/nol/.node-red/nodes',
|
||||
|
||||
/*******************************************************************************
|
||||
* Security
|
||||
* - adminAuth
|
||||
* - https
|
||||
* - httpsRefreshInterval
|
||||
* - requireHttps
|
||||
* - httpNodeAuth
|
||||
* - httpStaticAuth
|
||||
******************************************************************************/
|
||||
|
||||
/** To password protect the Node-RED editor and admin API, the following
|
||||
* property can be used. See http://nodered.org/docs/security.html for details.
|
||||
*/
|
||||
//adminAuth: {
|
||||
// type: "credentials",
|
||||
// users: [{
|
||||
// username: "admin",
|
||||
// password: "$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN.",
|
||||
// permissions: "*"
|
||||
// }]
|
||||
//},
|
||||
|
||||
/** The following property can be used to enable HTTPS
|
||||
* This property can be either an object, containing both a (private) key
|
||||
* and a (public) certificate, or a function that returns such an object.
|
||||
* See http://nodejs.org/api/https.html#https_https_createserver_options_requestlistener
|
||||
* for details of its contents.
|
||||
*/
|
||||
|
||||
/** Option 1: static object */
|
||||
//https: {
|
||||
// key: require("fs").readFileSync('privkey.pem'),
|
||||
// cert: require("fs").readFileSync('cert.pem')
|
||||
//},
|
||||
|
||||
/** Option 2: function that returns the HTTP configuration object */
|
||||
// https: function() {
|
||||
// // This function should return the options object, or a Promise
|
||||
// // that resolves to the options object
|
||||
// return {
|
||||
// key: require("fs").readFileSync('privkey.pem'),
|
||||
// cert: require("fs").readFileSync('cert.pem')
|
||||
// }
|
||||
// },
|
||||
|
||||
/** If the `https` setting is a function, the following setting can be used
|
||||
* to set how often, in hours, the function will be called. That can be used
|
||||
* to refresh any certificates.
|
||||
*/
|
||||
//httpsRefreshInterval : 12,
|
||||
|
||||
/** The following property can be used to cause insecure HTTP connections to
|
||||
* be redirected to HTTPS.
|
||||
*/
|
||||
//requireHttps: true,
|
||||
|
||||
/** To password protect the node-defined HTTP endpoints (httpNodeRoot),
|
||||
* including node-red-dashboard, or the static content (httpStatic), the
|
||||
* following properties can be used.
|
||||
* The `pass` field is a bcrypt hash of the password.
|
||||
* See http://nodered.org/docs/security.html#generating-the-password-hash
|
||||
*/
|
||||
//httpNodeAuth: {user:"user",pass:"$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN."},
|
||||
//httpStaticAuth: {user:"user",pass:"$2a$08$zZWtXTja0fB1pzD4sHCMyOCMYz2Z6dNbM6tl8sJogENOMcxWV9DN."},
|
||||
|
||||
/*******************************************************************************
|
||||
* Server Settings
|
||||
* - uiPort
|
||||
* - uiHost
|
||||
* - apiMaxLength
|
||||
* - httpServerOptions
|
||||
* - httpAdminRoot
|
||||
* - httpAdminMiddleware
|
||||
* - httpNodeRoot
|
||||
* - httpNodeCors
|
||||
* - httpNodeMiddleware
|
||||
* - httpStatic
|
||||
******************************************************************************/
|
||||
|
||||
/** the tcp port that the Node-RED web server is listening on */
|
||||
uiPort: process.env.PORT || 1880,
|
||||
|
||||
/** By default, the Node-RED UI accepts connections on all IPv4 interfaces.
|
||||
* To listen on all IPv6 addresses, set uiHost to "::",
|
||||
* The following property can be used to listen on a specific interface. For
|
||||
* example, the following would only allow connections from the local machine.
|
||||
*/
|
||||
//uiHost: "127.0.0.1",
|
||||
|
||||
/** The maximum size of HTTP request that will be accepted by the runtime api.
|
||||
* Default: 5mb
|
||||
*/
|
||||
//apiMaxLength: '5mb',
|
||||
|
||||
/** The following property can be used to pass custom options to the Express.js
|
||||
* server used by Node-RED. For a full list of available options, refer
|
||||
* to http://expressjs.com/en/api.html#app.settings.table
|
||||
*/
|
||||
//httpServerOptions: { },
|
||||
|
||||
/** By default, the Node-RED UI is available at http://localhost:1880/
|
||||
* The following property can be used to specify a different root path.
