Merge remote-tracking branch 'upstream/master' into dev-1.19
This commit is contained in:
commit
e2a861c2f9
3
Makefile
3
Makefile
|
|
@ -6,7 +6,8 @@ NETLIFY_FUNC = $(NODE_BIN)/netlify-lambda
|
|||
# but this can be overridden when calling make, e.g.
|
||||
# CONTAINER_ENGINE=podman make container-image
|
||||
CONTAINER_ENGINE ?= docker
|
||||
CONTAINER_IMAGE = kubernetes-hugo
|
||||
IMAGE_VERSION=$(shell scripts/hash-files.sh Dockerfile Makefile | cut -c 1-12)
|
||||
CONTAINER_IMAGE = kubernetes-hugo:v$(HUGO_VERSION)-$(IMAGE_VERSION)
|
||||
CONTAINER_RUN = $(CONTAINER_ENGINE) run --rm --interactive --tty --volume $(CURDIR):/src
|
||||
|
||||
CCRED=\033[0;31m
|
||||
|
|
|
|||
|
|
@ -192,6 +192,7 @@ aliases:
|
|||
- potapy4
|
||||
- dianaabv
|
||||
sig-docs-ru-reviews: # PR reviews for Russian content
|
||||
- Arhell
|
||||
- msheldyakov
|
||||
- aisonaku
|
||||
- potapy4
|
||||
|
|
|
|||
|
|
@ -511,7 +511,7 @@ section#cncf {
|
|||
}
|
||||
|
||||
#desktopKCButton {
|
||||
position: relative;
|
||||
position: absolute;
|
||||
font-size: 18px;
|
||||
background-color: $dark-grey;
|
||||
border-radius: 8px;
|
||||
|
|
|
|||
16
config.toml
16
config.toml
|
|
@ -275,6 +275,7 @@ description = "Production-Grade Container Orchestration"
|
|||
languageName ="English"
|
||||
# Weight used for sorting.
|
||||
weight = 1
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.zh]
|
||||
title = "Kubernetes"
|
||||
|
|
@ -282,6 +283,7 @@ description = "生产级别的容器编排系统"
|
|||
languageName = "中文 Chinese"
|
||||
weight = 2
|
||||
contentDir = "content/zh"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.zh.params]
|
||||
time_format_blog = "2006.01.02"
|
||||
|
|
@ -293,6 +295,7 @@ description = "운영 수준의 컨테이너 오케스트레이션"
|
|||
languageName = "한국어 Korean"
|
||||
weight = 3
|
||||
contentDir = "content/ko"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.ko.params]
|
||||
time_format_blog = "2006.01.02"
|
||||
|
|
@ -304,6 +307,7 @@ description = "プロダクショングレードのコンテナ管理基盤"
|
|||
languageName = "日本語 Japanese"
|
||||
weight = 4
|
||||
contentDir = "content/ja"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.ja.params]
|
||||
time_format_blog = "2006.01.02"
|
||||
|
|
@ -315,6 +319,7 @@ description = "Solution professionnelle d’orchestration de conteneurs"
|
|||
languageName ="Français"
|
||||
weight = 5
|
||||
contentDir = "content/fr"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.fr.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -327,6 +332,7 @@ description = "Orchestrazione di Container in produzione"
|
|||
languageName = "Italiano"
|
||||
weight = 6
|
||||
contentDir = "content/it"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.it.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -339,6 +345,7 @@ description = "Production-Grade Container Orchestration"
|
|||
languageName ="Norsk"
|
||||
weight = 7
|
||||
contentDir = "content/no"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.no.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -351,6 +358,7 @@ description = "Produktionsreife Container-Orchestrierung"
|
|||
languageName ="Deutsch"
|
||||
weight = 8
|
||||
contentDir = "content/de"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.de.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -363,6 +371,7 @@ description = "Orquestación de contenedores para producción"
|
|||
languageName ="Español"
|
||||
weight = 9
|
||||
contentDir = "content/es"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.es.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -375,6 +384,7 @@ description = "Orquestração de contêineres em nível de produção"
|
|||
languageName ="Português"
|
||||
weight = 9
|
||||
contentDir = "content/pt"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.pt.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -387,6 +397,7 @@ description = "Orkestrasi Kontainer dengan Skala Produksi"
|
|||
languageName ="Bahasa Indonesia"
|
||||
weight = 10
|
||||
contentDir = "content/id"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.id.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -399,6 +410,7 @@ description = "Production-Grade Container Orchestration"
|
|||
languageName = "Hindi"
|
||||
weight = 11
|
||||
contentDir = "content/hi"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.hi.params]
|
||||
time_format_blog = "01.02.2006"
|
||||
|
|
@ -410,6 +422,7 @@ description = "Giải pháp điều phối container trong môi trường produc
|
|||
languageName = "Tiếng Việt"
|
||||
contentDir = "content/vi"
|
||||
weight = 12
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.ru]
|
||||
title = "Kubernetes"
|
||||
|
|
@ -417,6 +430,7 @@ description = "Первоклассная оркестрация контейн
|
|||
languageName = "Русский"
|
||||
weight = 12
|
||||
contentDir = "content/ru"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.ru.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
@ -429,6 +443,7 @@ description = "Produkcyjny system zarządzania kontenerami"
|
|||
languageName = "Polski"
|
||||
weight = 13
|
||||
contentDir = "content/pl"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.pl.params]
|
||||
time_format_blog = "01.02.2006"
|
||||
|
|
@ -441,6 +456,7 @@ description = "Довершена система оркестрації конт
|
|||
languageName = "Українська"
|
||||
weight = 14
|
||||
contentDir = "content/uk"
|
||||
languagedirection = "ltr"
|
||||
|
||||
[languages.uk.params]
|
||||
time_format_blog = "02.01.2006"
|
||||
|
|
|
|||
|
|
@ -4,7 +4,6 @@ abstract: "Automatisierte Bereitstellung, Skalierung und Verwaltung von Containe
|
|||
cid: home
|
||||
---
|
||||
|
||||
{{< deprecationwarning >}}
|
||||
|
||||
{{< blocks/section id="oceanNodes" >}}
|
||||
{{% blocks/feature image="flower" %}}
|
||||
|
|
@ -59,4 +58,4 @@ Kubernetes ist Open Source und bietet Dir die Freiheit, die Infrastruktur vor Or
|
|||
|
||||
{{< blocks/kubernetes-features >}}
|
||||
|
||||
{{< blocks/case-studies >}}
|
||||
{{< blocks/case-studies >}}
|
||||
|
|
@ -41,7 +41,6 @@ Kubernetes is open source giving you the freedom to take advantage of on-premise
|
|||
<button id="desktopShowVideoButton" onclick="kub.showVideo()">Watch Video</button>
|
||||
<br>
|
||||
<br>
|
||||
<br>
|
||||
<a href="https://events.linuxfoundation.org/kubecon-cloudnativecon-europe/?utm_source=kubernetes.io&utm_medium=nav&utm_campaign=kccnceu20" button id="desktopKCButton">Attend KubeCon EU virtually on August 17-20, 2020</a>
|
||||
<br>
|
||||
<br>
|
||||
|
|
|
|||
|
|
@ -19,34 +19,20 @@ The entries in the catalog include not just the ability to [start a Kubernetes c
|
|||
|
||||
|
||||
|
||||
-
|
||||
Apache web server
|
||||
-
|
||||
Nginx web server
|
||||
-
|
||||
Crate - The Distributed Database for Docker
|
||||
-
|
||||
GlassFish - Java EE 7 Application Server
|
||||
-
|
||||
Tomcat - An open-source web server and servlet container
|
||||
-
|
||||
InfluxDB - An open-source, distributed, time series database
|
||||
-
|
||||
Grafana - Metrics dashboard for InfluxDB
|
||||
-
|
||||
Jenkins - An extensible open source continuous integration server
|
||||
-
|
||||
MariaDB database
|
||||
-
|
||||
MySql database
|
||||
-
|
||||
Redis - Key-value cache and store
|
||||
-
|
||||
PostgreSQL database
|
||||
-
|
||||
MongoDB NoSQL database
|
||||
-
|
||||
Zend Server - The Complete PHP Application Platform
|
||||
- Apache web server
|
||||
- Nginx web server
|
||||
- Crate - The Distributed Database for Docker
|
||||
- GlassFish - Java EE 7 Application Server
|
||||
- Tomcat - An open-source web server and servlet container
|
||||
- InfluxDB - An open-source, distributed, time series database
|
||||
- Grafana - Metrics dashboard for InfluxDB
|
||||
- Jenkins - An extensible open source continuous integration server
|
||||
- MariaDB database
|
||||
- MySql database
|
||||
- Redis - Key-value cache and store
|
||||
- PostgreSQL database
|
||||
- MongoDB NoSQL database
|
||||
- Zend Server - The Complete PHP Application Platform
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -12,14 +12,10 @@ In many ways the switch from VMs to containers is like the switch from monolithi
|
|||
|
||||
The benefits of thinking in terms of modular containers are enormous, in particular, modular containers provide the following:
|
||||
|
||||
-
|
||||
Speed application development, since containers can be re-used between teams and even larger communities
|
||||
-
|
||||
Codify expert knowledge, since everyone collaborates on a single containerized implementation that reflects best-practices rather than a myriad of different home-grown containers with roughly the same functionality
|
||||
-
|
||||
Enable agile teams, since the container boundary is a natural boundary and contract for team responsibilities
|
||||
-
|
||||
Provide separation of concerns and focus on specific functionality that reduces spaghetti dependencies and un-testable components
|
||||
- Speed application development, since containers can be re-used between teams and even larger communities
|
||||
- Codify expert knowledge, since everyone collaborates on a single containerized implementation that reflects best-practices rather than a myriad of different home-grown containers with roughly the same functionality
|
||||
- Enable agile teams, since the container boundary is a natural boundary and contract for team responsibilities
|
||||
- Provide separation of concerns and focus on specific functionality that reduces spaghetti dependencies and un-testable components
|
||||
|
||||
Building an application from modular containers means thinking about symbiotic groups of containers that cooperate to provide a service, not one container per service. In Kubernetes, the embodiment of this modular container service is a Pod. A Pod is a group of containers that share resources like file systems, kernel namespaces and an IP address. The Pod is the atomic unit of scheduling in a Kubernetes cluster, precisely because the symbiotic nature of the containers in the Pod require that they be co-scheduled onto the same machine, and the only way to reliably achieve this is by making container groups atomic scheduling units.
|
||||
|
||||
|
|
|
|||
|
|
@ -14,121 +14,71 @@ Here are the notes from today's meeting:
|
|||
|
||||
|
||||
|
||||
-
|
||||
Eric Paris: replacing salt with ansible (if we want)
|
||||
- Eric Paris: replacing salt with ansible (if we want)
|
||||
|
||||
-
|
||||
In contrib, there is a provisioning tool written in ansible
|
||||
-
|
||||
The goal in the rewrite was to eliminate as much of the cloud provider stuff as possible
|
||||
-
|
||||
The salt setup does a bunch of setup in scripts and then the environment is setup with salt
|
||||
- In contrib, there is a provisioning tool written in ansible
|
||||
- The goal in the rewrite was to eliminate as much of the cloud provider stuff as possible
|
||||
- The salt setup does a bunch of setup in scripts and then the environment is setup with salt
|
||||
|
||||
-
|
||||
This means that things like generating certs is done differently on GCE/AWS/Vagrant
|
||||
-
|
||||
For ansible, everything must be done within ansible
|
||||
-
|
||||
Background on ansible
|
||||
- This means that things like generating certs is done differently on GCE/AWS/Vagrant
|
||||
- For ansible, everything must be done within ansible
|
||||
- Background on ansible
|
||||
|
||||
-
|
||||
Does not have clients
|
||||
-
|
||||
Provisioner ssh into the machine and runs scripts on the machine
|
||||
-
|
||||
You define what you want your cluster to look like, run the script, and it sets up everything at once
|
||||
-
|
||||
If you make one change in a config file, ansible re-runs everything (which isn’t always desirable)
|
||||
-
|
||||
Uses a jinja2 template
|
||||
-
|
||||
Create machines with minimal software, then use ansible to get that machine into a runnable state
|
||||
- Does not have clients
|
||||
- Provisioner ssh into the machine and runs scripts on the machine
|
||||
- You define what you want your cluster to look like, run the script, and it sets up everything at once
|
||||
- If you make one change in a config file, ansible re-runs everything (which isn’t always desirable)
|
||||
- Uses a jinja2 template
|
||||
- Create machines with minimal software, then use ansible to get that machine into a runnable state
|
||||
|
||||
-
|
||||
Sets up all of the add-ons
|
||||
-
|
||||
Eliminates the provisioner shell scripts
|
||||
-
|
||||
Full cluster setup currently takes about 6 minutes
|
||||
- Sets up all of the add-ons
|
||||
- Eliminates the provisioner shell scripts
|
||||
- Full cluster setup currently takes about 6 minutes
|
||||
|
||||
-
|
||||
CentOS with some packages
|
||||
-
|
||||
Redeploy to the cluster takes 25 seconds
|
||||
-
|
||||
Questions for Eric
|
||||
- CentOS with some packages
|
||||
- Redeploy to the cluster takes 25 seconds
|
||||
- Questions for Eric
|
||||
|
||||
-
|
||||
Where does the provider-specific configuration go?
|
||||
- Where does the provider-specific configuration go?
|
||||
|
||||
-
|
||||
The only network setup that the ansible config does is flannel; you can turn it off
|
||||
-
|
||||
What about init vs. systemd?
|
||||
- The only network setup that the ansible config does is flannel; you can turn it off
|
||||
- What about init vs. systemd?
|
||||
|
||||
-
|
||||
Should be able to support in the code w/o any trouble (not yet implemented)
|
||||
-
|
||||
Discussion
|
||||
- Should be able to support in the code w/o any trouble (not yet implemented)
|
||||
- Discussion
|
||||
|
||||
-
|
||||
Why not push the setup work into containers or kubernetes config?
|
||||
- Why not push the setup work into containers or kubernetes config?
|
||||
|
||||
-
|
||||
To bootstrap a cluster drop a kubelet and a manifest
|
||||
-
|
||||
Running a kubelet and configuring the network should be the only things required. We can cut a machine image that is preconfigured minus the data package (certs, etc)
|
||||
- To bootstrap a cluster drop a kubelet and a manifest
|
||||
- Running a kubelet and configuring the network should be the only things required. We can cut a machine image that is preconfigured minus the data package (certs, etc)
|
||||
|
||||
-
|
||||
The ansible scripts install kubelet & docker if they aren’t already installed
|
||||
-
|
||||
Each OS (RedHat, Debian, Ubuntu) could have a different image. We could view this as part of the build process instead of the install process.
|
||||
-
|
||||
There needs to be solution for bare metal as well.
|
||||
-
|
||||
In favor of the overall goal -- reducing the special configuration in the salt configuration
|
||||
-
|
||||
Everything except the kubelet should run inside a container (eventually the kubelet should as well)
|
||||
- The ansible scripts install kubelet & docker if they aren’t already installed
|
||||
- Each OS (RedHat, Debian, Ubuntu) could have a different image. We could view this as part of the build process instead of the install process.
|
||||
- There needs to be solution for bare metal as well.
|
||||
- In favor of the overall goal -- reducing the special configuration in the salt configuration
|
||||
- Everything except the kubelet should run inside a container (eventually the kubelet should as well)
|
||||
|
||||
-
|
||||
Running in a container doesn’t cut down on the complexity that we currently have
|
||||
-
|
||||
But it does more clearly define the interface about what the code expects
|
||||
-
|
||||
These tools (Chef, Puppet, Ansible) conflate binary distribution with configuration
|
||||
- Running in a container doesn’t cut down on the complexity that we currently have
|
||||
- But it does more clearly define the interface about what the code expects
|
||||
- These tools (Chef, Puppet, Ansible) conflate binary distribution with configuration
|
||||
|
||||
-
|
||||
Containers more clearly separate these problems
|
||||
-
|
||||
The mesos deployment is not completely automated yet, but the mesos deployment is completely different: kubelets get put on top on an existing mesos cluster
|
||||
- Containers more clearly separate these problems
|
||||
- The mesos deployment is not completely automated yet, but the mesos deployment is completely different: kubelets get put on top on an existing mesos cluster
|
||||
|
||||
-
|
||||
The bash scripts allow the mesos devs to see what each cloud provider is doing and re-use the relevant bits
|
||||
-
|
||||
There was a large reverse engineering curve, but the bash is at least readable as opposed to the salt
|
||||
-
|
||||
Openstack uses a different deployment as well
|
||||
-
|
||||
We need a well documented list of steps (e.g. create certs) that are necessary to stand up a cluster
|
||||
- The bash scripts allow the mesos devs to see what each cloud provider is doing and re-use the relevant bits
|
||||
- There was a large reverse engineering curve, but the bash is at least readable as opposed to the salt
|
||||
- Openstack uses a different deployment as well
|
||||
- We need a well documented list of steps (e.g. create certs) that are necessary to stand up a cluster
|
||||
|
||||
-
|
||||
This would allow us to compare across cloud providers
|
||||
-
|
||||
We should reduce the number of steps as much as possible
|
||||
-
|
||||
Ansible has 241 steps to launch a cluster
|
||||
-
|
||||
1.0 Code freeze
|
||||
- This would allow us to compare across cloud providers
|
||||
- We should reduce the number of steps as much as possible
|
||||
- Ansible has 241 steps to launch a cluster
|
||||
- 1.0 Code freeze
|
||||
|
||||
-
|
||||
How are we getting out of code freeze?
|
||||
-
|
||||
This is a topic for next week, but the preview is that we will move slowly rather than totally opening the firehose
|
||||
- How are we getting out of code freeze?
|
||||
- This is a topic for next week, but the preview is that we will move slowly rather than totally opening the firehose
|
||||
|
||||
-
|
||||
We want to clear the backlog as fast as possible while maintaining stability both on HEAD and on the 1.0 branch
|
||||
-
|
||||
The backlog of almost 300 PRs but there are also various parallel feature branches that have been developed during the freeze
|
||||
-
|
||||
Cutting a cherry pick release today (1.0.1) that fixes a few issues
|
||||
- We want to clear the backlog as fast as possible while maintaining stability both on HEAD and on the 1.0 branch
|
||||
- The backlog of almost 300 PRs but there are also various parallel feature branches that have been developed during the freeze
|
||||
- Cutting a cherry pick release today (1.0.1) that fixes a few issues
|
||||
- Next week we will discuss the cadence for patch releases
|
||||
|
|
|
|||
|
|
@ -16,17 +16,10 @@ Fundamentally, ElasticKube delivers a web console for which compliments Kubernet
|
|||
|
||||
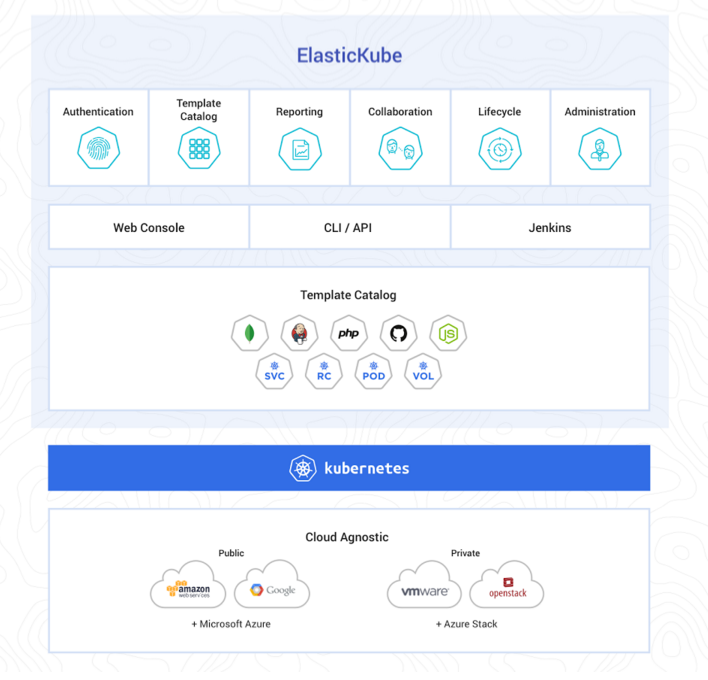
ElasticKube enables organizations to accelerate adoption by developers, application operations and traditional IT operations teams and shares a mutual goal of increasing developer productivity, driving efficiency in container management and promoting the use of microservices as a modern application delivery methodology. When leveraging ElasticKube in your environment, users need to ensure the following technologies are configured appropriately to guarantee everything runs correctly:
|
||||
|
||||
-
|
||||
Configure Google Container Engine (GKE) for cluster installation and management
|
||||
|
||||
-
|
||||
Use Kubernetes to provision the infrastructure and clusters for containers
|
||||
|
||||
-
|
||||
Use your existing tools of choice to actually build your containers
|
||||
-
|
||||
|
||||
Use ElasticKube to run, deploy and manage your containers and services
|
||||
- Configure Google Container Engine (GKE) for cluster installation and management
|
||||
- Use Kubernetes to provision the infrastructure and clusters for containers
|
||||
- Use your existing tools of choice to actually build your containers
|
||||
- Use ElasticKube to run, deploy and manage your containers and services
|
||||
|
||||
[](http://cl.ly/0i3M2L3Q030z/Image%202016-03-11%20at%209.49.12%20AM.png)
|
||||
|
||||
|
|
@ -39,14 +32,10 @@ Getting Started with Kubernetes and ElasticKube
|
|||
|
||||
(this is a 3min walk through video with the following topics)
|
||||
|
||||
1.
|
||||
Deploy ElasticKube to a Kubernetes cluster
|
||||
2.
|
||||
Configuration
|
||||
3.
|
||||
Admin: Setup and invite a user
|
||||
4.
|
||||
Deploy an instance
|
||||
1. Deploy ElasticKube to a Kubernetes cluster
|
||||
2. Configuration
|
||||
3. Admin: Setup and invite a user
|
||||
4. Deploy an instance
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -13,24 +13,18 @@ Today, we want to take you on a short tour explaining the background of our offe
|
|||
|
||||
In mid 2014 we looked at the challenges enterprises are facing in the context of digitization, where traditional enterprises experience that more and more competitors from the IT sector are pushing into the core of their markets. A big part of Fujitsu’s customers are such traditional businesses, so we considered how we could help them and came up with three basic principles:
|
||||
|
||||
-
|
||||
Decouple applications from infrastructure - Focus on where the value for the customer is: the application.
|
||||
-
|
||||
Decompose applications - Build applications from smaller, loosely coupled parts. Enable reconfiguration of those parts depending on the needs of the business. Also encourage innovation by low-cost experiments.
|
||||
-
|
||||
Automate everything - Fight the increasing complexity of the first two points by introducing a high degree of automation.
|
||||
- Decouple applications from infrastructure - Focus on where the value for the customer is: the application.
|
||||
- Decompose applications - Build applications from smaller, loosely coupled parts. Enable reconfiguration of those parts depending on the needs of the business. Also encourage innovation by low-cost experiments.
|
||||
- Automate everything - Fight the increasing complexity of the first two points by introducing a high degree of automation.
|
||||
|
||||
We found that Linux containers themselves cover the first point and touch the second. But at this time there was little support for creating distributed applications and running them managed automatically. We found Kubernetes as the missing piece.
|
||||
**Not a free lunch**
|
||||
|
||||
The general approach of Kubernetes in managing containerized workload is convincing, but as we looked at it with the eyes of customers, we realized that it’s not a free lunch. Many customers are medium-sized companies whose core business is often bound to strict data protection regulations. The top three requirements we identified are:
|
||||
|
||||
-
|
||||
On-premise deployments (with the option for hybrid scenarios)
|
||||
-
|
||||
Efficient operations as part of a (much) bigger IT infrastructure
|
||||
-
|
||||
Enterprise-grade support, potentially on global scale
|
||||
- On-premise deployments (with the option for hybrid scenarios)
|
||||
- Efficient operations as part of a (much) bigger IT infrastructure
|
||||
- Enterprise-grade support, potentially on global scale
|
||||
|
||||
We created Cloud Load Control with these requirements in mind. It is basically a distribution of Kubernetes targeted for on-premise use, primarily focusing on operational aspects of container infrastructure. We are committed to work with the community, and contribute all relevant changes and extensions upstream to the Kubernetes project.
|
||||
**On-premise deployments**
|
||||
|
|
@ -39,12 +33,9 @@ As Kubernetes core developer Tim Hockin often puts it in his[talks](https://spea
|
|||
|
||||
Cloud Load Control addresses these issues. It enables customers to reliably and readily provision a production grade Kubernetes clusters on their own infrastructure, with the following benefits:
|
||||
|
||||
-
|
||||
Proven setup process, lowers risk of problems while setting up the cluster
|
||||
-
|
||||
Reduction of provisioning time to minutes
|
||||
-
|
||||
Repeatable process, relevant especially for large, multi-tenant environments
|
||||
- Proven setup process, lowers risk of problems while setting up the cluster
|
||||
- Reduction of provisioning time to minutes
|
||||
- Repeatable process, relevant especially for large, multi-tenant environments
|
||||
|
||||
Cloud Load Control delivers these benefits for a range of platforms, starting from selected OpenStack distributions in the first versions of Cloud Load Control, and successively adding more platforms depending on customer demand. We are especially excited about the option to remove the virtualization layer and support Kubernetes bare-metal on Fujitsu servers in the long run. By removing a layer of complexity, the total cost to run the system would be decreased and the missing hypervisor would increase performance.
|
||||
|
||||
|
|
@ -53,10 +44,8 @@ Right now we are in the process of contributing a generic provider to set up Kub
|
|||
|
||||
Reducing operation costs is the target of any organization providing IT infrastructure. This can be achieved by increasing the efficiency of operations and helping operators to get their job done. Considering large-scale container infrastructures, we found it is important to differentiate between two types of operations:
|
||||
|
||||
-
|
||||
Platform-oriented, relates to the overall infrastructure, often including various systems, one of which might be Kubernetes.
|
||||
-
|
||||
Application-oriented, focusses rather on a single, or a small set of applications deployed on Kubernetes.
|
||||
- Platform-oriented, relates to the overall infrastructure, often including various systems, one of which might be Kubernetes.
|
||||
- Application-oriented, focusses rather on a single, or a small set of applications deployed on Kubernetes.
|
||||
|
||||
Kubernetes is already great for the application-oriented part. Cloud Load Control was created to help platform-oriented operators to efficiently manage Kubernetes as part of the overall infrastructure and make it easy to execute Kubernetes tasks relevant to them.
|
||||
|
||||
|
|
|
|||
|
|
@ -11,15 +11,12 @@ Hello, and welcome to the second installment of the Kubernetes state of the cont
|
|||
In January, 71% of respondents were currently using containers, in February, 89% of respondents were currently using containers. The percentage of users not even considering containers also shrank from 4% in January to a surprising 0% in February. Will see if that holds consistent in March.Likewise, the usage of containers continued to march across the dev/canary/prod lifecycle. In all parts of the lifecycle, container usage increased:
|
||||
|
||||
|
||||
-
|
||||
Development: 80% -\> 88%
|
||||
-
|
||||
Test: 67% -\> 72%
|
||||
-
|
||||
Pre production: 41% -\> 55%
|
||||
-
|
||||
Production: 50% -\> 62%
|
||||
What is striking in this is that pre-production growth continued, even as workloads were clearly transitioned into true production. Likewise the share of people considering containers for production rose from 78% in January to 82% in February. Again we’ll see if the trend continues into March.
|
||||
- Development: 80% -\> 88%
|
||||
- Test: 67% -\> 72%
|
||||
- Pre production: 41% -\> 55%
|
||||
- Production: 50% -\> 62%
|
||||
|
||||
What is striking in this is that pre-production growth continued, even as workloads were clearly transitioned into true production. Likewise the share of people considering containers for production rose from 78% in January to 82% in February. Again we’ll see if the trend continues into March.
|
||||
|
||||
## Container and cluster sizes
|
||||
|
||||
|
|
|
|||
|
|
@ -215,14 +215,10 @@ CRI is being actively developed and maintained by the Kubernetes [SIG-Node](http
|
|||
|
||||
|
||||
|
||||
-
|
||||
Post issues or feature requests on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
-
|
||||
Join the #sig-node channel on [Slack](https://kubernetes.slack.com/)
|
||||
-
|
||||
Subscribe to the [SIG-Node mailing list](mailto:kubernetes-sig-node@googlegroups.com)
|
||||
-
|
||||
Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- Post issues or feature requests on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
- Join the #sig-node channel on [Slack](https://kubernetes.slack.com/)
|
||||
- Subscribe to the [SIG-Node mailing list](mailto:kubernetes-sig-node@googlegroups.com)
|
||||
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -21,13 +21,8 @@ This progress is our commitment in continuing to make Kubernetes best way to man
|
|||
Connect
|
||||
|
||||
|
||||
-
|
||||
[Download](http://get.k8s.io/) Kubernetes
|
||||
-
|
||||
Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
-
|
||||
Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
-
|
||||
Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
-
|
||||
Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- [Download](http://get.k8s.io/) Kubernetes
|
||||
- Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
- Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
- Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
|
|
|
|||
|
|
@ -36,12 +36,11 @@ Most of the Kubernetes constructs, such as Pods, Services, Labels, etc. work wit
|
|||
|
|
||||
What doesn’t work yet?
|
||||
|
|
||||
-
|
||||
Pod abstraction is not same due to networking namespaces. Net result is that Windows containers in a single POD cannot communicate over localhost. Linux containers can share networking stack by placing them in the same network namespace.
|
||||
-
|
||||
DNS capabilities are not fully implemented
|
||||
-
|
||||
UDP is not supported inside a container
|
||||
|
||||
- Pod abstraction is not same due to networking namespaces. Net result is that Windows containers in a single POD cannot communicate over localhost. Linux containers can share networking stack by placing them in the same network namespace.
|
||||
- DNS capabilities are not fully implemented
|
||||
- UDP is not supported inside a container
|
||||
|
||||
|
|
||||
|
|
||||
When will it be ready for all production workloads (general availability)?
|
||||
|
|
|
|||
|
|
@ -78,11 +78,7 @@ _--Jean-Mathieu Saponaro, Research & Analytics Engineer, Datadog_
|
|||
|
||||
|
||||
|
||||
-
|
||||
Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
-
|
||||
Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
-
|
||||
Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
-
|
||||
Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
- Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
- Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
|
|
|
|||
|
|
@ -113,11 +113,7 @@ _-- Rob Hirschfeld, co-founder of RackN and co-chair of the Cluster Ops SIG_
|
|||
|
||||
|
||||
|
||||
-
|
||||
Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
-
|
||||
Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
-
|
||||
Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
-
|
||||
Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
- Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
- Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
|
|
|
|||
|
|
@ -26,87 +26,69 @@ Kubernetes has also earned the trust of many [Fortune 500 companies](https://kub
|
|||
|
||||
July 2016
|
||||
|
||||
-
|
||||
Kubernauts celebrated its [first anniversary](https://kubernetes.io/blog/2016/07/happy-k8sbday-1) of the Kubernetes 1.0 launch with 20 [#k8sbday](https://twitter.com/search?q=k8sbday&src=typd) parties hosted worldwide
|
||||
-
|
||||
Kubernetes [v1.3 release](https://kubernetes.io/blog/2016/07/kubernetes-1-3-bridging-cloud-native-and-enterprise-workloads/)
|
||||
- Kubernauts celebrated its [first anniversary](https://kubernetes.io/blog/2016/07/happy-k8sbday-1) of the Kubernetes 1.0 launch with 20 [#k8sbday](https://twitter.com/search?q=k8sbday&src=typd) parties hosted worldwide
|
||||
- Kubernetes [v1.3 release](https://kubernetes.io/blog/2016/07/kubernetes-1-3-bridging-cloud-native-and-enterprise-workloads/)
|
||||
|
||||
|
||||
|
||||
September 2016
|
||||
|
||||
-
|
||||
Kubernetes [v1.4 release](https://kubernetes.io/blog/2016/09/kubernetes-1-4-making-it-easy-to-run-on-kuberentes-anywhere/)
|
||||
-
|
||||
Launch of [kubeadm](https://kubernetes.io/blog/2016/09/how-we-made-kubernetes-easy-to-install), a tool that makes Kubernetes dramatically easier to install
|
||||
-
|
||||
[Pokemon Go](https://www.sdxcentral.com/articles/news/google-dealt-pokemon-go-traffic-50-times-beyond-expectations/2016/09/) - one of the largest installs of Kubernetes ever
|
||||
- Kubernetes [v1.4 release](https://kubernetes.io/blog/2016/09/kubernetes-1-4-making-it-easy-to-run-on-kuberentes-anywhere/)
|
||||
- Launch of [kubeadm](https://kubernetes.io/blog/2016/09/how-we-made-kubernetes-easy-to-install), a tool that makes Kubernetes dramatically easier to install
|
||||
- [Pokemon Go](https://www.sdxcentral.com/articles/news/google-dealt-pokemon-go-traffic-50-times-beyond-expectations/2016/09/) - one of the largest installs of Kubernetes ever
|
||||
|
||||
|
||||
|
||||
October 2016
|
||||
|
||||
-
|
||||
Introduced [Kubernetes service partners program](https://kubernetes.io/blog/2016/10/kubernetes-service-technology-partners-program) and a redesigned [partners page](https://kubernetes.io/partners/)
|
||||
- Introduced [Kubernetes service partners program](https://kubernetes.io/blog/2016/10/kubernetes-service-technology-partners-program) and a redesigned [partners page](https://kubernetes.io/partners/)
|
||||
|
||||
|
||||
|
||||
November 2016
|
||||
|
||||
-
|
||||
CloudNativeCon/KubeCon [Seattle](https://www.cncf.io/blog/2016/11/17/cloudnativeconkubecon-2016-wrap/)
|
||||
-
|
||||
Cloud Native Computing Foundation partners with The Linux Foundation to launch a [new Kubernetes certification, training and managed service provider program](https://www.cncf.io/blog/2016/11/08/cncf-partners-linux-foundation-launch-new-kubernetes-certification-training-managed-service-provider-program/)
|
||||
- CloudNativeCon/KubeCon [Seattle](https://www.cncf.io/blog/2016/11/17/cloudnativeconkubecon-2016-wrap/)
|
||||
- Cloud Native Computing Foundation partners with The Linux Foundation to launch a [new Kubernetes certification, training and managed service provider program](https://www.cncf.io/blog/2016/11/08/cncf-partners-linux-foundation-launch-new-kubernetes-certification-training-managed-service-provider-program/)
|
||||
|
||||
|
||||
|
||||
December 2016
|
||||
|
||||
-
|
||||
Kubernetes [v1.5 release](https://kubernetes.io/blog/2016/12/kubernetes-1-5-supporting-production-workloads/)
|
||||
- Kubernetes [v1.5 release](https://kubernetes.io/blog/2016/12/kubernetes-1-5-supporting-production-workloads/)
|
||||
|
||||
|
||||
|
||||
January 2017
|
||||
|
||||
-
|
||||
[Survey](https://www.cncf.io/blog/2017/01/17/container-management-trends-kubernetes-moves-testing-production/) from CloudNativeCon + KubeCon Seattle showcases the maturation of Kubernetes deployment
|
||||
- [Survey](https://www.cncf.io/blog/2017/01/17/container-management-trends-kubernetes-moves-testing-production/) from CloudNativeCon + KubeCon Seattle showcases the maturation of Kubernetes deployment
|
||||
|
||||
|
||||
|
||||
March 2017
|
||||
|
||||
-
|
||||
CloudNativeCon/KubeCon [Europe](https://www.cncf.io/blog/2017/04/17/highlights-cloudnativecon-kubecon-europe-2017/)
|
||||
-
|
||||
Kubernetes[v1.6 release](https://kubernetes.io/blog/2017/03/kubernetes-1-6-multi-user-multi-workloads-at-scale)
|
||||
- CloudNativeCon/KubeCon [Europe](https://www.cncf.io/blog/2017/04/17/highlights-cloudnativecon-kubecon-europe-2017/)
|
||||
- Kubernetes[v1.6 release](https://kubernetes.io/blog/2017/03/kubernetes-1-6-multi-user-multi-workloads-at-scale)
|
||||
|
||||
|
||||
|
||||
April 2017
|
||||
|
||||
-
|
||||
The [Battery Open Source Software (BOSS) Index](https://www.battery.com/powered/boss-index-tracking-explosive-growth-open-source-software/) lists Kubernetes as #33 in the top 100 popular open-source software projects
|
||||
- The [Battery Open Source Software (BOSS) Index](https://www.battery.com/powered/boss-index-tracking-explosive-growth-open-source-software/) lists Kubernetes as #33 in the top 100 popular open-source software projects
|
||||
|
||||
|
||||
|
||||
May 2017
|
||||
|
||||
-
|
||||
[Four Kubernetes projects](https://www.cncf.io/blog/2017/05/04/cncf-brings-kubernetes-coredns-opentracing-prometheus-google-summer-code-2017/) accepted to The [Google Summer of Code](https://developers.google.com/open-source/gsoc/) (GSOC) 2017 program
|
||||
-
|
||||
Stutterstock and Kubernetes appear in [The Wall Street Journal](https://blogs.wsj.com/cio/2017/05/26/shutterstock-ceo-says-new-business-plan-hinged-upon-total-overhaul-of-it/): “On average we [Shutterstock] deploy 45 different releases into production a day using that framework. We use Docker, Kubernetes and Jenkins [to build and run containers and automate development,” said CTO Marty Brodbeck on the company’s IT overhaul and adoption of containerization.
