Merge remote-tracking branch 'origin/main'
This commit is contained in:
commit
7346e50c65
18
README.md
18
README.md
|
|
@ -1,7 +1,4 @@
|
|||
推荐你通过在线阅读网站进行阅读,体验更好,速度更快!
|
||||
|
||||
- **[JavaGuide 在线阅读网站(新版,推荐 👍)](https://javaguide.cn/)**
|
||||
- [JavaGuide 在线阅读版(老版)](https://snailclimb.gitee.io/javaguide/#/)
|
||||
推荐你通过在线阅读网站进行阅读,体验更好,速度更快!地址:[javaguide.cn](https://javaguide.cn/)。
|
||||
|
||||
[<img src="https://oss.javaguide.cn/xingqiu/xingqiu.png" style="width:850px;margin: 0 auto" />](https://sourl.cn/e7ee87)
|
||||
|
||||
|
|
@ -32,9 +29,10 @@
|
|||
|
||||
## 项目相关
|
||||
|
||||
- [项目介绍](./docs/javaguide/intro.md)
|
||||
- [贡献指南](./docs/javaguide/contribution-guideline.md)
|
||||
- [常见问题](./docs/javaguide/faq.md)
|
||||
- [项目介绍](https://javaguide.cn/javaguide/intro.html)
|
||||
- [使用建议](https://javaguide.cn/javaguide/use-suggestion.html)
|
||||
- [贡献指南](https://javaguide.cn/javaguide/contribution-guideline.html)
|
||||
- [常见问题](https://javaguide.cn/javaguide/faq.html)
|
||||
|
||||
## Java
|
||||
|
||||
|
|
@ -73,6 +71,7 @@
|
|||
- [HashMap 核心源码+底层数据结构分析](./docs/java/collection/hashmap-source-code.md)
|
||||
- [ConcurrentHashMap 核心源码+底层数据结构分析](./docs/java/collection/concurrent-hash-map-source-code.md)
|
||||
- [CopyOnWriteArrayList 核心源码分析](./docs/java/collection/copyonwritearraylist-source-code.md)
|
||||
- [ArrayBlockingQueue 核心源码分析](./docs/java/collection/arrayblockingqueue-source-code.md)
|
||||
|
||||
### IO
|
||||
|
||||
|
|
@ -353,12 +352,13 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
|||
|
||||
### 分布式 ID
|
||||
|
||||
- [分布式 ID 常见知识点&面试题总结](https://javaguide.cn/distributed-system/distributed-id.html)
|
||||
- [分布式ID介绍&实现方案总结](https://javaguide.cn/distributed-system/distributed-id.html)
|
||||
- [分布式 ID 设计指南](https://javaguide.cn/distributed-system/distributed-id-design.html)
|
||||
|
||||
### 分布式锁
|
||||
|
||||
[分布式锁常见知识点&面试题总结](https://javaguide.cn/distributed-system/distributed-lock.html)
|
||||
- [分布式锁介绍](https://javaguide.cn/distributed-system/distributed-lock.html)
|
||||
- [分布式锁常见实现方案总结](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)
|
||||
|
||||
### 分布式事务
|
||||
|
||||
|
|
|
|||
|
|
@ -2,11 +2,6 @@ import { navbar } from "vuepress-theme-hope";
|
|||
|
||||
export default navbar([
|
||||
{ text: "面试指南", icon: "java", link: "/home.md" },
|
||||
{
|
||||
text: "知识星球",
|
||||
icon: "planet",
|
||||
link: "/about-the-author/zhishixingqiu-two-years.md",
|
||||
},
|
||||
{ text: "开源项目", icon: "github", link: "/open-source-project/" },
|
||||
{ text: "技术书籍", icon: "book", link: "/books/" },
|
||||
{
|
||||
|
|
@ -14,6 +9,27 @@ export default navbar([
|
|||
icon: "article",
|
||||
link: "/high-quality-technical-articles/",
|
||||
},
|
||||
{
|
||||
text: "知识星球",
|
||||
icon: "planet",
|
||||
children: [
|
||||
{
|
||||
text: "星球介绍",
|
||||
icon: "about",
|
||||
link: "/about-the-author/zhishixingqiu-two-years.md",
|
||||
},
|
||||
{
|
||||
text: "星球专属优质专栏",
|
||||
icon: "about",
|
||||
link: "/zhuanlan/",
|
||||
},
|
||||
{
|
||||
text: "星球优质主题汇总",
|
||||
icon: "star",
|
||||
link: "https://www.yuque.com/snailclimb/rpkqw1/ncxpnfmlng08wlf1",
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
text: "网站相关",
|
||||
icon: "about",
|
||||
|
|
|
|||
|
|
@ -13,6 +13,7 @@ export default sidebar({
|
|||
"/high-quality-technical-articles/": highQualityTechnicalArticles,
|
||||
"/zhuanlan/": [
|
||||
"java-mian-shi-zhi-bei",
|
||||
"back-end-interview-high-frequency-system-design-and-scenario-questions",
|
||||
"handwritten-rpc-framework",
|
||||
"source-code-reading",
|
||||
],
|
||||
|
|
@ -89,6 +90,7 @@ export default sidebar({
|
|||
"hashmap-source-code",
|
||||
"concurrent-hash-map-source-code",
|
||||
"copyonwritearraylist-source-code",
|
||||
"arrayblockingqueue-source-code",
|
||||
],
|
||||
},
|
||||
],
|
||||
|
|
@ -472,7 +474,7 @@ export default sidebar({
|
|||
{
|
||||
text: "分布式锁",
|
||||
icon: "lock",
|
||||
children: ["distributed-lock"],
|
||||
children: ["distributed-lock", "distributed-lock-implementations"],
|
||||
},
|
||||
{
|
||||
text: "RPC",
|
||||
|
|
|
|||
|
|
@ -22,9 +22,9 @@ tag:
|
|||
|
||||
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于 1970 年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
|
||||
|
||||

|
||||
Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1(代表 false 或者 true),这也是 Bloom Filter 节省内存的核心所在。这样来算的话,申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
|
||||
|
||||
位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
|
||||

|
||||
|
||||
总结:**一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。**
|
||||
|
||||
|
|
@ -40,9 +40,9 @@ tag:
|
|||
1. 对给定元素再次进行相同的哈希计算;
|
||||
2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
||||
|
||||
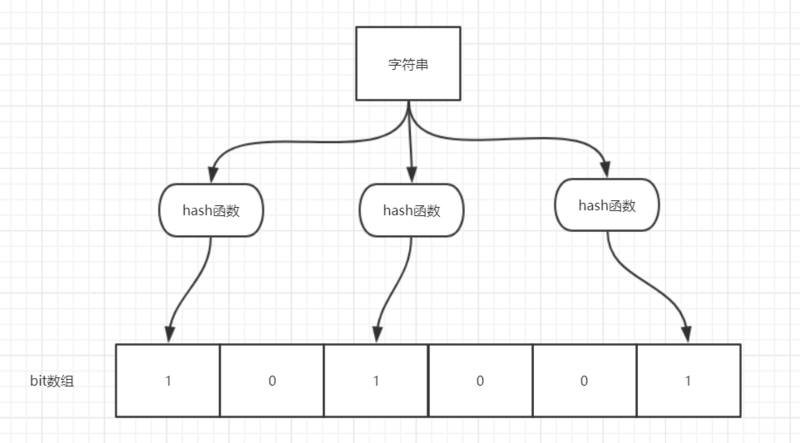
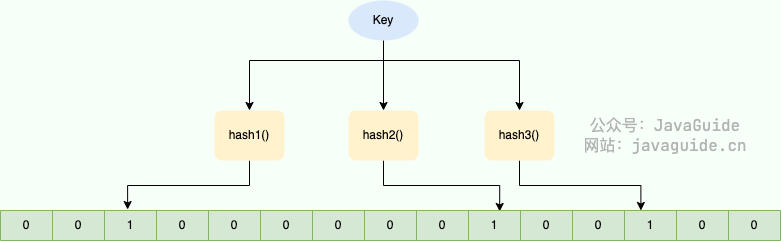
举个简单的例子:
|
||||
Bloom Filter 的简单原理图如下:
|
||||
|
||||
|
||||
|
||||
|
||||
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后将对应的位数组的下标设置为 1(当位数组初始化时,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
|
||||
|
||||
|
|
@ -54,8 +54,10 @@ tag:
|
|||
|
||||
## 布隆过滤器使用场景
|
||||
|
||||
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
|
||||
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
|
||||
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,上亿)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤(判断一个邮件地址是否在垃圾邮件列表中)、黑名单功能(判断一个IP地址或手机号码是否在黑名单中)等等。
|
||||
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重、对巨量的 QQ号/订单号去重。
|
||||
|
||||
去重场景也需要用到判断给定数据是否存在,因此布隆过滤器主要是为了解决海量数据的存在性问题。
|
||||
|
||||
## 编码实战
|
||||
|
||||
|
|
@ -256,7 +258,7 @@ RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、Ja
|
|||
|
||||
**具体操作如下:**
|
||||
|
||||
```
|
||||
```bash
|
||||
➜ ~ docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
|
||||
➜ ~ docker exec -it redis-redisbloom bash
|
||||
root@21396d02c252:/data# redis-cli
|
||||
|
|
|
|||
|
|
@ -373,7 +373,7 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
|
|||
- 用户级别环境变量 : `~/.bashrc`、`~/.bash_profile`。
|
||||
- 系统级别环境变量 : `/etc/bashrc`、`/etc/environment`、`/etc/profile`、`/etc/profile.d`。
|
||||
|
||||
上述配置文件执行先后顺序为:`/etc/enviroment` –> `/etc/profile` –> `/etc/profile.d` –> `~/.bash_profile` –> `/etc/bashrc` –> `~/.bashrc`
|
||||
上述配置文件执行先后顺序为:`/etc/environment` –> `/etc/profile` –> `/etc/profile.d` –> `~/.bash_profile` –> `/etc/bashrc` –> `~/.bashrc`
|
||||
|
||||
如果要修改系统级别环境变量文件,需要管理员具备对该文件的写入权限。
|
||||
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: 分布式ID常见问题总结
|
||||
title: 分布式ID介绍&实现方案总结
|
||||
category: 分布式
|
||||
---
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,366 @@
|
|||
---
|
||||
title: 分布式锁常见实现方案总结
|
||||
category: 分布式
|
||||
---
|
||||
|
||||
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点,我这里也先以 Redis 为例介绍分布式锁的实现。
|
||||
|
||||
## 基于 Redis 实现分布式锁
|
||||
|
||||
### 如何基于 Redis 实现一个最简易的分布式锁?
|
||||
|
||||
不论是本地锁还是分布式锁,核心都在于“互斥”。
|
||||
|
||||
在 Redis 中, `SETNX` 命令是可以帮助我们实现互斥。`SETNX` 即 **SET** if **N**ot e**X**ists (对应 Java 中的 `setIfAbsent` 方法),如果 key 不存在的话,才会设置 key 的值。如果 key 已经存在, `SETNX` 啥也不做。
|
||||
|
||||
```bash
|
||||
> SETNX lockKey uniqueValue
|
||||
(integer) 1
|
||||
> SETNX lockKey uniqueValue
|
||||
(integer) 0
|
||||
```
|
||||
|
||||
释放锁的话,直接通过 `DEL` 命令删除对应的 key 即可。
|
||||
|
||||
```bash
|
||||
> DEL lockKey
|
||||
(integer) 1
|
||||
```
|
||||
|
||||
为了防止误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value(唯一值)来判断。
|
||||
|
||||
选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
|
||||
|
||||
```lua
|
||||
// 释放锁时,先比较锁对应的 value 值是否相等,避免锁的误释放
|
||||
if redis.call("get",KEYS[1]) == ARGV[1] then
|
||||
return redis.call("del",KEYS[1])
|
||||
else
|
||||
return 0
|
||||
end
|
||||
```
|
||||
|
||||
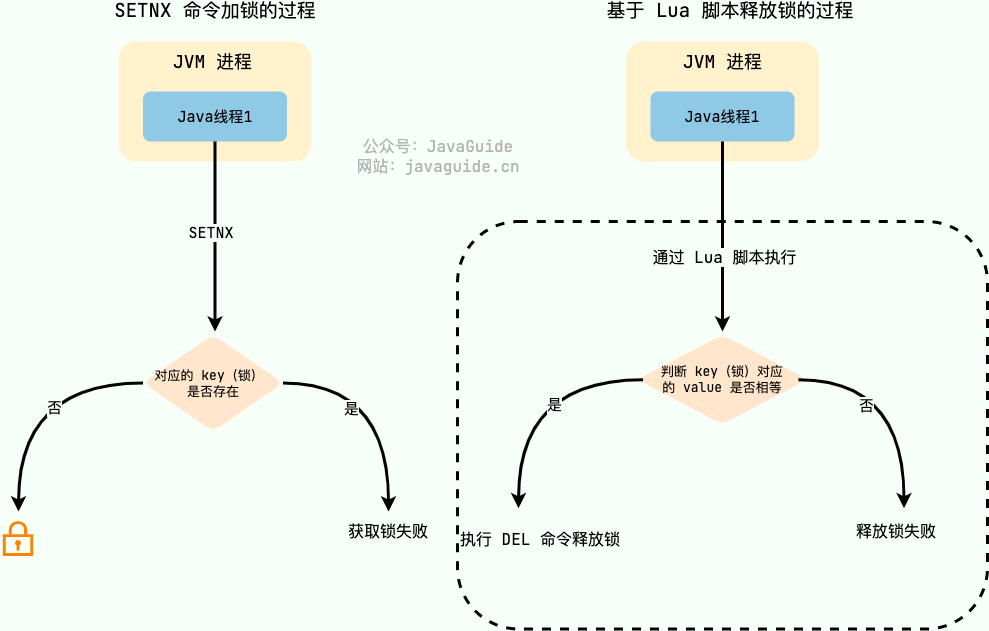
|
||||
|
||||
这是一种最简易的 Redis 分布式锁实现,实现方式比较简单,性能也很高效。不过,这种方式实现分布式锁存在一些问题。就比如应用程序遇到一些问题比如释放锁的逻辑突然挂掉,可能会导致锁无法被释放,进而造成共享资源无法再被其他线程/进程访问。
|
||||
|
||||
### 为什么要给锁设置一个过期时间?
|
||||
|
||||
为了避免锁无法被释放,我们可以想到的一个解决办法就是:**给这个 key(也就是锁) 设置一个过期时间** 。
|
||||
|
||||
```bash
|
||||
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
|
||||
OK
|
||||
```
|
||||
|
||||
- **lockKey**:加锁的锁名;
|
||||
- **uniqueValue**:能够唯一标示锁的随机字符串;
|
||||
- **NX**:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
|
||||
- **EX**:过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
|
||||
|
||||
**一定要保证设置指定 key 的值和过期时间是一个原子操作!!!** 不然的话,依然可能会出现锁无法被释放的问题。
|
||||
|
||||
这样确实可以解决问题,不过,这种解决办法同样存在漏洞:**如果操作共享资源的时间大于过期时间,就会出现锁提前过期的问题,进而导致分布式锁直接失效。如果锁的超时时间设置过长,又会影响到性能。**
|
||||
|
||||
你或许在想:**如果操作共享资源的操作还未完成,锁过期时间能够自己续期就好了!**
|
||||
|
||||
### 如何实现锁的优雅续期?
|
||||
|
||||
对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:<https://redis.io/topics/distlock> 。
|
||||
|
||||

|
||||
|
||||
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,不仅仅包括多种分布式锁的实现。并且,Redisson 还支持 Redis 单机、Redis Sentinel、Redis Cluster 等多种部署架构。
|
||||
|
||||
Redisson 中的分布式锁自带自动续期机制,使用起来非常简单,原理也比较简单,其提供了一个专门用来监控和续期锁的 **Watch Dog( 看门狗)**,如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放。
|
||||
|
||||
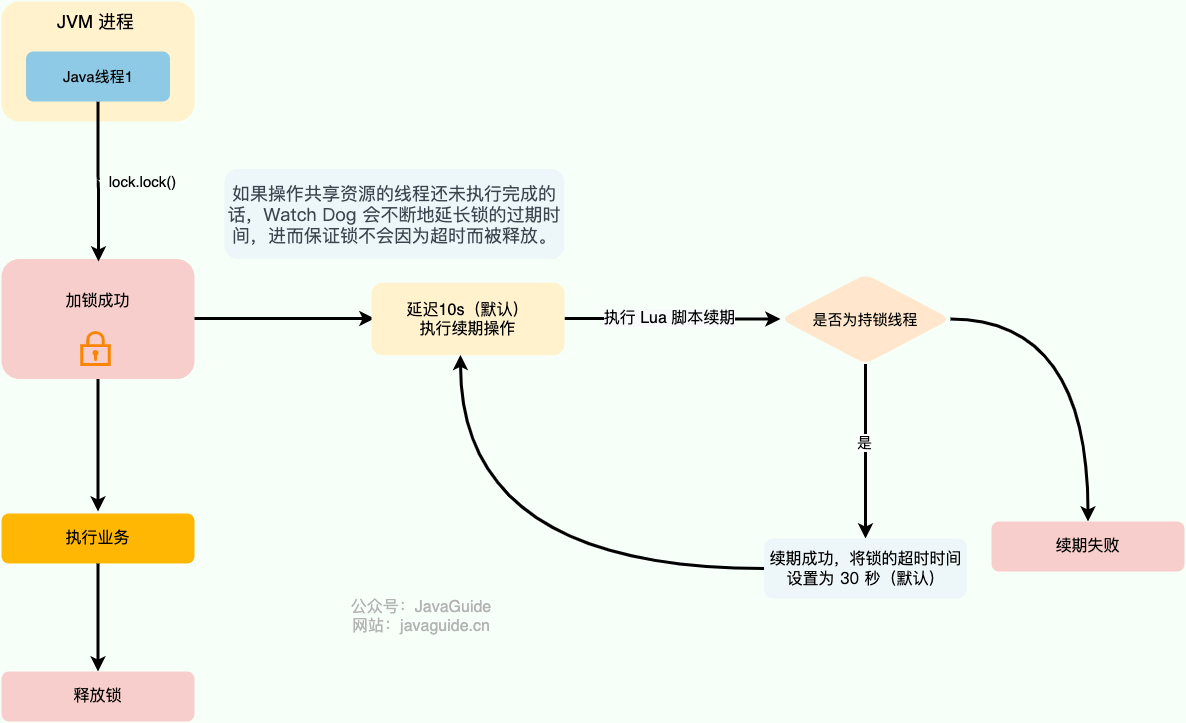
|
||||
|
||||
看门狗名字的由来于 `getLockWatchdogTimeout()` 方法,这个方法返回的是看门狗给锁续期的过期时间,默认为 30 秒([redisson-3.17.6](https://github.com/redisson/redisson/releases/tag/redisson-3.17.6))。
|
||||
|
||||
```java
|
||||
//默认 30秒,支持修改
|
||||
private long lockWatchdogTimeout = 30 * 1000;
|
||||
|
||||
public Config setLockWatchdogTimeout(long lockWatchdogTimeout) {
|
||||
this.lockWatchdogTimeout = lockWatchdogTimeout;
|
||||
return this;
|
||||
}
|
||||
public long getLockWatchdogTimeout() {
|
||||
return lockWatchdogTimeout;
|
||||
}
|
||||
```
|
||||
|
||||
`renewExpiration()` 方法包含了看门狗的主要逻辑:
|
||||
|
||||
```java
|
||||
private void renewExpiration() {
|
||||
//......
|
||||
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
|
||||
@Override
|
||||
public void run(Timeout timeout) throws Exception {
|
||||
//......
|
||||
// 异步续期,基于 Lua 脚本
|
||||
CompletionStage<Boolean> future = renewExpirationAsync(threadId);
|
||||
future.whenComplete((res, e) -> {
|
||||
if (e != null) {
|
||||
// 无法续期
|
||||
log.error("Can't update lock " + getRawName() + " expiration", e);
|
||||
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
|
||||
return;
|
||||
}
|
||||
|
||||
if (res) {
|
||||
// 递归调用实现续期
|
||||
renewExpiration();
|
||||
} else {
|
||||
// 取消续期
|
||||
cancelExpirationRenewal(null);
|
||||
}
|
||||
});
|
||||
}
|
||||
// 延迟 internalLockLeaseTime/3(默认 10s,也就是 30/3) 再调用
|
||||
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
|
||||
|
||||
ee.setTimeout(task);
|
||||
}
|
||||
```
|
||||
|
||||
默认情况下,每过 10 秒,看门狗就会执行续期操作,将锁的超时时间设置为 30 秒。看门狗续期前也会先判断是否需要执行续期操作,需要才会执行续期,否则取消续期操作。
|
||||
|
||||
Watch Dog 通过调用 `renewExpirationAsync()` 方法实现锁的异步续期:
|
||||
|
||||
```java
|
||||
protected CompletionStage<Boolean> renewExpirationAsync(long threadId) {
|
||||
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
|
||||
// 判断是否为持锁线程,如果是就执行续期操作,就锁的过期时间设置为 30s(默认)
|
||||
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
|
||||
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
|
||||
"return 1; " +
|
||||
"end; " +
|
||||
"return 0;",
|
||||
Collections.singletonList(getRawName()),
|
||||
internalLockLeaseTime, getLockName(threadId));
|
||||
}
|
||||
```
|
||||
|
||||
可以看出, `renewExpirationAsync` 方法其实是调用 Lua 脚本实现的续期,这样做主要是为了保证续期操作的原子性。
|
||||
|
||||
我这里以 Redisson 的分布式可重入锁 `RLock` 为例来说明如何使用 Redisson 实现分布式锁:
|
||||
|
||||
```java
|
||||
// 1.获取指定的分布式锁对象
|
||||
RLock lock = redisson.getLock("lock");
|
||||
// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
|
||||
lock.lock();
|
||||
// 3.执行业务
|
||||
...