|
||||
* If set to false, this is disabled.
|
||||
*/
|
||||
//httpAdminRoot: '/admin',
|
||||
|
||||
/** The following property can be used to add a custom middleware function
|
||||
* in front of all admin http routes. For example, to set custom http
|
||||
* headers. It can be a single function or an array of middleware functions.
|
||||
*/
|
||||
// httpAdminMiddleware: function(req,res,next) {
|
||||
// // Set the X-Frame-Options header to limit where the editor
|
||||
// // can be embedded
|
||||
// //res.set('X-Frame-Options', 'sameorigin');
|
||||
// next();
|
||||
// },
|
||||
|
||||
|
||||
/** Some nodes, such as HTTP In, can be used to listen for incoming http requests.
|
||||
* By default, these are served relative to '/'. The following property
|
||||
* can be used to specifiy a different root path. If set to false, this is
|
||||
* disabled.
|
||||
*/
|
||||
//httpNodeRoot: '/red-nodes',
|
||||
|
||||
/** The following property can be used to configure cross-origin resource sharing
|
||||
* in the HTTP nodes.
|
||||
* See https://github.com/troygoode/node-cors#configuration-options for
|
||||
* details on its contents. The following is a basic permissive set of options:
|
||||
*/
|
||||
//httpNodeCors: {
|
||||
// origin: "*",
|
||||
// methods: "GET,PUT,POST,DELETE"
|
||||
//},
|
||||
|
||||
/** If you need to set an http proxy please set an environment variable
|
||||
* called http_proxy (or HTTP_PROXY) outside of Node-RED in the operating system.
|
||||
* For example - http_proxy=http://myproxy.com:8080
|
||||
* (Setting it here will have no effect)
|
||||
* You may also specify no_proxy (or NO_PROXY) to supply a comma separated
|
||||
* list of domains to not proxy, eg - no_proxy=.acme.co,.acme.co.uk
|
||||
*/
|
||||
|
||||
/** The following property can be used to add a custom middleware function
|
||||
* in front of all http in nodes. This allows custom authentication to be
|
||||
* applied to all http in nodes, or any other sort of common request processing.
|
||||
* It can be a single function or an array of middleware functions.
|
||||
*/
|
||||
//httpNodeMiddleware: function(req,res,next) {
|
||||
// // Handle/reject the request, or pass it on to the http in node by calling next();
|
||||
// // Optionally skip our rawBodyParser by setting this to true;
|
||||
// //req.skipRawBodyParser = true;
|
||||
// next();
|
||||
//},
|
||||
|
||||
/** When httpAdminRoot is used to move the UI to a different root path, the
|
||||
* following property can be used to identify a directory of static content
|
||||
* that should be served at http://localhost:1880/.
|
||||
*/
|
||||
//httpStatic: '/home/nol/node-red-static/',
|
||||
|
||||
/*******************************************************************************
|
||||
* Runtime Settings
|
||||
* - lang
|
||||
* - logging
|
||||
* - contextStorage
|
||||
* - exportGlobalContextKeys
|
||||
* - externalModules
|
||||
******************************************************************************/
|
||||
|
||||
/** Uncomment the following to run node-red in your preferred language.
|
||||
* Available languages include: en-US (default), ja, de, zh-CN, zh-TW, ru, ko
|
||||
* Some languages are more complete than others.
|
||||
*/
|
||||
// lang: "de",
|
||||
|
||||
/** Configure the logging output */
|
||||
logging: {
|
||||
/** Only console logging is currently supported */
|
||||
console: {
|
||||
/** Level of logging to be recorded. Options are:
|
||||
* fatal - only those errors which make the application unusable should be recorded
|
||||
* error - record errors which are deemed fatal for a particular request + fatal errors
|
||||
* warn - record problems which are non fatal + errors + fatal errors
|
||||
* info - record information about the general running of the application + warn + error + fatal errors
|
||||
* debug - record information which is more verbose than info + info + warn + error + fatal errors
|
||||
* trace - record very detailed logging + debug + info + warn + error + fatal errors
|
||||
* off - turn off all logging (doesn't affect metrics or audit)
|
||||
*/
|
||||
level: "info",
|
||||
/** Whether or not to include metric events in the log output */
|
||||
metrics: false,
|
||||
/** Whether or not to include audit events in the log output */
|
||||
audit: false
|
||||
}
|
||||
},
|
||||
|
||||
/** Context Storage
|
||||
* The following property can be used to enable context storage. The configuration
|
||||
* provided here will enable file-based context that flushes to disk every 30 seconds.