|
||||
- [Four Kubernetes projects](https://www.cncf.io/blog/2017/05/04/cncf-brings-kubernetes-coredns-opentracing-prometheus-google-summer-code-2017/) accepted to The [Google Summer of Code](https://developers.google.com/open-source/gsoc/) (GSOC) 2017 program
|
||||
- Stutterstock and Kubernetes appear in [The Wall Street Journal](https://blogs.wsj.com/cio/2017/05/26/shutterstock-ceo-says-new-business-plan-hinged-upon-total-overhaul-of-it/): “On average we [Shutterstock] deploy 45 different releases into production a day using that framework. We use Docker, Kubernetes and Jenkins [to build and run containers and automate development,” said CTO Marty Brodbeck on the company’s IT overhaul and adoption of containerization.
|
||||
|
||||
|
||||
|
||||
June 2017
|
||||
|
||||
-
|
||||
Kubernetes [v1.7 release](https://kubernetes.io/blog/2017/06/kubernetes-1-7-security-hardening-stateful-application-extensibility-updates)
|
||||
-
|
||||
[Survey](https://www.cncf.io/blog/2017/06/28/survey-shows-kubernetes-leading-orchestration-platform/) from CloudNativeCon + KubeCon Europe shows Kubernetes leading as the orchestration platform of choice
|
||||
-
|
||||
Kubernetes ranked [#4](https://github.com/cncf/velocity) in the [30 highest velocity open source projects](https://www.cncf.io/blog/2017/06/05/30-highest-velocity-open-source-projects/)
|
||||
- Kubernetes [v1.7 release](https://kubernetes.io/blog/2017/06/kubernetes-1-7-security-hardening-stateful-application-extensibility-updates)
|
||||
- [Survey](https://www.cncf.io/blog/2017/06/28/survey-shows-kubernetes-leading-orchestration-platform/) from CloudNativeCon + KubeCon Europe shows Kubernetes leading as the orchestration platform of choice
|
||||
- Kubernetes ranked [#4](https://github.com/cncf/velocity) in the [30 highest velocity open source projects](https://www.cncf.io/blog/2017/06/05/30-highest-velocity-open-source-projects/)
|
||||
|
||||

|
||||
|
||||
|
|
@ -116,8 +98,7 @@ Figure 2: The 30 highest velocity open source projects. Source: [https://github.
|
|||
|
||||
July 2017
|
||||
|
||||
-
|
||||
Kubernauts celebrate the second anniversary of the Kubernetes 1.0 launch with [#k8sbday](https://twitter.com/search?q=k8sbday&src=typd) parties worldwide!
|
||||
- Kubernauts celebrate the second anniversary of the Kubernetes 1.0 launch with [#k8sbday](https://twitter.com/search?q=k8sbday&src=typd) parties worldwide!
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -92,14 +92,10 @@ Usage of UCD in the Process Flow:
|
|||
|
||||
UCD is used for deployment and the end-to end deployment process is automated here. UCD component process involves the following steps:
|
||||
|
||||
-
|
||||
Download the required artifacts for deployment from the Gitlab.
|
||||
-
|
||||
Login to Bluemix and set the KUBECONFIG based on the Kubernetes cluster used for creating the pods.
|
||||
-
|
||||
Create the application pod in the cluster using kubectl create command.
|
||||
-
|
||||
If needed, run a rolling update to update the existing pod.
|
||||
- Download the required artifacts for deployment from the Gitlab.
|
||||
- Login to Bluemix and set the KUBECONFIG based on the Kubernetes cluster used for creating the pods.
|
||||
- Create the application pod in the cluster using kubectl create command.
|
||||
- If needed, run a rolling update to update the existing pod.
|
||||
|
||||
|
||||
|
||||
|
|
@ -150,13 +146,8 @@ To expose our services to outside the cluster, we used Ingress. In IBM Cloud Kub
|
|||
|
||||
|
||||
|
||||
-
|
||||
Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
-
|
||||
Join the community portal for advocates on [K8sPort](http://k8sport.org/)
|
||||
-
|
||||
Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
-
|
||||
Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
-
|
||||
Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
- Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
- Join the community portal for advocates on [K8sPort](http://k8sport.org/)
|
||||
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
- Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
|
|
|
|||
|
|
@ -129,14 +129,10 @@ With our graduation, comes the release of Kompose 1.0.0, here’s what’s new:
|
|||
|
||||
|
||||
|
||||
-
|
||||
Docker Compose Version 3: Kompose now supports Docker Compose Version 3. New keys such as ‘deploy’ now convert to their Kubernetes equivalent.
|
||||
-
|
||||
Docker Push and Build Support: When you supply a ‘build’ key within your `docker-compose.yaml` file, Kompose will automatically build and push the image to the respective Docker repository for Kubernetes to consume.
|
||||
-
|
||||
New Keys: With the addition of version 3 support, new keys such as pid and deploy are supported. For full details on what Kompose supports, view our [conversion document](http://kompose.io/conversion/).
|
||||
-
|
||||
Bug Fixes: In every release we fix any bugs related to edge-cases when converting. This release fixes issues relating to converting volumes with ‘./’ in the target name.
|
||||
- Docker Compose Version 3: Kompose now supports Docker Compose Version 3. New keys such as ‘deploy’ now convert to their Kubernetes equivalent.
|
||||
- Docker Push and Build Support: When you supply a ‘build’ key within your `docker-compose.yaml` file, Kompose will automatically build and push the image to the respective Docker repository for Kubernetes to consume.
|
||||
- New Keys: With the addition of version 3 support, new keys such as pid and deploy are supported. For full details on what Kompose supports, view our [conversion document](http://kompose.io/conversion/).
|
||||
- Bug Fixes: In every release we fix any bugs related to edge-cases when converting. This release fixes issues relating to converting volumes with ‘./’ in the target name.
|
||||
|
||||
|
||||
|
||||
|
|
@ -145,28 +141,18 @@ What’s ahead?
|
|||
As we continue development, we will strive to convert as many Docker Compose keys as possible for all future and current Docker Compose releases, converting each one to their Kubernetes equivalent. All future releases will be backwards-compatible.
|
||||
|
||||
|
||||
-
|
||||
[Install Kompose](https://github.com/kubernetes/kompose/blob/master/docs/installation.md)
|
||||
-
|
||||
[Kompose Quick Start Guide](https://github.com/kubernetes/kompose/blob/master/docs/installation.md)
|
||||
-
|
||||
[Kompose Web Site](http://kompose.io/)
|
||||
-
|
||||
[Kompose Documentation](https://github.com/kubernetes/kompose/tree/master/docs)
|
||||
- [Install Kompose](https://github.com/kubernetes/kompose/blob/master/docs/installation.md)
|
||||
- [Kompose Quick Start Guide](https://github.com/kubernetes/kompose/blob/master/docs/installation.md)
|
||||
- [Kompose Web Site](http://kompose.io/)
|
||||
- [Kompose Documentation](https://github.com/kubernetes/kompose/tree/master/docs)
|
||||
|
||||
|
||||
|
||||
--Charlie Drage, Software Engineer, Red Hat
|
||||
|
||||
|
||||
-
|
||||
Post questions (or answer questions) on[Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
-
|
||||
Join the community portal for advocates on[K8sPort](http://k8sport.org/)
|
||||
-
|
||||
Follow us on Twitter[@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
-
|
||||
Connect with the community on[Slack](http://slack.k8s.io/)
|
||||
-
|
||||
Get involved with the Kubernetes project on[GitHub](https://github.com/kubernetes/kubernetes)
|
||||
-
|
||||
- Post questions (or answer questions) on[Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
- Join the community portal for advocates on[K8sPort](http://k8sport.org/)
|
||||
- Follow us on Twitter[@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- Connect with the community on[Slack](http://slack.k8s.io/)
|
||||
- Get involved with the Kubernetes project on[GitHub](https://github.com/kubernetes/kubernetes)
|
||||
|
|
|
|||
|
|
@ -987,13 +987,8 @@ Rolling updates and roll backs close an important feature gap for DaemonSets and
|
|||
|
||||
|
||||
|
||||
-
|
||||
Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
-
|
||||
Join the community portal for advocates on [K8sPort](http://k8sport.org/)
|
||||
-
|
||||
Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
-
|
||||
Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
-
|
||||
Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
- Post questions (or answer questions) on [Stack Overflow](http://stackoverflow.com/questions/tagged/kubernetes)
|
||||
- Join the community portal for advocates on [K8sPort](http://k8sport.org/)
|
||||
- Follow us on Twitter [@Kubernetesio](https://twitter.com/kubernetesio) for latest updates
|
||||
- Connect with the community on [Slack](http://slack.k8s.io/)
|
||||
- Get involved with the Kubernetes project on [GitHub](https://github.com/kubernetes/kubernetes)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,219 @@
|
|||
---
|
||||
layout: blog
|
||||
title: "Music and math: the Kubernetes 1.17 release interview"
|
||||
date: 2020-07-27
|
||||
---
|
||||
|
||||
**Author**: Adam Glick (Google)
|
||||
|
||||
Every time the Kubernetes release train stops at the station, we like to ask the release lead to take a moment to reflect on their experience. That takes the form of an interview on the weekly [Kubernetes Podcast from Google](https://kubernetespodcast.com/) that I co-host with [Craig Box](https://twitter.com/craigbox). If you're not familiar with the show, every week we summarise the new in the Cloud Native ecosystem, and have an insightful discussion with an interesting guest from the broader Kubernetes community.
|
||||
|
||||
At the time of the 1.17 release in December, we [talked to release team lead Guinevere Saenger](https://kubernetespodcast.com/episode/083-kubernetes-1.17/). We have [shared](https://kubernetes.io/blog/2018/07/16/how-the-sausage-is-made-the-kubernetes-1.11-release-interview-from-the-kubernetes-podcast/) [the](https://kubernetes.io/blog/2019/05/13/cat-shirts-and-groundhog-day-the-kubernetes-1.14-release-interview/) [transcripts](https://kubernetes.io/blog/2019/12/06/when-youre-in-the-release-team-youre-family-the-kubernetes-1.16-release-interview/) of previous interviews on the Kubernetes blog, and we're very happy to share another today.
|
||||
|
||||
Next week we will bring you up to date with the story of Kubernetes 1.18, as we gear up for the release of 1.19 next month. [Subscribe to the show](https://kubernetespodcast.com/subscribe/) wherever you get your podcasts to make sure you don't miss that chat!
|
||||
|
||||
---
|
||||
|
||||
**ADAM GLICK: You have a nontraditional background for someone who works as a software engineer. Can you explain that background?**
|
||||
|
||||
GUINEVERE SAENGER: My first career was as a [collaborative pianist](https://en.wikipedia.org/wiki/Collaborative_piano), which is an academic way of saying "piano accompanist". I was a classically trained pianist who spends most of her time onstage, accompanying other people and making them sound great.
|
||||
|
||||
**ADAM GLICK: Is that the piano equivalent of pair-programming?**
|
||||
|
||||
GUINEVERE SAENGER: No one has said it to me like that before, but all sorts of things are starting to make sense in my head right now. I think that's a really great way of putting it.
|
||||
|
||||
**ADAM GLICK: That's a really interesting background, as someone who also has a background with music. What made you decide to get into software development?**
|
||||
|
||||
GUINEVERE SAENGER: I found myself in a life situation where I needed more stable source of income, and teaching music, and performing for various gig opportunities, was really just not cutting it anymore. And I found myself to be working really, really hard with not much to show for it. I had a lot of friends who were software engineers. I live in Seattle. That's sort of a thing that happens to you when you live in Seattle — you get to know a bunch of software engineers, one way or the other.
|
||||
|
||||
The ones I met were all lovely people, and they said, hey, I'm happy to show you how to program in Python. And so I did that for a bit, and then I heard about this program called [Ada Developers Academy](https://adadevelopersacademy.org/). That's a year long coding school, targeted at women and non-binary folks that are looking for a second career in tech. And so I applied for that.
|
||||
|
||||
**CRAIG BOX: What can you tell us about that program?**
|
||||
|
||||
GUINEVERE SAENGER: It's incredibly selective, for starters. It's really popular in Seattle and has gotten quite a good reputation. It took me three tries to get in. They do two classes a year, and so it was a while before I got my response saying 'congratulations, we are happy to welcome you into Cohort 6'. I think what sets Ada Developers Academy apart from other bootcamp style coding programs are three things, I think? The main important one is that if you get in, you pay no tuition. The entire program is funded by company sponsors.
|
||||
|
||||
**CRAIG BOX: Right.**
|
||||
|
||||
GUINEVERE SAENGER: The other thing that really convinced me is that five months of the 11-month program are an industry internship, which means you get both practical experience, mentorship, and potential job leads at the end of it.
|
||||
|
||||
**CRAIG BOX: So very much like a condensed version of the University of Waterloo degree, where you do co-op terms.**
|
||||
|
||||
GUINEVERE SAENGER: Interesting. I didn't know about that.
|
||||
|
||||
**CRAIG BOX: Having lived in Waterloo for a while, I knew a lot of people who did that. But what would you say the advantages were of going through such a condensed schooling process in computer science?**
|
||||
|
||||
GUINEVERE SAENGER: I'm not sure that the condensed process is necessarily an advantage. I think it's a necessity, though. People have to quit their jobs to go do this program. It's not an evening school type of thing.
|
||||
|
||||
**CRAIG BOX: Right.**
|
||||
|
||||
GUINEVERE SAENGER: And your internship is basically a full-time job when you do it. One thing that Ada was really, really good at is giving us practical experience that directly relates to the workplace. We learned how to use Git. We learned how to design websites using [Rails](https://rubyonrails.org/). And we also learned how to collaborate, how to pair-program. We had a weekly retrospective, so we sort of got a soft introduction to workflows at a real workplace. Adding to that, the internship, and I think the overall experience is a little bit more 'practical workplace oriented' and a little bit less academic.
|
||||
|
||||
When you're done with it, you don't have to relearn how to be an adult in a working relationship with other people. You come with a set of previous skills. There are Ada graduates who have previously been campaign lawyers, and veterinarians, and nannies, cooks, all sorts of people. And it turns out these skills tend to translate, and they tend to matter.
|
||||
|
||||
**ADAM GLICK: With your background in music, what do you think that that allows you to bring to software development that could be missing from, say, standard software development training that people go through?**
|
||||
|
||||
GUINEVERE SAENGER: People tend to really connect the dots when I tell them I used to be a musician. Of course, I still consider myself a musician, because you don't really ever stop being a musician. But they say, 'oh, yeah, music and math', and that's just a similar sort of brain. And that makes so much sense. And I think there's a little bit of a point to that. When you learn a piece of music, you have to start recognizing patterns incredibly quickly, almost intuitively.
|
||||
|
||||
And I think that is the main skill that translates into programming— recognizing patterns, finding the things that work, finding the things that don't work. And for me, especially as a collaborative pianist, it's the communicating with people, the finding out what people really want, where something is going, how to figure out what the general direction is that we want to take, before we start writing the first line of code.
|
||||
|
||||
**CRAIG BOX: In your experience at Ada or with other experiences you've had, have you been able to identify patterns in other backgrounds for people that you'd recommend, 'hey, you're good at music, so therefore you might want to consider doing something like a course in computer science'?**
|
||||
|
||||
GUINEVERE SAENGER: Overall, I think ultimately writing code is just giving a set of instructions to a computer. And we do that in daily life all the time. We give instructions to our kids, we give instructions to our students. We do math, we write textbooks. We give instructions to a room full of people when you're in court as a lawyer.
|
||||
|
||||
Actually, the entrance exam to Ada Developers Academy used to have questions from the [LSAT](https://en.wikipedia.org/wiki/Law_School_Admission_Test) on it to see if you were qualified to join the program. They changed that when I applied, but I think that's a thing that happened at one point. So, overall, I think software engineering is a much more varied field than we give it credit for, and that there are so many ways in which you can apply your so-called other skills and bring them under the umbrella of software engineering.
|
||||
|
||||
**CRAIG BOX: I do think that programming is effectively half art and half science. There's creativity to be applied. There is perhaps one way to solve a problem most efficiently. But there are many different ways that you can choose to express how you compiled something down to that way.**
|
||||
|
||||
GUINEVERE SAENGER: Yeah, I mean, that's definitely true. I think one way that you could probably prove that is that if you write code at work and you're working on something with other people, you can probably tell which one of your co-workers wrote which package, just by the way it's written, or how it is documented, or how it is styled, or any of those things. I really do think that the human character shines through.
|
||||
|
||||
**ADAM GLICK: What got you interested in Kubernetes and open source?**
|
||||
|
||||
GUINEVERE SAENGER: The honest answer is absolutely nothing. Going back to my programming school— and remember that I had to do a five-month internship as part of my training— the way that the internship works is that sponsor companies for the program get interns in according to how much they sponsored a specific cohort of students.
|
||||
|
||||
So at the time, Samsung and SDS offered to host two interns for five months on their [Cloud Native Computing team](https://samsung-cnct.github.io/) and have that be their practical experience. So I go out of a Ruby on Rails full stack web development bootcamp and show up at my internship, and they said, "Welcome to Kubernetes. Try to bring up a cluster." And I said, "Kuber what?"
|
||||
|
||||
**CRAIG BOX: We've all said that on occasion.**
|
||||
|
||||
**ADAM GLICK: Trial by fire, wow.**
|
||||
|
||||
GUINEVERE SAENGER: I will say that that entire team was absolutely wonderful, delightful to work with, incredibly helpful. And I will forever be grateful for all of the help and support that I got in that environment. It was a great place to learn.
|
||||
|
||||
**CRAIG BOX: You now work on GitHub's Kubernetes infrastructure. Obviously, there was GitHub before there was a Kubernetes, so a migration happened. What can you tell us about the transition that GitHub made to running on Kubernetes?**
|
||||
|
||||
GUINEVERE SAENGER: A disclaimer here— I was not at GitHub at the time that the transition to Kubernetes was made. However, to the best of my knowledge, the decision to transition to Kubernetes was made and people decided, yes, we want to try Kubernetes. We want to use Kubernetes. And mostly, the only decision left was, which one of our applications should we move over to Kubernetes?
|
||||
|
||||
**CRAIG BOX: I thought GitHub was written on Rails, so there was only one application.**
|
||||
|
||||
GUINEVERE SAENGER: [LAUGHING] We have a lot of supplementary stuff under the covers.
|
||||
|
||||
**CRAIG BOX: I'm sure.**
|
||||
|
||||
GUINEVERE SAENGER: But yes, GitHub is written in Rails. It is still written in Rails. And most of the supplementary things are currently running on Kubernetes. We have a fair bit of stuff that currently does not run on Kubernetes. Mainly, that is GitHub Enterprise related things. I would know less about that because I am on the platform team that helps people use the Kubernetes infrastructure. But back to your question, leadership at the time decided that it would be a good idea to start with GitHub the Rails website as the first project to move to Kubernetes.
|
||||
|
||||
**ADAM GLICK: High stakes!**
|
||||
|
||||
GUINEVERE SAENGER: The reason for this was that they decided if they were going to not start big, it really wasn't going to transition ever. It was really not going to happen. So they just decided to go all out, and it was successful, for which I think the lesson would probably be commit early, commit big.
|
||||
|
||||
**CRAIG BOX: Are there any other lessons that you would take away or that you've learned kind of from the transition that the company made, and might be applicable to other people who are looking at moving their companies from a traditional infrastructure to a Kubernetes infrastructure?**
|
||||
|
||||
GUINEVERE SAENGER: I'm not sure this is a lesson specifically, but I was on support recently, and it turned out that, due to unforeseen circumstances and a mix of human error, a bunch of the namespaces on one of our Kubernetes clusters got deleted.
|
||||
|
||||
**ADAM GLICK: Oh, my.**
|
||||
|
||||
GUINEVERE SAENGER: It should not have affected any customers, I should mention, at this point. But all in all, it took a few of us a few hours to almost completely recover from this event. I think that, without Kubernetes, this would not have been possible.
|
||||
|
||||
**CRAIG BOX: Generally, deleting something like that is quite catastrophic. We've seen a number of other vendors suffer large outages when someone's done something to that effect, which is why we get [#hugops](https://twitter.com/hashtag/hugops) on Twitter all the time.**
|
||||
|
||||
GUINEVERE SAENGER: People did send me #hugops, that is a thing that happened. But overall, something like this was an interesting stress test and sort of proved that it wasn't nearly as catastrophic as a worst case scenario.
|
||||
|
||||
**CRAIG BOX: GitHub [runs its own data centers](https://githubengineering.com/githubs-metal-cloud/). Kubernetes was largely built for running on the cloud, but a lot of people do choose to run it on their own, bare metal. How do you manage clusters and provisioning of the machinery you run?**
|
||||
|
||||
GUINEVERE SAENGER: When I started, my onboarding project was to deprovision an old cluster, make sure all the traffic got moved to somewhere where it would keep running, provision a new cluster, and then move website traffic onto the new cluster. That was a really exciting onboarding project. At the time, we provisioned bare metal machines using Puppet. We still do that to a degree, but I believe the team that now runs our computing resources actually inserts virtual machines as an extra layer between the bare metal and the Kubernetes nodes.
|
||||
|
||||
Again, I was not intrinsically part of that decision, but my understanding is that it just makes for a greater reliability and reproducibility across the board. We've had some interesting hardware dependency issues come up, and the virtual machines basically avoid those.
|
||||
|
||||
**CRAIG BOX: You've been working with Kubernetes for a couple of years now. How did you get involved in the release process?**
|
||||
|
||||
GUINEVERE SAENGER: When I first started in the project, I started at the [special interest group for contributor experience](https://github.com/kubernetes/community/tree/master/sig-contributor-experience#readme), namely because one of my co-workers at the time, Aaron Crickenberger, was a big Kubernetes community person. Still is.
|
||||
|
||||
**CRAIG BOX: We've [had him on the show](https://kubernetespodcast.com/episode/046-kubernetes-1.14/) for one of these very release interviews!**
|
||||
|
||||
GUINEVERE SAENGER: In fact, this is true! So Aaron and I actually go way back to Samsung SDS. Anyway, Aaron suggested that I should write up a contribution to the Kubernetes project, and I said, me? And he said, yes, of course. You will be [speaking at KubeCon](https://www.youtube.com/watch?v=TkCDUFR6xqw), so you should probably get started with a PR or something. So I tried, and it was really, really hard. And I complained about it [in a public GitHub issue](https://github.com/kubernetes/community/issues/141), and people said, yeah. Yeah, we know it's hard. Do you want to help with that?
|
||||
|
||||
And so I started getting really involved with the [process for new contributors to get started](https://github.com/kubernetes/community/tree/master/contributors/guide) and have successes, kind of getting a foothold into a project that's as large and varied as Kubernetes. From there on, I began to talk to people, get to know people. The great thing about the Kubernetes community is that there is so much mentorship to go around.
|
||||
|
||||
**ADAM GLICK: Right.**
|
||||
|
||||
GUINEVERE SAENGER: There are so many friendly people willing to help. It's really funny when I talk to other people about it. They say, what do you mean, your coworker? And I said, well, he's really a colleague. He really works for another company.
|
||||
|
||||
**CRAIG BOX: He's sort-of officially a competitor.**
|
||||
|
||||
GUINEVERE SAENGER: Yeah.
|
||||
|
||||
**CRAIG BOX: But we're friends.**
|
||||
|
||||
GUINEVERE SAENGER: But he totally helped me when I didn't know how to git patch my borked pull request. So that happened. And eventually, somebody just suggested that I start following along in the release process and shadow someone on their release team role. And that, at the time, was Tim Pepper, who was bug triage lead, and I shadowed him for that role.
|
||||
|
||||
**CRAIG BOX: Another [podcast guest](https://kubernetespodcast.com/episode/010-kubernetes-1.11/) on the interview train.**
|
||||
|
||||
GUINEVERE SAENGER: This is a pattern that probably will make more sense once I explain to you about the shadow process of the release team.
|
||||
|
||||
**ADAM GLICK: Well, let's turn to the Kubernetes release and the release process. First up, what's new in this release of 1.17?**
|
||||
|
||||
GUINEVERE SAENGER: We have only a very few new things. The one that I'm most excited about is that we have moved [IPv4 and IPv6 dual stack](https://github.com/kubernetes/enhancements/issues/563) support to alpha. That is the most major change, and it has been, I think, a year and a half in coming. So this is the very first cut of that feature, and I'm super excited about that.
|
||||
|
||||
**CRAIG BOX: The people who have been promised IPv6 for many, many years and still don't really see it, what will this mean for them?**
|
||||
|
||||
**ADAM GLICK: And most importantly, why did we skip IPv5 support?**
|
||||
|
||||
GUINEVERE SAENGER: I don't know!
|
||||
|
||||
**CRAIG BOX: Please see [the appendix to this podcast](https://softwareengineering.stackexchange.com/questions/185380/ipv4-to-ipv6-where-is-ipv5) for technical explanations.**
|
||||
|
||||
GUINEVERE SAENGER: Having a dual stack configuration obviously enables people to have a much more flexible infrastructure and not have to worry so much about making decisions that will become outdated or that may be over-complicated. This basically means that pods can have dual stack addresses, and nodes can have dual stack addresses. And that basically just makes communication a lot easier.
|
||||
|
||||
**CRAIG BOX: What about features that didn't make it into the release? We had a conversation with Lachie in the [1.16 interview](https://kubernetespodcast.com/episode/072-kubernetes-1.16/), where he mentioned [sidecar containers](https://github.com/kubernetes/enhancements/blob/master/keps/sig-apps/sidecarcontainers.md). They unfortunately didn't make it into that release. And I see now that they haven't made this one either.**
|
||||
|
||||
GUINEVERE SAENGER: They have not, and we are actually currently undergoing an effort of tracking features that flip multiple releases.
|
||||
|
||||
As a community, we need everyone's help. There are a lot of features that people want. There is also a lot of cleanup that needs to happen. And we have started talking at previous KubeCons repeatedly about problems with maintainer burnout, reviewer burnout, have a hard time finding reviews for your particular contributions, especially if you are not an entrenched member of the community. And it has become very clear that this is an area where the entire community needs to improve.
|
||||
|
||||
So the unfortunate reality is that sometimes life happens, and people are busy. This is an open source project. This is not something that has company mandated OKRs. Particularly during the fourth quarter of the year in North America, but around the world, we have a lot of holidays. It is the end of the year. Kubecon North America happened as well. This makes it often hard to find a reviewer in time or to rally the support that you need for your enhancement proposal. Unfortunately, slipping releases is fairly common and, at this point, expected. We started out with having 42 enhancements and [landed with roughly half of that](https://docs.google.com/spreadsheets/d/1ebKGsYB1TmMnkx86bR2ZDOibm5KWWCs_UjV3Ys71WIs/edit#gid=0).
|
||||
|
||||
**CRAIG BOX: I was going to ask about the truncated schedule due to the fourth quarter of the year, where there are holidays in large parts of the world. Do you find that the Q4 release on the whole is smaller than others, if not for the fact that it's some week shorter?**
|
||||
|
||||
GUINEVERE SAENGER: Q4 releases are shorter by necessity because we are trying to finish the final release of the year before the end of the year holidays. Often, releases are under pressure of KubeCons, during which finding reviewers or even finding the time to do work can be hard to do, if you are attending. And even if you're not attending, your reviewers might be attending.
|
||||
|
||||
It has been brought up last year to make the final release more of a stability release, meaning no new alpha features. In practice, for this release, this is actually quite close to the truth. We have four features graduating to beta and most of our features are graduating to stable. I am hoping to use this as a precedent to change our process to make the final release a stability release from here on out. The timeline fits. The past experience fits this model.
|
||||
|
||||
**ADAM GLICK: On top of all of the release work that was going on, there was also KubeCon that happened. And you were involved in the [contributor summit](https://github.com/kubernetes/community/tree/master/events/2019/11-contributor-summit). How was the summit?**
|
||||
|
||||
GUINEVERE SAENGER: This was the first contributor summit where we had an organized events team with events organizing leads, and handbooks, and processes. And I have heard from multiple people— this is just word of mouth— that it was their favorite contributor summit ever.
|
||||
|
||||
**CRAIG BOX: Was someone allocated to hat production? [Everyone had sailor hats](https://flickr.com/photos/143247548@N03/49093218951/).**
|
||||
|
||||
GUINEVERE SAENGER: Yes, the entire event staff had sailor hats with their GitHub handle on them, and it was pretty fantastic. You can probably see me wearing one in some of the pictures from the contributor summit. That literally was something that was pulled out of a box the morning of the contributor summit, and no one had any idea. But at first, I was a little skeptical, but then I put it on and looked at myself in the mirror. And I was like, yes. Yes, this is accurate. We should all wear these.
|
||||
|
||||
**ADAM GLICK: Did getting everyone together for the contributor summit help with the release process?**
|
||||
|
||||
GUINEVERE SAENGER: It did not. It did quite the opposite, really. Well, that's too strong.
|
||||
|
||||
**ADAM GLICK: Is that just a matter of the time taken up?**
|
||||
|
||||
GUINEVERE SAENGER: It's just a completely different focus. Honestly, it helped getting to know people face-to-face that I had currently only interacted with on video. But we did have to cancel the release team meeting the day of the contributor summit because there was kind of no sense in having it happen. We moved it to the Tuesday, I believe.
|
||||
|
||||
**CRAIG BOX: The role of the release team leader has been described as servant leadership. Do you consider the position proactive or reactive?**
|
||||
|
||||
GUINEVERE SAENGER: Honestly, I think that depends on who's the release team lead, right? There are some people who are very watchful and look for trends, trying to detect problems before they happen. I tend to be in that camp, but I also know that sometimes it's not possible to predict things. There will be last minute bugs sometimes, sometimes not. If there is a last minute bug, you have to be ready to be on top of that. So for me, the approach has been I want to make sure that I have my priorities in order and also that I have backups in case I can't be available.
|
||||
|
||||
**ADAM GLICK: What was the most interesting part of the release process for you?**
|
||||
|
||||
GUINEVERE SAENGER: A release lead has to have served in other roles on the release team prior to being release team lead. To me, it was very interesting to see what other roles were responsible for, ones that I hadn't seen from the inside before, such as docs, CI signal. I had helped out with CI signal for a bit, but I want to give a big shout out to CI signal lead, Alena Varkockova, who was able to communicate effectively and kindly with everyone who was running into broken tests, failing tests. And she was very effective in getting all of our tests up and running.
|
||||
|
||||
So that was actually really cool to see. And yeah, just getting to see more of the workings of the team, for me, it was exciting. The other big exciting thing, of course, was to see all the changes that were going in and all the efforts that were being made.
|
||||
|
||||
**CRAIG BOX: The release lead for 1.18 has just been announced as [Jorge Alarcon](https://twitter.com/alejandrox135). What are you going to put in the proverbial envelope as advice for him?**
|
||||
|
||||
GUINEVERE SAENGER: I would want Jorge to be really on top of making sure that every Special Interest Group that enters a change, that has an enhancement for 1.18, is on top of the timelines and is responsive. Communication tends to be a problem. And I had hinted at this earlier, but some enhancements slipped simply because there wasn't enough reviewer bandwidth.
|
||||
|
||||
Greater communication of timelines and just giving people more time and space to be able to get in their changes, or at least, seemingly give them more time and space by sending early warnings, is going to be helpful. Of course, he's going to have a slightly longer release, too, than I did. This might be related to a unique Q4 challenge. Overall, I would encourage him to take more breaks, to rely more on his release shadows, and split out the work in a fashion that allows everyone to have a turn and everyone to have a break as well.
|
||||
|
||||
**ADAM GLICK: What would your advice be to someone who is hearing your experience and is inspired to get involved with the Kubernetes release or contributer process?**
|
||||
|
||||
GUINEVERE SAENGER: Those are two separate questions. So let me tackle the Kubernetes release question first. Kubernetes [SIG Release](https://github.com/kubernetes/sig-release/#readme) has, in my opinion, a really excellent onboarding program for new members. We have what is called the [Release Team Shadow Program](https://github.com/kubernetes/sig-release/blob/master/release-team/shadows.md). We also have the Release Engineering Shadow Program, or the Release Management Shadow Program. Those are two separate subprojects within SIG Release. And each subproject has a team of roles, and each role can have two to four shadows that are basically people who are part of that role team, and they are learning that role as they are doing it.
|
||||
|
||||
So for example, if I am the lead for bug triage on the release team, I may have two, three or four people that I closely work with on the bug triage tasks. These people are my shadows. And once they have served one release cycle as a shadow, they are now eligible to be lead in that role. We have an application form for this process, and it should probably be going up in January. It usually happens the first week of the release once all the release leads are put together.
|
||||
|
||||
**CRAIG BOX: Do you think being a member of the release team is something that is a good first contribution to the Kubernetes project overall?**
|
||||
|
||||
GUINEVERE SAENGER: It depends on what your goals are, right? I believe so. I believe, for me, personally, it has been incredibly helpful looking into corners of the project that I don't know very much about at all, like API machinery, storage. It's been really exciting to look over all the areas of code that I normally never touch.
|
||||
|
||||
It depends on what you want to get out of it. In general, I think that being a release team shadow is a really, really great on-ramp to being a part of the community because it has a paved path solution to contributing. All you have to do is show up to the meetings, ask questions of your lead, who is required to answer those questions.
|
||||
|
||||
And you also do real work. You really help, you really contribute. If you go across the issues and pull requests in the repo, you will see, 'Hi, my name is so-and-so. I am shadowing the CI signal lead for the current release. Can you help me out here?' And that's a valuable contribution, and it introduces people to others. And then people will recognize your name. They'll see a pull request by you, and they're like oh yeah, I know this person. They're legit.
|
||||
|
||||
---
|
||||
|
||||
_[Guinevere Saenger](https://twitter.com/guincodes) is a software engineer for GitHub and served as the Kubernetes 1.17 release team lead._
|
||||
|
||||
_You can find the [Kubernetes Podcast from Google](http://www.kubernetespodcast.com/) at [@KubernetesPod](https://twitter.com/KubernetesPod) on Twitter, and you can [subscribe](https://kubernetespodcast.com/subscribe/) so you never miss an episode._
|
||||
|
|
@ -12,7 +12,7 @@ quote: >
|
|||
Kubernetes enabled the self-healing and immutable infrastructure. We can do faster releases, so our developers are really happy. They can ship our features faster than before, and that makes our clients happier.