|
||||
// 4.释放锁
|
||||
lock.unlock();
|
||||
```
|
||||
|
||||
只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制。
|
||||
|
||||
```java
|
||||
// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
|
||||
lock.lock(10, TimeUnit.SECONDS);
|
||||
```
|
||||
|
||||
如果使用 Redis 来实现分布式锁的话,还是比较推荐直接基于 Redisson 来做的。
|
||||
|
||||
### 如何实现可重入锁?
|
||||
|
||||
所谓可重入锁指的是在一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法即可重入 ,而无需重新获得锁。像 Java 中的 `synchronized` 和 `ReentrantLock` 都属于可重入锁。
|
||||
|
||||
**不可重入的分布式锁基本可以满足绝大部分业务场景了,一些特殊的场景可能会需要使用可重入的分布式锁。**
|
||||
|
||||
可重入分布式锁的实现核心思路是线程在获取锁的时候判断是否为自己的锁,如果是的话,就不用再重新获取了。为此,我们可以为每个锁关联一个可重入计数器和一个占有它的线程。当可重入计数器大于 0 时,则锁被占有,需要判断占有该锁的线程和请求获取锁的线程是否为同一个。
|
||||
|
||||
实际项目中,我们不需要自己手动实现,推荐使用我们上面提到的 **Redisson** ,其内置了多种类型的锁比如可重入锁(Reentrant Lock)、自旋锁(Spin Lock)、公平锁(Fair Lock)、多重锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)。
|
||||
|
||||
|
||||
|
||||
### Redis 如何解决集群情况下分布式锁的可靠性?
|
||||
|
||||
为了避免单点故障,生产环境下的 Redis 服务通常是集群化部署的。
|
||||
|
||||
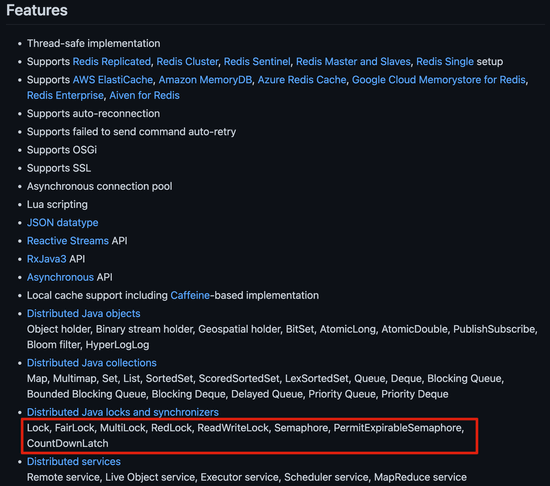
Redis 集群下,上面介绍到的分布式锁的实现会存在一些问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
|
||||
|
||||
|
||||
|
||||
针对这个问题,Redis 之父 antirez 设计了 [Redlock 算法](https://redis.io/topics/distlock) 来解决。
|
||||
|
||||

|
||||
|
||||
Redlock 算法的思想是让客户端向 Redis 集群中的多个独立的 Redis 实例依次请求申请加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
|
||||
|
||||
即使部分 Redis 节点出现问题,只要保证 Redis 集群中有半数以上的 Redis 节点可用,分布式锁服务就是正常的。
|
||||
|
||||
Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的,这样才可以避免 Redis 集群主从切换导致的锁丢失问题。
|
||||
|
||||
Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock,他认为这是一个很差的分布式锁实现。感兴趣的朋友可以看看[Redis 锁从面试连环炮聊到神仙打架](https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
|
||||
|
||||
实际项目中不建议使用 Redlock 算法,成本和收益不成正比。
|
||||
|
||||
如果不是非要实现绝对可靠的分布式锁的话,其实单机版 Redis 就完全够了,实现简单,性能也非常高。如果你必须要实现一个绝对可靠的分布式锁的话,可以基于 ZooKeeper 来做,只是性能会差一些。
|
||||
|
||||
## 基于 ZooKeeper 实现分布式锁
|
||||
|
||||
Redis 实现分布式锁性能较高,ZooKeeper 实现分布式锁可靠性更高。实际项目中,我们应该根据业务的具体需求来选择。
|
||||
|
||||
### 如何基于 ZooKeeper 实现分布式锁?
|
||||
|
||||
ZooKeeper 分布式锁是基于 **临时顺序节点** 和 **Watcher(事件监听器)** 实现的。
|
||||
|
||||
获取锁:
|
||||
|
||||
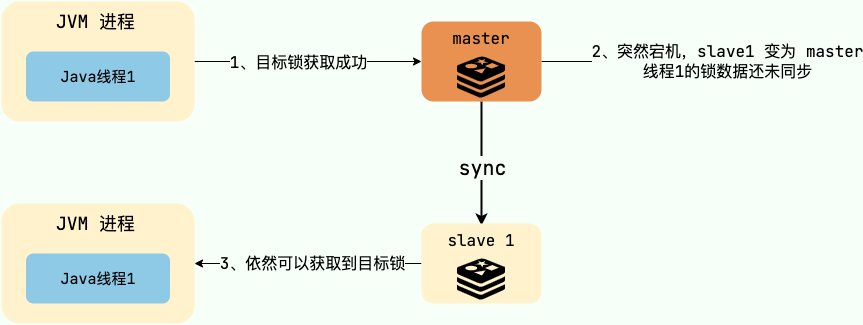
1. 首先我们要有一个持久节点`/locks`,客户端获取锁就是在`locks`下创建临时顺序节点。
|
||||
2. 假设客户端 1 创建了`/locks/lock1`节点,创建成功之后,会判断 `lock1`是否是 `/locks` 下最小的子节点。
|
||||
3. 如果 `lock1`是最小的子节点,则获取锁成功。否则,获取锁失败。
|
||||
4. 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如`/locks/lock0`上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1(避免无效自旋),这样客户端 1 就加锁成功了。
|
||||
|
||||
释放锁:
|
||||
|
||||
1. 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
|
||||
2. 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
|
||||
3. 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
|
||||
|
||||
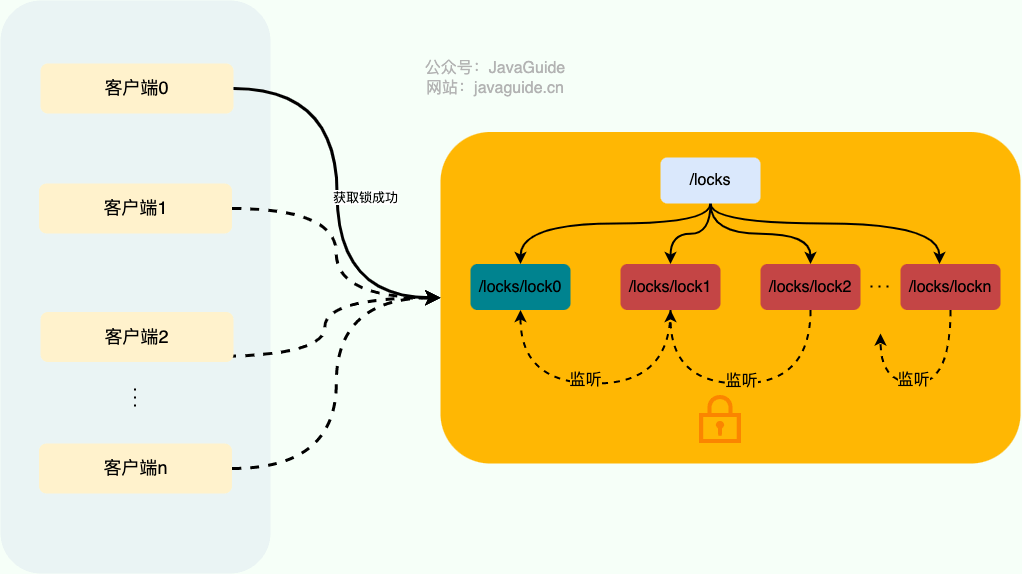
|
||||
|
||||
实际项目中,推荐使用 Curator 来实现 ZooKeeper 分布式锁。Curator 是 Netflix 公司开源的一套 ZooKeeper Java 客户端框架,相比于 ZooKeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
|
||||
|
||||
`Curator`主要实现了下面四种锁:
|
||||
|
||||
- `InterProcessMutex`:分布式可重入排它锁
|
||||
- `InterProcessSemaphoreMutex`:分布式不可重入排它锁
|
||||
- `InterProcessReadWriteLock`:分布式读写锁
|
||||
- `InterProcessMultiLock`:将多个锁作为单个实体管理的容器,获取锁的时候获取所有锁,释放锁也会释放所有锁资源(忽略释放失败的锁)。
|
||||
|
||||
```java
|
||||
CuratorFramework client = ZKUtils.getClient();
|
||||
client.start();
|
||||
// 分布式可重入排它锁
|
||||
InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
|
||||
// 分布式不可重入排它锁
|
||||
InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
|
||||
// 将多个锁作为一个整体
|
||||
InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));
|
||||
|
||||
if (!lock.acquire(10, TimeUnit.SECONDS)) {
|
||||
throw new IllegalStateException("不能获取多锁");
|
||||
}
|
||||
System.out.println("已获取多锁");
|
||||
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
|
||||
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
|
||||
try {
|
||||
// 资源操作
|
||||
resource.use();
|
||||
} finally {
|
||||
System.out.println("释放多个锁");
|
||||
lock.release();
|
||||
}
|
||||
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
|
||||
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
|
||||
client.close();
|
||||
```
|
||||
|
||||
### 为什么要用临时顺序节点?
|
||||
|
||||
每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。
|
||||
|
||||
我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
|
||||
可以看出,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
|
||||
|
||||
使用 Redis 实现分布式锁的时候,我们是通过过期时间来避免锁无法被释放导致死锁问题的,而 ZooKeeper 直接利用临时节点的特性即可。
|
||||
|
||||
假设不适用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
|
||||
|
||||
### 为什么要设置对前一个节点的监听?
|
||||
|
||||
> Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
|
||||
|
||||
同一时间段内,可能会有很多客户端同时获取锁,但只有一个可以获取成功。如果获取锁失败,则说明有其他的客户端已经成功获取锁。获取锁失败的客户端并不会不停地循环去尝试加锁,而是在前一个节点注册一个事件监听器。
|
||||
|
||||
这个事件监听器的作用是:**当前一个节点对应的客户端释放锁之后(也就是前一个节点被删除之后,监听的是删除事件),通知获取锁失败的客户端(唤醒等待的线程,Java 中的 `wait/notifyAll` ),让它尝试去获取锁,然后就成功获取锁了。**
|
||||
|
||||
### 如何实现可重入锁?
|
||||
|
||||
这里以 Curator 的 `InterProcessMutex` 对可重入锁的实现来介绍(源码地址:[InterProcessMutex.java](https://github.com/apache/curator/blob/master/curator-recipes/src/main/java/org/apache/curator/framework/recipes/locks/InterProcessMutex.java))。
|
||||
|
||||
当我们调用 `InterProcessMutex#acquire`方法获取锁的时候,会调用`InterProcessMutex#internalLock`方法。
|
||||
|
||||
```java
|
||||
// 获取可重入互斥锁,直到获取成功为止
|
||||
@Override
|
||||
public void acquire() throws Exception {
|
||||
if (!internalLock(-1, null)) {
|
||||
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`internalLock` 方法会先获取当前请求锁的线程,然后从 `threadData`( `ConcurrentMap<Thread, LockData>` 类型)中获取当前线程对应的 `lockData` 。 `lockData` 包含锁的信息和加锁的次数,是实现可重入锁的关键。
|
||||
|
||||
第一次获取锁的时候,`lockData`为 `null`。获取锁成功之后,会将当前线程和对应的 `lockData` 放到 `threadData` 中
|
||||
|
||||
```java
|
||||
private boolean internalLock(long time, TimeUnit unit) throws Exception {
|
||||
// 获取当前请求锁的线程
|
||||
Thread currentThread = Thread.currentThread();
|
||||
// 拿对应的 lockData
|
||||
LockData lockData = threadData.get(currentThread);
|
||||
// 第一次获取锁的话,lockData 为 null
|
||||
if (lockData != null) {
|
||||
// 当前线程获取过一次锁之后
|
||||
// 因为当前线程的锁存在, lockCount 自增后返回,实现锁重入.
|
||||
lockData.lockCount.incrementAndGet();
|
||||
return true;
|
||||
}
|
||||
// 尝试获取锁
|
||||
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
|
||||
if (lockPath != null) {
|
||||
LockData newLockData = new LockData(currentThread, lockPath);
|
||||
// 获取锁成功之后,将当前线程和对应的 lockData 放到 threadData 中
|
||||
threadData.put(currentThread, newLockData);
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
`LockData`是 `InterProcessMutex`中的一个静态内部类。
|
||||
|
||||
```java
|
||||
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
|
||||
|
||||
private static class LockData
|
||||
{
|
||||
// 当前持有锁的线程
|
||||
final Thread owningThread;
|
||||
// 锁对应的子节点
|
||||
final String lockPath;
|
||||
// 加锁的次数
|
||||
final AtomicInteger lockCount = new AtomicInteger(1);
|
||||
|
||||
private LockData(Thread owningThread, String lockPath)
|
||||
{
|
||||
this.owningThread = owningThread;
|
||||
this.lockPath = lockPath;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
如果已经获取过一次锁,后面再来获取锁的话,直接就会在 `if (lockData != null)` 这里被拦下了,然后就会执行`lockData.lockCount.incrementAndGet();` 将加锁次数加 1。
|
||||
|
||||
整个可重入锁的实现逻辑非常简单,直接在客户端判断当前线程有没有获取锁,有的话直接将加锁次数加 1 就可以了。
|
||||
|
||||
## 总结
|
||||
|
||||
这篇文章我们介绍了实现分布式锁的两种常见方式。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁。
|
||||
|
|
@ -1,11 +1,32 @@
|
|||
---
|
||||
title: 分布式锁常见问题总结
|
||||
title: 分布式锁介绍
|
||||
category: 分布式
|
||||
---
|
||||
|
||||
网上有很多分布式锁相关的文章,写了一个相对简洁易懂的版本,针对面试和工作应该够用了。
|
||||
|
||||
## 分布式锁介绍
|
||||
这篇文章我们先介绍一下分布式锁的基本概念。
|
||||
|
||||
## 为什么需要分布式锁?
|
||||
|
||||
在多线程环境中,如果多个线程同时访问共享资源(例如商品库存、外卖订单),会发生数据竞争,可能会导致出现脏数据或者系统问题,威胁到程序的正常运行。
|
||||
|
||||
举个例子,假设现在有 100 个用户参与某个限时秒杀活动,每位用户限购 1 件商品,且商品的数量只有 3 个。如果不对共享资源进行互斥访问,就可能出现以下情况:
|
||||
|
||||
- 线程 1、2、3 等多个线程同时进入抢购方法,每一个线程对应一个用户。
|
||||
- 线程 1 查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
|
||||
- 线程 2 也执行查询用户已经抢购的数量,发现当前用户尚未抢购且商品库存还有 1 个,因此认为可以继续执行抢购流程。
|
||||
- 线程 1 继续执行,将库存数量减少 1 个,然后返回成功。
|
||||
- 线程 2 继续执行,将库存数量减少 1 个,然后返回成功。
|
||||
- 此时就发生了超卖问题,导致商品被多卖了一份。
|
||||
|
||||
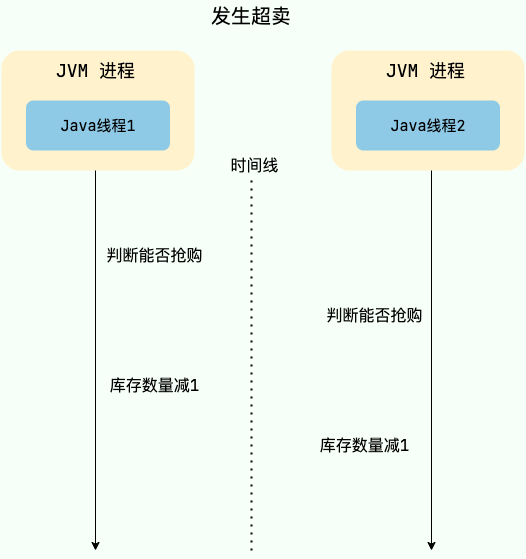
|
||||
|
||||
为了保证共享资源被安全地访问,我们需要使用互斥操作对共享资源进行保护,即同一时刻只允许一个线程访问共享资源,其他线程需要等待当前线程释放后才能访问。这样可以避免数据竞争和脏数据问题,保证程序的正确性和稳定性。
|
||||
|
||||
**如何才能实现共享资源的互斥访问呢?** 锁是一个比较通用的解决方案,更准确点来说是悲观锁。
|
||||
|
||||
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
|
||||
|
||||
对于单机多线程来说,在 Java 中,我们通常使用 `ReetrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
|
||||
|
||||
|
|
@ -25,371 +46,35 @@ category: 分布式
|
|||
|
||||
从图中可以看出,这些独立的进程中的线程访问共享资源是互斥的,同一时刻只有一个线程可以获取到分布式锁访问共享资源。
|
||||
|
||||
## 分布式锁应该具备哪些条件?
|
||||
|
||||
一个最基本的分布式锁需要满足:
|
||||
|
||||
- **互斥**:任意一个时刻,锁只能被一个线程持有;
|
||||
- **高可用**:锁服务是高可用的。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。
|
||||
- **互斥**:任意一个时刻,锁只能被一个线程持有。
|
||||
- **高可用**:锁服务是高可用的,当一个锁服务出现问题,能够自动切换到另外一个锁服务。并且,即使客户端的释放锁的代码逻辑出现问题,锁最终一定还是会被释放,不会影响其他线程对共享资源的访问。这一般是通过超时机制实现的。
|
||||
- **可重入**:一个节点获取了锁之后,还可以再次获取锁。
|
||||
|
||||
通常情况下,我们一般会选择基于 Redis 或者 ZooKeeper 实现分布式锁,Redis 用的要更多一点,我这里也以 Redis 为例介绍分布式锁的实现。
|
||||
除了上面这三个基本条件之外,一个好的分布式锁还需要满足下面这些条件:
|
||||
|
||||
## 基于 Redis 实现分布式锁
|
||||
- **高性能**:获取和释放锁的操作应该快速完成,并且不应该对整个系统的性能造成过大影响。
|
||||
- **非阻塞**:如果获取不到锁,不能无限期等待,避免对系统正常运行造成影响。
|
||||
|
||||
### 如何基于 Redis 实现一个最简易的分布式锁?
|
||||
## 分布式锁的常见实现方式有哪些?
|
||||
|
||||
不论是本地锁还是分布式锁,核心都在于“互斥”。
|
||||
常见分布式锁实现方案如下:
|
||||
|
||||
在 Redis 中, `SETNX` 命令是可以帮助我们实现互斥。`SETNX` 即 **SET** if **N**ot e**X**ists (对应 Java 中的 `setIfAbsent` 方法),如果 key 不存在的话,才会设置 key 的值。如果 key 已经存在, `SETNX` 啥也不做。
|
||||
- 基于关系型数据库比如 MySQL 实现分布式锁。
|
||||
- 基于分布式协调服务 ZooKeeper 实现分布式锁。
|
||||
- 基于分布式键值存储系统比如 Redis 、Etcd 实现分布式锁。
|
||||
|
||||
```bash
|
||||
> SETNX lockKey uniqueValue
|
||||
(integer) 1
|
||||
> SETNX lockKey uniqueValue
|
||||
(integer) 0
|
||||
```
|
||||
关系型数据库的方式一般是通过唯一索引或者排他锁实现。不过,一般不会使用这种方式,问题太多比如性能太差、不具备锁失效机制。
|
||||
|
||||
释放锁的话,直接通过 `DEL` 命令删除对应的 key 即可。
|
||||
|
||||
```bash
|
||||
> DEL lockKey
|
||||
(integer) 1
|
||||
```
|
||||
|
||||
为了防止误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value(唯一值)来判断。
|
||||
|
||||
选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
|
||||
|
||||
```lua
|
||||
// 释放锁时,先比较锁对应的 value 值是否相等,避免锁的误释放
|
||||
if redis.call("get",KEYS[1]) == ARGV[1] then
|
||||
return redis.call("del",KEYS[1])
|
||||
else
|
||||
return 0
|
||||
end
|
||||
```
|
||||
|
||||

|
||||
|
||||
这是一种最简易的 Redis 分布式锁实现,实现方式比较简单,性能也很高效。不过,这种方式实现分布式锁存在一些问题。就比如应用程序遇到一些问题比如释放锁的逻辑突然挂掉,可能会导致锁无法被释放,进而造成共享资源无法再被其他线程/进程访问。
|
||||
|
||||
### 为什么要给锁设置一个过期时间?
|
||||
|
||||
为了避免锁无法被释放,我们可以想到的一个解决办法就是:**给这个 key(也就是锁) 设置一个过期时间** 。
|
||||
|
||||
```bash
|
||||
127.0.0.1:6379> SET lockKey uniqueValue EX 3 NX
|
||||
OK
|
||||
```
|
||||
|
||||
- **lockKey**:加锁的锁名;
|
||||
- **uniqueValue**:能够唯一标示锁的随机字符串;
|
||||
- **NX**:只有当 lockKey 对应的 key 值不存在的时候才能 SET 成功;
|
||||
- **EX**:过期时间设置(秒为单位)EX 3 标示这个锁有一个 3 秒的自动过期时间。与 EX 对应的是 PX(毫秒为单位),这两个都是过期时间设置。
|
||||
|
||||
**一定要保证设置指定 key 的值和过期时间是一个原子操作!!!** 不然的话,依然可能会出现锁无法被释放的问题。
|
||||
|
||||
这样确实可以解决问题,不过,这种解决办法同样存在漏洞:**如果操作共享资源的时间大于过期时间,就会出现锁提前过期的问题,进而导致分布式锁直接失效。如果锁的超时时间设置过长,又会影响到性能。**
|
||||
|
||||
你或许在想:**如果操作共享资源的操作还未完成,锁过期时间能够自己续期就好了!**
|
||||
|
||||
### 如何实现锁的优雅续期?
|
||||
|
||||
对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:<https://redis.io/topics/distlock> 。
|
||||
|
||||

|
||||
|
||||
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,不仅仅包括多种分布式锁的实现。并且,Redisson 还支持 Redis 单机、Redis Sentinel、Redis Cluster 等多种部署架构。
|
||||
|
||||
Redisson 中的分布式锁自带自动续期机制,使用起来非常简单,原理也比较简单,其提供了一个专门用来监控和续期锁的 **Watch Dog( 看门狗)**,如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断地延长锁的过期时间,进而保证锁不会因为超时而被释放。
|
||||
|
||||

|
||||
|
||||
看门狗名字的由来于 `getLockWatchdogTimeout()` 方法,这个方法返回的是看门狗给锁续期的过期时间,默认为 30 秒([redisson-3.17.6](https://github.com/redisson/redisson/releases/tag/redisson-3.17.6))。
|
||||
|
||||
```java
|
||||
//默认 30秒,支持修改
|
||||
private long lockWatchdogTimeout = 30 * 1000;
|
||||
|
||||
public Config setLockWatchdogTimeout(long lockWatchdogTimeout) {
|
||||
this.lockWatchdogTimeout = lockWatchdogTimeout;
|
||||
return this;
|
||||
}
|
||||
public long getLockWatchdogTimeout() {
|
||||
return lockWatchdogTimeout;
|
||||
}
|
||||
```
|
||||
|
||||
`renewExpiration()` 方法包含了看门狗的主要逻辑:
|
||||
|
||||
```java
|
||||
private void renewExpiration() {
|
||||
//......