|
||||
* Refer to the documentation for further options: https://nodered.org/docs/api/context/
|
||||
*/
|
||||
//contextStorage: {
|
||||
// default: {
|
||||
// module:"localfilesystem"
|
||||
// },
|
||||
//},
|
||||
|
||||
/** `global.keys()` returns a list of all properties set in global context.
|
||||
* This allows them to be displayed in the Context Sidebar within the editor.
|
||||
* In some circumstances it is not desirable to expose them to the editor. The
|
||||
* following property can be used to hide any property set in `functionGlobalContext`
|
||||
* from being list by `global.keys()`.
|
||||
* By default, the property is set to false to avoid accidental exposure of
|
||||
* their values. Setting this to true will cause the keys to be listed.
|
||||
*/
|
||||
exportGlobalContextKeys: false,
|
||||
|
||||
/** Configure how the runtime will handle external npm modules.
|
||||
* This covers:
|
||||
* - whether the editor will allow new node modules to be installed
|
||||
* - whether nodes, such as the Function node are allowed to have their
|
||||
* own dynamically configured dependencies.
|
||||
* The allow/denyList options can be used to limit what modules the runtime
|
||||
* will install/load. It can use '*' as a wildcard that matches anything.
|
||||
*/
|
||||
externalModules: {
|
||||
// autoInstall: false, /** Whether the runtime will attempt to automatically install missing modules */
|
||||
// autoInstallRetry: 30, /** Interval, in seconds, between reinstall attempts */
|
||||
// palette: { /** Configuration for the Palette Manager */
|
||||
// allowInstall: true, /** Enable the Palette Manager in the editor */
|
||||
// allowUpdate: true, /** Allow modules to be updated in the Palette Manager */
|
||||
// allowUpload: true, /** Allow module tgz files to be uploaded and installed */
|
||||
// allowList: ['*'],
|
||||
// denyList: [],
|
||||
// allowUpdateList: ['*'],
|
||||
// denyUpdateList: []
|
||||
// },
|
||||
// modules: { /** Configuration for node-specified modules */
|
||||
// allowInstall: true,
|
||||
// allowList: [],
|
||||
// denyList: []
|
||||
// }
|
||||
},
|
||||
|
||||
|
||||
/*******************************************************************************
|
||||
* Editor Settings
|
||||
* - disableEditor
|
||||
* - editorTheme
|
||||
******************************************************************************/
|
||||
|
||||
/** The following property can be used to disable the editor. The admin API
|
||||
* is not affected by this option. To disable both the editor and the admin
|
||||
* API, use either the httpRoot or httpAdminRoot properties
|
||||
*/
|
||||
//disableEditor: false,
|
||||
|
||||
/** Customising the editor
|
||||
* See https://nodered.org/docs/user-guide/runtime/configuration#editor-themes
|
||||
* for all available options.
|
||||
*/
|
||||
editorTheme: {
|
||||
/** The following property can be used to set a custom theme for the editor.
|
||||
* See https://github.com/node-red-contrib-themes/theme-collection for
|
||||
* a collection of themes to chose from.
|
||||
*/
|
||||
//theme: "",
|
||||
|
||||
/** To disable the 'Welcome to Node-RED' tour that is displayed the first
|
||||
* time you access the editor for each release of Node-RED, set this to false
|
||||
*/
|
||||
//tours: false,
|
||||
|
||||
palette: {
|
||||
/** The following property can be used to order the categories in the editor
|
||||
* palette. If a node's category is not in the list, the category will get
|
||||
* added to the end of the palette.
|
||||
* If not set, the following default order is used:
|
||||
*/
|
||||
//categories: ['subflows', 'common', 'function', 'network', 'sequence', 'parser', 'storage'],
|
||||
},
|
||||
|
||||
projects: {
|
||||
/** To enable the Projects feature, set this value to true */
|
||||
enabled: false,
|
||||
workflow: {
|
||||
/** Set the default projects workflow mode.