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_adform_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/adform/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/adform_logo.png" style="width:15%;margin-bottom:0%" class="header_logo"><br> <div class="subhead">Improving Performance and Morale with Cloud Native
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -66,7 +66,7 @@ The company has a large infrastructure: <a href="https://www.openstack.org/">Ope
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_adform_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/adform/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"The fact that Cloud Native Computing Foundation incubated Kubernetes was a really big point for us because it was vendor neutral. And we can see that a community really gathers around it. Everyone shares their experiences, their knowledge, and the fact that it’s open source, you can contribute."<span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— Edgaras Apšega, IT Systems Engineer, Adform</span>
|
||||
</div>
|
||||
|
|
@ -83,7 +83,7 @@ The first production cluster was launched in the spring of 2018, and is now up t
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_adform_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/adform/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Releases are really nice for them, because they just push their code to Git and that’s it. They don’t have to worry about their virtual machines anymore." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— Andrius Cibulskis, IT Systems Engineer, Adform</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ featured: false
|
|||
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/Adidas1.png')">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/adidas/banner1.png')">
|
||||
<h1> CASE STUDY: adidas</h1>
|
||||
<div class="subhead">Staying True to Its Culture, adidas Got 40% of Its Most Impactful Systems Running on Kubernetes in a Year</div>
|
||||
</div>
|
||||
|
|
@ -33,7 +33,7 @@ featured: false
|
|||
</div>
|
||||
</div>
|
||||
</section>
|
||||
<div class="article image overlay" style="background-image: url('/images/Adidas2.png');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/adidas/banner2.png');">
|
||||
<div class="quotetext">
|
||||
"For me, Kubernetes is a platform made by engineers for engineers. It’s relieving the development team from tasks that they don’t want to do, but at the same time giving the visibility of what is behind the curtain, so they can also control it."
|
||||
<p><div class="quoteauthortext">- FERNANDO CORNAGO, SENIOR DIRECTOR OF PLATFORM ENGINEERING AT ADIDAS</div></p>
|
||||
|
|
@ -74,7 +74,7 @@ featured: false
|
|||
</section>
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/Adidas3.png');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/adidas/banner3.png');">
|
||||
<div class="quotetext">
|
||||
“There is no competitive edge over our competitors like Puma or Nike in running and operating a Kubernetes cluster. Our competitive edge is that we teach our internal engineers how to build cool e-comm stores that are fast, that are resilient, that are running perfectly.” <p><div class="quoteauthortext">- DANIEL EICHTEN, SENIOR DIRECTOR OF PLATFORM ENGINEERING AT ADIDAS</div></p>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_antfinancial_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/antfinancial/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/antfinancial_logo.png" class="header_logo" style="width:20%;margin-bottom:-2.5%"><br> <div class="subhead" style="margin-top:1%">Ant Financial’s Hypergrowth Strategy Using Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -50,7 +50,7 @@ featured: false
|
|||
To address those challenges and provide reliable and consistent services to its customers, Ant Financial embraced <a href="https://www.docker.com/">Docker</a> containerization in 2014. But they soon realized that they needed an orchestration solution for some tens-of-thousands-of-node clusters in the company’s data centers.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_antfinancial_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/antfinancial/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"On Double 11 this year, we had plenty of nodes on Kubernetes, but compared to the whole scale of our infrastructure, this is still in progress."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- RANGER YU, GLOBAL TECHNOLOGY PARTNERSHIP & DEVELOPMENT, ANT FINANCIAL</span>
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ featured: false
|
|||
All core financial systems were containerized by November 2017, and the migration to Kubernetes is ongoing. Ant’s platform also leverages a number of other CNCF projects, including <a href="https://prometheus.io/">Prometheus</a>, <a href="https://opentracing.io/">OpenTracing</a>, <a href="https://coreos.com/etcd/">etcd</a> and <a href="https://coredns.io/">CoreDNS</a>. “On Double 11 this year, we had plenty of nodes on Kubernetes, but compared to the whole scale of our infrastructure, this is still in progress,” says Ranger Yu, Global Technology Partnership & Development.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_antfinancial_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/antfinancial/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We’re very grateful for CNCF and this amazing technology, which we need as we continue to scale globally. We’re definitely embracing the community and open source more in the future." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- HAOJIE HANG, PRODUCT MANAGEMENT, ANT FINANCIAL</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ quote: >
|
|||
We made the right decisions at the right time. Kubernetes and the cloud native technologies are now seen as the de facto ecosystem.
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_appdirect_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/appdirect/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/appdirect_logo.png" class="header_logo" style="margin-bottom:-2%"><br> <div class="subhead" style="margin-top:1%;font-size:0.5em">AppDirect: How AppDirect Supported the 10x Growth of Its Engineering Staff with Kubernetess
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -53,7 +53,7 @@ quote: >
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_appdirect_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/appdirect/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We made the right decisions at the right time. Kubernetes and the cloud native technologies are now seen as the de facto ecosystem. We know where to focus our efforts in order to tackle the new wave of challenges we face as we scale out. The community is so active and vibrant, which is a great complement to our awesome internal team."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Alexandre Gervais, Staff Software Developer, AppDirect
|
||||
</span>
|
||||
|
|
@ -69,7 +69,7 @@ quote: >
|
|||
Lacerte’s strategy ultimately worked because of the very real impact the Kubernetes platform has had to deployment time. Due to less dependency on custom-made, brittle shell scripts with SCP commands, time to deploy a new version has shrunk from 4 hours to a few minutes. Additionally, the company invested a lot of effort to make things self-service for developers. "Onboarding a new service doesn’t require <a href="https://www.atlassian.com/software/jira">Jira</a> tickets or meeting with three different teams," says Lacerte. Today, the company sees 1,600 deployments per week, compared to 1-30 before.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_appdirect_banner4.jpg');width:100%;">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/appdirect/banner4.jpg');width:100%;">
|
||||
<div class="banner4text">
|
||||
"I think our velocity would have slowed down a lot if we didn’t have this new infrastructure."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Pierre-Alexandre Lacerte, Director of Software Development, AppDirect</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ quote: >
|
|||
---
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/babylon4.jpg')">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/babylon/banner4.jpg')">
|
||||
<h1> CASE STUDY: Babylon</h1>
|
||||
<div class="subhead">How Cloud Native Is Enabling Babylon’s Medical AI Innovations</div>
|
||||
</div>
|
||||
|
|
@ -36,7 +36,7 @@ quote: >
|
|||
Instead of waiting hours or days to be able to compute, teams can get access instantaneously. Clinical validations used to take 10 hours; now they are done in under 20 minutes. The portability of the cloud native platform has also enabled Babylon to expand into other countries.</div>
|
||||
</div>
|
||||
</section>
|
||||
<div class="article image overlay" style="background-image: url('/images/babylon1.jpg');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/babylon/banner1.jpg');">
|
||||
<div class="quotetext">
|
||||
“Kubernetes is a great platform for machine learning because it comes with all the scheduling and scalability that you need.”
|
||||
<p><div class="quoteauthortext">- JÉRÉMIE VALLÉE, AI INFRASTRUCTURE LEAD AT BABYLON</div></p>
|
||||
|
|
@ -84,7 +84,7 @@ quote: >
|
|||
</section>
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/babylon2.jpg');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/babylon/banner2.jpg');">
|
||||
<div class="quotetext">
|
||||
“Giving a Kubernetes-based platform to our data scientists has meant increased security, increased innovation through empowerment, and a more affordable health service as our cloud engineers are building an experience that is used by hundreds on a daily basis, rather than supporting specific bespoke use cases.” <p><div class="quoteauthortext">- JEAN MARIE FERDEGUE, DIRECTOR OF PLATFORM OPERATIONS AT BABYLON</div></p>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -14,7 +14,7 @@ quote: >
|
|||
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/booking1.jpg')">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/booking/banner1.jpg')">
|
||||
<h1> CASE STUDY: Booking.com</h1>
|
||||
<div class="subhead">After Learning the Ropes with a Kubernetes Distribution, Booking.com Built a Platform of Its Own</div>
|
||||
</div>
|
||||
|
|
@ -40,7 +40,7 @@ quote: >
|
|||
</div>
|
||||
</div>
|
||||
</section>
|
||||
<div class="article image overlay" style="background-image: url('/images/booking2.JPG');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/booking/banner2.jpg');">
|
||||
<div class="quotetext">
|
||||
“As our users learn Kubernetes and become more sophisticated Kubernetes users, they put pressure on us to provide a better, more native Kubernetes experience, which is great. It’s a super healthy dynamic.”
|
||||
<p><div class="quoteauthortext">- BEN TYLER, PRINCIPAL DEVELOPER, B PLATFORM TRACK AT BOOKING.COM</div></p>
|
||||
|
|
@ -91,7 +91,7 @@ quote: >
|
|||
</section>
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/booking3.jpg');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/booking/banner3.jpg');">
|
||||
<div class="quotetext">
|
||||
“We have a tutorial. You follow the tutorial. Your code is running. Then, it’s business-logic time. The time to gain access to resources is decreased enormously.” <p><div class="quoteauthortext">- BEN TYLER, PRINCIPAL DEVELOPER, B PLATFORM TRACK AT BOOKING.COM</div></p>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -13,7 +13,7 @@ quote: >
|
|||
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/BoozAllen4.jpg')">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/booz-allen/banner4.jpg')">
|
||||
<h1> CASE STUDY: Booz Allen Hamilton</h1>
|
||||
<div class="subhead">How Booz Allen Hamilton Is Helping Modernize the Federal Government with Kubernetes</div>
|
||||
</div>
|
||||
|
|
@ -38,7 +38,7 @@ quote: >
|
|||
</div>
|
||||
</div>
|
||||
</section>
|
||||
<div class="article image overlay" style="background-image: url('/images/BoozAllen2.jpg');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/booz-allen/banner2.jpg');">
|
||||
<div class="quotetext">
|
||||
"When there’s a regulatory change in an agency, or a legislative change in Congress, or an executive order that changes the way you do business, how do I deploy that and get that out to the people who need it rapidly? At the end of the day, that’s the problem we’re trying to help the government solve with tools like Kubernetes."
|
||||
<p><div class="quoteauthortext">- JOSH BOYD, CHIEF TECHNOLOGIST AT BOOZ ALLEN HAMILTON</div></p>
|
||||
|
|
@ -75,7 +75,7 @@ quote: >
|
|||
</section>
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/BoozAllen1.png');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/booz-allen/banner1.png');">
|
||||
<div class="quotetext">
|
||||
"Kubernetes alone enables a dramatic reduction in cost as resources are prioritized to the day’s event" <p><div class="quoteauthortext">- MARTIN FOLKOFF, SENIOR LEAD TECHNOLOGIST AT BOOZ ALLEN HAMILTON</div></p>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ quote: >
|
|||
The CNCF Landscape quickly explains what’s going on in all the different areas from storage to cloud providers to automation and so forth. This is our shopping cart to build a cloud infrastructure. We can go choose from the different aisles.
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_bose_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/bose/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/bose_logo.png" class="header_logo" style="width:20%;margin-bottom:-1.2%"><br> <div class="subhead" style="margin-top:1%">Bose: Supporting Rapid Development for Millions of IoT Products With Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -56,7 +56,7 @@ From the beginning, the team knew it wanted a microservices architecture and pla
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_bose_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/bose/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Everybody on the team thinks in terms of automation, leaning out the processes, getting things done as quickly as possible. When you step back and look at what it means for a 50-plus-year-old speaker company to have that sort of culture, it really is quite incredible, and I think the tools that we use and the foundation that we’ve built with them is a huge piece of that."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Dylan O’Mahony, Cloud Architecture Manager, Bose</span>
|
||||
|
||||
|
|
@ -70,7 +70,7 @@ From the beginning, the team knew it wanted a microservices architecture and pla
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_bose_banner4.jpg');width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/bose/banner4.jpg');width:100%">
|
||||
<div class="banner4text">
|
||||
"The CNCF Landscape quickly explains what’s going on in all the different areas from storage to cloud providers to automation and so forth. This is our shopping cart to build a cloud infrastructure. We can go choose from the different aisles." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Josh West, Lead Cloud Engineer, Bose</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_capitalone_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/capitalone/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/capitalone-logo.png" style="margin-bottom:-2%" class="header_logo"><br> <div class="subhead">Supporting Fast Decisioning Applications with Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -55,7 +55,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_capitalone_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/capitalone/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We want to provide the tools in the same ecosystem, in a consistent way, rather than have a large custom snowflake ecosystem where every tool needs its own custom deployment. Kubernetes gives us the ability to bring all of these together, so the richness of the open source and even the license community dealing with big data can be corralled."
|
||||
|
||||
|
|
@ -69,7 +69,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_capitalone_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/capitalone/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
With Kubernetes, "a team can come to us and we can have them up and running with a basic decisioning app in a fortnight, which before would have taken a whole quarter, if not longer. Kubernetes is a manifold productivity multiplier."
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
logo: cern_featured_logo.png
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_cern_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/cern/banner1.jpg')">
|
||||
<h1> CASE STUDY: CERN<br> <div class="subhead" style="margin-top:1%">CERN: Processing Petabytes of Data More Efficiently with Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -52,7 +52,7 @@ logo: cern_featured_logo.png
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_cern_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/cern/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Before, the tendency was always: ‘I need this, I get a couple of developers, and I implement it.’ Right now it’s ‘I need this, I’m sure other people also need this, so I’ll go and ask around.’ The CNCF is a good source because there’s a very large catalog of applications available. It’s very hard right now to justify developing a new product in-house. There is really no real reason to keep doing that. It’s much easier for us to try it out, and if we see it’s a good solution, we try to reach out to the community and start working with that community." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Ricardo Rocha, Software Engineer, CERN</span>
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ logo: cern_featured_logo.png
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_cern_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/cern/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"With Kubernetes, there’s a well-established technology and a big community that we can contribute to. It allows us to do our physics analysis without having to focus so much on the lower level software. This is just exciting. We are looking forward to keep contributing to the community and collaborating with everyone."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Ricardo Rocha, Software Engineer, CERN</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_chinaunicom_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/chinaunicom/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/chinaunicom_logo.png" class="header_logo" style="width:25%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%;line-height:1.4em">China Unicom: How China Unicom Leveraged Kubernetes to Boost Efficiency<br>and Lower IT Costs
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -51,7 +51,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_chinaunicom_banner3.jpg');width:100%;padding-left:0;">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/chinaunicom/banner3.jpg');width:100%;padding-left:0;">
|
||||
<div class="banner3text">
|
||||
"We could never imagine we can achieve this scalability in such a short time."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Chengyu Zhang, Group Leader of Platform Technology R&D, China Unicom</span>
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_chinaunicom_banner4.jpg');width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/chinaunicom/banner4.jpg');width:100%">
|
||||
<div class="banner4text">
|
||||
"This technology is relatively complicated, but as long as developers get used to it, they can enjoy all the benefits." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Jie Jia, Member of Platform Technology R&D, China Unicom</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_montreal_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/montreal/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/montreal_logo.png" class="header_logo" style="width:20%;margin-bottom:-1.2%"><br> <div class="subhead" style="margin-top:1%">City of Montréal - How the City of Montréal Is Modernizing Its 30-Year-Old, Siloed Architecture with Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -50,7 +50,7 @@ featured: false
|
|||
The first step to modernize the architecture was containerization. “We based our effort on the new trends; we understood the benefits of immutability and deployments without downtime and such things,” says Solutions Architect Marc Khouzam. The team started with a small Docker farm with four or five servers, with Rancher for providing access to the Docker containers and their logs and Jenkins for deployment.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_montreal_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/montreal/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Getting a project running in Kubernetes is entirely dependent on how long you need to program the actual software. It’s no longer dependent on deployment. Deployment is so fast that it’s negligible."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- MARC KHOUZAM, SOLUTIONS ARCHITECT, CITY OF MONTRÉAL</span>
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ featured: false
|
|||
Another important factor in the decision was vendor neutrality. “As a government entity, it is essential for us to be neutral in our selection of products and providers,” says Thibault. “The independence of the Cloud Native Computing Foundation from any company provides this.”
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_montreal_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/montreal/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Kubernetes has been great. It’s been stable, and it provides us with elasticity, resilience, and robustness. While re-architecting for Kubernetes, we also benefited from the monitoring and logging aspects, with centralized logging, Prometheus logging, and Grafana dashboards. We have enhanced visibility of what’s being deployed." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- MORGAN MARTINET, ENTERPRISE ARCHITECT, CITY OF MONTRÉAL</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ quote: >
|
|||
---
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/Denso2.jpg')">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/denso/banner2.jpg')">
|
||||
<h1> CASE STUDY: Denso</h1>
|
||||
<div class="subhead">How DENSO Is Fueling Development on the Vehicle Edge with Kubernetes</div>
|
||||
</div>
|
||||
|
|
@ -36,7 +36,7 @@ quote: >
|
|||
Critical layer features can take 2-3 years to implement in the traditional, waterfall model of development at DENSO. With the Kubernetes platform and agile methods, there’s a 2-month development cycle for non-critical software. Now, ten new applications are released a year, and a new prototype is introduced every week. "By utilizing Kubernetes managed services, such as GKE/EKS/AKS, we can unify the environment and simplify our maintenance operation," says Koizumi.
|
||||
</div>
|
||||
</section>
|
||||
<div class="article image overlay" style="background-image: url('/images/Denso1.png');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/denso/banner1.png');">
|
||||
<div class="quotetext">
|
||||
"Another disruptive innovation is coming, so to survive in this situation, we need to change our culture."
|
||||
<p><div class="quoteauthortext">- SEIICHI KOIZUMI, R&D PRODUCT MANAGER, DIGITAL INNOVATION DEPARTMENT AT DENSO</div></p>
|
||||
|
|
@ -79,7 +79,7 @@ quote: >
|
|||
</section>
|
||||
|
||||
|
||||
<div class="article image overlay" style="background-image: url('/images/Denso4.jpg');">
|
||||
<div class="article image overlay" style="background-image: url('/images/case-studies/denso/banner4.jpg');">
|
||||
<div class="quotetext">
|
||||
"By utilizing Kubernetes managed services, such as GKE/EKS/AKS, we can unify the environment and simplify our maintenance operation." <p><div class="quoteauthortext">- SEIICHI KOIZUMI, R&D PRODUCT MANAGER, DIGITAL INNOVATION DEPARTMENT AT DENSO</div></p>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ logo: ibm_featured_logo.svg
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_ibm_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/ibm/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/ibm_logo.png" class="header_logo" style="width:10%"><br> <div class="subhead">Building an Image Trust Service on Kubernetes with Notary and TUF</div></h1>
|
||||
|
||||
</div>
|
||||
|
|
@ -58,7 +58,7 @@ The availability of image signing "is a huge benefit to security-conscious custo
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_ibm_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/ibm/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Image signing is one key part of our Kubernetes container service offering, and our container registry team saw Notary as the de facto way to implement that capability in the current Docker and container ecosystem"<span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br><br>- Michael Hough, a software developer with the IBM Cloud Container Registry team</span>
|
||||
</div>
|
||||
|
|
@ -75,7 +75,7 @@ The availability of image signing "is a huge benefit to security-conscious custo
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_ibm_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/ibm/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"With our IBM Cloud Kubernetes as-a-service offering and the admission controller we have made available, it allows both IBM services as well as customers of the IBM public cloud to use security policies to control service deployment."<span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br><br>- Michael Hough, a software developer with the IBM Cloud Container Registry team</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ quote: >
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_ing_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/ing/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/ing_logo.png" style="margin-bottom:-1.5%;" class="header_logo"><br> <div class="subhead"> Driving Banking Innovation with Cloud Native
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -58,7 +58,7 @@ quote: >
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_ing_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/ing/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We decided to standardize ING on a Kubernetes framework." Everything is run on premise due to banking regulations, he adds, but "we will be building an internal public cloud. We are trying to get on par with what public clouds are doing. That’s one of the reasons we got Kubernetes."
|
||||
<span style="font-size:16px;text-transform:uppercase;letter-spacing:0.1em;"><br><br>— Thijs Ebbers, Infrastructure Architect, ING</span>
|
||||
|
|
@ -72,7 +72,7 @@ quote: >
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_ing_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/ing/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We have to run the complete platform of services we need, many routing from different places. We need this Kubernetes framework for deploying the containers, with all those components, monitoring, logging. It’s complex." <span style="font-size:16px;text-transform:uppercase;letter-spacing:0.1em;"><br><br>— Onno Van der Voort, Infrastructure Architect, ING</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_jdcom_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/jdcom/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/jdcom_logo.png" class="header_logo" style="width:17%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%">JD.com: How JD.com Pioneered Kubernetes for E-Commerce at Hyperscale
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -51,7 +51,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_jdcom_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/jdcom/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We customized Kubernetes and built a modern system on top of it. This entire ecosystem of Kubernetes plus our own optimizations have helped us save costs and time."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- HAIFENG LIU, CHIEF ARCHITECT, JD.com</span>
|
||||
|
||||
|
|
@ -67,7 +67,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_jdcom_banner4.jpg');width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/jdcom/banner4.jpg');width:100%">
|
||||
<div class="banner4text">
|
||||
"My advice is first you need to combine this technology with your own businesses, and the second is you need clear goals. You cannot just use the technology because others are using it. You need to consider your own objectives." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- HAIFENG LIU, CHIEF ARCHITECT, JD.com</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ logo: naic_featured_logo.png
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_naic_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/naic/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/naic_logo.png" class="header_logo" style="width:18%"><br> <div class="subhead" style="margin-top:1%">A Culture and Technology Transition Enabled by Kubernetes</div></h1>
|
||||
|
||||
</div>
|
||||
|
|
@ -59,7 +59,7 @@ In addition, NAIC is onboarding teams to the new platform, and those teams have
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_naic_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/naic/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"In our experience, vendor lock-in and tooling that is highly specific results in less resilient technology with fewer minds working to solve problems and grow the community." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Dan Barker, Chief Enterprise Architect, NAIC</span>
|
||||
</div>
|
||||
|
|
@ -77,7 +77,7 @@ As for other CNCF projects, NAIC is using Prometheus on a small scale and hopes
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_naic_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/naic/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We knew that Kubernetes had become the de facto standard for container orchestration. Two major factors for selecting this were the three major cloud vendors hosting their own versions and having it hosted in a neutral party as fully open source."<span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br><br>- Dan Barker, Chief Enterprise Architect, NAIC</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_nav_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/nav/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/nav_logo.png" class="header_logo" style="width:15%"><br> <div class="subhead" style="margin-top:1%">How A Startup Reduced Its Infrastructure Costs by 50% With Kubernetes
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -52,7 +52,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_nav_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/nav/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"The community is absolutely vital: being able to pass ideas around, talk about a lot of the similar challenges that we’re all facing, and just get help. I like that we’re able to tackle the same problems for different reasons but help each other along the way."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Travis Jeppson, Director of Engineering, Nav</span>
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ featured: false
|
|||
Jeppson’s four-person Engineering Services team got Kubernetes up and running in six months (they decided to use <a href="http://kubespray.io/">Kubespray</a> to spin up clusters), and the full migration of Nav’s 25 microservices and one primary monolith was completed in another six months. “We couldn’t rewrite everything; we couldn’t stop,” he says. “We had to stay up, we had to stay available, and we had to have minimal amount of downtime. So we got really comfortable around our building pipeline, our metrics and logging, and then around Kubernetes itself: how to launch it, how to upgrade it, how to service it. And we moved little by little.”
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_nav_banner4.jpg')" style="width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/nav/banner4.jpg')" style="width:100%">
|
||||
<div class="banner4text">
|
||||
“Kubernetes has brought so much value to Nav by allowing all of these new freedoms that we had just never had before.” <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Travis Jeppson, Director of Engineering, Nav</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -6,7 +6,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
featured: false
|
||||
---
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_nerdalize_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/nerdalize/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/nerdalize_logo.png" class="header_logo" style="width:25%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%">Nerdalize: Providing Affordable and Sustainable Cloud Hosting with Kubernetes
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -47,7 +47,7 @@ featured: false
|
|||
After trying to develop its own scheduling system using another open source tool, Nerdalize found Kubernetes. “Kubernetes provided us with more functionality out of the gate,” says van der Veer.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_nerdalize_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/nerdalize/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
“We always try to get a working version online first, like minimal viable products, and then move to stabilize that,” says van der Veer. “And I think that these kinds of day-two problems are now immediately solved. The rapid prototyping we saw internally is a very valuable aspect of Kubernetes.”<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>— AD VAN DER VEER, PRODUCT ENGINEER, NERDALIZE</span>
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ featured: false
|
|||
Not to mention the 40% cost savings. “Every euro that we have to invest for licensing of software that’s not open source comes from that 40%,” says van der Veer. If Nerdalize had used a non-open source orchestration platform instead of Kubernetes, “that would reduce our cost savings proposition to like 30%. Kubernetes directly allows us to have this business model and this strategic advantage.”
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_nerdalize_banner4.jpg')" style="width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/nerdalize/banner4.jpg')" style="width:100%">
|
||||
<div class="banner4text">
|
||||
“One of our customers used to spend up to a day setting up the virtual machines, network and software every time they wanted to run a project in the cloud. On our platform, with Docker and Kubernetes, customers can have their projects running in a couple of minutes.”
|
||||
<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- MAAIKE STOOPS, CUSTOMER EXPERIENCE QUEEN, NERDALIZE</span>
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ featured: false
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_netease_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/netease/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/netease_logo.png" class="header_logo" style="width:22%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%"> How NetEase Leverages Kubernetes to Support Internet Business Worldwide</div></h1>
|
||||
|
||||
</div>
|
||||
|
|
@ -47,7 +47,7 @@ featured: false
|
|||
After considering building its own orchestration solution, NetEase decided to base its private cloud platform on <a href="https://kubernetes.io/">Kubernetes</a>. The fact that the technology came out of Google gave the team confidence that it could keep up with NetEase’s scale. “After our 2-to-3-month evaluation, we believed it could satisfy our needs,” says Feng.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_netease_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/netease/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We leveraged the programmability of Kubernetes so that we can build a platform to satisfy the needs of our internal customers for upgrades and deployment."
|
||||
<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Feng Changjian, Architect for NetEase Cloud and Container Service, NetEase</span>
|
||||
|
|
@ -60,7 +60,7 @@ featured: false
|
|||
And the team is continuing to make improvements. For example, the e-commerce part of the business needs to leverage mixed deployments, which in the past required using two separate platforms: the infrastructure-as-a-service platform and the Kubernetes platform. More recently, NetEase has created a cross-platform application that enables using both with one-command deployment.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_netease_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/netease/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"As long as a company has a mature team and enough developers, I think Kubernetes is a very good technology that can help them."
|
||||
<span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br><br>- Li Lanqing, Kubernetes Developer, NetEase</span>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
---
|
||||
|
||||
<div class="banner1" style="padding-left:8% !important;background-image: url('/images/CaseStudy_newyorktimes_banner1.jpg')">
|
||||
<div class="banner1" style="padding-left:8% !important;background-image: url('/images/case-studies/newyorktimes/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/newyorktimes_logo.png" class="header_logo"><br> <div class="subhead">The New York Times: From Print to the Web to Cloud Native
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -64,7 +64,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_newyorktimes_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/newyorktimes/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We had some internal tooling that attempted to do what Kubernetes does for containers, but for VMs. We asked why are we building and maintaining these tools ourselves?"
|
||||
</div>
|
||||
|
|
@ -79,7 +79,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_newyorktimes_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/newyorktimes/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Right now, every team is running a small Kubernetes cluster, but it would be nice if we could all live in a larger ecosystem," says Kapadia. "Then we can harness the power of things like service mesh proxies that can actually do a lot of instrumentation between microservices, or service-to-service orchestration. Those are the new things that we want to experiment with as we go forward."
|
||||
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ logo: nokia_featured_logo.png
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_nokia_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/nokia/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/nokia_logo.png" class="header_logo" style="width:20%;margin-bottom:-2.2%"><br> <div class="subhead" style="margin-top:1%">Nokia: Enabling 5G and DevOps at a Telecom Company with Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -51,7 +51,7 @@ logo: nokia_featured_logo.png
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_nokia_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/nokia/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Having the community and CNCF around Kubernetes is not only important for having a connection to other companies who are using Kubernetes and a forum where you can ask or discuss features of Kubernetes. But as a company who would like to contribute to Kubernetes, it was very important to have a CLA (Contributors License Agreement) which is connected to the CNCF and not to a particular company. That was a critical step for us to start contributing to Kubernetes and Helm."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Gergely Csatari, Senior Open Source Engineer, Nokia</span>
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ logo: nokia_featured_logo.png
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_nokia_banner4.jpg')" style="width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/nokia/banner4.jpg')" style="width:100%">
|
||||
<div class="banner4text">
|
||||
"Kubernetes opened the window to all of these open source projects instead of implementing everything in house. Our engineers can focus more on the application level, which is actually the thing what we are selling, and not on the infrastructure level. For us, the most important thing about Kubernetes is it allows us to focus on value creation of our business." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Gergely Csatari, Senior Open Source Engineer, Nokia</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_nordstrom_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/nordstrom/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/nordstrom_logo.png" class="header_logo" style="margin-bottom:-1.5% !important;width:20% !important;"><br> <div class="subhead">Finding Millions in Potential Savings in a Tough Retail Climate
|
||||
|
||||
|
||||
|
|
@ -60,7 +60,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_nordstrom_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/nordstrom/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We made a bet that Kubernetes was going to take off, informed by early indicators of community support and project velocity, so we rebuilt our system with Kubernetes at the core,"
|
||||
</div>
|
||||
|
|
@ -77,7 +77,7 @@ The benefits were immediate for the teams that came on board. "Teams running on
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_nordstrom_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/nordstrom/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Teams running on our Kubernetes cluster loved the fact that they had fewer issues to worry about. They didn’t need to manage infrastructure or operating systems," says Grigoriu. "Early adopters loved the declarative nature of Kubernetes. They loved the reduced surface area they had to deal with."