|
||||
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
|
||||
@Override
|
||||
public void run(Timeout timeout) throws Exception {
|
||||
//......
|
||||
// 异步续期,基于 Lua 脚本
|
||||
CompletionStage<Boolean> future = renewExpirationAsync(threadId);
|
||||
future.whenComplete((res, e) -> {
|
||||
if (e != null) {
|
||||
// 无法续期
|
||||
log.error("Can't update lock " + getRawName() + " expiration", e);
|
||||
EXPIRATION_RENEWAL_MAP.remove(getEntryName());
|
||||
return;
|
||||
}
|
||||
|
||||
if (res) {
|
||||
// 递归调用实现续期
|
||||
renewExpiration();
|
||||
} else {
|
||||
// 取消续期
|
||||
cancelExpirationRenewal(null);
|
||||
}
|
||||
});
|
||||
}
|
||||
// 延迟 internalLockLeaseTime/3(默认 10s,也就是 30/3) 再调用
|
||||
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
|
||||
|
||||
ee.setTimeout(task);
|
||||
}
|
||||
```
|
||||
|
||||
默认情况下,每过 10 秒,看门狗就会执行续期操作,将锁的超时时间设置为 30 秒。看门狗续期前也会先判断是否需要执行续期操作,需要才会执行续期,否则取消续期操作。
|
||||
|
||||
Watch Dog 通过调用 `renewExpirationAsync()` 方法实现锁的异步续期:
|
||||
|
||||
```java
|
||||
protected CompletionStage<Boolean> renewExpirationAsync(long threadId) {
|
||||
return evalWriteAsync(getRawName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
|
||||
// 判断是否为持锁线程,如果是就执行续期操作,就锁的过期时间设置为 30s(默认)
|
||||
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
|
||||
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
|
||||
"return 1; " +
|
||||
"end; " +
|
||||
"return 0;",
|
||||
Collections.singletonList(getRawName()),
|
||||
internalLockLeaseTime, getLockName(threadId));
|
||||
}
|
||||
```
|
||||
|
||||
可以看出, `renewExpirationAsync` 方法其实是调用 Lua 脚本实现的续期,这样做主要是为了保证续期操作的原子性。
|
||||
|
||||
我这里以 Redisson 的分布式可重入锁 `RLock` 为例来说明如何使用 Redisson 实现分布式锁:
|
||||
|
||||
```java
|
||||
// 1.获取指定的分布式锁对象
|
||||
RLock lock = redisson.getLock("lock");
|
||||
// 2.拿锁且不设置锁超时时间,具备 Watch Dog 自动续期机制
|
||||
lock.lock();
|
||||
// 3.执行业务
|
||||
...
|
||||
// 4.释放锁
|
||||
lock.unlock();
|
||||
```
|
||||
|
||||
只有未指定锁超时时间,才会使用到 Watch Dog 自动续期机制。
|
||||
|
||||
```java
|
||||
// 手动给锁设置过期时间,不具备 Watch Dog 自动续期机制
|
||||
lock.lock(10, TimeUnit.SECONDS);
|
||||
```
|
||||
|
||||
如果使用 Redis 来实现分布式锁的话,还是比较推荐直接基于 Redisson 来做的。
|
||||
|
||||
### 如何实现可重入锁?
|
||||
|
||||
所谓可重入锁指的是在一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法即可重入 ,而无需重新获得锁。像 Java 中的 `synchronized` 和 `ReentrantLock` 都属于可重入锁。
|
||||
|
||||
**不可重入的分布式锁基本可以满足绝大部分业务场景了,一些特殊的场景可能会需要使用可重入的分布式锁。**
|
||||
|
||||
可重入分布式锁的实现核心思路是线程在获取锁的时候判断是否为自己的锁,如果是的话,就不用再重新获取了。为此,我们可以为每个锁关联一个可重入计数器和一个占有它的线程。当可重入计数器大于 0 时,则锁被占有,需要判断占有该锁的线程和请求获取锁的线程是否为同一个。
|
||||
|
||||
实际项目中,我们不需要自己手动实现,推荐使用我们上面提到的 **Redisson** ,其内置了多种类型的锁比如可重入锁(Reentrant Lock)、自旋锁(Spin Lock)、公平锁(Fair Lock)、多重锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)。
|
||||
|
||||

|
||||
|
||||
### Redis 如何解决集群情况下分布式锁的可靠性?
|
||||
|
||||
为了避免单点故障,生产环境下的 Redis 服务通常是集群化部署的。
|
||||
|
||||
Redis 集群下,上面介绍到的分布式锁的实现会存在一些问题。由于 Redis 集群数据同步到各个节点时是异步的,如果在 Redis 主节点获取到锁后,在没有同步到其他节点时,Redis 主节点宕机了,此时新的 Redis 主节点依然可以获取锁,所以多个应用服务就可以同时获取到锁。
|
||||
|
||||

|
||||
|
||||
针对这个问题,Redis 之父 antirez 设计了 [Redlock 算法](https://redis.io/topics/distlock) 来解决。
|
||||
|
||||

|
||||
|
||||
Redlock 算法的思想是让客户端向 Redis 集群中的多个独立的 Redis 实例依次请求申请加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁,否则加锁失败。
|
||||
|
||||
即使部分 Redis 节点出现问题,只要保证 Redis 集群中有半数以上的 Redis 节点可用,分布式锁服务就是正常的。
|
||||
|
||||
Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的,这样才可以避免 Redis 集群主从切换导致的锁丢失问题。
|
||||
|
||||
Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock,他认为这是一个很差的分布式锁实现。感兴趣的朋友可以看看[Redis 锁从面试连环炮聊到神仙打架](https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
|
||||
|
||||
实际项目中不建议使用 Redlock 算法,成本和收益不成正比。
|
||||
|
||||
如果不是非要实现绝对可靠的分布式锁的话,其实单机版 Redis 就完全够了,实现简单,性能也非常高。如果你必须要实现一个绝对可靠的分布式锁的话,可以基于 ZooKeeper 来做,只是性能会差一些。
|
||||
|
||||
## 基于 ZooKeeper 实现分布式锁
|
||||
|
||||
Redis 实现分布式锁性能较高,ZooKeeper 实现分布式锁可靠性更高。实际项目中,我们应该根据业务的具体需求来选择。
|
||||
|
||||
### 如何基于 ZooKeeper 实现分布式锁?
|
||||
|
||||
ZooKeeper 分布式锁是基于 **临时顺序节点** 和 **Watcher(事件监听器)** 实现的。
|
||||
|
||||
获取锁:
|
||||
|
||||
1. 首先我们要有一个持久节点`/locks`,客户端获取锁就是在`locks`下创建临时顺序节点。
|
||||
2. 假设客户端 1 创建了`/locks/lock1`节点,创建成功之后,会判断 `lock1`是否是 `/locks` 下最小的子节点。
|
||||
3. 如果 `lock1`是最小的子节点,则获取锁成功。否则,获取锁失败。
|
||||
4. 如果获取锁失败,则说明有其他的客户端已经成功获取锁。客户端 1 并不会不停地循环去尝试加锁,而是在前一个节点比如`/locks/lock0`上注册一个事件监听器。这个监听器的作用是当前一个节点释放锁之后通知客户端 1(避免无效自旋),这样客户端 1 就加锁成功了。
|
||||
|
||||
释放锁:
|
||||
|
||||
1. 成功获取锁的客户端在执行完业务流程之后,会将对应的子节点删除。
|
||||
2. 成功获取锁的客户端在出现故障之后,对应的子节点由于是临时顺序节点,也会被自动删除,避免了锁无法被释放。
|
||||
3. 我们前面说的事件监听器其实监听的就是这个子节点删除事件,子节点删除就意味着锁被释放。
|
||||
|
||||

|
||||
|
||||
实际项目中,推荐使用 Curator 来实现 ZooKeeper 分布式锁。Curator 是 Netflix 公司开源的一套 ZooKeeper Java 客户端框架,相比于 ZooKeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
|
||||
|
||||
`Curator`主要实现了下面四种锁:
|
||||
|
||||
- `InterProcessMutex`:分布式可重入排它锁
|
||||
- `InterProcessSemaphoreMutex`:分布式不可重入排它锁
|
||||
- `InterProcessReadWriteLock`:分布式读写锁
|
||||
- `InterProcessMultiLock`:将多个锁作为单个实体管理的容器,获取锁的时候获取所有锁,释放锁也会释放所有锁资源(忽略释放失败的锁)。
|
||||
|
||||
```java
|
||||
CuratorFramework client = ZKUtils.getClient();
|
||||
client.start();
|
||||
// 分布式可重入排它锁
|
||||
InterProcessLock lock1 = new InterProcessMutex(client, lockPath1);
|
||||
// 分布式不可重入排它锁
|
||||
InterProcessLock lock2 = new InterProcessSemaphoreMutex(client, lockPath2);
|
||||
// 将多个锁作为一个整体
|
||||
InterProcessMultiLock lock = new InterProcessMultiLock(Arrays.asList(lock1, lock2));
|
||||
|
||||
if (!lock.acquire(10, TimeUnit.SECONDS)) {
|
||||
throw new IllegalStateException("不能获取多锁");
|
||||
}
|
||||
System.out.println("已获取多锁");
|
||||
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
|
||||
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
|
||||
try {
|
||||
// 资源操作
|
||||
resource.use();
|
||||
} finally {
|
||||
System.out.println("释放多个锁");
|
||||
lock.release();
|
||||
}
|
||||
System.out.println("是否有第一个锁: " + lock1.isAcquiredInThisProcess());
|
||||
System.out.println("是否有第二个锁: " + lock2.isAcquiredInThisProcess());
|
||||
client.close();
|
||||
```
|
||||
|
||||
### 为什么要用临时顺序节点?
|
||||
|
||||
每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。
|
||||
|
||||
我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
|
||||
可以看出,临时节点相比持久节点,最主要的是对会话失效的情况处理不一样,临时节点会话消失则对应的节点消失。这样的话,如果客户端发生异常导致没来得及释放锁也没关系,会话失效节点自动被删除,不会发生死锁的问题。
|
||||
|
||||
使用 Redis 实现分布式锁的时候,我们是通过过期时间来避免锁无法被释放导致死锁问题的,而 ZooKeeper 直接利用临时节点的特性即可。
|
||||
|
||||
假设不适用顺序节点的话,所有尝试获取锁的客户端都会对持有锁的子节点加监听器。当该锁被释放之后,势必会造成所有尝试获取锁的客户端来争夺锁,这样对性能不友好。使用顺序节点之后,只需要监听前一个节点就好了,对性能更友好。
|
||||
|
||||
### 为什么要设置对前一个节点的监听?
|
||||
|
||||
> Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
|
||||
|
||||
同一时间段内,可能会有很多客户端同时获取锁,但只有一个可以获取成功。如果获取锁失败,则说明有其他的客户端已经成功获取锁。获取锁失败的客户端并不会不停地循环去尝试加锁,而是在前一个节点注册一个事件监听器。
|
||||
|
||||
这个事件监听器的作用是:**当前一个节点对应的客户端释放锁之后(也就是前一个节点被删除之后,监听的是删除事件),通知获取锁失败的客户端(唤醒等待的线程,Java 中的 `wait/notifyAll` ),让它尝试去获取锁,然后就成功获取锁了。**
|
||||
|
||||
### 如何实现可重入锁?
|
||||
|
||||
这里以 Curator 的 `InterProcessMutex` 对可重入锁的实现来介绍(源码地址:[InterProcessMutex.java](https://github.com/apache/curator/blob/master/curator-recipes/src/main/java/org/apache/curator/framework/recipes/locks/InterProcessMutex.java))。
|
||||
|
||||
当我们调用 `InterProcessMutex#acquire`方法获取锁的时候,会调用`InterProcessMutex#internalLock`方法。
|
||||
|
||||
```java
|
||||
// 获取可重入互斥锁,直到获取成功为止
|
||||
@Override
|
||||
public void acquire() throws Exception {
|
||||
if (!internalLock(-1, null)) {
|
||||
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`internalLock` 方法会先获取当前请求锁的线程,然后从 `threadData`( `ConcurrentMap<Thread, LockData>` 类型)中获取当前线程对应的 `lockData` 。 `lockData` 包含锁的信息和加锁的次数,是实现可重入锁的关键。
|
||||
|
||||
第一次获取锁的时候,`lockData`为 `null`。获取锁成功之后,会将当前线程和对应的 `lockData` 放到 `threadData` 中
|
||||
|
||||
```java
|
||||
private boolean internalLock(long time, TimeUnit unit) throws Exception {
|
||||
// 获取当前请求锁的线程
|
||||
Thread currentThread = Thread.currentThread();
|
||||
// 拿对应的 lockData
|
||||
LockData lockData = threadData.get(currentThread);
|
||||
// 第一次获取锁的话,lockData 为 null
|
||||
if (lockData != null) {
|
||||
// 当前线程获取过一次锁之后
|
||||
// 因为当前线程的锁存在, lockCount 自增后返回,实现锁重入.
|
||||
lockData.lockCount.incrementAndGet();
|
||||
return true;
|
||||
}
|
||||
// 尝试获取锁
|
||||
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
|
||||
if (lockPath != null) {
|
||||
LockData newLockData = new LockData(currentThread, lockPath);
|
||||
// 获取锁成功之后,将当前线程和对应的 lockData 放到 threadData 中
|
||||
threadData.put(currentThread, newLockData);
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
```
|
||||
|
||||
`LockData`是 `InterProcessMutex`中的一个静态内部类。
|
||||
|
||||
```java
|
||||
|
||||
private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
|
||||
|
||||
private static class LockData
|
||||
{
|
||||
// 当前持有锁的线程
|
||||
final Thread owningThread;
|
||||
// 锁对应的子节点
|
||||
final String lockPath;
|
||||
// 加锁的次数
|
||||
final AtomicInteger lockCount = new AtomicInteger(1);
|
||||
|
||||
private LockData(Thread owningThread, String lockPath)
|
||||
{
|
||||
this.owningThread = owningThread;
|
||||
this.lockPath = lockPath;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
如果已经获取过一次锁,后面再来获取锁的话,直接就会在 `if (lockData != null)` 这里被拦下了,然后就会执行`lockData.lockCount.incrementAndGet();` 将加锁次数加 1。
|
||||
|
||||
整个可重入锁的实现逻辑非常简单,直接在客户端判断当前线程有没有获取锁,有的话直接将加锁次数加 1 就可以了。
|
||||
基于 ZooKeeper 或者 Redis 实现分布式锁这两种实现方式要用的更多一些,我专门写了一篇文章来详细介绍这两种方案:[分布式锁常见实现方案总结](./distributed-lock-implementations.md)。
|
||||
|
||||
## 总结
|
||||
|
||||
这篇文章我们介绍了分布式锁的基本概念以及实现分布式锁的两种常见方式。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁。
|
||||
这篇文章我们主要介绍了:
|
||||
|
||||
- 分布式锁的用途:分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。
|
||||
- 分布式锁的应该具备的条件:互斥、高可用、可重入、高性能、非阻塞。
|
||||
- 分布式锁的常见实现方式:关系型数据库比如 MySQL、分布式协调服务 ZooKeeper、分布式键值存储系统比如 Redis 、Etcd 。
|
||||
|
|
|
|||
|
|
@ -1 +0,0 @@
|
|||
<mxfile host="Electron" modified="2023-03-22T07:46:10.534Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/20.3.0 Chrome/104.0.5112.114 Electron/20.1.3 Safari/537.36" etag="AiToXsPRDCuB0m7tcCvY" version="20.3.0" type="device"><diagram id="OCHATffbN17S1b6ytZqW" name="第 1 