|
||||
* - manual - you must manually commit changes
|
||||
* - auto - changes are automatically committed
|
||||
* This can be overridden per-user from the 'Git config'
|
||||
* section of 'User Settings' within the editor
|
||||
*/
|
||||
mode: "manual"
|
||||
}
|
||||
},
|
||||
|
||||
codeEditor: {
|
||||
/** Select the text editor component used by the editor.
|
||||
* Defaults to "ace", but can be set to "ace" or "monaco"
|
||||
*/
|
||||
lib: "ace",
|
||||
options: {
|
||||
/** The follow options only apply if the editor is set to "monaco"
|
||||
*
|
||||
* theme - must match the file name of a theme in
|
||||
* packages/node_modules/@node-red/editor-client/src/vendor/monaco/dist/theme
|
||||
* e.g. "tomorrow-night", "upstream-sunburst", "github", "my-theme"
|
||||
*/
|
||||
theme: "vs",
|
||||
/** other overrides can be set e.g. fontSize, fontFamily, fontLigatures etc.
|
||||
* for the full list, see https://microsoft.github.io/monaco-editor/api/interfaces/monaco.editor.istandaloneeditorconstructionoptions.html
|
||||
*/
|
||||
//fontSize: 14,
|
||||
//fontFamily: "Cascadia Code, Fira Code, Consolas, 'Courier New', monospace",
|
||||
//fontLigatures: true,
|
||||
}
|
||||
}
|
||||
},
|
||||
|
||||
/*******************************************************************************
|
||||
* Node Settings
|
||||
* - fileWorkingDirectory
|
||||
* - functionGlobalContext
|
||||
* - functionExternalModules
|
||||
* - nodeMessageBufferMaxLength
|
||||
* - ui (for use with Node-RED Dashboard)
|
||||
* - debugUseColors
|
||||
* - debugMaxLength
|
||||
* - execMaxBufferSize
|
||||
* - httpRequestTimeout
|
||||
* - mqttReconnectTime
|
||||
* - serialReconnectTime
|
||||
* - socketReconnectTime
|
||||
* - socketTimeout
|
||||
* - tcpMsgQueueSize
|
||||
* - inboundWebSocketTimeout
|
||||
* - tlsConfigDisableLocalFiles
|
||||
* - webSocketNodeVerifyClient
|
||||
******************************************************************************/
|
||||
|
||||
/** The working directory to handle relative file paths from within the File nodes
|
||||
* defaults to the working directory of the Node-RED process.
|
||||
*/
|
||||
//fileWorkingDirectory: "",
|
||||
|
||||
/** Allow the Function node to load additional npm modules directly */
|
||||
functionExternalModules: true,
|
||||
|
||||
/** The following property can be used to set predefined values in Global Context.
|
||||
* This allows extra node modules to be made available with in Function node.
|
||||
* For example, the following:
|
||||
* functionGlobalContext: { os:require('os') }
|
||||
* will allow the `os` module to be accessed in a Function node using:
|
||||
* global.get("os")
|
||||
*/
|
||||
functionGlobalContext: {
|
||||
// os:require('os'),
|
||||
},
|
||||
|
||||
/** The maximum number of messages nodes will buffer internally as part of their
|
||||
* operation. This applies across a range of nodes that operate on message sequences.
|
||||
* defaults to no limit. A value of 0 also means no limit is applied.