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_northwestern_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/northwestern/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/northwestern_logo.png" style="margin-bottom:-1%" class="header_logo"><br> <div class="subhead">Cloud Native at Northwestern Mutual
|
||||
|
||||
|
||||
|
|
@ -22,7 +22,7 @@ css: /css/style_case_studies.css
|
|||
<div class="cols">
|
||||
<div class="col1">
|
||||
<h2>Challenge</h2>
|
||||
In the spring of 2015, Northwestern Mutual acquired a fintech startup, LearnVest, and decided to take "Northwestern Mutual’s leading products and services and meld it with LearnVest’s digital experience and innovative financial planning platform," says Brad Williams, Director of Engineering for Client Experience, Northwestern Mutual. The company’s existing infrastructure had been optimized for batch workflows hosted on on-prem networks; deployments were very traditional, focused on following a process instead of providing deployment agility. "We had to build a platform that was elastically scalable, but also much more responsive, so we could quickly get data to the client website so our end-customers have the experience they expect," says Williams.
|
||||
In the spring of 2015, Northwestern Mutual acquired a fintech startup, LearnVest, and decided to take "Northwestern Mutual’s leading products and services and meld it with LearnVest’s digital experience and innovative financial planning platform," says Brad Williams, Director of Engineering for Client Experience, Northwestern Mutual. The company’s existing infrastructure had been optimized for batch workflows hosted on on-prem networks; deployments were very traditional, focused on following a process instead of providing deployment agility. "We had to build a platform that was elastically scalable, but also much more responsive, so we could quickly get data to the client website so our end-customers have the experience they expect," says Williams.
|
||||
<br>
|
||||
<h2>Solution</h2>
|
||||
The platform team came up with a plan for using the public cloud (AWS), Docker containers, and Kubernetes for orchestration. "Kubernetes gave us that base framework so teams can be very autonomous in what they’re building and deliver very quickly and frequently," says Northwestern Mutual Cloud Native Engineer Frank Greco Jr. The team also built and open-sourced <a href="https://github.com/northwesternmutual/kanali">Kanali</a>, a Kubernetes-native API management tool that uses OpenTracing, Jaeger, and gRPC.
|
||||
|
|
@ -53,7 +53,7 @@ In order to give the company’s 4.5 million clients the digital experience they
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_northwestern_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/northwestern/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Kubernetes has definitely been the right choice for us. It gave us that base framework so teams can be autonomous in what they’re building and deliver very quickly and frequently."
|
||||
|
||||
|
|
@ -63,12 +63,12 @@ In order to give the company’s 4.5 million clients the digital experience they
|
|||
<div class="fullcol">
|
||||
Williams and the rest of the platform team decided that the first step would be to start moving from private data centers to AWS. With a new microservice architecture in mind—and the freedom to implement what was best for the organization—they began using Docker containers. After looking into the various container orchestration options, they went with Kubernetes, even though it was still in beta at the time. "There was some debate whether we should build something ourselves, or just leverage that product and evolve with it," says Northwestern Mutual Cloud Native Engineer Frank Greco Jr. "Kubernetes has definitely been the right choice for us. It gave us that base framework so teams can be autonomous in what they’re building and deliver very quickly and frequently."<br><br>
|
||||
As early adopters, the team had to do a lot of work with Ansible scripts to stand up the cluster. "We had a lot of hard security requirements given the nature of our business," explains Bryan Pfremmer, App Platform Teams Manager, Northwestern Mutual. "We found ourselves running a configuration that very few other people ever tried." The client experience group was the first to use the new platform; today, a few hundred of the company’s 1,500 engineers are using it and more are eager to get on board.
|
||||
The results have been dramatic. Before, infrastructure deployments could take two weeks; now, it is done in a matter of minutes. Now with a focus on Infrastructure automation, and self-service, "You can take an app to production in that same day if you want to," says Pfremmer.
|
||||
The results have been dramatic. Before, infrastructure deployments could take two weeks; now, it is done in a matter of minutes. Now with a focus on Infrastructure automation, and self-service, "You can take an app to production in that same day if you want to," says Pfremmer.
|
||||
|
||||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_northwestern_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/northwestern/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Now, developers have autonomy, they can use this whenever they want, however they want. It becomes more valuable the more instrumentation downstream that happens, as we mature in it."
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ weight: 4
|
|||
quote: >
|
||||
People at Ocado Technology have been quite amazed. They ask, ‘Can we do this on a Dev cluster?’ and 10 minutes later we have rolled out something that is deployed across the cluster. The speed from idea to implementation to deployment is amazing.
|
||||
---
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_ocado_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/ocado/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/ocado_logo.png" class="header_logo"><br> <div class="subhead">Ocado: Running Grocery Warehouses with a Cloud Native Platform</div></h1>
|
||||
|
||||
</div>
|
||||
|
|
@ -32,7 +32,7 @@ quote: >
|
|||
</div>
|
||||
|
||||
<div class="col2">
|
||||
|
||||
|
||||
|
||||
<h2>Impact</h2>
|
||||
With Kubernetes, "the speed from idea to implementation to deployment is amazing," says Bryant. "I’ve seen features go from development to production inside of a week now. In the old world, a new application deployment could easily take over a month." And because there are no longer restrictive deployment windows in the warehouses, the rate of deployments has gone from as few as two per week to dozens per week. Ocado has also achieved cost savings because Kubernetes gives the team the ability to have more fine-grained resource allocation. Says DevOps Team Leader Kevin McCormack: "We have more confidence in the resource allocation/separation features of Kubernetes, so we have been able to migrate from around 10 fleet clusters to one Kubernetes cluster." The team also uses <a href="https://prometheus.io/">Prometheus</a> and <a href="https://grafana.com/">Grafana</a> to visualize resource allocation, and makes the data available to developers. "The increased visibility offered by Prometheus means developers are more aware of what they are using and how their use impacts others, especially since we now have one shared cluster," says McCormack. "I’d estimate that we use about 15-25% less hardware resources to host the same applications in Kubernetes in our test environments."
|
||||
|
|
@ -54,7 +54,7 @@ Bryant had already been using Kubernetes with <a href="https://www.codeforlife.e
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_ocado_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/ocado/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We were looking for a platform with wide adoption, and that was where the momentum was, the two paths converged, and we didn’t even go through any proof-of-concept stage. The Code for Life work served that purpose," <span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br><br>- Kevin McCormack, DevOps Team Leader, Ocado</span>
|
||||
</div>
|
||||
|
|
@ -68,7 +68,7 @@ Bryant had already been using Kubernetes with <a href="https://www.codeforlife.e
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_ocado_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/ocado/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"The unified API of Kubernetes means this is all in one place, and it’s one flow for approval and rollout. I’ve seen features go from development to production inside of a week now. In the old world, a new application deployment could easily take over a month." <span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br><br>- Mike Bryant, Platform Engineer, Ocado</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_openAI_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/openAI/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/openAI_logo.png" style="margin-bottom:-1%" class="header_logo"><br> <div class="subhead">Launching and Scaling Up Experiments, Made Simple
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -56,7 +56,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_openAI_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/openAI/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
OpenAI’s experiments take advantage of Kubernetes’ benefits, including portability. "Because Kubernetes provides a consistent API, we can move our research experiments very easily between clusters..."
|
||||
|
||||
|
|
@ -69,7 +69,7 @@ css: /css/style_case_studies.css
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_openAI_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/openAI/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"One of our researchers who is working on a new distributed training system has been able to get his experiment running in two or three days," says Berner. "In a week or two he scaled it out to hundreds of GPUs. Previously, that would have easily been a couple of months of work."
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ featured: false
|
|||
quote: >
|
||||
We’re already seeing tremendous benefits with Kubernetes—improved engineering productivity, faster delivery of applications and a simplified infrastructure. But this is just the beginning. Kubernetes will help transform the way that educational content is delivered online.
|
||||
---
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_pearson_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/pearson/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/pearson_logo.png" style="margin-bottom:-1.5%;" class="header_logo"><br> <div class="subhead">Reinventing the World’s Largest Education Company With Kubernetes
|
||||
</div></h1>
|
||||
</div>
|
||||
|
|
@ -47,7 +47,7 @@ quote: >
|
|||
The team adopted Kubernetes when it was still version 1.2 and are still going strong now on 1.7; they use Terraform and Ansible to deploy it on to basic AWS primitives. "We were trying to understand how we can create value for Pearson from this technology," says Ben Somogyi, Principal Architect for the Cloud Platforms. "It turned out that Kubernetes’ benefits are huge. We’re trying to help our applications development teams that use our platform go faster, so we filled that gap with a CI/CD pipeline that builds their images for them, standardizes them, patches everything up, allows them to deploy their different environments onto the cluster, and obfuscating the details of how difficult the work underneath the covers is."
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_pearson_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/pearson/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Your internal customers need to feel like they are choosing the very best option for them. We are experiencing this first hand in the growth of adoption. We are seeing triple-digit, year-on-year growth of the service."<span style="font-size:16px;text-transform:uppercase;letter-spacing:0.1em;"><br><br>— Chris Jackson, Director for Cloud Platforms & SRE at Pearson</span>
|
||||
</div>
|
||||
|
|
@ -60,7 +60,7 @@ quote: >
|
|||
Jackson estimates they’ve achieved a 15-20% boost in productivity for developer teams who adopt the platform. They also see a reduction in the number of customer-impacting incidents. Plus, says Jackson, "Teams who were previously limited to 1-2 releases per academic year can now ship code multiple times per day!"
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_pearson_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/pearson/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Teams who were previously limited to 1-2 releases per academic year can now ship code multiple times per day!" <span style="font-size:16px;text-transform:uppercase;letter-spacing:0.1em;"><br><br>— Chris Jackson, Director for Cloud Platforms & SRE at Pearson</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_pingcap_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/pingcap/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/pingcap_logo.png" class="header_logo" style="width:20%;margin-bottom:-1.5%"><br> <div class="subhead" style="margin-top:1%">PingCAP Bets on Cloud Native for Its TiDB Database Platform
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -52,7 +52,7 @@ featured: false
|
|||
Knowing that using a distributed system isn’t easy, the PingCAP team began looking for the right orchestration layer to help reduce some of that complexity for end users. Kubernetes had been on their radar for quite some time. "We knew Kubernetes had the promise of helping us solve our problems," says Xu. "We were just waiting for it to mature."
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_pingcap_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/pingcap/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"With the governance process being so open, it’s not hard to find out what’s the latest development in the technology and community, or figure out who to reach out to if we have problems or issues."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- KEVIN XU, GENERAL MANAGER OF GLOBAL STRATEGY AND OPERATIONS, PINGCAP</span>
|
||||
|
||||
|
|
@ -65,7 +65,7 @@ featured: false
|
|||
TiDB’s cloud native architecture consists of a stateless SQL layer (also called TiDB) and a persistent key-value storage layer that supports distributed transactions (<a href="https://github.com/tikv/tikv">TiKV</a>, which is now in the CNCF Sandbox), which are loosely coupled. "You can scale both out or in depending on your computation and storage needs, and the two scaling processes can happen independent of each other," says Xu. The PingCAP team also built the <a href="https://github.com/pingcap/tidb-operator">TiDB Operator</a> based on Kubernetes, which helps bootstrap a TiDB cluster on any cloud environment and simplifies and automates deployment, scaling, scheduling, upgrades, and maintenance. The company also recently previewed its fully-managed <a href="https://www.pingcap.com/blog/announcing-tidb-cloud-managed-as-a-service-and-in-the-marketplace/">TiDB Cloud</a> offering.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_pingcap_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/pingcap/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"A cloud native infrastructure will not only save you money and allow you to be more in control of the infrastructure resources you consume, but also empower new product innovation, new experience for your users, and new business possibilities. It’s both a cost reducer and a money maker." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- KEVIN XU, GENERAL MANAGER OF GLOBAL STRATEGY AND OPERATIONS, PINGCAP</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ quote: >
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_pinterest_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/pinterest/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/pinterest_logo.png" style="margin-bottom:-1%" class="header_logo"><br> <div class="subhead">Pinning Its Past, Present, and Future on Cloud Native
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -60,7 +60,7 @@ The first phase involved moving to Docker. "Pinterest has been heavily running o
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_pinterest_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/pinterest/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Though Kubernetes lacked certain things we wanted, we realized that by the time we get to productionizing many of those things, we’ll be able to leverage what the community is doing." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— MICHEAL BENEDICT, PRODUCT MANAGER FOR THE CLOUD AND THE DATA INFRASTRUCTURE GROUP AT PINTEREST</span>
|
||||
</div>
|
||||
|
|
@ -75,7 +75,7 @@ At the beginning of 2018, the team began onboarding its first use case into the
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_pinterest_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/pinterest/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"So far it’s been good, especially the elasticity around how we can configure our Jenkins workloads on Kubernetes shared cluster. That is the win we were pushing for." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— MICHEAL BENEDICT, PRODUCT MANAGER FOR THE CLOUD AND THE DATA INFRASTRUCTURE GROUP AT PINTEREST</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ featured: false
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_prowise_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/prowise/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/prowise_logo.png" class="header_logo" style="width:25%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%">Prowise: How Kubernetes is Enabling the Edtech Solution’s Global Expansion
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -50,7 +50,7 @@ featured: false
|
|||
The company’s existing infrastructure on Microsoft Azure Cloud was all on virtual machines, “a pretty traditional setup,” van den Bosch says. “We decided that we want some features in our software that requires being able to scale quickly, being able to deploy new applications and versions on different versions of different programming languages quickly. And we didn’t really want the hassle of trying to keep those servers in a particular state.”
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_prowise_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/prowise/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"You don’t have to go all-in immediately. You can just take a few projects, a service, run it alongside your more traditional stack, and build it up from there. Kubernetes scales, so as you add applications and services to it, it will scale with you. You don’t have to do it all at once, and that’s really a secret to everything, but especially true to Kubernetes."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>— VICTOR VAN DEN BOSCH, SENIOR DEVOPS ENGINEER, PROWISE</span>
|
||||
|
||||
|
|
@ -67,7 +67,7 @@ featured: false
|
|||
With its first web-based applications now running in beta on Prowise’s Kubernetes platform, the team is seeing the benefits of rapid and smooth deployments. “The old way of deploying took half an hour of preparations and half an hour deploying it. With Kubernetes, it’s a couple of seconds,” says Senior Developer Bart Haalstra. As a result, adds van den Bosch, “We’ve gone from quarterly releases to a release every month in production. We’re pretty much deploying every hour or just when we find that a feature is ready for production. Before, our releases were mostly done on off-hours, where it couldn’t impact our customers, as our confidence the process itself was relatively low. With Kubernetes, we dare to deploy in the middle of a busy day with high confidence the deployment will succeed.”
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_prowise_banner4.jpg')" style="width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/prowise/banner4.jpg')" style="width:100%">
|
||||
<div class="banner4text">
|
||||
"Kubernetes allows us to really consider the best tools for a problem. Want to have a full-fledged analytics application developed by a third party that is just right for your use case? Run it. Dabbling in machine learning and AI algorithms but getting tired of waiting days for training to complete? It takes only seconds to scale it. Got a stubborn developer that wants to use a programming language no one has heard of? Let him, if it runs in a container, of course. And all of that while your operations team/DevOps get to sleep at night." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- VICTOR VAN DEN BOSCH, SENIOR DEVOPS ENGINEER, PROWISE</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_ricardoch_banner1.png')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/ricardoch/banner1.png')">
|
||||
<h1> CASE STUDY:<img src="/images/ricardoch_logo.png" class="/images/header_logo" style="width:25%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%">ricardo.ch: How Kubernetes Improved Velocity and DevOps Harmony
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ featured: false
|
|||
To address the velocity issue, ricardo.ch CTO Jeremy Seitz established a new software factory called EPD, which consists of 65 engineers, 7 product managers and 2 designers. "We brought these three departments together so that they can kind of streamline this and talk to each other much more closely," says Meury.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_ricardoch_banner3.png')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/ricardoch/banner3.png')">
|
||||
<div class="banner3text">
|
||||
"Being in the End User Community demonstrates that we stand behind these technologies. In Switzerland, if all the companies see that ricardo.ch’s using it, I think that will help adoption. I also like that we’re connected to the other end users, so if there is a really heavy problem, I could go to the Slack channel, and say, ‘Hey, you guys…’ Like Reddit, Github and New York Times or whoever can give a recommendation on what to use here or how to solve that. So that’s kind of a superpower."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>— CEDRIC MEURY, HEAD OF PLATFORM ENGINEERING, RICARDO.CH</span>
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ featured: false
|
|||
Meury estimates that half of the application has been migrated to Kubernetes. And the plan is to move everything to the Google Cloud Platform by the end of 2018. "We are still running some servers in our own data centers, but all of the containerization efforts and describing our services as Kubernetes manifests will allow us to quite easily make that shift," says Meury.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_ricardoch_banner4.png')" style="width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/ricardoch/banner4.png')" style="width:100%">
|
||||
<div class="banner4text">
|
||||
"One of the core moments was when a front-end developer asked me how to do a port forward from his laptop to a front-end application to debug, and I told him the command. And he was like, ‘Wow, that’s all I need to do?’ He was super excited and happy about it. That showed me that this power in the right hands can just accelerate development."
|
||||
<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- CEDRIC MEURY, HEAD OF PLATFORM ENGINEERING, RICARDO.CH</span>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_slamtec_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/slamtec/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/slamtec_logo.png" class="header_logo" style="width:17%;margin-bottom:%"><br> </h1>
|
||||
<br><br>
|
||||
</div>
|
||||
|
|
@ -47,7 +47,7 @@ featured: false
|
|||
After an evaluation of existing technologies, Ji’s team chose <a href="https://kubernetes.io/">Kubernetes</a> for orchestration. "CNCF brings quality assurance and a complete ecosystem for Kubernetes, which is very important for the wide application of Kubernetes," says Ji. Plus, "avoiding binding to an infrastructure technology or provider can help us ensure that our business is deployed and migrated in cross-regional environments, and can serve users all over the world."
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_slamtec_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/slamtec/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"CNCF brings quality assurance and a complete ecosystem for Kubernetes, which is very important for the wide application of Kubernetes."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- BENNIU JI, DIRECTOR OF CLOUD COMPUTING BUSINESS DIVISION</span>
|
||||
|
||||
|
|
@ -60,7 +60,7 @@ featured: false
|
|||
The company uses <a href="https://goharbor.io/">Harbor</a> as a container image repository. "Harbor’s replication function helps us implement CI/CD on both private and public clouds," says Ji. "In addition, multi-project support, certification and policy configuration, and integration with Kubernetes are also excellent functions." <a href="https://helm.sh/">Helm</a> is also being used as a package manager, and the team is evaluating the Istio framework. "We’re very pleased that Kubernetes and these frameworks can be seamlessly integrated," Ji adds.
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_slamtec_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/slamtec/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"Cloud native is suitable for microservice architecture, it’s suitable for fast iteration and agile development, and it has a relatively perfect ecosystem and active community." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- BENNIU JI, DIRECTOR OF CLOUD COMPUTING BUSINESS DIVISION</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ quote: >
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_slingtv_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/slingtv/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/slingtv_logo.png" style="margin-bottom:-1.5%;width:15% !important" class="header_logo"><br> <div class="subhead" style="padding-top:1% !important">Sling TV: Marrying Kubernetes and AI to Enable Proper Web Scale
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -62,7 +62,7 @@ Led by the belief that “the cloud native architectures and patterns really giv
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_slingtv_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/slingtv/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
“We needed the flexibility to enable our use case versus just a simple orchestrater. Enabling our future in a way that did not give us vendor lock-in was also a key part of our strategy. I think that is part of the Rancher value proposition.” <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— Brad Linder, Cloud Native & Big Data Evangelist for Sling TV</span>
|
||||
</div>
|
||||
|
|
@ -75,7 +75,7 @@ With the emphasis on common tooling, “We are getting to the place where we can
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_slingtv_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/slingtv/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
“We have to be able to react to changes and hiccups in the matrix. It is the foundation for our ability to deliver a high-quality service for our customers." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— Brad Linder, Cloud Native & Big Data Evangelist for Sling TV</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ logo: sos_featured_logo.png
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_sos_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/sos/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/sos_logo.png" class="header_logo" style="width:20%;margin-bottom:-1.2%"><br> <div class="subhead" style="margin-top:1%">SOS International: Using Kubernetes to Provide Emergency Assistance in a Connected World
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -56,7 +56,7 @@ logo: sos_featured_logo.png
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_sos_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/sos/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"We have to deliver new digital services, but we also have to migrate the old stuff, and we have to transform our core systems into new systems built on top of this platform. One of the reasons why we chose this technology is that we could build new digital services while changing the old one."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Martin Ahrentsen, Head of Enterprise Architecture, SOS International</span>
|
||||
|
||||
|
|
@ -70,7 +70,7 @@ logo: sos_featured_logo.png
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_sos_banner4.jpg');width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/sos/banner4.jpg');width:100%">
|
||||
<div class="banner4text">
|
||||
"During our onboarding, we could see that we were chosen by IT professionals because we provided the new technologies." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Martin Ahrentsen, Head of Enterprise Architecture, SOS International</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_spotify_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/spotify/banner1.jpg')">
|
||||
<h1> CASE STUDY: Spotify<br> <div class="subhead" style="margin-top:1%">Spotify: An Early Adopter of Containers, Spotify Is Migrating from Homegrown Orchestration to Kubernetes
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -52,7 +52,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_spotify_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/spotify/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"The community has been extremely helpful in getting us to work through all the technology much faster and much easier. And it’s helped us validate all the things we’re doing." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- Dave Zolotusky, Software Engineer, Infrastructure and Operations, Spotify</span>
|
||||
|
||||
|
|
@ -67,7 +67,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_spotify_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/spotify/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We were able to use a lot of the Kubernetes APIs and extensibility features to support and interface with our legacy infrastructure, so the integration was straightforward and easy."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- James Wen, Site Reliability Engineer, Spotify</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -5,7 +5,7 @@ cid: caseStudies
|
|||
css: /css/style_case_studies.css
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_squarespace_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/squarespace/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/squarespace_logo.png" class="header_logo"><br> <div class="subhead">Squarespace: Gaining Productivity and Resilience with Kubernetes
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -51,7 +51,7 @@ Since Squarespace moved to Kubernetes, in conjunction with modernizing its netwo
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_squarespace_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/squarespace/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
After experimenting with another container orchestration platform and "breaking it in very painful ways," Lynch says, the team began experimenting with Kubernetes in mid-2016 and found that it "answered all the questions that we had."
|
||||
|
||||
|
|
@ -68,7 +68,7 @@ Since Squarespace moved to Kubernetes, in conjunction with modernizing its netwo
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_squarespace_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/squarespace/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We switched to Kubernetes, a new world....It allowed us to streamline our process, so we can now easily create an entire microservice project from templates," Lynch says. And the whole process takes only five minutes, an almost 85% reduction in time compared to their VM deployment.
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_thredup_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/thredup/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/thredup_logo.png" class="header_logo" style="width:17%;margin-bottom:%"><br> </h1>
|
||||
<br><br>
|
||||
</div>
|
||||
|
|
@ -49,7 +49,7 @@ featured: false
|
|||
"We wanted to make sure that our engineers could embrace the DevOps mindset as they built software," Homer says. "It was really important to us that they could own the life cycle from end to end, from conception at design, through shipping it and running it in production, from marketing to ecommerce, the user experience and our internal distribution center operations."
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_thredup_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/thredup/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Kubernetes enabled auto scaling in a seamless and easily manageable way on days like Black Friday. We no longer have to sit there adding instances, monitoring the traffic, doing a lot of manual work."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- CHRIS HOMER, COFOUNDER/CTO, THREDUP</span>
|
||||
|
||||
|
|
@ -62,7 +62,7 @@ featured: false
|
|||
According to the infrastructure team, the key improvement was the consistent experience Kubernetes enabled for developers. "It lets developers work in the same environment that their application will be running in production," says Infrastructure Engineer Oleksandr Snagovskyi. Plus, "It became easier to test, easier to refine, and easier to deploy, because everything’s done automatically," says Infrastructure Engineer Oleksii Asiutin. "One of the main goals of our team is to make developers’ lives more comfortable, and we are achieving this with Kubernetes. They can experiment with existing applications and create new services, and do it all blazingly fast."
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_thredup_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/thredup/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"One of the main goals of our team is to make developers’ lives more comfortable, and we are achieving this with Kubernetes. They can experiment with existing applications and create new services, and do it all blazingly fast." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- OLEKSII ASIUTIN, INFRASTRUCTURE ENGINEER, THREDUP</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ css: /css/style_case_studies.css
|
|||
featured: false
|
||||
---
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_vsco_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/vsco/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/vsco_logo.png" class="header_logo" style="width:17%;margin-bottom:-2%"><br> <div class="subhead" style="margin-top:1%">VSCO: How a Mobile App Saved 70% on Its EC2 Bill with Cloud Native
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -48,7 +48,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_vsco_banner2.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/vsco/banner2.jpg')">
|
||||
<div class="banner3text">
|
||||
"Kubernetes seemed to have the strongest open source community around it, plus, we had started to standardize on a lot of the Google stack, with Go as a language, and gRPC for almost all communication between our own services inside the data center. So it seemed pretty natural for us to choose Kubernetes."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- MELINDA LU, ENGINEERING MANAGER FOR VSCO'S MACHINE LEARNING TEAM</span>
|
||||
|
||||
|
|
@ -64,7 +64,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_vsco_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/vsco/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"I've been really impressed seeing how our engineers have come up with really creative solutions to things by just combining a lot of Kubernetes primitives, exposing Kubernetes constructs as a service to our engineers as opposed to exposing higher order constructs has worked well for us. It lets you get familiar with the technology and do more interesting things with it." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- MELINDA LU, ENGINEERING MANAGER FOR VSCO’S MACHINE LEARNING TEAM</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ featured: false
|
|||
---
|
||||
|
||||
|
||||
<div class="banner1" style="background-image: url('/images/CaseStudy_woorank_banner1.jpg')">
|
||||
<div class="banner1" style="background-image: url('/images/case-studies/woorank/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/woorank_logo.png" class="header_logo" style="width:25%;margin-bottom:-1%"><br> <div class="subhead" style="margin-top:1%">Woorank: How Kubernetes Helped a Startup Manage 50 Microservices with<br>12 Engineers—At 30% Less Cost
|
||||
</div></h1>
|
||||
|
||||
|
|
@ -50,7 +50,7 @@ featured: false
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_woorank_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/woorank/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"Cloud native technologies have brought to us a transparency on everything going on in our system, from the code to the server. It has brought huge cost savings and a better way of dealing with those costs and keeping them under control. And performance-wise, it has helped our team understand how we can make our code work better on the cloud native infrastructure."<br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>— NILS DE MOOR, CTO/COFOUNDER, WOORANK</span>
|
||||
|
||||
|
|
@ -66,7 +66,7 @@ featured: false
|
|||
The company’s number one concern was immediately erased: Maintaining Kubernetes is the responsibility of just one person on staff, and it’s not his fulltime job. Updating the old infrastructure “was always a pain,” says De Moor: It used to take two active working days, “and it was always a bit scary when we did that.” With Kubernetes, it’s just a matter of “a few hours of passively following the process.”
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_woorank_banner4.jpg')" style="width:100%">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/woorank/banner4.jpg')" style="width:100%">
|
||||
<div class="banner4text">
|
||||
"When things fail and errors pop up, the system tries to heal itself, and that’s really, for us, the key reason to work with Kubernetes. It allowed us to set up certain testing frameworks to just be alerted when things go wrong, instead of having to look at whether everything went right. It’s made people’s lives much easier. It’s quite a big mindset change." <br style="height:25px"><span style="font-size:14px;letter-spacing:2px;text-transform:uppercase;margin-top:5% !important;"><br>- NILS DE MOOR, CTO/COFOUNDER, WOORANK</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -11,7 +11,7 @@ quote: >
|
|||
With OpenTracing, my team was able to look at a trace and make optimization suggestions to another team without ever looking at their code.
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_workiva_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/workiva/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/workiva_logo.png" style="margin-bottom:0%" class="header_logo"><br> <div class="subhead">Using OpenTracing to Help Pinpoint the Bottlenecks
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -30,12 +30,12 @@ quote: >
|
|||
<a href="https://www.workiva.com/">Workiva</a> offers a cloud-based platform for managing and reporting business data. This SaaS product, Wdesk, is used by more than 70 percent of the Fortune 500 companies. As the company made the shift from a monolith to a more distributed, microservice-based system, "We had a number of people working on this, all on different teams, so we needed to identify what the issues were and where the bottlenecks were," says Senior Software Architect MacLeod Broad. With back-end code running on Google App Engine, Google Compute Engine, as well as Amazon Web Services, Workiva needed a tracing system that was agnostic of platform. While preparing one of the company’s first products utilizing AWS, which involved a "sync and link" feature that linked data from spreadsheets built in the new application with documents created in the old application on Workiva’s existing system, Broad’s team found an ideal use case for tracing: There were circular dependencies, and optimizations often turned out to be micro-optimizations that didn’t impact overall speed.
|
||||
|
||||
<br>
|
||||
|
||||
|
||||
</div>
|
||||
|
||||
<div class="col2">
|
||||
<h2>Solution</h2>
|
||||
Broad’s team introduced the platform-agnostic distributed tracing system OpenTracing to help them pinpoint the bottlenecks.
|
||||
Broad’s team introduced the platform-agnostic distributed tracing system OpenTracing to help them pinpoint the bottlenecks.
|
||||
<br>
|
||||
<h2>Impact</h2>
|
||||
Now used throughout the company, OpenTracing produced immediate results. Software Engineer Michael Davis reports: "Tracing has given us immediate, actionable insight into how to improve our service. Through a combination of seeing where each call spends its time, as well as which calls are most often used, we were able to reduce our average response time by 95 percent (from 600ms to 30ms) in a single fix."
|
||||
|
|
@ -61,14 +61,14 @@ The challenges faced by Broad’s team may sound familiar to other companies tha
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_workiva_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/workiva/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"A tracing system can at a glance explain an architecture, narrow down a performance bottleneck and zero in on it, and generally just help direct an investigation at a high level. Being able to do that at a glance is much faster than at a meeting or with three days of debugging, and it’s a lot faster than never figuring out the problem and just moving on."<span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase"><br>— MACLEOD BROAD, SENIOR SOFTWARE ARCHITECT AT WORKIVA</span>
|
||||
</div>
|
||||
</div>
|
||||
<section class="section3">
|
||||
<div class="fullcol">
|
||||
|
||||
|
||||
Simply put, it was an ideal use case for tracing. "A tracing system can at a glance explain an architecture, narrow down a performance bottleneck and zero in on it, and generally just help direct an investigation at a high level," says Broad. "Being able to do that at a glance is much faster than at a meeting or with three days of debugging, and it’s a lot faster than never figuring out the problem and just moving on."<br><br>
|
||||
With Workiva’s back-end code running on <a href="https://cloud.google.com/compute/">Google Compute Engine</a> as well as App Engine and AWS, Broad knew that he needed a tracing system that was platform agnostic. "We were looking at different tracing solutions," he says, "and we decided that because it seemed to be a very evolving market, we didn’t want to get stuck with one vendor. So OpenTracing seemed like the cleanest way to avoid vendor lock-in on what backend we actually had to use."<br><br>
|
||||
Once they introduced OpenTracing into this first use case, Broad says, "The trace made it super obvious where the bottlenecks were." Even though everyone had assumed it was Workiva’s existing code that was slowing things down, that wasn’t exactly the case. "It looked like the existing code was slow only because it was reaching out to our next-generation services, and they were taking a very long time to service all those requests," says Broad. "On the waterfall graph you can see the exact same work being done on every request when it was calling back in. So every service request would look the exact same for every response being paged out. And then it was just a no-brainer of, ‘Why is it doing all this work again?’"<br><br>
|
||||
|
|
@ -78,7 +78,7 @@ Using the insight OpenTracing gave them, "My team was able to look at a trace an
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_workiva_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/workiva/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We were looking at different tracing solutions and we decided that because it seemed to be a very evolving market, we didn’t want to get stuck with one vendor. So OpenTracing seemed like the cleanest way to avoid vendor lock-in on what backend we actually had to use." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase"><br>— MACLEOD BROAD, SENIOR SOFTWARE ARCHITECT AT WORKIVA</span>
|
||||
</div>
|
||||
|
|
@ -90,7 +90,7 @@ Using the insight OpenTracing gave them, "My team was able to look at a trace an
|
|||
Some teams were won over quickly. "Tracing has given us immediate, actionable insight into how to improve our [Workspaces] service," says Software Engineer Michael Davis. "Through a combination of seeing where each call spends its time, as well as which calls are most often used, we were able to reduce our average response time by 95 percent (from 600ms to 30ms) in a single fix." <br><br>
|
||||
Most of Workiva’s major products are now traced using OpenTracing, with data pushed into <a href="https://cloud.google.com/stackdriver/">Google StackDriver</a>. Even the products that aren’t fully traced have some components and libraries that are. <br><br>
|
||||
Broad points out that because some of the engineers were working on App Engine and already had experience with the platform’s Appstats library for profiling performance, it didn’t take much to get them used to using OpenTracing. But others were a little more reluctant. "The biggest hindrance to adoption I think has been the concern about how much latency is introducing tracing [and StackDriver] going to cost," he says. "People are also very concerned about adding middleware to whatever they’re working on. Questions about passing the context around and how that’s done were common. A lot of our Go developers were fine with it, because they were already doing that in one form or another. Our Java developers were not super keen on doing that because they’d used other systems that didn’t require that."<br><br>
|
||||
But the benefits clearly outweighed the concerns, and today, Workiva’s official policy is to use tracing."
|
||||
But the benefits clearly outweighed the concerns, and today, Workiva’s official policy is to use tracing."
|
||||
In fact, Broad believes that tracing naturally fits in with Workiva’s existing logging and metrics systems. "This was the way we presented it internally, and also the way we designed our use," he says. "Our traces are logged in the exact same mechanism as our app metric and logging data, and they get pushed the exact same way. So we treat all that data exactly the same when it’s being created and when it’s being recorded. We have one internal library that we use for logging, telemetry, analytics and tracing."
|
||||
|
||||
|
||||
|
|
@ -98,7 +98,7 @@ In fact, Broad believes that tracing naturally fits in with Workiva’s existing
|
|||
|
||||
<div class="banner5">
|
||||
<div class="banner5text">
|
||||
"Tracing has given us immediate, actionable insight into how to improve our [Workspaces] service. Through a combination of seeing where each call spends its time, as well as which calls are most often used, we were able to reduce our average response time by 95 percent (from 600ms to 30ms) in a single fix." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase"><br>— Michael Davis, Software Engineer, Workiva </span>
|
||||
"Tracing has given us immediate, actionable insight into how to improve our [Workspaces] service. Through a combination of seeing where each call spends its time, as well as which calls are most often used, we were able to reduce our average response time by 95 percent (from 600ms to 30ms) in a single fix." <span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase"><br>— Michael Davis, Software Engineer, Workiva </span>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ quote: >
|
|||
We had to change some practices and code, and the way things were built, but we were able to get our main systems onto Kubernetes in a month or so, and then into production within two months. That’s very fast for a finance company.