页">7VxZd6LKFv41rHXOQ7IKKBAeGTSxj5DJdNq8ISKCAx7FAX793VUMyqCxO5qk+57OWh1qoIY9f7uKMLw23d4srPnICAbOhOHQYMvwOsNxLItE+EVqoqSmIclJhbvwBmmnXcWTFztpJUprV97AWRY6hkEwCb15sdIOZjPHDgt11mIRbIrdhsGkOOvccp1KxZNtTaq1L94gHGX7EuVdw63juaNsalHASUvfssfuIljN0gkZjm+JrVZLSpqnVjZYutPlyBoEm70qvsnw2iIIwuRputWcCSFuRrfkvdaB1nzhC2cWnvJCxM6d5+Wt1n/d3Pz7Q9Xix/DqKhtmGUYZRZwBECgtBotwFLjBzJo0d7WqvVqsHTIqC4Vdl04QzNNK3wnDKGW2tQoDqBqF00naugwXwTgnNw81w2AWpt1ZAcrVvWXrDFYL2zmyIXiddiS72HszJcmNE0ydcBFBh4UzsUJvXRQDK5UmN++Xv3ofeLAWDqWSz7PidTpVKvkSQsVBQmvhOmH63o4x8LC3kF0VZddPsC7b6dqarJxMBEu8pOKZs2oz8kLnaW5RAm5An99kizeZaMEkWNDR+KFkO7ad98xaZsHMOcaztbMIne1RZqStua6kJBVwIyPyZk85ZT6pG+3rJYcOs7BA+p+m84eTeTjkPpTMnIw+m8hchcjfvhtQwTQlRm0xsso0G4wiMZJaIT5sOqyjcIlu+0ROq6yJ586gaAMpHahXCQk98A1K2jD1BgNq8epYumM6Klkw6UxsEhsFNvGoyiZZqHLpYkzi/zBf8WGuoshHQfhYR4ErujUJ7PE1+e+vv2tZ2rH6EOYV+HC6riycpRdbfToe0Yw52RfdqaAygl7DwQmZTs3DqTcN3jHhrKhXHjqmSypEX3Vqd4WuITot+vbUPL1TEDBbChkyF54NEQyHS+ciMlAXK4iTMGVGQQLEf1dB1nC1pGxSoAMrzLe7Rnhyye9v1toipllViJk+y5B7lj4ZDjacjJi0swfqL+yVJce2HPGSXhnjknjwuMYvY1y1+GWDcr7Yp2o7KmQGXDMnj96UQq3cMFAjch8svdALiIHoB2EYTA+rexL5wL8a4xISb6Fay3kCAYfelvBVpVMqWS3KauB5YIUWCFlS5FrLtctw6ha4zWn3tyb3Gqm4/7Jd2THyrNtHZOvBusMP+EEk8EYkrO2pvTZ8ZWNocjyY2l77dhT2b4T4bjZaWi/C4v7pWzC4fdzcedIa3uI7MzvuTOXoNZK2d92x0OGTfm1PRfdP7a3p90h9fKePt6bei6He79+0Yjr/i7nue213MJ1MBujb2tGRZ2jKpq03N4b/4BpdJTI10v49srnJuu9D+xPewhibzstkDONHRuwiKPPWyyOy4H1Td732zWhivQyCQVq+97eb3o/HoH3zILfHaGt2jZXpKcj0xysjbkYD/4G7e8KxGb8GZtzkOv7oBdYqdHxja4zdpP9sbppkTTCfpbuCOetxpq62Tf/xhdQ5nhqauhJ3/Db0acO746gXocj0MG9226HRfViZcRv6PKzuNIQMD8eG/pCVgfZYMDxl0+k+8B2/uTE1BRka3hq+G97pz3SdbZi34/f2yg9QfuDJe2kbWd8K+Iez8q6vAm3NlenD/rpN3PEVdKcpLOx7a8S9dB1Kso5Zb2t0n1d33R7udR9Qx3fdtH1Dx3lCGN7j2rpKxtqaT1gw/ZHY7Rox7AvmNrB548Zm112ZrV5kdl99Q0OCqeGI0OBOV2CNz+RdHvbI3eku0MeG9RI62RtYNwaaCHcajKsDzTXgWQy88hQe6ImMbi/r7+b9b2HNdA3PW0KPXtyE/WGUrLnNwTOsC9aqYRZ4H5m+S/ZD1sYZ3TZ+0tsI9h5999usOTWAD00EsoaADzAurBfWTdacjdXpQr9ZALL2Ou/fbOS2Z057vssaugI6o4TWC8ia3wa5f/Y6MZY6POhejIm2n8dmysXQSuSqFpOvCZF54VIGs1E1mE2BkRRGASwjMzJmJJZpiowkMYC6kia59RuAGvFcoEYuBsPSJ4Ma7oQ0ijMbKCTXSMg6sZZLzz4bSHkTfOzRJXPzda7/3aEpX1Qk1CgOkYCpCkapDCTIbwx0YbDDybWI5suC1IQcx3DNqYLyTgmQEfolxlUGaki/Jkpng7vyQayznFuzWmCyy+Vf2Yk5Jfhk4fb/4rBE0lAcrAVxZOjsWUB/12EXsOwyozRI3kphGYl07aysNJMlYUZWSB9ZYxSN4iaVUfS0Rm7tIZtkqQeQzQdj9HrTf1T9zgLDEeaK7p19n627PMzmatz/W7JXBsViPSgWiKyoYpYQbbFoyTRbjKqRUAIiC2iVJSp2TUbBWZOcTd9fHJHRqiCSB56RoAYzqk4qTxTN3ywVLsilE4cGe82deOTQ4K4vFUbyNTHIF/BiQOdF9IPYjOu82EtNCC3o20IpSksHGfVmipY/2U3KH+QmpWKOpiF/bDKXz/Kc+wBDJKqvVFHEJ+RyT/QTmYCfxU+wXIEl2WHS13UTwmeo968q73GzcBQWnk+9hbNHwe+zzzWHwrkWgqsGo6CI1HdKJDVOPK5GgX+eAchS5gePNRejYNpfLd92omUNLHrgikN1xIs6VFku4XuRqzvCb9RA2bIlPR+3xM9VNyyyBYW7lkEIjisdLd07Cw8oQEz0CZpIlXrrhT+yIeC5t1N3KO3mIoUzOGf5RO3NwuJLO2dJksqXcsqZvguDT/4w+Dz5VOwAAKiL0UtZxDTo107DHENr6k2iZFJosqZzOh/PY2pF+gGIdLk6x79La7a8WoKADg+AFcRIYsHeAfIF/EvgC6xboNtoUECTP8j0AacgRm3SPevkObekHOIRBdMNAmBk7mcgUAW6fMgxYn3etuRBS1baGQzFoXwmgyxx142SUmT6uGeROZTb6X2bLF7KJuOvd5nkfaEM/qA8XfXioVxm0qXvk1z+Rtybhx00lOk3EH+mU4nSjTgJcdWYpS4HcLGTd8zVEHnfqh9O5lBbSfKMybkTe2rq5s89c8Il7rJV+8cKNdy92KETPuFexW9+dze3Sp+nQjUnexAlSA2iFiTqwDTGyEKU/1t1kBs1AO1j1UE8T9RMg7qaYBTCTSUxjBoJMUkNxIaNNEKUFXKL7YZ8iLKfLX/XnDRwlWncq0BUKudT+TAV/ebl2p6dGoF+DUk8fkuzEtFCec/8qPSHjhla6YUwCmnHTmiPskL2hcxRWPoTyX2hJOg1F6hZqSYTwV5K0IW6vFEV2AkEvqgsBUuYUYSP8g1lJl7KV7A5hXOP/NnOQqjJq7+FoktHxcLudFjcPTakv8kzhc7nhd37g+4ZJenQ+aECoWKSpmwSQase8SWWksgdJlgbDBcRQIHCdpHUyGgPyFcymOnJpJQdcCt1walAwLmk7SUv9jIDCryu51mMF4uYBg7pgUshf2K+lTTAlRKFEanmCGRCFe2dkoJXF+jqajMQLRIFFA47SxmILJGy+/wEZkRZeJ0sk663kNTNF5YvVSDvKmgvFVzNf+Qjw4AcpXo1SOFpH+7XQ/lzeQL2pzwBd4r5OWe2A+Pi5RMs1H1Bll+sPnf6+WH1z7j5TxD0Dd0dPD6N7IZo/okfkPFF8133ZdLlPiCrJXIVLv/3ARnXKH1AVuNlL3XXspZJh33sf1+hfJWvUITKVyhCjXKf6SsUKO4+gE/yk7s/M8A3/wc=</diagram></mxfile>
|
||||
|
|
@ -1 +0,0 @@
|
|||
<mxfile host="Electron" modified="2022-09-01T05:56:36.359Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="rtqWC0t9ZphBIG-VxnhK" version="13.4.5" type="device"><diagram id="1WlLurKbbY4VXUe8oHch" name="第 1 页">7VtZd6JME/41nPN9F8lpoEG4ZNGEOYIxOpPX3CESBBccxAV+/VvNpiwmM6MmM3ln5iJQvVXXU9W1NFKsstjfBeZqqvsTe04xaLKnWJViGJpGPPwhlCiliGIrJTiBO8k6HQgDN7YzIsqoG3dir0sdQ9+fh+6qTLT85dK2whLNDAJ/V+724s/Lq65Mx64RBpY5r1Of3Ek4zffFi4eGe9t1pvnSPIfTlrFpzZzA3yyzBSmG7fCdTkdImxdmPlm20/XUnPi7IxLbplgl8P0wfVrsFXtOhJvLLR3XOdFaMB7Yy/BHBojfo29Tun/3vHRX40f9WeBexjdMts2tOd/Y+T4SbsMoF1GyR5vMQlOsvJu6oT1YmRZp3YFSAG0aLuZZ84u/DDOUaR7eJ+Z6Wox9cedzxZ/7Abwv/SV0ktdh4M8K0bNAyRiyg9Den9wqXQgQNNP2F3YYRNAlG8Bx2bYypcStDIPdAWKOzWjTI3Qxat1ymXJliuUUsx9kCw+ZeJtF/f1usxhHgTYbc4Pgu2OYq5vtDXNhSdcldyxe0MaXlxfGsoqeFcGfkGmD5E+KuVDtTMyMWBczLbJ1MdP5wIsLma0J+cs3HQhUW6DkDiXKVLtFSQIlyDXhw6bDJglX5Nagw+bcdZbwaoEobaDLRIQunDFS1rBwJxOyTCOkB9BRxX6EC8HEt0owsagOk8jVUboESI2HDl+TvT2BQzl79YNw6jv+0py3D1TZ2gTbwjIOXbq+v8qInh2GUSY6cxP6b1rLkaS5QtKEk9dPHWDc3wSW/YoW8s14BPbcDN1tef4m6WZDH3wXVi5wZGk+P5wyJDmhAlFoBo4dZuMqKBWM/DpwrZp1DdpD4x+K4c0FUeXleL0qJFmBt2uOIXQoYfLjdhPYazc2x8l8xEpWZIfJnjmZ4tSTaDZ4kSyQyCY7uOdjnE9r7Ukju0G3ENOU4ckO+DNhzx1HNild8U/+y8vaPhft01pccVj8PMyEXUKY/77x84abdQKDBB1obrU/NMKTQ/5+MbcmOYZliRzJF5ny6FRPp4MNpzOm7fQJ+pU9sGBbps1f0wNjXDkSWNzggzGun+7ctVwwjd8OdCAWXpFHd5GE54XhJ4fEg792Q9cnB8DYD0N/AR3mpEEuIu5ylAP/Gg6PkHgG2Vyv0rThxd0TXOVkSSmnopwCzxMzNEHJ0lems946FCPvAW1Gebg3mOdIxuOn/caKkWvePyJL9bdddsJOIo7VI25rLayt7kk7XRHjycJytftpOL7j4t5yujafuOBh8MWf3D/ueq6whVFsd2nF3YUYPUfCvjeccV027ae5MnoYaHvDGxF63FNne0MdxUD3xnedOFn/ydiOXc2ZLObzCfqytVXk6oq009T2Tvf6jj6UIkMh7d8ii5lvxx60D/Ae5th1n+YzmD/SYwfBO2s+PSITxhuq42p307n5NPEn2fuDt9+N/nn0tbu+qM3Q3hjqG8OVkOHNNnrcjiZen+kNcGzEz74Rt5muN30CXrmup+/1mZP2X64Mg/AE65mqwxnLEWOosmZ4j0+EZrtyaKhS3PU06KPB2Fk0ilBkuJg1hlqoD/sbI9agT3/TUxDSXRzraj9/B9ljTnelXXfYZ7tee2coEtIVvNc9J+ypXxM+NVi3642O3vvw3mfJuKyN8LcB/HD+fugrQVt7Y3iwv2Ebdz0J9RSJhn3v9XiU8SGlfCxHe334ddMbjvBo2Eddz3Gy9l0yzwBhGMdoqkzm2hsDzBnelB8O9Rj2BWvr2LhzYmPobIzOKDKGz56uIM5QcERk0FMl4PErGcvCHpme6oB8LOCXyMnaAd8YZML1FJhXBZkrgFkMWLkSC/JE+nCU93eK/vfAc8LD1z2Rxyhuw/4wSnnWGHgGvoBXBdOAfWR4DtkP4Y3RhxoeqBqCvUffPI02Fjrg0EagawhwgHmBX+Cb8JzP1R1Cv6UPuva8Gt/tRM01FiPPoXVVApuRQvMJdM3TQO+/ut0YC10WbC/GxNovcmbSiKmcma2G9JBtCIjZa6WGdD2w+mm/yINfTBxizTVylMBRkkK1MSUrlNhKKB1KhodOQpGIR74jhZh81XFw5prg3VVKpBO/LFOiWCzlwVJJzefWWv6oU/49MrMTLihfvFL3IO9HXkpO/idzhmbm3Mik65kdWtP8Ja8QoctoOubK+TluSPxooaEMQl8r86un54kyCpSEqTZPiTwlARHN7ChTGGhqi5SIKYHOKSIZIsFz8gBBJLQeqe1BA0WJEnA1N0mXJgUBWE4g88AkIqIkPhkiU7KQKK1KFqpFh1N/Md6sf64KxpY0qVoGSyIYm3+rTnNWOazFlsthnMDW9aDVoAfitfSgLto/twLQuEHhKhUAulJwa/Hvm//T+RF0bL+5HX3KpF98M+kXmUrSj8/L+i+a1zejiBqx+kjrY/8E68PiB1tfww1C4bw+pfXRqBnIg/lhhqVLoNyca39l1qPG4dezTaER4kq0c4ht3oqUaoXZepxUD4M4Ev0AkVAUUlb7JGFQvVjWGAjhpkCodaVAKK/mlgAXKKGdpGdJngZB8QFYjkTKMp1cZ2FK4mrY/B65UjUbugB6GFdO34aknUYN2F3tGqsxa79qPflHbnTPyxSYVsVE3vdOt1nO9UPxU1zqnodUq3oZ+OHXuvSnz+pOYXJmrCHkMcsHXeviphubNFJYr8xlYynw8PXTjZUaDqkIBs74fwwWiG0ywAuCmPnwzKH/N5UKRQq2C/FMaswCHKqouzEz84YghzTxSSSikAeIaqQWaZJoSlCOSogpqydKiO8cDr/q8349HH49G224gabPi4WvH+8yDRWFv5fMF79kPs/VcEzZ0bznFXOz1rB/tKe5uAPhq3VBjr9tVS6rTviQ2lytWpbEM8ItU5ktdZVX80hMg0f63IXGVKU/WaWRqeenH22nP1NpvHz9HiGuevd8hqmKqGz2H2GoDR+Jfe6aZCrg/1JNkmkqSookUhfS0BxTcvtvjYqID1fLJx9fpcJNtwb1NAqp7W6Sc3Hksw1ZTb4WkZN7+dNQ/2eA5VimAmsB9BGwBYjvA2xD6fitrL2a54gkz0m/NkGvZPQcd5TFl54bMvrsk/AmVTqRrJM6t0RJ6OgMyW84iqLAb17hK//M6UgBxQvdXSCxCBPy8I+rHy0Mzd6+Z8kPn/5G/FcqRz+lZ4l+dUiCT/RLIncmr1WOaqfYKWX8q4On6gD5bz1fU0CWv4j6wevhl5FpIHP4/Snb/hc=</diagram></mxfile>
|
||||
|
|
@ -1 +0,0 @@
|
|||
<mxfile host="Electron" modified="2023-02-25T04:22:30.160Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/20.3.0 Chrome/104.0.5112.114 Electron/20.1.3 Safari/537.36" etag="Fg7v1vZiTGKDpKPKZGDF" version="20.3.0" type="device"><diagram id="1WlLurKbbY4VXUe8oHch" name="第 1 页">7RxZe6LK8tfwmHwNNAiPCJowRzCOzmScl/shIIILDqICv/4Um8piYuKS5J6ZeQi9VVfXXtWdELQ4Dx48bTlRXMOcERQyAoKWCIoiScTCj7gnTHsaHJ92WJ5tZJP2HX07MrNOlPWubcNcFSb6rjvz7WWxU3cXC1P3C32a57nb4rSxOyvuutQss9LR17VZtffZNvxJfi6W3w88mrY1ybdmGZyOjDR9annuepFtSFB0m22321w6PNdyYNlJVxPNcLcHXXSLoEXPdf30ax6I5iwmbk63dF37yOgOcc9c+Kcs+POwno9CT56OmL73x1K15d3mLoOy0WZrMz9Ggqwf5hRKjmjGQEiCbm4ntm/2l5oej25BJqBv4s9n2fDYns1Ed+Z6yVra1MZ4jKF/5Xvu1MxHFu4CljerJ8jRMT3fDA66shM9mO7c9L0QpuSjXEbdTPxIvpG2t3tmUo1szuSAj0yDzoQoEyBrB3tPQ/jIyPgGklIXJmlKulw46SqRx+MxpetXJPJOhDMiUyyqEJnk6RoioyvRmK7SuMUQQosQ4IMlOI5oNohWgxCahNBGFfrDuf06IpdId0jnrEub2dYCmjpQ04T+ZkxFG8yJkA3MbcOIt6nl6p7vKAbvLvzMIJLchTiVm62cUw1c4RTPVBlFXYtRuEJ70wD7mzVdz5+4lrvQZq19b3Pf23HdZcYgx/T9MKOWtvbdktkpkRIo6IW/MjonjWHcuGfyphQcDkph1qrqmr72NjtNNQPb/3XwfQAUWnuYcSMHeZSrK3ft6ebrhsTXPMv0X7LhmTbElH1RSDxzpvn2puj56lieLX1ybcB5J1wsWTQDmC5JTYppturQE5UA0Rx3zxRA0SxTBJUSpwIqkcHdic6w0WyNkWZnsVFYLbVFQWLZP+vYRScydrdKhEyACSS9DPaD8GUlP1scwbUS68MQXJvgWaLFEzwmODIzTDxKhgSCb+dbwhHSXTMYdSrT0UYQeRWE/nRb5JmAtzZK4MUyuYzpmlCaaRKMVCulL6lzxSDt4rNsk0KIU2eo7kBtaLYgA3c4E6czxZTGBbAsVwTgjscr8ypCRdZ4pWt7/lED0Vf0/GzJ89PUTnMPPArD1QRYNE3eM8d5d5ZXIfHrlIZwexl/2vMkA9gpR6JIT+7K9m03VpKR6/vuHCbM4oHmLqgvBljwr0bB/Ng9NbXVMs1MxnYQs7aZbCnkvSjvgW9D8zUwH2kTtH5jEVQzAIZT4tOjSv0Om3j0HKz1CNna43ekS+6mQxu0ETK0EjIbfa5vFEfYKiIfGXPdlh8n/uiBibqLyUp7Zryn/jfXePy+7drcBlbRnYUedeZ8+Dvkgu5gynTodJ5sN9FTXw5UZxj3R11pGqjSMIJ+Z/TQjpL9n9XNyJYtYz6bGejbxpSQrYjCVpZaW8XpWcpACFUxHv8Z6tRsM3JgvI8DgLHtPM+mAD9UIgtBm9aevyMN1quSZcsPk5n2bLhG1n5ygu3w13dXfujx8hQF6kBZq7aAVGe6VqJWaDg9qtvHkRr9dtWoRXWcyTPgynQcJVCmVjp/sVTVGCfYT5MsRl0MKVVqyqrz/TnuM+2mr0pC1HFkmCPD2mk4DFGo2phWB7KvDHprNZJhTm/dFRFSbBwpUi9vA+0xo9jCtjPo0R2ntVVFASkiDhTH8rvSjwRPGfbtOMODdg/aPTpel43F+K2Bfzhv7+cKMNZaqw6cb9DCHUdAXVEg4dyBEg0zPIQUj8UwUAY/1t3BEA8HPdRxLCsb3yZw+gjDOkqWmjGsQO1jRnUm7GCgRHAu2FvB6oMVqQNrrbaHoTr47SgiYlQRhzENupIAOP6I19JwRqorWUAfHfCN6aRvAW8MNGG6IsCVgOYi8CwCXtkCDfREymCYz7d28x8B5wSHH0FMj2HUgvNhlOIsU/ANeAGuIiaB96HqWPF5YtwoZSDjviQjOHv405FJda4AH1oIZA0BHwAu4At4xzjnsDoDmLdwQdZ+L0cPW1621fnQsUhFEkBnBF97BllzZJD7H3YnwlyHBt2LcKztFzGbXKPo2hieqhhNzFVtJuauZTAbR+OdOKw5Kd5hId5JAp1KyAPhDCRfItHCRFMk+Dz2iYOgdtIjfNM22kNc6cl3HXln7tkgmhLBk1mSx/O7rRzYKikq3euLgwArPeaRAOtz5INHHFC++UGKw2btAx/VTP4nMH0tc21JRjM1fX2SN/IS1IuJyelyznDFMH5XaTksDNQFB+S18k2Ke0fCWcjx3pF91sRppXzU0FaT3Q5HCf9pMr1qgsYwpXLZtRM0/gP4eLmqwfv4f1gRQGjd6//z8396v487Is2pjX/Wd41PJic43ygv/jfQbaWEeT0PMBeGEN8T7C1pgRkH7I/7nzQf7Pgi6aEOUqucudRb6navkv8wh6qrUV8oISZxSZtZdJo2nwCK4UqgjhSB3sHyWhUgySqHXzUMxaz7hpahLCpVS1EQxoIBq5Wh99kN+k124wwzcarvfgnLz3VxUlPqqnDgeDmerBQ6uRtendRSuaZ0cvzqpKpsnyNUrjfB5/GKbZR5xd/u8qSWVSd4t6+mEKV6IoPq6om3VYiaq4DjClHlwP+xQhTvEhmKquHVTRWirorxxRWi4iFY/NEegnuLQiz+SwpR9hC7t0AfpRDk2eWOItXOvHpna/Ml4nKBLJkp/GEkWz+RqWflbSJZ8uzqxdls2Wcs+yRlSBzmKK9nLJ+InexHspOqviD6y86z2HlunpksFTxPCw8mZK8ajtZBOL70fqX8YLI0v4FenA8fKQYXrW9Q76lv/CcseuMryAxJkvzthSYnYiEwbs9cfbo6L0CuXDoVw2NDM7nxNcNjDpfen9QEXCSqKZ1i9lquva5KlZM6+Vl1FpckOUIczbWvSHKWKUk8i+pS9JsSnXrPM9LbOGDyjQ44f0K6fza6g3L0CWnVANfcJ13GGjOf24OXZDN/eHaqBy/Nv5IHr8ufGwTfTJ4rMPEDUEGslecrv/Esi+LxB2/tdjN9V3jUntQ/9yz9OspxVT5qfdA9amCywLS8Yn3mLVhpwUWegb6oQ8c9RDXEu6SHEDFmMHNNp1yOiz+Dh2D/eojbeAj2VA9xbgXmXR6C59/mIV7xKFfyEPxfD/GaKh+1PnfgInBe98xdBH0RF3FXeq9+RR9R9/snBR9BfW0fweNP6CMaH+4jClb55ZdF7IXt9kXKJ9WoCrElA3riL4W91bCTJP02y17F7M0L6Bv4gvxUf33BcZV9IVsgGap4JfflsoW6O+2CJ6jesH4pT0Ai7hO6ghPemt3q4ejr5r1K29s8HCVRuRZYfux56rtREjVegfTuZ6PQ3P8NjXT6/i+V0K1/AQ==</diagram></mxfile>
|
||||
|
|
@ -1 +0,0 @@
|
|||
<mxfile host="Electron" modified="2022-09-01T02:08:58.162Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="NSFpHFTWZMqKqWBPE-A3" version="13.4.5" type="device"><diagram id="1WlLurKbbY4VXUe8oHch" name="第 1 页">5Vpbd6JIEP41PGYOlwbhkYsmzBGM0Yxr3hAQQQQHUYFfv9UNeINkshNNZnfNQ+jqW/VX1XUDilNX2X1irRdG7LghxdJORnEaxbIMQwvwD1PykiJJnZLgJb5TDToSRn7hVkS6om59x92cDUzjOEz99TnRjqPItdMzmpUk8f582DwOz3ddW57bIIxsK2xSJ76TLupzCdKx48H1vUW9tcCjsmdm2UsvibdRtSHFcj2h1+uJZffKqherTrpZWE68PyFxXYpTkzhOy6dVprohBrfGrZzXe6X3wHjiRul7Jvy8365meaIvZ/wo+emZ1vpud1etsrPCrVsfgzCb5jVC5IguXoShOGW/8FN3tLZs3LsHnQDaIl2FVffcD0M1DuOEzOVca47mCOibNImXbt0TxRFMV6q93SR1s1cPxRygAh1045WbJjkMqSeIFbqV+jG1+u2PwmQ71ZjFiRyFDlcpUaVA3mHtI4bwUMH4DyBlrwxpCV2tnFwT5Pl8ztr2DUE+qHAFMivQDZAZiWuCzNQDrw4y1wD5+w8DCFRXpJQeJSlUt0PJIiUqDfABh7QN4QvcTkGuSFboexE0bcDNBbqCUfXBlshVx8p3HLxNq0iPQqfx8nGUVtaQEa8kptpm1WLqoIaYJL4pJfZWQkIN7F0HjG/VjJN0EXtxZIXdI1U5UvtxvK4EFLhpmldoWds0vrA5F1ACXEn+V4UzaUxx4xtfN7XstFPLq1bzotnbZHe4puVh8Anelg8cON4mtvsGMJXPTK3Ec9O3rDPXLvDEDa3U350z0ia+aupj7AOLB0URmPP7jLgLDSgZq2ZdKMGBjQ9YSKHFRAohvpWbtRWdqYzwc4sdJBHy3YZIWYYBDLfOjp3w5JH/cPvFLqV0qC5PiWAGBKorURKiRIbqCpQoUhJNumRK6tVbwhHKXas12nS2b80g7jnTuvcbg8QFvq0ZWQ/r2RrjSpDmFYrX3rr8VdRTTT7GEqdK9/rVe9VS3MFl4IQzHbhD1dK/q1v1kHg+37g3UZum1ny3dhY29IqMjX5t8ZmGCK/rb0XXtlzhlv4WoW/8mXQ41OJxEWracv5WtpxpCWtakG/eMriScpcMgpvYwc+f4hSu5wRO3UvDKYTYMCiHTOBES3rkd12/wXDvdRzCBx3Hx3SlGZ3dPASedWjuhldSuAiBUUuewaCWPIO5WXTFoF+jDDnnGj/6K5IGH3wU8WeP8cZP/Rj7qlmcpvHqTX2ek1+Ln0vxjVSszbpMz+d+hsWqkC3lmkrXFHh2rNQCL142wfnuPIpVMhA2qz4+mOxLrqDZJNvaBe1bD0+0rcW7PudwTs5zRs7v7JW9MwJ5b6hS4axsX39YpLN7vhhEi4014ZPH0ffYeXjaD3xxB7O4fmQX/ZWUv+RiNhgv+T5XjtN9hX4c6ZkZTDG9GGjLzNSmBdCD2X2vIPtPzN3M1z1nFYYO/X3narRvqPJe17p7Ixh6xljOTRX3/8htNtzNAugfoQzW2Pcn4RLWz43Co6HNWZMn2oL5pub5+v0itCZO7FTtxyDbT/96ivX7oaQv6cwcG1vTl2kzWG6Nops7wZAdjFBhFi+xWXTZfrCYAK98PzAyY+mV46O1aWKeYD9L83gzmrKmpuhm8DTBNNdXUlOTi36gwxgd5i7zaU7npo84c6ynxni4NQsdxgy3A5WmDR8Vhjas24A94g1f3vfHQ64fdPemKtOGijIj8NKB9kz41GHffjA9aQ+hPeTwvKoP87cF+aG6fRwrQ193awZwvnEX9QOZHqgyA+fOjGJa8SGXfETTzBg/bwfjKZqOh3Q/8Lyqf0/WGdEI5rG6puC1MnOEeDNYCOOxUcC5YG8DmfdeYY69rdmb5ub4JTBUmjdVlGMMBpoMPD7juRyckR1oHuBjA78YJ3sPfCPAhB+osK4GmKsgswJk5csc4Ekb42k93juMfwCeCQ/PGcZjWnThfIguedZZeAa+gFcVMSD73Aw8fB7MG2uMdTTSdBrOnv8IdMZcGSCHLg26RoMcYF3gF/jGPNdr9ccwLopB117Ws/u9pPvmahp4jKHJcGfk1JqArgU66P2z3y+Q2Ofg7hUI3/brmEzhPMLkeb5hMpHYtJg17foGk28JYXgcr4gCflDggSMPKk4eDpnD/6aAIKDORdzJs824U/zMEgLTkipimYGQINhEOP6USdqnABHh8BMoEt2Q2XXDDcdyxfmrFbdTyQjXkYwknIcfPMd+dT7QaYk+yoQan/9dObwAOTxJ3htpPJGwrBIJqzhtKPN5nNj3CEXGqd89fndQ7zpLPrgnJDMaJTEkmVEoSTpsFcBW5DXFNzs6KRqUx3ylaPBn2IhXorlX9BS3T5RcIX9kzdSq4kSSIS3d1F7UjfqlBn0lE0RflqakpqKLbXH2zRRd+vxk5pPr+ah2uV9Xz685ekdBvwn/n3HZPqGij4Sm2f/Uij4rNsD/dfXmrGDyG6Wct0syGGrH2ixuUac/vJG+eaH+Y1JpvsVtr4ze2nJ9QWWUZ1ts16dGQqz0BXfiNuXNm94l9t9xl1rq3P8xdy9IX/76nn3/+/vo/+vuO/QXv8BnmyXmdsfSFNK/3rF0Ol/9yo1tqVc1PE3kyPgruCMYZ/b7BGNMf7RS0PuIUNiT9yU18uyrev1rF9CE9gQ4viVj4z/4wrmSHMeclxmFS3mUnqnxMcOvF/rkryK4ZgqEyx4yoiSZFEJESpZbvm9qKYeRwZAl4wcFlzWaBbKyuCGqpMypksGwvkC+lCDrSCweLAmUzL/jHe6fZ5P5K1XeUOdcK+iWeLPtA8PfMMrQPH4OWqrV8aNbrvs3</diagram></mxfile>