|
||||
*/
|
||||
//nodeMessageBufferMaxLength: 0,
|
||||
|
||||
/** If you installed the optional node-red-dashboard you can set it's path
|
||||
* relative to httpNodeRoot
|
||||
* Other optional properties include
|
||||
* readOnly:{boolean},
|
||||
* middleware:{function or array}, (req,res,next) - http middleware
|
||||
* ioMiddleware:{function or array}, (socket,next) - socket.io middleware
|
||||
*/
|
||||
//ui: { path: "ui" },
|
||||
|
||||
/** Colourise the console output of the debug node */
|
||||
//debugUseColors: true,
|
||||
|
||||
/** The maximum length, in characters, of any message sent to the debug sidebar tab */
|
||||
debugMaxLength: 1000,
|
||||
|
||||
/** Maximum buffer size for the exec node. Defaults to 10Mb */
|
||||
//execMaxBufferSize: 10000000,
|
||||
|
||||
/** Timeout in milliseconds for HTTP request connections. Defaults to 120s */
|
||||
//httpRequestTimeout: 120000,
|
||||
|
||||
/** Retry time in milliseconds for MQTT connections */
|
||||
mqttReconnectTime: 15000,
|
||||
|
||||
/** Retry time in milliseconds for Serial port connections */
|
||||
serialReconnectTime: 15000,
|
||||
|
||||
/** Retry time in milliseconds for TCP socket connections */
|
||||
//socketReconnectTime: 10000,
|
||||
|
||||
/** Timeout in milliseconds for TCP server socket connections. Defaults to no timeout */
|
||||
//socketTimeout: 120000,
|
||||
|
||||
/** Maximum number of messages to wait in queue while attempting to connect to TCP socket
|
||||
* defaults to 1000
|
||||
*/
|
||||
//tcpMsgQueueSize: 2000,
|
||||
|
||||
/** Timeout in milliseconds for inbound WebSocket connections that do not
|
||||
* match any configured node. Defaults to 5000
|
||||
*/
|
||||
//inboundWebSocketTimeout: 5000,
|
||||
|
||||
/** To disable the option for using local files for storing keys and
|
||||
* certificates in the TLS configuration node, set this to true.
|
||||
*/
|
||||
//tlsConfigDisableLocalFiles: true,
|
||||
|
||||
/** The following property can be used to verify websocket connection attempts.
|
||||
* This allows, for example, the HTTP request headers to be checked to ensure
|
||||
* they include valid authentication information.
|
||||
*/
|
||||
//webSocketNodeVerifyClient: function(info) {
|
||||
// /** 'info' has three properties:
|
||||
// * - origin : the value in the Origin header
|
||||
// * - req : the HTTP request
|
||||
// * - secure : true if req.connection.authorized or req.connection.encrypted is set
|
||||
// *
|
||||
// * The function should return true if the connection should be accepted, false otherwise.
|
||||
// *
|
||||
// * Alternatively, if this function is defined to accept a second argument, callback,
|
||||
// * it can be used to verify the client asynchronously.
|
||||
// * The callback takes three arguments:
|
||||
// * - result : boolean, whether to accept the connection or not
|
||||
// * - code : if result is false, the HTTP error status to return
|
||||
// * - reason: if result is false, the HTTP reason string to return
|
||||
// */
|
||||
//},
|
||||
}
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
FROM nodered/node-red:2.2.3-12
|
||||
|
||||
ARG PREFIX
|
||||
|
||||
ENV NODE_OPTIONS=--max_old_space_size=128
|
||||
|
||||
USER root
|
||||
|
||||
RUN apk update && \
|
||||
apk add py3-pip
|
||||
|
||||
USER node-red
|
||||
# Copy package.json to the WORKDIR so npm builds all
|
||||
# of your added nodes modules for Node-RED
|
||||
COPY package.json .
|
||||
RUN npm install --unsafe-perm --no-update-notifier --no-fund --only=production
|
||||
|
||||
ADD scripts/entrypoint.sh .
|
||||
|
||||
ENTRYPOINT ["./entrypoint.sh"]
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
#### Examples
|
||||
|
||||
This example folder contains multiple node-red flow setups, each is isolated with a folder that allows you to run the different examples with the same settings.
|
||||
|
||||
##### Add customized npm package
|
||||
|
||||
You can add customized npm package via `npm install` or directly modify `packages.json`. Then rebuild your container image.
|
||||
|
||||
##### Build
|
||||
|
||||
Simply to run the following command to build node-red image
|
||||
|
||||
```
|
||||
./build.sh
|
||||
```
|
||||
|
||||
##### Run the container image
|
||||
|
||||
To run the container image, use
|
||||
|
||||
```
|
||||
KUBEFLOW_HOST=<your-kubeflow-instance-endpoint> \
|
||||
KUBEFLOW_USERNAME=<your-username-account> \
|
||||
KUBEFLOW_PASSWORD=<your-password> \
|
||||
./run.sh <example-args>
|
||||
```
|
||||
|
||||
which would mount the current folder (i.e. ./example) onto the containers. We took this as a convenient step as you could change codes with node-red UI and the mounting volume allows the changes to be reflected onto your local file system.
|
||||
|
||||
The example-args allows you to specify which example you want to run, for example
|
||||
|
||||
```
|
||||
./run.sh 0.helloworld
|
||||
```
|
||||
|
||||
would run the `0.helloworld` example.
|
||||
|
||||
##### Visit vis UI
|
||||
|
||||
then you can go to UI, check it out: http://127.0.0.1:1880/
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
#!/usr/bin/env bash
|
||||
|
||||
docker compose build
|
||||
|
|
@ -0,0 +1,33 @@
|
|||
################################################################################
|
||||
# Node-RED Stack or Compose
|
||||
################################################################################
|
||||
# docker stack deploy node-red --compose-file docker-compose-node-red.yml
|
||||
# docker-compose -f docker-compose-node-red.yml -p myNoderedProject up
|
||||
################################################################################
|
||||
version: "3.7"
|
||||
|
||||
services:
|
||||
node-red:
|
||||
image: reg.footprint-ai.com/public/kube-nodered:latest
|
||||
build:
|
||||
context: .
|
||||
dockerfile: Dockerfile
|
||||
labels:
|
||||
# workaround around a docker-compose bug when image is also used by docker run (https://github.com/docker/compose/issues/10162)
|
||||
com.docker.compose.container-number: "1"
|
||||
environment:
|
||||
- TZ=Asia/Taipei
|
||||
- USERDIR=$USERDIR
|
||||
- NODE_RED_CREDENTIAL_SECRET=noderedtutorial
|
||||
- KUBEFLOW_HOST=$KUBEFLOW_HOST
|
||||
- KUBEFLOW_USERNAME=$KUBEFLOW_USERNAME
|
||||
- KUBEFLOW_PASSWORD=$KUBEFLOW_PASSWORD
|
||||
ports:
|
||||
- "1880:1880"
|
||||
networks:
|
||||
- node-red-net
|
||||
volumes:
|
||||
- ./:/data
|
||||
|
||||
networks:
|
||||
node-red-net:
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,127 @@
|
|||
{
|
||||
"name": "node-red",
|
||||
"version": "2.2.3",
|
||||
"description": "Low-code programming for event-driven applications",
|
||||
"homepage": "http://nodered.org",
|
||||
"license": "Apache-2.0",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "https://github.com/node-red/node-red.git"
|
||||
},
|
||||
"private": "true",
|
||||
"scripts": {
|
||||
"start": "node $NODE_OPTIONS node_modules/node-red/red.js",
|
||||
"test": "grunt",
|
||||
"build": "grunt build",
|
||||
"dev": "grunt dev",
|
||||
"build-dev": "grunt build-dev",
|
||||
"docs": "grunt docs"
|
||||
},
|
||||
"contributors": [
|
||||
{
|
||||
"name": "Nick O'Leary"
|
||||
},
|
||||
{
|
||||
"name": "Dave Conway-Jones"
|
||||
}
|
||||
],
|
||||
"dependencies": {
|
||||
"acorn": "8.7.0",
|
||||
"acorn-walk": "8.2.0",
|
||||
"ajv": "8.10.0",
|
||||
"async-mutex": "0.3.2",
|
||||
"basic-auth": "2.0.1",
|
||||
"bcryptjs": "2.4.3",
|
||||
"body-parser": "1.19.1",
|
||||
"cheerio": "1.0.0-rc.10",
|
||||
"clone": "2.1.2",
|
||||
"content-type": "1.0.4",
|
||||
"cookie": "0.4.2",
|
||||
"cookie-parser": "1.4.6",
|
||||
"cors": "2.8.5",
|
||||
"cronosjs": "1.7.1",
|
||||
"denque": "2.0.1",
|
||||
"express": "4.17.2",
|
||||
"express-session": "1.17.2",
|
||||
"form-data": "4.0.0",
|
||||
"fs-extra": "10.0.0",
|
||||
"fs.notify": "0.0.4",
|
||||
"got": "11.8.3",
|
||||
"hash-sum": "2.0.0",
|
||||
"hpagent": "0.1.2",
|
||||
"https-proxy-agent": "5.0.0",
|
||||
"i18next": "21.6.11",
|
||||
"iconv-lite": "0.6.3",
|
||||
"is-utf8": "0.2.1",
|
||||
"js-yaml": "3.14.1",
|
||||
"json-stringify-safe": "5.0.1",
|
||||
"jsonata": "1.8.6",
|
||||
"lodash.clonedeep": "^4.5.0",
|
||||
"media-typer": "1.1.0",
|
||||
"memorystore": "1.6.7",
|
||||
"mime": "3.0.0",
|
||||
"moment-timezone": "0.5.34",
|
||||
"mqtt": "4.3.5",
|
||||
"multer": "1.4.4",
|
||||
"mustache": "4.2.0",
|
||||
"node-red": "2.2.3",
|
||||
"node-red-admin": "^2.2.3",
|
||||
"node-red-contrib-pythonshell": "github:namgk/node-red-contrib-pythonshell",
|
||||
"nopt": "5.0.0",
|
||||
"oauth2orize": "1.11.1",
|
||||
"on-headers": "1.0.2",
|
||||
"passport": "0.5.2",
|
||||
"passport-http-bearer": "1.0.1",
|
||||
"passport-oauth2-client-password": "0.1.2",
|
||||
"raw-body": "2.4.3",
|
||||
"semver": "7.3.5",
|
||||
"tar": "6.1.11",
|
||||
"tough-cookie": "4.0.0",
|
||||
"uglify-js": "3.15.1",
|
||||
"uuid": "8.3.2",
|
||||
"ws": "7.5.6",
|
||||
"xml2js": "0.4.23"
|
||||
},
|
||||
"optionalDependencies": {
|
||||
"bcrypt": "5.0.1"
|
||||
},
|
||||
"devDependencies": {
|
||||
"dompurify": "2.3.6",
|
||||
"grunt": "1.5.2",
|
||||
"grunt-chmod": "~1.1.1",
|
||||
"grunt-cli": "~1.4.3",
|
||||
"grunt-concurrent": "3.0.0",
|
||||
"grunt-contrib-clean": "~2.0.0",
|
||||
"grunt-contrib-compress": "2.0.0",
|
||||
"grunt-contrib-concat": "~1.0.1",
|
||||
"grunt-contrib-copy": "~1.0.0",
|
||||
"grunt-contrib-jshint": "3.1.1",
|
||||
"grunt-contrib-uglify": "5.0.1",
|
||||
"grunt-contrib-watch": "~1.1.0",
|
||||
"grunt-jsdoc": "2.4.1",
|
||||
"grunt-jsdoc-to-markdown": "6.0.0",
|
||||
"grunt-jsonlint": "2.1.3",
|
||||
"grunt-mkdir": "~1.1.0",
|
||||
"grunt-npm-command": "~0.1.2",
|
||||
"grunt-sass": "~3.1.0",
|
||||
"grunt-simple-mocha": "~0.4.1",
|
||||
"grunt-simple-nyc": "^3.0.1",
|
||||
"i18next-http-backend": "1.3.2",
|
||||
"jquery-i18next": "1.2.1",
|
||||
"jsdoc-nr-template": "github:node-red/jsdoc-nr-template",
|
||||
"marked": "4.0.12",
|
||||
"minami": "1.2.3",
|
||||
"mocha": "9.2.0",
|
||||
"node-red-node-test-helper": "^0.2.7",
|
||||
"nodemon": "2.0.15",
|
||||
"proxy": "^1.0.2",
|
||||
"sass": "1.49.7",
|
||||
"should": "13.2.3",
|
||||
"sinon": "11.1.2",
|
||||
"stoppable": "^1.1.0",
|
||||
"supertest": "6.2.2"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=12"
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,15 @@
|
|||
#!/usr/bin/env bash
|
||||
|
||||
target=$1
|
||||
|
||||
if [ "$#" -eq 1 ]
|
||||
then
|
||||
USERDIR=/data/$target
|
||||
else
|
||||
USERDIR=/data/0.helloworld
|
||||
fi
|
||||
|
||||
echo "run with userdir=$USERDIR"
|
||||
|
||||
USERDIR=$USERDIR docker compose up
|
||||
#USERDIR=$USERDIR docker compose convert
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
#!/bin/bash
|
||||
|
||||
trap stop SIGINT SIGTERM
|
||||
|
||||
function stop() {
|
||||
kill $CHILD_PID
|
||||
wait $CHILD_PID
|
||||
}
|
||||
|
||||
/usr/local/bin/node $NODE_OPTIONS node_modules/node-red/red.js --userDir $USERDIR &
|
||||
|
||||
CHILD_PID="$!"
|
||||
|
||||
wait "${CHILD_PID}"
|
||||
Loading…
Reference in New Issue