|
||||
---
|
||||
|
||||
<div class="banner1 desktop" style="background-image: url('/images/CaseStudy_ygrene_banner1.jpg')">
|
||||
<div class="banner1 desktop" style="background-image: url('/images/case-studies/ygrene/banner1.jpg')">
|
||||
<h1> CASE STUDY:<img src="/images/ygrene_logo.png" style="margin-bottom:-1%" class="header_logo"><br> <div class="subhead">Ygrene: Using Cloud Native to Bring Security and Scalability to the Finance Industry
|
||||
|
||||
</div></h1>
|
||||
|
|
@ -61,7 +61,7 @@ By 2017, deployments and scalability had become pain points. The company was uti
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner3" style="background-image: url('/images/CaseStudy_ygrene_banner3.jpg')">
|
||||
<div class="banner3" style="background-image: url('/images/case-studies/ygrene/banner3.jpg')">
|
||||
<div class="banner3text">
|
||||
"CNCF has been an amazing incubator for so many projects. Now we look at its webpage regularly to find out if there are any new, awesome, high-quality projects we can implement into our stack. It’s actually become a hub for us for knowing what software we need to be looking at to make our systems more secure or more scalable."<span style="font-size:14px;letter-spacing:0.12em;padding-top:20px;text-transform:uppercase;line-height:14px"><br><br>— Austin Adams, Development Manager, Ygrene Energy Fund</span>
|
||||
</div>
|
||||
|
|
@ -78,7 +78,7 @@ Notary, in particular, "has been a godsend," says Adams. "We need to know that o
|
|||
|
||||
</div>
|
||||
</section>
|
||||
<div class="banner4" style="background-image: url('/images/CaseStudy_ygrene_banner4.jpg')">
|
||||
<div class="banner4" style="background-image: url('/images/case-studies/ygrene/banner4.jpg')">
|
||||
<div class="banner4text">
|
||||
"We had to change some practices and code, and the way things were built," Adams says, "but we were able to get our main systems onto Kubernetes in a month or so, and then into production within two months. That’s very fast for a finance company."</span>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -64,7 +64,7 @@ Before choosing a guide, here are some considerations:
|
|||
* [Auditing](/docs/tasks/debug-application-cluster/audit/) describes how to interact with Kubernetes' audit logs.
|
||||
|
||||
### Securing the kubelet
|
||||
* [Master-Node communication](/docs/concepts/architecture/master-node-communication/)
|
||||
* [Control Plane-Node communication](/docs/concepts/architecture/control-plane-node-communication/)
|
||||
* [TLS bootstrapping](/docs/reference/command-line-tools-reference/kubelet-tls-bootstrapping/)
|
||||
* [Kubelet authentication/authorization](/docs/admin/kubelet-authentication-authorization/)
|
||||
|
||||
|
|
|
|||
|
|
@ -303,6 +303,9 @@ to get a mapping of UIDs to names for both FlowSchemas and
|
|||
PriorityLevelConfigurations.
|
||||
|
||||
## Observability
|
||||
|
||||
### Metrics
|
||||
|
||||
When you enable the API Priority and Fairness feature, the kube-apiserver
|
||||
exports additional metrics. Monitoring these can help you determine whether your
|
||||
configuration is inappropriately throttling important traffic, or find
|
||||
|
|
@ -365,9 +368,65 @@ poorly-behaved workloads that may be harming system health.
|
|||
long requests took to actually execute, grouped by the FlowSchema that matched the
|
||||
request and the PriorityLevel to which it was assigned.
|
||||
|
||||
### Debug endpoints
|
||||
|
||||
When you enable the API Priority and Fairness feature, the kube-apiserver serves the following additional paths at its HTTP[S] ports.
|
||||
|
||||
- `/debug/api_priority_and_fairness/dump_priority_levels` - a listing of all the priority levels and the current state of each. You can fetch like this:
|
||||
```shell
|
||||
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels
|
||||
```
|
||||
The output is similar to this:
|
||||
```
|
||||
PriorityLevelName, ActiveQueues, IsIdle, IsQuiescing, WaitingRequests, ExecutingRequests,
|
||||
workload-low, 0, true, false, 0, 0,
|
||||
global-default, 0, true, false, 0, 0,
|
||||
exempt, <none>, <none>, <none>, <none>, <none>,
|
||||
catch-all, 0, true, false, 0, 0,
|
||||
system, 0, true, false, 0, 0,
|
||||
leader-election, 0, true, false, 0, 0,
|
||||
workload-high, 0, true, false, 0, 0,
|
||||
```
|
||||
|
||||
- `/debug/api_priority_and_fairness/dump_queues` - a listing of all the queues and their current state. You can fetch like this:
|
||||
```shell
|
||||
kubectl get --raw /debug/api_priority_and_fairness/dump_queues
|
||||
```
|
||||
The output is similar to this:
|
||||
```
|
||||
PriorityLevelName, Index, PendingRequests, ExecutingRequests, VirtualStart,
|
||||
workload-high, 0, 0, 0, 0.0000,
|
||||
workload-high, 1, 0, 0, 0.0000,
|
||||
workload-high, 2, 0, 0, 0.0000,
|
||||
...
|
||||
leader-election, 14, 0, 0, 0.0000,
|
||||
leader-election, 15, 0, 0, 0.0000,
|
||||
```
|
||||
|
||||
- `/debug/api_priority_and_fairness/dump_requests` - a listing of all the requests that are currently waiting in a queue. You can fetch like this:
|
||||
```shell
|
||||
kubectl get --raw /debug/api_priority_and_fairness/dump_requests
|
||||
```
|
||||
The output is similar to this:
|
||||
```
|
||||
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime,
|
||||
exempt, <none>, <none>, <none>, <none>, <none>,
|
||||
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:26:57.179170694Z,
|
||||
```
|
||||
|
||||
In addition to the queued requests, the output includeas one phantom line for each priority level that is exempt from limitation.
|
||||
|
||||
You can get a more detailed listing with a command like this:
|
||||
```shell
|
||||
kubectl get --raw '/debug/api_priority_and_fairness/dump_requests?includeRequestDetails=1'
|
||||
```
|
||||
The output is similar to this:
|
||||
```
|
||||
PriorityLevelName, FlowSchemaName, QueueIndex, RequestIndexInQueue, FlowDistingsher, ArriveTime, UserName, Verb, APIPath, Namespace, Name, APIVersion, Resource, SubResource,
|
||||
system, system-nodes, 12, 0, system:node:127.0.0.1, 2020-07-23T15:31:03.583823404Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
|
||||
system, system-nodes, 12, 1, system:node:127.0.0.1, 2020-07-23T15:31:03.594555947Z, system:node:127.0.0.1, create, /api/v1/namespaces/scaletest/configmaps,
|
||||
```
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -323,7 +323,7 @@ When load on your application grows or shrinks, it's easy to scale with `kubectl
|
|||
kubectl scale deployment/my-nginx --replicas=1
|
||||
```
|
||||
```shell
|
||||
deployment.extensions/my-nginx scaled
|
||||
deployment.apps/my-nginx scaled
|
||||
```
|
||||
|
||||
Now you only have one pod managed by the deployment.
|
||||
|
|
|
|||
|
|
@ -12,7 +12,7 @@ understand exactly how it is expected to work. There are 4 distinct networking
|
|||
problems to address:
|
||||
|
||||
1. Highly-coupled container-to-container communications: this is solved by
|
||||
[pods](/docs/concepts/workloads/pods/pod/) and `localhost` communications.
|
||||
{{< glossary_tooltip text="Pods" term_id="pod" >}} and `localhost` communications.
|
||||
2. Pod-to-Pod communications: this is the primary focus of this document.
|
||||
3. Pod-to-Service communications: this is covered by [services](/docs/concepts/services-networking/service/).
|
||||
4. External-to-Service communications: this is covered by [services](/docs/concepts/services-networking/service/).
|
||||
|
|
|
|||
|
|
@ -224,7 +224,7 @@ data has the following advantages:
|
|||
- improves performance of your cluster by significantly reducing load on kube-apiserver, by
|
||||
closing watches for config maps marked as immutable.
|
||||
|
||||
To use this feature, enable the `ImmutableEmphemeralVolumes`
|
||||
To use this feature, enable the `ImmutableEphemeralVolumes`
|
||||
[feature gate](/docs/reference/command-line-tools-reference/feature-gates/) and set
|
||||
your Secret or ConfigMap `immutable` field to `true`. For example:
|
||||
```yaml
|
||||
|
|
|
|||
|
|
@ -132,11 +132,9 @@ metadata:
|
|||
name: frontend
|
||||
spec:
|
||||
containers:
|
||||
- name: db
|
||||
image: mysql
|
||||
- name: app
|
||||
image: images.my-company.example/app:v4
|
||||
env:
|
||||
- name: MYSQL_ROOT_PASSWORD
|
||||
value: "password"
|
||||
resources:
|
||||
requests:
|
||||
memory: "64Mi"
|
||||
|
|
@ -144,8 +142,8 @@ spec:
|
|||
limits:
|
||||
memory: "128Mi"
|
||||
cpu: "500m"
|
||||
- name: wp
|
||||
image: wordpress
|
||||
- name: log-aggregator
|
||||
image: images.my-company.example/log-aggregator:v6
|
||||
resources:
|
||||
requests:
|
||||
memory: "64Mi"
|
||||
|
|
@ -330,18 +328,15 @@ metadata:
|
|||
name: frontend
|
||||
spec:
|
||||
containers:
|
||||
- name: db
|
||||
image: mysql
|
||||
env:
|
||||
- name: MYSQL_ROOT_PASSWORD
|
||||
value: "password"
|
||||
- name: app
|
||||
image: images.my-company.example/app:v4
|
||||
resources:
|
||||
requests:
|
||||
ephemeral-storage: "2Gi"
|
||||
limits:
|
||||
ephemeral-storage: "4Gi"
|
||||
- name: wp
|
||||
image: wordpress
|
||||
- name: log-aggregator
|
||||
image: images.my-company.example/log-aggregator:v6
|
||||
resources:
|
||||
requests:
|
||||
ephemeral-storage: "2Gi"
|
||||
|
|
|
|||
|
|
@ -217,7 +217,7 @@ makes Pod P eligible to preempt Pods on another Node.
|
|||
#### Graceful termination of preemption victims
|
||||
|
||||
When Pods are preempted, the victims get their
|
||||
[graceful termination period](/docs/concepts/workloads/pods/pod/#termination-of-pods).
|
||||
[graceful termination period](/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination).
|
||||
They have that much time to finish their work and exit. If they don't, they are
|
||||
killed. This graceful termination period creates a time gap between the point
|
||||
that the scheduler preempts Pods and the time when the pending Pod (P) can be
|
||||
|
|
@ -230,7 +230,7 @@ priority Pods to zero or a small number.
|
|||
|
||||
#### PodDisruptionBudget is supported, but not guaranteed
|
||||
|
||||
A [Pod Disruption Budget (PDB)](/docs/concepts/workloads/pods/disruptions/)
|
||||
A [PodDisruptionBudget](/docs/concepts/workloads/pods/disruptions/) (PDB)
|
||||
allows application owners to limit the number of Pods of a replicated application
|
||||
that are down simultaneously from voluntary disruptions. Kubernetes supports
|
||||
PDB when preempting Pods, but respecting PDB is best effort. The scheduler tries
|
||||
|
|
|
|||
|
|
@ -42,7 +42,7 @@ so it must complete before the call to delete the container can be sent.
|
|||
No parameters are passed to the handler.
|
||||
|
||||
A more detailed description of the termination behavior can be found in
|
||||
[Termination of Pods](/docs/concepts/workloads/pods/pod/#termination-of-pods).
|
||||
[Termination of Pods](/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination).
|
||||
|
||||
### Hook handler implementations
|
||||
|
||||
|
|
|
|||
|
|
@ -129,7 +129,7 @@ example, run these on your desktop/laptop:
|
|||
- for example, to test this out: `for n in $nodes; do scp ~/.docker/config.json root@"$n":/var/lib/kubelet/config.json; done`
|
||||
|
||||
{{< note >}}
|
||||
For production clusers, use a configuration management tool so that you can apply this
|
||||
For production clusters, use a configuration management tool so that you can apply this
|
||||
setting to all the nodes where you need it.
|
||||
{{< /note >}}
|
||||
|
||||
|
|
|
|||
|
|
@ -1,112 +0,0 @@
|
|||
---
|
||||
title: Poseidon-Firmament Scheduler
|
||||
content_type: concept
|
||||
weight: 80
|
||||
---
|
||||
|
||||
<!-- overview -->
|
||||
|
||||
{{< feature-state for_k8s_version="v1.6" state="alpha" >}}
|
||||
|
||||
The Poseidon-Firmament scheduler is an alternate scheduler that can be deployed alongside the default Kubernetes scheduler.
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
Poseidon is a service that acts as the integration glue between the [Firmament scheduler](https://github.com/Huawei-PaaS/firmament) and Kubernetes. Poseidon-Firmament augments the current Kubernetes scheduling capabilities. It incorporates novel flow network graph based scheduling capabilities alongside the default Kubernetes scheduler. The Firmament scheduler models workloads and clusters as flow networks and runs min-cost flow optimizations over these networks to make scheduling decisions.
|
||||
|
||||
Firmament models the scheduling problem as a constraint-based optimization over a flow network graph. This is achieved by reducing scheduling to a min-cost max-flow optimization problem. The Poseidon-Firmament scheduler dynamically refines the workload placements.
|
||||
|
||||
Poseidon-Firmament scheduler runs alongside the default Kubernetes scheduler as an alternate scheduler. You can simultaneously run multiple, different schedulers.
|
||||
|
||||
Flow graph scheduling with the Poseidon-Firmament scheduler provides the following advantages:
|
||||
|
||||
- Workloads (Pods) are bulk scheduled to enable scheduling at massive scale.
|
||||
The Poseidon-Firmament scheduler outperforms the Kubernetes default scheduler by a wide margin when it comes to throughput performance for scenarios where compute resource requirements are somewhat uniform across your workload (Deployments, ReplicaSets, Jobs).
|
||||
- The Poseidon-Firmament's scheduler's end-to-end throughput performance and bind time improves as the number of nodes in a cluster increases. As you scale out, Poseidon-Firmament scheduler is able to amortize more and more work across workloads.
|
||||
- Scheduling in Poseidon-Firmament is dynamic; it keeps cluster resources in a global optimal state during every scheduling run.
|
||||
- The Poseidon-Firmament scheduler supports scheduling complex rule constraints.
|
||||
|
||||
## How the Poseidon-Firmament scheduler works
|
||||
|
||||
Kubernetes supports [using multiple schedulers](/docs/tasks/administer-cluster/configure-multiple-schedulers/). You can specify, for a particular Pod, that it is scheduled by a custom scheduler (“poseidon” for this case), by setting the `schedulerName` field in the PodSpec at the time of pod creation. The default scheduler will ignore that Pod and allow Poseidon-Firmament scheduler to schedule the Pod on a relevant node.
|
||||
|
||||
For example:
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
...
|
||||
spec:
|
||||
schedulerName: poseidon
|
||||
...
|
||||
```
|
||||
|
||||
## Batch scheduling
|
||||
|
||||
As mentioned earlier, Poseidon-Firmament scheduler enables an extremely high throughput scheduling environment at scale due to its bulk scheduling approach versus Kubernetes pod-at-a-time approach. In our extensive tests, we have observed substantial throughput benefits as long as resource requirements (CPU/Memory) for incoming Pods are uniform across jobs (Replicasets/Deployments/Jobs), mainly due to efficient amortization of work across jobs.
|
||||
|
||||
Although, Poseidon-Firmament scheduler is capable of scheduling various types of workloads, such as service, batch, etc., the following are a few use cases where it excels the most:
|
||||
|
||||
1. For “Big Data/AI” jobs consisting of large number of tasks, throughput benefits are tremendous.
|
||||
2. Service or batch jobs where workload resource requirements are uniform across jobs (Replicasets/Deployments/Jobs).
|
||||
|
||||
## Feature state
|
||||
|
||||
Poseidon-Firmament is designed to work with Kubernetes release 1.6 and all subsequent releases.
|
||||
|
||||
{{< caution >}}
|
||||
Poseidon-Firmament scheduler does not provide support for high availability; its implementation assumes that the scheduler cannot fail.
|
||||
{{< /caution >}}
|
||||
|
||||
## Feature comparison {#feature-comparison-matrix}
|
||||
|
||||
{{< table caption="Feature comparison of Kubernetes and Poseidon-Firmament schedulers." >}}
|
||||
|Feature|Kubernetes Default Scheduler|Poseidon-Firmament Scheduler|Notes|
|
||||
|--- |--- |--- |--- |
|
||||
|Node Affinity/Anti-Affinity|Y|Y||
|
||||
|Pod Affinity/Anti-Affinity - including support for pod anti-affinity symmetry|Y|Y|The default scheduler outperforms the Poseidon-Firmament scheduler pod affinity/anti-affinity functionality.|
|
||||
|Taints & Tolerations|Y|Y||
|
||||
|Baseline Scheduling capability in accordance to available compute resources (CPU & Memory) on a node|Y|Y†|**†** Not all Predicates & Priorities are supported with Poseidon-Firmament.|
|
||||
|Extreme Throughput at scale|Y†|Y|**†** Bulk scheduling approach scales or increases workload placement. Firmament scheduler offers high throughput when resource requirements (CPU/Memory) for incoming Pods are uniform across ReplicaSets/Deployments/Jobs.|
|
||||
|Colocation Interference Avoidance|N|N||
|
||||
|Priority Preemption|Y|N†|**†** Partially exists in Poseidon-Firmament versus extensive support in Kubernetes default scheduler.|
|
||||
|Inherent Rescheduling|N|Y†|**†** Poseidon-Firmament scheduler supports workload re-scheduling. In each scheduling run, Poseidon-Firmament considers all Pods, including running Pods, and as a result can migrate or evict Pods – a globally optimal scheduling environment.|
|
||||
|Gang Scheduling|N|Y||
|
||||
|Support for Pre-bound Persistence Volume Scheduling|Y|Y||
|
||||
|Support for Local Volume & Dynamic Persistence Volume Binding Scheduling|Y|N||
|
||||
|High Availability|Y|N||
|
||||
|Real-time metrics based scheduling|N|Y†|**†** Partially supported in Poseidon-Firmament using Heapster (now deprecated) for placing Pods using actual cluster utilization statistics rather than reservations.|
|
||||
|Support for Max-Pod per node|Y|Y|Poseidon-Firmament scheduler seamlessly co-exists with Kubernetes default scheduler.|
|
||||
|Support for Ephemeral Storage, in addition to CPU/Memory|Y|Y||
|
||||
{{< /table >}}
|
||||
|
||||
## Installation
|
||||
|
||||
The [Poseidon-Firmament installation guide](https://github.com/kubernetes-sigs/poseidon/blob/master/docs/install/README.md#Installation) explains how to deploy Poseidon-Firmament to your cluster.
|
||||
|
||||
## Performance comparison
|
||||
|
||||
{{< note >}}
|
||||
Please refer to the [latest benchmark results](https://github.com/kubernetes-sigs/poseidon/blob/master/docs/benchmark/README.md) for detailed throughput performance comparison test results between Poseidon-Firmament scheduler and the Kubernetes default scheduler.
|
||||
{{< /note >}}
|
||||
|
||||
Pod-by-pod schedulers, such as the Kubernetes default scheduler, process Pods in small batches (typically one at a time). These schedulers have the following crucial drawbacks:
|
||||
|
||||
1. The scheduler commits to a pod placement early and restricts the choices for other pods that wait to be placed.
|
||||
2. There is limited opportunities for amortizing work across pods because they are considered for placement individually.
|
||||
|
||||
These downsides of pod-by-pod schedulers are addressed by batching or bulk scheduling in Poseidon-Firmament scheduler. Processing several pods in a batch allows the scheduler to jointly consider their placement, and thus to find the best trade-off for the whole batch instead of one pod. At the same time it amortizes work across pods resulting in much higher throughput.
|
||||
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
* See [Poseidon-Firmament](https://github.com/kubernetes-sigs/poseidon#readme) on GitHub for more information.
|
||||
* See the [design document](https://github.com/kubernetes-sigs/poseidon/blob/master/docs/design/README.md) for Poseidon.
|
||||
* Read [Firmament: Fast, Centralized Cluster Scheduling at Scale](https://www.usenix.org/system/files/conference/osdi16/osdi16-gog.pdf), the academic paper on the Firmament scheduling design.
|
||||
* If you'd like to contribute to Poseidon-Firmament, refer to the [developer setup instructions](https://github.com/kubernetes-sigs/poseidon/blob/master/docs/devel/README.md).
|
||||
|
||||
|
|
@ -25,8 +25,6 @@ The Kubernetes API lets you query and manipulate the state of objects in the Kub
|
|||
API endpoints, resource types and samples are described in the [API Reference](/docs/reference/kubernetes-api/).
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## API changes
|
||||
|
|
@ -87,7 +85,7 @@ Kubernetes implements an alternative Protobuf based serialization format for the
|
|||
|
||||
To make it easier to eliminate fields or restructure resource representations, Kubernetes supports
|
||||
multiple API versions, each at a different API path, such as `/api/v1` or
|
||||
`/apis/extensions/v1beta1`.
|
||||
`/apis/rbac.authorization.k8s.io/v1alpha1`.
|
||||
|
||||
Versioning is done at the API level rather than at the resource or field level to ensure that the
|
||||
API presents a clear, consistent view of system resources and behavior, and to enable controlling
|
||||
|
|
@ -157,14 +155,6 @@ The flag accepts comma separated set of key=value pairs describing runtime confi
|
|||
{{< note >}}Enabling or disabling groups or resources requires restarting the kube-apiserver and the
|
||||
kube-controller-manager to pick up the `--runtime-config` changes.{{< /note >}}
|
||||
|
||||
## Enabling specific resources in the extensions/v1beta1 group
|
||||
|
||||
DaemonSets, Deployments, StatefulSet, NetworkPolicies, PodSecurityPolicies and ReplicaSets in the `extensions/v1beta1` API group are disabled by default.
|
||||
For example: to enable deployments and daemonsets, set
|
||||
`--runtime-config=extensions/v1beta1/deployments=true,extensions/v1beta1/daemonsets=true`.
|
||||
|
||||
{{< note >}}Individual resource enablement/disablement is only supported in the `extensions/v1beta1` API group for legacy reasons.{{< /note >}}
|
||||
|
||||
## Persistence
|
||||
|
||||
Kubernetes stores its serialized state in terms of the API resources by writing them into
|
||||
|
|
|
|||
|
|
@ -92,7 +92,7 @@ and the `spec` format for a Deployment can be found in
|
|||
## {{% heading "whatsnext" %}}
|
||||
|
||||
* [Kubernetes API overview](/docs/reference/using-api/api-overview/) explains some more API concepts
|
||||
* Learn about the most important basic Kubernetes objects, such as [Pod](/docs/concepts/workloads/pods/pod-overview/).
|
||||
* Learn about the most important basic Kubernetes objects, such as [Pod](/docs/concepts/workloads/pods/).
|
||||
* Learn about [controllers](/docs/concepts/architecture/controller/) in Kubernetes
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -236,11 +236,7 @@ well as lower-trust users.The following listed controls should be enforced/disal
|
|||
spec.securityContext.supplementalGroups[*]<br>
|
||||
spec.securityContext.fsGroup<br>
|
||||
spec.containers[*].securityContext.runAsGroup<br>
|
||||
spec.containers[*].securityContext.supplementalGroups[*]<br>
|
||||
spec.containers[*].securityContext.fsGroup<br>
|
||||
spec.initContainers[*].securityContext.runAsGroup<br>
|
||||
spec.initContainers[*].securityContext.supplementalGroups[*]<br>
|
||||
spec.initContainers[*].securityContext.fsGroup<br>
|
||||
<br><b>Allowed Values:</b><br>
|
||||
non-zero<br>
|
||||
undefined / nil (except for `*.runAsGroup`)<br>
|
||||
|
|
|
|||
|
|
@ -235,7 +235,7 @@ IngressClass resource will ensure that new Ingresses without an
|
|||
If you have more than one IngressClass marked as the default for your cluster,
|
||||
the admission controller prevents creating new Ingress objects that don't have
|
||||
an `ingressClassName` specified. You can resolve this by ensuring that at most 1
|
||||
IngressClasess are marked as default in your cluster.
|
||||
IngressClasses are marked as default in your cluster.
|
||||
{{< /caution >}}
|
||||
|
||||
## Types of Ingress
|
||||
|
|
|
|||
|
|
@ -1356,7 +1356,7 @@ persistent volume:
|
|||
of a volume. This map must correspond to the map returned in the
|
||||
`volume.attributes` field of the `CreateVolumeResponse` by the CSI driver as
|
||||
defined in the [CSI spec](https://github.com/container-storage-interface/spec/blob/master/spec.md#createvolume).
|
||||
The map is passed to the CSI driver via the `volume_attributes` field in the
|
||||
The map is passed to the CSI driver via the `volume_context` field in the
|
||||
`ControllerPublishVolumeRequest`, `NodeStageVolumeRequest`, and
|
||||
`NodePublishVolumeRequest`.
|
||||
- `controllerPublishSecretRef`: A reference to the secret object containing
|
||||
|
|
|
|||
|
|
@ -60,7 +60,7 @@ A DaemonSet also needs a [`.spec`](https://git.k8s.io/community/contributors/dev
|
|||
|
||||
The `.spec.template` is one of the required fields in `.spec`.
|
||||
|
||||
The `.spec.template` is a [pod template](/docs/concepts/workloads/pods/pod-overview/#pod-templates). It has exactly the same schema as a [Pod](/docs/concepts/workloads/pods/pod/), except it is nested and does not have an `apiVersion` or `kind`.
|
||||
The `.spec.template` is a [pod template](/docs/concepts/workloads/pods/#pod-templates). It has exactly the same schema as a {{< glossary_tooltip text="Pod" term_id="pod" >}}, except it is nested and does not have an `apiVersion` or `kind`.
|
||||
|
||||
In addition to required fields for a Pod, a Pod template in a DaemonSet has to specify appropriate
|
||||
labels (see [pod selector](#pod-selector)).
|
||||
|
|
|
|||
|
|
@ -13,8 +13,8 @@ weight: 30
|
|||
|
||||
<!-- overview -->
|
||||
|
||||
A _Deployment_ provides declarative updates for [Pods](/docs/concepts/workloads/pods/pod/) and
|
||||
[ReplicaSets](/docs/concepts/workloads/controllers/replicaset/).
|
||||
A _Deployment_ provides declarative updates for {{< glossary_tooltip text="Pods" term_id="pod" >}}
|
||||
{{< glossary_tooltip term_id="replica-set" text="ReplicaSets" >}}.
|
||||
|
||||
You describe a _desired state_ in a Deployment, and the Deployment {{< glossary_tooltip term_id="controller" >}} changes the actual state to the desired state at a controlled rate. You can define Deployments to create new ReplicaSets, or to remove existing Deployments and adopt all their resources with new Deployments.
|
||||
|
||||
|
|
@ -23,8 +23,6 @@ Do not manage ReplicaSets owned by a Deployment. Consider opening an issue in th
|
|||
{{< /note >}}
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## Use Case
|
||||
|
|
@ -1053,8 +1051,7 @@ A Deployment also needs a [`.spec` section](https://git.k8s.io/community/contrib
|
|||
|
||||
The `.spec.template` and `.spec.selector` are the only required field of the `.spec`.
|
||||
|
||||
The `.spec.template` is a [Pod template](/docs/concepts/workloads/pods/pod-overview/#pod-templates). It has exactly the same schema as a [Pod](/docs/concepts/workloads/pods/pod/), except it is nested and does not have an
|
||||
`apiVersion` or `kind`.
|
||||
The `.spec.template` is a [Pod template](/docs/concepts/workloads/pods/#pod-templates). It has exactly the same schema as a {{< glossary_tooltip text="Pod" term_id="pod" >}}, except it is nested and does not have an `apiVersion` or `kind`.
|
||||
|
||||
In addition to required fields for a Pod, a Pod template in a Deployment must specify appropriate
|
||||
labels and an appropriate restart policy. For labels, make sure not to overlap with other controllers. See [selector](#selector)).
|
||||
|
|
@ -1155,10 +1152,6 @@ created Pod should be ready without any of its containers crashing, for it to be
|
|||
This defaults to 0 (the Pod will be considered available as soon as it is ready). To learn more about when
|
||||
a Pod is considered ready, see [Container Probes](/docs/concepts/workloads/pods/pod-lifecycle/#container-probes).
|
||||
|
||||
### Rollback To
|
||||
|
||||
Field `.spec.rollbackTo` has been deprecated in API versions `extensions/v1beta1` and `apps/v1beta1`, and is no longer supported in API versions starting `apps/v1beta2`. Instead, `kubectl rollout undo` as introduced in [Rolling Back to a Previous Revision](#rolling-back-to-a-previous-revision) should be used.
|
||||
|
||||
### Revision History Limit
|
||||
|
||||
A Deployment's revision history is stored in the ReplicaSets it controls.
|
||||
|
|
|
|||
|
|
@ -111,12 +111,6 @@ To control the cascading deletion policy, set the `propagationPolicy`
|
|||
field on the `deleteOptions` argument when deleting an Object. Possible values include "Orphan",
|
||||
"Foreground", or "Background".
|
||||
|
||||
Prior to Kubernetes 1.9, the default garbage collection policy for many controller resources was `orphan`.
|
||||
This included ReplicationController, ReplicaSet, StatefulSet, DaemonSet, and
|
||||
Deployment. For kinds in the `extensions/v1beta1`, `apps/v1beta1`, and `apps/v1beta2` group versions, unless you
|
||||
specify otherwise, dependent objects are orphaned by default. In Kubernetes 1.9, for all kinds in the `apps/v1`
|
||||
group version, dependent objects are deleted by default.
|
||||
|
||||
Here's an example that deletes dependents in background:
|
||||
|
||||
```shell
|
||||
|
|
|
|||
|
|
@ -122,7 +122,7 @@ A Job also needs a [`.spec` section](https://git.k8s.io/community/contributors/d
|
|||
|
||||
The `.spec.template` is the only required field of the `.spec`.
|
||||
|
||||
The `.spec.template` is a [pod template](/docs/concepts/workloads/pods/pod-overview/#pod-templates). It has exactly the same schema as a [pod](/docs/user-guide/pods), except it is nested and does not have an `apiVersion` or `kind`.
|
||||
The `.spec.template` is a [pod template](/docs/concepts/workloads/pods/#pod-templates). It has exactly the same schema as a {{< glossary_tooltip text="Pod" term_id="pod" >}}, except it is nested and does not have an `apiVersion` or `kind`.
|
||||
|
||||
In addition to required fields for a Pod, a pod template in a Job must specify appropriate
|
||||
labels (see [pod selector](#pod-selector)) and an appropriate restart policy.
|
||||
|
|
|
|||
|
|
@ -126,7 +126,7 @@ A ReplicationController also needs a [`.spec` section](https://git.k8s.io/commun
|
|||
|
||||
The `.spec.template` is the only required field of the `.spec`.
|
||||
|
||||
The `.spec.template` is a [pod template](/docs/concepts/workloads/pods/pod-overview/#pod-templates). It has exactly the same schema as a [pod](/docs/concepts/workloads/pods/pod/), except it is nested and does not have an `apiVersion` or `kind`.
|
||||
The `.spec.template` is a [pod template](/docs/concepts/workloads/pods/#pod-templates). It has exactly the same schema as a {{< glossary_tooltip text="Pod" term_id="pod" >}}, except it is nested and does not have an `apiVersion` or `kind`.
|
||||
|
||||
In addition to required fields for a Pod, a pod template in a ReplicationController must specify appropriate
|
||||
labels and an appropriate restart policy. For labels, make sure not to overlap with other controllers. See [pod selector](#pod-selector).
|
||||
|
|
|
|||
|
|
@ -1,5 +1,271 @@
|
|||
---
|
||||
title: "Pods"
|
||||
reviewers:
|
||||
- erictune
|
||||
title: Pods
|
||||
content_type: concept
|
||||
weight: 10
|
||||
no_list: true
|
||||
card:
|
||||
name: concepts
|
||||
weight: 60
|
||||
---
|
||||
|
||||
<!-- overview -->
|
||||
|
||||
_Pods_ are the smallest deployable units of computing that you can create and manage in Kubernetes.
|
||||
|
||||
A _Pod_ (as in a pod of whales or pea pod) is a group of one or more
|
||||
{{< glossary_tooltip text="containers" term_id="container" >}}, with shared storage/network resources, and a specification
|
||||
for how to run the containers. A Pod's contents are always co-located and
|
||||
co-scheduled, and run in a shared context. A Pod models an
|
||||
application-specific "logical host": it contains one or more application
|
||||
containers which are relatively tightly coupled.
|
||||
In non-cloud contexts, applications executed on the same physical or virtual machine are analogous to cloud applications executed on the same logical host.
|
||||
|
||||
As well as application containers, a Pod can contain
|
||||
[init containers](/docs/concepts/workloads/pods/init-containers/) that run
|
||||
during Pod startup. You can also inject
|
||||
[ephemeral containers](/docs/concepts/workloads/pods/ephemeral-containers/)
|
||||
for debugging if your cluster offers this.