|
||||
|
|
@ -1 +0,0 @@
|
|||
<mxfile host="Electron" modified="2022-09-01T02:08:36.651Z" agent="5.0 (Macintosh; Intel Mac OS X 10_16_0) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="rlszdDvRCq1sE68Id5g7" version="13.4.5" type="device"><diagram id="WvAjgkPtNnpgH_JUfW7g" name="第 1 页">7VrZdpvKEv0aHpPF0CB4ZJKNLyDLkqMjvyFADEKgi5AEfP2pZtAEdnwSKck96yYP7q6eqnftqu6iRTDyOn9IrY1vJI4bETTp5ASjEDRNUSQHf7CkqCWCMKgFXho4TaeTYBKUbiMkG+kucNztRccsSaIs2FwK7SSOXTu7kFlpmhwuuy2T6HLVjeW5HcHEtqKudBY4md/uixNODY9u4Pnt0hyL6paFZa+8NNnFzYIEzSy55XLJ181rq52s2enWt5zkcCZiVIKR0yTJ6tI6l90Ig9viVo8bvtN6VDx14+wzAyRtpsx87u3pP+X60VELXnx6/tLsZW9FO7fdRqVsVrQIVVt08SQUwUgHP8jcycaycesBOAEyP1tHTfM2S5PVEUkGJMsgiuQkStJqNgYAom372LNtiZMYJpS6e2q2uXfTzM3PRM0eH9xk7WZpAV2a1iPeDSFprqkfzswrMLXMP7MswzVgWA2lvOPcJ1Sh0AD7D0BmOyA/fTNAQKg8IQ0JQSLUASHyBC91wIdNZ30IX+F2DnIjsqLAi6FqA5QuyCUMYQDEF5uGdeA4eJlek56MTuLpkzhrXJfib2Sm1sFaMw1Qx0wC27VSa92bG4nqMt91IFQ01STN/MRLYitST1LpJNWTZNNYKHSzrGjgsnZZcmm/aywBwrT4qwG6qsxx5SvbVpX8vFEpmlrX0+xduj/66bsm2ia71HY/AqKJwlbqudlH/ZqOGKUPLZ66kZUF+8uA22e/ZuhzEoDOR6Zw1KVDI+aKArWmzagrFhzV+HFitIw7j5HguLxKSANCZQkePJgjVIEQEMFThMoRPE8IZNUkEsKwl1a6tYCD9IIYn3fY1N0GpbWo5sNU2OCtV2CwEsEqVyTD1IjwctLxwDqLx6o4REPUS5gP3aTj6ccjulHs4pTriwBfgOMU3USBn+TIF/4rezkmWS637l34QHXo8GTtLRzCJRGH8zaWUx3D3/Yk5V3bcrl7nqQItag2rscgpnuWItSN0uzdojT3a6L0j0bl6+juWFv/aPG7hWzut4XsnzIm90lPuved9Dd4EqK7151f7EmD/3tSF5XB/6YnDT7pSfG/z5NYpie/+6WexHfvhx3Pih0Rf6w4YXFB5zOIsfzZyuAGGFcSmmQ6wNP/JCX7LkPPcGsh6oPtJ29oTHtyt2ajrrLt2jU7t/jvToSEq4nunA5QPebuuft10wDIGUS16gSpwgCX/+j42+PrV0nFRcj9oQzj0ynpp3NS5o8Ky1Q3V7hzAF4uF4OziHH7AMy132nalEDoC789cYS625cb4fsgb31rg4vBuvocfEytqzT8OdkGWZDgeLtIsixZf0jnZfWvJz3PsENK1nZTf6ZeBjm2qlQtKbZSspVA2bEyi2DEukoPt3uPoKUcbE3Lz48m/VZIaDHLd3ZJBtbjC2kryV5nHMYpWMYo2L29tvdGKB4MWSidtR1oj362eGDLUexvrRmbPk+eEufx5TAK+D2MYvTYLvW1ULwVfD6arlidqftpgUQ+T7TcDOdYXo6UVW4q8xLk4eJhWFbrz8z9ItA8Zx1FDvm0dxUyMGTxoCnqwQjHnjEVC1PG7d8Km472ixDaJyiHOQ76LFrB/IVReiTUGWv2Qlow3lS8QHvwI2vmJE5Tfw7zw/yvl0R7GAvaiszNqbEzA5E0w9XOKNXCCcf0aIJKs3xLzFKl9dCfga6sHhq5sfLq/vHGNLFOsJ6leKwZz2lTkTQzfJlhmRtImamIpR5q0EeDsatiXpCFGSDGnGqZMR3vzFKDPuPdSCZJI0CloYzbOmCPWCMQD/p0zOihejBlkTRklBuhl42U10pPDdbVw/lZfQz1MYPHNW1Yvx3YD7X1U18R2tSdGcL+pirSQ5EcySIF+86Nct7oIdZ6xPPcmL7uRtM5mk/HpB56XtN+qOaZkAjG0Zoi4blyc4JYM/S56dQoYV+wtoHMB680p97OHM4Lc/oWGjLJmjIqMAYjRQQdX/FYBvZIjxQP8LFBX4yTfQC9EWDCjmSYVwHMZbBZCbYKRAbwJI3pvO3vHfs/gs6VDq85xmNeqrA/RNY6azSUQS/QVUYU2L4wQw/vB+tGG1MNTRSNhL0X30KNMtcG2EElgWsk2AHmBX1Bb6xzO5c+hX5xAlx72yweDoIWmOt56FGGIoLPiJk1A66FGvD+NdBLxOsM+F6JsLffJGIOrh4kEOI7EbMVnQfMVnb7U6nvgyZHCDIhyvi6AgWJPH3QvI6l/9oniQF5+SSBqO7RNug52e73JMH0GAqukyyBL5gI3zlFqXpEAiHCNgRJex7f7YrhWC6/fPcF79wu3G3sIgyuHOi3fzuh+55NuShr9n+BPvffXdI2fNlWyIjQgeI2eQVP2w4lr/pbWxi7IlhYxqlC/ciAXxuGlUTEyf0DfjhvV12kP7kmJDAKIVBVAiMRgnBcKoSlqjf6r3bcrgaY1dtsRv+ZEeKdK9w7PMX1M5JL1f9qzsxqLodVVrRyM9tvK+2LPnmjuzV3SXSm79MG33e3vgHRfZ/N0TxJNdeSRK+kiw1K+34e0H2zxvTkMGdBIohVJAL+IlzGFIa0V+xmyH2BrOoM+8MFCROyG9pqWvJydTzJVWeYn6se3qp5hPos4wiR/UTG/Wcw9ZyL7JFKPS9sHXa9HzPZwWXMFLgulW50mEH19CuW+jPL6bdCjPo3</diagram></mxfile>
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -71,6 +71,12 @@ CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细
|
|||
2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
|
||||
3. **Nacos 不仅支持 CP 也支持 AP。**
|
||||
|
||||
**🐛 修正(参见:[issue#1906](https://github.com/Snailclimb/JavaGuide/issues/1906))**:
|
||||
|
||||
ZooKeeper 通过可线性化(Linearizable)写入、全局 FIFO 顺序访问等机制来保障数据一致性。多节点部署的情况下, ZooKeeper 集群处于 Quorum 模式。Quorum 模式下的 ZooKeeper 集群, 是一组 ZooKeeper 服务器节点组成的集合,其中大多数节点必须同意任何变更才能被视为有效。
|
||||
|
||||
由于 Quorum 模式下的读请求不会触发各个 ZooKeeper 节点之间的数据同步,因此在某些情况下还是可能会存在读取到旧数据的情况,导致不同的客户端视图上看到的结果不同,这可能是由于网络延迟、丢包、重传等原因造成的。ZooKeeper 为了解决这个问题,提供了 Watcher 机制和版本号机制来帮助客户端检测数据的变化和版本号的变更,以保证数据的一致性。
|
||||
|
||||
### 总结
|
||||
|
||||
在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
|
||||
|
|
|
|||
|
|
@ -102,7 +102,7 @@ Leader 会向所有的 Follower 周期性发送心跳来保证自己的 Leader
|
|||
|
||||
由于可能同一时刻出现多个 Candidate,导致没有 Candidate 获得大多数选票,如果没有其他手段来重新分配选票的话,那么可能会无限重复下去。
|
||||
|
||||
raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的枚举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
|
||||
raft 使用了随机的选举超时时间来避免上述情况。每一个 Candidate 在发起选举后,都会随机化一个新的选举超时时间,这种机制使得各个服务器能够分散开来,在大多数情况下只有一个服务器会率先超时;它会在其他服务器超时之前赢得选举。
|
||||
|
||||
## 4 日志复制
|
||||
|
||||
|
|
@ -119,7 +119,7 @@ raft 保证以下两个性质:
|
|||
- 在两个日志里,有两个 entry 拥有相同的 index 和 term,那么它们一定有相同的 cmd
|
||||
- 在两个日志里,有两个 entry 拥有相同的 index 和 term,那么它们前面的 entry 也一定相同
|
||||
|
||||
通过“仅有 Leader 可以生存 entry”来保证第一个性质,第二个性质需要一致性检查来进行保证。
|
||||
通过“仅有 Leader 可以生成 entry”来保证第一个性质,第二个性质需要一致性检查来进行保证。
|
||||
|
||||
一般情况下,Leader 和 Follower 的日志保持一致,然后,Leader 的崩溃会导致日志不一样,这样一致性检查会产生失败。Leader 通过强制 Follower 复制自己的日志来处理日志的不一致。这就意味着,在 Follower 上的冲突日志会被领导者的日志覆盖。
|
||||
|
||||
|
|
|
|||
|
|
@ -135,4 +135,4 @@ CPU 缓存是通过将最近使用的数据存储在高速缓存中来实现更
|
|||
## 参考
|
||||
|
||||
- Disruptor 高性能之道-等待策略:<http://wuwenliang.net/2022/02/28/Disruptor高性能之道-等待策略/>
|
||||
- 《Java 并发编程实战》- 40 | 案例分析(三):高性能队列 Disruptor:https://time.geekbang.org/column/article/98134
|
||||
- 《Java 并发编程实战》- 40 | 案例分析(三):高性能队列 Disruptor:<https://time.geekbang.org/column/article/98134>
|
||||
|
|
|
|||
|
|
@ -65,6 +65,7 @@ title: JavaGuide(Java学习&面试指南)
|
|||
- [HashMap 核心源码+底层数据结构分析](./java/collection/hashmap-source-code.md)
|
||||
- [ConcurrentHashMap 核心源码+底层数据结构分析](./java/collection/concurrent-hash-map-source-code.md)
|
||||
- [CopyOnWriteArrayList 核心源码分析](./java/collection/copyonwritearraylist-source-code.md)
|
||||
- [ArrayBlockingQueue 核心源码分析](./java/collection/arrayblockingqueue-source-code.md)
|
||||
|
||||
### IO
|
||||
|
||||
|
|
@ -350,7 +351,8 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
|
|||
|
||||
### 分布式锁
|
||||
|
||||
[分布式锁常见知识点&面试题总结](./distributed-system/distributed-lock.md)
|
||||
- [分布式锁介绍](https://javaguide.cn/distributed-system/distributed-lock.html)
|
||||
- [分布式锁常见实现方案总结](https://javaguide.cn/distributed-system/distributed-lock-implementations.html)
|
||||
|
||||
### 分布式事务
|
||||
|
||||
|
|
|
|||
|
|
@ -105,7 +105,7 @@ icon: jianli
|
|||
|
||||
### 实习经历/工作经历(重要)
|
||||
|
||||
工作经历针对社招,实际经历针对校招。
|
||||
工作经历针对社招,实习经历针对校招。
|
||||
|
||||
工作经历建议采用时间倒序的方式来介绍。实习经历和工作经历都需要简单突出介绍自己在职期间主要做了什么。
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,773 @@
|
|||
---
|
||||
title: ArrayBlockingQueue 源码分析
|
||||
category: Java
|
||||
tag:
|
||||
- Java集合
|
||||
---
|
||||
|
||||
## 阻塞队列简介
|
||||
|
||||
### 阻塞队列的历史
|
||||
|
||||
Java 阻塞队列的历史可以追溯到 JDK1.5 版本,当时 Java 平台增加了 `java.util.concurrent`,即我们常说的 JUC 包,其中包含了各种并发流程控制工具、并发容器、原子类等。这其中自然也包含了我们这篇文章所讨论的阻塞队列。
|
||||
|
||||
为了解决高并发场景下多线程之间数据共享的问题,JDK1.5 版本中出现了 `ArrayBlockingQueue` 和 `LinkedBlockingQueue`,它们是带有生产者-消费者模式实现的并发容器。其中,`ArrayBlockingQueue` 是有界队列,即添加的元素达到上限之后,再次添加就会被阻塞或者抛出异常。而 `LinkedBlockingQueue` 则由链表构成的队列,正是因为链表的特性,所以 `LinkedBlockingQueue` 在添加元素上并不会向 `ArrayBlockingQueue` 那样有着较多的约束,所以 `LinkedBlockingQueue` 设置队列是否有界是可选的(注意这里的无界并不是指可以添加任务数量的元素,而是说队列的大小默认为 `Integer.MAX_VALUE`,近乎于无限大)。
|
||||
|
||||
随着 Java 的不断发展,JDK 后续的几个版本又对阻塞队列进行了不少的更新和完善:
|
||||
|
||||
1. JDK1.6 版本:增加 `SynchronousQueue`,一个不存储元素的阻塞队列。
|
||||
2. JDK1.7 版本:增加 `TransferQueue`,一个支持更多操作的阻塞队列。
|
||||
3. JDK1.8 版本:增加 `DelayQueue`,一个支持延迟获取元素的阻塞队列。
|
||||
|
||||
### 阻塞队列的思想
|
||||
|
||||
阻塞队列就是典型的生产者-消费者模型,它可以做到以下几点:
|
||||
|
||||
1. 当阻塞队列数据为空时,所有的消费者线程都会被阻塞,等待队列非空。
|
||||
2. 当生产者往队列里填充数据后,队列就会通知消费者队列非空,消费者此时就可以进来消费。
|
||||
3. 当阻塞队列因为消费者消费过慢或者生产者存放元素过快导致队列填满时无法容纳新元素时,生产者就会被阻塞,等待队列非满时继续存放元素。
|
||||
4. 当消费者从队列中消费一个元素之后,队列就会通知生产者队列非满,生产者可以继续填充数据了。
|
||||
|
||||
总结一下:阻塞队列就说基于非空和非满两个条件实现生产者和消费者之间的交互,尽管这些交互流程和等待通知的机制实现非常复杂,好在 Doug Lea 的操刀之下已将阻塞队列的细节屏蔽,我们只需调用 `put`、`take`、`offfer`、`poll` 等 API 即可实现多线程之间的生产和消费。
|
||||
|
||||
这也使得阻塞队列在多线程开发中有着广泛的运用,最常见的例子无非是我们的线程池,从源码中我们就能看出当核心线程无法及时处理任务时,这些任务都会扔到 `workQueue` 中。
|
||||
|
||||
```java
|
||||
public ThreadPoolExecutor(int corePoolSize,
|
||||
int maximumPoolSize,
|
||||
long keepAliveTime,
|
||||
TimeUnit unit,
|
||||
BlockingQueue<Runnable> workQueue,
|
||||
ThreadFactory threadFactory,
|
||||
RejectedExecutionHandler handler) {// ...}
|
||||
```
|
||||
|
||||
## ArrayBlockingQueue 常见方法及测试
|
||||
|
||||
简单了解了阻塞队列的历史之后,我们就开始重点讨论本篇文章所要介绍的并发容器——`ArrayBlockingQueue`。为了后续更加深入的了解 `ArrayBlockingQueue`,我们不妨基于下面几个实例了解以下 `ArrayBlockingQueue` 的使用。
|
||||
|
||||
先看看第一个例子,我们这里会用两个线程分别模拟生产者和消费者,生产者生产完会使用 `put` 方法生产 10 个元素给消费者进行消费,当队列元素达到我们设置的上限 5 时,`put` 方法就会阻塞。
|
||||
同理消费者也会通过 `take` 方法消费元素,当队列为空时,`take` 方法就会阻塞消费者线程。这里笔者为了保证消费者能够在消费完 10 个元素后及时退出。便通过倒计时门闩,来控制消费者结束,生产者在这里只会生产 10 个元素。当消费者将 10 个元素消费完成之后,按下倒计时门闩,所有线程都会停止。
|
||||
|
||||
```java
|
||||
public class ProducerConsumerExample {
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
|
||||
// 创建一个大小为 5 的 ArrayBlockingQueue
|
||||
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
// 创建生产者线程
|
||||
Thread producer = new Thread(() -> {
|
||||
try {
|
||||
for (int i = 1; i <= 10; i++) {
|
||||
// 向队列中添加元素,如果队列已满则阻塞等待
|
||||
queue.put(i);
|
||||
System.out.println("生产者添加元素:" + i);
|
||||
}
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
});
|
||||
|
||||
CountDownLatch countDownLatch = new CountDownLatch(1);
|
||||
|
||||
// 创建消费者线程
|
||||
Thread consumer = new Thread(() -> {
|
||||
try {
|
||||
int count = 0;
|
||||
while (true) {
|
||||
|
||||
// 从队列中取出元素,如果队列为空则阻塞等待
|
||||
int element = queue.take();
|
||||
System.out.println("消费者取出元素:" + element);
|
||||
++count;
|
||||
if (count == 10) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
countDownLatch.countDown();
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
});
|
||||
|
||||
// 启动线程
|
||||
producer.start();
|
||||
consumer.start();
|
||||
|
||||
// 等待线程结束
|
||||
producer.join();
|
||||
consumer.join();
|
||||
|
||||
countDownLatch.await();
|
||||
|
||||
producer.interrupt();
|
||||
consumer.interrupt();
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
代码输出结果如下,可以看到只有生产者往队列中投放元素之后消费者才能消费,这也就意味着当队列中没有数据的时消费者就会阻塞,等待队列非空再继续消费。
|
||||
|
||||
```cpp
|
||||
生产者添加元素:1
|
||||
生产者添加元素:2
|
||||
消费者取出元素:1
|
||||
消费者取出元素:2
|
||||
消费者取出元素:3
|
||||
生产者添加元素:3
|
||||
生产者添加元素:4
|
||||
生产者添加元素:5
|
||||
消费者取出元素:4
|
||||
生产者添加元素:6
|
||||
消费者取出元素:5
|
||||
生产者添加元素:7
|
||||
生产者添加元素:8
|
||||
生产者添加元素:9
|
||||
生产者添加元素:10
|
||||
消费者取出元素:6
|
||||
消费者取出元素:7
|
||||
消费者取出元素:8
|
||||
消费者取出元素:9
|
||||
消费者取出元素:10
|
||||
```
|
||||
|
||||
了解了 `put`、`take` 这两个会阻塞的存和取方法之后,我我们再来看看阻塞队列中非阻塞的入队和出队方法 `offer` 和 `poll`。
|
||||
|
||||
如下所示,我们设置了一个大小为 3 的阻塞队列,我们会尝试在队列用 offer 方法存放 4 个元素,然后再从队列中用 `poll` 尝试取 4 次。
|
||||
|
||||
```cpp
|
||||
public class OfferPollExample {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 创建一个大小为 3 的 ArrayBlockingQueue
|
||||
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
|
||||
|
||||
// 向队列中添加元素
|
||||
System.out.println(queue.offer("A"));
|
||||
System.out.println(queue.offer("B"));
|
||||
System.out.println(queue.offer("C"));
|
||||
|
||||
// 尝试向队列中添加元素,但队列已满,返回 false
|
||||
System.out.println(queue.offer("D"));
|
||||
|
||||
// 从队列中取出元素
|
||||
System.out.println(queue.poll());
|
||||
System.out.println(queue.poll());
|
||||
System.out.println(queue.poll());
|
||||
|
||||
// 尝试从队列中取出元素,但队列已空,返回 null
|
||||
System.out.println(queue.poll());
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
最终代码的输出结果如下,可以看到因为队列的大小为 3 的缘故,我们前 3 次存放到队列的结果为 true,第 4 次存放时,由于队列已满,所以存放结果返回 false。这也是为什么我们后续的 `poll` 方法只得到了 3 个元素的值。