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## What is a Pod?
|
||||
|
||||
{{< note >}}
|
||||
While Kubernetes supports more
|
||||
{{< glossary_tooltip text="container runtimes" term_id="container-runtime" >}}
|
||||
than just Docker, [Docker](https://www.docker.com/) is the most commonly known
|
||||
runtime, and it helps to describe Pods using some terminology from Docker.
|
||||
{{< /note >}}
|
||||
|
||||
The shared context of a Pod is a set of Linux namespaces, cgroups, and
|
||||
potentially other facets of isolation - the same things that isolate a Docker
|
||||
container. Within a Pod's context, the individual applications may have
|
||||
further sub-isolations applied.
|
||||
|
||||
In terms of Docker concepts, a Pod is similar to a group of Docker containers
|
||||
with shared namespaces and shared filesystem volumes.
|
||||
|
||||
## Using Pods
|
||||
|
||||
Usually you don't need to create Pods directly, even singleton Pods. Instead, create them using workload resources such as {{< glossary_tooltip text="Deployment"
|
||||
term_id="deployment" >}} or {{< glossary_tooltip text="Job" term_id="job" >}}.
|
||||
If your Pods need to track state, consider the
|
||||
{{< glossary_tooltip text="StatefulSet" term_id="statefulset" >}} resource.
|
||||
|
||||
Pods in a Kubernetes cluster are used in two main ways:
|
||||
|
||||
* **Pods that run a single container**. The "one-container-per-Pod" model is the
|
||||
most common Kubernetes use case; in this case, you can think of a Pod as a
|
||||
wrapper around a single container; Kubernetes manages Pods rather than managing
|
||||
the containers directly.
|
||||
* **Pods that run multiple containers that need to work together**. A Pod can
|
||||
encapsulate an application composed of multiple co-located containers that are
|
||||
tightly coupled and need to share resources. These co-located containers
|
||||
form a single cohesive unit of service—for example, one container serving data
|
||||
stored in a shared volume to the public, while a separate _sidecar_ container
|
||||
refreshes or updates those files.
|
||||
The Pod wraps these containers, storage resources, and an ephemeral network
|
||||
identity together as a single unit.
|
||||
|
||||
{{< note >}}
|
||||
Grouping multiple co-located and co-managed containers in a single Pod is a
|
||||
relatively advanced use case. You should use this pattern only in specific
|
||||
instances in which your containers are tightly coupled.
|
||||
{{< /note >}}
|
||||
|
||||
Each Pod is meant to run a single instance of a given application. If you want to
|
||||
scale your application horizontally (to provide more overall resources by running
|
||||
more instances), you should use multiple Pods, one for each instance. In
|
||||
Kubernetes, this is typically referred to as _replication_.
|
||||
Replicated Pods are usually created and managed as a group by a workload resource
|
||||
and its {{< glossary_tooltip text="controller" term_id="controller" >}}.
|
||||
|
||||
See [Pods and controllers](#pods-and-controllers) for more information on how
|
||||
Kubernetes uses workload resources, and their controllers, to implement application
|
||||
scaling and auto-healing.
|
||||
|
||||
### How Pods manage multiple containers
|
||||
|
||||
Pods are designed to support multiple cooperating processes (as containers) that form
|
||||
a cohesive unit of service. The containers in a Pod are automatically co-located and
|
||||
co-scheduled on the same physical or virtual machine in the cluster. The containers
|
||||
can share resources and dependencies, communicate with one another, and coordinate
|
||||
when and how they are terminated.
|
||||
|
||||
For example, you might have a container that
|
||||
acts as a web server for files in a shared volume, and a separate "sidecar" container
|
||||
that updates those files from a remote source, as in the following diagram:
|
||||
|
||||
{{< figure src="/images/docs/pod.svg" alt="example pod diagram" width="50%" >}}
|
||||
|
||||
Some Pods have {{< glossary_tooltip text="init containers" term_id="init-container" >}} as well as {{< glossary_tooltip text="app containers" term_id="app-container" >}}. Init containers run and complete before the app containers are started.
|
||||
|
||||
Pods natively provide two kinds of shared resources for their constituent containers:
|
||||
[networking](#pod-networking) and [storage](#pod-storage).
|
||||
|
||||
## Working with Pods
|
||||
|
||||
You'll rarely create individual Pods directly in Kubernetes—even singleton Pods. This
|
||||
is because Pods are designed as relatively ephemeral, disposable entities. When
|
||||
a Pod gets created (directly by you, or indirectly by a
|
||||
{{< glossary_tooltip text="controller" term_id="controller" >}}), the new Pod is
|
||||
scheduled to run on a {{< glossary_tooltip term_id="node" >}} in your cluster.
|
||||
The Pod remains on that node until the Pod finishes execution, the Pod object is deleted,
|
||||
the Pod is *evicted* for lack of resources, or the node fails.
|
||||
|
||||
{{< note >}}
|
||||
Restarting a container in a Pod should not be confused with restarting a Pod. A Pod
|
||||
is not a process, but an environment for running container(s). A Pod persists until
|
||||
it is deleted.
|
||||
{{< /note >}}
|
||||
|
||||
When you create the manifest for a Pod object, make sure the name specified is a valid
|
||||
[DNS subdomain name](/docs/concepts/overview/working-with-objects/names#dns-subdomain-names).
|
||||
|
||||
### Pods and controllers
|
||||
|
||||
You can use workload resources to create and manage multiple Pods for you. A controller
|
||||
for the resource handles replication and rollout and automatic healing in case of
|
||||
Pod failure. For example, if a Node fails, a controller notices that Pods on that
|
||||
Node have stopped working and creates a replacement Pod. The scheduler places the
|
||||
replacement Pod onto a healthy Node.
|
||||
|
||||
Here are some examples of workload resources that manage one or more Pods:
|
||||
|
||||
* {{< glossary_tooltip text="Deployment" term_id="deployment" >}}
|
||||
* {{< glossary_tooltip text="StatefulSet" term_id="statefulset" >}}
|
||||
* {{< glossary_tooltip text="DaemonSet" term_id="daemonset" >}}
|
||||
|
||||
### Pod templates
|
||||
|
||||
Controllers for {{< glossary_tooltip text="workload" term_id="workload" >}} resources create Pods
|
||||
from a _pod template_ and manage those Pods on your behalf.
|
||||
|
||||
PodTemplates are specifications for creating Pods, and are included in workload resources such as
|
||||
[Deployments](/docs/concepts/workloads/controllers/deployment/),
|
||||
[Jobs](/docs/concepts/jobs/run-to-completion-finite-workloads/), and
|
||||
[DaemonSets](/docs/concepts/workloads/controllers/daemonset/).
|
||||
|
||||
Each controller for a workload resource uses the `PodTemplate` inside the workload
|
||||
object to make actual Pods. The `PodTemplate` is part of the desired state of whatever
|
||||
workload resource you used to run your app.
|
||||
|
||||
The sample below is a manifest for a simple Job with a `template` that starts one
|
||||
container. The container in that Pod prints a message then pauses.
|
||||
|
||||
```yaml
|
||||
apiVersion: batch/v1
|
||||
kind: Job
|
||||
metadata:
|
||||
name: hello
|
||||
spec:
|
||||
template:
|
||||
# This is the pod template
|
||||
spec:
|
||||
containers:
|
||||
- name: hello
|
||||
image: busybox
|
||||
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
|
||||
restartPolicy: OnFailure
|
||||
# The pod template ends here
|
||||
```
|
||||
|
||||
Modifying the pod template or switching to a new pod template has no effect on the
|
||||
Pods that already exist. Pods do not receive template updates directly. Instead,
|
||||
a new Pod is created to match the revised pod template.
|
||||
|
||||
For example, the deployment controller ensures that the running Pods match the current
|
||||
pod template for each Deployment object. If the template is updated, the Deployment has
|
||||
to remove the existing Pods and create new Pods based on the updated template. Each workload
|
||||
resource implements its own rules for handling changes to the Pod template.
|
||||
|
||||
On Nodes, the {{< glossary_tooltip term_id="kubelet" text="kubelet" >}} does not
|
||||
directly observe or manage any of the details around pod templates and updates; those
|
||||
details are abstracted away. That abstraction and separation of concerns simplifies
|
||||
system semantics, and makes it feasible to extend the cluster's behavior without
|
||||
changing existing code.
|
||||
|
||||
## Resource sharing and communication
|
||||
|
||||
Pods enable data sharing and communication among their constituent
|
||||
containters.
|
||||
|
||||
### Storage in Pods {#pod-storage}
|
||||
|
||||
A Pod can specify a set of shared storage
|
||||
{{< glossary_tooltip text="volumes" term_id="volume" >}}. All containers
|
||||
in the Pod can access the shared volumes, allowing those containers to
|
||||
share data. Volumes also allow persistent data in a Pod to survive
|
||||
in case one of the containers within needs to be restarted. See
|
||||
[Storage](/docs/concepts/storage/) for more information on how
|
||||
Kubernetes implements shared storage and makes it available to Pods.
|
||||
|
||||
### Pod networking
|
||||
|
||||
Each Pod is assigned a unique IP address for each address family. Every
|
||||
container in a Pod shares the network namespace, including the IP address and
|
||||
network ports. Inside a Pod (and **only** then), the containers that belong to the Pod
|
||||
can communicate with one another using `localhost`. When containers in a Pod communicate
|
||||
with entities *outside the Pod*,
|
||||
they must coordinate how they use the shared network resources (such as ports).
|
||||
Within a Pod, containers share an IP address and port space, and
|
||||
can find each other via `localhost`. The containers in a Pod can also communicate
|
||||
with each other using standard inter-process communications like SystemV semaphores
|
||||
or POSIX shared memory. Containers in different Pods have distinct IP addresses
|
||||
and can not communicate by IPC without
|
||||
[special configuration](/docs/concepts/policy/pod-security-policy/).
|
||||
Containers that want to interact with a container running in a different Pod can
|
||||
use IP networking to comunicate.
|
||||
|
||||
Containers within the Pod see the system hostname as being the same as the configured
|
||||
`name` for the Pod. There's more about this in the [networking](/docs/concepts/cluster-administration/networking/)
|
||||
section.
|
||||
|
||||
## Privileged mode for containers
|
||||
|
||||
Any container in a Pod can enable privileged mode, using the `privileged` flag on the [security context](/docs/tasks/configure-pod-container/security-context/) of the container spec. This is useful for containers that want to use operating system administrative capabilities such as manipulating the network stack or accessing hardware devices.
|
||||
Processes within a privileged container get almost the same privileges that are available to processes outside a container.
|
||||
|
||||
{{< note >}}
|
||||
Your {{< glossary_tooltip text="container runtime" term_id="container-runtime" >}} must support the concept of a privileged container for this setting to be relevant.
|
||||
{{< /note >}}
|
||||
|
||||
## Static Pods
|
||||
|
||||
_Static Pods_ are managed directly by the kubelet daemon on a specific node,
|
||||
without the {{< glossary_tooltip text="API server" term_id="kube-apiserver" >}}
|
||||
observing them.
|
||||
Whereas most Pods are managed by the control plane (for example, a
|
||||
{{< glossary_tooltip text="Deployment" term_id="deployment" >}}), for static
|
||||
Pods, the kubelet directly supervises each static Pod (and restarts it if it fails).
|
||||
|
||||
Static Pods are always bound to one {{< glossary_tooltip term_id="kubelet" >}} on a specific node.
|
||||
The main use for static Pods is to run a self-hosted control plane: in other words,
|
||||
using the kubelet to supervise the individual [control plane components](/docs/concepts/overview/components/#control-plane-components).
|
||||
|
||||
The kubelet automatically tries to create a {{< glossary_tooltip text="mirror Pod" term_id="mirror-pod" >}}
|
||||
on the Kubernetes API server for each static Pod.
|
||||
This means that the Pods running on a node are visible on the API server,
|
||||
but cannot be controlled from there.
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
* Learn about the [lifecycle of a Pod](/docs/concepts/workloads/pods/pod-lifecycle/).
|
||||
* Learn about [PodPresets](/docs/concepts/workloads/pods/podpreset/).
|
||||
* Lean about [RuntimeClass](/docs/concepts/containers/runtime-class/) and how you can use it to
|
||||
configure different Pods with different container runtime configurations.
|
||||
* Read about [Pod topology spread constraints](/docs/concepts/workloads/pods/pod-topology-spread-constraints/).
|
||||
* Read about [PodDisruptionBudget](https://kubernetes.io/docs/concepts/workloads/pods/disruptions/) and how you can use it to manage application availability during disruptions.
|
||||
* Pod is a top-level resource in the Kubernetes REST API.
|
||||
The [Pod](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#pod-v1-core)
|
||||
object definition describes the object in detail.
|
||||
* [The Distributed System Toolkit: Patterns for Composite Containers](https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns) explains common layouts for Pods with more than one container.
|
||||
|
||||
To understand the context for why Kubernetes wraps a common Pod API in other resources (such as {{< glossary_tooltip text="StatefulSets" term_id="statefulset" >}} or {{< glossary_tooltip text="Deployments" term_id="deployment" >}}, you can read about the prior art, including:
|
||||
* [Aurora](http://aurora.apache.org/documentation/latest/reference/configuration/#job-schema)
|
||||
* [Borg](https://research.google.com/pubs/pub43438.html)
|
||||
* [Marathon](https://mesosphere.github.io/marathon/docs/rest-api.html)
|
||||
* [Omega](https://research.google/pubs/pub41684/)
|
||||
* [Tupperware](https://engineering.fb.com/data-center-engineering/tupperware/).
|
||||
|
|
|
|||
|
|
@ -11,17 +11,15 @@ weight: 60
|
|||
<!-- overview -->
|
||||
This guide is for application owners who want to build
|
||||
highly available applications, and thus need to understand
|
||||
what types of Disruptions can happen to Pods.
|
||||
what types of disruptions can happen to Pods.
|
||||
|
||||
It is also for Cluster Administrators who want to perform automated
|
||||
It is also for cluster administrators who want to perform automated
|
||||
cluster actions, like upgrading and autoscaling clusters.
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## Voluntary and Involuntary Disruptions
|
||||
## Voluntary and involuntary disruptions
|
||||
|
||||
Pods do not disappear until someone (a person or a controller) destroys them, or
|
||||
there is an unavoidable hardware or system software error.
|
||||
|
|
@ -48,7 +46,7 @@ Administrator. Typical application owner actions include:
|
|||
- updating a deployment's pod template causing a restart
|
||||
- directly deleting a pod (e.g. by accident)
|
||||
|
||||
Cluster Administrator actions include:
|
||||
Cluster administrator actions include:
|
||||
|
||||
- [Draining a node](/docs/tasks/administer-cluster/safely-drain-node/) for repair or upgrade.
|
||||
- Draining a node from a cluster to scale the cluster down (learn about
|
||||
|
|
@ -68,7 +66,7 @@ Not all voluntary disruptions are constrained by Pod Disruption Budgets. For exa
|
|||
deleting deployments or pods bypasses Pod Disruption Budgets.
|
||||
{{< /caution >}}
|
||||
|
||||
## Dealing with Disruptions
|
||||
## Dealing with disruptions
|
||||
|
||||
Here are some ways to mitigate involuntary disruptions:
|
||||
|
||||
|
|
@ -90,58 +88,58 @@ of cluster (node) autoscaling may cause voluntary disruptions to defragment and
|
|||
Your cluster administrator or hosting provider should have documented what level of voluntary
|
||||
disruptions, if any, to expect.
|
||||
|
||||
Kubernetes offers features to help run highly available applications at the same
|
||||
time as frequent voluntary disruptions. We call this set of features
|
||||
*Disruption Budgets*.
|
||||
|
||||
|
||||
## How Disruption Budgets Work
|
||||
## Pod disruption budgets
|
||||
|
||||
{{< feature-state for_k8s_version="v1.5" state="beta" >}}
|
||||
|
||||
An Application Owner can create a `PodDisruptionBudget` object (PDB) for each application.
|
||||
A PDB limits the number of pods of a replicated application that are down simultaneously from
|
||||
voluntary disruptions. For example, a quorum-based application would
|
||||
Kubernetes offers features to help you run highly available applications even when you
|
||||
introduce frequent voluntary disruptions.
|
||||
|
||||
As an application owner, you can create a PodDisruptionBudget (PDB) for each application.
|
||||
A PDB limits the number of Pods of a replicated application that are down simultaneously from
|
||||
voluntary disruptions. For example, a quorum-based application would
|
||||
like to ensure that the number of replicas running is never brought below the
|
||||
number needed for a quorum. A web front end might want to
|
||||
ensure that the number of replicas serving load never falls below a certain
|
||||
percentage of the total.
|
||||
|
||||
Cluster managers and hosting providers should use tools which
|
||||
respect Pod Disruption Budgets by calling the [Eviction API](/docs/tasks/administer-cluster/safely-drain-node/#the-eviction-api)
|
||||
instead of directly deleting pods or deployments. Examples are the `kubectl drain` command
|
||||
and the Kubernetes-on-GCE cluster upgrade script (`cluster/gce/upgrade.sh`).
|
||||
respect PodDisruptionBudgets by calling the [Eviction API](/docs/tasks/administer-cluster/safely-drain-node/#the-eviction-api)
|
||||
instead of directly deleting pods or deployments.
|
||||
|
||||
When a cluster administrator wants to drain a node
|
||||
they use the `kubectl drain` command. That tool tries to evict all
|
||||
the pods on the machine. The eviction request may be temporarily rejected,
|
||||
and the tool periodically retries all failed requests until all pods
|
||||
are terminated, or until a configurable timeout is reached.
|
||||
For example, the `kubectl drain` subcommand lets you mark a node as going out of
|
||||
service. When you run `kubectl drain`, the tool tries to evict all of the Pods on
|
||||
the Node you're taking out of service. The eviction request that `kubectl` submits on
|
||||
your behalf may be temporarily rejected, so the tool periodically retries all failed
|
||||
requests until all Pods on the target node are terminated, or until a configurable timeout
|
||||
is reached.
|
||||
|
||||
A PDB specifies the number of replicas that an application can tolerate having, relative to how
|
||||
many it is intended to have. For example, a Deployment which has a `.spec.replicas: 5` is
|
||||
supposed to have 5 pods at any given time. If its PDB allows for there to be 4 at a time,
|
||||
then the Eviction API will allow voluntary disruption of one, but not two pods, at a time.
|
||||
then the Eviction API will allow voluntary disruption of one (but not two) pods at a time.
|
||||
|
||||
The group of pods that comprise the application is specified using a label selector, the same
|
||||
as the one used by the application's controller (deployment, stateful-set, etc).
|
||||
|
||||
The "intended" number of pods is computed from the `.spec.replicas` of the pods controller.
|
||||
The controller is discovered from the pods using the `.metadata.ownerReferences` of the object.
|
||||
The "intended" number of pods is computed from the `.spec.replicas` of the workload resource
|
||||
that is managing those pods. The control plane discovers the owning workload resource by
|
||||
examining the `.metadata.ownerReferences` of the Pod.
|
||||
|
||||
PDBs cannot prevent [involuntary disruptions](#voluntary-and-involuntary-disruptions) from
|
||||
occurring, but they do count against the budget.
|
||||
|
||||
Pods which are deleted or unavailable due to a rolling upgrade to an application do count
|
||||
against the disruption budget, but controllers (like deployment and stateful-set)
|
||||
are not limited by PDBs when doing rolling upgrades -- the handling of failures
|
||||
during application updates is configured in the controller spec.
|
||||
(Learn about [updating a deployment](/docs/concepts/workloads/controllers/deployment/#updating-a-deployment).)
|
||||
against the disruption budget, but workload resources (such as Deployment and StatefulSet)
|
||||
are not limited by PDBs when doing rolling upgrades. Instead, the handling of failures
|
||||
during application updates is configured in the spec for the specific workload resource.
|
||||
|
||||
When a pod is evicted using the eviction API, it is gracefully terminated (see
|
||||
`terminationGracePeriodSeconds` in [PodSpec](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#podspec-v1-core).)
|
||||
When a pod is evicted using the eviction API, it is gracefully
|
||||
[terminated](/docs/concepts/workloads/pods/pod-lifecycle/#pod-termination), honoring the
|
||||
`terminationGracePeriodSeconds` setting in its [PodSpec](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#podspec-v1-core).)
|
||||
|
||||
## PDB Example
|
||||
## PodDisruptionBudget example {#pdb-example}
|
||||
|
||||
Consider a cluster with 3 nodes, `node-1` through `node-3`.
|
||||
The cluster is running several applications. One of them has 3 replicas initially called
|
||||
|
|
@ -272,4 +270,6 @@ the nodes in your cluster, such as a node or system software upgrade, here are s
|
|||
|
||||
* Learn more about [draining nodes](/docs/tasks/administer-cluster/safely-drain-node/)
|
||||
|
||||
* Learn about [updating a deployment](/docs/concepts/workloads/controllers/deployment/#updating-a-deployment)
|
||||
including steps to maintain its availability during the rollout.
|
||||
|
||||
|
|
|
|||
|
|
@ -6,16 +6,60 @@ weight: 30
|
|||
|
||||
<!-- overview -->
|
||||
|
||||
{{< comment >}}Updated: 4/14/2015{{< /comment >}}
|
||||
{{< comment >}}Edited and moved to Concepts section: 2/2/17{{< /comment >}}
|
||||
|
||||
This page describes the lifecycle of a Pod.
|
||||
This page describes the lifecycle of a Pod. Pods follow a defined lifecycle, starting
|
||||
in the `Pending` [phase](#pod-phase), moving through `Running` if at least one
|
||||
of its primary containers starts OK, and then through either the `Succeeded` or
|
||||
`Failed` phases depending on whether any container in the Pod terminated in failure.
|
||||
|
||||
Whilst a Pod is running, the kubelet is able to restart containers to handle some
|
||||
kind of faults. Within a Pod, Kubernetes tracks different container
|
||||
[states](#container-states) and handles
|
||||
|
||||
In the Kubernetes API, Pods have both a specification and an actual status. The
|
||||
status for a Pod object consists of a set of [Pod conditions](#pod-conditions).
|
||||
You can also inject [custom readiness information](#pod-readiness-gate) into the
|
||||
condition data for a Pod, if that is useful to your application.
|
||||
|
||||
Pods are only [scheduled](/docs/concepts/scheduling-eviction/) once in their lifetime.
|
||||
Once a Pod is scheduled (assigned) to a Node, the Pod runs on that Node until it stops
|
||||
or is [terminated](#pod-termination).
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## Pod lifetime
|
||||
|
||||
Like individual application containers, Pods are considered to be relatively
|
||||
ephemeral (rather than durable) entities. Pods are created, assigned a unique
|
||||
ID ([UID](/docs/concepts/overview/working-with-objects/names/#uids)), and scheduled
|
||||
to nodes where they remain until termination (according to restart policy) or
|
||||
deletion.
|
||||
If a {{< glossary_tooltip term_id="node" >}} dies, the Pods scheduled to that node
|
||||
are [scheduled for deletion](#pod-garbage-collection) after a timeout period.
|
||||
|
||||
Pods do not, by themselves, self-heal. If a Pod is scheduled to a
|
||||
{{< glossary_tooltip text="node" term_id="node" >}} that then fails,
|
||||
or if the scheduling operation itself fails, the Pod is deleted; likewise, a Pod won't
|
||||
survive an eviction due to a lack of resources or Node maintenance. Kubernetes uses a
|
||||
higher-level abstraction, called a
|
||||
{{< glossary_tooltip term_id="controller" text="controller" >}}, that handles the work of
|
||||
managing the relatively disposable Pod instances.
|
||||
|
||||
A given Pod (as defined by a UID) is never "rescheduled" to a different node; instead,
|
||||
that Pod can be replaced by a new, near-identical Pod, with even the same name i
|
||||
desired, but with a different UID.
|
||||
|
||||
When something is said to have the same lifetime as a Pod, such as a
|
||||
{{< glossary_tooltip term_id="volume" text="volume" >}},
|
||||
that means that the thing exists as long as that specific Pod (with that exact UID)
|
||||
exists. If that Pod is deleted for any reason, and even if an identical replacement
|
||||
is created, the related thing (a volume, in this example) is also destroyed and
|
||||
created anew.
|
||||
|
||||
{{< figure src="/images/docs/pod.svg" title="Pod diagram" width="50%" >}}
|
||||
|
||||
*A multi-container Pod that contains a file puller and a
|
||||
web server that uses a persistent volume for shared storage between the containers.*
|
||||
|
||||
## Pod phase
|
||||
|
||||
A Pod's `status` field is a
|
||||
|
|
@ -24,7 +68,7 @@ object, which has a `phase` field.
|
|||
|
||||
The phase of a Pod is a simple, high-level summary of where the Pod is in its
|
||||
lifecycle. The phase is not intended to be a comprehensive rollup of observations
|
||||
of Container or Pod state, nor is it intended to be a comprehensive state machine.
|
||||
of container or Pod state, nor is it intended to be a comprehensive state machine.
|
||||
|
||||
The number and meanings of Pod phase values are tightly guarded.
|
||||
Other than what is documented here, nothing should be assumed about Pods that
|
||||
|
|
@ -34,188 +78,106 @@ Here are the possible values for `phase`:
|
|||
|
||||
Value | Description
|
||||
:-----|:-----------
|
||||
`Pending` | The Pod has been accepted by the Kubernetes system, but one or more of the Container images has not been created. This includes time before being scheduled as well as time spent downloading images over the network, which could take a while.
|
||||
`Running` | The Pod has been bound to a node, and all of the Containers have been created. At least one Container is still running, or is in the process of starting or restarting.
|
||||
`Succeeded` | All Containers in the Pod have terminated in success, and will not be restarted.
|
||||
`Failed` | All Containers in the Pod have terminated, and at least one Container has terminated in failure. That is, the Container either exited with non-zero status or was terminated by the system.
|
||||
`Unknown` | For some reason the state of the Pod could not be obtained, typically due to an error in communicating with the host of the Pod.
|
||||
`Pending` | The Pod has been accepted by the Kubernetes cluster, but one or more of the containers has not been set up and made ready to run. This includes time a Pod spends waiting to bescheduled as well as the time spent downloading container images over the network.
|
||||
`Running` | The Pod has been bound to a node, and all of the containers have been created. At least one container is still running, or is in the process of starting or restarting.
|
||||
`Succeeded` | All containers in the Pod have terminated in success, and will not be restarted.
|
||||
`Failed` | All containers in the Pod have terminated, and at least one container has terminated in failure. That is, the container either exited with non-zero status or was terminated by the system.
|
||||
`Unknown` | For some reason the state of the Pod could not be obtained. This phase typically occurs due to an error in communicating with the node where the Pod should be running.
|
||||
|
||||
If a node dies or is disconnected from the rest of the cluster, Kubernetes
|
||||
applies a policy for setting the `phase` of all Pods on the lost node to Failed.
|
||||
|
||||
## Container states
|
||||
|
||||
As well as the [phase](#pod-phase) of the Pod overall, Kubernetes tracks the state of
|
||||
each container inside a Pod. You can use
|
||||
[container lifecycle hooks](/docs/concepts/containers/container-lifecycle-hooks/) to
|
||||
trigger events to run at certain points in a container's lifecycle.
|
||||
|
||||
Once the {{< glossary_tooltip text="scheduler" term_id="kube-scheduler" >}}
|
||||
assigns a Pod to a Node, the kubelet starts creating containers for that Pod
|
||||
using a {{< glossary_tooltip text="container runtime" term_id="container-runtime" >}}.
|
||||
There are three possible container states: `Waiting`, `Running`, and `Terminated`.
|
||||
|
||||
To the check state of a Pod's containers, you can use
|
||||
`kubectl describe pod <name-of-pod>`. The output shows the state for each container
|
||||
within that Pod.
|
||||
|
||||
Each state has a specific meaning:
|
||||
|
||||
### `Waiting` {#container-state-waiting}
|
||||
|
||||
If a container is not in either the `Running` or `Terminated` state, it `Waiting`.
|
||||
A container in the `Waiting` state is still running the operations it requires in
|
||||
order to complete start up: for example, pulling the container image from a container
|
||||
image registry, or applying {{< glossary_tooltip text="Secret" term_id="secret" >}}
|
||||
data.
|
||||
When you use `kubectl` to query a Pod with a container that is `Waiting`, you also see
|
||||
a Reason field to summarize why the container is in that state.
|
||||
|
||||
### `Running` {#container-state-running}
|
||||
|
||||
The `Running` status indicates that a container is executing without issues. If there
|
||||
was a `postStart` hook configured, it has already executed and executed. When you use
|
||||
`kubectl` to query a Pod with a container that is `Running`, you also see information
|
||||
about when the container entered the `Running` state.
|
||||
|
||||
### `Terminated` {#container-state-terminated}
|
||||
|
||||
A container in the `Terminated` state has begin execution and has then either run to
|
||||
completion or has failed for some reason. When you use `kubectl` to query a Pod with
|
||||
a container that is `Terminated`, you see a reason, and exit code, and the start and
|
||||
finish time for that container's period of execution.
|
||||
|
||||
If a container has a `preStop` hook configured, that runs before the container enters
|
||||
the `Terminated` state.
|
||||
|
||||
## Container restart policy {#restart-policy}
|
||||
|
||||
The `spec` of a Pod has a `restartPolicy` field with possible values Always, OnFailure,
|
||||
and Never. The default value is Always.
|
||||
|
||||
The `restartPolicy` applies to all containers in the Pod. `restartPolicy` only
|
||||
refers to restarts of the containers by the kubelet on the same node. After containers
|
||||
in a Pod exit, the kubelet restarts them with an exponential back-off delay (10s, 20s,
|
||||
40s, …), that is capped at five minutes. Once a container has executed with no problems
|
||||
for 10 minutes without any problems, the kubelet resets the restart backoff timer for
|
||||
that container.
|
||||
|
||||
## Pod conditions
|
||||
|
||||
A Pod has a PodStatus, which has an array of
|
||||
[PodConditions](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#podcondition-v1-core)
|
||||
through which the Pod has or has not passed. Each element of the PodCondition
|
||||
array has six possible fields:
|
||||
through which the Pod has or has not passed:
|
||||
|
||||
* The `lastProbeTime` field provides a timestamp for when the Pod condition
|
||||
was last probed.
|
||||
* `PodScheduled`: the Pod has been scheduled to a node.
|
||||
* `ContainersReady`: all containers in the Pod are ready.
|
||||
* `Initialized`: all [init containers](/docs/concepts/workloads/pods/init-containers/)
|
||||
have started successfully.
|
||||
* `Ready`: the Pod is able to serve requests and should be added to the load
|
||||
balancing pools of all matching Services.
|
||||
|
||||
* The `lastTransitionTime` field provides a timestamp for when the Pod
|
||||
last transitioned from one status to another.
|
||||
|
||||
* The `message` field is a human-readable message indicating details
|
||||
about the transition.
|
||||
|
||||
* The `reason` field is a unique, one-word, CamelCase reason for the condition's last transition.
|
||||
|
||||
* The `status` field is a string, with possible values "`True`", "`False`", and "`Unknown`".
|
||||
|
||||
* The `type` field is a string with the following possible values:
|
||||
|
||||
* `PodScheduled`: the Pod has been scheduled to a node;
|
||||
* `Ready`: the Pod is able to serve requests and should be added to the load
|
||||
balancing pools of all matching Services;
|
||||
* `Initialized`: all [init containers](/docs/concepts/workloads/pods/init-containers)
|
||||
have started successfully;
|
||||
* `ContainersReady`: all containers in the Pod are ready.
|
||||
Field name | Description
|
||||
:--------------------|:-----------
|
||||
`type` | Name of this Pod condition.
|
||||
`status` | Indicates whether that condition is applicable, with possible values "`True`", "`False`", or "`Unknown`".
|
||||
`lastProbeTime` | Timestamp of when the Pod condition was last probed.
|
||||
`lastTransitionTime` | Timestamp for when the Pod last transitioned from one status to another.
|
||||
`reason` | Machine-readable, UpperCamelCase text indicating the reason for the condition's last transition.
|
||||
`message` | Human-readable message indicating details about the last status transition.
|
||||
|
||||
|
||||
|
||||
## Container probes
|
||||
|
||||
A [Probe](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#probe-v1-core) is a diagnostic
|
||||
performed periodically by the [kubelet](/docs/admin/kubelet/)
|
||||
on a Container. To perform a diagnostic,
|
||||
the kubelet calls a
|
||||
[Handler](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#handler-v1-core) implemented by
|
||||
the Container. There are three types of handlers:
|
||||
|
||||
* [ExecAction](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#execaction-v1-core):
|
||||
Executes a specified command inside the Container. The diagnostic
|
||||
is considered successful if the command exits with a status code of 0.
|
||||
|
||||
* [TCPSocketAction](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#tcpsocketaction-v1-core):
|
||||
Performs a TCP check against the Container's IP address on
|
||||
a specified port. The diagnostic is considered successful if the port is open.
|
||||
|
||||
* [HTTPGetAction](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#httpgetaction-v1-core):
|
||||
Performs an HTTP Get request against the Container's IP
|
||||
address on a specified port and path. The diagnostic is considered successful
|
||||
if the response has a status code greater than or equal to 200 and less than 400.
|
||||
|
||||
Each probe has one of three results:
|
||||
|
||||
* Success: The Container passed the diagnostic.
|
||||
* Failure: The Container failed the diagnostic.
|
||||
* Unknown: The diagnostic failed, so no action should be taken.
|
||||
|
||||
The kubelet can optionally perform and react to three kinds of probes on running
|
||||
Containers:
|
||||
|
||||
* `livenessProbe`: Indicates whether the Container is running. If
|
||||
the liveness probe fails, the kubelet kills the Container, and the Container
|
||||
is subjected to its [restart policy](#restart-policy). If a Container does not
|
||||
provide a liveness probe, the default state is `Success`.
|
||||
|
||||
* `readinessProbe`: Indicates whether the Container is ready to service requests.
|
||||
If the readiness probe fails, the endpoints controller removes the Pod's IP
|
||||
address from the endpoints of all Services that match the Pod. The default
|
||||
state of readiness before the initial delay is `Failure`. If a Container does
|
||||
not provide a readiness probe, the default state is `Success`.
|
||||
|
||||
* `startupProbe`: Indicates whether the application within the Container is started.
|
||||
All other probes are disabled if a startup probe is provided, until it succeeds.
|
||||
If the startup probe fails, the kubelet kills the Container, and the Container
|
||||
is subjected to its [restart policy](#restart-policy). If a Container does not
|
||||
provide a startup probe, the default state is `Success`.
|
||||
|
||||
### When should you use a liveness probe?
|
||||
|
||||
{{< feature-state for_k8s_version="v1.0" state="stable" >}}
|
||||
|
||||
If the process in your Container is able to crash on its own whenever it
|
||||
encounters an issue or becomes unhealthy, you do not necessarily need a liveness
|
||||
probe; the kubelet will automatically perform the correct action in accordance
|
||||
with the Pod's `restartPolicy`.
|
||||
|
||||
If you'd like your Container to be killed and restarted if a probe fails, then
|
||||
specify a liveness probe, and specify a `restartPolicy` of Always or OnFailure.
|
||||
|
||||
### When should you use a readiness probe?
|
||||
|
||||
{{< feature-state for_k8s_version="v1.0" state="stable" >}}
|
||||
|
||||
If you'd like to start sending traffic to a Pod only when a probe succeeds,
|
||||
specify a readiness probe. In this case, the readiness probe might be the same
|
||||
as the liveness probe, but the existence of the readiness probe in the spec means
|
||||
that the Pod will start without receiving any traffic and only start receiving
|
||||
traffic after the probe starts succeeding.
|
||||
If your Container needs to work on loading large data, configuration files, or migrations during startup, specify a readiness probe.
|
||||
|
||||
If you want your Container to be able to take itself down for maintenance, you
|
||||
can specify a readiness probe that checks an endpoint specific to readiness that
|
||||
is different from the liveness probe.
|
||||
|
||||
Note that if you just want to be able to drain requests when the Pod is deleted,
|
||||
you do not necessarily need a readiness probe; on deletion, the Pod automatically
|
||||
puts itself into an unready state regardless of whether the readiness probe exists.
|
||||
The Pod remains in the unready state while it waits for the Containers in the Pod
|
||||
to stop.