|
||||
|
||||
```cpp
|
||||
true
|
||||
true
|
||||
true
|
||||
false
|
||||
A
|
||||
B
|
||||
C
|
||||
null
|
||||
```
|
||||
|
||||
了解了阻塞存取和非阻塞存取,我们再来看看阻塞队列的一个比较特殊的操作,某些场景下,我们希望能够一次性将阻塞队列的结果存到列表中再进行批量操作,我们就可以使用阻塞队列的 `drainTo` 方法,这个方法会一次性将队列中所有元素存放到列表,如果队列中有元素,且成功存到 list 中则 `drainTo` 会返回本次转移到 list 中的元素数,反之若队列为空,`drainTo` 则直接返回 0。
|
||||
|
||||
```java
|
||||
public class DrainToExample {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// 创建一个大小为 5 的 ArrayBlockingQueue
|
||||
ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<>(5);
|
||||
|
||||
// 向队列中添加元素
|
||||
queue.add(1);
|
||||
queue.add(2);
|
||||
queue.add(3);
|
||||
queue.add(4);
|
||||
queue.add(5);
|
||||
|
||||
// 创建一个 List,用于存储从队列中取出的元素
|
||||
List<Integer> list = new ArrayList<>();
|
||||
|
||||
// 从队列中取出所有元素,并添加到 List 中
|
||||
queue.drainTo(list);
|
||||
|
||||
// 输出 List 中的元素
|
||||
System.out.println(list);
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
代码输出结果如下
|
||||
|
||||
```cpp
|
||||
[1, 2, 3, 4, 5]
|
||||
```
|
||||
|
||||
## ArrayBlockingQueue 源码分析
|
||||
|
||||
自此我们对阻塞队列的使用有了基本的印象,接下来我们就可以进一步了解一下 `ArrayBlockingQueue` 的工作机制了。
|
||||
|
||||
### 整体设计
|
||||
|
||||
在了解 `ArrayBlockingQueue` 的具体细节之前,我们先来看看 `ArrayBlockingQueue` 的类图。
|
||||
|
||||
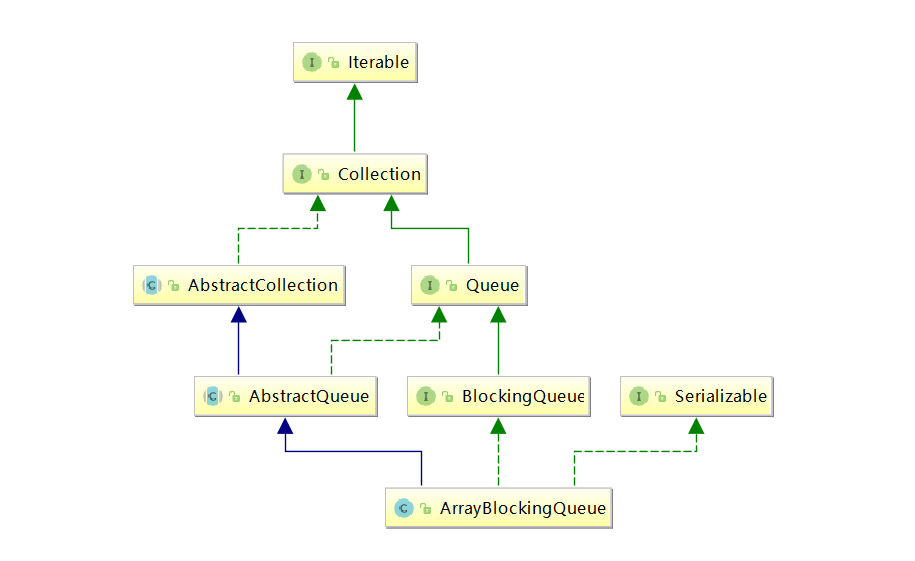
|
||||
|
||||
从图中我们可以看出,`ArrayBlockingQueue` 继承了阻塞队列 `BlockingQueue` 这个接口,不难猜出通过继承 `BlockingQueue` 这个接口之后,`ArrayBlockingQueue` 就拥有了阻塞队列那些常见的操作行为。
|
||||
|
||||
同时, `ArrayBlockingQueue` 还继承了 `AbstractQueue` 这个抽象类,这个继承了 `AbstractCollection` 和 `Queue` 的抽象类,从抽象类的特定和语义我们也可以猜出,这个继承关系使得 `ArrayBlockingQueue` 拥有了队列的常见操作。
|
||||
|
||||
所以我们是否可以得出这样一个结论,通过继承 `AbstractQueue` 获得队列所有的操作模板,其实现的入队和出队操作的整体框架。然后 `ArrayBlockingQueue` 通过继承 `BlockingQueue` 获取到阻塞队列的常见操作并将这些操作实现,填充到 `AbstractQueue` 模板方法的细节中,由此 `ArrayBlockingQueue` 成为一个完整的阻塞队列。
|
||||
|
||||
为了印证这一点,我们到源码中一探究竟。首先我们先来看看 `AbstractQueue`,从类的继承关系我们可以大致得出,它通过 `AbstractCollection` 获得了集合的常见操作方法,然后通过 `Queue` 接口获得了队列的特性。
|
||||
|
||||
```java
|
||||
public abstract class AbstractQueue<E>
|
||||
extends AbstractCollection<E>
|
||||
implements Queue<E> {
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
对于集合的操作无非是增删改查,所以我们不妨从添加方法入手,从源码中我们可以看到,它实现了 `AbstractCollection` 的 `add` 方法,其内部逻辑如下:
|
||||
|
||||
1. 调用继承 `Queue` 接口的来的 `offer` 方法,如果 `offer` 成功则返回 `true`。
|
||||
2. 如果 `offer` 失败,即代表当前元素入队失败直接抛异常。
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
```
|
||||
|
||||
而 `AbstractQueue` 中并没有对 `Queue` 的 `offer` 的实现,很明显这样做的目的是定义好了 `add` 的核心逻辑,将 `offer` 的细节交由其子类即我们的 `ArrayBlockingQueue` 实现。
|
||||
|
||||
到此,我们对于抽象类 `AbstractQueue` 的分析就结束了,我们继续看看 `ArrayBlockingQueue` 中另一个重要的继承接口 `BlockingQueue`。
|
||||
|
||||
点开 `BlockingQueue` 之后,我们可以看到这个接口同样继承了 `Queue` 接口,这就意味着它也具备了队列所拥有的所有行为。同时,它还定义了自己所需要实现的方法。
|
||||
|
||||
```java
|
||||
public interface BlockingQueue<E> extends Queue<E> {
|
||||
|
||||
//元素入队成功返回true,反之则会抛出异常IllegalStateException
|
||||
boolean add(E e);
|
||||
|
||||
//元素入队成功返回true,反之返回false
|
||||
boolean offer(E e);
|
||||
|
||||
//元素入队成功则直接返回,如果队列已满元素不可入队则将线程阻塞,因为阻塞期间可能会被打断,所以这里方法签名抛出了InterruptedException
|
||||
void put(E e) throws InterruptedException;
|
||||
|
||||
//和上一个方法一样,只不过队列满时只会阻塞单位为unit,时间为timeout的时长,如果在等待时长内没有入队成功则直接返回false。
|
||||
boolean offer(E e, long timeout, TimeUnit unit)
|
||||
throws InterruptedException;
|
||||
|
||||
//从队头取出一个元素,如果队列为空则阻塞等待,因为会阻塞线程的缘故,所以该方法可能会被打断,所以签名定义了InterruptedException
|
||||
E take() throws InterruptedException;
|
||||
|
||||
//取出队头的元素并返回,如果当前队列为空则阻塞等待timeout且单位为unit的时长,如果这个时间段没有元素则直接返回null。
|
||||
E poll(long timeout, TimeUnit unit)
|
||||
throws InterruptedException;
|
||||
|
||||
//获取队列剩余元素个数
|
||||
int remainingCapacity();
|
||||
|
||||
//删除我们指定的对象,如果成功返回true,反之返回false。
|
||||
boolean remove(Object o);
|
||||
|
||||
//判断队列中是否包含指定元素
|
||||
public boolean contains(Object o);
|
||||
|
||||
//将队列中的元素全部存到指定的集合中
|
||||
int drainTo(Collection<? super E> c);
|
||||
|
||||
//转移maxElements个元素到集合中
|
||||
int drainTo(Collection<? super E> c, int maxElements);
|
||||
}
|
||||
```
|
||||
|
||||
了解了 `BlockingQueue` 的常见操作后,我们就知道了 `ArrayBlockingQueue` 通过继承 `BlockingQueue` 的方法并实现后,填充到 `AbstractQueue` 的方法上,由此我们便知道了上文中 `AbstractQueue` 的 `add` 方法的 `offer` 方法是哪里是实现的了。
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
//AbstractQueue的offer来自下层的ArrayBlockingQueue从BlockingQueue继承并实现的offer方法
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
```
|
||||
|
||||
### 初始化
|
||||
|
||||
了解 `ArrayBlockingQueue` 的细节前,我们不妨先看看其构造函数,了解一下其初始化过程。从源码中我们可以看出 `ArrayBlockingQueue` 有 3 个构造方法,而最核心的构造方法就是下方这一个。
|
||||
|
||||
```java
|
||||
// capacity 表示队列初始容量,fair 表示 锁的公平性
|
||||
public ArrayBlockingQueue(int capacity, boolean fair) {
|
||||
//如果设置的队列大小小于0,则直接抛出IllegalArgumentException
|
||||
if (capacity <= 0)
|
||||
throw new IllegalArgumentException();
|
||||
//初始化一个数组用于存放队列的元素
|
||||
this.items = new Object[capacity];
|
||||
//创建阻塞队列流程控制的锁
|
||||
lock = new ReentrantLock(fair);
|
||||
//用lock锁创建两个条件控制队列生产和消费
|
||||
notEmpty = lock.newCondition();
|
||||
notFull = lock.newCondition();
|
||||
}
|
||||
```
|
||||
|
||||
这个构造方法里面有两个比较核心的成员变量 `notEmpty`(非空) 和 `notFull` (非满) ,需要我们格外留意,它们是实现生产者和消费者有序工作的关键所在,这一点笔者会在后续的源码解析中详细说明,这里我们只需初步了解一下阻塞队列的构造即可。
|
||||
|
||||
另外两个构造方法都是基于上述的构造方法,默认情况下,我们会使用下面这个构造方法,该构造方法就意味着 `ArrayBlockingQueue` 用的是非公平锁,即各个生产者或者消费者线程收到通知后,对于锁的争抢是随机的。
|
||||
|
||||
```java
|
||||
public ArrayBlockingQueue(int capacity) {
|
||||
this(capacity, false);
|
||||
}
|
||||
```
|
||||
|
||||
还有一个不怎么常用的构造方法,在初始化容量和锁的非公平性之后,它还提供了一个 `Collection` 参数,从源码中不难看出这个构造方法是将外部传入的集合的元素在初始化时直接存放到阻塞队列中。
|
||||
|
||||
```java
|
||||
public ArrayBlockingQueue(int capacity, boolean fair,
|
||||
Collection<? extends E> c) {
|
||||
//初始化容量和锁的公平性
|
||||
this(capacity, fair);
|
||||
|
||||
final ReentrantLock lock = this.lock;
|
||||
//上锁并将c中的元素存放到ArrayBlockingQueue底层的数组中
|
||||
lock.lock();
|
||||
try {
|
||||
int i = 0;
|
||||
try {
|
||||
//遍历并添加元素到数组中
|
||||
for (E e : c) {
|
||||
checkNotNull(e);
|
||||
items[i++] = e;
|
||||
}
|
||||
} catch (ArrayIndexOutOfBoundsException ex) {
|
||||
throw new IllegalArgumentException();
|
||||
}
|
||||
//记录当前队列容量
|
||||
count = i;
|
||||
//更新下一次put或者offer或用add方法添加到队列底层数组的位置
|
||||
putIndex = (i == capacity) ? 0 : i;
|
||||
} finally {
|
||||
//完成遍历后释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 阻塞式获取和新增元素
|
||||
|
||||
`ArrayBlockingQueue` 阻塞式获取和新增元素对应的就是生产者-消费者模型,虽然它也支持非阻塞式获取和新增元素(例如 `poll()` 和 `offer(E e)` 方法,后文会介绍到),但一般不会使用。
|
||||
|
||||
`ArrayBlockingQueue` 阻塞式获取和新增元素的方法为:
|
||||
|
||||
- `put(E e)`:将元素插入队列中,如果队列已满,则该方法会一直阻塞,直到队列有空间可用或者线程被中断。
|
||||
- `take()` :获取并移除队列头部的元素,如果队列为空,则该方法会一直阻塞,直到队列非空或者线程被中断。
|
||||
|
||||
这两个方法实现的关键就是在于两个条件对象 `notEmpty`(非空) 和 `notFull` (非满),这个我们在上文的构造方法中有提到。
|
||||
|
||||
接下来笔者就通过两张图让大家了解一下这两个条件是如何在阻塞队列中运用的。
|
||||
|
||||
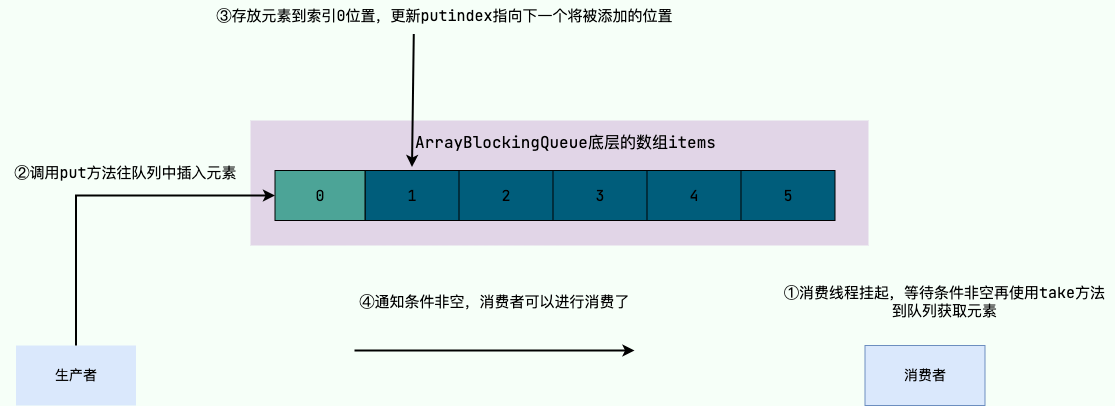
|
||||
|
||||
假设我们的代码消费者先启动,当它发现队列中没有数据,那么非空条件就会将这个线程挂起,即等待条件非空时挂起。然后 CPU 执行权到达生产者,生产者发现队列中可以存放数据,于是将数据存放进去,通知此时条件非空,此时消费者就会被唤醒到队列中使用 `take` 等方法获取值了。
|
||||
|
||||
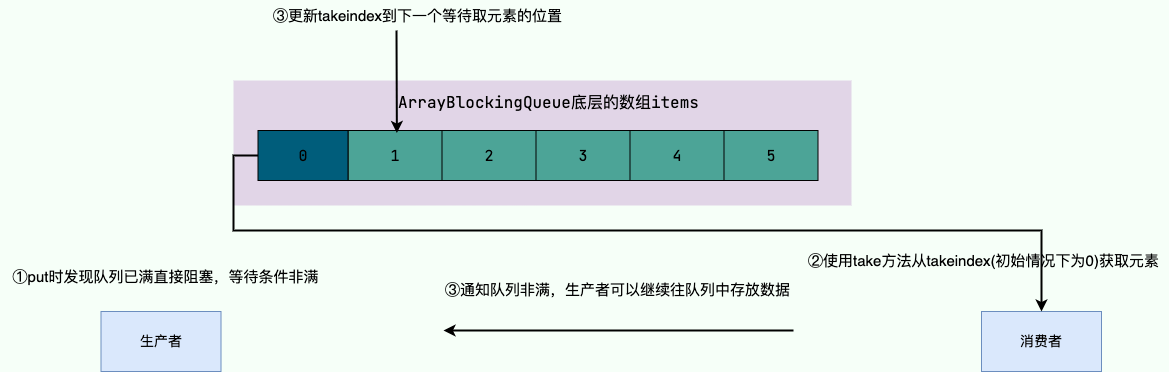
|
||||
|
||||
随后的执行中,生产者生产速度远远大于消费者消费速度,于是生产者将队列塞满后再次尝试将数据存入队列,发现队列已满,于是阻塞队列就将当前线程挂起,等待非满。然后消费者拿着 CPU 执行权进行消费,于是队列可以存放新数据了,发出一个非满的通知,此时挂起的生产者就会等待 CPU 执行权到来时再次尝试将数据存到队列中。
|
||||
|
||||
简单了解阻塞队列的基于两个条件的交互流程之后,我们不妨看看 `put` 和 `take` 方法的源码。
|
||||
|
||||
```java
|
||||
public void put(E e) throws InterruptedException {
|
||||
//确保插入的元素不为null
|
||||
checkNotNull(e);
|
||||
//加锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
//这里使用lockInterruptibly()方法而不是lock()方法是为了能够响应中断操作,如果在等待获取锁的过程中被打断则该方法会抛出InterruptedException异常。
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//如果count等数组长度则说明队列已满,当前线程将被挂起放到AQS队列中,等待队列非满时插入(非满条件)。
|
||||
//在等待期间,锁会被释放,其他线程可以继续对队列进行操作。
|
||||
while (count == items.length)
|
||||
notFull.await();
|
||||
//如果队列可以存放元素,则调用enqueue将元素入队
|
||||
enqueue(e);
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`put`方法内部调用了 `enqueue` 方法来实现元素入队,我们继续深入查看一下 `enqueue` 方法的实现细节:
|
||||
|
||||
```java
|
||||
private void enqueue(E x) {
|
||||
//获取队列底层的数组
|
||||
final Object[] items = this.items;
|
||||
//将putindex位置的值设置为我们传入的x
|
||||
items[putIndex] = x;
|
||||
//更新putindex,如果putindex等于数组长度,则更新为0
|
||||
if (++putIndex == items.length)
|
||||
putIndex = 0;
|
||||
//队列长度+1
|
||||
count++;
|
||||
//通知队列非空,那些因为获取元素而阻塞的线程可以继续工作了
|
||||
notEmpty.signal();
|
||||
}
|
||||
```
|
||||
|
||||
从源码中可以看到入队操作的逻辑就是在数组中追加一个新元素,整体执行步骤为:
|
||||
|
||||
1. 获取 `ArrayBlockingQueue` 底层的数组 `items`。
|
||||
2. 将元素存到 `putIndex` 位置。
|
||||
3. 更新 `putIndex` 到下一个位置,如果 `putIndex` 等于队列长度,则说明 `putIndex` 已经到达数组末尾了,下一次插入则需要 0 开始。(`ArrayBlockingQueue` 用到了循环队列的思想,即从头到尾循环复用一个数组)
|
||||
4. 更新 `count` 的值,表示当前队列长度+1。
|
||||
5. 调用 `notEmpty.signal()` 通知队列非空,消费者可以从队列中获取值了。
|
||||
|
||||
自此我们了解了 `put` 方法的流程,为了更加完整的了解 `ArrayBlockingQueue` 关于生产者-消费者模型的设计,我们继续看看阻塞获取队列元素的 `take` 方法。
|
||||
|
||||
```java
|
||||
public E take() throws InterruptedException {
|
||||
//获取锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//如果队列中元素个数为0,则将当前线程打断并存入AQS队列中,等待队列非空时获取并移除元素(非空条件)
|
||||
while (count == 0)
|
||||
notEmpty.await();
|
||||
//如果队列不为空则调用dequeue获取元素
|
||||
return dequeue();
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
理解了 `put` 方法再看`take` 方法就很简单了,其核心逻辑和`put` 方法正好是相反的,比如`put` 方法在队列满的时候等待队列非满时插入元素(非满条件),而`take` 方法等待队列非空时获取并移除元素(非空条件)。
|
||||
|
||||
`take`方法内部调用了 `dequeue` 方法来实现元素出队,其核心逻辑和 `enqueue` 方法也是相反的。
|
||||
|
||||
```java
|
||||
private E dequeue() {
|
||||
//获取阻塞队列底层的数组
|
||||
final Object[] items = this.items;
|
||||
@SuppressWarnings("unchecked")
|
||||
//从队列中获取takeIndex位置的元素
|
||||
E x = (E) items[takeIndex];
|
||||
//将takeIndex置空
|
||||
items[takeIndex] = null;
|
||||
//takeIndex向后挪动,如果等于数组长度则更新为0
|
||||
if (++takeIndex == items.length)
|
||||
takeIndex = 0;
|
||||
//队列长度减1
|
||||
count--;
|
||||
if (itrs != null)
|
||||
itrs.elementDequeued();
|
||||
//通知那些被打断的线程当前队列状态非满,可以继续存放元素
|
||||
notFull.signal();
|
||||
return x;
|
||||
}
|
||||
```
|
||||
|
||||
由于`dequeue` 方法(出队)和上面介绍的 `enqueue` 方法(入队)的步骤大致类似,这里就不重复介绍了。
|
||||
|
||||
为了帮助理解,我专门画了一张图来展示 `notEmpty`(非空) 和 `notFull` (非满)这两个条件对象是如何控制 `ArrayBlockingQueue` 的存和取的。
|
||||
|
||||
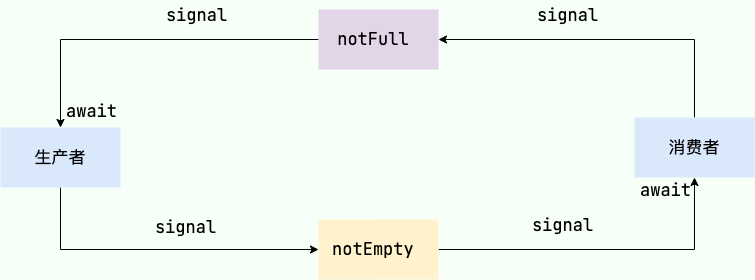
|
||||
|
||||
- **消费者**:当消费者从队列中 `take` 或者 `poll` 等操作取出一个元素之后,就会通知队列非满,此时那些等待非满的生产者就会被唤醒等待获取 CPU 时间片进行入队操作。
|
||||
- **生产者**:当生产者将元素存到队列中后,就会触发通知队列非空,此时消费者就会被唤醒等待 CPU 时间片尝试获取元素。如此往复,两个条件对象就构成一个环路,控制着多线程之间的存和取。
|
||||
|
||||
### 非阻塞式获取和新增元素
|
||||
|
||||
`ArrayBlockingQueue` 非阻塞式获取和新增元素的方法为:
|
||||
|
||||
- `offer(E e)`:将元素插入队列尾部。如果队列已满,则该方法会直接返回 false,不会等待并阻塞线程。
|
||||
- `poll()`:获取并移除队列头部的元素,如果队列为空,则该方法会直接返回 null,不会等待并阻塞线程。
|
||||
- `add(E e)`:将元素插入队列尾部。如果队列已满则会抛出 `IllegalStateException` 异常,底层基于 `offer(E e)` 方法。
|
||||
- `remove()`:移除队列头部的元素,如果队列为空则会抛出 `NoSuchElementException` 异常,底层基于 `poll()`。
|
||||
- `peek()`:获取但不移除队列头部的元素,如果队列为空,则该方法会直接返回 null,不会等待并阻塞线程。
|
||||
|
||||
先来看看 `offer` 方法,逻辑和 `put` 差不多,唯一的区别就是入队失败时不会阻塞当前线程,而是直接返回 `false`。
|
||||
|
||||
```java
|
||||
public boolean offer(E e) {
|
||||
//确保插入的元素不为null
|
||||
checkNotNull(e);
|
||||
//获取锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();
|
||||
try {
|
||||
//队列已满直接返回false
|
||||
if (count == items.length)
|
||||
return false;
|
||||
else {
|
||||
//反之将元素入队并直接返回true
|
||||
enqueue(e);
|
||||
return true;
|
||||
}
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`poll` 方法同理,获取元素失败也是直接返回空,并不会阻塞获取元素的线程。
|
||||
|
||||
```java
|
||||
public E poll() {
|
||||
final ReentrantLock lock = this.lock;
|
||||
//上锁
|
||||
lock.lock();
|
||||
try {
|
||||
//如果队列为空直接返回null,反之出队返回元素值
|
||||
return (count == 0) ? null : dequeue();
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`add` 方法其实就是对于 `offer` 做了一层封装,如下代码所示,可以看到 `add` 会调用没有规定时间的 `offer`,如果入队失败则直接抛异常。
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
//调用下方的add
|
||||
return super.add(e);
|
||||
}
|
||||
|
||||
|
||||
public boolean add(E e) {
|
||||
//调用offer如果失败直接抛出异常
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
throw new IllegalStateException("Queue full");
|
||||
}
|
||||
```
|
||||
|
||||
`remove` 方法同理,调用 `poll`,如果返回 `null` 则说明队列没有元素,直接抛出异常。
|
||||
|
||||
```java
|
||||
public E remove() {
|
||||
E x = poll();
|
||||
if (x != null)
|
||||
return x;
|
||||
else
|
||||
throw new NoSuchElementException();
|
||||
}
|
||||
```
|
||||
|
||||
`peek()` 方法的逻辑也很简单,内部调用了 `itemAt` 方法。
|
||||
|
||||
```java
|
||||
public E peek() {
|
||||
//加锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();
|
||||
try {
|
||||
//当队列为空时返回 null
|
||||
return itemAt(takeIndex);
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
//返回队列中指定位置的元素
|
||||
@SuppressWarnings("unchecked")
|
||||
final E itemAt(int i) {
|
||||
return (E) items[i];
|
||||
}
|
||||
```
|
||||
|
||||
### 指定超时时间内阻塞式获取和新增元素
|
||||
|
||||
在 `offer(E e)` 和 `poll()` 非阻塞获取和新增元素的基础上,设计者提供了带有等待时间的 `offer(E e, long timeout, TimeUnit unit)` 和 `poll(long timeout, TimeUnit unit)` ,用于在指定的超时时间内阻塞式地添加和获取元素。
|
||||
|
||||
```java
|
||||
public boolean offer(E e, long timeout, TimeUnit unit)
|
||||
throws InterruptedException {
|
||||
|
||||
checkNotNull(e);
|
||||
long nanos = unit.toNanos(timeout);
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//队列已满,进入循环
|
||||
while (count == items.length) {
|
||||
//时间到了队列还是满的,则直接返回false
|
||||
if (nanos <= 0)
|
||||
return false;
|
||||
//阻塞nanos时间,等待非满
|
||||
nanos = notFull.awaitNanos(nanos);
|
||||
}
|
||||
enqueue(e);
|
||||
return true;
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,带有超时时间的 `offer` 方法在队列已满的情况下,会等待用户所传的时间段,如果规定时间内还不能存放元素则直接返回 `false`。
|
||||
|
||||
```java
|
||||
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
|
||||
long nanos = unit.toNanos(timeout);
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lockInterruptibly();
|
||||
try {
|
||||
//队列为空,循环等待,若时间到还是空的,则直接返回null
|
||||
while (count == 0) {
|
||||
if (nanos <= 0)
|
||||
return null;
|
||||
nanos = notEmpty.awaitNanos(nanos);
|
||||
}
|
||||
return dequeue();
|
||||
} finally {
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
同理,带有超时时间的 `poll` 也一样,队列为空则在规定时间内等待,若时间到了还是空的,则直接返回 null。
|
||||
|
||||
### 判断元素是否存在
|
||||
|
||||
`ArrayBlockingQueue` 提供了 `contains(Object o)` 来判断指定元素是否存在于队列中。
|
||||
|
||||
```java
|
||||
public boolean contains(Object o) {
|
||||
//若目标元素为空,则直接返回 false
|
||||
if (o == null) return false;
|
||||
//获取当前队列的元素数组
|
||||
final Object[] items = this.items;
|
||||
//加锁
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();
|
||||
try {
|
||||
// 如果队列非空
|
||||
if (count > 0) {
|
||||
final int putIndex = this.putIndex;
|
||||
//从队列头部开始遍历
|
||||
int i = takeIndex;
|
||||
do {
|
||||
if (o.equals(items[i]))
|
||||
return true;
|
||||
if (++i == items.length)
|
||||
i = 0;
|
||||
} while (i != putIndex);
|
||||
}
|
||||
return false;
|
||||
} finally {
|
||||
//释放锁
|
||||
lock.unlock();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## ArrayBlockingQueue 获取和新增元素的方法对比
|
||||
|
||||
为了帮助理解 `ArrayBlockingQueue` ,我们再来对比一下上面提到的这些获取和新增元素的方法。
|
||||
|
||||
新增元素:
|
||||
|
||||
| 方法 | 队列满时处理方式 | 方法返回值 |
|
||||
| ----------------------------------------- | -------------------------------------------------------- | ---------- |
|
||||
| `put(E e)` | 线程阻塞,直到中断或被唤醒 | void |
|
||||
| `offer(E e)` | 直接返回 false | boolean |
|
||||
| `offer(E e, long timeout, TimeUnit unit)` | 指定超时时间内阻塞,超过规定时间还未添加成功则返回 false | boolean |
|
||||
| `add(E e)` | 直接抛出 `IllegalStateException` 异常 | boolean |
|
||||
|
||||
获取/移除元素:
|
||||
|
||||
| 方法 | 队列空时处理方式 | 方法返回值 |
|
||||
| ----------------------------------- | --------------------------------------------------- | ---------- |
|
||||
| `take()` | 线程阻塞,直到中断或被唤醒 | E |
|
||||
| `poll()` | 返回 null | E |
|
||||
| `poll(long timeout, TimeUnit unit)` | 指定超时时间内阻塞,超过规定时间还是空的则返回 null | E |
|
||||
| `peek()` | 返回 null | E |
|
||||
| `remove()` | 直接抛出 `NoSuchElementException` 异常 | boolean |
|
||||
|
||||
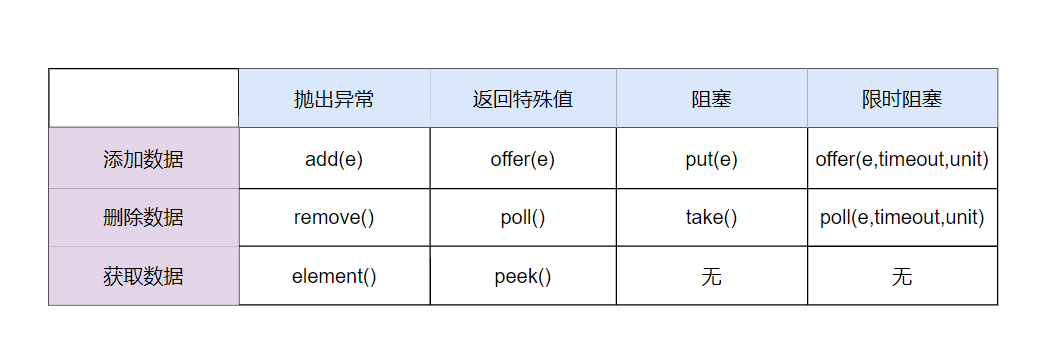
|
||||
|
||||
## ArrayBlockingQueue 相关面试题
|
||||
|
||||
### ArrayBlockingQueue 是什么?它的特点是什么?
|
||||
|
||||
`ArrayBlockingQueue` 是 `BlockingQueue` 接口的有界队列实现类,常用于多线程之间的数据共享,底层采用数组实现,从其名字就能看出来了。
|
||||
|
||||
`ArrayBlockingQueue` 的容量有限,一旦创建,容量不能改变。
|
||||
|
||||
为了保证线程安全,`ArrayBlockingQueue` 的并发控制采用可重入锁 `ReentrantLock` ,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。并且,它还支持公平和非公平两种方式的锁访问机制,默认是非公平锁。
|
||||
|
||||
`ArrayBlockingQueue` 虽名为阻塞队列,但也支持非阻塞获取和新增元素(例如 `poll()` 和 `offer(E e)` 方法),只是队列满时添加元素会抛出异常,队列为空时获取的元素为 null,一般不会使用。
|
||||
|
||||
### ArrayBlockingQueue 和 LinkedBlockingQueue 有什么区别?
|
||||
|
||||
`ArrayBlockingQueue` 和 `LinkedBlockingQueue` 是 Java 并发包中常用的两种阻塞队列实现,它们都是线程安全的。不过,不过它们之间也存在下面这些区别:
|
||||
|
||||
- 底层实现:`ArrayBlockingQueue` 基于数组实现,而 `LinkedBlockingQueue` 基于链表实现。
|
||||
- 是否有界:`ArrayBlockingQueue` 是有界队列,必须在创建时指定容量大小。`LinkedBlockingQueue` 创建时可以不指定容量大小,默认是`Integer.MAX_VALUE`,也就是无界的。但也可以指定队列大小,从而成为有界的。
|
||||
- 锁是否分离: `ArrayBlockingQueue`中的锁是没有分离的,即生产和消费用的是同一个锁;`LinkedBlockingQueue`中的锁是分离的,即生产用的是`putLock`,消费是`takeLock`,这样可以防止生产者和消费者线程之间的锁争夺。
|
||||
- 内存占用:`ArrayBlockingQueue` 需要提前分配数组内存,而 `LinkedBlockingQueue` 则是动态分配链表节点内存。这意味着,`ArrayBlockingQueue` 在创建时就会占用一定的内存空间,且往往申请的内存比实际所用的内存更大,而`LinkedBlockingQueue` 则是根据元素的增加而逐渐占用内存空间。
|
||||
|
||||
### ArrayBlockingQueue 和 ConcurrentLinkedQueue 有什么区别?
|
||||
|
||||
`ArrayBlockingQueue` 和 `ConcurrentLinkedQueue` 是 Java 并发包中常用的两种队列实现,它们都是线程安全的。不过,不过它们之间也存在下面这些区别:
|
||||
|
||||
- 底层实现:`ArrayBlockingQueue` 基于数组实现,而 `ConcurrentLinkedQueue` 基于链表实现。
|
||||
- 是否有界:`ArrayBlockingQueue` 是有界队列,必须在创建时指定容量大小,而 `ConcurrentLinkedQueue` 是无界队列,可以动态地增加容量。
|
||||
- 是否阻塞:`ArrayBlockingQueue` 支持阻塞和非阻塞两种获取和新增元素的方式(一般只会使用前者), `ConcurrentLinkedQueue` 是无界的,仅支持非阻塞式获取和新增元素。
|
||||
|
||||
### ArrayBlockingQueue 的实现原理是什么?
|
||||
|
||||
`ArrayBlockingQueue` 的实现原理主要分为以下几点(这里以阻塞式获取和新增元素为例介绍):
|
||||
|
||||
- `ArrayBlockingQueue` 内部维护一个定长的数组用于存储元素。
|
||||
- 通过使用 `ReentrantLock` 锁对象对读写操作进行同步,即通过锁机制来实现线程安全。
|
||||
- 通过 `Condition` 实现线程间的等待和唤醒操作。
|
||||
|
||||
这里再详细介绍一下线程间的等待和唤醒具体的实现(不需要记具体的方法,面试中回答要点即可):
|
||||
|
||||
- 当队列已满时,生产者线程会调用 `notFull.await()` 方法让生产者进行等待,等待队列非满时插入(非满条件)。
|
||||
- 当队列为空时,消费者线程会调用 `notEmpty.await()`方法让消费者进行等待,等待队列非空时消费(非空条件)。
|
||||
- 当有新的元素被添加时,生产者线程会调用 `notEmpty.signal()`方法唤醒正在等待消费的消费者线程。
|
||||
- 当队列中有元素被取出时,消费者线程会调用 `notFull.signal()`方法唤醒正在等待插入元素的生产者线程。
|
||||
|
||||
关于 `Condition`接口的补充:
|
||||
|
||||
> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 `Condition` 接口默认提供的。而`synchronized`关键字就相当于整个 `Lock` 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程,这样会造成很大的效率问题。而`Condition`实例的`signalAll()`方法,只会唤醒注册在该`Condition`实例中的所有等待线程。
|
||||
|
||||
## 参考文献
|
||||
|
||||
- 深入理解 Java 系列 | BlockingQueue 用法详解:<https://juejin.cn/post/6999798721269465102>
|
||||
- 深入浅出阻塞队列 BlockingQueue 及其典型实现 ArrayBlockingQueue:<https://zhuanlan.zhihu.com/p/539619957>
|
||||
- 并发编程大扫盲:ArrayBlockingQueue 底层原理和实战:<https://zhuanlan.zhihu.com/p/339662987>
|
||||
|
|
@ -477,3 +477,12 @@ Java 中常用的阻塞队列实现类有以下几种:
|
|||
6. ......
|
||||
|
||||
日常开发中,这些队列使用的其实都不多,了解即可。
|
||||
|
||||
### ArrayBlockingQueue 和 LinkedBlockingQueue 有什么区别?
|
||||
|
||||
`ArrayBlockingQueue` 和 `LinkedBlockingQueue` 是 Java 并发包中常用的两种阻塞队列实现,它们都是线程安全的。不过,不过它们之间也存在下面这些区别:
|
||||
|
||||
- 底层实现:`ArrayBlockingQueue` 基于数组实现,而 `LinkedBlockingQueue` 基于链表实现。
|
||||
- 是否有界:`ArrayBlockingQueue` 是有界队列,必须在创建时指定容量大小。`LinkedBlockingQueue` 创建时可以不指定容量大小,默认是`Integer.MAX_VALUE`,也就是无界的。但也可以指定队列大小,从而成为有界的。
|
||||
- 锁是否分离: `ArrayBlockingQueue`中的锁是没有分离的,即生产和消费用的是同一个锁;`LinkedBlockingQueue`中的锁是分离的,即生产用的是`putLock`,消费是`takeLock`,这样可以防止生产者和消费者线程之间的锁争夺。
|
||||
- 内存占用:`ArrayBlockingQueue` 需要提前分配数组内存,而 `LinkedBlockingQueue` 则是动态分配链表节点内存。这意味着,`ArrayBlockingQueue` 在创建时就会占用一定的内存空间,且往往申请的内存比实际所用的内存更大,而`LinkedBlockingQueue` 则是根据元素的增加而逐渐占用内存空间。
|
||||
|
|
|
|||
|
|
@ -418,7 +418,7 @@ assertEquals("hello!world!nice!", completableFuture.get());
|
|||
|
||||
**那 `thenCompose()` 和 `thenCombine()` 有什么区别呢?**
|
||||
|
||||
- `thenCompose()` 可以两个 `CompletableFuture` 对象,并将前一个任务的返回结果作为下一个任务的参数,它们之间存在着先后顺序。
|
||||
- `thenCompose()` 可以链接两个 `CompletableFuture` 对象,并将前一个任务的返回结果作为下一个任务的参数,它们之间存在着先后顺序。
|
||||
- `thenCombine()` 会在两个任务都执行完成后,把两个任务的结果合并。两个任务是并行执行的,它们之间并没有先后依赖顺序。
|
||||
|
||||
### 并行运行多个 CompletableFuture
|
||||
|
|
|
|||
|
|
@ -336,6 +336,7 @@ pool-1-thread-4 End. Time = Sun Apr 12 11:14:47 CST 2020
|
|||
pool-1-thread-5 End. Time = Sun Apr 12 11:14:47 CST 2020
|
||||
pool-1-thread-3 End. Time = Sun Apr 12 11:14:47 CST 2020
|
||||
pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
|
||||
Finished all threads // 任务全部执行完了才会跳出来,因为executor.isTerminated()判断为true了才会跳出while循环,当且仅当调用 shutdown() 方法后,并且所有提交的任务完成后返回为 true
|
||||
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -80,7 +80,7 @@ String result = new String(bufferedInputStream.readAllBytes());
|
|||
System.out.println(result);
|
||||
```
|
||||
|
||||
`DataInputStream` 用于读取指定类型数据,不能单独使用,必须结合 `FileInputStream` 。
|
||||
`DataInputStream` 用于读取指定类型数据,不能单独使用,必须结合其它流,比如 `FileInputStream` 。
|
||||
|
||||
```java
|
||||
FileInputStream fileInputStream = new FileInputStream("input.txt");
|
||||
|
|
@ -138,7 +138,7 @@ FileOutputStream fileOutputStream = new FileOutputStream("output.txt");
|
|||
BufferedOutputStream bos = new BufferedOutputStream(fileOutputStream)
|
||||
```
|
||||
|
||||
**`DataOutputStream`** 用于写入指定类型数据,不能单独使用,必须结合 `FileOutputStream`
|
||||
**`DataOutputStream`** 用于写入指定类型数据,不能单独使用,必须结合其它流,比如 `FileOutputStream` 。
|
||||
|
||||
```java
|
||||
// 输出流
|
||||
|
|
|
|||
|
|
@ -31,9 +31,9 @@ ClassFile {
|
|||
u2 access_flags;//Class 的访问标记
|
||||
u2 this_class;//当前类
|
||||
u2 super_class;//父类
|
||||
u2 interfaces_count;//接口
|
||||
u2 interfaces_count;//接口数量
|
||||
u2 interfaces[interfaces_count];//一个类可以实现多个接口
|
||||
u2 fields_count;//Class 文件的字段属性
|
||||
u2 fields_count;//Class 文件的字段属性数量
|
||||
field_info fields[fields_count];//一个类可以有多个字段
|
||||
u2 methods_count;//Class 文件的方法数量
|
||||
method_info methods[methods_count];//一个类可以有个多个方法
|
||||
|
|
@ -71,7 +71,7 @@ ClassFile {
|
|||
u2 major_version;//Class 的大版本号
|
||||
```
|
||||
|
||||
紧接着魔数的四个字节存储的是 Class 文件的版本号:第 5 和第 6 位是**次版本号**,第 7 和第 8 位是**主版本号**。
|
||||
紧接着魔数的四个字节存储的是 Class 文件的版本号:第 5 和第 6 个字节是**次版本号**,第 7 和第 8 个字节是**主版本号**。
|
||||
|
||||
每当 Java 发布大版本(比如 Java 8,Java9)的时候,主版本号都会加 1。你可以使用 `javap -v` 命令来快速查看 Class 文件的版本号信息。
|
||||
|
||||
|
|
@ -143,7 +143,7 @@ public class Employee {
|
|||
```java
|
||||
u2 this_class;//当前类
|
||||
u2 super_class;//父类
|
||||
u2 interfaces_count;//接口
|
||||
u2 interfaces_count;//接口数量
|
||||
u2 interfaces[interfaces_count];//一个类可以实现多个接口
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ tag:
|
|||
|
||||
## 类的生命周期
|
||||
|
||||
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段::加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。其中,前三个阶段可以统称为连接(Linking)。
|
||||
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段::加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。其中,验证、准备和解析这三个阶段可以统称为连接(Linking)。
|
||||
|
||||
这 7 个阶段的顺序如下图所示:
|
||||
|
||||
|
|
@ -107,7 +107,7 @@ tag:
|
|||
|
||||
对于`<clinit> ()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `<clinit> ()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起多个线程阻塞,并且这种阻塞很难被发现。
|
||||
|
||||
对于初始化阶段,虚拟机严格规范了有且只有 5 种情况下,必须对类进行初始化(只有主动去使用类才会初始化类):
|
||||
对于初始化阶段,虚拟机严格规范了有且只有 6 种情况下,必须对类进行初始化(只有主动去使用类才会初始化类):
|
||||
|
||||
1. 当遇到 `new`、 `getstatic`、`putstatic` 或 `invokestatic` 这 4 条字节码指令时,比如 `new` 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
|
||||
- 当 jvm 执行 `new` 指令时会初始化类。即当程序创建一个类的实例对象。
|
||||
|
|
|
|||
|
|
@ -243,7 +243,7 @@ Found 1 deadlock.