|
||||
|
||||
### When should you use a startup probe?
|
||||
|
||||
{{< feature-state for_k8s_version="v1.16" state="alpha" >}}
|
||||
|
||||
If your Container usually starts in more than `initialDelaySeconds + failureThreshold × periodSeconds`, you should specify a startup probe that checks the same endpoint as the liveness probe. The default for `periodSeconds` is 30s.
|
||||
You should then set its `failureThreshold` high enough to allow the Container to start, without changing the default values of the liveness probe. This helps to protect against deadlocks.
|
||||
|
||||
For more information about how to set up a liveness, readiness, startup probe, see
|
||||
[Configure Liveness, Readiness and Startup Probes](/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/).
|
||||
|
||||
## Pod and Container status
|
||||
|
||||
For detailed information about Pod Container status, see
|
||||
[PodStatus](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#podstatus-v1-core)
|
||||
and
|
||||
[ContainerStatus](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#containerstatus-v1-core).
|
||||
Note that the information reported as Pod status depends on the current
|
||||
[ContainerState](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#containerstatus-v1-core).
|
||||
|
||||
## Container States
|
||||
|
||||
Once Pod is assigned to a node by scheduler, kubelet starts creating containers using container runtime.There are three possible states of containers: Waiting, Running and Terminated. To check state of container, you can use `kubectl describe pod [POD_NAME]`. State is displayed for each container within that Pod.
|
||||
|
||||
* `Waiting`: Default state of container. If container is not in either Running or Terminated state, it is in Waiting state. A container in Waiting state still runs its required operations, like pulling images, applying Secrets, etc. Along with this state, a message and reason about the state are displayed to provide more information.
|
||||
|
||||
```yaml
|
||||
...
|
||||
State: Waiting
|
||||
Reason: ErrImagePull
|
||||
...
|
||||
```
|
||||
|
||||
* `Running`: Indicates that the container is executing without issues. The `postStart` hook (if any) is executed prior to the container entering a Running state. This state also displays the time when the container entered Running state.
|
||||
|
||||
```yaml
|
||||
...
|
||||
State: Running
|
||||
Started: Wed, 30 Jan 2019 16:46:38 +0530
|
||||
...
|
||||
```
|
||||
|
||||
* `Terminated`: Indicates that the container completed its execution and has stopped running. A container enters into this when it has successfully completed execution or when it has failed for some reason. Regardless, a reason and exit code is displayed, as well as the container's start and finish time. Before a container enters into Terminated, `preStop` hook (if any) is executed.
|
||||
|
||||
```yaml
|
||||
...
|
||||
State: Terminated
|
||||
Reason: Completed
|
||||
Exit Code: 0
|
||||
Started: Wed, 30 Jan 2019 11:45:26 +0530
|
||||
Finished: Wed, 30 Jan 2019 11:45:26 +0530
|
||||
...
|
||||
```
|
||||
|
||||
## Pod readiness {#pod-readiness-gate}
|
||||
### Pod readiness {#pod-readiness-gate}
|
||||
|
||||
{{< feature-state for_k8s_version="v1.14" state="stable" >}}
|
||||
|
||||
Your application can inject extra feedback or signals into PodStatus:
|
||||
_Pod readiness_. To use this, set `readinessGates` in the PodSpec to specify
|
||||
a list of additional conditions that the kubelet evaluates for Pod readiness.
|
||||
_Pod readiness_. To use this, set `readinessGates` in the Pod's `spec` to
|
||||
specify a list of additional conditions that the kubelet evaluates for Pod readiness.
|
||||
|
||||
Readiness gates are determined by the current state of `status.condition`
|
||||
fields for the Pod. If Kubernetes cannot find such a
|
||||
condition in the `status.conditions` field of a Pod, the status of the condition
|
||||
fields for the Pod. If Kubernetes cannot find such a condition in the
|
||||
`status.conditions` field of a Pod, the status of the condition
|
||||
is defaulted to "`False`".
|
||||
|
||||
Here is an example:
|
||||
|
|
@ -258,152 +220,226 @@ For a Pod that uses custom conditions, that Pod is evaluated to be ready **only*
|
|||
when both the following statements apply:
|
||||
|
||||
* All containers in the Pod are ready.
|
||||
* All conditions specified in `ReadinessGates` are `True`.
|
||||
* All conditions specified in `readinessGates` are `True`.
|
||||
|
||||
When a Pod's containers are Ready but at least one custom condition is missing or
|
||||
`False`, the kubelet sets the Pod's condition to `ContainersReady`.
|
||||
`False`, the kubelet sets the Pod's [condition](#pod-condition) to `ContainersReady`.
|
||||
|
||||
## Restart policy
|
||||
## Container probes
|
||||
|
||||
A PodSpec has a `restartPolicy` field with possible values Always, OnFailure,
|
||||
and Never. The default value is Always.
|
||||
`restartPolicy` applies to all Containers in the Pod. `restartPolicy` only
|
||||
refers to restarts of the Containers by the kubelet on the same node. Exited
|
||||
Containers that are restarted by the kubelet are restarted with an exponential
|
||||
back-off delay (10s, 20s, 40s ...) capped at five minutes, and is reset after ten
|
||||
minutes of successful execution. As discussed in the
|
||||
[Pods document](/docs/user-guide/pods/#durability-of-pods-or-lack-thereof),
|
||||
once bound to a node, a Pod will never be rebound to another node.
|
||||
A [Probe](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#probe-v1-core) is a diagnostic
|
||||
performed periodically by the [kubelet](/docs/admin/kubelet/)
|
||||
on a Container. To perform a diagnostic,
|
||||
the kubelet calls a
|
||||
[Handler](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#handler-v1-core) implemented by
|
||||
the container. There are three types of handlers:
|
||||
|
||||
* [ExecAction](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#execaction-v1-core):
|
||||
Executes a specified command inside the container. The diagnostic
|
||||
is considered successful if the command exits with a status code of 0.
|
||||
|
||||
## Pod lifetime
|
||||
* [TCPSocketAction](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#tcpsocketaction-v1-core):
|
||||
Performs a TCP check against the Pod's IP address on
|
||||
a specified port. The diagnostic is considered successful if the port is open.
|
||||
|
||||
In general, Pods remain until a human or
|
||||
* [HTTPGetAction](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#httpgetaction-v1-core):
|
||||
Performs an HTTP `GET` request against the Pod's IP
|
||||
address on a specified port and path. The diagnostic is considered successful
|
||||
if the response has a status code greater than or equal to 200 and less than 400.
|
||||
|
||||
Each probe has one of three results:
|
||||
|
||||
* `Success`: The container passed the diagnostic.
|
||||
* `Failure`: The container failed the diagnostic.
|
||||
* `Unknown`: The diagnostic failed, so no action should be taken.
|
||||
|
||||
The kubelet can optionally perform and react to three kinds of probes on running
|
||||
containers:
|
||||
|
||||
* `livenessProbe`: Indicates whether the container is running. If
|
||||
the liveness probe fails, the kubelet kills the container, and the container
|
||||
is subjected to its [restart policy](#restart-policy). If a Container does not
|
||||
provide a liveness probe, the default state is `Success`.
|
||||
|
||||
* `readinessProbe`: Indicates whether the container is ready to respond to requests.
|
||||
If the readiness probe fails, the endpoints controller removes the Pod's IP
|
||||
address from the endpoints of all Services that match the Pod. The default
|
||||
state of readiness before the initial delay is `Failure`. If a Container does
|
||||
not provide a readiness probe, the default state is `Success`.
|
||||
|
||||
* `startupProbe`: Indicates whether the application within the container is started.
|
||||
All other probes are disabled if a startup probe is provided, until it succeeds.
|
||||
If the startup probe fails, the kubelet kills the container, and the container
|
||||
is subjected to its [restart policy](#restart-policy). If a Container does not
|
||||
provide a startup probe, the default state is `Success`.
|
||||
|
||||
For more information about how to set up a liveness, readiness, or startup probe,
|
||||
see [Configure Liveness, Readiness and Startup Probes](/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/).
|
||||
|
||||
### When should you use a liveness probe?
|
||||
|
||||
{{< feature-state for_k8s_version="v1.0" state="stable" >}}
|
||||
|
||||
If the process in your container is able to crash on its own whenever it
|
||||
encounters an issue or becomes unhealthy, you do not necessarily need a liveness
|
||||
probe; the kubelet will automatically perform the correct action in accordance
|
||||
with the Pod's `restartPolicy`.
|
||||
|
||||
If you'd like your container to be killed and restarted if a probe fails, then
|
||||
specify a liveness probe, and specify a `restartPolicy` of Always or OnFailure.
|
||||
|
||||
### When should you use a readiness probe?
|
||||
|
||||
{{< feature-state for_k8s_version="v1.0" state="stable" >}}
|
||||
|
||||
If you'd like to start sending traffic to a Pod only when a probe succeeds,
|
||||
specify a readiness probe. In this case, the readiness probe might be the same
|
||||
as the liveness probe, but the existence of the readiness probe in the spec means
|
||||
that the Pod will start without receiving any traffic and only start receiving
|
||||
traffic after the probe starts succeeding.
|
||||
If your container needs to work on loading large data, configuration files, or
|
||||
migrations during startup, specify a readiness probe.
|
||||
|
||||
If you want your container to be able to take itself down for maintenance, you
|
||||
can specify a readiness probe that checks an endpoint specific to readiness that
|
||||
is different from the liveness probe.
|
||||
|
||||
{{< note >}}
|
||||
If you just want to be able to drain requests when the Pod is deleted, you do not
|
||||
necessarily need a readiness probe; on deletion, the Pod automatically puts itself
|
||||
into an unready state regardless of whether the readiness probe exists.
|
||||
The Pod remains in the unready state while it waits for the containers in the Pod
|
||||
to stop.
|
||||
{{< /note >}}
|
||||
|
||||
### When should you use a startup probe?
|
||||
|
||||
{{< feature-state for_k8s_version="v1.16" state="alpha" >}}
|
||||
|
||||
Startup probes are useful for Pods that have containers that take a long time to
|
||||
come into service. Rather than set a long liveness interval, you can configure
|
||||
a separate configuration for probing the container as it starts up, allowing
|
||||
a time longer than the liveness interval would allow.
|
||||
|
||||
If your container usually starts in more than
|
||||
`initialDelaySeconds + failureThreshold × periodSeconds`, you should specify a
|
||||
startup probe that checks the same endpoint as the liveness probe. The default for
|
||||
`periodSeconds` is 30s. You should then set its `failureThreshold` high enough to
|
||||
allow the container to start, without changing the default values of the liveness
|
||||
probe. This helps to protect against deadlocks.
|
||||
|
||||
## Termination of Pods {#pod-termination}
|
||||
|
||||
Because Pods represent processes running on nodes in the cluster, it is important to
|
||||
allow those processes to gracefully terminate when they are no longer needed (rather
|
||||
than being abruptly stopped with a `KILL` signal and having no chance to clean up).
|
||||
|
||||
The design aim is for you to be able to request deletion and know when processes
|
||||
terminate, but also be able to ensure that deletes eventually complete.
|
||||
When you request deletion of a Pod, the cluster records and tracks the intended grace period
|
||||
before the Pod is allowed to be forcefully killed. With that forceful shutdown tracking in
|
||||
place, the {{< glossary_tooltip text="kubelet" term_id="kubelet" >}} attempts graceful
|
||||
shutdown.
|
||||
|
||||
Typically, the container runtime sends a a TERM signal is sent to the main process in each
|
||||
container. Once the grace period has expired, the KILL signal is sent to any remainig
|
||||
processes, and the Pod is then deleted from the
|
||||
{{< glossary_tooltip text="API Server" term_id="kube-apiserver" >}}. If the kubelet or the
|
||||
container runtime's management service is restarted while waiting for processes to terminate, the
|
||||
cluster retries from the start including the full original grace period.
|
||||
|
||||
An example flow:
|
||||
|
||||
1. You use the `kubectl` tool to manually delete a specific Pod, with the default grace period
|
||||
(30 seconds).
|
||||
1. The Pod in the API server is updated with the time beyond which the Pod is considered "dead"
|
||||
along with the grace period.
|
||||
If you use `kubectl describe` to check on the Pod you're deleting, that Pod shows up as
|
||||
"Terminating".
|
||||
On the node where the Pod is running: as soon as the kubelet sees that a Pod has been marked
|
||||
as terminating (a graceful shutdown duration has been set), the kubelet begins the local Pod
|
||||
shutdown process.
|
||||
1. If one of the Pod's containers has defined a `preStop`
|
||||
[hook](/docs/concepts/containers/container-lifecycle-hooks/#hook-details), the kubelet
|
||||
runs that hook inside of the container. If the `preStop` hook is still running after the
|
||||
grace period expires, the kubelet requests a small, one-off grace period extension of 2
|
||||
seconds.
|
||||
{{< note >}}
|
||||
If the `preStop` hook needs longer to complete than the default grace period allows,
|
||||
you must modify `terminationGracePeriodSeconds` to suit this.
|
||||
{{< /note >}}
|
||||
1. The kubelet triggers the container runtime to send a TERM signal to process 1 inside each
|
||||
container.
|
||||
{{< note >}}
|
||||
The containers in the Pod receive the TERM signal at different times and in an arbitrary
|
||||
order. If the order of shutdowns matters, consider using a `preStop` hook to synchronize.
|
||||
{{< /note >}}
|
||||
1. At the same time as the kubelet is starting graceful shutdown, the control plane removes that
|
||||
shutting-down Pod from Endpoints (and, if enabled, EndpointSlice) objects where these represent
|
||||
a {{< glossary_tooltip term_id="service" text="Service" >}} with a configured
|
||||
{{< glossary_tooltip text="selector" term_id="selector" >}}.
|
||||
{{< glossary_tooltip text="ReplicaSets" term_id="replica-set" >}} and other workload resources
|
||||
no longer treat the shutting-down Pod as a valid, in-service replica. Pods that shut down slowly
|
||||
cannot continue to serve traffic as load balancers (like the service proxy) remove the Pod from
|
||||
the list of endpoints as soon as the termination grace period _begins_.
|
||||
1. When the grace period expires, the kubelet triggers forcible shutdown. The container runtime sends
|
||||
`SIGKILL` to any processes still running in any container in the Pod.
|
||||
The kubelet also cleans up a hidden `pause` container if that container runtime uses one.
|
||||
1. The kubelet triggers forcible removal of Pod object from the API server, by setting grace period
|
||||
to 0 (immediate deletion).
|
||||
1. The API server deletes the Pod's API object, which is then no longer visible from any client.
|
||||
|
||||
### Forced Pod termination {#pod-termination-forced}
|
||||
|
||||
{{< caution >}}
|
||||
Forced deletions can be potentially disruptiove for some workloads and their Pods.
|
||||
{{< /caution >}}
|
||||
|
||||
By default, all deletes are graceful within 30 seconds. The `kubectl delete` command supports
|
||||
the `--grace-period=<seconds>` option which allows you to override the default and specify your
|
||||
own value.
|
||||
|
||||
Setting the grace period to `0` forcibly and immediately deletes the Pod from the API
|
||||
server. If the pod was still running on a node, that forcible deletion triggers the kubelet to
|
||||
begin immediate cleanup.
|
||||
|
||||
{{< note >}}
|
||||
You must specify an additional flag `--force` along with `--grace-period=0` in order to perform force deletions.
|
||||
{{< /note >}}
|
||||
|
||||
When a force deletion is performed, the API server does not wait for confirmation
|
||||
from the kubelet that the Pod has been terminated on the node it was running on. It
|
||||
removes the Pod in the API immediately so a new Pod can be created with the same
|
||||
name. On the node, Pods that are set to terminate immediately will still be given
|
||||
a small grace period before being force killed.
|
||||
|
||||
If you need to force-delete Pods that are part of a StatefulSet, refer to the task
|
||||
documentation for
|
||||
[deleting Pods from a StatefulSet](/docs/tasks/run-application/force-delete-stateful-set-pod/).
|
||||
|
||||
### Garbage collection of failed Pods {#pod-garbage-collection}
|
||||
|
||||
For failed Pods, the API objects remain in the cluster's API until a human or
|
||||
{{< glossary_tooltip term_id="controller" text="controller" >}} process
|
||||
explicitly removes them.
|
||||
|
||||
The control plane cleans up terminated Pods (with a phase of `Succeeded` or
|
||||
`Failed`), when the number of Pods exceeds the configured threshold
|
||||
(determined by `terminated-pod-gc-threshold` in the kube-controller-manager).
|
||||
This avoids a resource leak as Pods are created and terminated over time.
|
||||
|
||||
There are different kinds of resources for creating Pods:
|
||||
|
||||
- Use a {{< glossary_tooltip term_id="deployment" >}},
|
||||
{{< glossary_tooltip term_id="replica-set" >}} or {{< glossary_tooltip term_id="statefulset" >}}
|
||||
for Pods that are not expected to terminate, for example, web servers.
|
||||
|
||||
- Use a {{< glossary_tooltip term_id="job" >}}
|
||||
for Pods that are expected to terminate once their work is complete;
|
||||
for example, batch computations. Jobs are appropriate only for Pods with
|
||||
`restartPolicy` equal to OnFailure or Never.
|
||||
|
||||
- Use a {{< glossary_tooltip term_id="daemonset" >}}
|
||||
for Pods that need to run one per eligible node.
|
||||
|
||||
All workload resources contain a PodSpec. It is recommended to create the
|
||||
appropriate workload resource and let the resource's controller create Pods
|
||||
for you, rather than directly create Pods yourself.
|
||||
|
||||
If a node dies or is disconnected from the rest of the cluster, Kubernetes
|
||||
applies a policy for setting the `phase` of all Pods on the lost node to Failed.
|
||||
|
||||
## Examples
|
||||
|
||||
### Advanced liveness probe example
|
||||
|
||||
Liveness probes are executed by the kubelet, so all requests are made in the
|
||||
kubelet network namespace.
|
||||
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
labels:
|
||||
test: liveness
|
||||
name: liveness-http
|
||||
spec:
|
||||
containers:
|
||||
- args:
|
||||
- /server
|
||||
image: k8s.gcr.io/liveness
|
||||
livenessProbe:
|
||||
httpGet:
|
||||
# when "host" is not defined, "PodIP" will be used
|
||||
# host: my-host
|
||||
# when "scheme" is not defined, "HTTP" scheme will be used. Only "HTTP" and "HTTPS" are allowed
|
||||
# scheme: HTTPS
|
||||
path: /healthz
|
||||
port: 8080
|
||||
httpHeaders:
|
||||
- name: X-Custom-Header
|
||||
value: Awesome
|
||||
initialDelaySeconds: 15
|
||||
timeoutSeconds: 1
|
||||
name: liveness
|
||||
```
|
||||
|
||||
### Example states
|
||||
|
||||
* Pod is running and has one Container. Container exits with success.
|
||||
* Log completion event.
|
||||
* If `restartPolicy` is:
|
||||
* Always: Restart Container; Pod `phase` stays Running.
|
||||
* OnFailure: Pod `phase` becomes Succeeded.
|
||||
* Never: Pod `phase` becomes Succeeded.
|
||||
|
||||
* Pod is running and has one Container. Container exits with failure.
|
||||
* Log failure event.
|
||||
* If `restartPolicy` is:
|
||||
* Always: Restart Container; Pod `phase` stays Running.
|
||||
* OnFailure: Restart Container; Pod `phase` stays Running.
|
||||
* Never: Pod `phase` becomes Failed.
|
||||
|
||||
* Pod is running and has two Containers. Container 1 exits with failure.
|
||||
* Log failure event.
|
||||
* If `restartPolicy` is:
|
||||
* Always: Restart Container; Pod `phase` stays Running.
|
||||
* OnFailure: Restart Container; Pod `phase` stays Running.
|
||||
* Never: Do not restart Container; Pod `phase` stays Running.
|
||||
* If Container 1 is not running, and Container 2 exits:
|
||||
* Log failure event.
|
||||
* If `restartPolicy` is:
|
||||
* Always: Restart Container; Pod `phase` stays Running.
|
||||
* OnFailure: Restart Container; Pod `phase` stays Running.
|
||||
* Never: Pod `phase` becomes Failed.
|
||||
|
||||
* Pod is running and has one Container. Container runs out of memory.
|
||||
* Container terminates in failure.
|
||||
* Log OOM event.
|
||||
* If `restartPolicy` is:
|
||||
* Always: Restart Container; Pod `phase` stays Running.
|
||||
* OnFailure: Restart Container; Pod `phase` stays Running.
|
||||
* Never: Log failure event; Pod `phase` becomes Failed.
|
||||
|
||||
* Pod is running, and a disk dies.
|
||||
* Kill all Containers.
|
||||
* Log appropriate event.
|
||||
* Pod `phase` becomes Failed.
|
||||
* If running under a controller, Pod is recreated elsewhere.
|
||||
|
||||
* Pod is running, and its node is segmented out.
|
||||
* Node controller waits for timeout.
|
||||
* Node controller sets Pod `phase` to Failed.
|
||||
* If running under a controller, Pod is recreated elsewhere.
|
||||
|
||||
|
||||
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
|
||||
* Get hands-on experience
|
||||
[attaching handlers to Container lifecycle events](/docs/tasks/configure-pod-container/attach-handler-lifecycle-event/).
|
||||
|
||||
* Get hands-on experience
|
||||
[Configure Liveness, Readiness and Startup Probes](/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/).
|
||||
|
||||
* Learn more about [Container lifecycle hooks](/docs/concepts/containers/container-lifecycle-hooks/).
|
||||
|
||||
[configuring Liveness, Readiness and Startup Probes](/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/).
|
||||
|
||||
* Learn more about [container lifecycle hooks](/docs/concepts/containers/container-lifecycle-hooks/).
|
||||
|
||||
* For detailed information about Pod / Container status in the API, see [PodStatus](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#podstatus-v1-core)
|
||||
and
|
||||
[ContainerStatus](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#containerstatus-v1-core).
|
||||
|
||||
|
|
|
|||
|
|
@ -1,123 +0,0 @@
|
|||
---
|
||||
reviewers:
|
||||
- erictune
|
||||
title: Pod Overview
|
||||
content_type: concept
|
||||
weight: 10
|
||||
card:
|
||||
name: concepts
|
||||
weight: 60
|
||||
---
|
||||
|
||||
<!-- overview -->
|
||||
This page provides an overview of `Pod`, the smallest deployable object in the Kubernetes object model.
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
## Understanding Pods
|
||||
|
||||
A *Pod* is the basic execution unit of a Kubernetes application--the smallest and simplest unit in the Kubernetes object model that you create or deploy. A Pod represents processes running on your {{< glossary_tooltip term_id="cluster" text="cluster" >}}.
|
||||
|
||||
A Pod encapsulates an application's container (or, in some cases, multiple containers), storage resources, a unique network identity (IP address), as well as options that govern how the container(s) should run. A Pod represents a unit of deployment: *a single instance of an application in Kubernetes*, which might consist of either a single {{< glossary_tooltip text="container" term_id="container" >}} or a small number of containers that are tightly coupled and that share resources.
|
||||
|
||||
[Docker](https://www.docker.com) is the most common container runtime used in a Kubernetes Pod, but Pods support other [container runtimes](/docs/setup/production-environment/container-runtimes/) as well.
|
||||
|
||||
|
||||
Pods in a Kubernetes cluster can be used in two main ways:
|
||||
|
||||
* **Pods that run a single container**. The "one-container-per-Pod" model is the most common Kubernetes use case; in this case, you can think of a Pod as a wrapper around a single container, and Kubernetes manages the Pods rather than the containers directly.
|
||||
* **Pods that run multiple containers that need to work together**. A Pod might encapsulate an application composed of multiple co-located containers that are tightly coupled and need to share resources. These co-located containers might form a single cohesive unit of service--one container serving files from a shared volume to the public, while a separate "sidecar" container refreshes or updates those files. The Pod wraps these containers and storage resources together as a single manageable entity.
|
||||
|
||||
Each Pod is meant to run a single instance of a given application. If you want to scale your application horizontally (to provide more overall resources by running more instances), you should use multiple Pods, one for each instance. In Kubernetes, this is typically referred to as _replication_.
|
||||
Replicated Pods are usually created and managed as a group by a workload resource and its {{< glossary_tooltip text="_controller_" term_id="controller" >}}.
|
||||
See [Pods and controllers](#pods-and-controllers) for more information on how Kubernetes uses controllers to implement workload scaling and healing.
|
||||
|
||||
### How Pods manage multiple containers
|
||||
|
||||
Pods are designed to support multiple cooperating processes (as containers) that form a cohesive unit of service. The containers in a Pod are automatically co-located and co-scheduled on the same physical or virtual machine in the cluster. The containers can share resources and dependencies, communicate with one another, and coordinate when and how they are terminated.
|
||||
|
||||
Note that grouping multiple co-located and co-managed containers in a single Pod is a relatively advanced use case. You should use this pattern only in specific instances in which your containers are tightly coupled. For example, you might have a container that acts as a web server for files in a shared volume, and a separate "sidecar" container that updates those files from a remote source, as in the following diagram:
|
||||
|
||||
{{< figure src="/images/docs/pod.svg" alt="example pod diagram" width="50%" >}}
|
||||
|
||||
Some Pods have {{< glossary_tooltip text="init containers" term_id="init-container" >}} as well as {{< glossary_tooltip text="app containers" term_id="app-container" >}}. Init containers run and complete before the app containers are started.
|
||||
|
||||
Pods provide two kinds of shared resources for their constituent containers: *networking* and *storage*.
|
||||
|
||||
#### Networking
|
||||
|
||||
Each Pod is assigned a unique IP address for each address family. Every container in a Pod shares the network namespace, including the IP address and network ports. Containers *inside a Pod* can communicate with one another using `localhost`. When containers in a Pod communicate with entities *outside the Pod*, they must coordinate how they use the shared network resources (such as ports).
|
||||
|
||||
#### Storage
|
||||
|
||||
A Pod can specify a set of shared storage {{< glossary_tooltip text="volumes" term_id="volume" >}}. All containers in the Pod can access the shared volumes, allowing those containers to share data. Volumes also allow persistent data in a Pod to survive in case one of the containers within needs to be restarted. See [Volumes](/docs/concepts/storage/volumes/) for more information on how Kubernetes implements shared storage in a Pod.
|
||||
|
||||
## Working with Pods
|
||||
|
||||
You'll rarely create individual Pods directly in Kubernetes--even singleton Pods. This is because Pods are designed as relatively ephemeral, disposable entities. When a Pod gets created (directly by you, or indirectly by a {{< glossary_tooltip text="_controller_" term_id="controller" >}}), it is scheduled to run on a {{< glossary_tooltip term_id="node" >}} in your cluster. The Pod remains on that node until the process is terminated, the pod object is deleted, the Pod is *evicted* for lack of resources, or the node fails.
|
||||
|
||||
{{< note >}}
|
||||
Restarting a container in a Pod should not be confused with restarting a Pod. A Pod is not a process, but an environment for running a container. A Pod persists until it is deleted.
|
||||
{{< /note >}}
|
||||
|
||||
Pods do not, by themselves, self-heal. If a Pod is scheduled to a Node that fails, or if the scheduling operation itself fails, the Pod is deleted; likewise, a Pod won't survive an eviction due to a lack of resources or Node maintenance. Kubernetes uses a higher-level abstraction, called a controller, that handles the work of managing the relatively disposable Pod instances. Thus, while it is possible to use Pod directly, it's far more common in Kubernetes to manage your pods using a controller.
|
||||
|
||||
### Pods and controllers
|
||||
|
||||
You can use workload resources to create and manage multiple Pods for you. A controller for the resource handles replication and rollout and automatic healing in case of Pod failure. For example, if a Node fails, a controller notices that Pods on that Node have stopped working and creates a replacement Pod. The scheduler places the replacement Pod onto a healthy Node.
|
||||
|
||||
Here are some examples of workload resources that manage one or more Pods:
|
||||
|
||||
* {{< glossary_tooltip text="Deployment" term_id="deployment" >}}
|
||||
* {{< glossary_tooltip text="StatefulSet" term_id="statefulset" >}}
|
||||
* {{< glossary_tooltip text="DaemonSet" term_id="daemonset" >}}
|
||||
|
||||
|
||||
## Pod templates
|
||||
|
||||
Controllers for {{< glossary_tooltip text="workload" term_id="workload" >}} resources create Pods
|
||||
from a pod template and manage those Pods on your behalf.
|
||||
|
||||
PodTemplates are specifications for creating Pods, and are included in workload resources such as
|
||||
[Deployments](/docs/concepts/workloads/controllers/deployment/),
|
||||
[Jobs](/docs/concepts/jobs/run-to-completion-finite-workloads/), and
|
||||
[DaemonSets](/docs/concepts/workloads/controllers/daemonset/).
|
||||
|
||||
Each controller for a workload resource uses the PodTemplate inside the workload object to make actual Pods. The PodTemplate is part of the desired state of whatever workload resource you used to run your app.
|
||||
|
||||
The sample below is a manifest for a simple Job with a `template` that starts one container. The container in that Pod prints a message then pauses.
|
||||
|
||||
```yaml
|
||||
apiVersion: batch/v1
|
||||
kind: Job
|
||||
metadata:
|
||||
name: hello
|
||||
spec:
|
||||
template:
|
||||
# This is the pod template
|
||||
spec:
|
||||
containers:
|
||||
- name: hello
|
||||
image: busybox
|
||||
command: ['sh', '-c', 'echo "Hello, Kubernetes!" && sleep 3600']
|
||||
restartPolicy: OnFailure
|
||||
# The pod template ends here
|
||||
```
|
||||
|
||||
Modifying the pod template or switching to a new pod template has no effect on the Pods that already exist. Pods do not receive template updates directly; instead, a new Pod is created to match the revised pod template.
|
||||
|
||||
For example, a Deployment controller ensures that the running Pods match the current pod template. If the template is updated, the controller has to remove the existing Pods and create new Pods based on the updated template. Each workload controller implements its own rules for handling changes to the Pod template.
|
||||
|
||||
On Nodes, the {{< glossary_tooltip term_id="kubelet" text="kubelet" >}} does not directly observe or manage any of the details around pod templates and updates; those details are abstracted away. That abstraction and separation of concerns simplifies system semantics, and makes it feasible to extend the cluster's behavior without changing existing code.
|
||||
|
||||
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
* Learn more about [Pods](/docs/concepts/workloads/pods/pod/)
|
||||
* [The Distributed System Toolkit: Patterns for Composite Containers](https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns) explains common layouts for Pods with more than one container
|
||||
* Learn more about Pod behavior:
|
||||
* [Pod Termination](/docs/concepts/workloads/pods/pod/#termination-of-pods)
|
||||
* [Pod Lifecycle](/docs/concepts/workloads/pods/pod-lifecycle/)
|
||||
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
---
|
||||
title: Pod Topology Spread Constraints
|
||||
content_type: concept
|
||||
weight: 50
|
||||
weight: 40
|
||||
---
|
||||
|
||||
<!-- overview -->
|
||||
|
|
|
|||
|
|
@ -1,209 +0,0 @@
|
|||
---
|
||||
reviewers:
|
||||
title: Pods
|
||||
content_type: concept
|
||||
weight: 20
|
||||
---
|
||||
|
||||
<!-- overview -->
|
||||
|
||||
_Pods_ are the smallest deployable units of computing that can be created and
|
||||
managed in Kubernetes.
|
||||
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## What is a Pod?
|
||||
|
||||
A _Pod_ (as in a pod of whales or pea pod) is a group of one or more
|
||||
{{< glossary_tooltip text="containers" term_id="container" >}} (such as
|
||||
Docker containers), with shared storage/network, and a specification
|
||||
for how to run the containers. A Pod's contents are always co-located and
|
||||
co-scheduled, and run in a shared context. A Pod models an
|
||||
application-specific "logical host" - it contains one or more application
|
||||
containers which are relatively tightly coupled — in a pre-container
|
||||
world, being executed on the same physical or virtual machine would mean being
|
||||
executed on the same logical host.
|
||||
|
||||
While Kubernetes supports more container runtimes than just Docker, Docker is
|
||||
the most commonly known runtime, and it helps to describe Pods in Docker terms.
|
||||
|
||||
The shared context of a Pod is a set of Linux namespaces, cgroups, and
|
||||
potentially other facets of isolation - the same things that isolate a Docker
|
||||
container. Within a Pod's context, the individual applications may have
|
||||
further sub-isolations applied.
|
||||
|
||||
Containers within a Pod share an IP address and port space, and
|
||||
can find each other via `localhost`. They can also communicate with each
|
||||
other using standard inter-process communications like SystemV semaphores or
|
||||
POSIX shared memory. Containers in different Pods have distinct IP addresses
|
||||
and can not communicate by IPC without
|
||||
[special configuration](/docs/concepts/policy/pod-security-policy/).
|
||||
These containers usually communicate with each other via Pod IP addresses.
|
||||
|
||||
Applications within a Pod also have access to shared {{< glossary_tooltip text="volumes" term_id="volume" >}}, which are defined
|
||||
as part of a Pod and are made available to be mounted into each application's
|
||||
filesystem.
|
||||
|
||||
In terms of [Docker](https://www.docker.com/) constructs, a Pod is modelled as
|
||||
a group of Docker containers with shared namespaces and shared filesystem
|
||||
volumes.
|
||||
|
||||
Like individual application containers, Pods are considered to be relatively
|
||||
ephemeral (rather than durable) entities. As discussed in
|
||||
[pod lifecycle](/docs/concepts/workloads/pods/pod-lifecycle/), Pods are created, assigned a unique ID (UID), and
|
||||
scheduled to nodes where they remain until termination (according to restart
|
||||
policy) or deletion. If a {{< glossary_tooltip term_id="node" >}} dies, the Pods scheduled to that node are
|
||||
scheduled for deletion, after a timeout period. A given Pod (as defined by a UID) is not
|
||||
"rescheduled" to a new node; instead, it can be replaced by an identical Pod,
|
||||
with even the same name if desired, but with a new UID (see [replication
|
||||
controller](/docs/concepts/workloads/controllers/replicationcontroller/) for more details).
|
||||
|
||||
When something is said to have the same lifetime as a Pod, such as a volume,
|
||||
that means that it exists as long as that Pod (with that UID) exists. If that
|
||||
Pod is deleted for any reason, even if an identical replacement is created, the
|
||||
related thing (e.g. volume) is also destroyed and created anew.