|
|||
|
||||
### JConsole:Java 监视与管理控制台
|
||||
|
||||
JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监视本地及远程服务器的 java 进程的内存使用情况。你可以在控制台输出`console`命令启动或者在 JDK 目录下的 bin 目录找到`jconsole.exe`然后双击启动。
|
||||
JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监视本地及远程服务器的 java 进程的内存使用情况。你可以在控制台输入`jconsole`命令启动或者在 JDK 目录下的 bin 目录找到`jconsole.exe`然后双击启动。
|
||||
|
||||
#### 连接 Jconsole
|
||||
|
||||
|
|
|
|||
|
|
@ -51,7 +51,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||
|
||||
### 对象优先在 Eden 区分配
|
||||
|
||||
大多数情况下,对象在新生代中 Eden 区分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。下面我们来进行实际测试以下。
|
||||
大多数情况下,对象在新生代中 Eden 区分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起一次 Minor GC。下面我们来进行实际测试一下。
|
||||
|
||||
测试代码:
|
||||
|
||||
|
|
|
|||
|
|
@ -258,7 +258,7 @@ JDK1.4 中新加入的 **NIO(Non-Blocking I/O,也被称为 New I/O)**,
|
|||
|
||||
直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
||||
|
||||
类似的概念还有 **堆外内存** 。在一些文章中将直接内存等价于堆外内,个人觉得不是特别准确。
|
||||
类似的概念还有 **堆外内存** 。在一些文章中将直接内存等价于堆外内存,个人觉得不是特别准确。
|
||||
|
||||
堆外内存就是把内存对象分配在堆(新生代+老年代+永久代)以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ tag:
|
|||
|
||||
### String 增强
|
||||
|
||||
Java 11 增加了两个的字符串处理方法,如以下所示。
|
||||
Java 12 增加了两个的字符串处理方法,如以下所示。
|
||||
|
||||
`indent()` 方法可以实现字符串缩进。
|
||||
|
||||
|
|
@ -145,7 +145,7 @@ if(obj instanceof String str){
|
|||
|
||||
### 增强 ZGC(释放未使用内存)
|
||||
|
||||
在 Java 11 中是实验性的引入的 ZGC 在实际的使用中存在未能主动将未使用的内存释放给操作系统的问题。
|
||||
在 Java 11 中实验性引入的 ZGC 在实际的使用中存在未能主动将未使用的内存释放给操作系统的问题。
|
||||
|
||||
ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 **ZPageCache** 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织。
|
||||
|
||||
|
|
|
|||
|
|
@ -117,7 +117,7 @@ c++ php
|
|||
|
||||
### 其他
|
||||
|
||||
- 从 Java11 引入的 ZGC 作为继 G1 过后的下一代 GC 算法,从支持 Linux 平台到 Java14 开始支持 MacOS 和 Window(个人感觉是终于可以在日常开发工具中先体验下 ZGC 的效果了,虽然其实 G1 也够用)
|
||||
- 从 Java11 引入的 ZGC 作为继 G1 过后的下一代 GC 算法,从支持 Linux 平台到 Java14 开始支持 MacOS 和 Windows(个人感觉是终于可以在日常开发工具中先体验下 ZGC 的效果了,虽然其实 G1 也够用)
|
||||
- 移除了 CMS(Concurrent Mark Sweep) 垃圾收集器(功成而退)
|
||||
- 新增了 jpackage 工具,标配将应用打成 jar 包外,还支持不同平台的特性包,比如 linux 下的`deb`和`rpm`,window 平台下的`msi`和`exe`
|
||||
|
||||
|
|
|
|||
|
|
@ -9,7 +9,7 @@ Java 16 在 2021 年 3 月 16 日正式发布,非长期支持(LTS)版本
|
|||
|
||||
相关阅读:[OpenJDK Java 16 文档](https://openjdk.java.net/projects/jdk/16/) 。
|
||||
|
||||
## JEP 338:向量 API(第二次孵化)
|
||||
## JEP 338:向量 API(第一次孵化)
|
||||
|
||||
向量(Vector) API 最初由 [JEP 338](https://openjdk.java.net/jeps/338) 提出,并作为[孵化 API](http://openjdk.java.net/jeps/11)集成到 Java 16 中。第二轮孵化由 [JEP 414](https://openjdk.java.net/jeps/414) 提出并集成到 Java 17 中,第三轮孵化由 [JEP 417](https://openjdk.java.net/jeps/417) 提出并集成到 Java 18 中,第四轮由 [JEP 426](https://openjdk.java.net/jeps/426) 提出并集成到了 Java 19 中。
|
||||
|
||||
|
|
@ -84,7 +84,7 @@ Java 14([ JEP 370](https://openjdk.org/jeps/370)) 的时候,第一次孵化外
|
|||
| ---------- | ----------------- | --------------------------------------- | ---------------------------------------- |
|
||||
| Java SE 14 | preview | [JEP 305](https://openjdk.org/jeps/305) | 首次引入 instanceof 模式匹配。 |
|
||||
| Java SE 15 | Second Preview | [JEP 375](https://openjdk.org/jeps/375) | 相比较上个版本无变化,继续收集更多反馈。 |
|
||||
| Java SE 16 | Permanent Release | [JEP 394](https://openjdk.org/jeps/394) | 模式变量不在隐式为 final。 |
|
||||
| Java SE 16 | Permanent Release | [JEP 394](https://openjdk.org/jeps/394) | 模式变量不再隐式为 final。 |
|
||||
|
||||
从 Java 16 开始,你可以对 `instanceof` 中的变量值进行修改。
|
||||
|
||||
|
|
|
|||
|
|
@ -40,9 +40,9 @@ Java 17 将是继 Java 8 以来最重要的长期支持(LTS)版本,是 Jav
|
|||
|
||||
JDK 17 之前,我们可以借助 `Random`、`ThreadLocalRandom`和`SplittableRandom`来生成随机数。不过,这 3 个类都各有缺陷,且缺少常见的伪随机算法支持。
|
||||
|
||||
Java 17 为伪随机数生成器 (pseudorandom number generator,RPNG,又称为确定性随机位生成器)增加了新的接口类型和实现,使得开发者更容易在应用程序中互换使用各种 PRNG 算法。
|
||||
Java 17 为伪随机数生成器 (pseudorandom number generator,PRNG,又称为确定性随机位生成器)增加了新的接口类型和实现,使得开发者更容易在应用程序中互换使用各种 PRNG 算法。
|
||||
|
||||
> [RPNG](https://ctf-wiki.org/crypto/streamcipher/prng/intro/) 用来生成接近于绝对随机数序列的数字序列。一般来说,PRNG 会依赖于一个初始值,也称为种子,来生成对应的伪随机数序列。只要种子确定了,PRNG 所生成的随机数就是完全确定的,因此其生成的随机数序列并不是真正随机的。
|
||||
> [PRNG](https://ctf-wiki.org/crypto/streamcipher/prng/intro/) 用来生成接近于绝对随机数序列的数字序列。一般来说,PRNG 会依赖于一个初始值,也称为种子,来生成对应的伪随机数序列。只要种子确定了,PRNG 所生成的随机数就是完全确定的,因此其生成的随机数序列并不是真正随机的。
|
||||
|
||||
使用示例:
|
||||
|
||||
|
|
|
|||
|
|
@ -211,7 +211,7 @@ num = 3;//在lambda表达式中试图修改num同样是不允许的。
|
|||
|
||||
#### 访问字段和静态变量
|
||||
|
||||
与局部变量相比,我们对 lambda 表达式中的实例字段和静态变量都有读写访问权限。 该行为和匿名对象是一致的。
|
||||
与局部变量相比,我们在 lambda 表达式中对实例字段和静态变量都有读写访问权限。 该行为和匿名对象是一致的。
|
||||
|
||||
```java
|
||||
class Lambda4 {
|
||||
|
|
|
|||
|
|
@ -244,7 +244,7 @@ System.out.println(currentProcess.info());
|
|||
|
||||
- **平台日志 API 改进**:Java 9 允许为 JDK 和应用配置同样的日志实现。新增了 `System.LoggerFinder` 用来管理 JDK 使 用的日志记录器实现。JVM 在运行时只有一个系统范围的 `LoggerFinder` 实例。我们可以通过添加自己的 `System.LoggerFinder` 实现来让 JDK 和应用使用 SLF4J 等其他日志记录框架。
|
||||
- **`CompletableFuture`类增强**:新增了几个新的方法(`completeAsync` ,`orTimeout` 等)。
|
||||
- **Nashorn 引擎的增强**:Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性(Java 11 中已经被弃用)。
|
||||
- **Nashorn 引擎的增强**:Nashorn 是从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性(Java 11 中已经被弃用)。
|
||||
- **I/O 流的新特性**:增加了新的方法来读取和复制 `InputStream` 中包含的数据。
|
||||
- **改进应用的安全性能**:Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 SHA3-512。
|
||||
- **改进方法句柄(Method Handle)**:方法句柄从 Java7 开始引入,Java9 在类`java.lang.invoke.MethodHandles` 中新增了更多的静态方法来创建不同类型的方法句柄。
|
||||
|
|
|
|||
|
|
@ -0,0 +1,33 @@
|
|||
## 星球介绍
|
||||
|
||||
为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的[ Java 面试知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面,非常适合准备 Java 面试和学习 Java 的同学。
|
||||
|
||||
**欢迎准备 Java 面试以及学习 Java 的同学加入我的 [知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。**
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
[](../about-the-author/zhishixingqiu-two-years.md)
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍:[JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
|
||||
|
||||
## 如何加入?
|
||||
|
||||
**方式一(不推荐)**:扫描下面的二维码原价加入(续费半价不到)。
|
||||
|
||||
|
||||
|
||||
**方式二(推荐)**:添加我的个人微信(**javaguide1024**)领取一个 **30** 元的星球专属优惠券(续费半价不到)。
|
||||
|
||||
**一定要备注“优惠卷”**,不然通过不了。
|
||||
|
||||

|
||||
|
||||
**无任何套路,无任何潜在收费项。用心做内容,不割韭菜!**
|
||||
|
||||
进入星球之后,记得查看 **[星球使用指南](https://t.zsxq.com/0d18KSarv)** (一定要看!) 。
|
||||
|
||||
随着时间推移,星球积累的干货资源越来越多,我花在星球上的时间也越来越多,星球的价格会逐步向上调整,想要加入的同学一定要尽早。
|
||||
|
||||
不过, **一定要确定需要再进** 。并且, **三天之内觉得内容不满意可以全额退款** 。
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
**方式一(不推荐)**:扫描下面的二维码原价加入(续费半价不到)。
|
||||
|
||||

|
||||
|
||||
**方式二(推荐)**:添加我的个人微信(**javaguide1024**)领取一个 **30** 元的星球专属优惠券(续费半价不到)。
|
||||
|
||||
**一定要备注“优惠卷”**,不然通过不了。
|
||||
|
||||

|
||||
|
||||
**无任何套路,无任何潜在收费项。用心做内容,不割韭菜!**
|
||||
|
||||
进入星球之后,记得查看 **[星球使用指南](https://t.zsxq.com/0d18KSarv)** (一定要看!) 。
|
||||
|
||||
随着时间推移,星球积累的干货资源越来越多,我花在星球上的时间也越来越多,星球的价格会逐步向上调整,想要加入的同学一定要尽早。
|
||||
|
||||
不过, **一定要确定需要再进** 。并且, **三天之内觉得内容不满意可以全额退款** 。
|
||||
|
|
@ -654,10 +654,11 @@ public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
|
|||
> `TransactionInterceptor` 类中的 `invoke()`方法内部实际调用的是 `TransactionAspectSupport` 类的 `invokeWithinTransaction()`方法。由于新版本的 Spring 对这部分重写很大,而且用到了很多响应式编程的知识,这里就不列源码了。
|
||||
|
||||
#### Spring AOP 自调用问题
|
||||
因为SpringAOP工作原理导致@Transaction失效 。
|
||||
当一个方法被标记了@Transactional注解的时候,Spring事务管理器只会在被其他类方法调用的时候生效,而不会在一个类中方法调用生效。
|
||||
|
||||
这是因为Spring AOP工作原理决定的。因为Spring AOP使用动态代理来实现事务的管理,他会在运行的时候为带有@Transaction注解的方法生成代理对象,并在方法调用的前后应用事物逻辑。如果该方法被其他类调用我们的代理对象就会拦截方法调用并处理事物。但是在一个类中的其他方法内部调用的时候我们代理对象就无法拦截到这个内部调用,因此事物也就失效了。
|
||||
|
||||
当一个方法被标记了`@Transactional` 注解的时候,Spring 事务管理器只会在被其他类方法调用的时候生效,而不会在一个类中方法调用生效。
|
||||
|
||||
这是因为 Spring AOP 工作原理决定的。因为 Spring AOP 使用动态代理来实现事务的管理,它会在运行的时候为带有 `@Transactional` 注解的方法生成代理对象,并在方法调用的前后应用事物逻辑。如果该方法被其他类调用我们的代理对象就会拦截方法调用并处理事务。但是在一个类中的其他方法内部调用的时候,我们代理对象就无法拦截到这个内部调用,因此事务也就失效了。
|
||||
|
||||
`MyService` 类中的`method1()`调用`method2()`就会导致`method2()`的事务失效。
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,26 @@
|
|||
---
|
||||
title: 《后端面试高频系统设计&场景题》
|
||||
category: 知识星球
|
||||
---
|
||||
|
||||
## 介绍
|
||||
|
||||
**《后端面试高频系统设计&场景题》** 是我的[知识星球](../about-the-author/zhishixingqiu-two-years.md)的一个内部小册,包含了常见的系统设计案例比如短链系统、秒杀系统以及高频的场景题比如海量数据去重、第三方授权登录。
|
||||
|
||||
在几年前,国内的后端技术面试通常不会涉及到系统设计和场景题。相比之下,国外的后端技术面试则更加注重这方面的考察。然而近年来,随着国内的技术面试越来越卷,越来越多的公司开始在面试中考察系统设计和场景问题的解决,以更全面的考察求职者,不论是校招还是社招。
|
||||
|
||||
不过,正常面试全是场景题的情况还是极少的,面试官一般会在面试中穿插一两个系统设计和场景题来考察你。
|
||||
|
||||

|
||||
|
||||
于是,我总结了这份《后端面试高频系统设计&场景题》,包含了常见的系统设计案例比如短链系统、秒杀系统以及高频的场景题比如海量数据去重、第三方授权登录。
|
||||
|
||||
即使不是准备面试,我也强烈推荐你认真阅读这一系列文章,这对于提升自己系统设计思维和解决实际问题的能力还是非常有帮助的。并且,涉及到的很多案例都可以用到自己的项目上比如抽奖系统设计、第三方授权登录、Redis实现延时任务的正确方式。
|
||||
|
||||
《后端面试高频系统设计&场景题》本身是属于《Java面试指北》的一部分,后面由于内容篇幅较多,因此被单独提了出来。
|
||||
|
||||
## 内容概览
|
||||
|
||||

|
||||
|
||||
<!-- @include: @planet2.snippet.md -->
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: 《手写 RPC 框架》(付费)
|
||||
title: 《手写 RPC 框架》
|
||||
category: 知识星球
|
||||
---
|
||||
|
||||
|
|
@ -18,16 +18,4 @@ category: 知识星球
|
|||
- GitHub 地址:[https://github.com/Snailclimb/guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 。
|
||||
- Gitee 地址:[https://gitee.com/SnailClimb/guide-rpc-framework](https://gitee.com/SnailClimb/guide-rpc-framework) 。
|
||||
|
||||
## 星球其他资源
|
||||
|
||||
除了 **《手写 RPC 框架》** 之外,星球还有 **《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《Java 面试指北》**、**《Kafka 常见面试题/知识点总结》** 等多个专属小册。
|
||||
|
||||

|
||||
|
||||
另外,星球还会有读书活动、学习打卡、简历修改、免费提问、海量 Java 优质面试资源以及各种不定时的福利。
|
||||
|
||||

|
||||
|
||||
## 星球限时优惠
|
||||
|
||||
<!-- @include: @the-way-join-planet.snippet.md -->
|
||||
<!-- @include: @planet2.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: 《Java 面试指北》(付费)
|
||||
title: 《Java 面试指北》
|
||||
category: 知识星球
|
||||
star: 5
|
||||
---
|
||||
|
|
@ -72,20 +72,6 @@ star: 5
|
|||
|
||||
每一篇内容都非常干货,不少球友看了之后表示收获满满。不过,最重要的还是知行合一。
|
||||
|
||||
## 星球其他资源
|
||||
|
||||
除了 **《Java 面试指北》** 之外,星球还有 **《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、 **《从零开始写一个 RPC 框架》**(已更新完)、**《Kafka 常见面试题/知识点总结》** 等多个专属小册。
|
||||
|
||||

|
||||
|
||||
还会免费赠送多本优质 PDF 面试手册。
|
||||
|
||||
|
||||
|
||||
另外,星球还会有读书活动、学习打卡、简历修改、免费提问、海量 Java 优质面试资源以及各种不定时的福利。
|
||||
|
||||

|
||||
|
||||
## 星球限时优惠
|
||||
|
||||
<!-- @include: @the-way-join-planet.snippet.md -->
|
||||
<!-- @include: @planet2.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -6,6 +6,7 @@ category: 知识星球
|
|||
这部分的内容为我的[知识星球](../about-the-author/zhishixingqiu-two-years.md)专属,目前已经更新了下面这些专栏:
|
||||
|
||||
- **[《Java 面试指北》](./java-mian-shi-zhi-bei.md)** : 与 JavaGuide 开源版的内容互补!
|
||||
- **[《后端面试高频系统设计&场景题》](./back-end-interview-high-frequency-system-design-and-scenario-questions.md)** : 包含了常见的系统设计案例比如短链系统、秒杀系统以及高频的场景题比如海量数据去重、第三方授权登录。
|
||||
- **[《手写 RPC 框架》](./java-mian-shi-zhi-bei.md)** : 从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。
|
||||
- **[《Java 必读源码系列》](./source-code-reading.md)**:目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot 2.1 等框架/中间件的源码
|
||||
- ......
|
||||
|
|
@ -16,14 +17,8 @@ category: 知识星球
|
|||
|
||||
## 更多专栏
|
||||
|
||||
除了上面介绍的之外,我的[知识星球](../about-the-author/zhishixingqiu-two-years.md)还有 **《Kafka 常见面试题/知识点总结》**、**《程序员副业赚钱之路》**等多个专栏。
|
||||
除了上面介绍的之外,我的[知识星球](../about-the-author/zhishixingqiu-two-years.md)还有 《Kafka 常见面试题/知识点总结》、《程序员副业赚钱之路》等多个专栏。
|
||||
|
||||

|
||||

|
||||
|
||||
另外,星球还会有读书活动、学习打卡、简历修改、免费提问、海量 Java 优质面试资源以及各种不定时的福利。
|
||||
|
||||

|
||||
|
||||
## 星球限时优惠
|
||||
|
||||
<!-- @include: @the-way-join-planet.snippet.md -->
|
||||
<!-- @include: @planet2.snippet.md -->
|
||||
|
|
|
|||
|
|
@ -1,5 +1,5 @@
|
|||
---
|
||||
title: 《Java 必读源码系列》(付费)
|
||||
title: 《Java 必读源码系列》
|
||||
category: 知识星球
|
||||
star: true
|
||||
---
|
||||
|
|
@ -14,16 +14,4 @@ star: true
|
|||
|
||||
|
||||
|
||||
## 星球其他资源
|
||||
|
||||
除了 **《Java 必读源码系列》** 之外,星球还有 **《从零开始写一个 RPC 框架》**、 **《Java 面试指北》**、 **《Java 必读源码系列》**(目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot2.1 的源码)、**《Kafka 常见面试题/知识点总结》** 等多个专栏。
|
||||
|
||||

|
||||
|
||||
另外,星球还会有读书活动、学习打卡、简历修改、免费提问、海量 Java 优质面试资源以及各种不定时的福利。
|
||||
|
||||

|
||||
|
||||
## 星球限时优惠
|
||||
|
||||
<!-- @include: @the-way-join-planet.snippet.md -->
|
||||
<!-- @include: @planet2.snippet.md -->
|
||||
|
|
|
|||
Loading…
Reference in New Issue