|
||||
|
||||
{{< figure src="/images/docs/pod.svg" title="Pod diagram" width="50%" >}}
|
||||
|
||||
*A multi-container Pod that contains a file puller and a
|
||||
web server that uses a persistent volume for shared storage between the containers.*
|
||||
|
||||
## Motivation for Pods
|
||||
|
||||
### Management
|
||||
|
||||
Pods are a model of the pattern of multiple cooperating processes which form a
|
||||
cohesive unit of service. They simplify application deployment and management
|
||||
by providing a higher-level abstraction than the set of their constituent
|
||||
applications. Pods serve as unit of deployment, horizontal scaling, and
|
||||
replication. Colocation (co-scheduling), shared fate (e.g. termination),
|
||||
coordinated replication, resource sharing, and dependency management are
|
||||
handled automatically for containers in a Pod.
|
||||
|
||||
### Resource sharing and communication
|
||||
|
||||
Pods enable data sharing and communication among their constituents.
|
||||
|
||||
The applications in a Pod all use the same network namespace (same IP and port
|
||||
space), and can thus "find" each other and communicate using `localhost`.
|
||||
Because of this, applications in a Pod must coordinate their usage of ports.
|
||||
Each Pod has an IP address in a flat shared networking space that has full
|
||||
communication with other physical computers and Pods across the network.
|
||||
|
||||
Containers within the Pod see the system hostname as being the same as the configured
|
||||
`name` for the Pod. There's more about this in the [networking](/docs/concepts/cluster-administration/networking/)
|
||||
section.
|
||||
|
||||
In addition to defining the application containers that run in the Pod, the Pod
|
||||
specifies a set of shared storage volumes. Volumes enable data to survive
|
||||
container restarts and to be shared among the applications within the Pod.
|
||||
|
||||
## Uses of pods
|
||||
|
||||
Pods can be used to host vertically integrated application stacks (e.g. LAMP),
|
||||
but their primary motivation is to support co-located, co-managed helper
|
||||
programs, such as:
|
||||
|
||||
* content management systems, file and data loaders, local cache managers, etc.
|
||||
* log and checkpoint backup, compression, rotation, snapshotting, etc.
|
||||
* data change watchers, log tailers, logging and monitoring adapters, event publishers, etc.
|
||||
* proxies, bridges, and adapters
|
||||
* controllers, managers, configurators, and updaters
|
||||
|
||||
Individual Pods are not intended to run multiple instances of the same
|
||||
application, in general.
|
||||
|
||||
For a longer explanation, see [The Distributed System ToolKit: Patterns for
|
||||
Composite
|
||||
Containers](https://kubernetes.io/blog/2015/06/the-distributed-system-toolkit-patterns).
|
||||
|
||||
## Alternatives considered
|
||||
|
||||
_Why not just run multiple programs in a single (Docker) container?_
|
||||
|
||||
1. Transparency. Making the containers within the Pod visible to the
|
||||
infrastructure enables the infrastructure to provide services to those
|
||||
containers, such as process management and resource monitoring. This
|
||||
facilitates a number of conveniences for users.
|
||||
1. Decoupling software dependencies. The individual containers may be
|
||||
versioned, rebuilt and redeployed independently. Kubernetes may even support
|
||||
live updates of individual containers someday.
|
||||
1. Ease of use. Users don't need to run their own process managers, worry about
|
||||
signal and exit-code propagation, etc.
|
||||
1. Efficiency. Because the infrastructure takes on more responsibility,
|
||||
containers can be lighter weight.
|
||||
|
||||
_Why not support affinity-based co-scheduling of containers?_
|
||||
|
||||
That approach would provide co-location, but would not provide most of the
|
||||
benefits of Pods, such as resource sharing, IPC, guaranteed fate sharing, and
|
||||
simplified management.
|
||||
|
||||
## Durability of pods (or lack thereof)
|
||||
|
||||
Pods aren't intended to be treated as durable entities. They won't survive scheduling failures, node failures, or other evictions, such as due to lack of resources, or in the case of node maintenance.
|
||||
|
||||
In general, users shouldn't need to create Pods directly. They should almost
|
||||
always use controllers even for singletons, for example,
|
||||
[Deployments](/docs/concepts/workloads/controllers/deployment/).
|
||||
Controllers provide self-healing with a cluster scope, as well as replication
|
||||
and rollout management.
|
||||
Controllers like [StatefulSet](/docs/concepts/workloads/controllers/statefulset.md)
|
||||
can also provide support to stateful Pods.
|
||||
|
||||
The use of collective APIs as the primary user-facing primitive is relatively common among cluster scheduling systems, including [Borg](https://research.google.com/pubs/pub43438.html), [Marathon](https://mesosphere.github.io/marathon/docs/rest-api.html), [Aurora](http://aurora.apache.org/documentation/latest/reference/configuration/#job-schema), and [Tupperware](https://www.slideshare.net/Docker/aravindnarayanan-facebook140613153626phpapp02-37588997).
|
||||
|
||||
Pod is exposed as a primitive in order to facilitate:
|
||||
|
||||
* scheduler and controller pluggability
|
||||
* support for pod-level operations without the need to "proxy" them via controller APIs
|
||||
* decoupling of Pod lifetime from controller lifetime, such as for bootstrapping
|
||||
* decoupling of controllers and services — the endpoint controller just watches Pods
|
||||
* clean composition of Kubelet-level functionality with cluster-level functionality — Kubelet is effectively the "pod controller"
|
||||
* high-availability applications, which will expect Pods to be replaced in advance of their termination and certainly in advance of deletion, such as in the case of planned evictions or image prefetching.
|
||||
|
||||
## Termination of Pods
|
||||
|
||||
Because Pods represent running processes on nodes in the cluster, it is important to allow those processes to gracefully terminate when they are no longer needed (vs being violently killed with a KILL signal and having no chance to clean up). Users should be able to request deletion and know when processes terminate, but also be able to ensure that deletes eventually complete. When a user requests deletion of a Pod, the system records the intended grace period before the Pod is allowed to be forcefully killed, and a TERM signal is sent to the main process in each container. Once the grace period has expired, the KILL signal is sent to those processes, and the Pod is then deleted from the API server. If the Kubelet or the container manager is restarted while waiting for processes to terminate, the termination will be retried with the full grace period.
|
||||
|
||||
An example flow:
|
||||
|
||||
1. User sends command to delete Pod, with default grace period (30s)
|
||||
1. The Pod in the API server is updated with the time beyond which the Pod is considered "dead" along with the grace period.
|
||||
1. Pod shows up as "Terminating" when listed in client commands
|
||||
1. (simultaneous with 3) When the Kubelet sees that a Pod has been marked as terminating because the time in 2 has been set, it begins the Pod shutdown process.
|
||||
1. If one of the Pod's containers has defined a [preStop hook](/docs/concepts/containers/container-lifecycle-hooks/#hook-details), it is invoked inside of the container. If the `preStop` hook is still running after the grace period expires, step 2 is then invoked with a small (2 second) one-time extended grace period. You must modify `terminationGracePeriodSeconds` if the `preStop` hook needs longer to complete.
|
||||
1. The container is sent the TERM signal. Note that not all containers in the Pod will receive the TERM signal at the same time and may each require a `preStop` hook if the order in which they shut down matters.
|
||||
1. (simultaneous with 3) Pod is removed from endpoints list for service, and are no longer considered part of the set of running Pods for replication controllers. Pods that shutdown slowly cannot continue to serve traffic as load balancers (like the service proxy) remove them from their rotations.
|
||||
1. When the grace period expires, any processes still running in the Pod are killed with SIGKILL.
|
||||
1. The Kubelet will finish deleting the Pod on the API server by setting grace period 0 (immediate deletion). The Pod disappears from the API and is no longer visible from the client.
|
||||
|
||||
By default, all deletes are graceful within 30 seconds. The `kubectl delete` command supports the `--grace-period=<seconds>` option which allows a user to override the default and specify their own value. The value `0` [force deletes](/docs/concepts/workloads/pods/pod/#force-deletion-of-pods) the Pod.
|
||||
You must specify an additional flag `--force` along with `--grace-period=0` in order to perform force deletions.
|
||||
|
||||
### Force deletion of pods
|
||||
|
||||
Force deletion of a Pod is defined as deletion of a Pod from the cluster state and etcd immediately. When a force deletion is performed, the API server does not wait for confirmation from the kubelet that the Pod has been terminated on the node it was running on. It removes the Pod in the API immediately so a new Pod can be created with the same name. On the node, Pods that are set to terminate immediately will still be given a small grace period before being force killed.
|
||||
|
||||
Force deletions can be potentially dangerous for some Pods and should be performed with caution. In case of StatefulSet Pods, please refer to the task documentation for [deleting Pods from a StatefulSet](/docs/tasks/run-application/force-delete-stateful-set-pod/).
|
||||
|
||||
## Privileged mode for pod containers
|
||||
|
||||
Any container in a Pod can enable privileged mode, using the `privileged` flag on the [security context](/docs/tasks/configure-pod-container/security-context/) of the container spec. This is useful for containers that want to use Linux capabilities like manipulating the network stack and accessing devices. Processes within the container get almost the same privileges that are available to processes outside a container. With privileged mode, it should be easier to write network and volume plugins as separate Pods that don't need to be compiled into the kubelet.
|
||||
|
||||
{{< note >}}
|
||||
Your container runtime must support the concept of a privileged container for this setting to be relevant.
|
||||
{{< /note >}}
|
||||
|
||||
## API Object
|
||||
|
||||
Pod is a top-level resource in the Kubernetes REST API.
|
||||
The [Pod API object](/docs/reference/generated/kubernetes-api/{{< param "version" >}}/#pod-v1-core) definition
|
||||
describes the object in detail.
|
||||
When creating the manifest for a Pod object, make sure the name specified is a valid
|
||||
[DNS subdomain name](/docs/concepts/overview/working-with-objects/names#dns-subdomain-names).
|
||||
|
||||
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
---
|
||||
reviewers:
|
||||
- jessfraz
|
||||
title: Pod Preset
|
||||
title: Pod Presets
|
||||
content_type: concept
|
||||
weight: 50
|
||||
---
|
||||
|
|
@ -32,20 +32,20 @@ specific service do not need to know all the details about that service.
|
|||
|
||||
In order to use Pod presets in your cluster you must ensure the following:
|
||||
|
||||
1. You have enabled the API type `settings.k8s.io/v1alpha1/podpreset`. For
|
||||
example, this can be done by including `settings.k8s.io/v1alpha1=true` in
|
||||
the `--runtime-config` option for the API server. In minikube add this flag
|
||||
`--extra-config=apiserver.runtime-config=settings.k8s.io/v1alpha1=true` while
|
||||
starting the cluster.
|
||||
1. You have enabled the admission controller `PodPreset`. One way to doing this
|
||||
is to include `PodPreset` in the `--enable-admission-plugins` option value specified
|
||||
for the API server. In minikube, add this flag
|
||||
|
||||
```shell
|
||||
--extra-config=apiserver.enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,PodPreset
|
||||
```
|
||||
|
||||
while starting the cluster.
|
||||
1. You have enabled the API type `settings.k8s.io/v1alpha1/podpreset`. For
|
||||
example, this can be done by including `settings.k8s.io/v1alpha1=true` in
|
||||
the `--runtime-config` option for the API server. In minikube add this flag
|
||||
`--extra-config=apiserver.runtime-config=settings.k8s.io/v1alpha1=true` while
|
||||
starting the cluster.
|
||||
1. You have enabled the admission controller named `PodPreset`. One way to doing this
|
||||
is to include `PodPreset` in the `--enable-admission-plugins` option value specified
|
||||
for the API server. For example, if you use Minikube, add this flag:
|
||||
|
||||
```shell
|
||||
--extra-config=apiserver.enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,PodPreset
|
||||
```
|
||||
|
||||
while starting your cluster.
|
||||
|
||||
## How it works
|
||||
|
||||
|
|
@ -64,31 +64,28 @@ When a pod creation request occurs, the system does the following:
|
|||
modified by a `PodPreset`. The annotation is of the form
|
||||
`podpreset.admission.kubernetes.io/podpreset-<pod-preset name>: "<resource version>"`.
|
||||
|
||||
Each Pod can be matched by zero or more Pod Presets; and each `PodPreset` can be
|
||||
applied to zero or more pods. When a `PodPreset` is applied to one or more
|
||||
Pods, Kubernetes modifies the Pod Spec. For changes to `Env`, `EnvFrom`, and
|
||||
`VolumeMounts`, Kubernetes modifies the container spec for all containers in
|
||||
the Pod; for changes to `Volume`, Kubernetes modifies the Pod Spec.
|
||||
Each Pod can be matched by zero or more PodPresets; and each PodPreset can be
|
||||
applied to zero or more Pods. When a PodPreset is applied to one or more
|
||||
Pods, Kubernetes modifies the Pod Spec. For changes to `env`, `envFrom`, and
|
||||
`volumeMounts`, Kubernetes modifies the container spec for all containers in
|
||||
the Pod; for changes to `volumes`, Kubernetes modifies the Pod Spec.
|
||||
|
||||
{{< note >}}
|
||||
A Pod Preset is capable of modifying the following fields in a Pod spec when appropriate:
|
||||
- The `.spec.containers` field.
|
||||
- The `initContainers` field (requires Kubernetes version 1.14.0 or later).
|
||||
- The `.spec.containers` field
|
||||
- The `.spec.initContainers` field
|
||||
{{< /note >}}
|
||||
|
||||
### Disable Pod Preset for a Specific Pod
|
||||
### Disable Pod Preset for a specific pod
|
||||
|
||||
There may be instances where you wish for a Pod to not be altered by any Pod
|
||||
Preset mutations. In these cases, you can add an annotation in the Pod Spec
|
||||
preset mutations. In these cases, you can add an annotation in the Pod's `.spec`
|
||||
of the form: `podpreset.admission.kubernetes.io/exclude: "true"`.
|
||||
|
||||
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
|
||||
See [Injecting data into a Pod using PodPreset](/docs/tasks/inject-data-application/podpreset/)
|
||||
|
||||
For more information about the background, see the [design proposal for PodPreset](https://git.k8s.io/community/contributors/design-proposals/service-catalog/pod-preset.md).
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -28,41 +28,62 @@ Kubernetes documentation welcomes improvements from all contributors, new and ex
|
|||
|
||||
## Getting started
|
||||
|
||||
Anyone can open an issue about documentation, or contribute a change with a pull request (PR) to the [`kubernetes/website` GitHub repository](https://github.com/kubernetes/website). You need to be comfortable with [git](https://git-scm.com/) and [GitHub](https://lab.github.com/) to operate effectively in the Kubernetes community.
|
||||
Anyone can open an issue about documentation, or contribute a change with a
|
||||
pull request (PR) to the
|
||||
[`kubernetes/website` GitHub repository](https://github.com/kubernetes/website).
|
||||
You need to be comfortable with
|
||||
[git](https://git-scm.com/) and
|
||||
[GitHub](https://lab.github.com/)
|
||||
to work effectively in the Kubernetes community.
|
||||
|
||||
To get involved with documentation:
|
||||
|
||||
1. Sign the CNCF [Contributor License Agreement](https://github.com/kubernetes/community/blob/master/CLA.md).
|
||||
2. Familiarize yourself with the [documentation repository](https://github.com/kubernetes/website) and the website's [static site generator](https://gohugo.io).
|
||||
3. Make sure you understand the basic processes for [opening a pull request](/docs/contribute/new-content/new-content/) and [reviewing changes](/docs/contribute/review/reviewing-prs/).
|
||||
1. Familiarize yourself with the [documentation repository](https://github.com/kubernetes/website)
|
||||
and the website's [static site generator](https://gohugo.io).
|
||||
1. Make sure you understand the basic processes for
|
||||
[opening a pull request](/docs/contribute/new-content/open-a-pr/) and
|
||||
[reviewing changes](/docs/contribute/review/reviewing-prs/).
|
||||
|
||||
Some tasks require more trust and more access in the Kubernetes organization.
|
||||
See [Participating in SIG Docs](/docs/contribute/participating/) for more details about
|
||||
See [Participating in SIG Docs](/docs/contribute/participate/) for more details about
|
||||
roles and permissions.
|
||||
|
||||
## Your first contribution
|
||||
|
||||
- Read the [Contribution overview](/docs/contribute/new-content/overview/) to learn about the different ways you can contribute.
|
||||
- See [Contribute to kubernetes/website](https://github.com/kubernetes/website/contribute) to find issues that make good entry points.
|
||||
- [Open a pull request using GitHub](/docs/contribute/new-content/new-content/#changes-using-github) to existing documentation and learn more about filing issues in GitHub.
|
||||
- [Review pull requests](/docs/contribute/review/reviewing-prs/) from other Kubernetes community members for accuracy and language.
|
||||
- Read the Kubernetes [content](/docs/contribute/style/content-guide/) and [style guides](/docs/contribute/style/style-guide/) so you can leave informed comments.
|
||||
- Learn about [page content types](/docs/contribute/style/page-content-types/) and [Hugo shortcodes](/docs/contribute/style/hugo-shortcodes/).
|
||||
- Read the [Contribution overview](/docs/contribute/new-content/overview/) to
|
||||
learn about the different ways you can contribute.
|
||||
- Check [kubernetes/website issues list](/https://github.com/kubernetes/website/issues/)
|
||||
for issues that make good entry points.
|
||||
- [Open a pull request using GitHub](/docs/contribute/new-content/open-a-pr/#changes-using-github)
|
||||
to existing documentation and learn more about filing issues in GitHub.
|
||||
- [Review pull requests](/docs/contribute/review/reviewing-prs/) from other
|
||||
Kubernetes community members for accuracy and language.
|
||||
- Read the Kubernetes [content](/docs/contribute/style/content-guide/) and
|
||||
[style guides](/docs/contribute/style/style-guide/) so you can leave informed comments.
|
||||
- Learn about [page content types](/docs/contribute/style/page-content-types/)
|
||||
and [Hugo shortcodes](/docs/contribute/style/hugo-shortcodes/).
|
||||
|
||||
## Next steps
|
||||
|
||||
- Learn to [work from a local clone](/docs/contribute/new-content/new-content/#fork-the-repo) of the repository.
|
||||
- Learn to [work from a local clone](/docs/contribute/new-content/open-a-pr/#fork-the-repo)
|
||||
of the repository.
|
||||
- Document [features in a release](/docs/contribute/new-content/new-features/).
|
||||
- Participate in [SIG Docs](/docs/contribute/participating/), and become a [member or reviewer](/docs/contribute/participating/#roles-and-responsibilities).
|
||||
- Participate in [SIG Docs](/docs/contribute/participate/), and become a
|
||||
[member or reviewer](/docs/contribute/participate/roles-and-responsibilities/).
|
||||
|
||||
- Start or help with a [localization](/docs/contribute/localization/).
|
||||
|
||||
## Get involved with SIG Docs
|
||||
|
||||
[SIG Docs](/docs/contribute/participating/) is the group of contributors who publish and maintain Kubernetes documentation and the website. Getting involved with SIG Docs is a great way for Kubernetes contributors (feature development or otherwise) to have a large impact on the Kubernetes project.
|
||||
[SIG Docs](/docs/contribute/participate/) is the group of contributors who
|
||||
publish and maintain Kubernetes documentation and the website. Getting
|
||||
involved with SIG Docs is a great way for Kubernetes contributors (feature
|
||||
development or otherwise) to have a large impact on the Kubernetes project.
|
||||
|
||||
SIG Docs communicates with different methods:
|
||||
|
||||
- [Join `#sig-docs` on the Kubernetes Slack instance](http://slack.k8s.io/). Make sure to
|
||||
- [Join `#sig-docs` on the Kubernetes Slack instance](https://slack.k8s.io/). Make sure to
|
||||
introduce yourself!
|
||||
- [Join the `kubernetes-sig-docs` mailing list](https://groups.google.com/forum/#!forum/kubernetes-sig-docs),
|
||||
where broader discussions take place and official decisions are recorded.
|
||||
|
|
|
|||
|
|
@ -13,13 +13,12 @@ This page assumes that you understand how to
|
|||
to learn about more ways to contribute. You need to use the Git command line
|
||||
client and other tools for some of these tasks.
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## Propose improvements
|
||||
|
||||
SIG Docs [members](/docs/contribute/participating/#members) can propose improvements.
|
||||
SIG Docs [members](/docs/contribute/participate/roles-and-responsibilities/#members)
|
||||
can propose improvements.
|
||||
|
||||
After you've been contributing to the Kubernetes documentation for a while, you
|
||||
may have ideas for improving the [Style Guide](/docs/contribute/style/style-guide/)
|
||||
|
|
@ -42,8 +41,8 @@ documentation testing might involve working with sig-testing.
|
|||
|
||||
## Coordinate docs for a Kubernetes release
|
||||
|
||||
SIG Docs [approvers](/docs/contribute/participating/#approvers) can coordinate
|
||||
docs for a Kubernetes release.
|
||||
SIG Docs [approvers](/docs/contribute/participate/roles-and-responsibilities/#approvers)
|
||||
can coordinate docs for a Kubernetes release.
|
||||
|
||||
Each Kubernetes release is coordinated by a team of people participating in the
|
||||
sig-release Special Interest Group (SIG). Others on the release team for a given
|
||||
|
|
@ -73,8 +72,8 @@ rotated among SIG Docs approvers.
|
|||
|
||||
## Serve as a New Contributor Ambassador
|
||||
|
||||
SIG Docs [approvers](/docs/contribute/participating/#approvers) can serve as
|
||||
New Contributor Ambassadors.
|
||||
SIG Docs [approvers](/docs/contribute/participate/roles-and-responsibilities/#approvers)
|
||||
can serve as New Contributor Ambassadors.
|
||||
|
||||
New Contributor Ambassadors welcome new contributors to SIG-Docs,
|
||||
suggest PRs to new contributors, and mentor new contributors through their first
|
||||
|
|
@ -92,14 +91,14 @@ Current New Contributor Ambassadors are announced at each SIG-Docs meeting, and
|
|||
|
||||
## Sponsor a new contributor
|
||||
|
||||
SIG Docs [reviewers](/docs/contribute/participating/#reviewers) can sponsor
|
||||
new contributors.
|
||||
SIG Docs [reviewers](/docs/contribute/participate/roles-and-responsibilities/#reviewers)
|
||||
can sponsor new contributors.
|
||||
|
||||
After a new contributor has successfully submitted 5 substantive pull requests
|
||||
to one or more Kubernetes repositories, they are eligible to apply for
|
||||
[membership](/docs/contribute/participating#members) in the Kubernetes
|
||||
organization. The contributor's membership needs to be backed by two sponsors
|
||||
who are already reviewers.
|
||||
[membership](/docs/contribute/participate/roles-and-responsibilities/#members)
|
||||
in the Kubernetes organization. The contributor's membership needs to be
|
||||
backed by two sponsors who are already reviewers.
|
||||
|
||||
New docs contributors can request sponsors by asking in the #sig-docs channel
|
||||
on the [Kubernetes Slack instance](https://kubernetes.slack.com) or on the
|
||||
|
|
@ -111,7 +110,8 @@ membership in the Kubernetes organization.
|
|||
|
||||
## Serve as a SIG Co-chair
|
||||
|
||||
SIG Docs [approvers](/docs/contribute/participating/#approvers) can serve a term as a co-chair of SIG Docs.
|
||||
SIG Docs [approvers](/docs/contribute/participate/roles-and-responsibilities/#approvers)
|
||||
can serve a term as a co-chair of SIG Docs.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
|
|
@ -120,7 +120,12 @@ Approvers must meet the following requirements to be a co-chair:
|
|||
- Have been a SIG Docs approver for at least 6 months
|
||||
- Have [led a Kubernetes docs release](/docs/contribute/advanced/#coordinate-docs-for-a-kubernetes-release) or shadowed two releases
|
||||
- Understand SIG Docs workflows and tooling: git, Hugo, localization, blog subproject
|
||||
- Understand how other Kubernetes SIGs and repositories affect the SIG Docs workflow, including: [teams in k/org](https://github.com/kubernetes/org/blob/master/config/kubernetes/sig-docs/teams.yaml), [process in k/community](https://github.com/kubernetes/community/tree/master/sig-docs), plugins in [k/test-infra](https://github.com/kubernetes/test-infra/), and the role of [SIG Architecture](https://github.com/kubernetes/community/tree/master/sig-architecture).
|
||||
- Understand how other Kubernetes SIGs and repositories affect the SIG Docs
|
||||
workflow, including:
|
||||
[teams in k/org](https://github.com/kubernetes/org/blob/master/config/kubernetes/sig-docs/teams.yaml),
|
||||
[process in k/community](https://github.com/kubernetes/community/tree/master/sig-docs),
|
||||
plugins in [k/test-infra](https://github.com/kubernetes/test-infra/), and the role of
|
||||
[SIG Architecture](https://github.com/kubernetes/community/tree/master/sig-architecture).
|
||||
- Commit at least 5 hours per week (and often more) to the role for a minimum of 6 months
|
||||
|
||||
### Responsibilities
|
||||
|
|
|
|||
|
|
@ -15,21 +15,16 @@ like
|
|||
[kubectl apply](/docs/reference/generated/kubectl/kubectl-commands#apply) and
|
||||
[kubectl taint](/docs/reference/generated/kubectl/kubectl-commands#taint).
|
||||
This topic does not show how to generate the
|
||||
[kubectl](/docs/reference/generated/kubectl/kubectl/)
|
||||
[kubectl](/docs/reference/generated/kubectl/kubectl-commands/)
|
||||
options reference page. For instructions on how to generate the kubectl options
|
||||
reference page, see
|
||||
[Generating Reference Pages for Kubernetes Components and Tools](/docs/home/contribute/generated-reference/kubernetes-components/).
|
||||
[Generating Reference Pages for Kubernetes Components and Tools](/docs/contribute/generate-ref-docs/kubernetes-components/).
|
||||
{{< /note >}}
|
||||
|
||||
|
||||
|
||||
## {{% heading "prerequisites" %}}
|
||||
|
||||
|
||||
{{< include "prerequisites-ref-docs.md" >}}
|
||||
|
||||
|
||||
|
||||
<!-- steps -->
|
||||
|
||||
## Setting up the local repositories
|
||||
|
|
|
|||
|
|
@ -194,16 +194,14 @@ The use of `make docker-serve` is deprecated. Please use `make container-serve`
|
|||
In `<web-base>` run `git add` and `git commit` to commit the change.
|
||||
|
||||
Submit your changes as a
|
||||
[pull request](/docs/contribute/start/) to the
|
||||
[pull request](/docs/contribute/new-content/open-a-pr/) to the
|
||||
[kubernetes/website](https://github.com/kubernetes/website) repository.
|
||||
Monitor your pull request, and respond to reviewer comments as needed. Continue
|
||||
to monitor your pull request until it has been merged.
|
||||
|
||||
|
||||
|
||||
## {{% heading "whatsnext" %}}
|
||||
|
||||
|
||||
* [Generating Reference Documentation Quickstart](/docs/contribute/generate-ref-docs/quickstart/)
|
||||
* [Generating Reference Docs for Kubernetes Components and Tools](/docs/contribute/generate-ref-docs/kubernetes-components/)
|
||||
* [Generating Reference Documentation for kubectl Commands](/docs/contribute/generate-ref-docs/kubectl/)
|
||||
|
|
|
|||
|
|
@ -18,4 +18,5 @@
|
|||
|
||||
- You need to know how to create a pull request to a GitHub repository.
|
||||
This involves creating your own fork of the repository. For more
|
||||
information, see [Work from a local clone](/docs/contribute/intermediate/#work_from_a_local_clone).
|
||||
information, see [Work from a local clone](/docs/contribute/new-content/open-a-pr/#fork-the-repo).
|
||||
|
||||
|
|
|
|||
|
|
@ -10,15 +10,10 @@ This page shows how to use the `update-imported-docs` script to generate
|
|||
the Kubernetes reference documentation. The script automates
|
||||
the build setup and generates the reference documentation for a release.
|
||||
|
||||
|
||||
|
||||
## {{% heading "prerequisites" %}}
|
||||
|
||||
|
||||
{{< include "prerequisites-ref-docs.md" >}}
|
||||
|
||||
|
||||
|
||||
<!-- steps -->
|
||||
|
||||
## Getting the docs repository
|
||||
|
|
@ -87,7 +82,7 @@ The `update-imported-docs` script performs the following steps:
|
|||
the sections in the `kubectl` command reference.
|
||||
|
||||
When the generated files are in your local clone of the `<web-base>`
|
||||
repository, you can submit them in a [pull request](/docs/contribute/start/)
|
||||
repository, you can submit them in a [pull request](/docs/contribute/new-content/open-a-pr/)
|
||||
to `<web-base>`.
|
||||
|
||||
## Configuration file format
|
||||
|
|
|
|||
|
|
@ -183,7 +183,7 @@ Description | URLs
|
|||
-----|-----
|
||||
Home | [All heading and subheading URLs](/docs/home/)
|
||||
Setup | [All heading and subheading URLs](/docs/setup/)
|
||||
Tutorials | [Kubernetes Basics](/docs/tutorials/kubernetes-basics/), [Hello Minikube](/docs/tutorials/stateless-application/hello-minikube/)
|
||||
Tutorials | [Kubernetes Basics](/docs/tutorials/kubernetes-basics/), [Hello Minikube](/docs/tutorials/hello-minikube/)
|
||||
Site strings | [All site strings in a new localized TOML file](https://github.com/kubernetes/website/tree/master/i18n)
|
||||
|
||||
Translated documents must reside in their own `content/**/` subdirectory, but otherwise follow the same URL path as the English source. For example, to prepare the [Kubernetes Basics](/docs/tutorials/kubernetes-basics/) tutorial for translation into German, create a subfolder under the `content/de/` folder and copy the English source:
|
||||
|
|
|
|||
|
|
@ -1,6 +1,5 @@
|
|||
---
|
||||
title: Opening a pull request
|
||||
slug: new-content
|
||||
content_type: concept
|
||||
weight: 10
|
||||
card:
|
||||
|
|
|
|||
|
|
@ -20,8 +20,12 @@ This section contains information you should know before contributing new conten
|
|||
- Write Kubernetes documentation in Markdown and build the Kubernetes site using [Hugo](https://gohugo.io/).
|
||||
- The source is in [GitHub](https://github.com/kubernetes/website). You can find Kubernetes documentation at `/content/en/docs/`. Some of the reference documentation is automatically generated from scripts in the `update-imported-docs/` directory.
|
||||
- [Page content types](/docs/contribute/style/page-content-types/) describe the presentation of documentation content in Hugo.
|
||||
- In addition to the standard Hugo shortcodes, we use a number of [custom Hugo shortcodes](/docs/contribute/style/hugo-shortcodes/) in our documentation to control the presentation of content.
|
||||
- Documentation source is available in multiple languages in `/content/`. Each language has its own folder with a two-letter code determined by the [ISO 639-1 standard](https://www.loc.gov/standards/iso639-2/php/code_list.php). For example, English documentation source is stored in `/content/en/docs/`.
|
||||
- In addition to the standard Hugo shortcodes, we use a number of
|
||||
[custom Hugo shortcodes](/docs/contribute/style/hugo-shortcodes/) in our documentation to control the presentation of content.
|
||||
- Documentation source is available in multiple languages in `/content/`. Each
|
||||
language has its own folder with a two-letter code determined by the
|
||||
[ISO 639-1 standard](https://www.loc.gov/standards/iso639-2/php/code_list.php). For
|
||||
example, English documentation source is stored in `/content/en/docs/`.
|
||||
- For more information about contributing to documentation in multiple languages or starting a new translation, see [localization](/docs/contribute/localization).
|
||||
|
||||
## Before you begin {#before-you-begin}
|
||||
|
|
|
|||
|
|
@ -20,18 +20,18 @@ SIG Docs welcomes content and reviews from all contributors. Anyone can open a
|
|||
pull request (PR), and anyone is welcome to file issues about content or comment
|
||||
on pull requests in progress.
|
||||
|
||||
You can also become a [member](/docs/contribute/participating/roles-and-responsibilities/#members),
|
||||
[reviewer](/docs/contribute/participating/roles-and-responsibilities/#reviewers), or [approver](/docs/contribute/participating/roles-and-responsibilities/#approvers). These roles require greater
|
||||
access and entail certain responsibilities for approving and committing changes.
|
||||
See [community-membership](https://github.com/kubernetes/community/blob/master/community-membership.md)
|
||||
You can also become a [member](/docs/contribute/participate/roles-and-responsibilities/#members),
|
||||
[reviewer](/docs/contribute/participate/roles-and-responsibilities/#reviewers), or
|
||||
[approver](/docs/contribute/participate/roles-and-responsibilities/#approvers).
|
||||
These roles require greater access and entail certain responsibilities for
|
||||
approving and committing changes. See
|
||||
[community-membership](https://github.com/kubernetes/community/blob/master/community-membership.md)
|
||||
for more information on how membership works within the Kubernetes community.
|
||||
|
||||
The rest of this document outlines some unique ways these roles function within
|
||||
SIG Docs, which is responsible for maintaining one of the most public-facing
|
||||
aspects of Kubernetes -- the Kubernetes website and documentation.
|
||||
|
||||
|
||||
|
||||
<!-- body -->
|
||||
|
||||
## SIG Docs chairperson
|
||||
|
|
@ -58,8 +58,9 @@ There are two categories of SIG Docs [teams](https://github.com/orgs/kubernetes/
|
|||
Each can be referenced with their `@name` in GitHub comments to communicate with
|
||||
everyone in that group.
|
||||
|
||||
Sometimes Prow and GitHub teams overlap without matching exactly. For assignment of issues, pull requests, and to support PR approvals,
|
||||
the automation uses information from `OWNERS` files.
|
||||
Sometimes Prow and GitHub teams overlap without matching exactly. For
|
||||
assignment of issues, pull requests, and to support PR approvals, the
|
||||
automation uses information from `OWNERS` files.
|
||||
|
||||
### OWNERS files and front-matter
|
||||
|
||||
|
|
@ -114,6 +115,6 @@ SIG Docs approvers. Here's how it works.
|
|||
|
||||
For more information about contributing to the Kubernetes documentation, see:
|
||||
|
||||
- [Contributing new content](/docs/contribute/overview/)
|
||||
- [Contributing new content](/docs/contribute/new-content/overview/)
|
||||
- [Reviewing content](/docs/contribute/review/reviewing-prs)
|
||||
- [Documentation style guide](/docs/contribute/style/)
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue