-  +
+ 
@@ -31,7 +31,7 @@ title: JavaGuide(Java学习&&面试指南)
@@ -240,7 +240,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
[Elasticsearch常见面试题总结(付费)](./database/elasticsearch/elasticsearch-questions-01.md)
-
+
## 开发工具
@@ -432,5 +432,5 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号“**JavaGuide**”。
-
+
diff --git a/docs/interview-preparation/interview-experience.md b/docs/interview-preparation/interview-experience.md
index 450b9d97..1c695bb6 100644
--- a/docs/interview-preparation/interview-experience.md
+++ b/docs/interview-preparation/interview-experience.md
@@ -9,21 +9,21 @@ category: 知识星球
如果你是非科班的同学,也能在这些文章中找到对应的非科班的同学写的面经。
-
+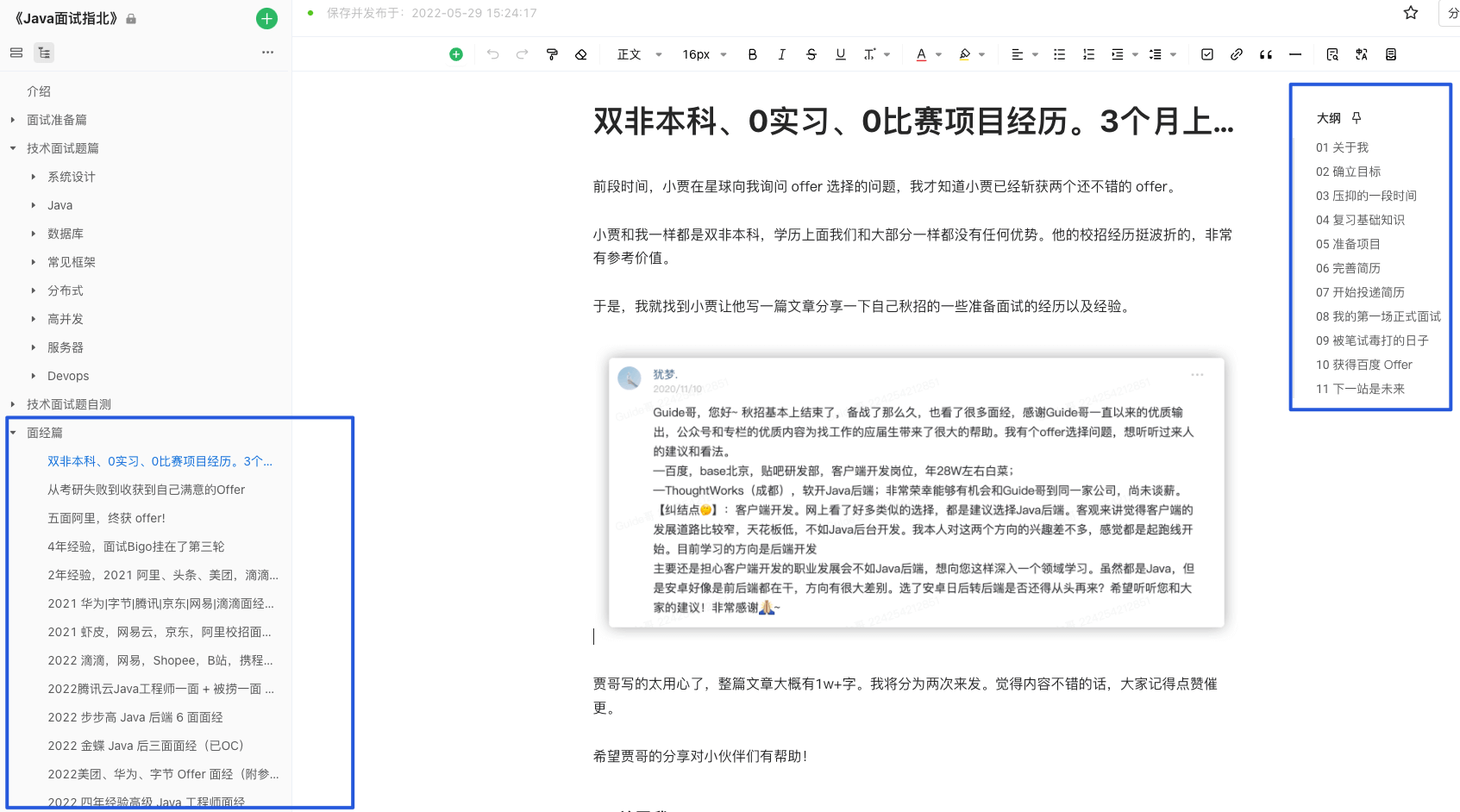
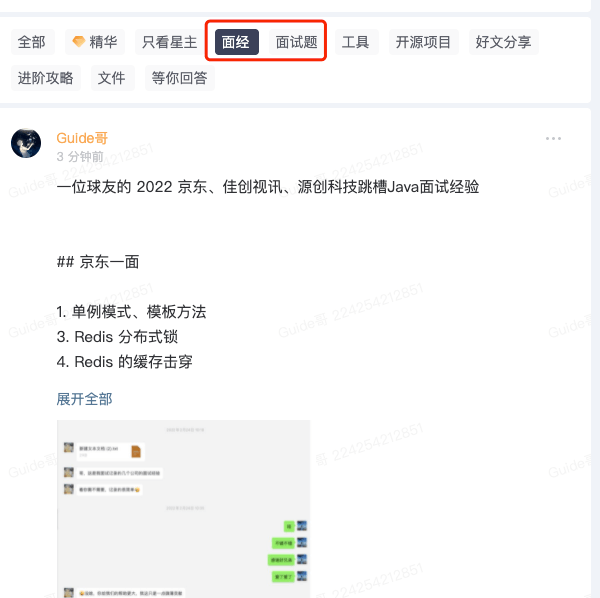
并且,[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)还有专门分享面经和面试题的专题,里面会分享很多优质的面经和面试题。
-
+
-
+
-
+
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
@@ -31,7 +31,7 @@ category: 知识星球
@@ -43,7 +43,7 @@ category: 知识星球
@@ -51,7 +51,7 @@ category: 知识星球
diff --git a/docs/interview-preparation/project-experience-guide.md b/docs/interview-preparation/project-experience-guide.md
index 5586314b..4439fc2f 100644
--- a/docs/interview-preparation/project-experience-guide.md
+++ b/docs/interview-preparation/project-experience-guide.md
@@ -15,7 +15,7 @@ category: 面试准备
你可以通过慕课网、哔哩哔哩、拉勾、极客时间、培训机构(比如黑马、尚硅谷)等渠道获取到适合自己的实战项目视频/专栏。
-
+
尽量选择一个适合自己的项目,没必要必须做分布式/微服务项目,对于绝大部分同学来说,能把一个单机项目做好就已经很不错了。
@@ -35,7 +35,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
你可以参考 [Java 优质开源实战项目](https://javaguide.cn/open-source-project/practical-project.html "Java 优质开源实战项目") 上面推荐的实战类开源项目,质量都很高,项目类型也比较全面,涵盖博客/论坛系统、考试/刷题系统、商城系统、权限管理系统、快速开发脚手架以及各种轮子。
-
+
一定要记住: **不光要做,还要改进,改善。不论是实战项目视频或者专栏还是实战类开源项目,都一定会有很多可以完善改进的地方。**
@@ -69,7 +69,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
-
+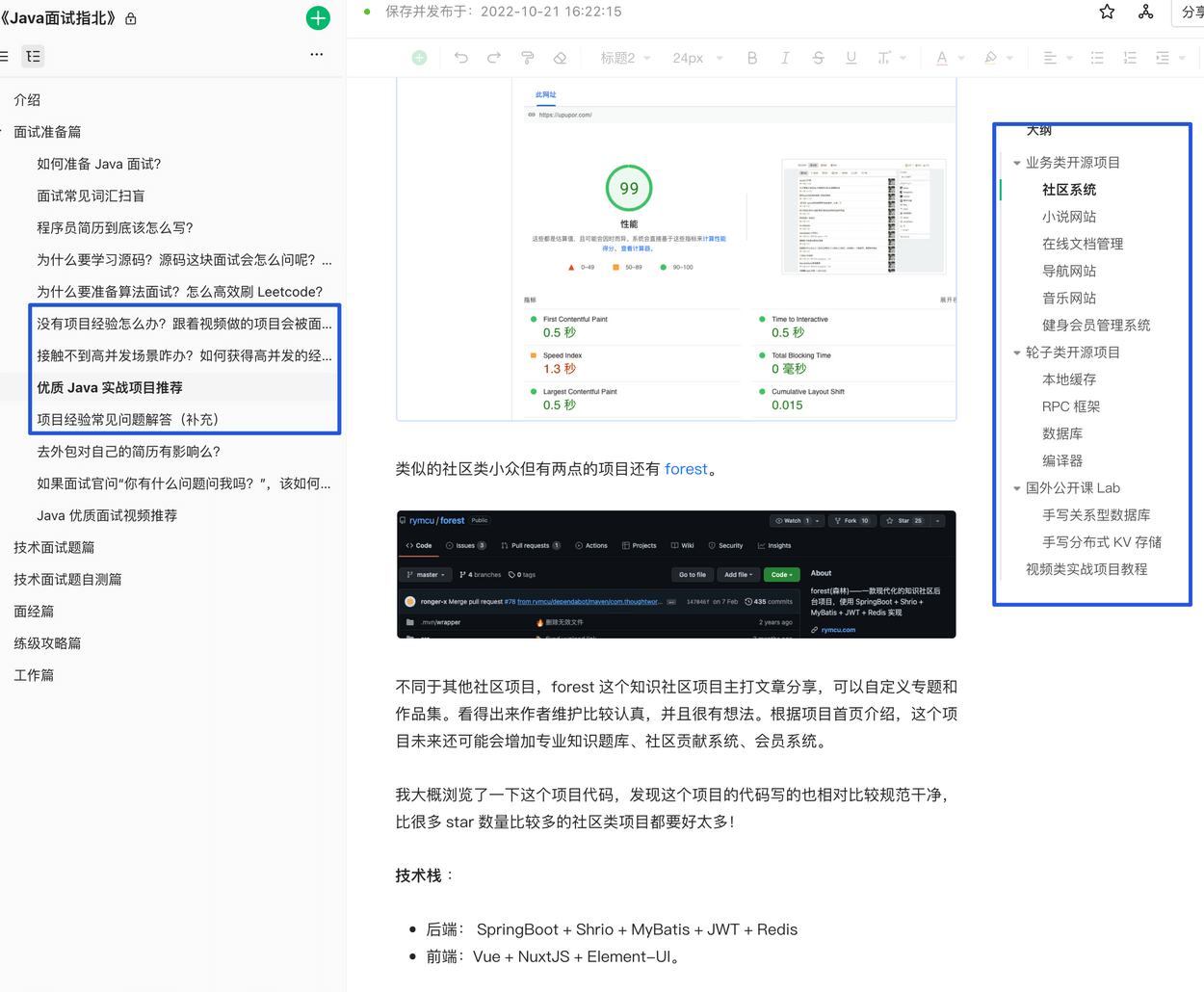
这篇文章一共推荐了 15+ 个实战项目,有业务类的,也有轮子类的,有开源项目、也有视频教程。对于参加校招的小伙伴,我更建议做一个业务类项目加上一个轮子类的项目。
diff --git a/docs/interview-preparation/self-test-of-common-interview-questions.md b/docs/interview-preparation/self-test-of-common-interview-questions.md
index 2ef0023c..f496c1d1 100644
--- a/docs/interview-preparation/self-test-of-common-interview-questions.md
+++ b/docs/interview-preparation/self-test-of-common-interview-questions.md
@@ -7,23 +7,23 @@ category: 知识星球
在 **[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的 **「技术面试题自测篇」** ,我总结了 Java 面试中最重要的知识点的最常见的面试题并按照面试提问的方式展现出来。
-
+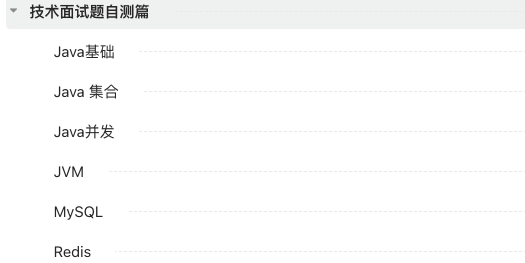
每一道用于自测的面试题我都会给出重要程度,方便大家在时间比较紧张的时候根据自身情况来选择性自测。并且,我还会给出提示,方便你回忆起对应的知识点。
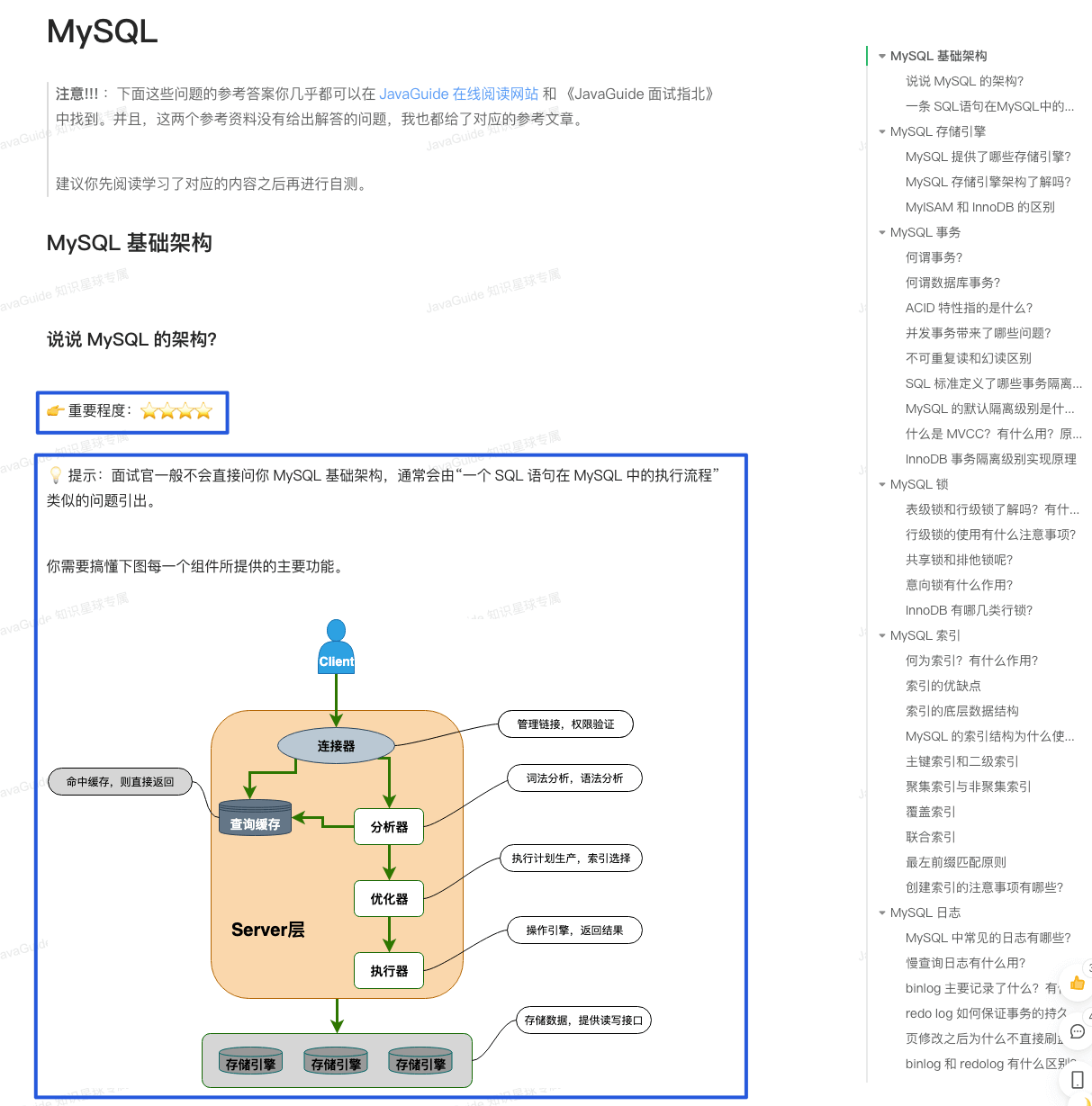
在面试中如果你实在没有头绪的话,一个好的面试官也是会给你提示的。
-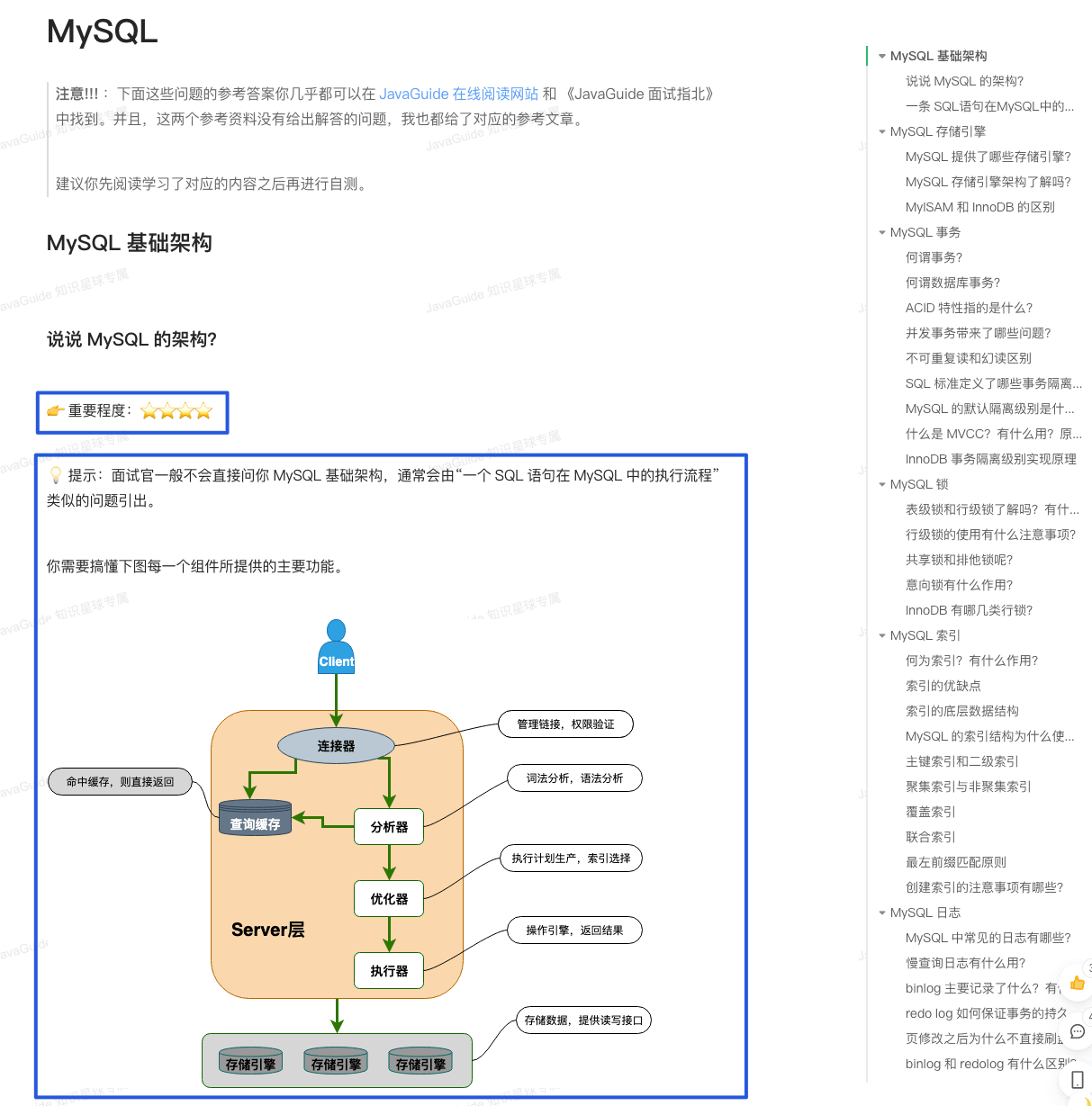
+
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://www.yuque.com/docs/share/8a30ffb5-83f3-40f9-baf9-38de68b906dc),干货非常多,学习氛围非常好!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
-
+
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
@@ -33,6 +33,6 @@ category: 知识星球
diff --git a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
index 09c29bd0..5ff34aa4 100644
--- a/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
+++ b/docs/interview-preparation/teach-you-how-to-prepare-for-the-interview-hand-in-hand.md
@@ -79,15 +79,15 @@ category: 知识星球
**1.个人介绍没太多实用的信息。**
-
+
技术博客、Github 以及在校获奖经历的话,能写就尽量写在这里。 你可以参考下面 👇 的模板进行修改:
-
+
**2.项目经历过于简单,完全没有质量可言**
-
+
每一个项目经历真的就一两句话可以描述了么?还是自己不想写?还是说不是自己做的,不敢多写。
@@ -102,11 +102,11 @@ category: 知识星球
**3.计算机二级这个证书对于计算机专业完全不用写了,没有含金量的。**
-
+
**4.技能介绍问题太大。**
-
+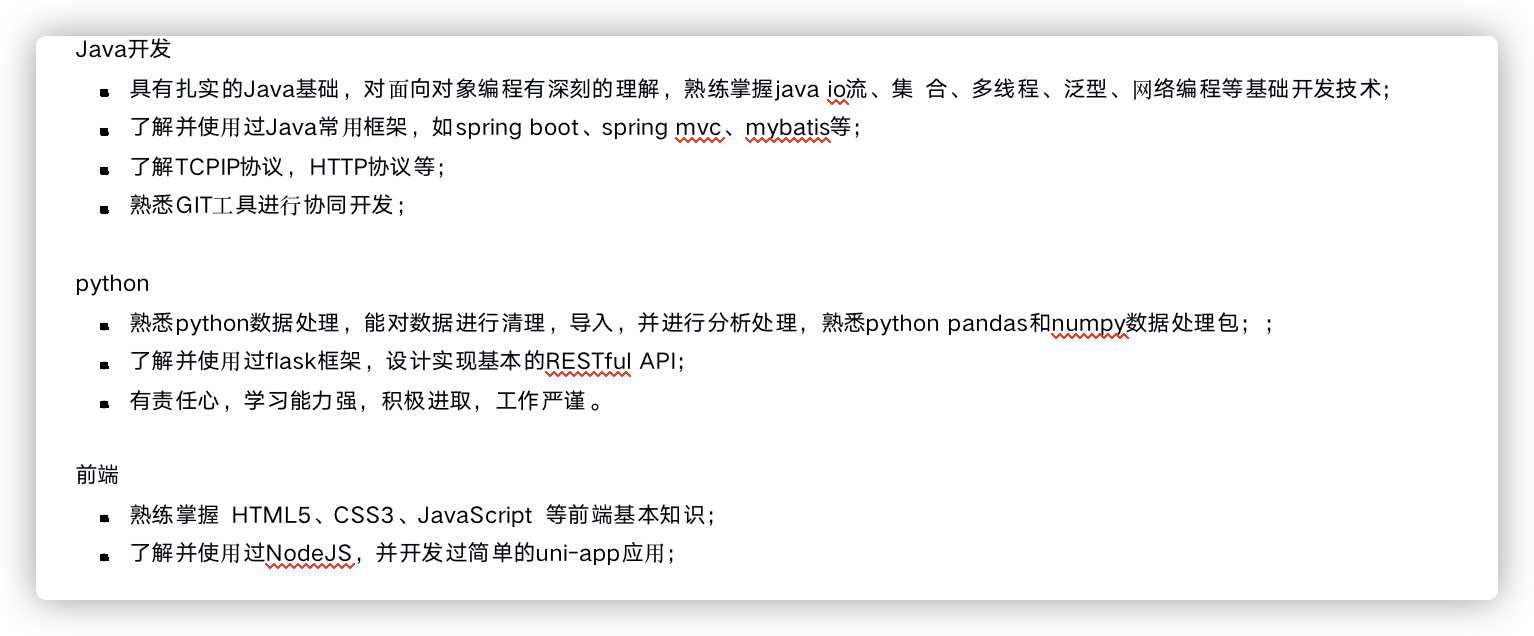
- 技术名词最好规范大小写比较好,比如 java->Java ,spring boot -> Spring Boot 。这个虽然有些面试官不会介意,但是很多面试官都会在意这个细节的。
- 技能介绍太杂,没有亮点。不需要全才,某个领域做得好就行了!
@@ -176,7 +176,7 @@ category: 知识星球
- 降级
- 熔断
-
+
不同类型的公司对于技能的要求侧重点是不同的比如腾讯、字节可能更重视计算机基础比如网络、操作系统这方面的内容。阿里、美团这种可能更重视你的项目经历、实战能力。
diff --git a/docs/java/basis/bigdecimal.md b/docs/java/basis/bigdecimal.md
index b224ff00..8363fd78 100644
--- a/docs/java/basis/bigdecimal.md
+++ b/docs/java/basis/bigdecimal.md
@@ -46,7 +46,7 @@ System.out.println(a == b);// false
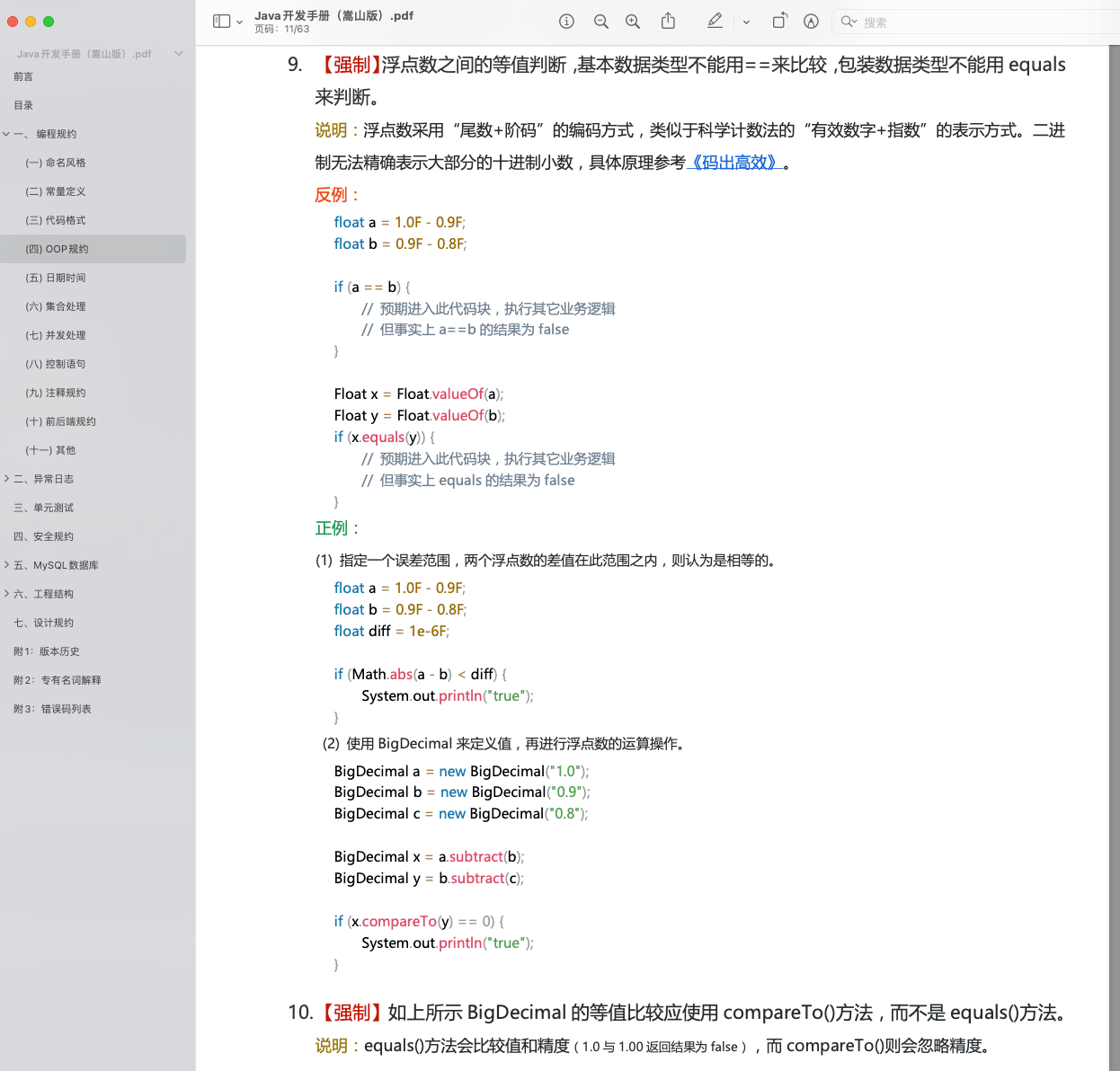
《阿里巴巴 Java 开发手册》中提到:**浮点数之间的等值判断,基本数据类型不能用 == 来比较,包装数据类型不能用 equals 来判断。**
-
+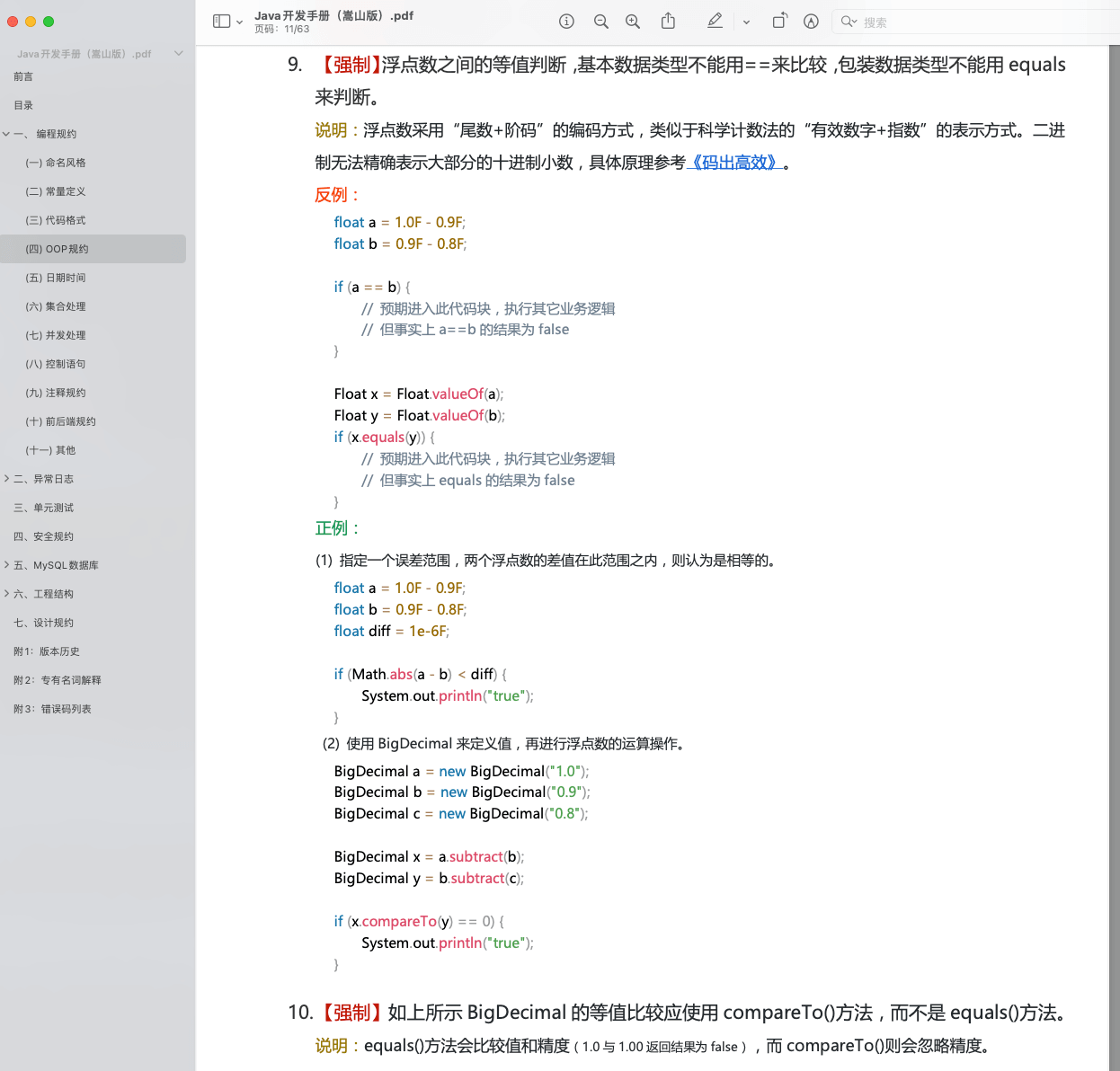
具体原因我们在上面已经详细介绍了,这里就不多提了。
@@ -71,7 +71,7 @@ System.out.println(x.compareTo(y));// 0
《阿里巴巴 Java 开发手册》对这部分内容也有提到,如下图所示。
-
+
### 加减乘除
@@ -142,7 +142,7 @@ System.out.println(n);// 1.255
《阿里巴巴 Java 开发手册》中提到:
-
+
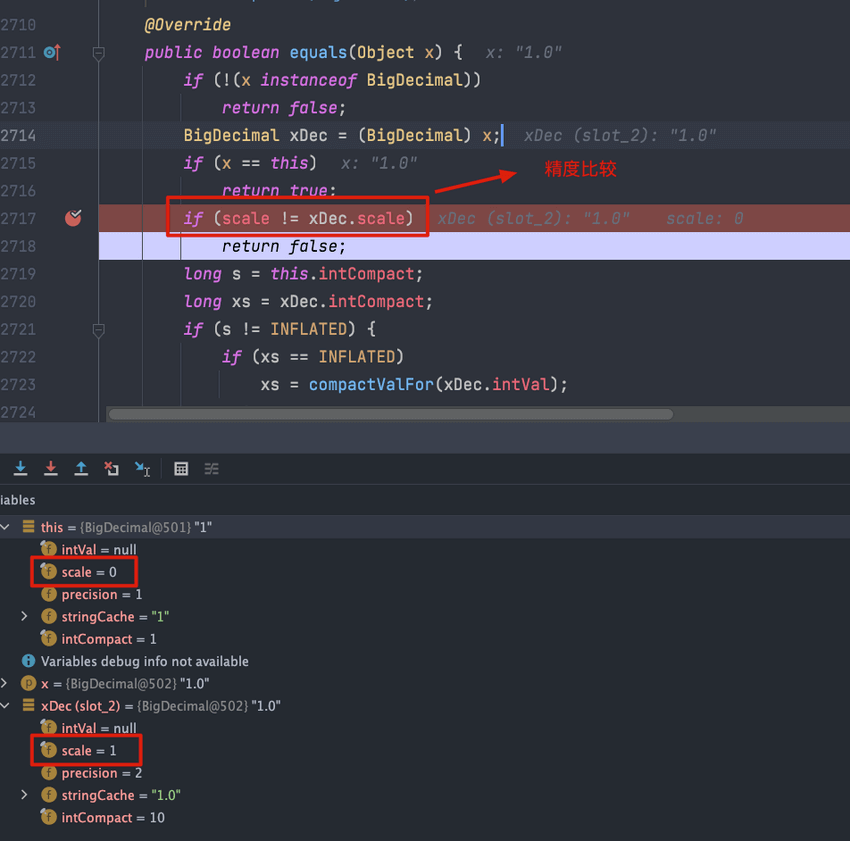
`BigDecimal` 使用 `equals()` 方法进行等值比较出现问题的代码示例:
@@ -156,7 +156,7 @@ System.out.println(a.equals(b));//false
1.0 的 scale 是 1,1 的 scale 是 0,因此 `a.equals(b)` 的结果是 false。
-
+
`compareTo()` 方法可以比较两个 `BigDecimal` 的值,如果相等就返回 0,如果第 1 个数比第 2 个数大则返回 1,反之返回-1。
diff --git a/docs/java/basis/generics-and-wildcards.md b/docs/java/basis/generics-and-wildcards.md
index d9d18fd7..9db8fef8 100644
--- a/docs/java/basis/generics-and-wildcards.md
+++ b/docs/java/basis/generics-and-wildcards.md
@@ -9,11 +9,11 @@ tag:
[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) 的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn/#/) 的补充完善,两者可以配合使用。
-
+
[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7)只是星球内部众多资料中的一个,星球还有很多其他优质资料比如[专属专栏](https://javaguide.cn/zhuanlan/)、Java 编程视频、PDF 资料。
-
+
最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
@@ -25,7 +25,7 @@ tag:
@@ -35,6 +35,6 @@ tag:
\ No newline at end of file
diff --git a/docs/java/basis/java-basic-questions-01.md b/docs/java/basis/java-basic-questions-01.md
index fd3fb2c4..d0971f17 100644
--- a/docs/java/basis/java-basic-questions-01.md
+++ b/docs/java/basis/java-basic-questions-01.md
@@ -41,7 +41,7 @@ Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不
除了我们平时最常用的 HotSpot VM 外,还有 J9 VM、Zing VM、JRockit VM 等 JVM 。维基百科上就有常见 JVM 的对比:[Comparison of Java virtual machines](https://en.wikipedia.org/wiki/Comparison_of_Java_virtual_machines) ,感兴趣的可以去看看。并且,你可以在 [Java SE Specifications](https://docs.oracle.com/javase/specs/index.html) 上找到各个版本的 JDK 对应的 JVM 规范。
-
+
#### JDK 和 JRE
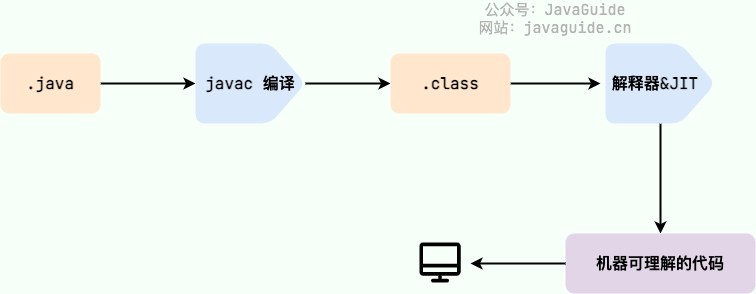
@@ -57,7 +57,7 @@ JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有
**Java 程序从源代码到运行的过程如下图所示:**
-
+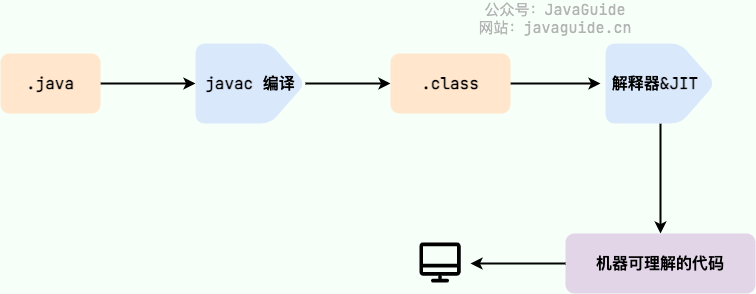
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT(just-in-time compilation) 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
@@ -78,7 +78,7 @@ AOT 可以提前编译节省启动时间,那为什么不全部使用这种编
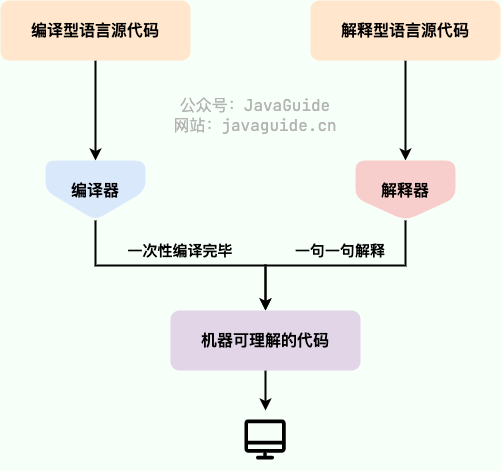
- **编译型** :[编译型语言](https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E8%AA%9E%E8%A8%80) 会通过[编译器](https://zh.wikipedia.org/wiki/%E7%B7%A8%E8%AD%AF%E5%99%A8)将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
- **解释型** :[解释型语言](https://zh.wikipedia.org/wiki/%E7%9B%B4%E8%AD%AF%E8%AA%9E%E8%A8%80)会通过[解释器](https://zh.wikipedia.org/wiki/直譯器)一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
-
+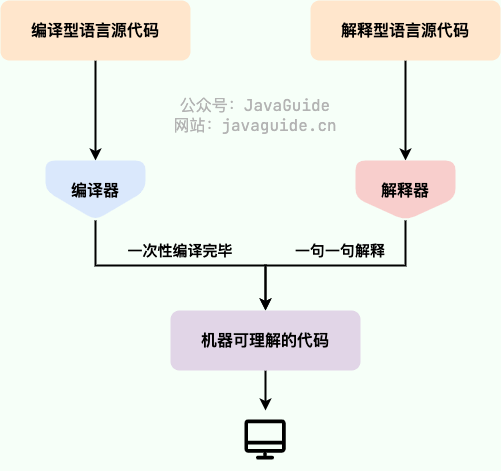
根据维基百科介绍:
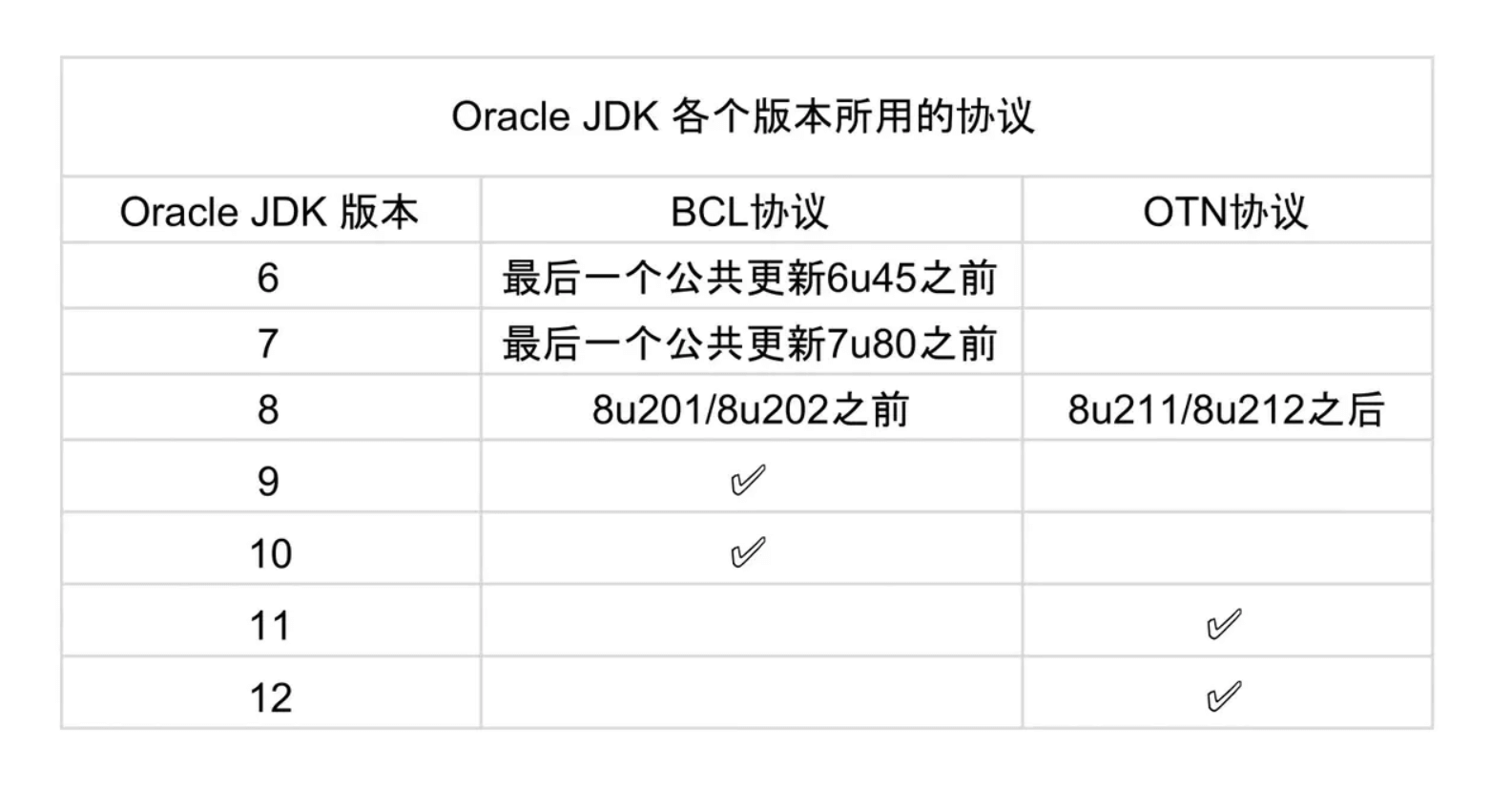
@@ -126,14 +126,14 @@ AOT 可以提前编译节省启动时间,那为什么不全部使用这种编
>
> 基于以上这些原因,OpenJDK 还是有存在的必要的!
-
+
🌈 拓展一下:
- BCL 协议(Oracle Binary Code License Agreement): 可以使用 JDK(支持商用),但是不能进行修改。
- OTN 协议(Oracle Technology Network License Agreement): 11 及之后新发布的 JDK 用的都是这个协议,可以自己私下用,但是商用需要付费。
-
+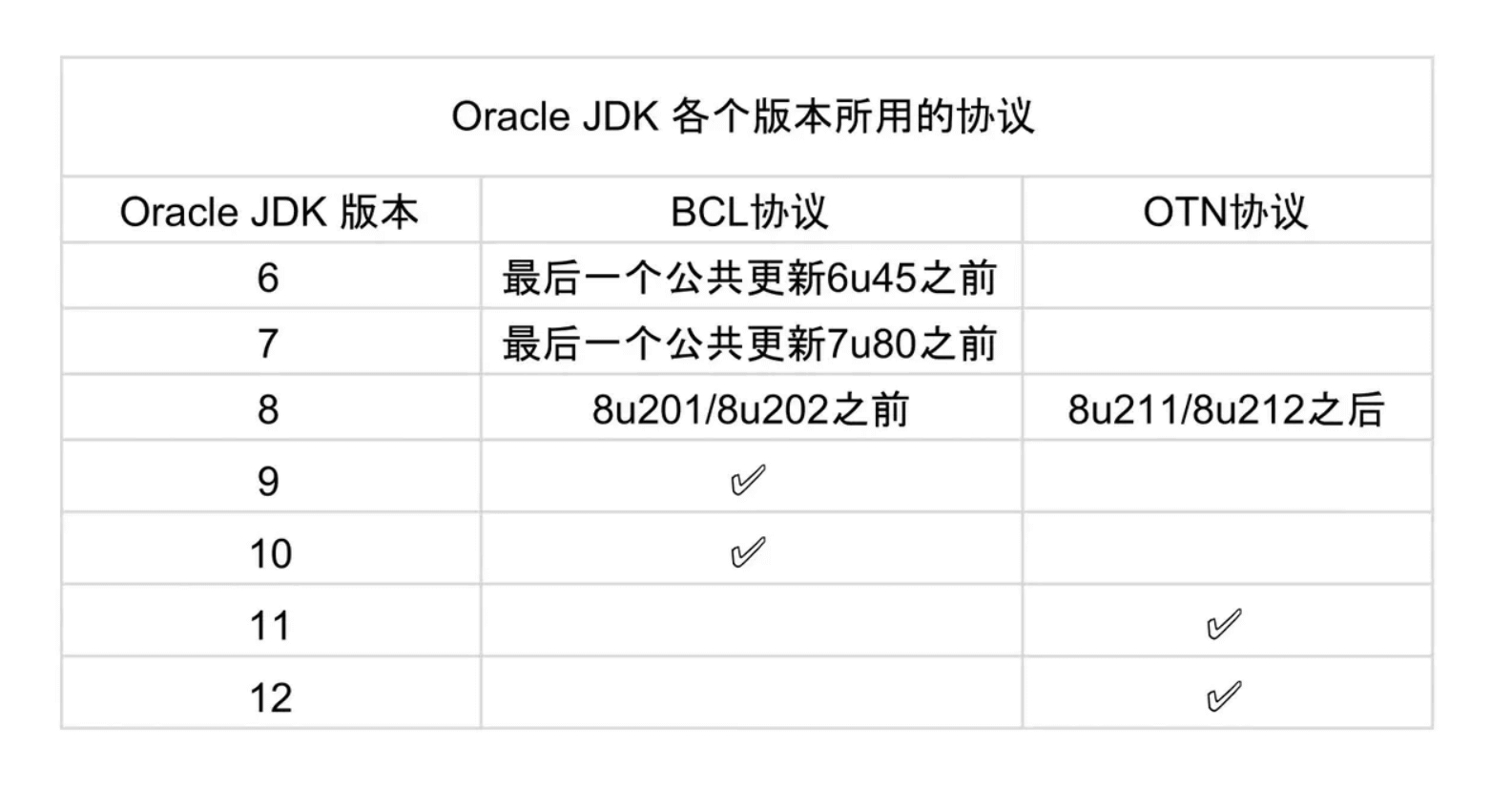
相关阅读 👍:[《Differences Between Oracle JDK and OpenJDK》](https://www.baeldung.com/oracle-jdk-vs-openjdk)
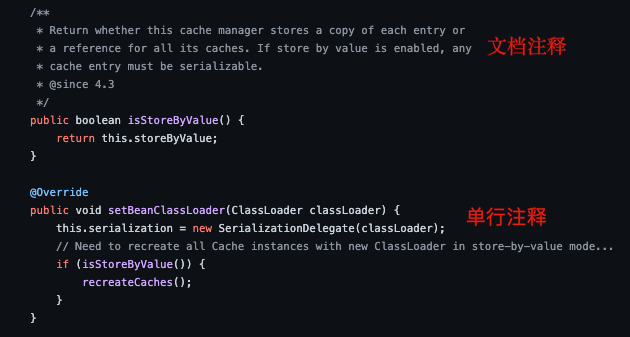
@@ -163,7 +163,7 @@ Java 中的注释有三种:
用的比较多的还是单行注释和文档注释,多行注释在实际开发中使用的相对较少。
-
+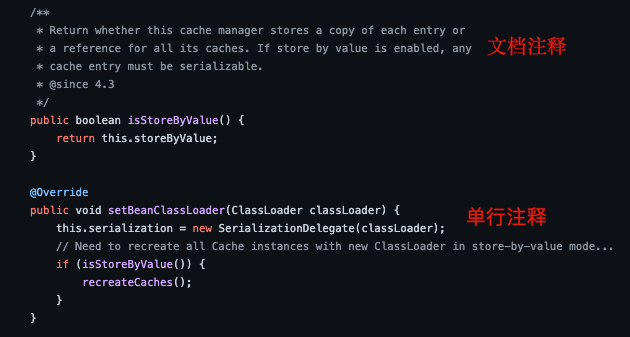
在我们编写代码的时候,如果代码量比较少,我们自己或者团队其他成员还可以很轻易地看懂代码,但是当项目结构一旦复杂起来,我们就需要用到注释了。注释并不会执行(编译器在编译代码之前会把代码中的所有注释抹掉,字节码中不保留注释),是我们程序员写给自己看的,注释是你的代码说明书,能够帮助看代码的人快速地理清代码之间的逻辑关系。因此,在写程序的时候随手加上注释是一个非常好的习惯。
diff --git a/docs/java/basis/java-basic-questions-02.md b/docs/java/basis/java-basic-questions-02.md
index a011238a..17ce504b 100644
--- a/docs/java/basis/java-basic-questions-02.md
+++ b/docs/java/basis/java-basic-questions-02.md
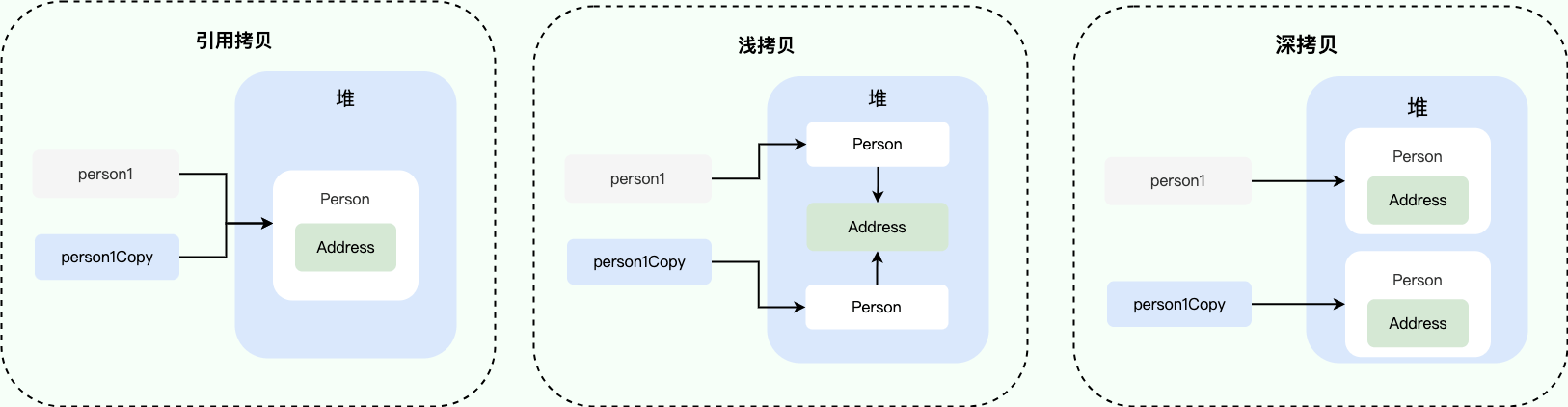
@@ -209,7 +209,7 @@ System.out.println(person1.getAddress() == person1Copy.getAddress());
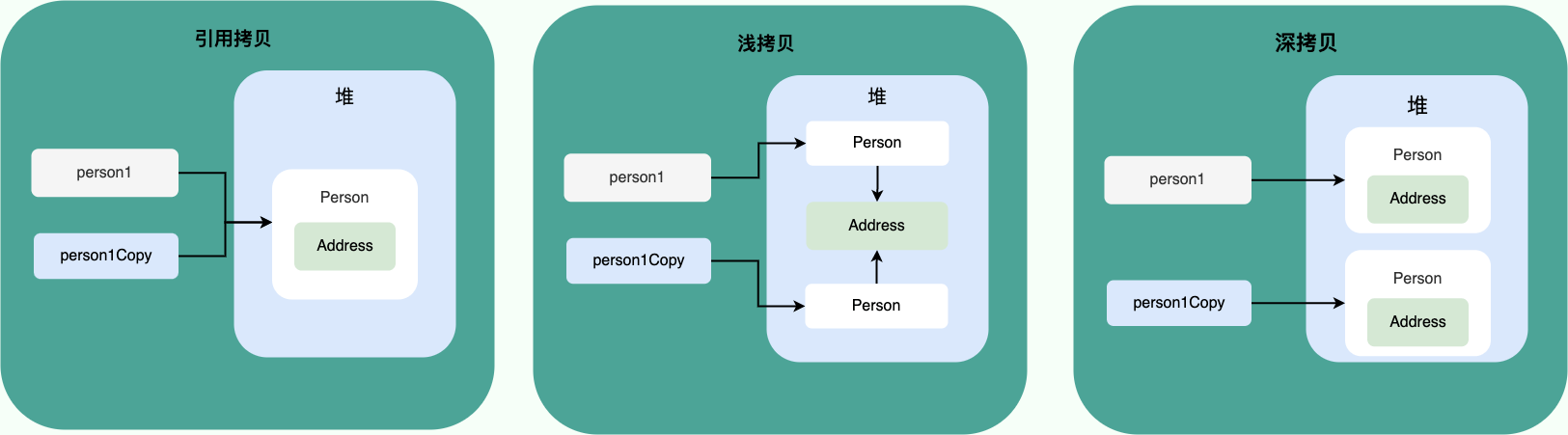
我专门画了一张图来描述浅拷贝、深拷贝、引用拷贝:
-
+
## Java 常见类
@@ -473,7 +473,7 @@ public final class String implements java.io.Serializable, Comparable
, C
>
> JDK 官方就说了绝大部分字符串对象只包含 Latin-1 可表示的字符。
>
-> 
+> 
>
> 如果字符串中包含的汉字超过 Latin-1 可表示范围内的字符,`byte` 和 `char` 所占用的空间是一样的。
>
@@ -492,7 +492,7 @@ String str4 = str1 + str2 + str3;
上面的代码对应的字节码如下:
-
+
可以看出,字符串对象通过“+”的字符串拼接方式,实际上是通过 `StringBuilder` 调用 `append()` 方法实现的,拼接完成之后调用 `toString()` 得到一个 `String` 对象 。
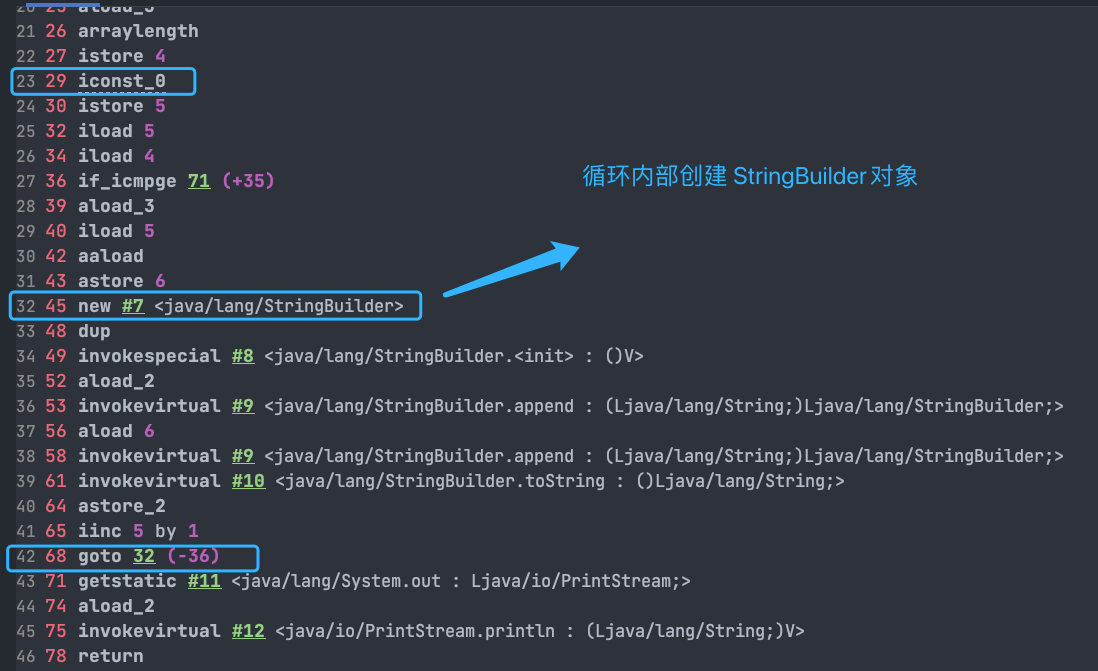
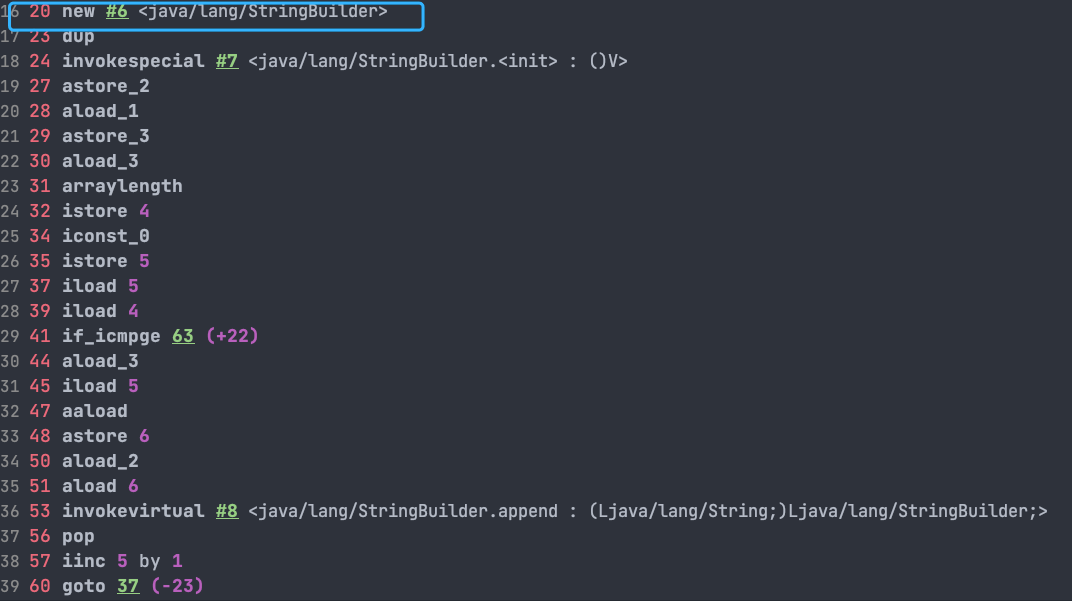
@@ -509,7 +509,7 @@ System.out.println(s);
`StringBuilder` 对象是在循环内部被创建的,这意味着每循环一次就会创建一个 `StringBuilder` 对象。
-
+
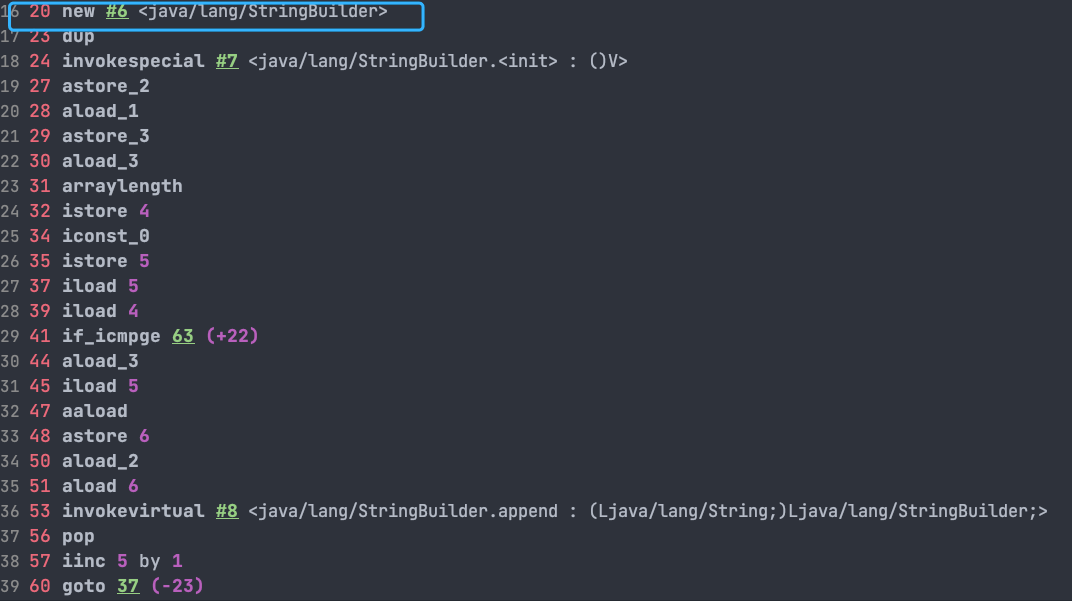
如果直接使用 `StringBuilder` 对象进行字符串拼接的话,就不会存在这个问题了。
@@ -522,7 +522,7 @@ for (String value : arr) {
System.out.println(s);
```
-
+
如果你使用 IDEA 的话,IDEA 自带的代码检查机制也会提示你修改代码。
@@ -559,7 +559,7 @@ String s1 = new String("abc");
对应的字节码:
-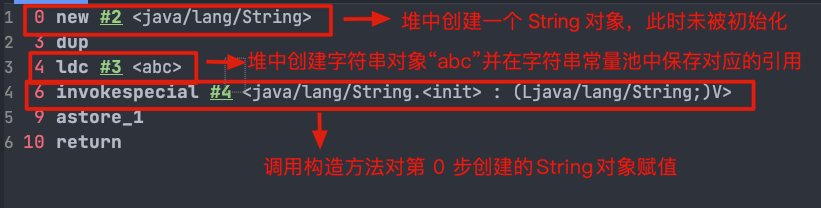
+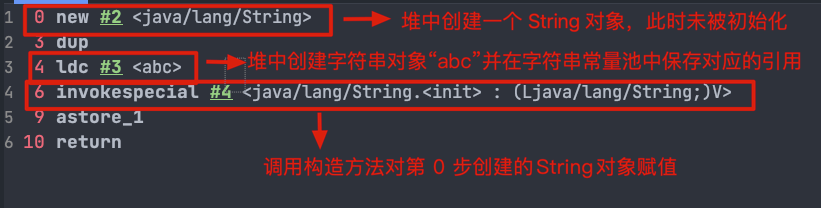
`ldc` 命令用于判断字符串常量池中是否保存了对应的字符串对象的引用,如果保存了的话直接返回,如果没有保存的话,会在堆中创建对应的字符串对象并将该字符串对象的引用保存到字符串常量池中。
@@ -576,7 +576,7 @@ String s2 = new String("abc");
对应的字节码:
-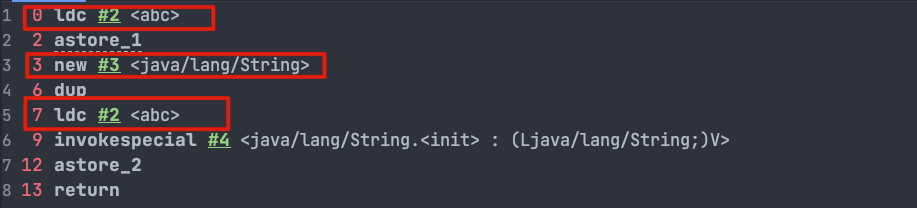
+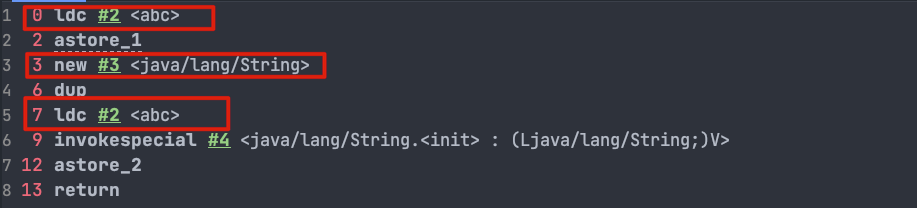
这里就不对上面的字节码进行详细注释了,7 这个位置的 `ldc` 命令不会在堆中创建新的字符串对象“abc”,这是因为 0 这个位置已经执行了一次 `ldc` 命令,已经在堆中创建过一次字符串对象“abc”了。7 这个位置执行 `ldc` 命令会直接返回字符串常量池中字符串对象“abc”对应的引用。
@@ -624,13 +624,13 @@ System.out.println(str4 == str5);//false
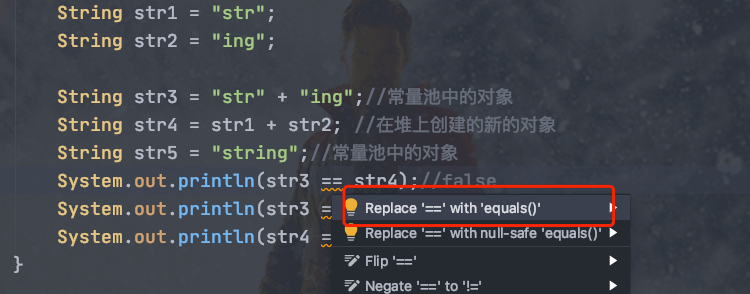
> **注意** :比较 String 字符串的值是否相等,可以使用 `equals()` 方法。 `String` 中的 `equals` 方法是被重写过的。 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是字符串的值是否相等。如果你使用 `==` 比较两个字符串是否相等的话,IDEA 还是提示你使用 `equals()` 方法替换。
-
+
**对于编译期可以确定值的字符串,也就是常量字符串 ,jvm 会将其存入字符串常量池。并且,字符串常量拼接得到的字符串常量在编译阶段就已经被存放字符串常量池,这个得益于编译器的优化。**
在编译过程中,Javac 编译器(下文中统称为编译器)会进行一个叫做 **常量折叠(Constant Folding)** 的代码优化。《深入理解 Java 虚拟机》中是也有介绍到:
-
+
常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
diff --git a/docs/java/basis/java-basic-questions-03.md b/docs/java/basis/java-basic-questions-03.md
index 4a7e6b1a..3525eda3 100644
--- a/docs/java/basis/java-basic-questions-03.md
+++ b/docs/java/basis/java-basic-questions-03.md
@@ -16,7 +16,7 @@ head:
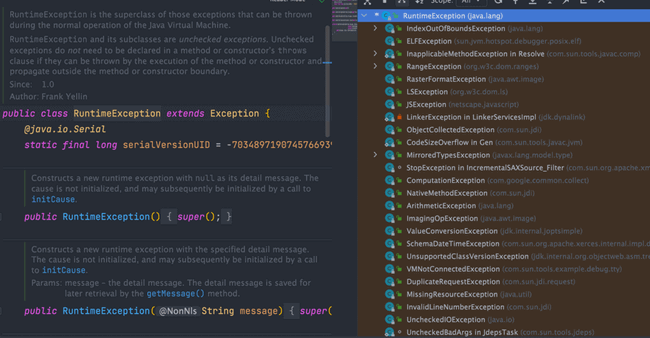
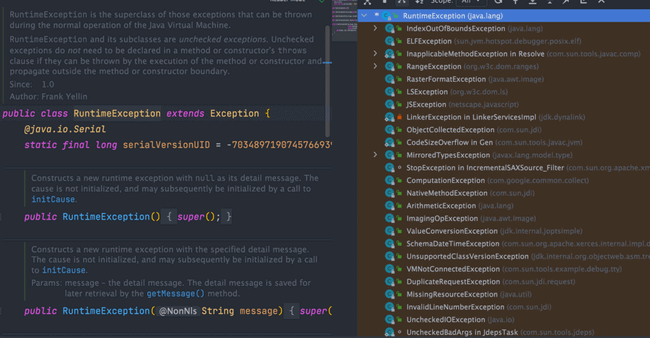
**Java 异常类层次结构图概览** :
-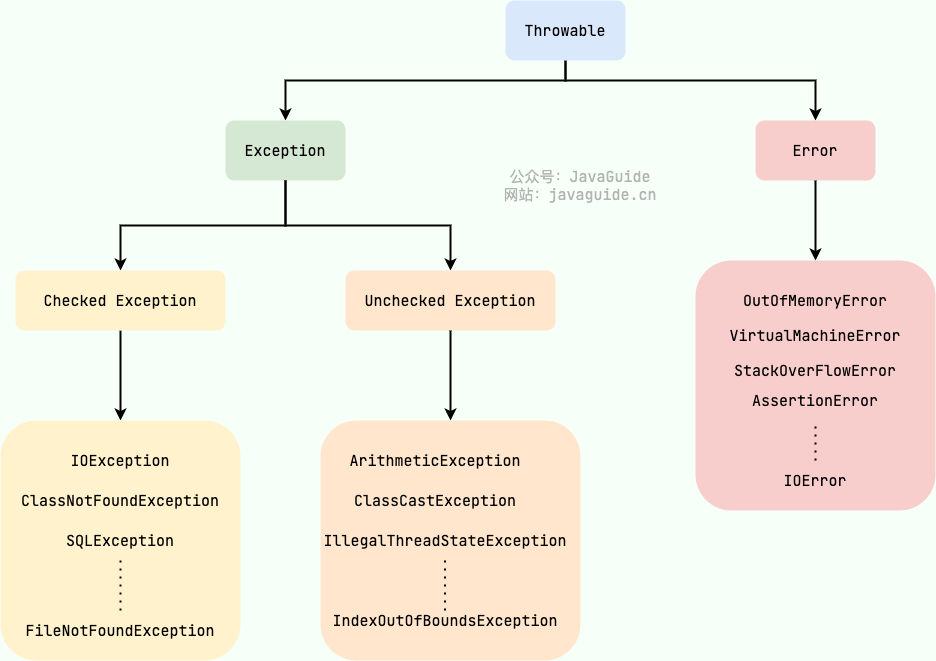
+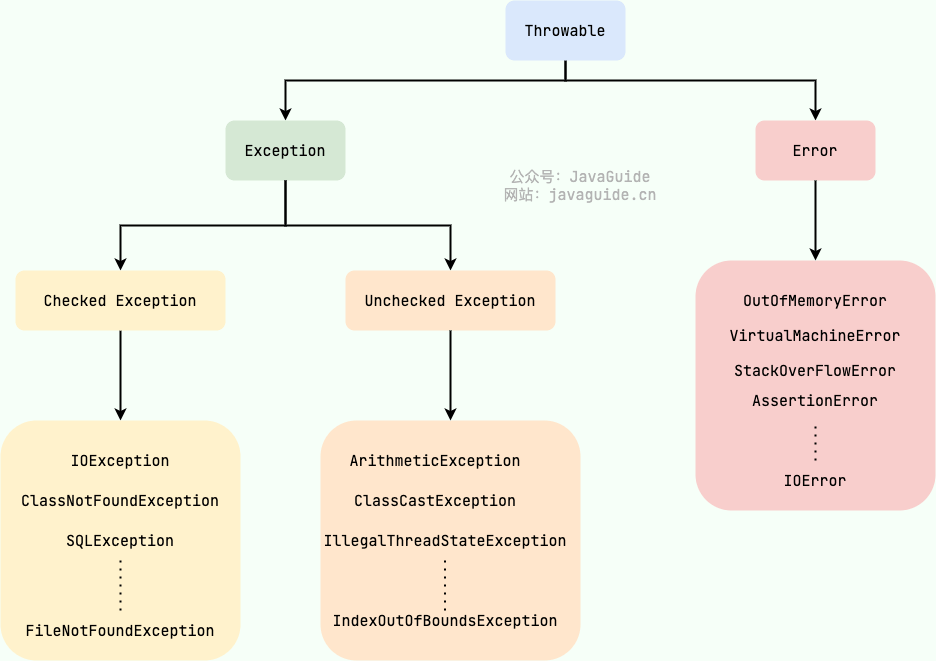
### Exception 和 Error 有什么区别?
@@ -31,7 +31,7 @@ head:
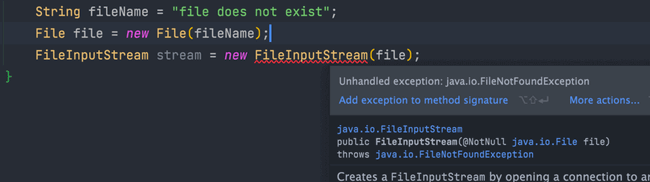
比如下面这段 IO 操作的代码:
-
+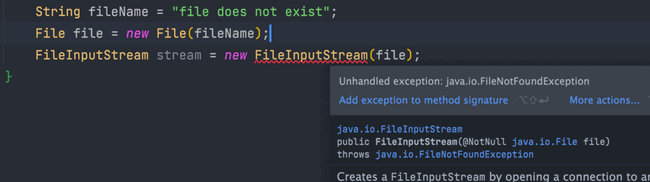
除了`RuntimeException`及其子类以外,其他的`Exception`类及其子类都属于受检查异常 。常见的受检查异常有: IO 相关的异常、`ClassNotFoundException` 、`SQLException`...。
@@ -49,7 +49,7 @@ head:
- `UnsupportedOperationException`(不支持的操作错误比如重复创建同一用户)
- ......
-
+
### Throwable 类常用方法有哪些?
@@ -415,7 +415,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
-
+
### SPI 和 API 有什么区别?
@@ -423,7 +423,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
-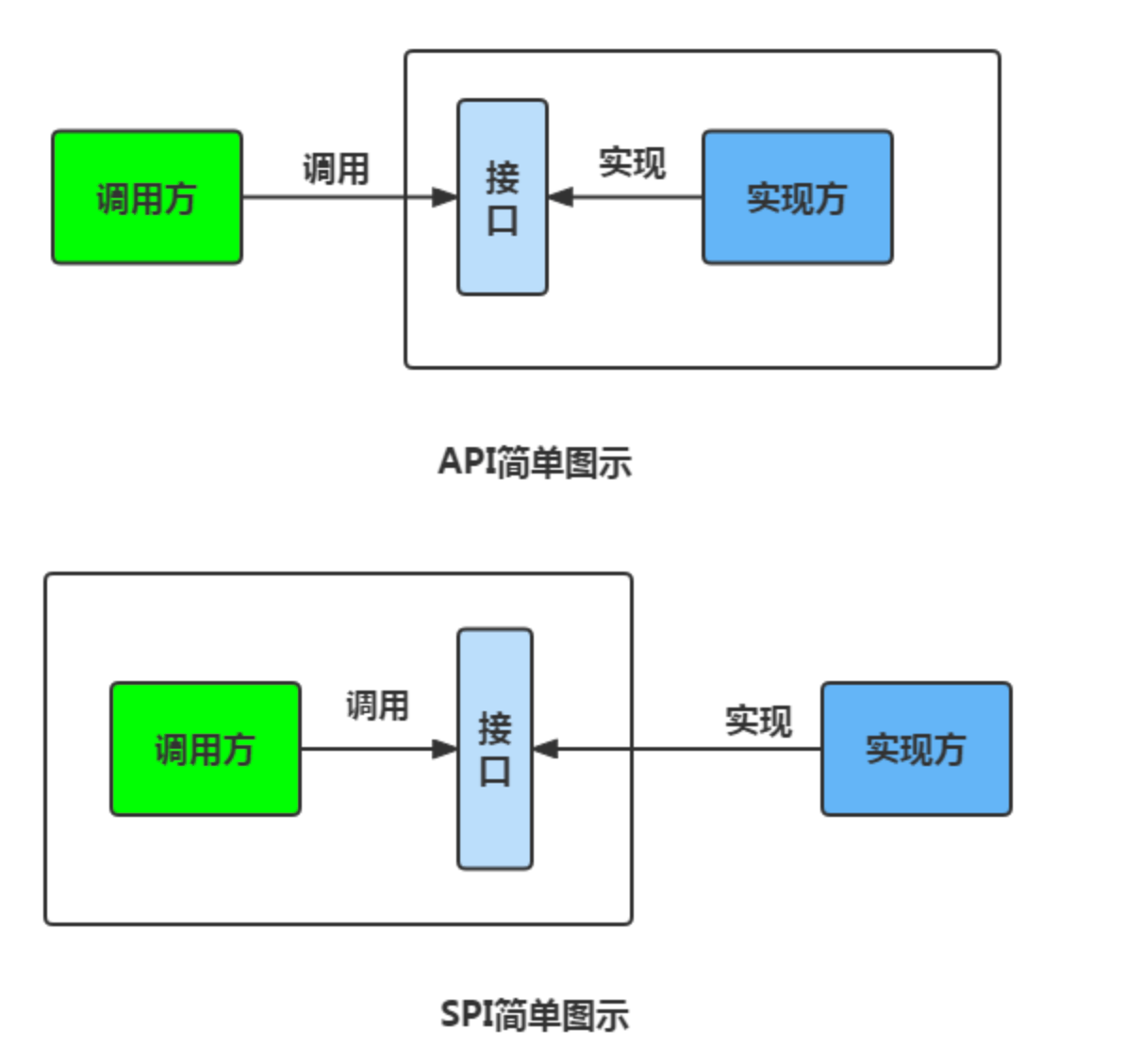
+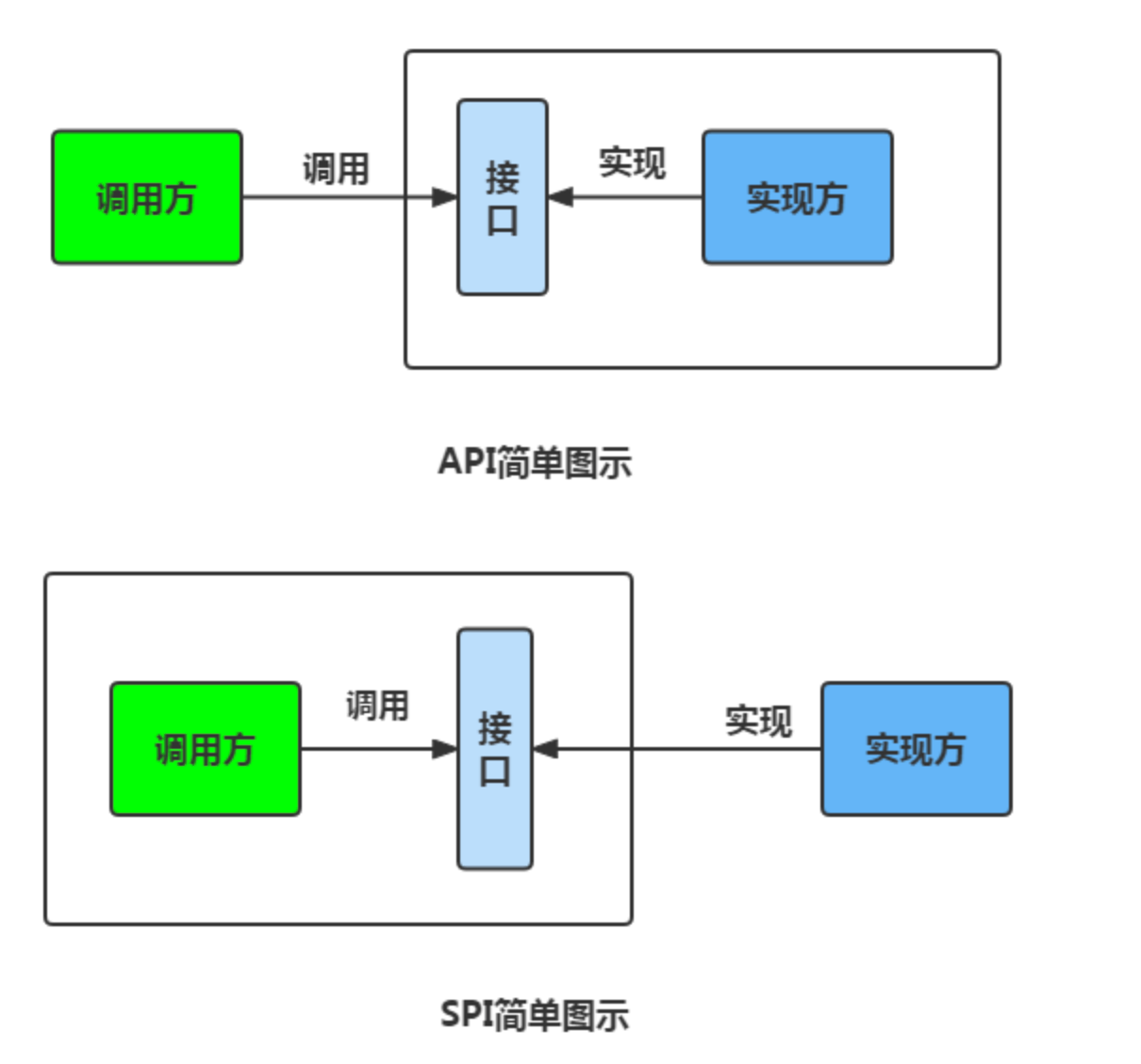
一般模块之间都是通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
@@ -481,7 +481,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
3. 网络层
4. 网络接口层
-
+
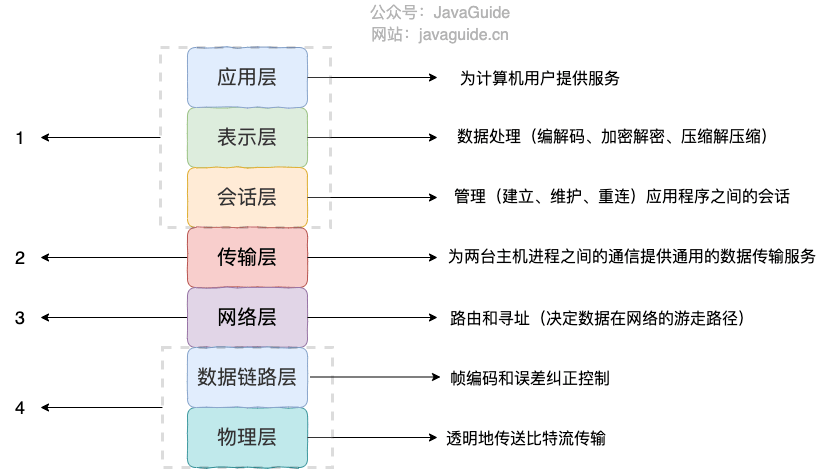
如上图所示,OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。这不就对应的是序列化和反序列化么?
diff --git a/docs/java/basis/proxy.md b/docs/java/basis/proxy.md
index 5d27281d..4eafe2d7 100644
--- a/docs/java/basis/proxy.md
+++ b/docs/java/basis/proxy.md
@@ -13,7 +13,7 @@ tag:
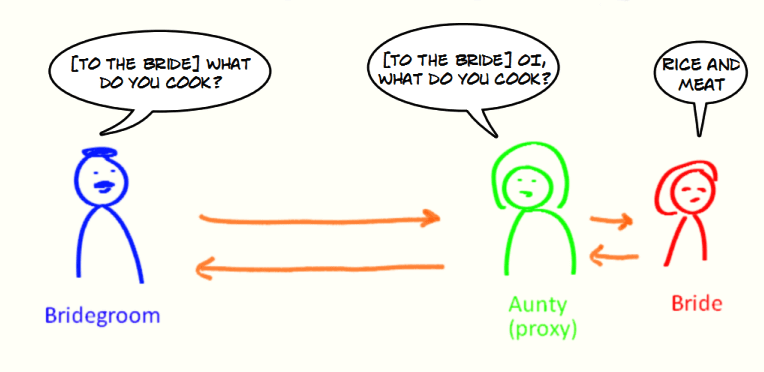
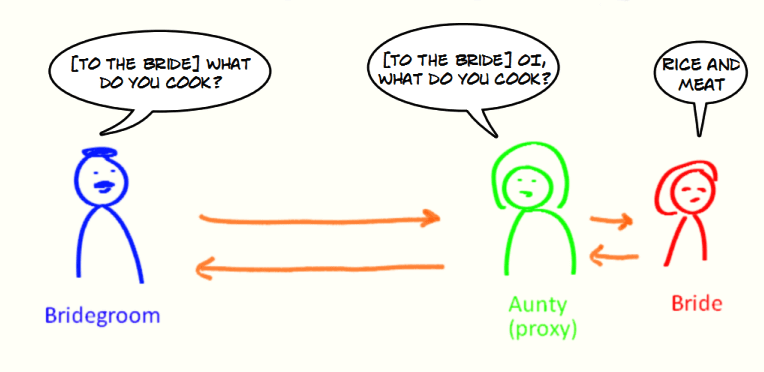
举个例子:新娘找来了自己的姨妈来代替自己处理新郎的提问,新娘收到的提问都是经过姨妈处理过滤之后的。姨妈在这里就可以看作是代理你的代理对象,代理的行为(方法)是接收和回复新郎的提问。
-
+
https://medium.com/@mithunsasidharan/understanding-the-proxy-design-pattern-5e63fe38052a
diff --git a/docs/java/basis/serialization.md b/docs/java/basis/serialization.md
index e6645178..30d4d395 100644
--- a/docs/java/basis/serialization.md
+++ b/docs/java/basis/serialization.md
@@ -42,7 +42,7 @@ tag:
3. 网络层
4. 网络接口层
-
+
如上图所示,OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。这不就对应的是序列化和反序列化么?
diff --git a/docs/java/basis/spi.md b/docs/java/basis/spi.md
index 99eedae6..ac7bea3b 100644
--- a/docs/java/basis/spi.md
+++ b/docs/java/basis/spi.md
@@ -28,7 +28,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
-
+
### SPI 和 API 有什么区别?
@@ -36,7 +36,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
-
+
一般模块之间都是通过通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
@@ -50,7 +50,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
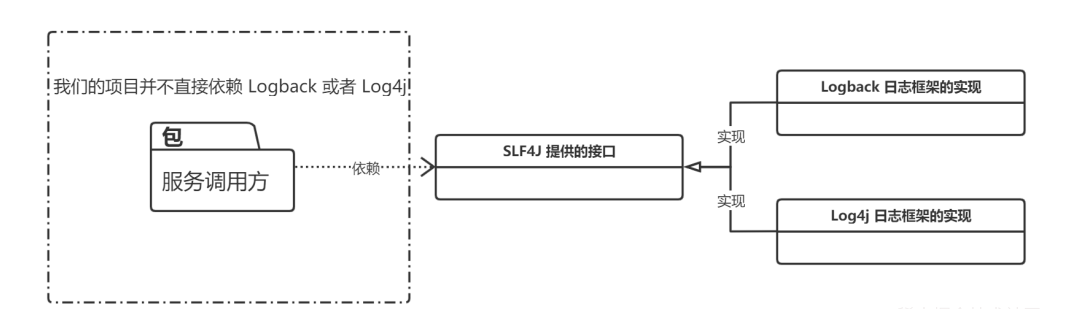
SLF4J (Simple Logging Facade for Java)是 Java 的一个日志门面(接口),其具体实现有几种,比如:Logback、Log4j、Log4j2 等等,而且还可以切换,在切换日志具体实现的时候我们是不需要更改项目代码的,只需要在 Maven 依赖里面修改一些 pom 依赖就好了。
-
+
这就是依赖 SPI 机制实现的,那我们接下来就实现一个简易版本的日志框架。
@@ -222,11 +222,11 @@ public class Logback implements Logger {
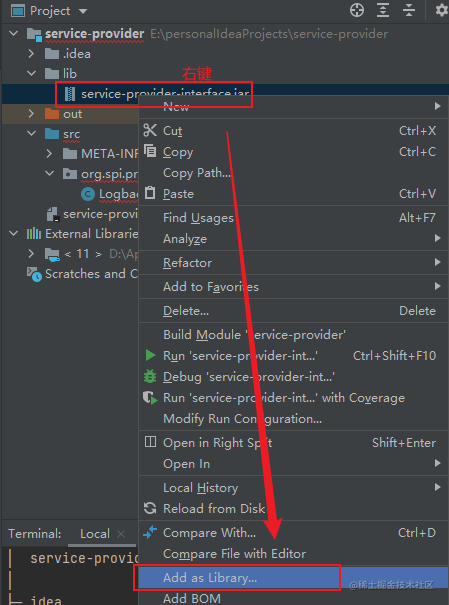
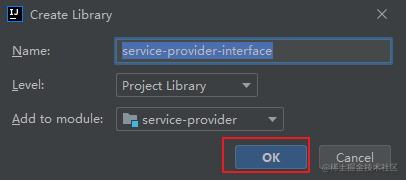
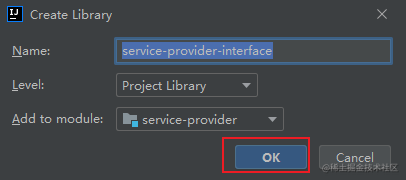
新建 lib 目录,然后将 jar 包拷贝过来,再添加到项目中。
-
+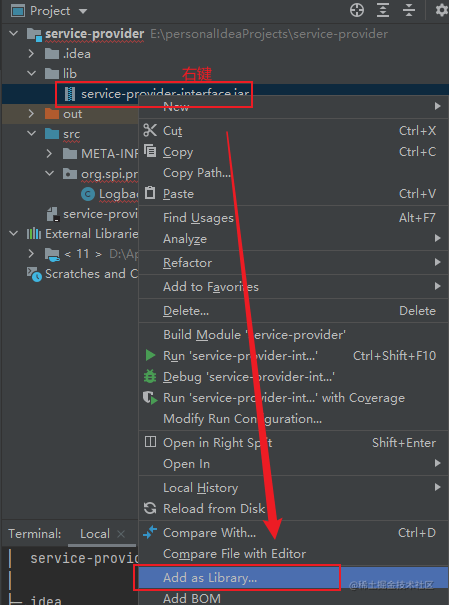
再点击 OK 。
-
+
接下来就可以在项目中导入 jar 包里面的一些类和方法了,就像 JDK 工具类导包一样的。
@@ -246,7 +246,7 @@ public class Logback implements Logger {
然后先导入 `Logger` 的接口 jar 包,再导入具体的实现类的 jar 包。
-
+
新建 Main 方法测试:
diff --git a/docs/java/basis/syntactic-sugar.md b/docs/java/basis/syntactic-sugar.md
index c4251538..5b643045 100644
--- a/docs/java/basis/syntactic-sugar.md
+++ b/docs/java/basis/syntactic-sugar.md
@@ -25,7 +25,7 @@ head:
**语法糖(Syntactic Sugar)** 也称糖衣语法,是英国计算机学家 Peter.J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。简而言之,语法糖让程序更加简洁,有更高的可读性。
-
+
> 有意思的是,在编程领域,除了语法糖,还有语法盐和语法糖精的说法,篇幅有限这里不做扩展了。
diff --git a/docs/java/basis/unsafe.md b/docs/java/basis/unsafe.md
index de89c767..e4236e90 100644
--- a/docs/java/basis/unsafe.md
+++ b/docs/java/basis/unsafe.md
@@ -20,7 +20,7 @@ tag:
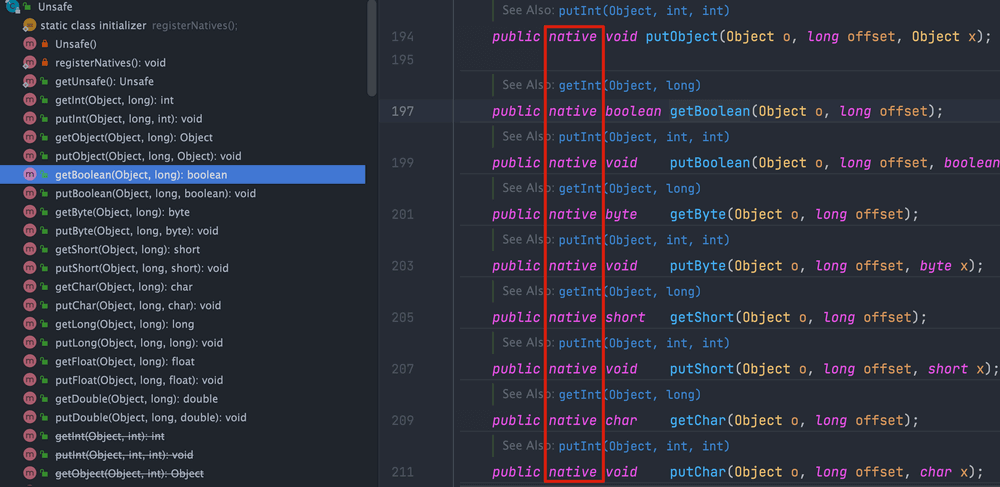
另外,`Unsafe` 提供的这些功能的实现需要依赖本地方法(Native Method)。你可以将本地方法看作是 Java 中使用其他编程语言编写的方法。本地方法使用 **`native`** 关键字修饰,Java 代码中只是声明方法头,具体的实现则交给 **本地代码**。
-
+
**为什么要使用本地方法呢?**
@@ -163,11 +163,11 @@ addr3: 2433733894944
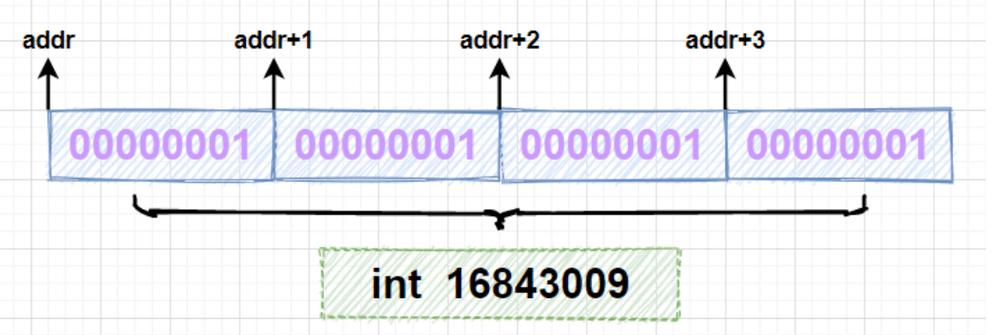
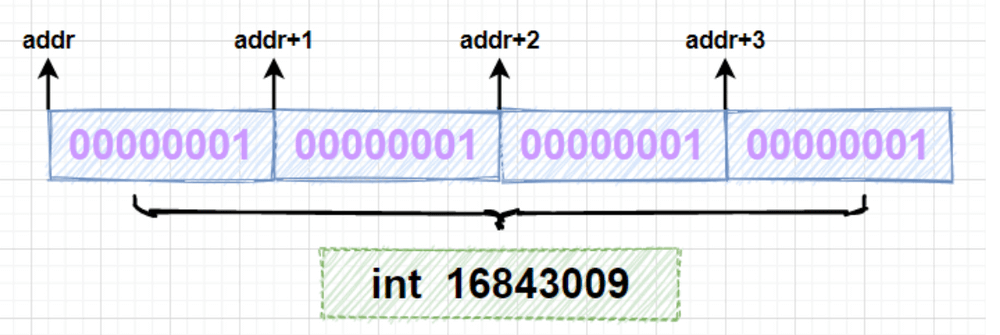
你可以通过下图理解这个过程:
-
+
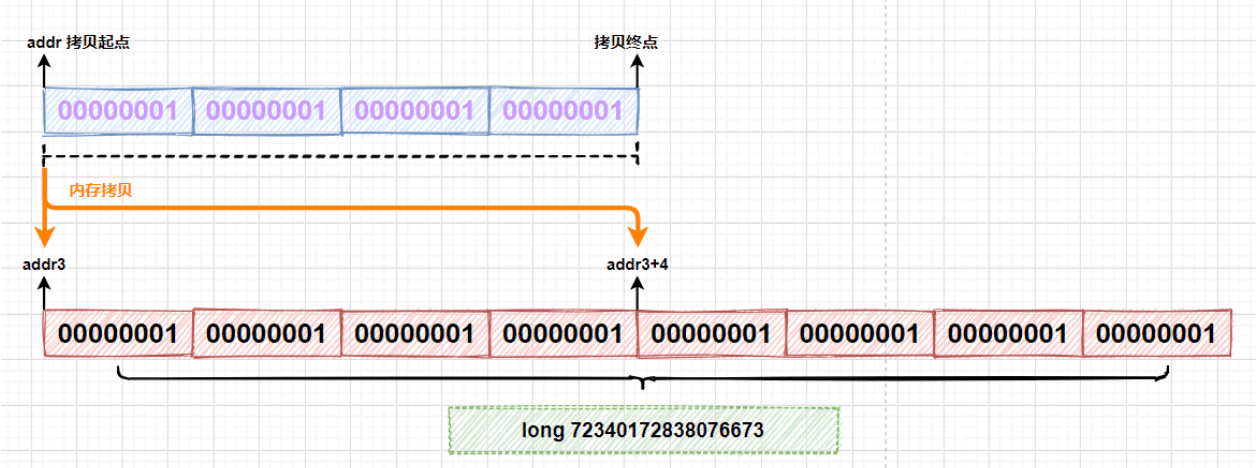
在代码中调用`reallocateMemory`方法重新分配了一块 8 字节长度的内存空间,通过比较`addr`和`addr3`可以看到和之前申请的内存地址是不同的。在代码中的第二个 for 循环里,调用`copyMemory`方法进行了两次内存的拷贝,每次拷贝内存地址`addr`开始的 4 个字节,分别拷贝到以`addr3`和`addr3+4`开始的内存空间上:
-
+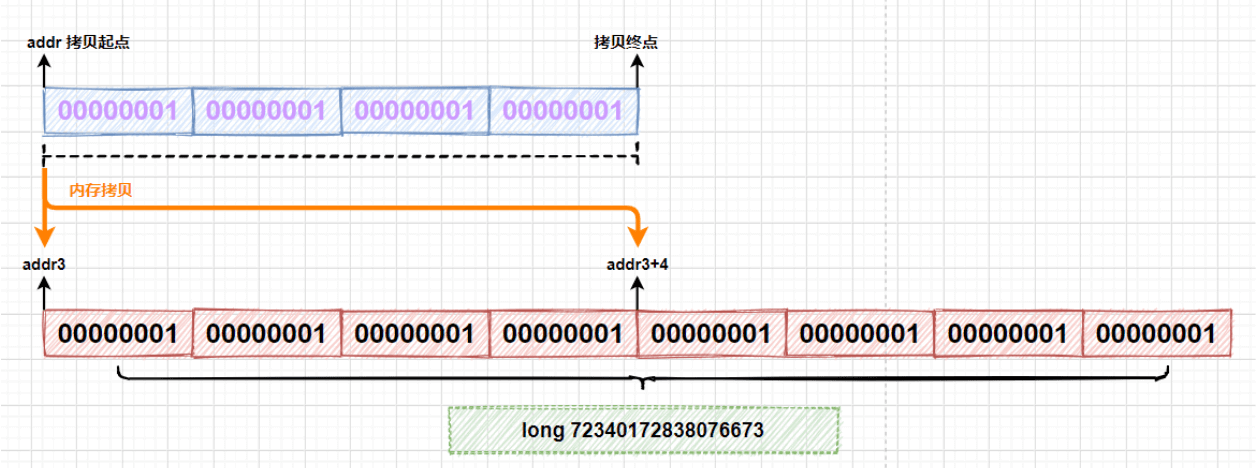
拷贝完成后,使用`getLong`方法一次性读取 8 个字节,得到`long`类型的值为 72340172838076673。
@@ -283,7 +283,7 @@ main thread end
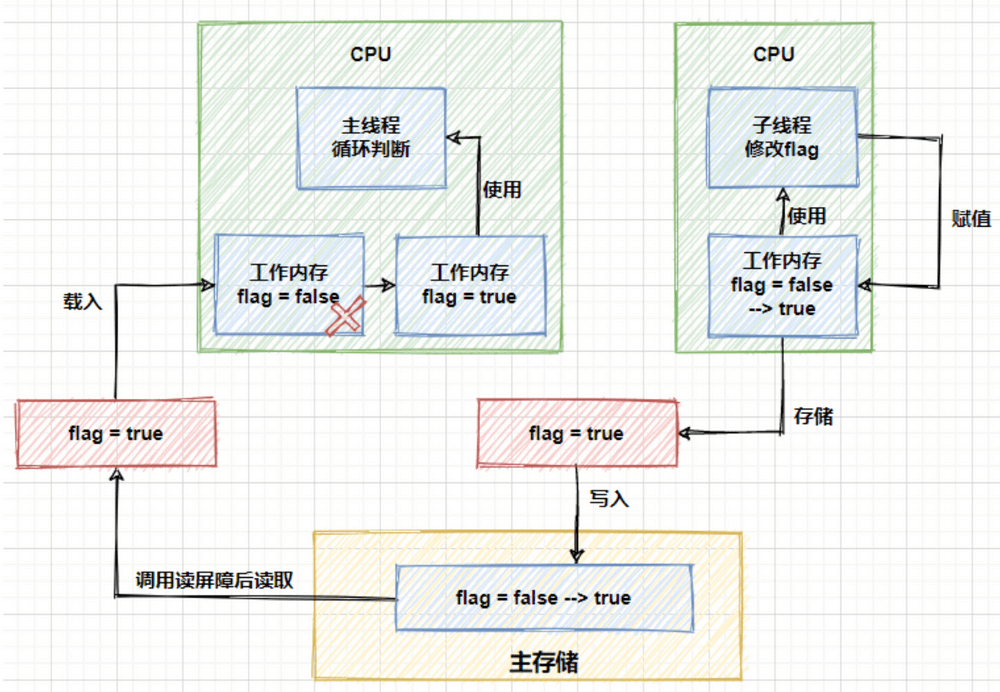
而如果删掉上面代码中的`loadFence`方法,那么主线程将无法感知到`flag`发生的变化,会一直在`while`中循环。可以用图来表示上面的过程:
-
+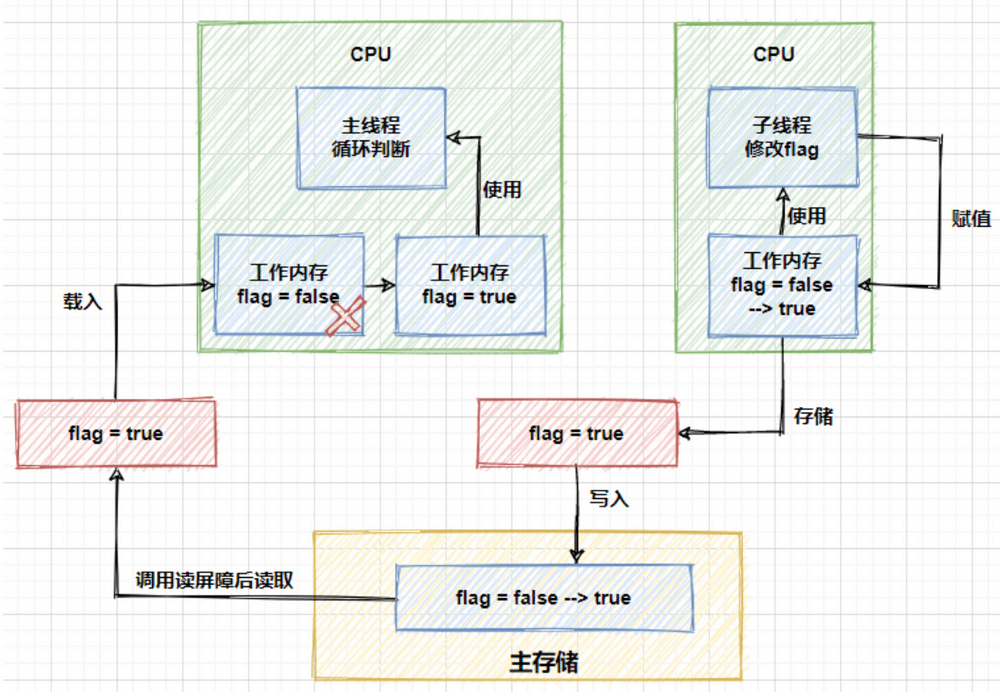
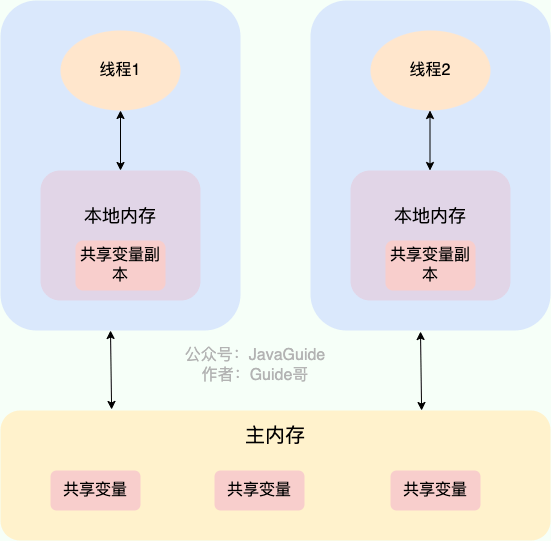
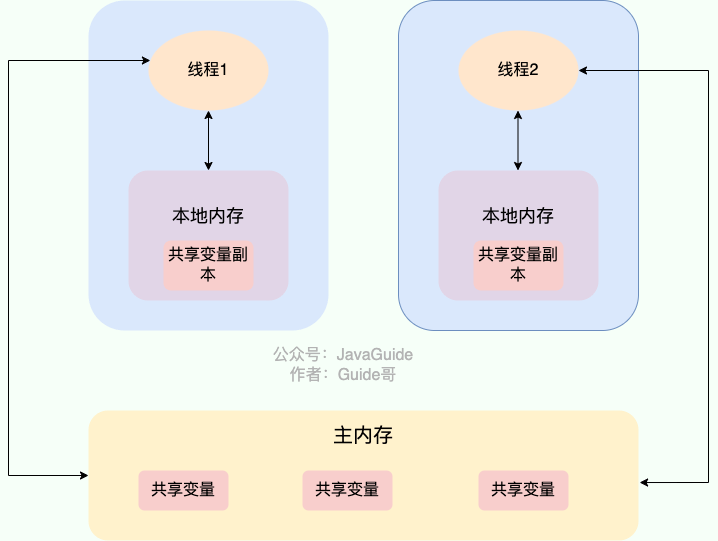
了解 Java 内存模型(`JMM`)的小伙伴们应该清楚,运行中的线程不是直接读取主内存中的变量的,只能操作自己工作内存中的变量,然后同步到主内存中,并且线程的工作内存是不能共享的。上面的图中的流程就是子线程借助于主内存,将修改后的结果同步给了主线程,进而修改主线程中的工作空间,跳出循环。
@@ -341,7 +341,7 @@ public native void putOrderedLong(Object o, long offset, long x);
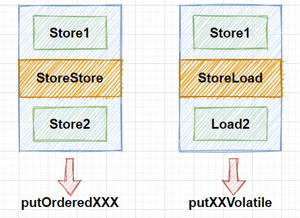
顺序写入与`volatile`写入的差别在于,在顺序写时加入的内存屏障类型为`StoreStore`类型,而在`volatile`写入时加入的内存屏障是`StoreLoad`类型,如下图所示:
-
+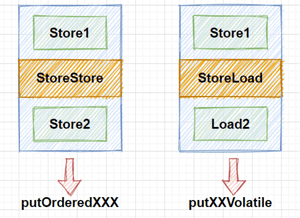
在有序写入方法中,使用的是`StoreStore`屏障,该屏障确保`Store1`立刻刷新数据到内存,这一操作先于`Store2`以及后续的存储指令操作。而在`volatile`写入中,使用的是`StoreLoad`屏障,该屏障确保`Store1`立刻刷新数据到内存,这一操作先于`Load2`及后续的装载指令,并且,`StoreLoad`屏障会使该屏障之前的所有内存访问指令,包括存储指令和访问指令全部完成之后,才执行该屏障之后的内存访问指令。
@@ -398,7 +398,7 @@ public native int arrayIndexScale(Class arrayClass);
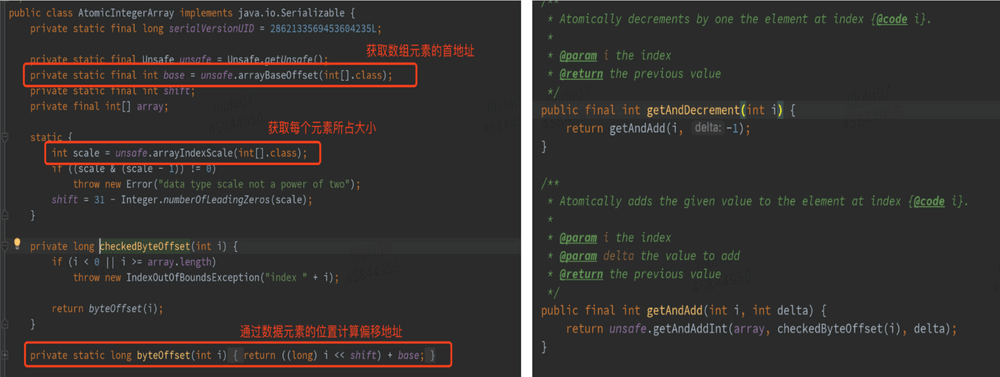
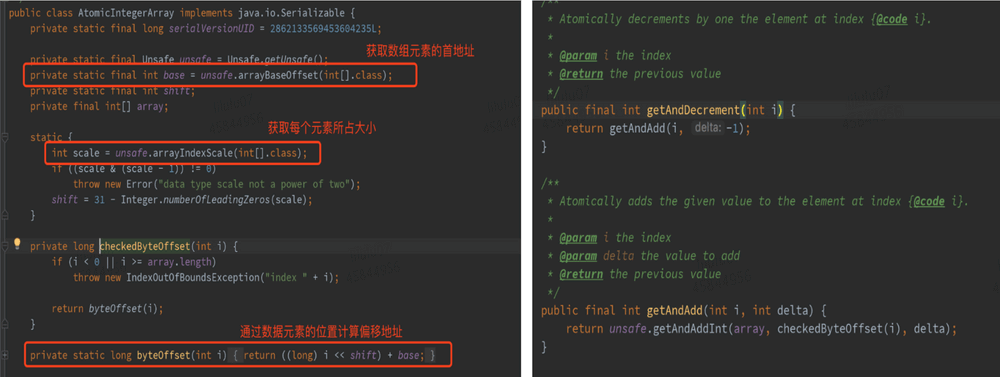
这两个与数据操作相关的方法,在 `java.util.concurrent.atomic` 包下的 `AtomicIntegerArray`(可以实现对 `Integer` 数组中每个元素的原子性操作)中有典型的应用,如下图 `AtomicIntegerArray` 源码所示,通过 `Unsafe` 的 `arrayBaseOffset` 、`arrayIndexScale` 分别获取数组首元素的偏移地址 `base` 及单个元素大小因子 `scale` 。后续相关原子性操作,均依赖于这两个值进行数组中元素的定位,如下图二所示的 `getAndAdd` 方法即通过 `checkedByteOffset` 方法获取某数组元素的偏移地址,而后通过 CAS 实现原子性操作。
-
+
### CAS 操作
@@ -473,7 +473,7 @@ private void increment(int x){
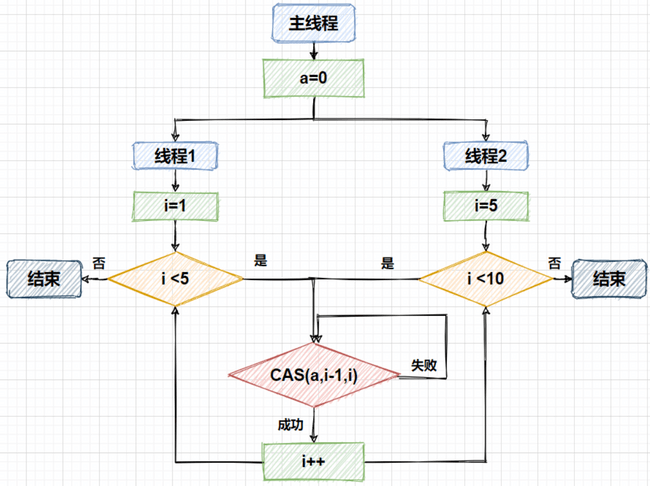
在上面的例子中,使用两个线程去修改`int`型属性`a`的值,并且只有在`a`的值等于传入的参数`x`减一时,才会将`a`的值变为`x`,也就是实现对`a`的加一的操作。流程如下所示:
-
+
需要注意的是,在调用`compareAndSwapInt`方法后,会直接返回`true`或`false`的修改结果,因此需要我们在代码中手动添加自旋的逻辑。在`AtomicInteger`类的设计中,也是采用了将`compareAndSwapInt`的结果作为循环条件,直至修改成功才退出死循环的方式来实现的原子性的自增操作。
@@ -565,7 +565,7 @@ unpark mainThread success
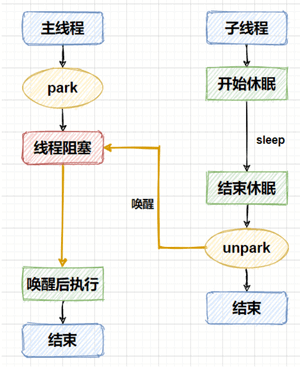
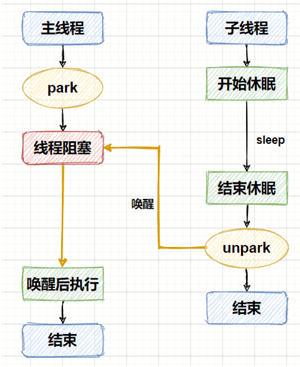
程序运行的流程也比较容易看懂,子线程开始运行后先进行睡眠,确保主线程能够调用`park`方法阻塞自己,子线程在睡眠 5 秒后,调用`unpark`方法唤醒主线程,使主线程能继续向下执行。整个流程如下图所示:
-
+
### Class 操作
@@ -644,7 +644,7 @@ private static void defineTest() {
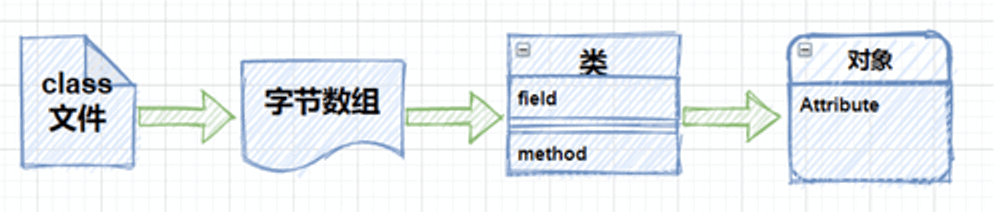
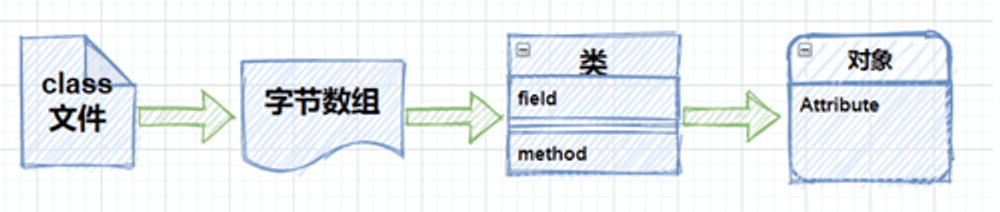
在上面的代码中,首先读取了一个`class`文件并通过文件流将它转化为字节数组,之后使用`defineClass`方法动态的创建了一个类,并在后续完成了它的实例化工作,流程如下图所示,并且通过这种方式创建的类,会跳过 JVM 的所有安全检查。
-
+
除了`defineClass`方法外,Unsafe 还提供了一个`defineAnonymousClass`方法:
diff --git a/docs/java/basis/why-there-only-value-passing-in-java.md b/docs/java/basis/why-there-only-value-passing-in-java.md
index 20c3cc8f..56083354 100644
--- a/docs/java/basis/why-there-only-value-passing-in-java.md
+++ b/docs/java/basis/why-there-only-value-passing-in-java.md
@@ -75,7 +75,7 @@ num2 = 20
在 `swap()` 方法中,`a`、`b` 的值进行交换,并不会影响到 `num1`、`num2`。因为,`a`、`b` 的值,只是从 `num1`、`num2` 的复制过来的。也就是说,a、b 相当于 `num1`、`num2` 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
-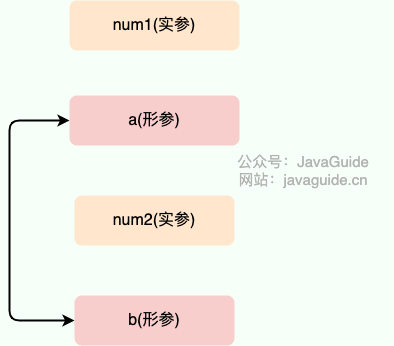
+
通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看案例2。
@@ -106,7 +106,7 @@ num2 = 20
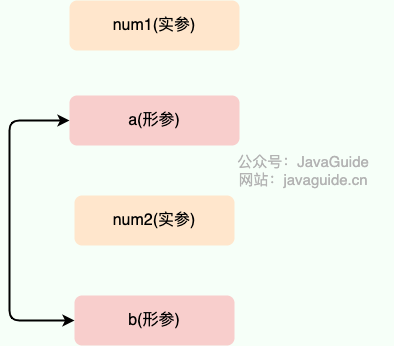
解析:
-
+
看了这个案例很多人肯定觉得 Java 对引用类型的参数采用的是引用传递。
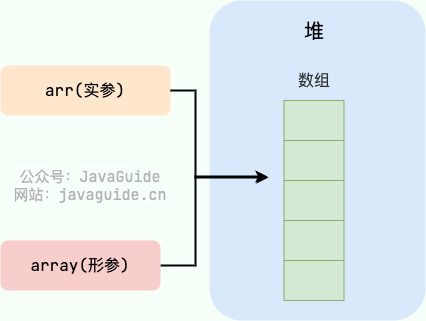
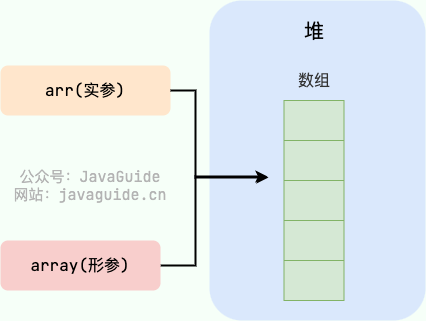
@@ -156,7 +156,7 @@ xiaoLi:小李
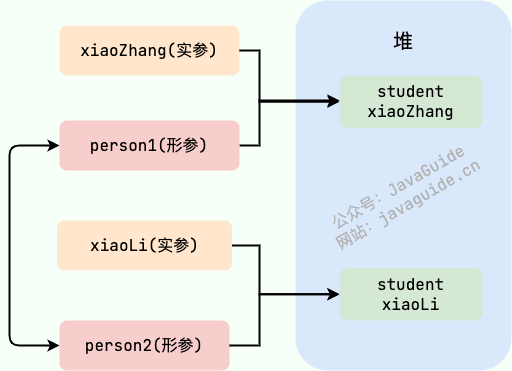
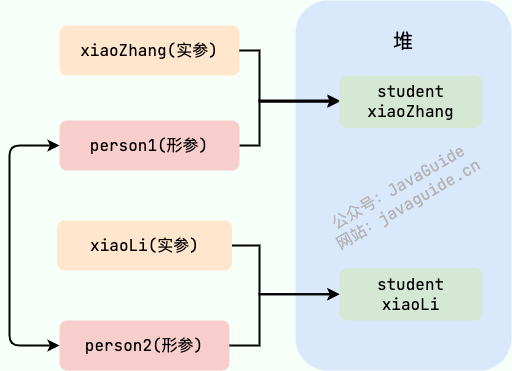
`swap` 方法的参数 `person1` 和 `person2` 只是拷贝的实参 `xiaoZhang` 和 `xiaoLi` 的地址。因此, `person1` 和 `person2` 的互换只是拷贝的两个地址的互换罢了,并不会影响到实参 `xiaoZhang` 和 `xiaoLi` 。
-
+
## 引用传递是怎么样的?
diff --git a/docs/java/collection/concurrent-hash-map-source-code.md b/docs/java/collection/concurrent-hash-map-source-code.md
index 4f15a139..8a5f4f3e 100644
--- a/docs/java/collection/concurrent-hash-map-source-code.md
+++ b/docs/java/collection/concurrent-hash-map-source-code.md
@@ -14,7 +14,7 @@ tag:
### 1. 存储结构
-
+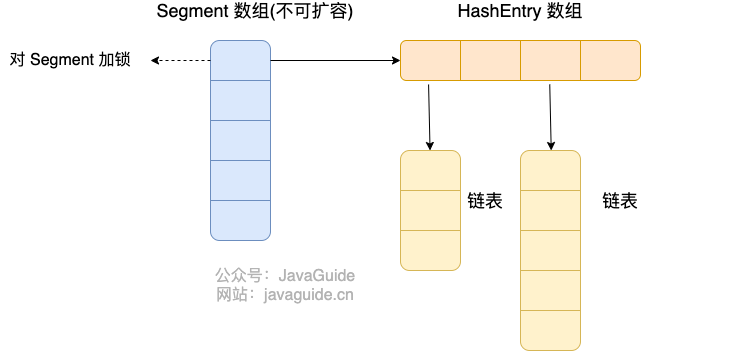
Java 7 中 `ConcurrentHashMap` 的存储结构如上图,`ConcurrnetHashMap` 由很多个 `Segment` 组合,而每一个 `Segment` 是一个类似于 `HashMap` 的结构,所以每一个 `HashMap` 的内部可以进行扩容。但是 `Segment` 的个数一旦**初始化就不能改变**,默认 `Segment` 的个数是 16 个,你也可以认为 `ConcurrentHashMap` 默认支持最多 16 个线程并发。
@@ -404,7 +404,7 @@ public V get(Object key) {
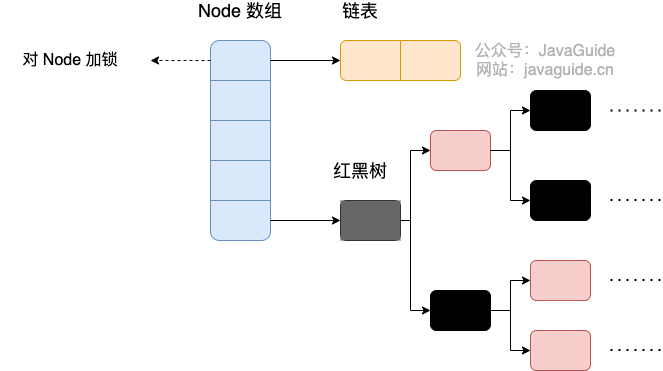
### 1. 存储结构
-
+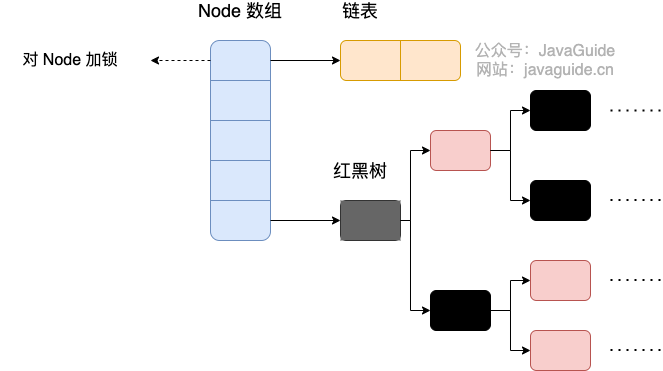
可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。当冲突链表达到一定长度时,链表会转换成红黑树。
diff --git a/docs/java/collection/java-collection-questions-01.md b/docs/java/collection/java-collection-questions-01.md
index 4c28775b..12245126 100644
--- a/docs/java/collection/java-collection-questions-01.md
+++ b/docs/java/collection/java-collection-questions-01.md
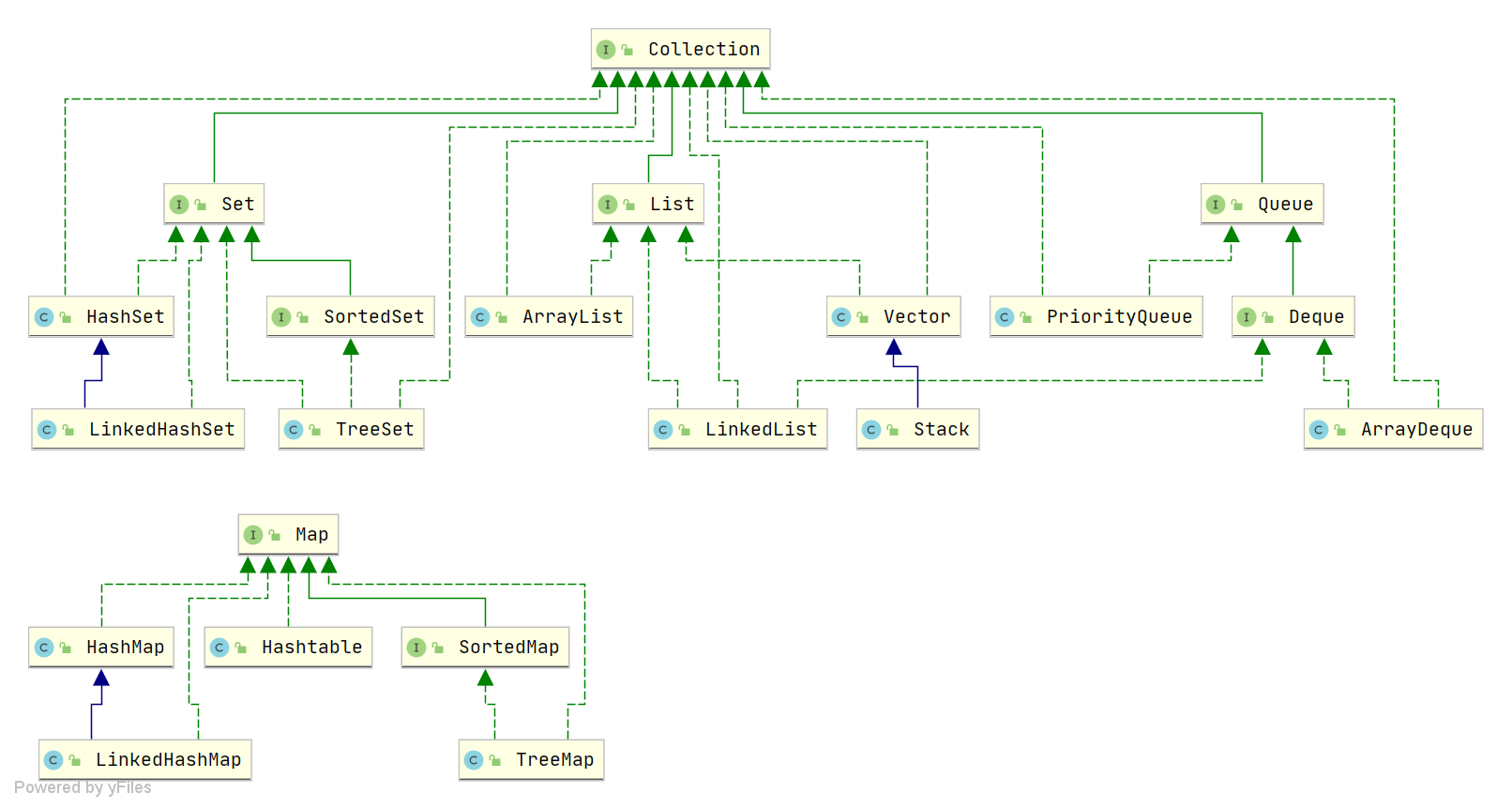
@@ -20,7 +20,7 @@ Java 集合, 也叫作容器,主要是由两大接口派生而来:一个
Java 集合框架如下图所示:
-
+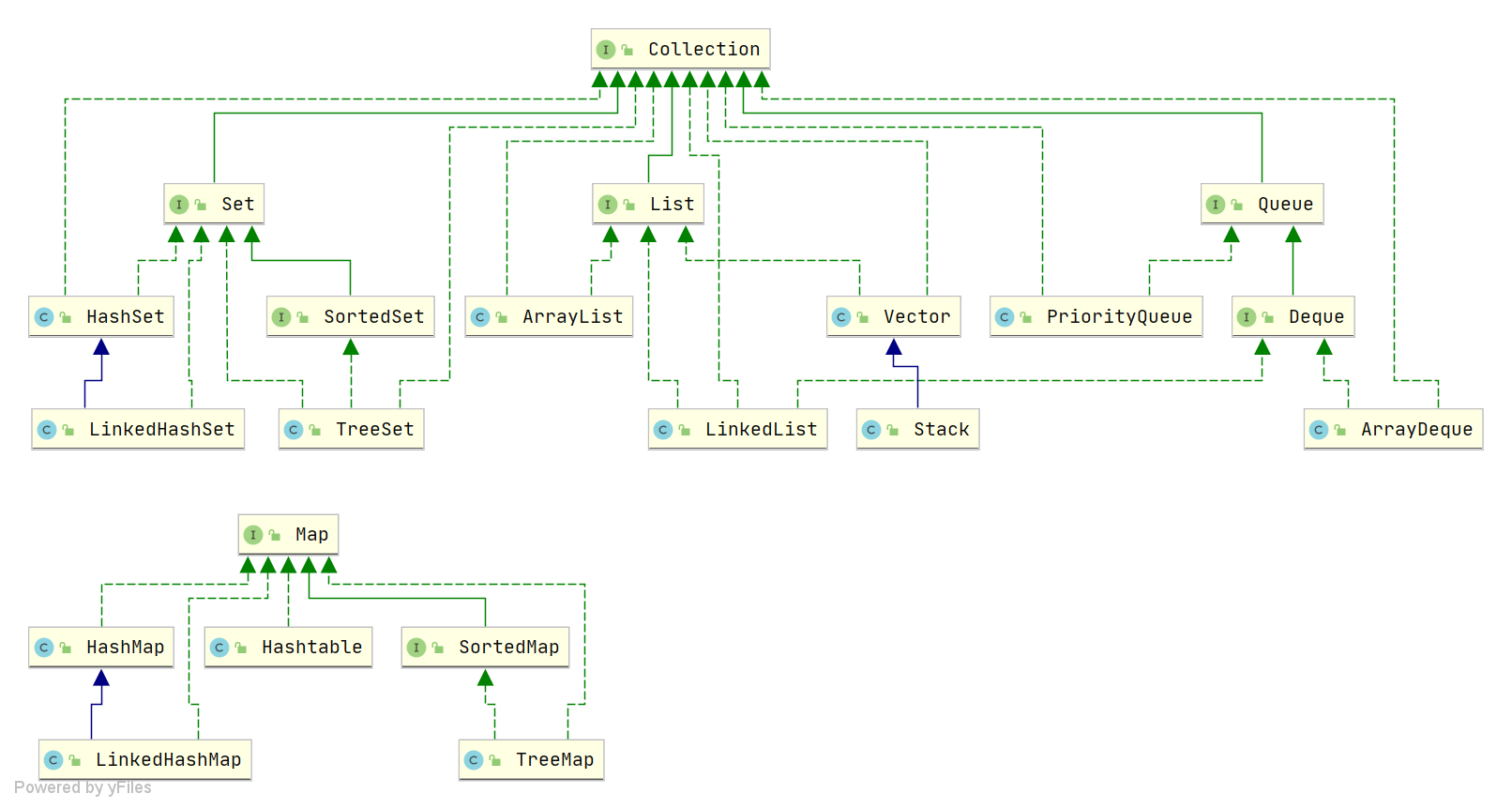
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了`AbstractList`, `NavigableSet`等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
@@ -95,7 +95,7 @@ Java 集合框架如下图所示:
我们在项目中一般是不会使用到 `LinkedList` 的,需要用到 `LinkedList` 的场景几乎都可以使用 `ArrayList` 来代替,并且,性能通常会更好!就连 `LinkedList` 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 `LinkedList` 。
-
+
另外,不要下意识地认为 `LinkedList` 作为链表就最适合元素增删的场景。我在上面也说了,`LinkedList` 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的时间复杂度都是 O(n) 。
diff --git a/docs/java/collection/java-collection-questions-02.md b/docs/java/collection/java-collection-questions-02.md
index fd0ca6f7..7a811ef3 100644
--- a/docs/java/collection/java-collection-questions-02.md
+++ b/docs/java/collection/java-collection-questions-02.md
@@ -74,7 +74,7 @@ head:
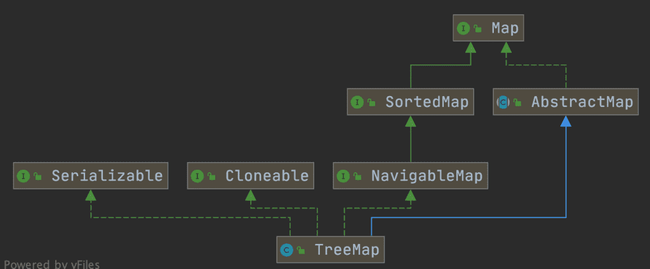
`TreeMap` 和`HashMap` 都继承自`AbstractMap` ,但是需要注意的是`TreeMap`它还实现了`NavigableMap`接口和`SortedMap` 接口。
-
+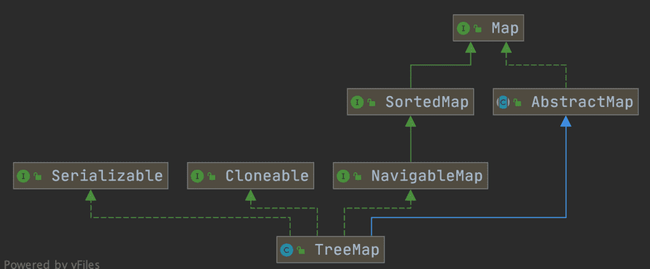
实现 `NavigableMap` 接口让 `TreeMap` 有了对集合内元素的搜索的能力。
@@ -206,13 +206,13 @@ static int hash(int h) {
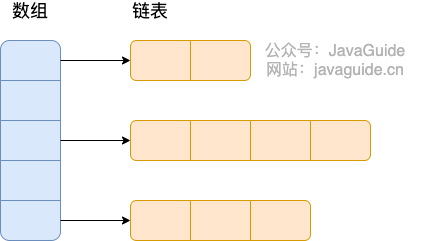
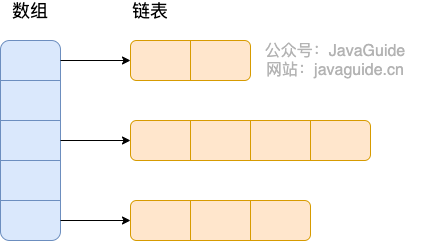
所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
+
#### JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
-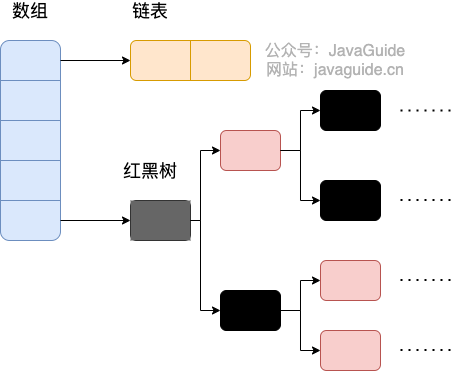
+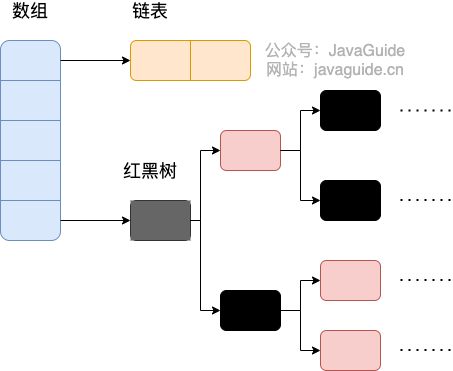
> TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
@@ -304,13 +304,13 @@ final void treeifyBin(Node[] tab, int hash) {
**Hashtable** :
-
+
https://www.cnblogs.com/chengxiao/p/6842045.html>
**JDK1.7 的 ConcurrentHashMap** :
-
+
`ConcurrentHashMap` 是由 `Segment` 数组结构和 `HashEntry` 数组结构组成。
@@ -318,7 +318,7 @@ final void treeifyBin(Node[] tab, int hash) {
**JDK1.8 的 ConcurrentHashMap** :
-
+
JDK1.8 的 `ConcurrentHashMap` 不再是 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。不过,Node 只能用于链表的情况,红黑树的情况需要使用 **`TreeNode`**。当冲突链表达到一定长度时,链表会转换成红黑树。
@@ -342,7 +342,7 @@ static final class TreeBin extends Node {
#### JDK1.8 之前
-
+
首先将数据分为一段一段(这个“段”就是 `Segment`)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
@@ -361,7 +361,7 @@ static class Segment extends ReentrantLock implements Serializable {
#### JDK1.8 之后
-
+
Java 8 几乎完全重写了 `ConcurrentHashMap`,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
diff --git a/docs/java/concurrent/completablefuture-intro.md b/docs/java/concurrent/completablefuture-intro.md
index a0d65f8a..2622b50d 100644
--- a/docs/java/concurrent/completablefuture-intro.md
+++ b/docs/java/concurrent/completablefuture-intro.md
@@ -19,11 +19,11 @@ public class CompletableFuture implements Future, CompletionStage {
}
```
-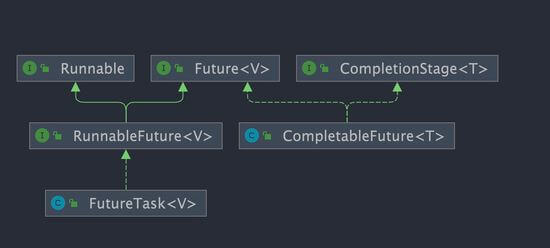
+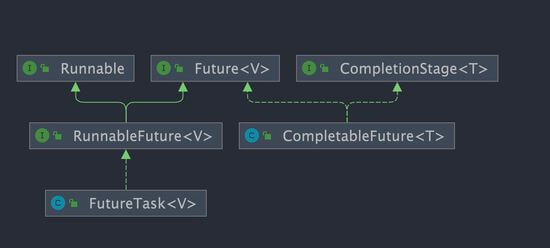
`CompletableFuture` 除了提供了更为好用和强大的 `Future` 特性之外,还提供了函数式编程的能力。
-
+
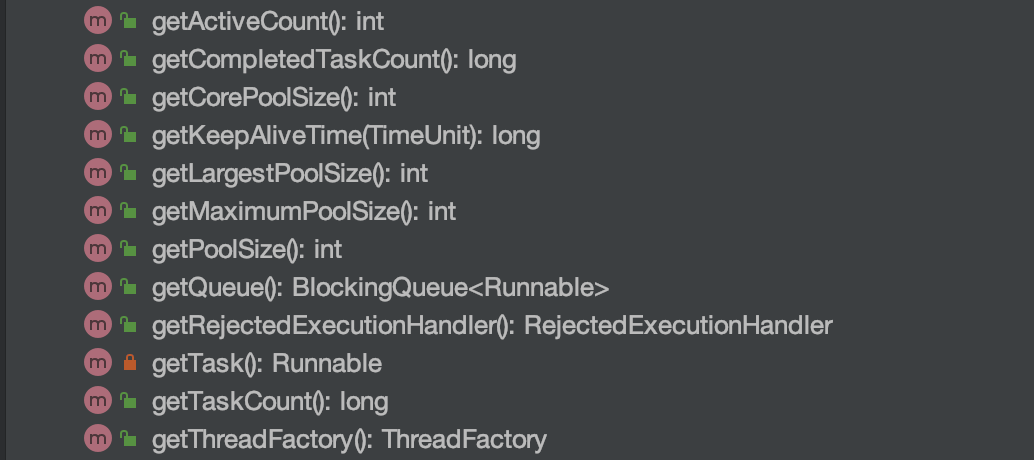
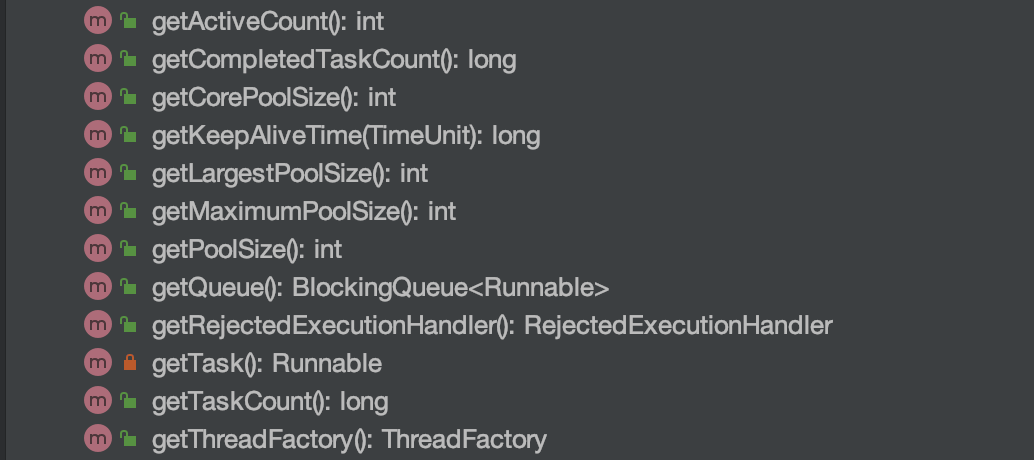
`Future` 接口有 5 个方法:
@@ -37,7 +37,7 @@ public class CompletableFuture implements Future, CompletionStage {
`CompletionStage` 接口中的方法比较多,`CompletableFuture` 的函数式能力就是这个接口赋予的。从这个接口的方法参数你就可以发现其大量使用了 Java8 引入的函数式编程。
-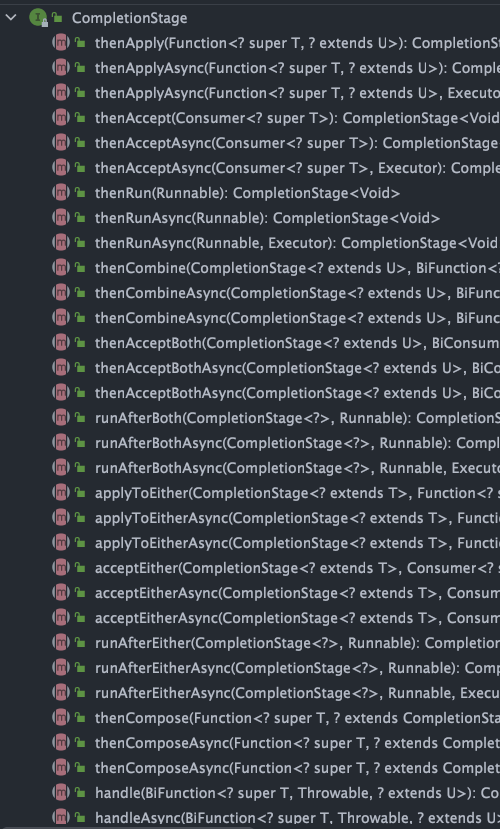
+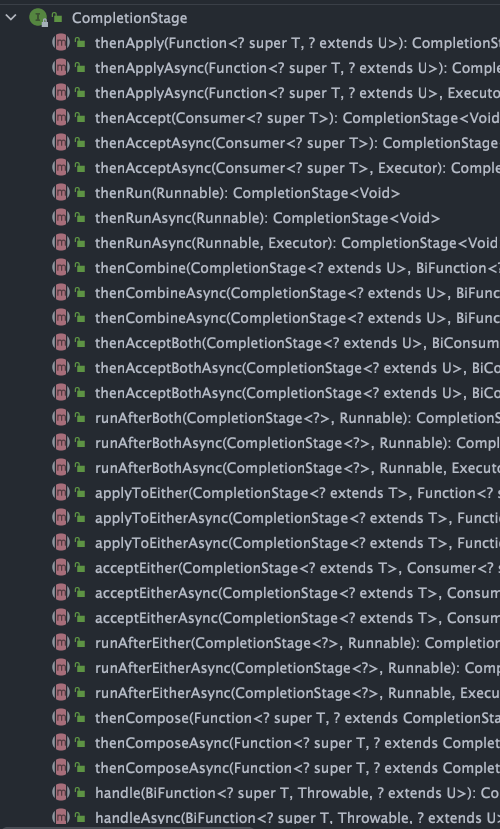
由于方法众多,所以这里不能一一讲解,下文中我会介绍大部分常见方法的使用。
diff --git a/docs/java/concurrent/java-concurrent-questions-01.md b/docs/java/concurrent/java-concurrent-questions-01.md
index f872d688..1f11db78 100644
--- a/docs/java/concurrent/java-concurrent-questions-01.md
+++ b/docs/java/concurrent/java-concurrent-questions-01.md
@@ -65,7 +65,7 @@ public class MultiThread {
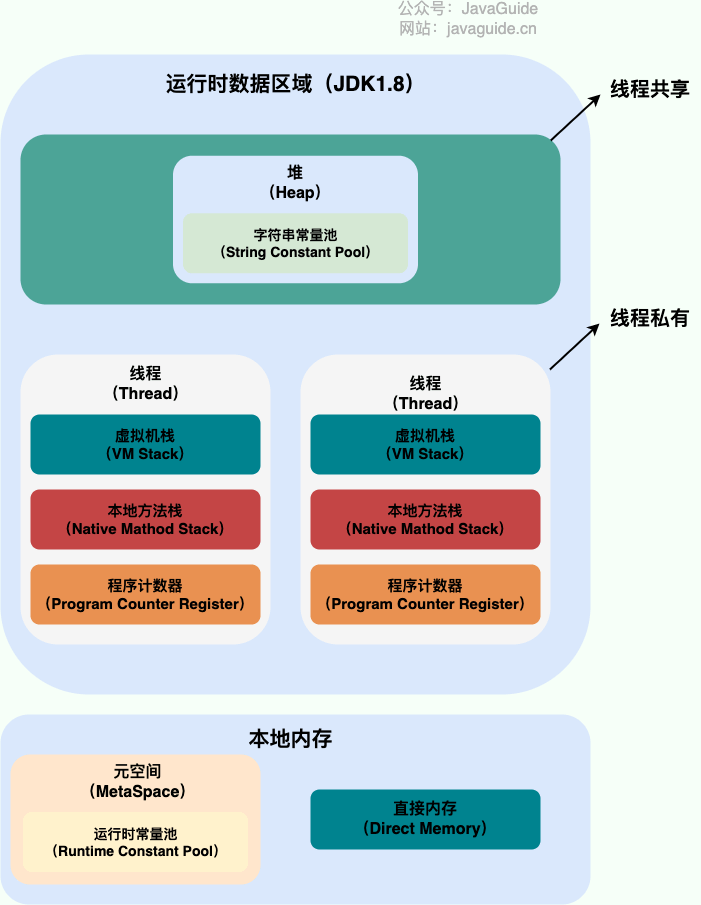
下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。
-
+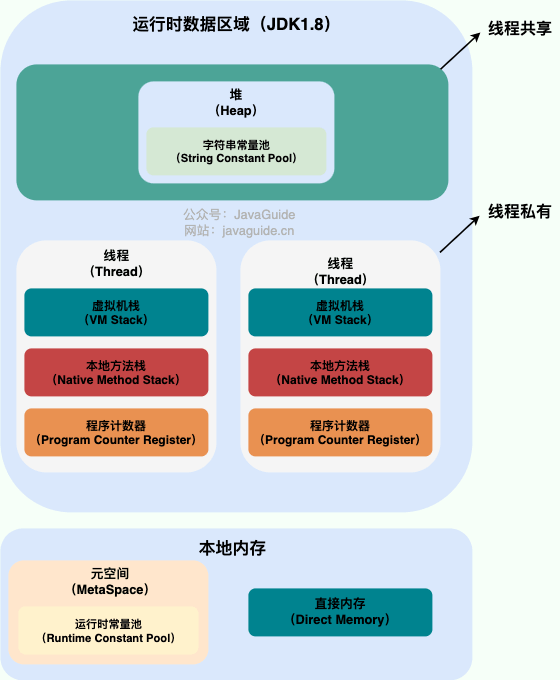
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
@@ -140,7 +140,7 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
Java 线程状态变迁图(图源:[挑错 |《Java 并发编程的艺术》中关于线程状态的三处错误](https://mp.weixin.qq.com/s/UOrXql_LhOD8dhTq_EPI0w)):
-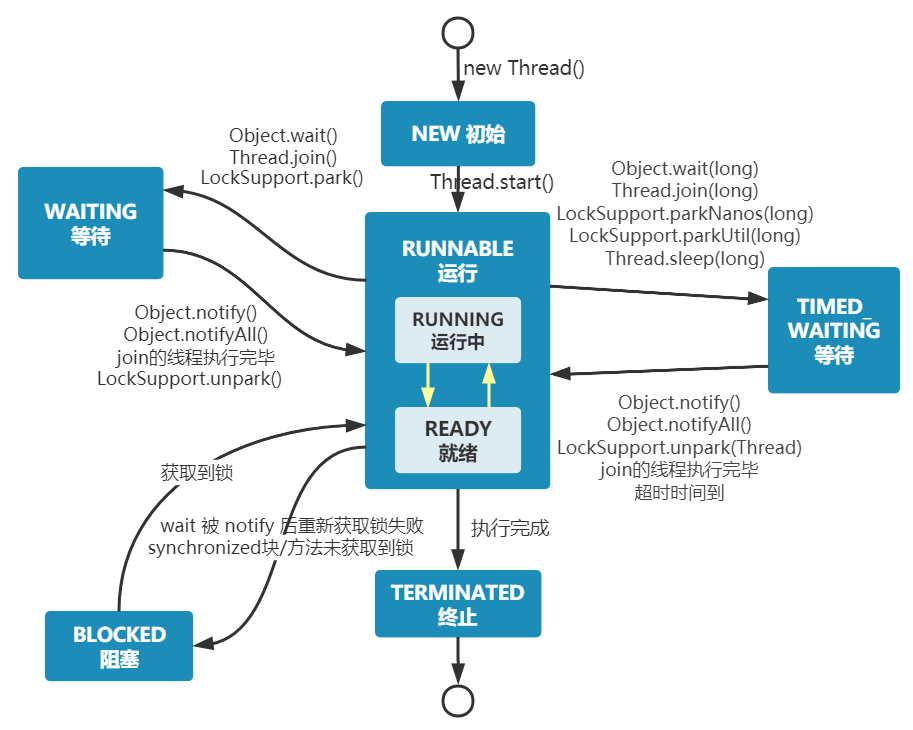
+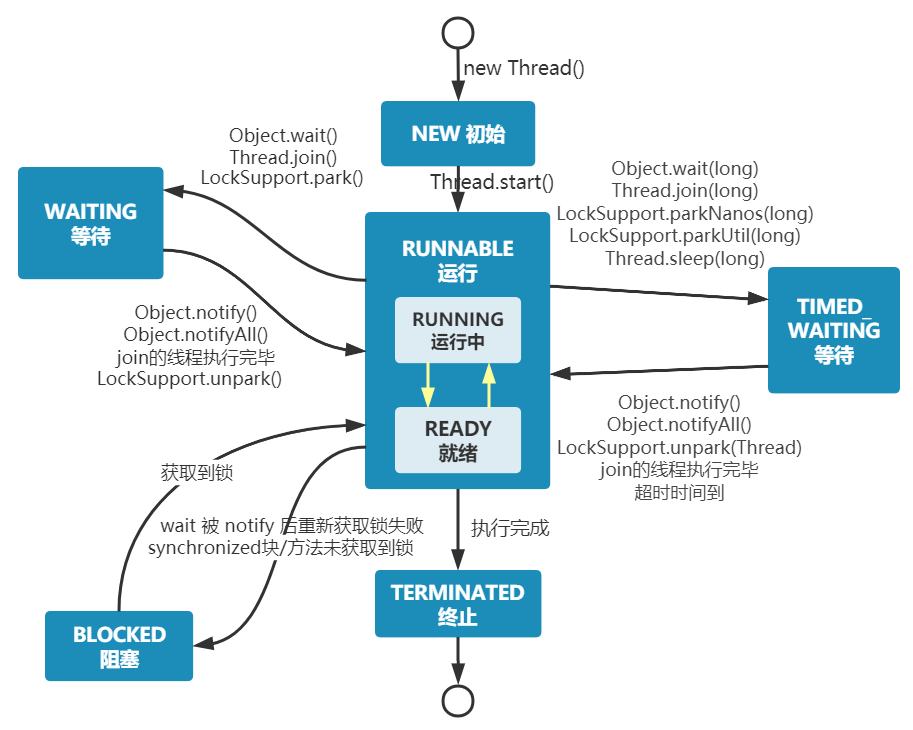
由上图可以看出:线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
diff --git a/docs/java/concurrent/java-concurrent-questions-02.md b/docs/java/concurrent/java-concurrent-questions-02.md
index 39481323..ef7c99b4 100644
--- a/docs/java/concurrent/java-concurrent-questions-02.md
+++ b/docs/java/concurrent/java-concurrent-questions-02.md
@@ -22,9 +22,9 @@ JMM(Java 内存模型)相关的问题比较多,也比较重要,于是我
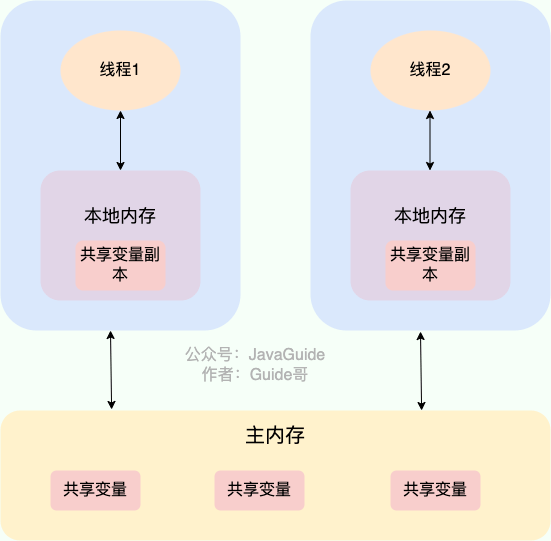
在 Java 中,`volatile` 关键字可以保证变量的可见性,如果我们将变量声明为 **`volatile`** ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
-
+
-
+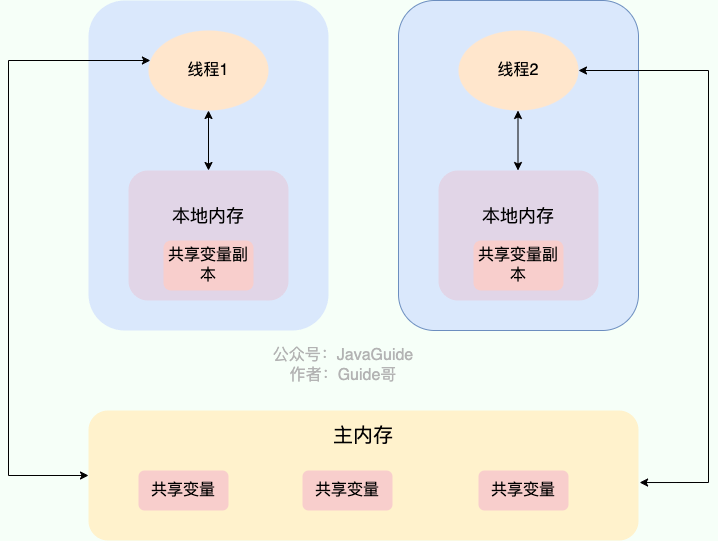
`volatile` 关键字其实并非是 Java 语言特有的,在 C 语言里也有,它最原始的意义就是禁用 CPU 缓存。如果我们将一个变量使用 `volatile` 修饰,这就指示 编译器,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
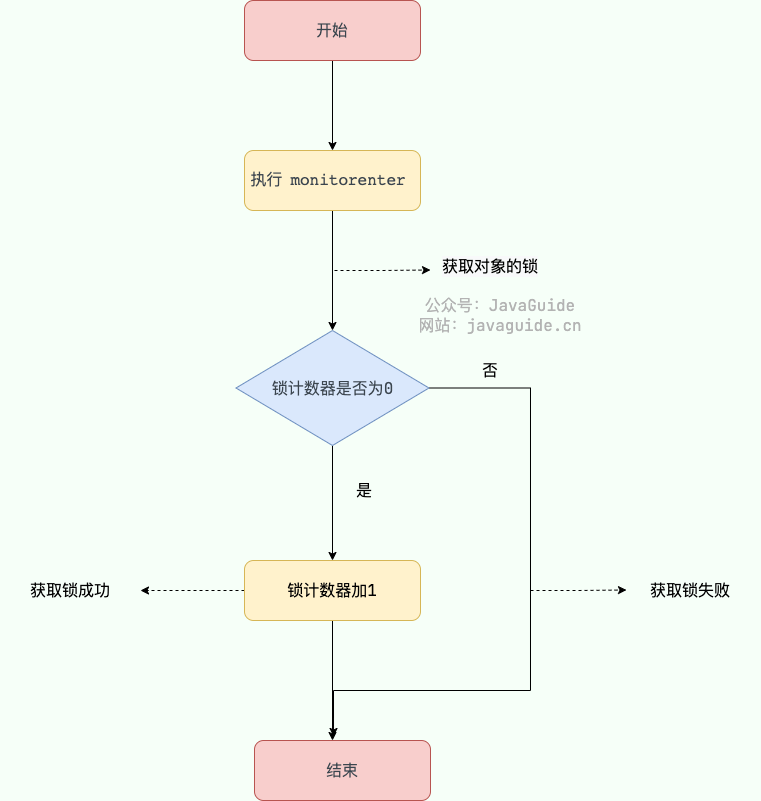
@@ -390,11 +390,11 @@ public class SynchronizedDemo {
在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
-
+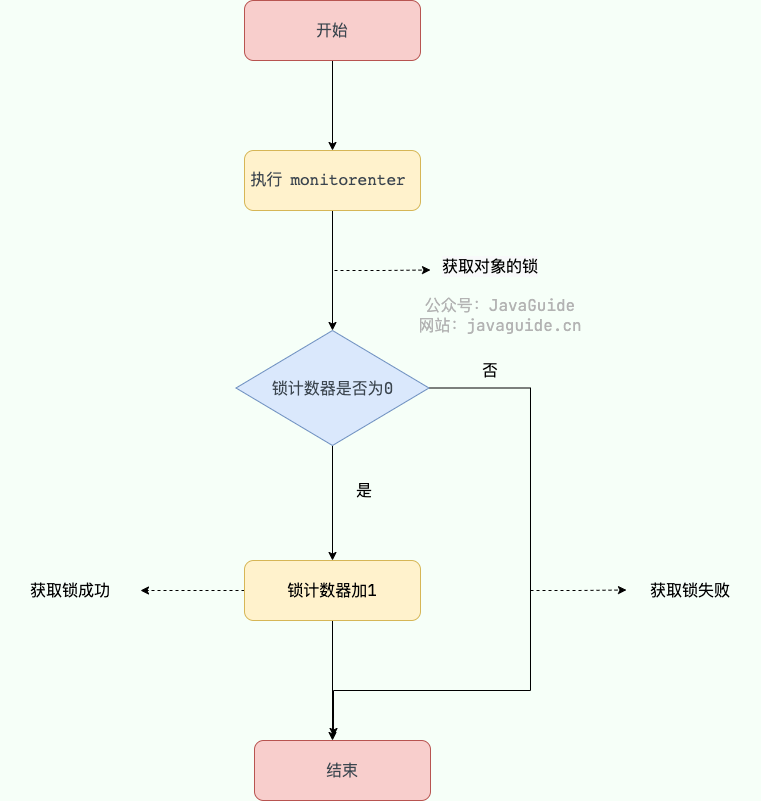
对象锁的的拥有者线程才可以执行 `monitorexit` 指令来释放锁。在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放,其他线程可以尝试获取锁。
-
+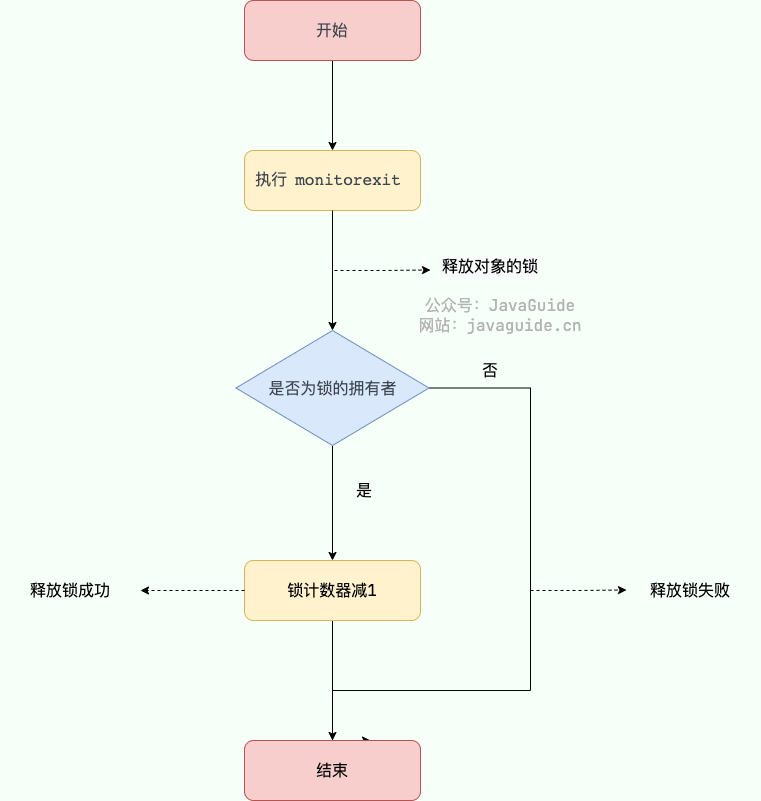
如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
@@ -455,7 +455,7 @@ public class ReentrantLock implements Lock, java.io.Serializable {}
`ReentrantLock` 里面有一个内部类 `Sync`,`Sync` 继承 AQS(`AbstractQueuedSynchronizer`),添加锁和释放锁的大部分操作实际上都是在 `Sync` 中实现的。`Sync` 有公平锁 `FairSync` 和非公平锁 `NonfairSync` 两个子类。
-
+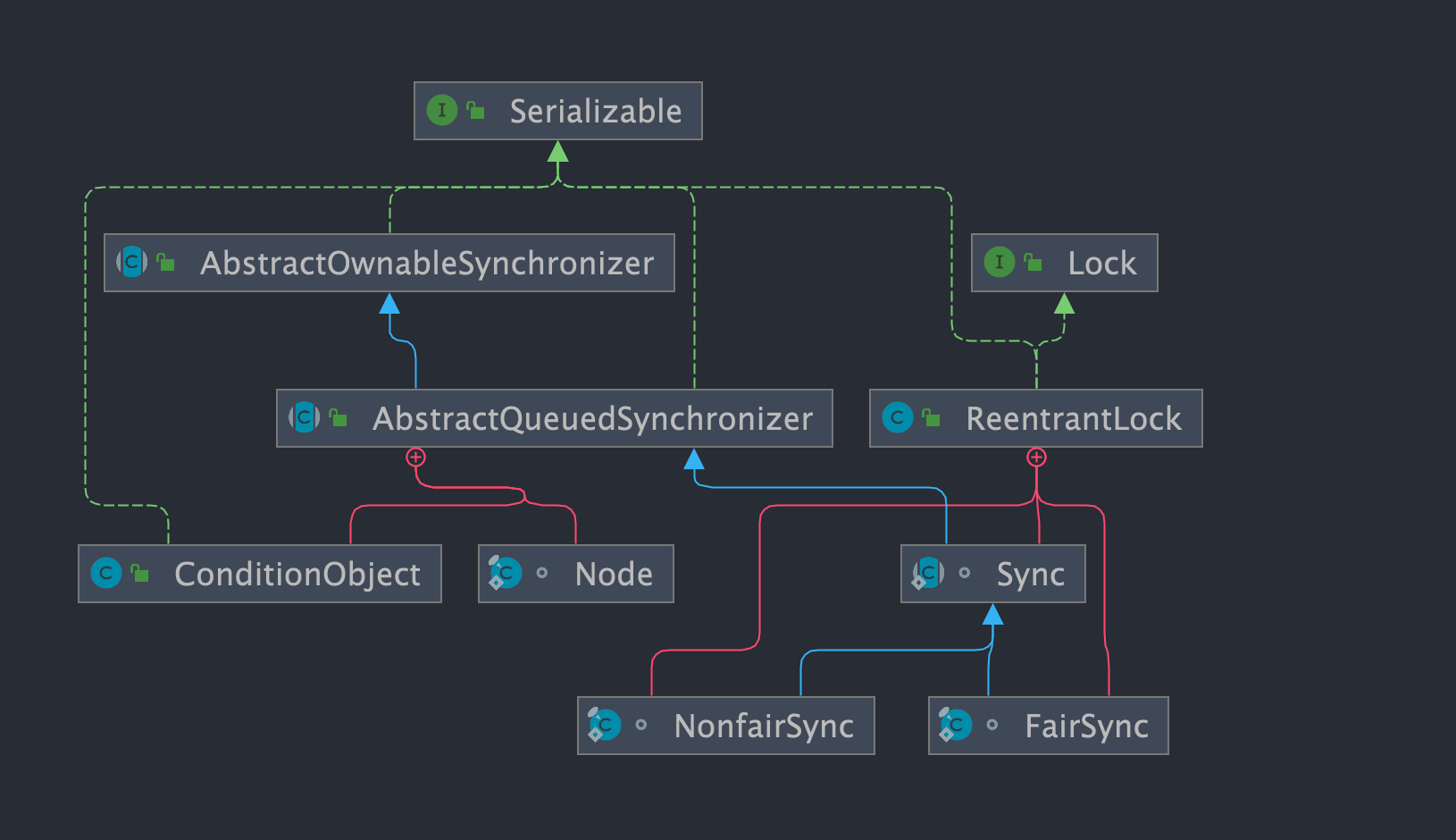
`ReentrantLock` 默认使用非公平锁,也可以通过构造器来显示的指定使用公平锁。
@@ -548,7 +548,7 @@ public interface ReadWriteLock {
和 `ReentrantLock` 一样,`ReentrantReadWriteLock` 底层也是基于 AQS 实现的。
-
+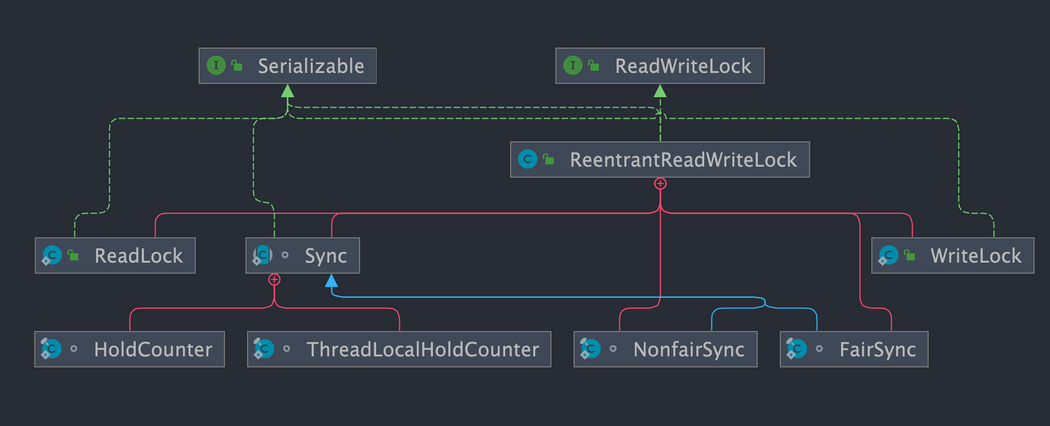
`ReentrantReadWriteLock` 也支持公平锁和非公平锁,默认使用非公平锁,可以通过构造器来显示的指定。
diff --git a/docs/java/concurrent/java-concurrent-questions-03.md b/docs/java/concurrent/java-concurrent-questions-03.md
index 9edec254..84d3ff2d 100644
--- a/docs/java/concurrent/java-concurrent-questions-03.md
+++ b/docs/java/concurrent/java-concurrent-questions-03.md
@@ -153,11 +153,11 @@ ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
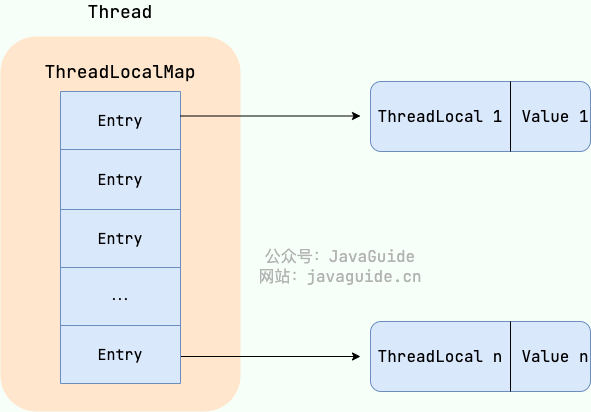
`ThreadLocal` 数据结构如下图所示:
-
+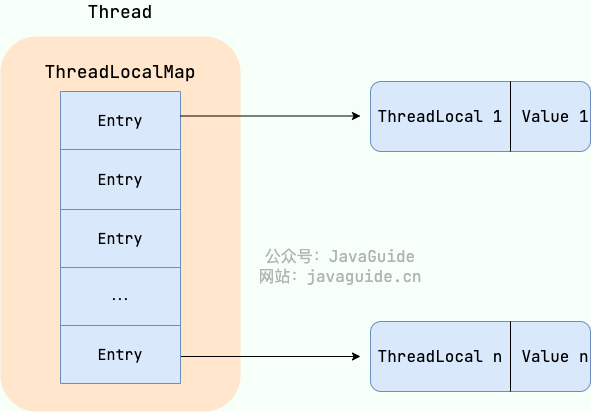
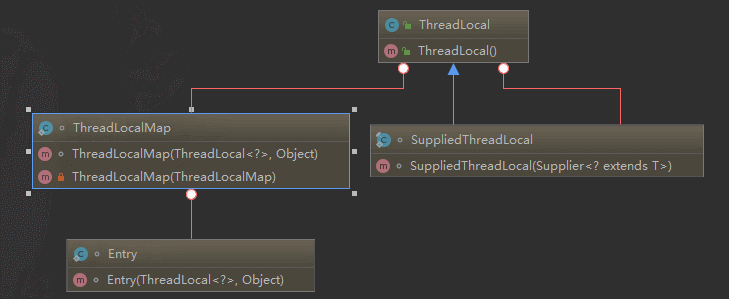
`ThreadLocalMap`是`ThreadLocal`的静态内部类。
-
+
### ThreadLocal 内存泄露问题是怎么导致的?
@@ -218,7 +218,7 @@ static class Entry extends WeakReference> {
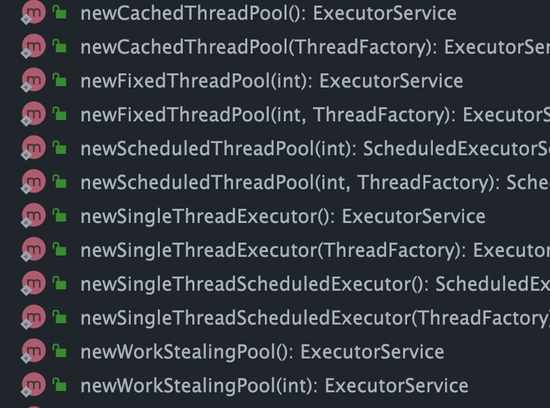
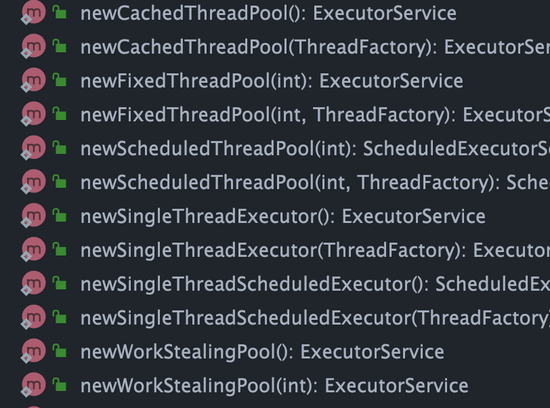
对应 `Executors` 工具类中的方法如图所示:
-
+
### 为什么不推荐使用内置线程池?
@@ -338,7 +338,7 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
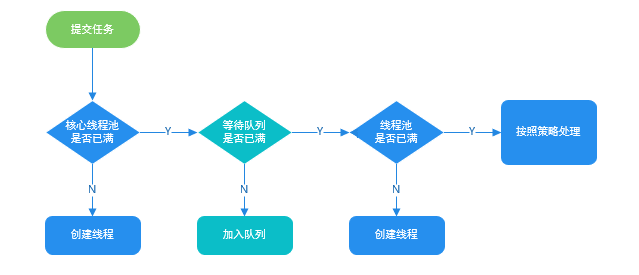
### 线程池处理任务的流程了解吗?
-
+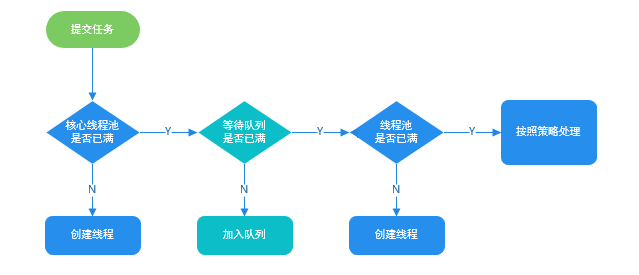
1. 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
2. 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
@@ -451,7 +451,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
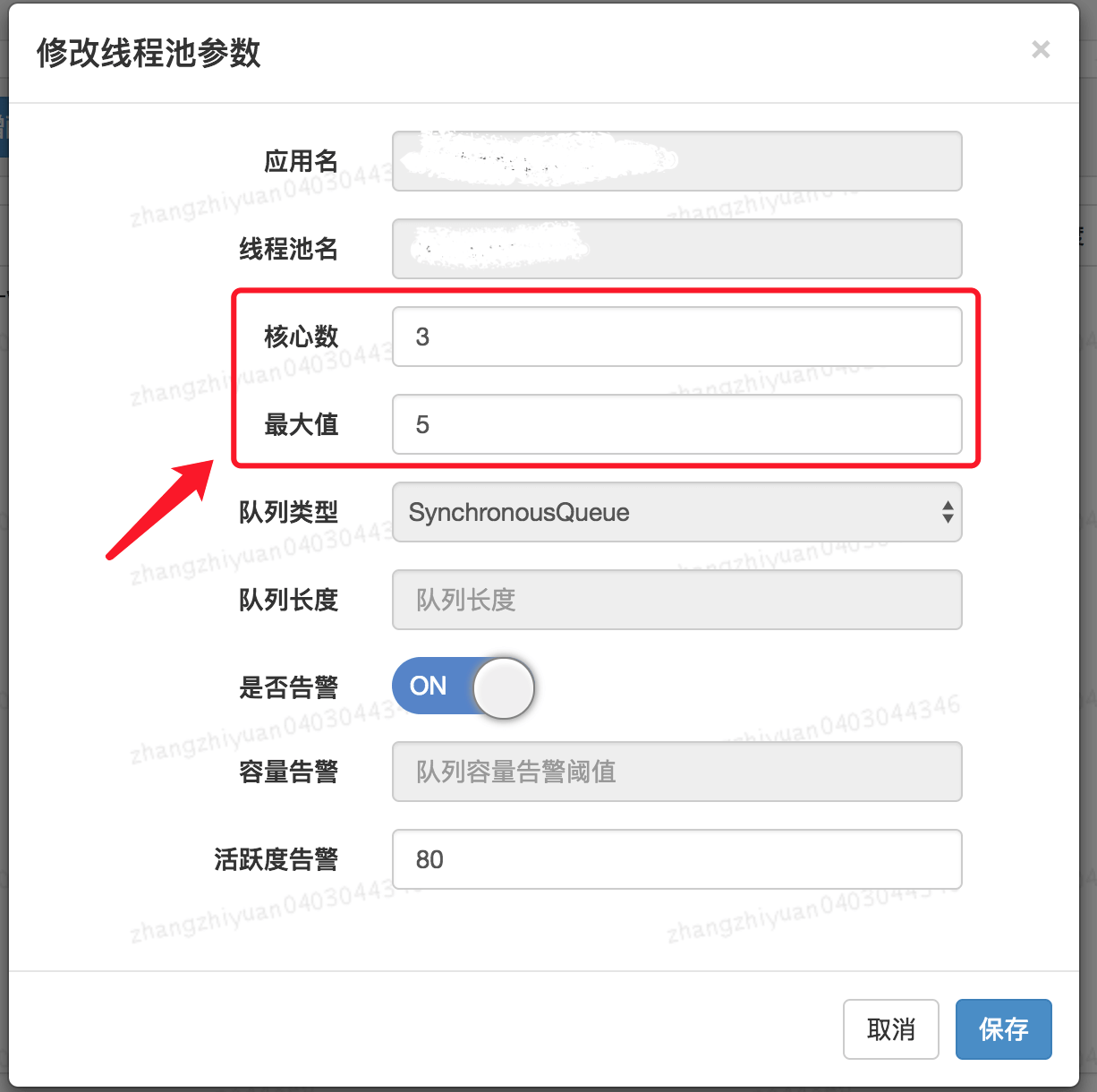
**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
-
+
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize()`这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
@@ -459,7 +459,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
最终实现的可动态修改线程池参数效果如下。👏👏👏
-
+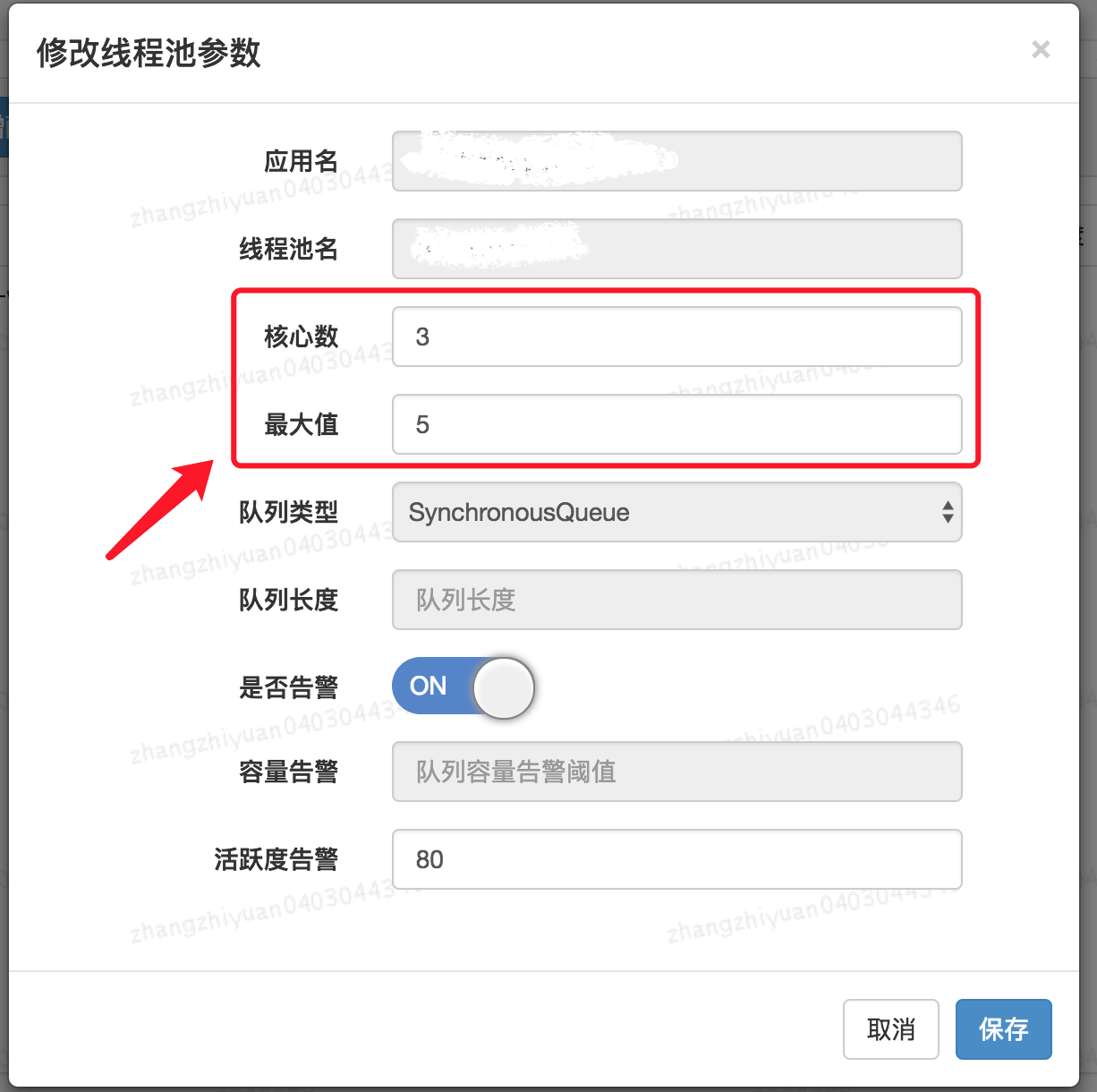
还没看够?推荐 why 神的[如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
@@ -518,7 +518,7 @@ Future submit(Runnable task);
`FutureTask` 不光实现了 `Future`接口,还实现了`Runnable` 接口,因此可以作为任务直接被线程执行。
-
+
`FutureTask` 有两个构造函数,可传入 `Callable` 或者 `Runnable` 对象。实际上,传入 `Runnable` 对象也会在方法内部转换为`Callable` 对象。
@@ -553,13 +553,13 @@ public class CompletableFuture implements Future, CompletionStage {
可以看到,`CompletableFuture` 同时实现了 `Future` 和 `CompletionStage` 接口。
-
+
`CompletionStage` 接口描述了一个异步计算的阶段。很多计算可以分成多个阶段或步骤,此时可以通过它将所有步骤组合起来,形成异步计算的流水线。
`CompletionStage` 接口中的方法比较多,`CompletableFuture` 的函数式能力就是这个接口赋予的。从这个接口的方法参数你就可以发现其大量使用了 Java8 引入的函数式编程。
-
+
## AQS
diff --git a/docs/java/concurrent/java-thread-pool-best-practices.md b/docs/java/concurrent/java-thread-pool-best-practices.md
index efdcc1c3..2a795f61 100644
--- a/docs/java/concurrent/java-thread-pool-best-practices.md
+++ b/docs/java/concurrent/java-thread-pool-best-practices.md
@@ -30,7 +30,7 @@ tag:
除此之外,我们还可以利用 `ThreadPoolExecutor` 的相关 API 做一个简陋的监控。从下图可以看出, `ThreadPoolExecutor`提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
-
+
下面是一个简单的 Demo。`printThreadPoolStatus()`会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
@@ -61,13 +61,13 @@ public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
**我们再来看一个真实的事故案例!** (本案例来源自:[《线程池运用不当的一次线上事故》](https://club.perfma.com/article/646639) ,很精彩的一个案例)
-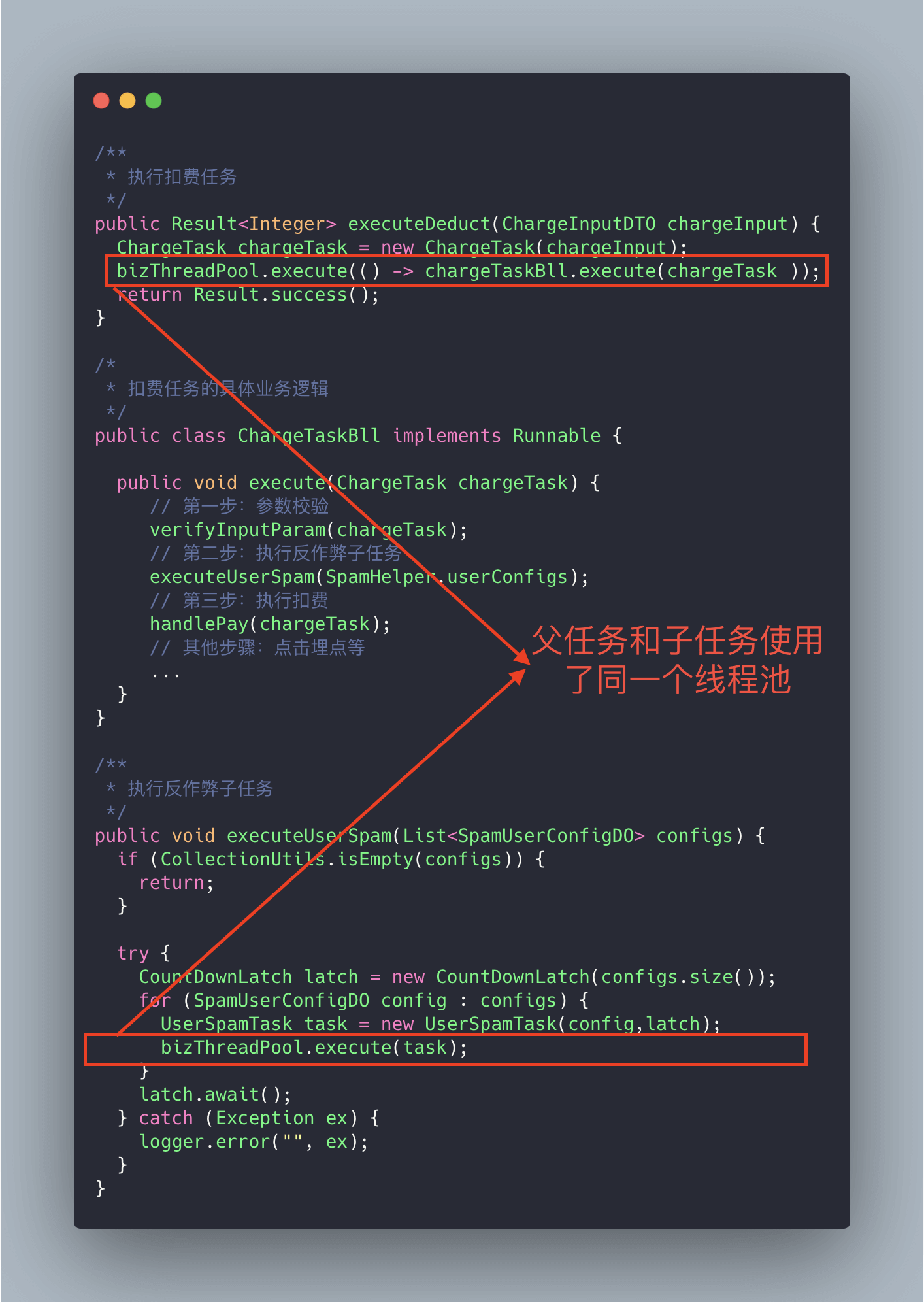
+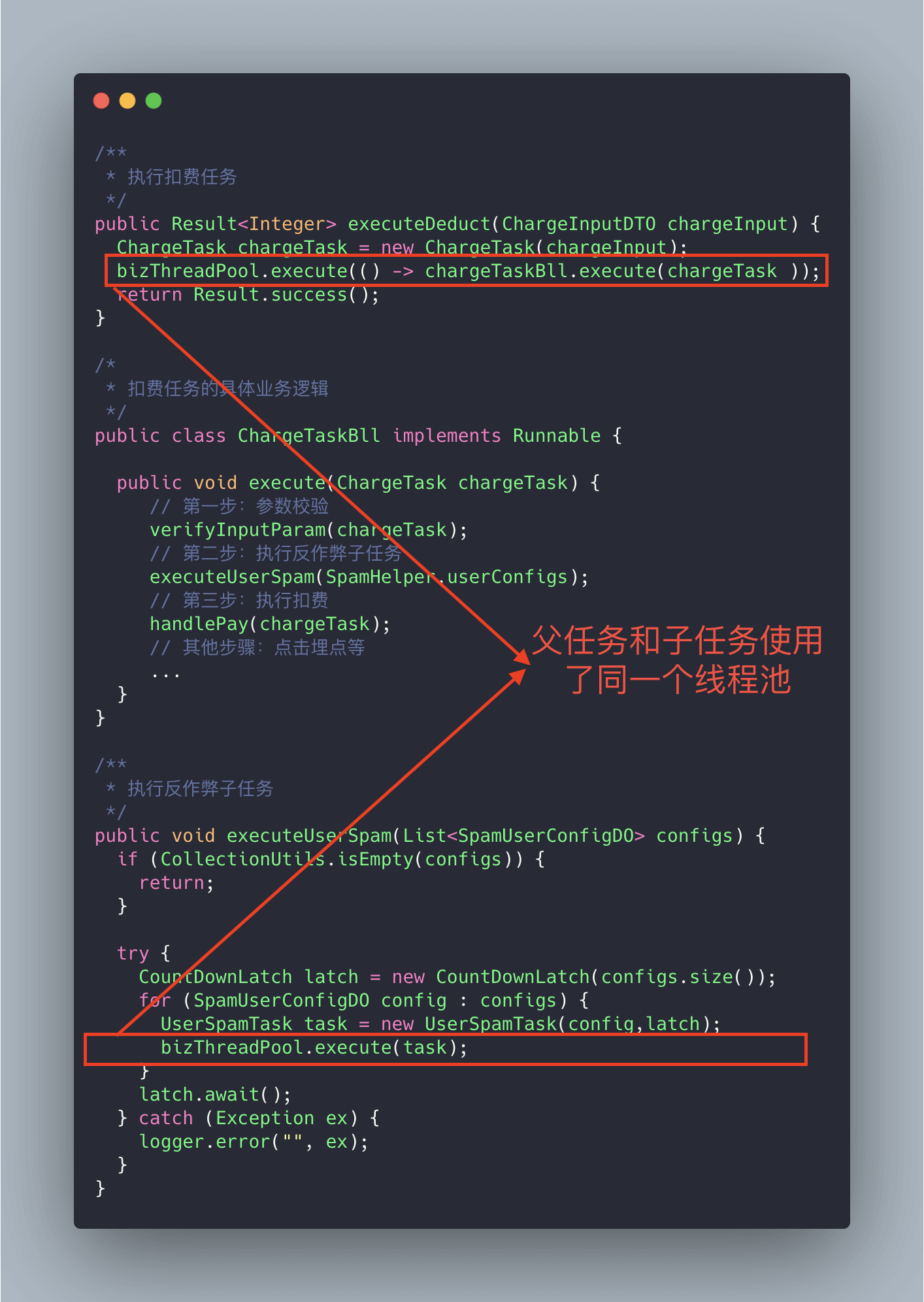
上面的代码可能会存在死锁的情况,为什么呢?画个图给大家捋一捋。
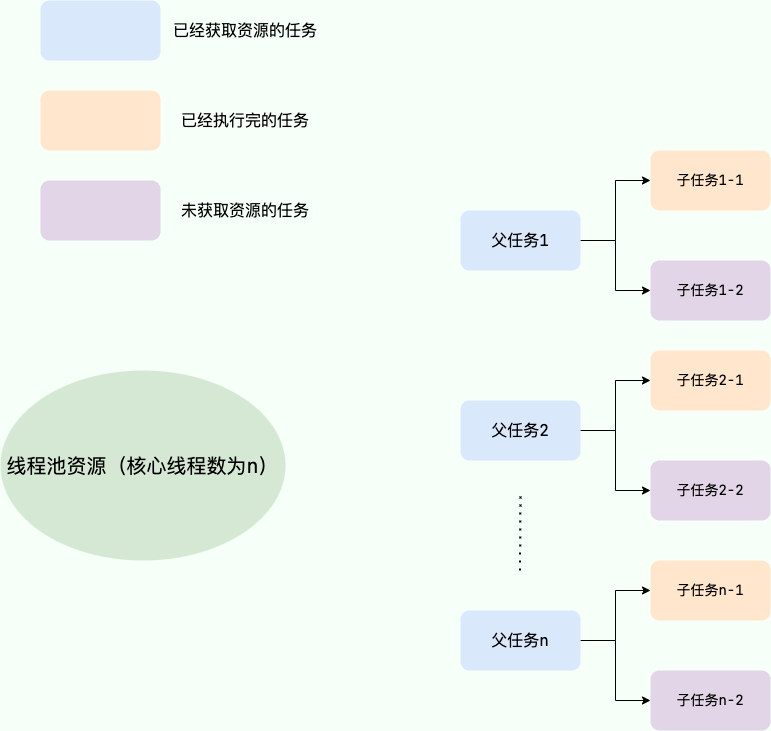
试想这样一种极端情况:假如我们线程池的核心线程数为 **n**,父任务(扣费任务)数量为 **n**,父任务下面有两个子任务(扣费任务下的子任务),其中一个已经执行完成,另外一个被放在了任务队列中。由于父任务把线程池核心线程资源用完,所以子任务因为无法获取到线程资源无法正常执行,一直被阻塞在队列中。父任务等待子任务执行完成,而子任务等待父任务释放线程池资源,这也就造成了 **"死锁"** 。
-
+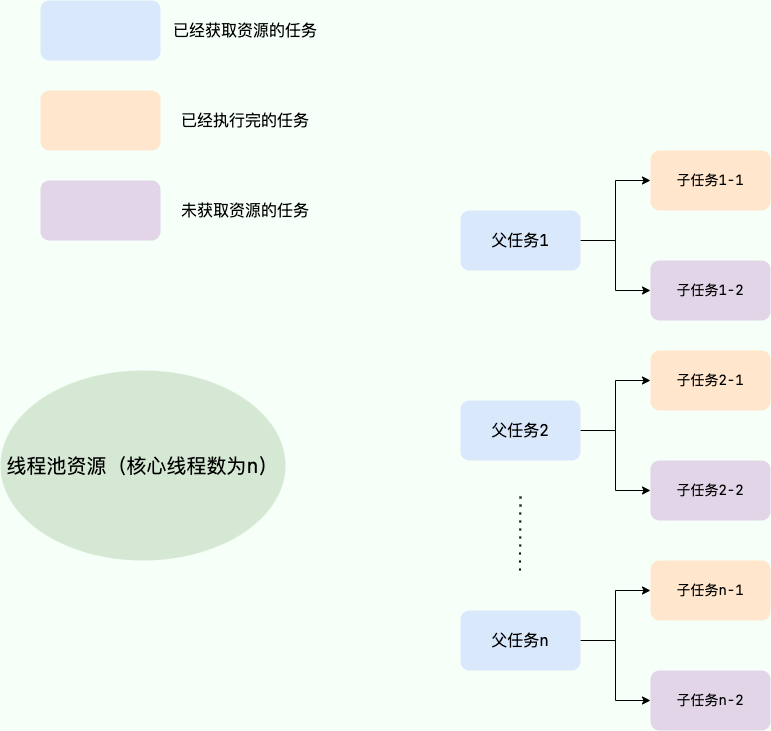
解决方法也很简单,就是新增加一个用于执行子任务的线程池专门为其服务。
@@ -183,7 +183,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
-
+
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize()`这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
@@ -191,7 +191,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
最终实现的可动态修改线程池参数效果如下。👏👏👏
-
+
还没看够?推荐 why 神的[《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
diff --git a/docs/java/concurrent/java-thread-pool-summary.md b/docs/java/concurrent/java-thread-pool-summary.md
index d67cf2a4..5c8e0d7d 100644
--- a/docs/java/concurrent/java-thread-pool-summary.md
+++ b/docs/java/concurrent/java-thread-pool-summary.md
@@ -47,7 +47,7 @@ tag:
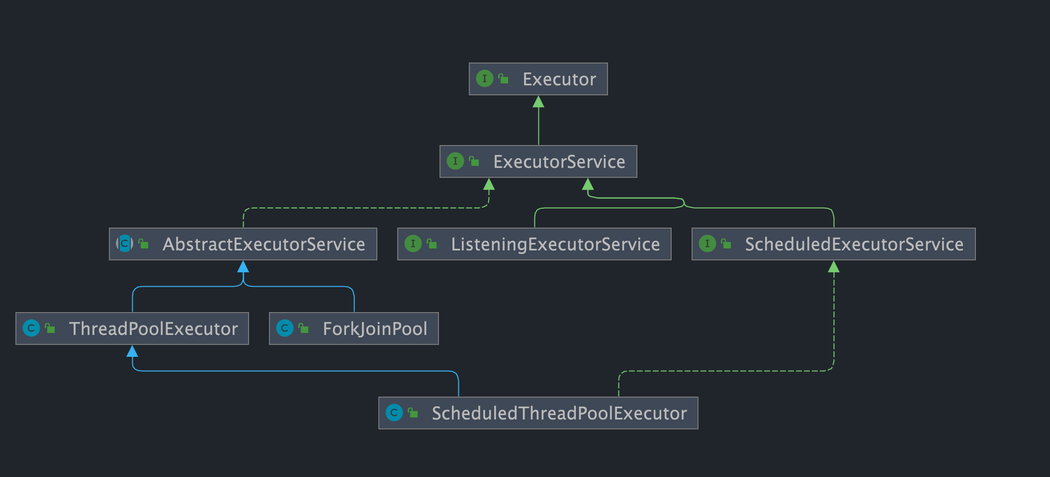
如下图所示,包括任务执行机制的核心接口 **`Executor`** ,以及继承自 `Executor` 接口的 **`ExecutorService` 接口。`ThreadPoolExecutor`** 和 **`ScheduledThreadPoolExecutor`** 这两个关键类实现了 **`ExecutorService`** 接口。
-
+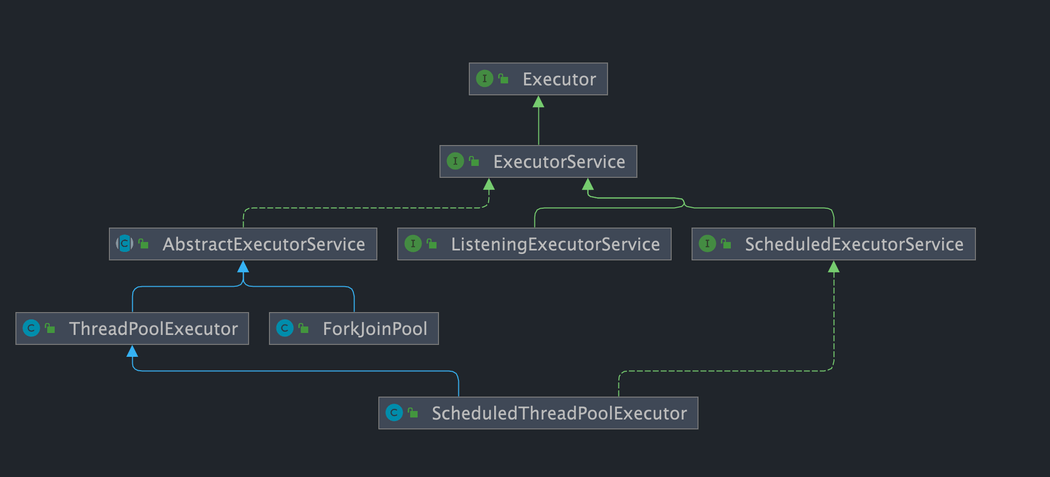
这里提了很多底层的类关系,但是,实际上我们需要更多关注的是 `ThreadPoolExecutor` 这个类,这个类在我们实际使用线程池的过程中,使用频率还是非常高的。
@@ -169,7 +169,7 @@ Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecu
对应 `Executors` 工具类中的方法如图所示:
-
+
《阿里巴巴 Java 开发手册》强制线程池不允许使用 `Executors` 去创建,而是通过 `ThreadPoolExecutor` 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
@@ -410,7 +410,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
下图是我为了省事直接从网上找到,原地址不明。
-
+
在 `execute` 方法中,多次调用 `addWorker` 方法。`addWorker` 这个方法主要用来创建新的工作线程,如果返回 true 说明创建和启动工作线程成功,否则的话返回的就是 false。
diff --git a/docs/java/concurrent/jmm.md b/docs/java/concurrent/jmm.md
index f17dfaef..f1da58f5 100644
--- a/docs/java/concurrent/jmm.md
+++ b/docs/java/concurrent/jmm.md
@@ -28,7 +28,7 @@ JMM(Java内存模型)主要定义了对于一个共享变量,当另一个线
> **🐛 修正(参见: [issue#1848](https://github.com/Snailclimb/JavaGuide/issues/1848))**:对 CPU 缓存模型绘图不严谨的地方进行完善。
-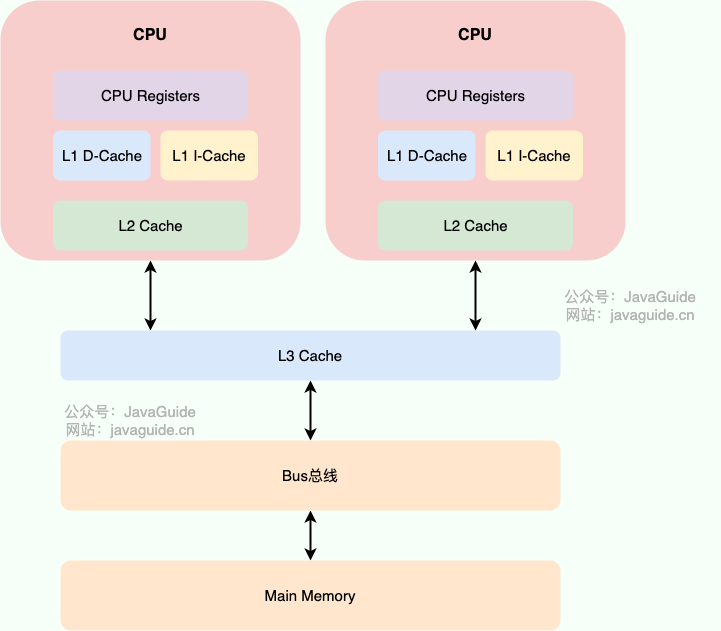
+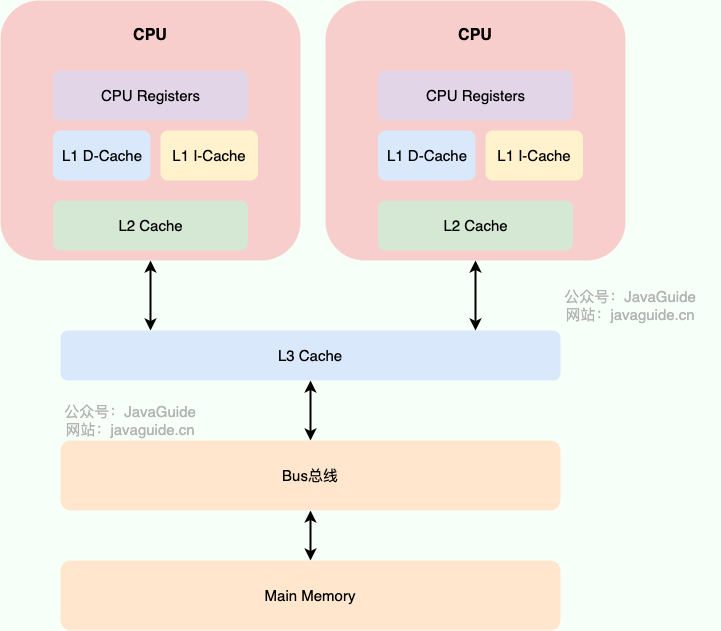
现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache。有些 CPU 可能还有 L4 Cache,这里不做讨论,并不常见
@@ -36,7 +36,7 @@ JMM(Java内存模型)主要定义了对于一个共享变量,当另一个线
**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议(比如 [MESI 协议](https://zh.wikipedia.org/wiki/MESI%E5%8D%8F%E8%AE%AE))或者其他手段来解决。** 这个缓存一致性协议指的是在 CPU 高速缓存与主内存交互的时候需要遵守的原则和规范。不同的 CPU 中,使用的缓存一致性协议通常也会有所不同。
-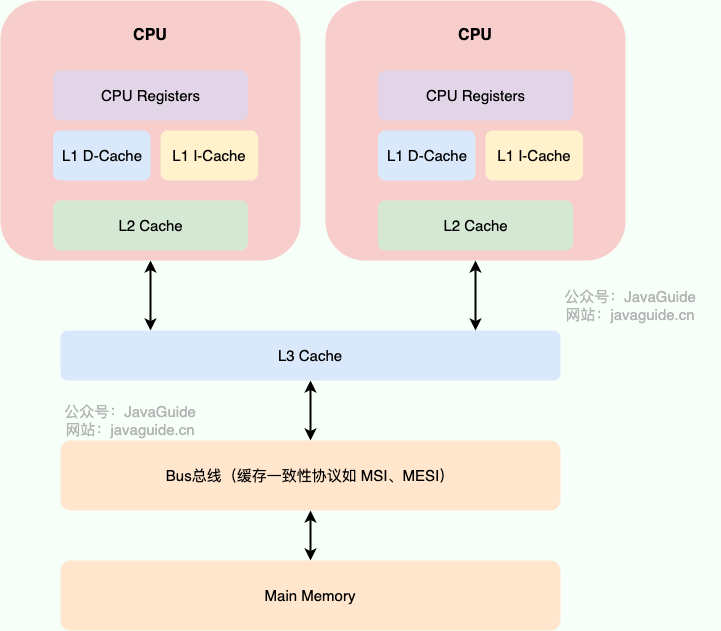
+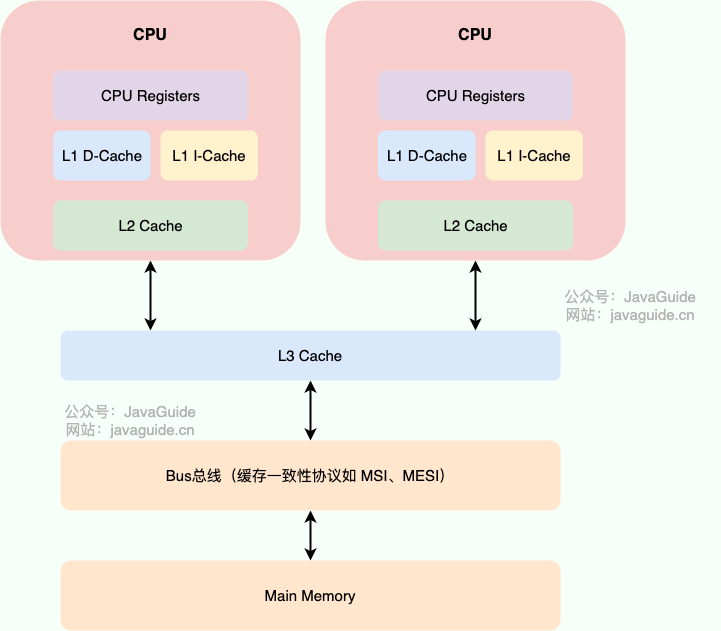
我们的程序运行在操作系统之上,操作系统屏蔽了底层硬件的操作细节,将各种硬件资源虚拟化。于是,操作系统也就同样需要解决内存缓存不一致性问题。
@@ -94,7 +94,7 @@ JMM 说白了就是定义了一些规范来解决这些问题,开发者可以
Java 内存模型的抽象示意图如下:
-
+
从上图来看,线程 1 与线程 2 之间如果要进行通信的话,必须要经历下面 2 个步骤:
@@ -150,7 +150,7 @@ JSR 133 引入了 happens-before 这个概念来描述两个操作之间的内
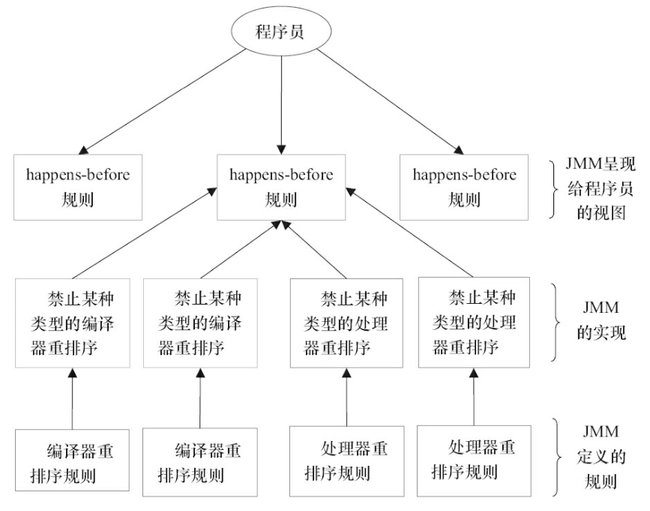
下面这张是 《Java 并发编程的艺术》这本书中的一张 JMM 设计思想的示意图,非常清晰。
-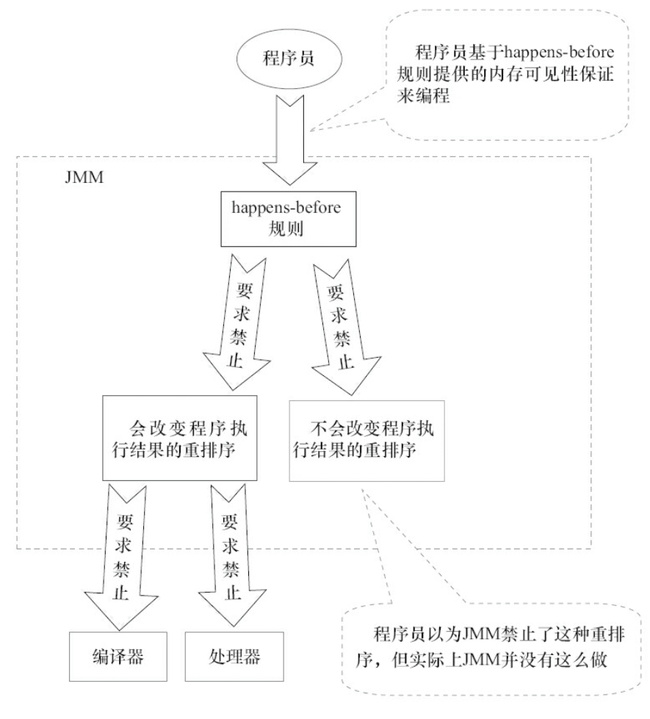
+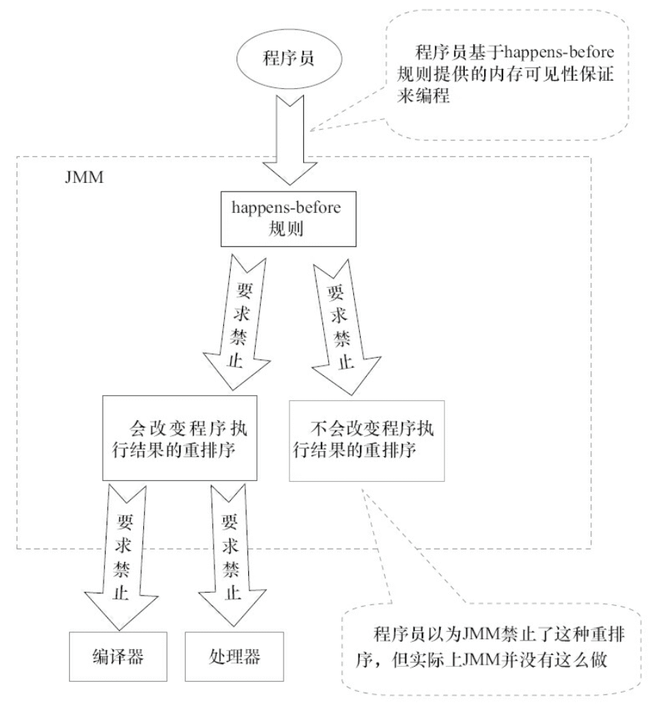
了解了 happens-before 原则的设计思想,我们再来看看 JSR-133 对 happens-before 原则的定义:
@@ -191,7 +191,7 @@ happens-before 的规则就 8 条,说多不多,重点了解下面列举的 5
happens-before 与 JMM 的关系用《Java 并发编程的艺术》这本书中的一张图就可以非常好的解释清楚。
-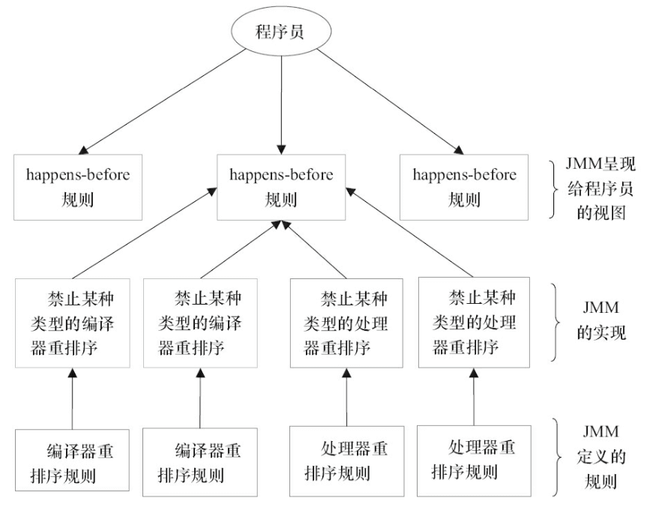
+
## 再看并发编程三个重要特性
diff --git a/docs/java/concurrent/threadlocal.md b/docs/java/concurrent/threadlocal.md
index 9015c3fe..4f57757e 100644
--- a/docs/java/concurrent/threadlocal.md
+++ b/docs/java/concurrent/threadlocal.md
@@ -312,7 +312,7 @@ public class ThreadLocal {
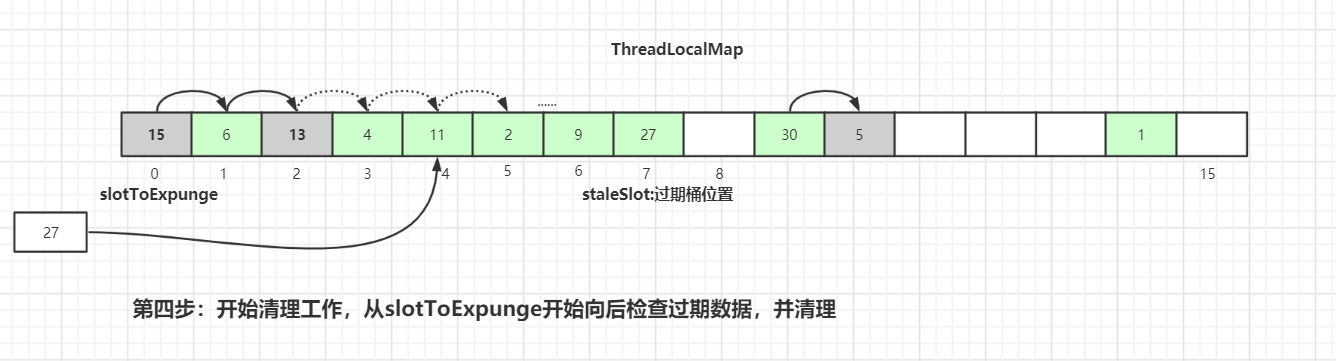
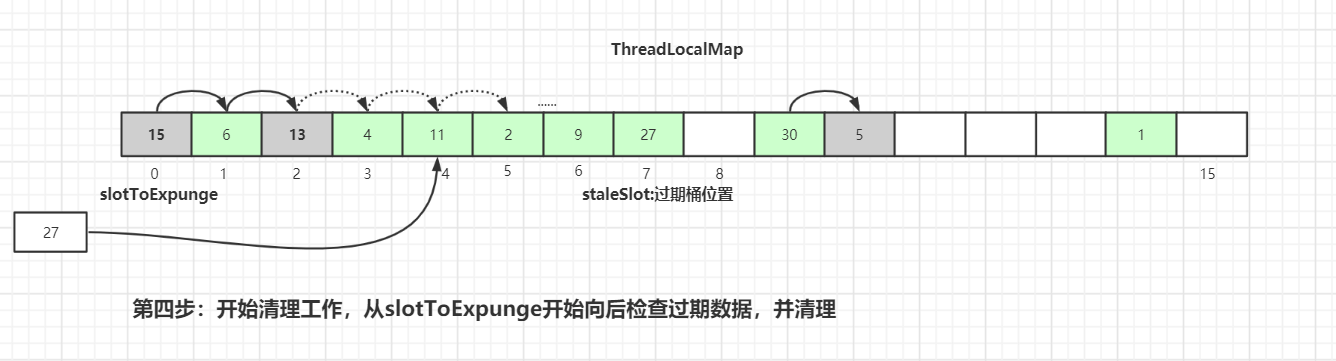
从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,找到后更新`Entry`的值并交换`staleSlot`元素的位置(`staleSlot`位置为过期元素),更新`Entry`数据,然后开始进行过期`Entry`的清理工作,如下图所示:
-向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:
+向后遍历过程中,如果没有找到相同 key 值的 Entry 数据:

diff --git a/docs/java/io/io-basis.md b/docs/java/io/io-basis.md
index 53c76927..9101ea15 100755
--- a/docs/java/io/io-basis.md
+++ b/docs/java/io/io-basis.md
@@ -58,7 +58,7 @@ try (InputStream fis = new FileInputStream("input.txt")) {
`input.txt` 文件内容:
-
+
输出:
@@ -129,7 +129,7 @@ try (FileOutputStream output = new FileOutputStream("output.txt")) {
运行结果:
-
+
类似于 `FileInputStream`,`FileOutputStream` 通常也会配合 `BufferedOutputStream`(字节缓冲输出流,后文会讲到)来使用。
@@ -168,7 +168,7 @@ output.writeObject(person);
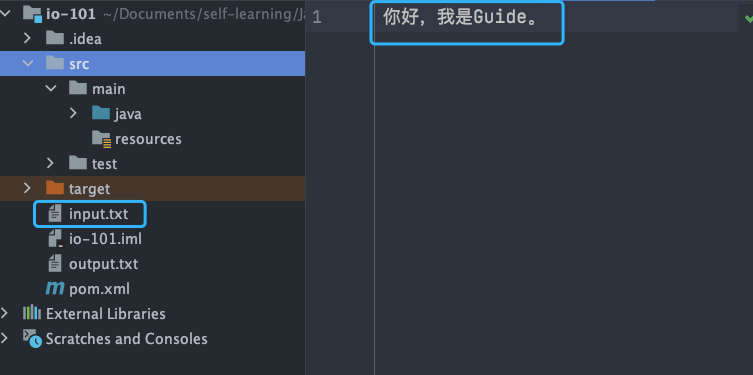
乱码问题这个很容易就可以复现,我们只需要将上面提到的 `FileInputStream` 代码示例中的 `input.txt` 文件内容改为中文即可,原代码不需要改动。
-
+
输出:
@@ -227,7 +227,7 @@ try (FileReader fileReader = new FileReader("input.txt");) {
`input.txt` 文件内容:
-
+
输出:
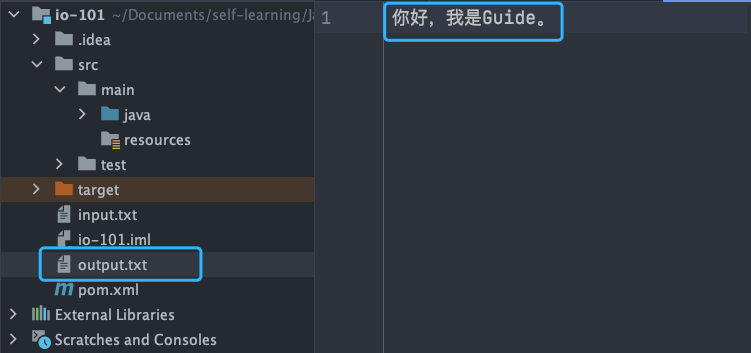
@@ -275,7 +275,7 @@ try (Writer output = new FileWriter("output.txt")) {
输出结果:
-
+
## 字节缓冲流
@@ -510,7 +510,7 @@ System.out.println("读取之前的偏移量:" + randomAccessFile.getFilePoint
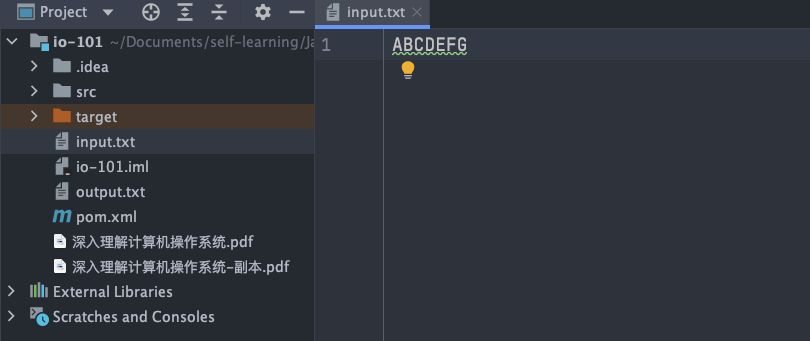
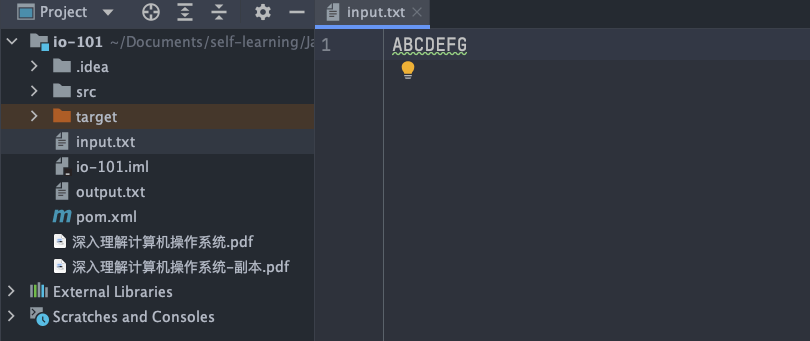
`input.txt` 文件内容:
-
+
输出:
@@ -535,10 +535,10 @@ randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});
`RandomAccessFile` 可以帮助我们合并文件分片,示例代码如下:
-
+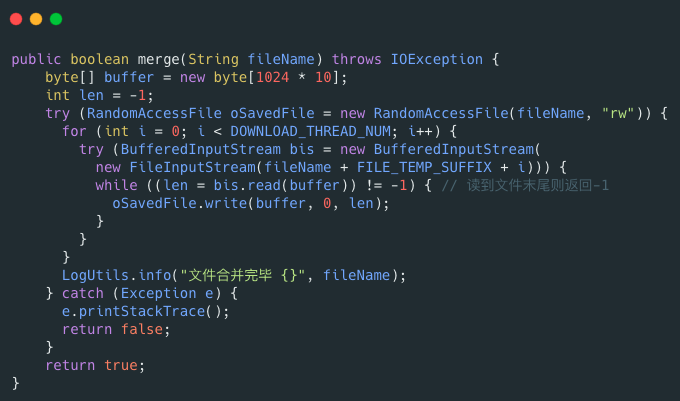
我在[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中详细介绍了大文件的上传问题。
-
+
`RandomAccessFile` 的实现依赖于 `FileDescriptor` (文件描述符) 和 `FileChannel` (内存映射文件)。
diff --git a/docs/java/io/io-model.md b/docs/java/io/io-model.md
index c91d8541..3741c415 100644
--- a/docs/java/io/io-model.md
+++ b/docs/java/io/io-model.md
@@ -25,7 +25,7 @@ I/O(**I**nput/**O**utpu) 即**输入/输出** 。
根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。
-
+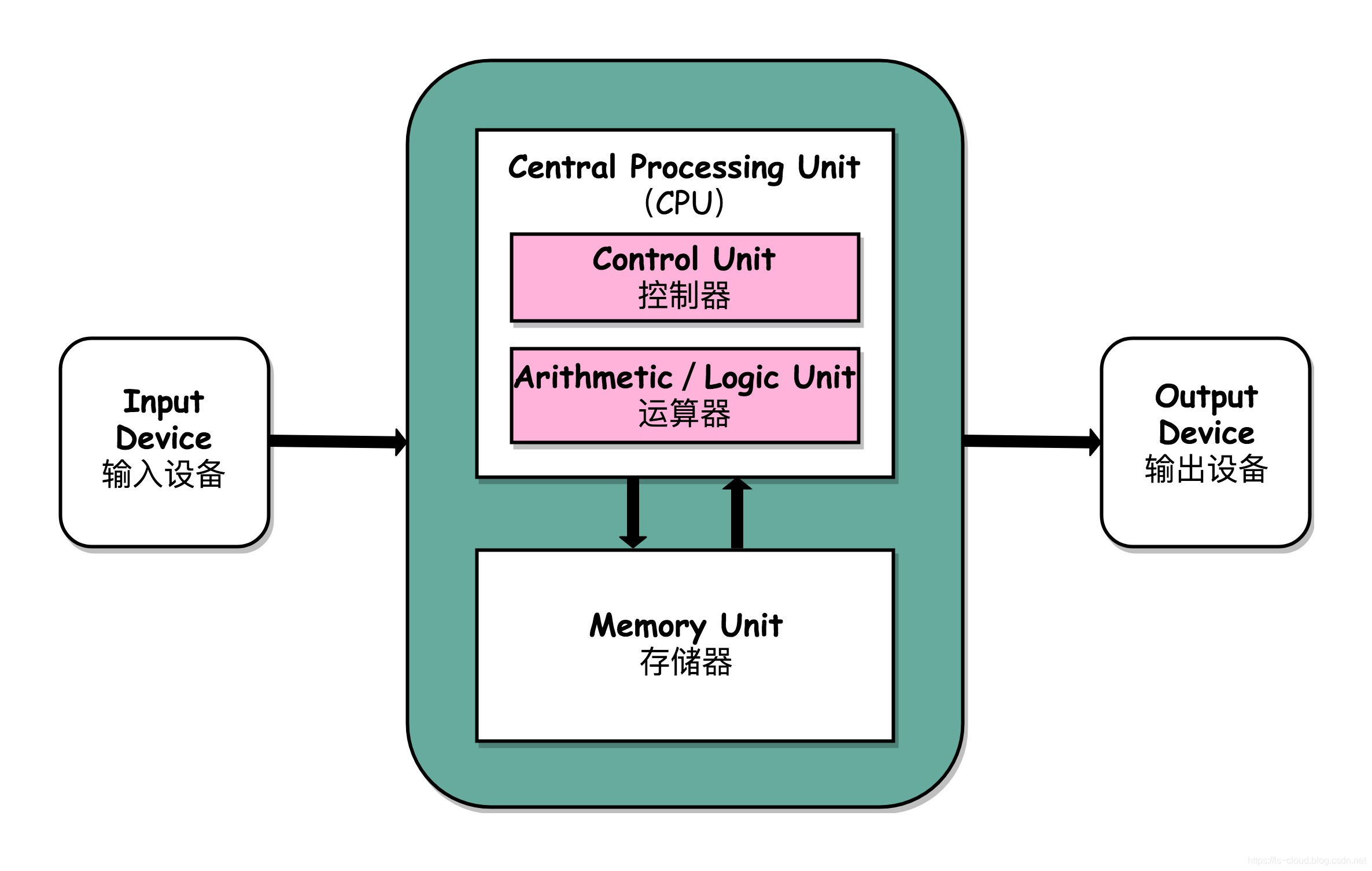
输入设备(比如键盘)和输出设备(比如显示器)都属于外部设备。网卡、硬盘这种既可以属于输入设备,也可以属于输出设备。
diff --git a/docs/java/jvm/class-file-structure.md b/docs/java/jvm/class-file-structure.md
index 3175e91b..9339bd66 100644
--- a/docs/java/jvm/class-file-structure.md
+++ b/docs/java/jvm/class-file-structure.md
@@ -44,11 +44,11 @@ ClassFile {
通过分析 `ClassFile` 的内容,我们便可以知道 class 文件的组成。
-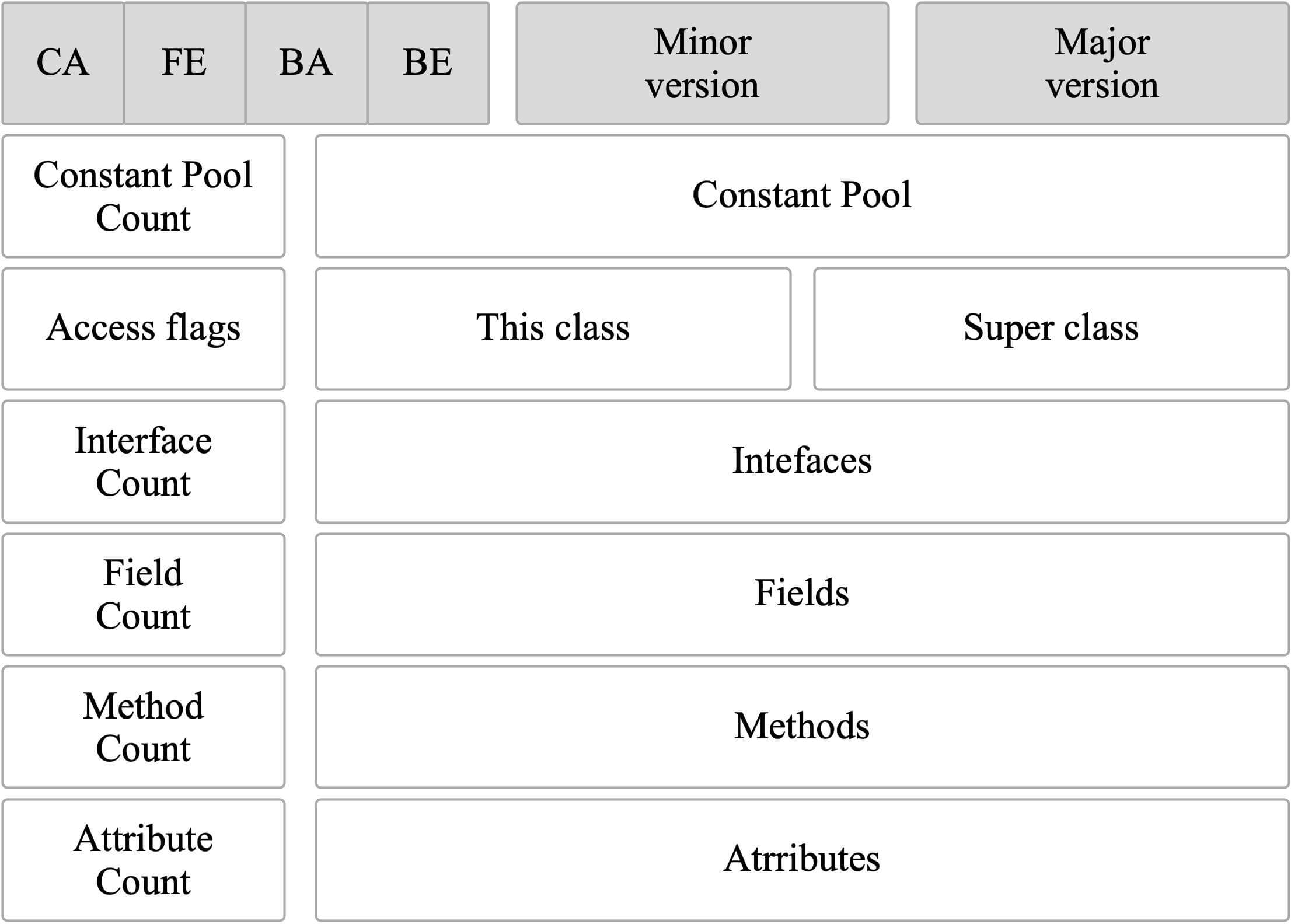
+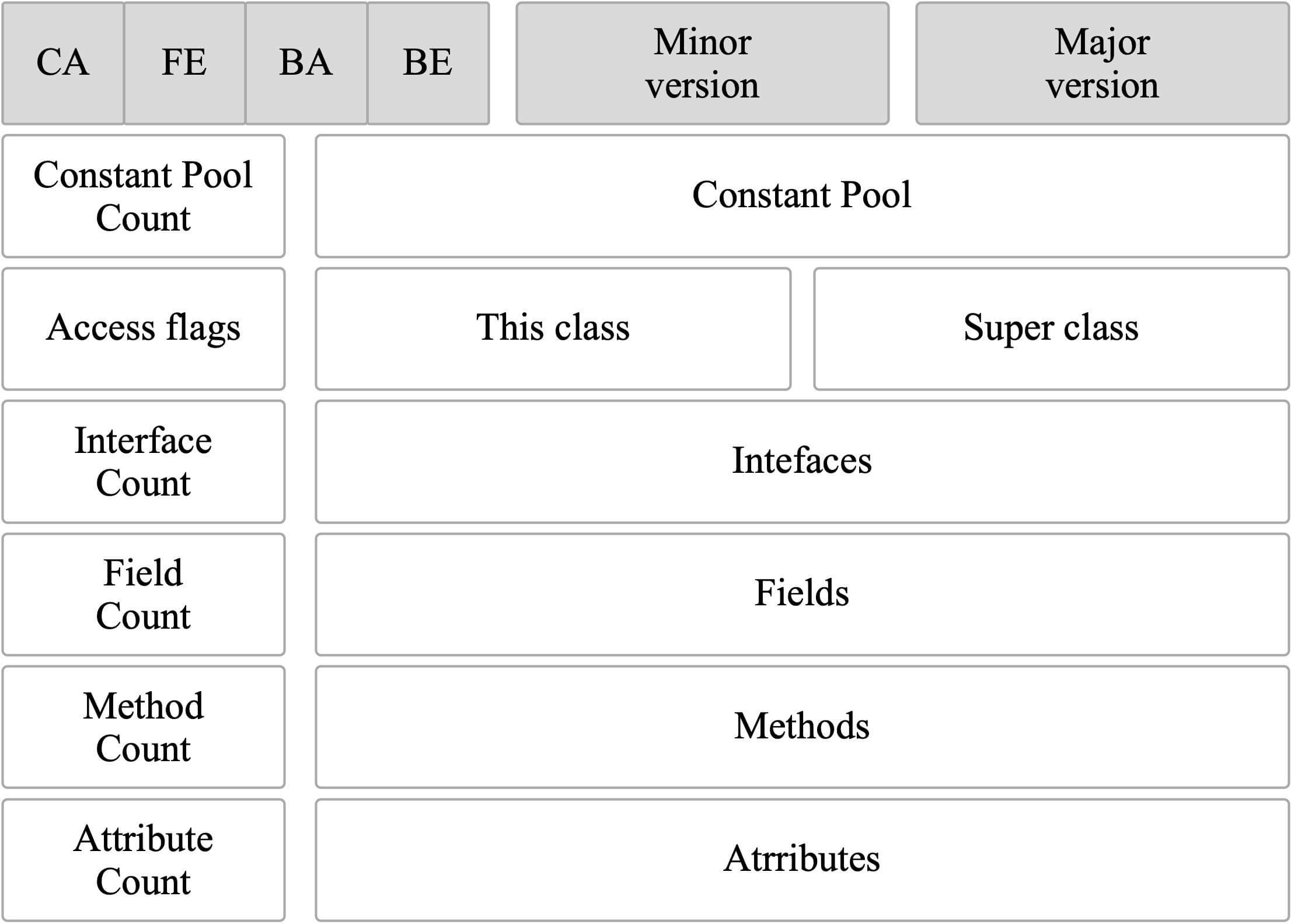
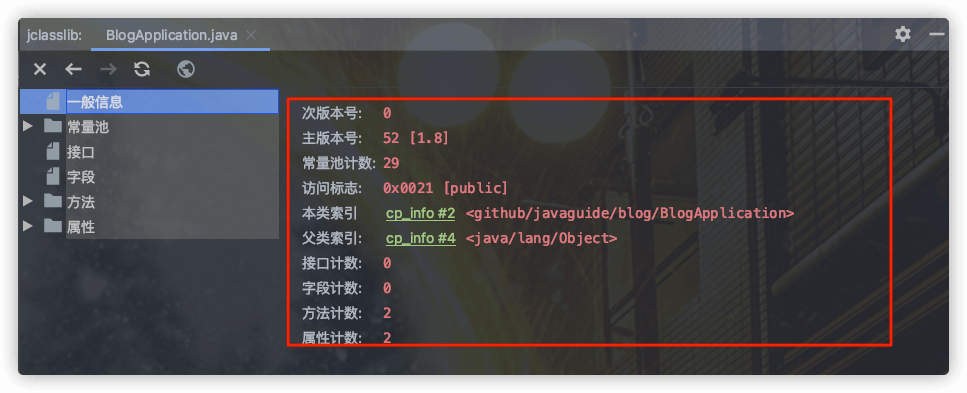
下面这张图是通过 IDEA 插件 `jclasslib` 查看的,你可以更直观看到 Class 文件结构。
-
+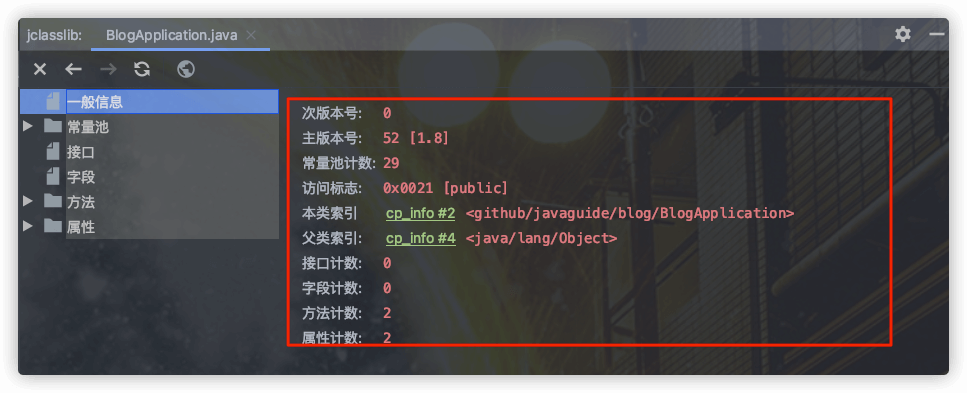
使用 `jclasslib` 不光可以直观地查看某个类对应的字节码文件,还可以查看类的基本信息、常量池、接口、属性、函数等信息。
@@ -176,7 +176,7 @@ Java 类的继承关系由类索引、父类索引和接口索引集合三项确
**字段的 access_flag 的取值:**
-
+
### 方法表集合(Methods)
@@ -195,7 +195,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
**方法表的 access_flag 取值:**
-
+
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
diff --git a/docs/java/jvm/class-loading-process.md b/docs/java/jvm/class-loading-process.md
index 1cd06f12..9e1b8e4c 100644
--- a/docs/java/jvm/class-loading-process.md
+++ b/docs/java/jvm/class-loading-process.md
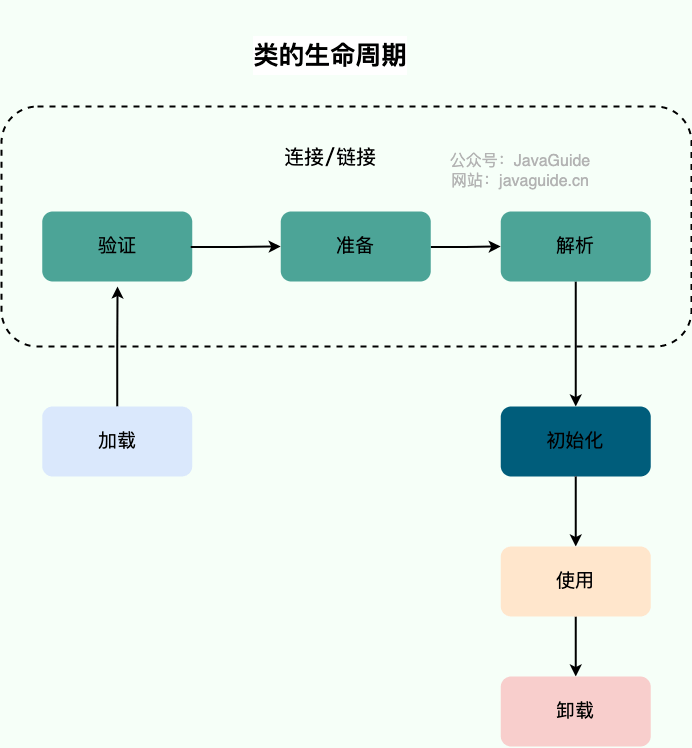
@@ -11,7 +11,7 @@ tag:
这 7 个阶段的顺序如下图所示:
-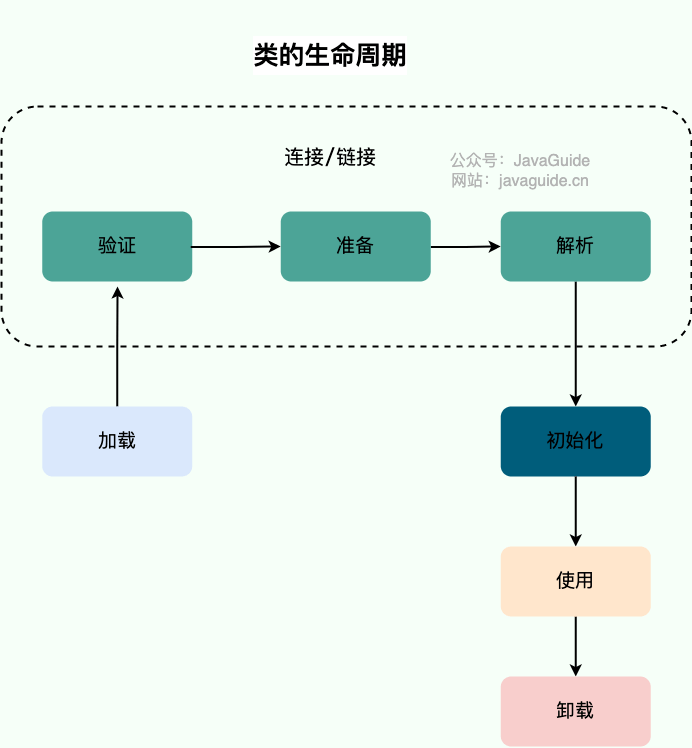
+
## 类加载过程
@@ -19,7 +19,7 @@ tag:
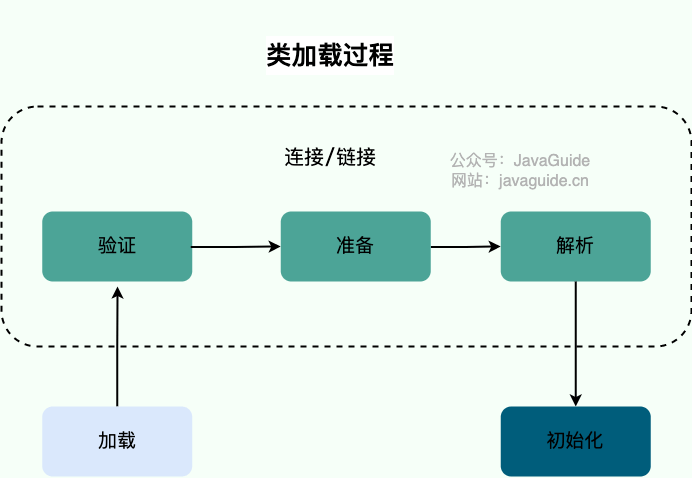
系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
-
+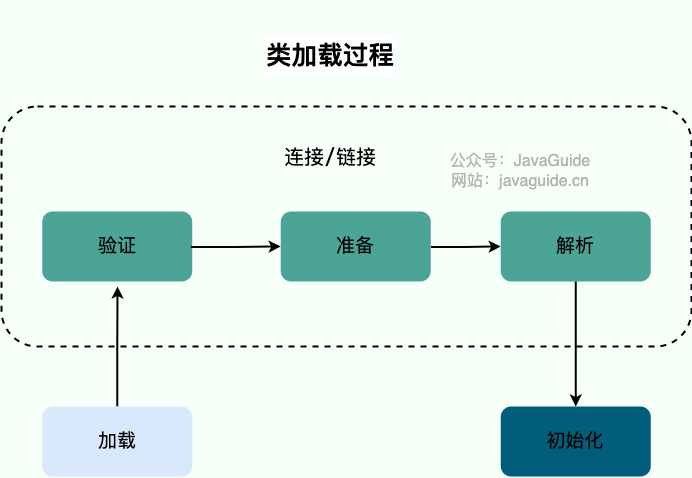
详见 [Java Virtual Machine Specification - 5.3. Creation and Loading](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-5.html#jvms-5.3 "Java Virtual Machine Specification - 5.3. Creation and Loading")。
@@ -58,7 +58,7 @@ tag:
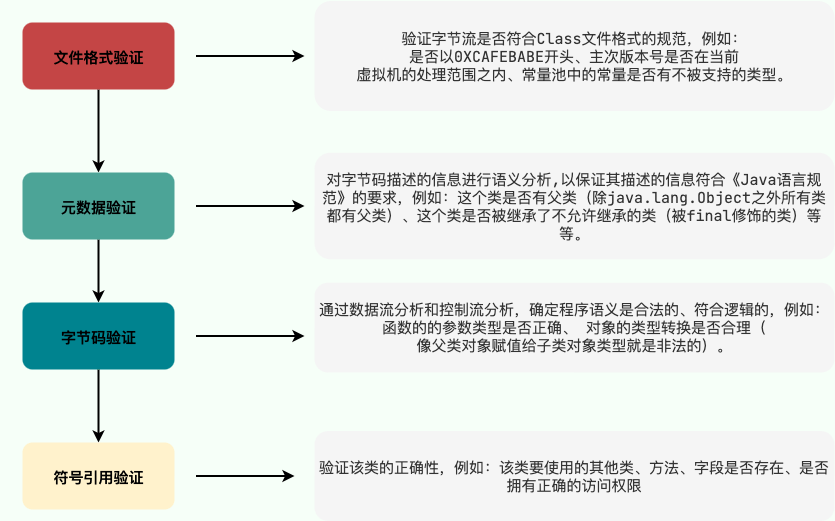
3. 字节码验证(程序语义检查)
4. 符号引用验证(类的正确性检查)
-
+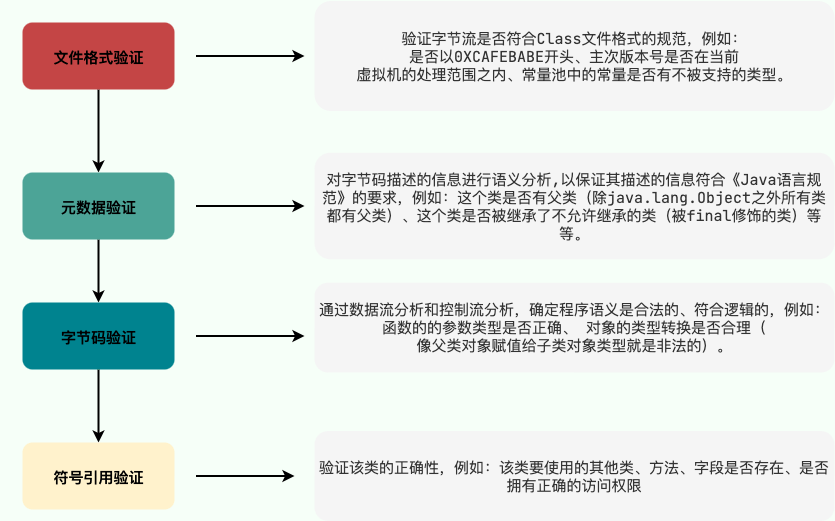
文件格式验证这一阶段是基于该类的二进制字节流进行的,主要目的是保证输入的字节流能正确地解析并存储于方法区之内,格式上符合描述一个 Java 类型信息的要求。除了这一阶段之外,其余三个验证阶段都是基于方法区的存储结构上进行的,不会再直接读取、操作字节流了。
@@ -93,7 +93,7 @@ tag:
《深入理解 Java 虚拟机》7.34 节第三版对符号引用和直接引用的解释如下:
-
+
举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方法表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
diff --git a/docs/java/jvm/classloader.md b/docs/java/jvm/classloader.md
index 4e5d9ab3..bbb91e02 100644
--- a/docs/java/jvm/classloader.md
+++ b/docs/java/jvm/classloader.md
@@ -12,7 +12,7 @@ tag:
- 类加载过程:**加载->连接->初始化**。
- 连接过程又可分为三步:**验证->准备->解析**。
-
+
加载是类加载过程的第一步,主要完成下面 3 件事情:
@@ -97,7 +97,7 @@ JVM 中内置了三个重要的 `ClassLoader`:
除了这三种类加载器之外,用户还可以加入自定义的类加载器来进行拓展,以满足自己的特殊需求。就比如说,我们可以对 Java 类的字节码( `.class` 文件)进行加密,加载时再利用自定义的类加载器对其解密。
-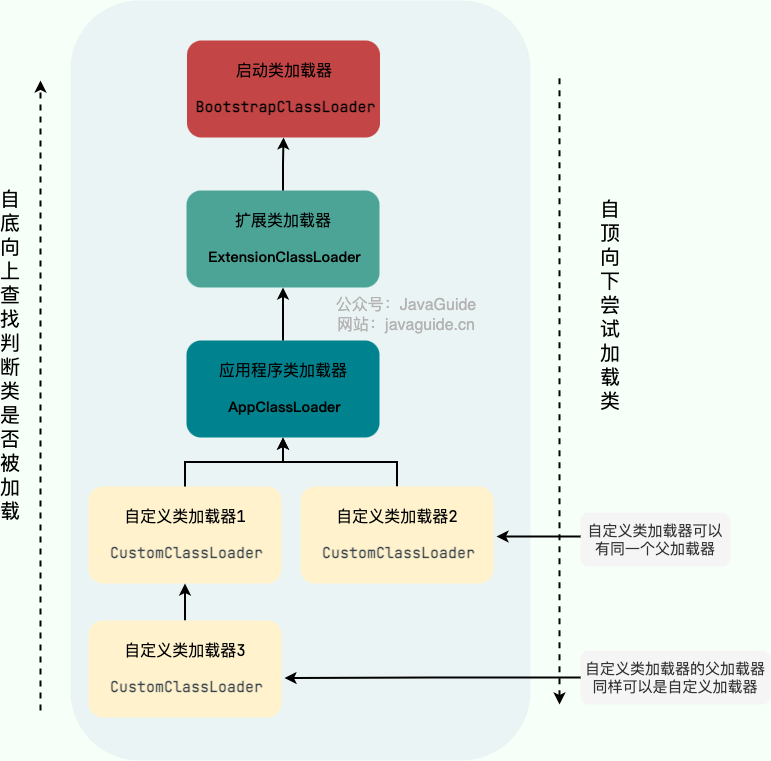
+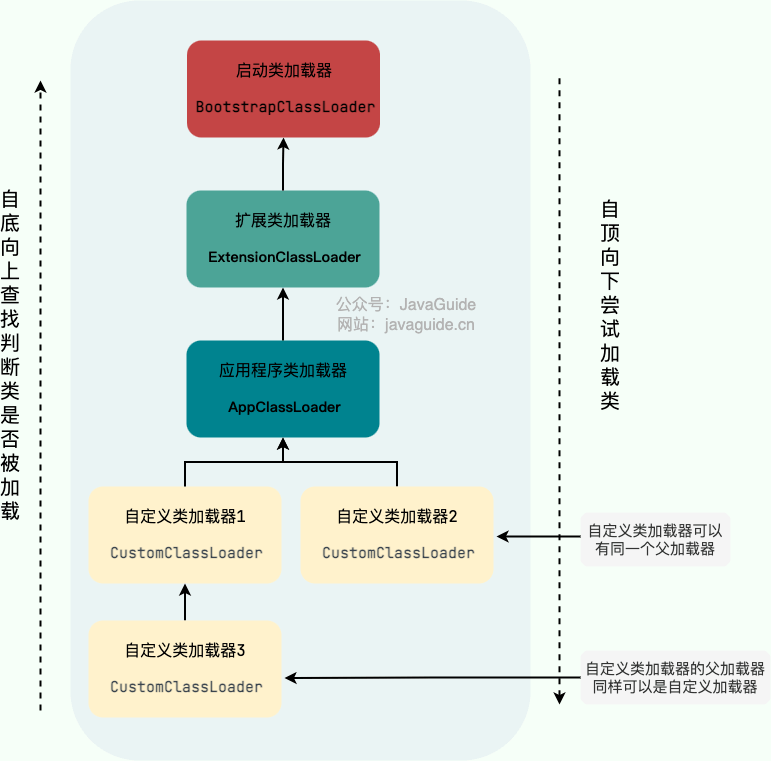
除了 `BootstrapClassLoader` 是 JVM 自身的一部分之外,其他所有的类加载器都是在 JVM 外部实现的,并且全都继承自 `ClassLoader`抽象类。这样做的好处是用户可以自定义类加载器,以便让应用程序自己决定如何去获取所需的类。
@@ -197,7 +197,7 @@ public class PrintClassLoaderTree {
下图展示的各种类加载器之间的层次关系被称为类加载器的“**双亲委派模型(Parents Delegation Model)**”。
-
+
注意⚠️:双亲委派模型并不是一种强制性的约束,只是 JDK 官方推荐的一种方式。如果我们因为某些特殊需求想要打破双亲委派模型,也是可以的,后文会介绍具体的方法。
@@ -298,7 +298,7 @@ protected Class loadClass(String name, boolean resolve)
Tomcat 的类加载器的层次结构如下:
-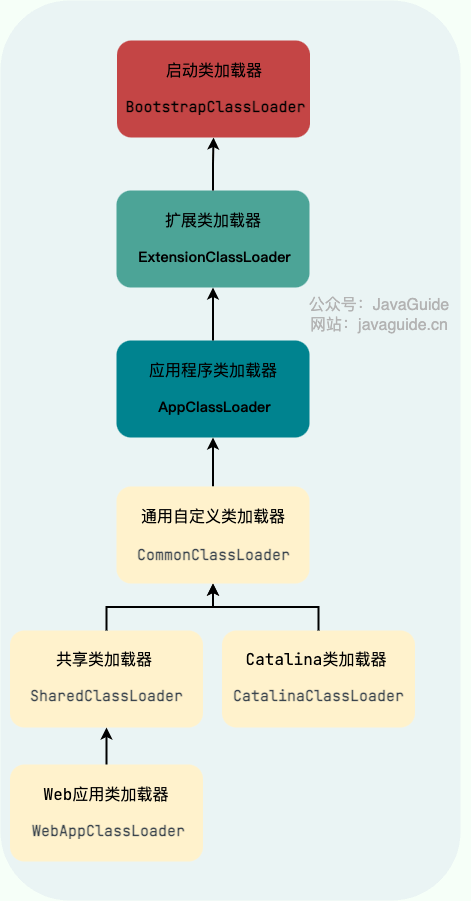
+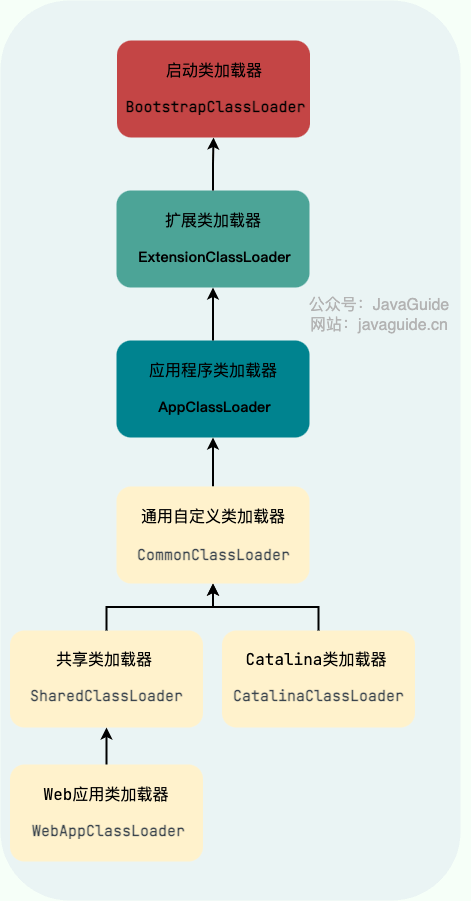
感兴趣的小伙伴可以自行研究一下 Tomcat 类加载器的层次结构,这有助于我们搞懂 Tomcat 隔离 Web 应用的原理,推荐资料是[《深入拆解 Tomcat & Jetty》](http://gk.link/a/10Egr)。
diff --git a/docs/java/jvm/jvm-garbage-collection.md b/docs/java/jvm/jvm-garbage-collection.md
index 01f67ef6..b714acf7 100644
--- a/docs/java/jvm/jvm-garbage-collection.md
+++ b/docs/java/jvm/jvm-garbage-collection.md
@@ -121,7 +121,7 @@ public class GCTest {
>
> jdk8 官方文档引用 :https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html 。
>
-> 
+> 
>
> **动态年龄计算的代码如下:**
>
diff --git a/docs/java/jvm/memory-area.md b/docs/java/jvm/memory-area.md
index 382d6ad9..a5b696c6 100644
--- a/docs/java/jvm/memory-area.md
+++ b/docs/java/jvm/memory-area.md
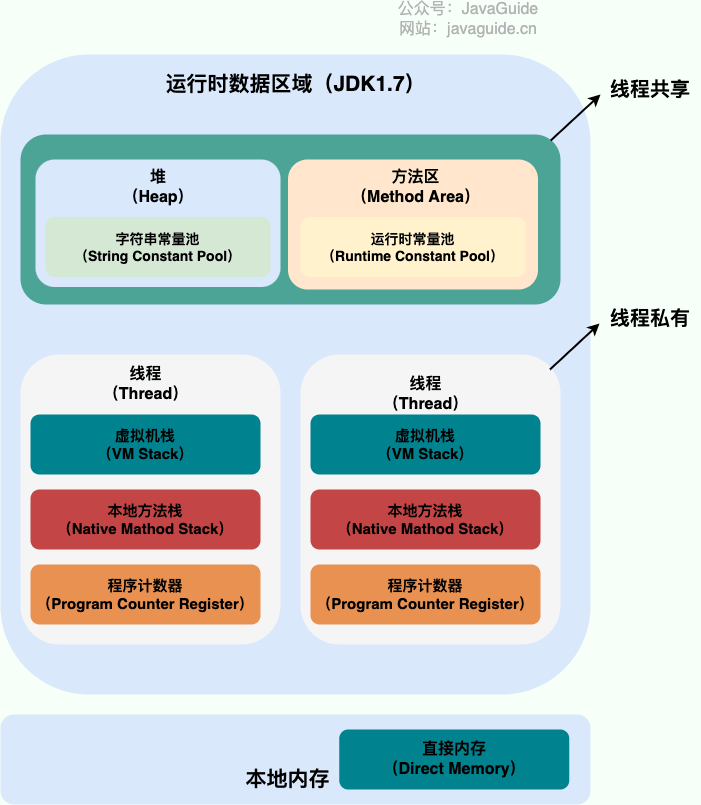
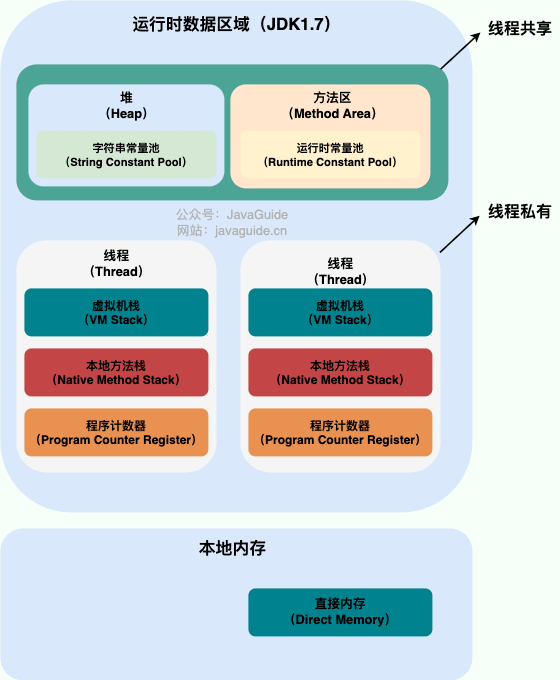
@@ -25,11 +25,11 @@ Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成
**JDK 1.8 之前** :
-
+
**JDK 1.8 之后** :
-
+
**线程私有的:**
@@ -68,17 +68,17 @@ Java 虚拟机规范对于运行时数据区域的规定是相当宽松的。以
栈由一个个栈帧组成,而每个栈帧中都拥有:局部变量表、操作数栈、动态链接、方法返回地址。和数据结构上的栈类似,两者都是先进后出的数据结构,只支持出栈和入栈两种操作。
-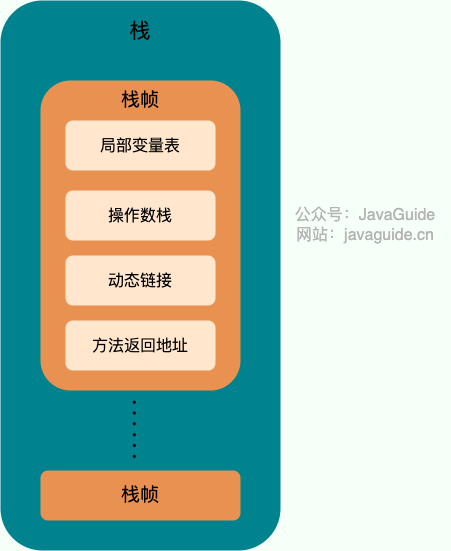
+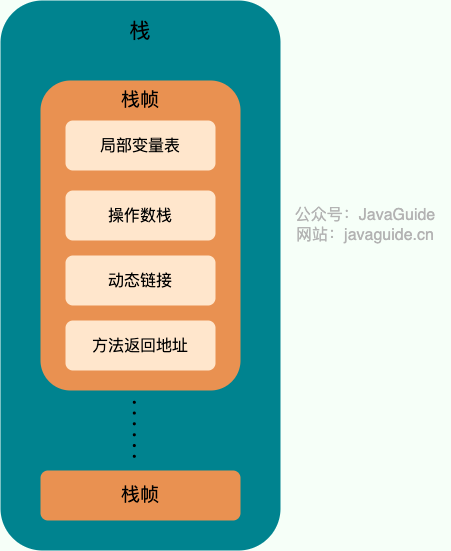
**局部变量表** 主要存放了编译期可知的各种数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)。
-
+
**操作数栈** 主要作为方法调用的中转站使用,用于存放方法执行过程中产生的中间计算结果。另外,计算过程中产生的临时变量也会放在操作数栈中。
**动态链接** 主要服务一个方法需要调用其他方法的场景。Class 文件的常量池里保存有大量的符号引用比如方法引用的符号引用。当一个方法要调用其他方法,需要将常量池中指向方法的符号引用转化为其在内存地址中的直接引用。动态链接的作用就是为了将符号引用转换为调用方法的直接引用,这个过程也被称为 **动态连接** 。
-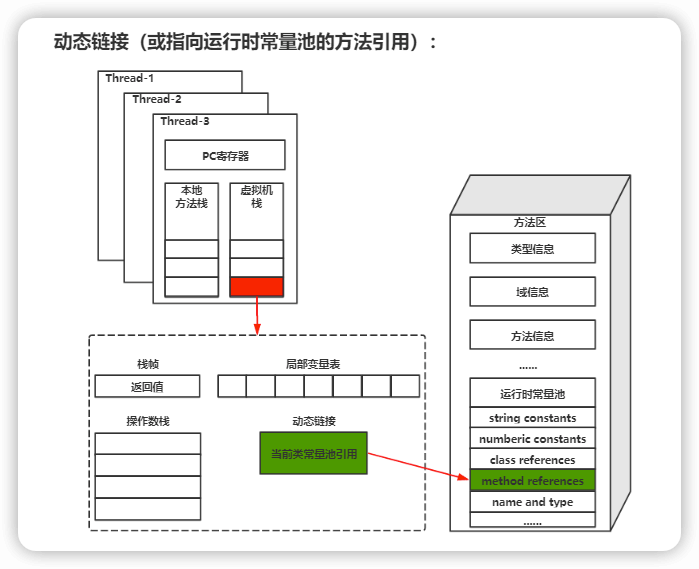
+
栈空间虽然不是无限的,但一般正常调用的情况下是不会出现问题的。不过,如果函数调用陷入无限循环的话,就会导致栈中被压入太多栈帧而占用太多空间,导致栈空间过深。那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 `StackOverFlowError` 错误。
@@ -159,13 +159,13 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
**方法区和永久代以及元空间是什么关系呢?** 方法区和永久代以及元空间的关系很像 Java 中接口和类的关系,类实现了接口,这里的类就可以看作是永久代和元空间,接口可以看作是方法区,也就是说永久代以及元空间是 HotSpot 虚拟机对虚拟机规范中方法区的两种实现方式。并且,永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
-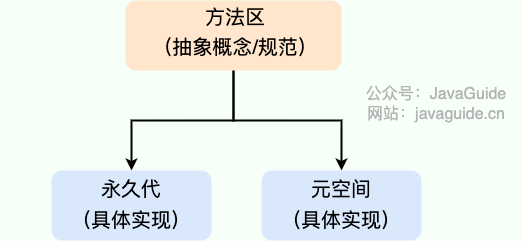
+
**为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?**
下图来自《深入理解 Java 虚拟机》第 3 版 2.2.5
-
+
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
@@ -205,7 +205,7 @@ Class 文件中除了有类的版本、字段、方法、接口等描述信息
《深入理解 Java 虚拟机》7.34 节第三版对符号引用和直接引用的解释如下:
-
+
常量池表会在类加载后存放到方法区的运行时常量池中。
@@ -232,9 +232,9 @@ HotSpot 虚拟机中字符串常量池的实现是 `src/hotspot/share/classfile/
JDK1.7 之前,字符串常量池存放在永久代。JDK1.7 字符串常量池和静态变量从永久代移动了 Java 堆中。
-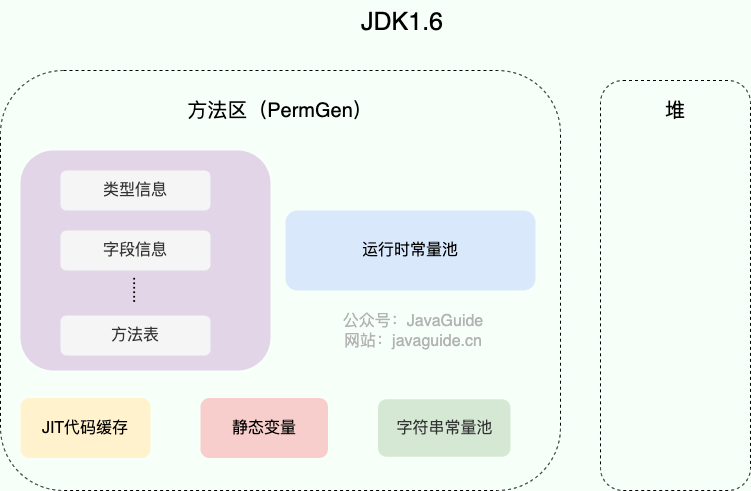
+
-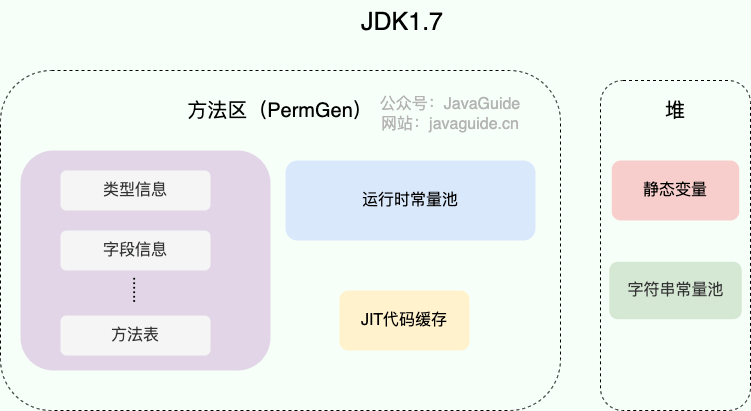
+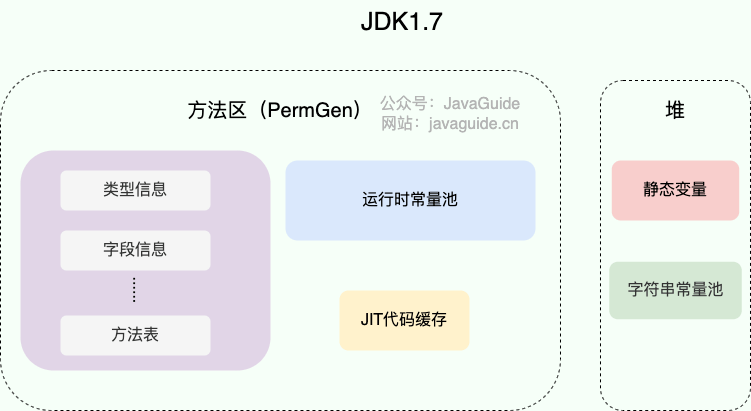
**JDK 1.7 为什么要将字符串常量池移动到堆中?**
@@ -326,13 +326,13 @@ Java 对象的创建过程我建议最好是能默写出来,并且要掌握每
如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与对象类型数据各自的具体地址信息。
-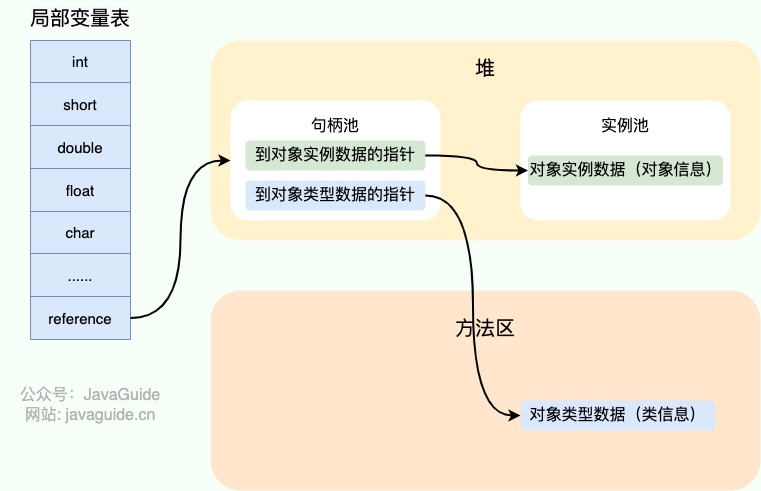
+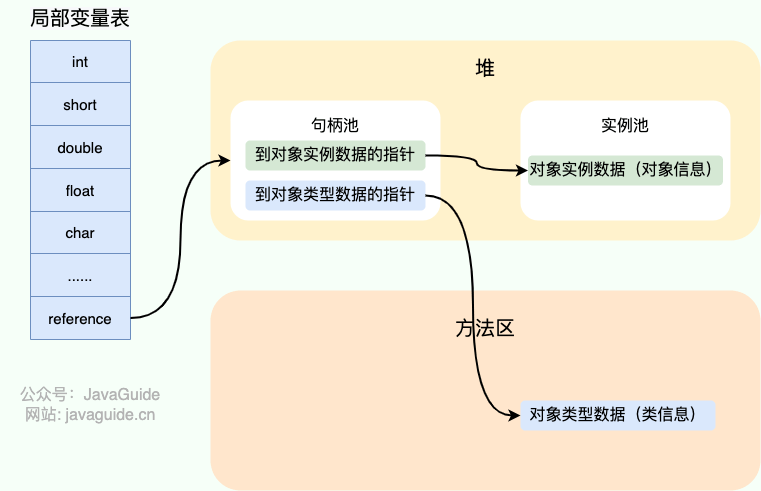
#### 直接指针
如果使用直接指针访问,reference 中存储的直接就是对象的地址。
-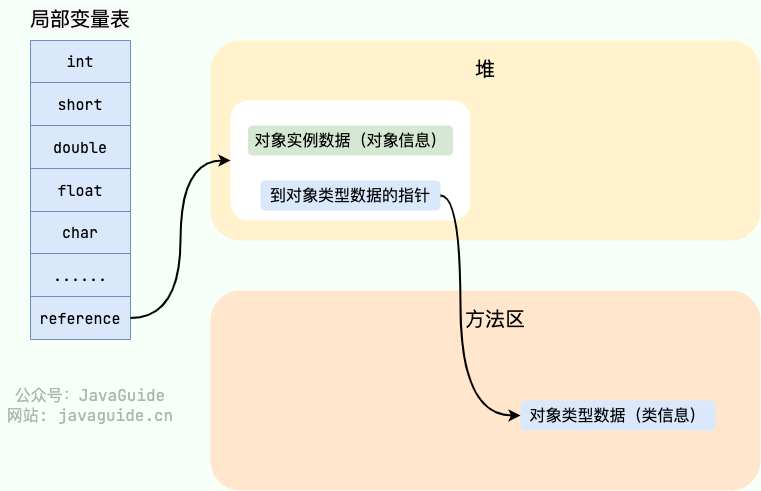
+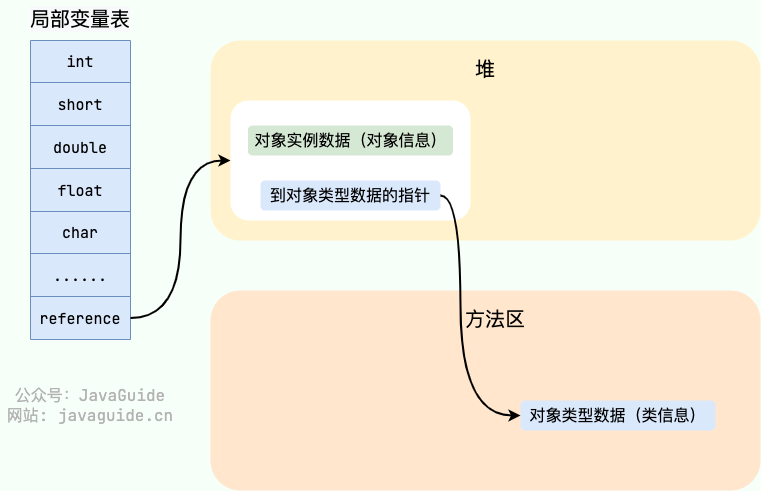
这两种对象访问方式各有优势。使用句柄来访问的最大好处是 reference 中存储的是稳定的句柄地址,在对象被移动时只会改变句柄中的实例数据指针,而 reference 本身不需要修改。使用直接指针访问方式最大的好处就是速度快,它节省了一次指针定位的时间开销。
diff --git a/docs/java/new-features/java10.md b/docs/java/new-features/java10.md
index fa34b90d..e164837e 100644
--- a/docs/java/new-features/java10.md
+++ b/docs/java/new-features/java10.md
@@ -69,7 +69,7 @@ static List copyOf(Collection coll) {
使用 `copyOf()` 创建的集合为不可变集合,不能进行添加、删除、替换、 排序等操作,不然会报 `java.lang.UnsupportedOperationException` 异常。 IDEA 也会有相应的提示。
-
+
并且,`java.util.stream.Collectors` 中新增了静态方法,用于将流中的元素收集为不可变的集合。
diff --git a/docs/java/new-features/java11.md b/docs/java/new-features/java11.md
index 361dd775..282c82a1 100644
--- a/docs/java/new-features/java11.md
+++ b/docs/java/new-features/java11.md
@@ -9,7 +9,7 @@ tag:
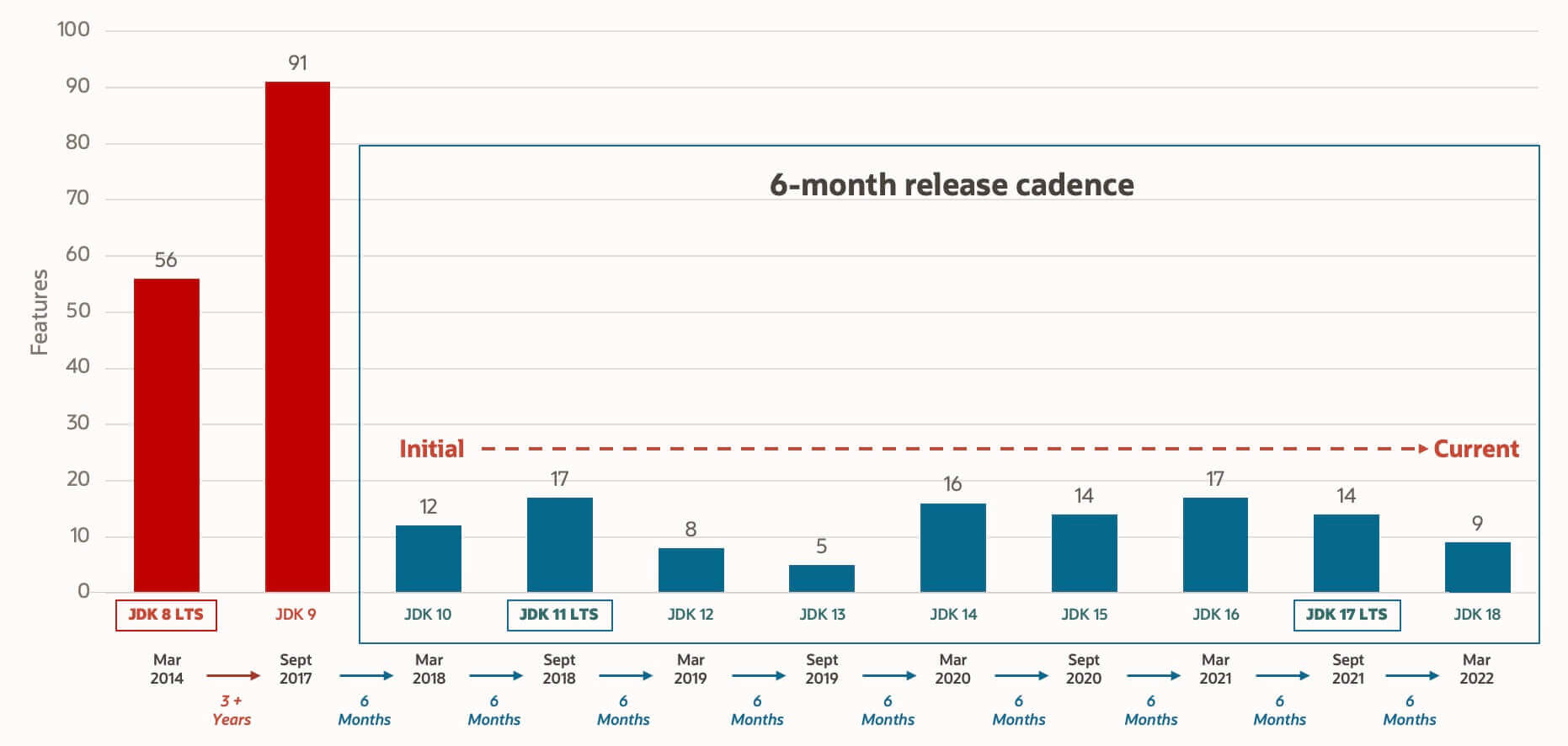
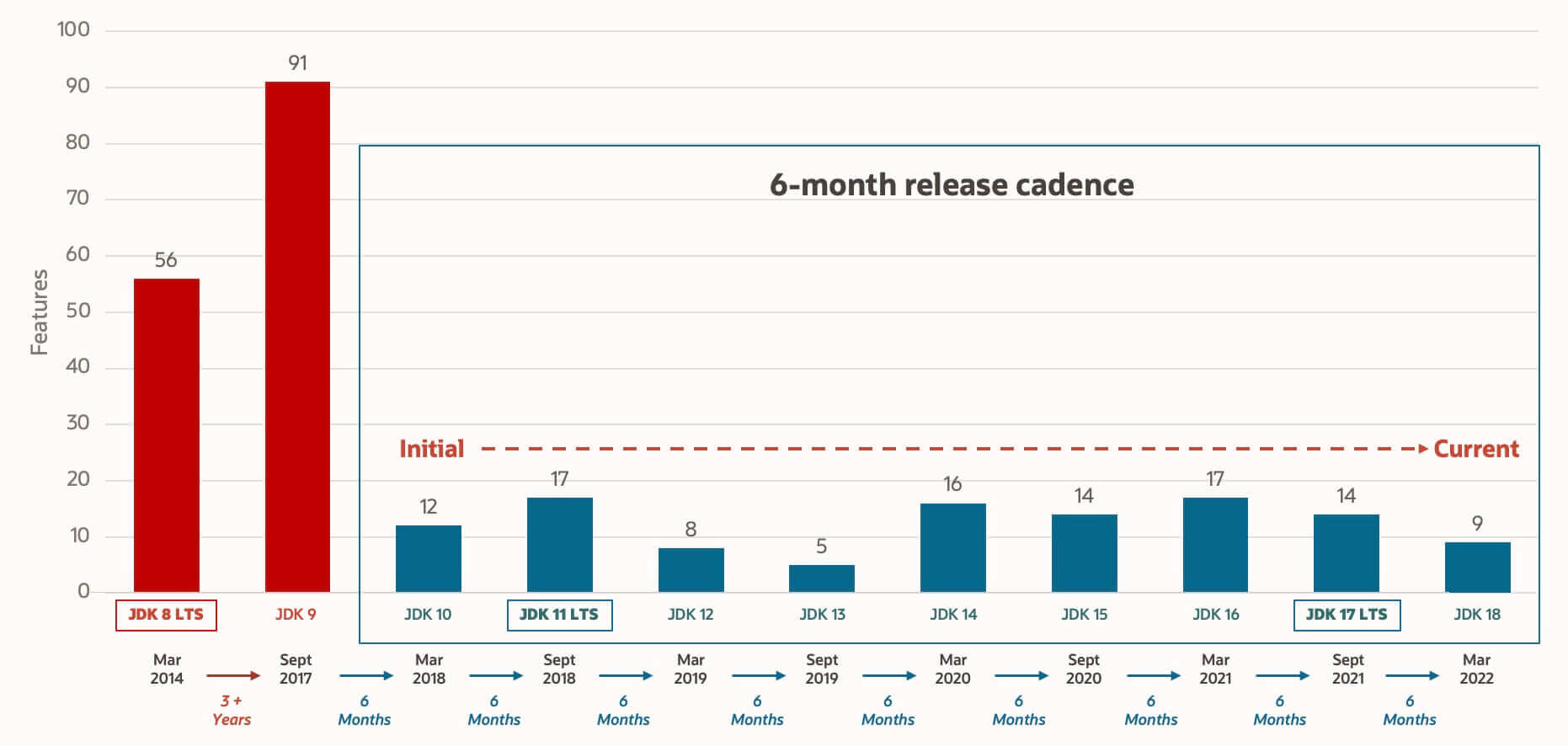
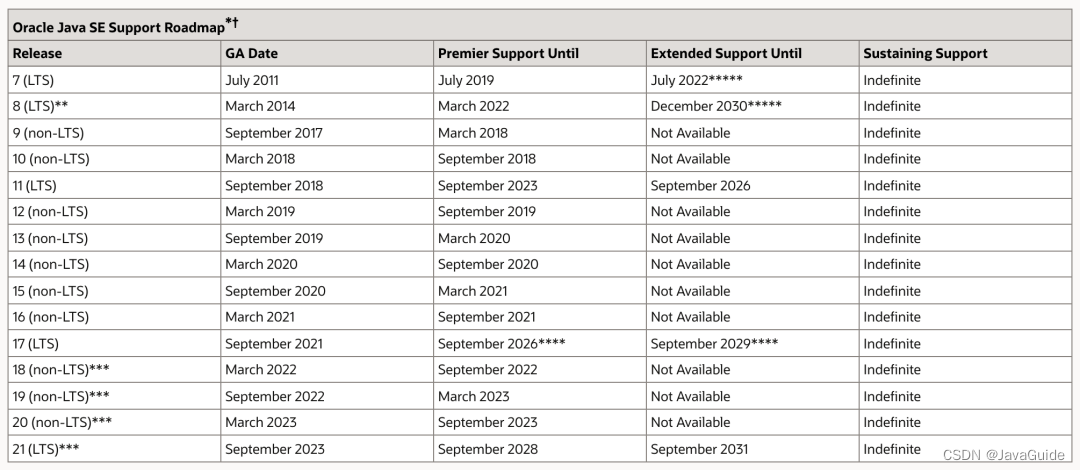
下面这张图是 Oracle 官方给出的 Oracle JDK 支持的时间线。
-
+
**概览(精选了一部分)** :
diff --git a/docs/java/new-features/java15.md b/docs/java/new-features/java15.md
index 5879c08e..10eca7f9 100644
--- a/docs/java/new-features/java15.md
+++ b/docs/java/new-features/java15.md
@@ -105,7 +105,7 @@ public non-sealed class Manager extends Person {
}
```
-
+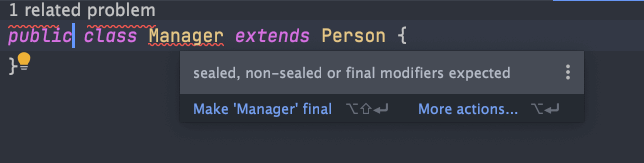
如果允许扩展的子类和封闭类在同一个源代码文件里,封闭类可以不使用 permits 语句,Java 编译器将检索源文件,在编译期为封闭类添加上许可的子类。
diff --git a/docs/java/new-features/java17.md b/docs/java/new-features/java17.md
index 500f1946..5b6e8017 100644
--- a/docs/java/new-features/java17.md
+++ b/docs/java/new-features/java17.md
@@ -11,7 +11,7 @@ Java 17 在 2021 年 9 月 14 日正式发布,是一个长期支持(LTS)
17 最多可以支持到 2029 年 9 月份。
-
+
Java 17 将是继 Java 8 以来最重要的长期支持(LTS)版本,是 Java 社区八年努力的成果。Spring 6.x 和 Spring Boot 3.x 最低支持的就是 Java 17。
diff --git a/docs/java/new-features/java18.md b/docs/java/new-features/java18.md
index 32a9b3ee..91aeeeb5 100644
--- a/docs/java/new-features/java18.md
+++ b/docs/java/new-features/java18.md
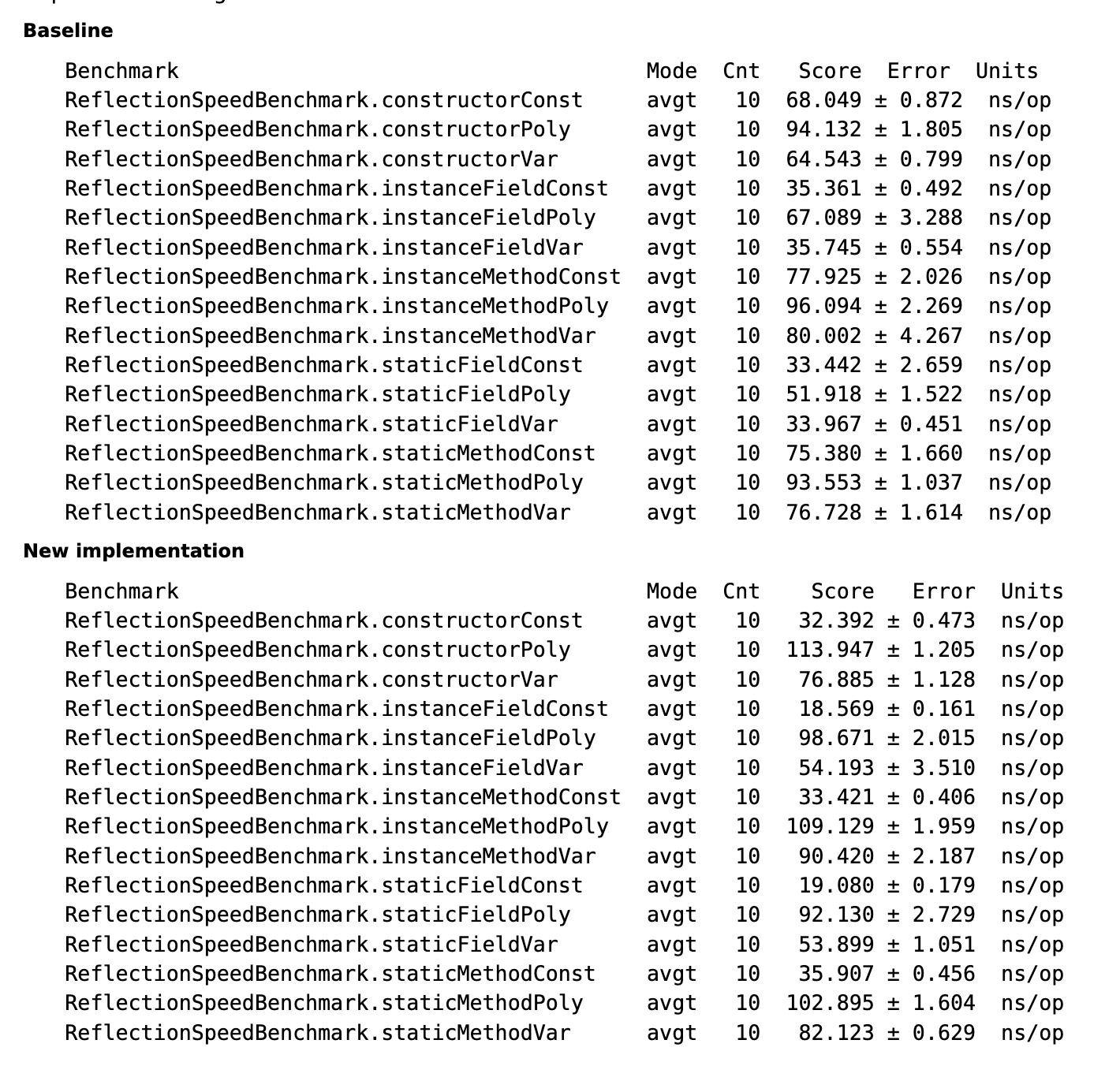
@@ -80,7 +80,7 @@ Java 18 改进了 `java.lang.reflect.Method`、`Constructor` 的实现逻辑,
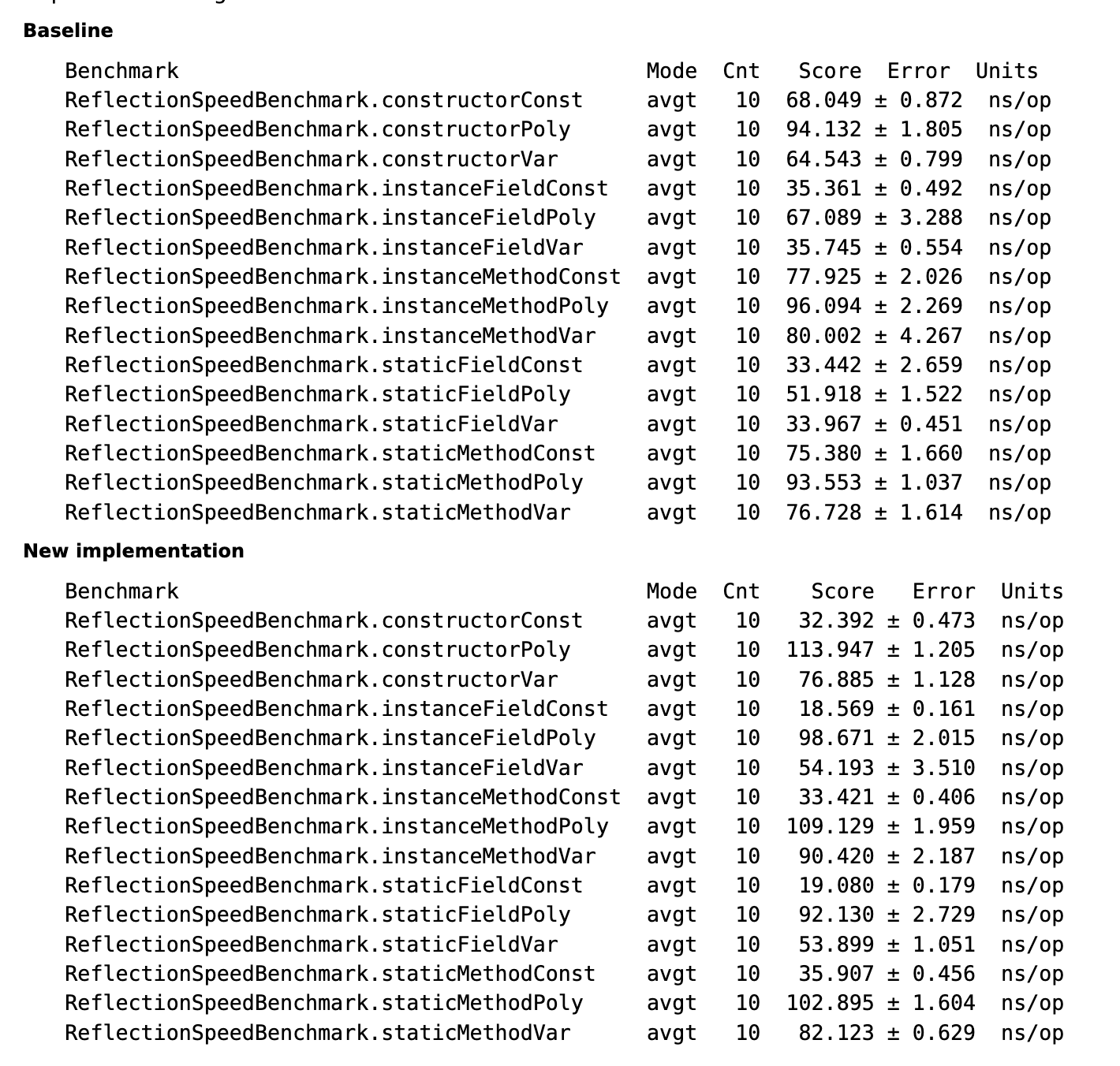
OpenJDK 官方给出了新老实现的反射性能基准测试结果。
-
+
## JEP 417: 向量 API(第三次孵化)
diff --git a/docs/java/new-features/java8-tutorial-translate.md b/docs/java/new-features/java8-tutorial-translate.md
index 270976c7..980a9eca 100644
--- a/docs/java/new-features/java8-tutorial-translate.md
+++ b/docs/java/new-features/java8-tutorial-translate.md
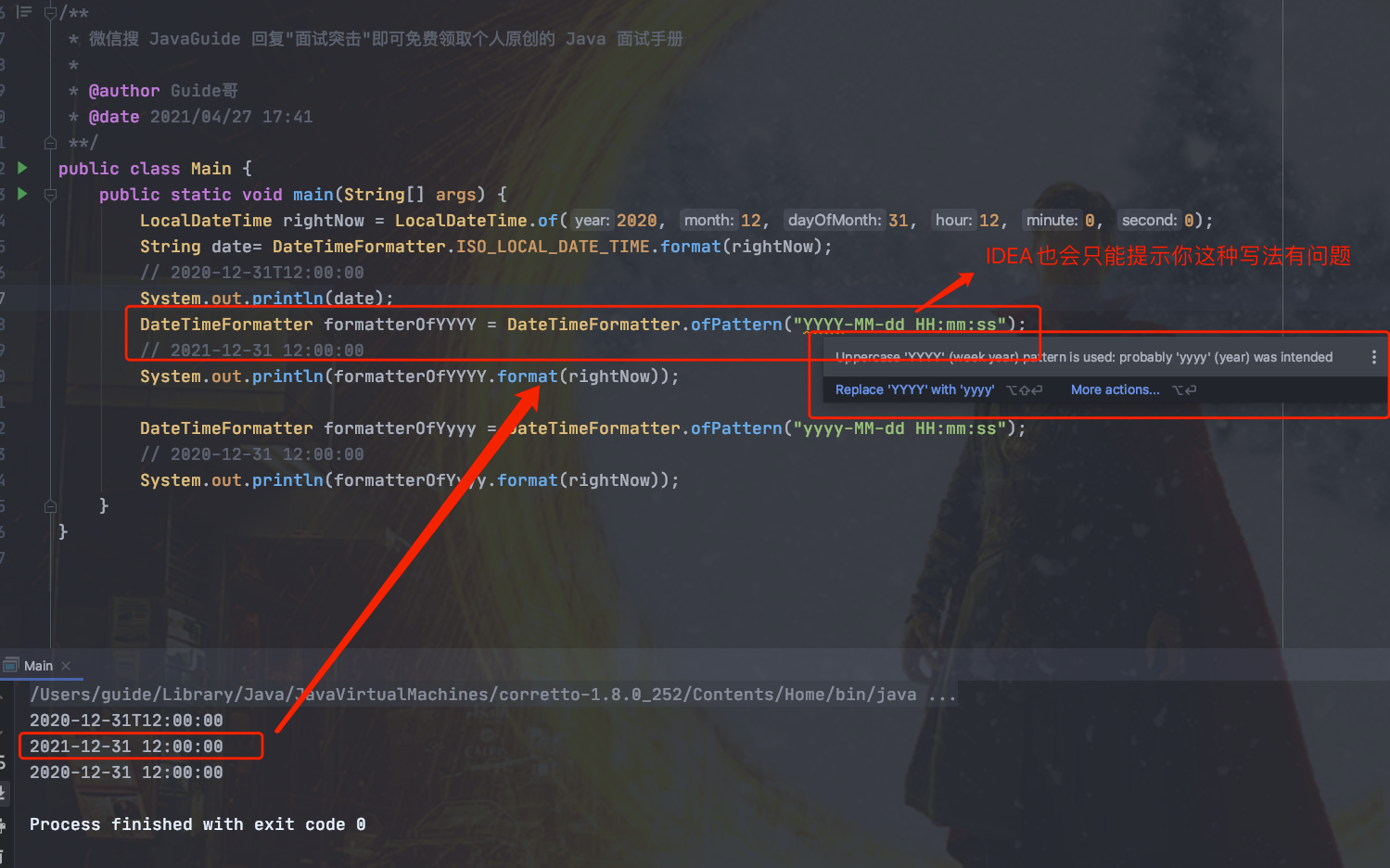
@@ -803,7 +803,7 @@ System.out.println(formatterOfYyyy.format(rightNow));
从下图可以更清晰的看到具体的错误,并且 IDEA 已经智能地提示更倾向于使用 `yyyy` 而不是 `YYYY` 。
-
+
### LocalDateTime(本地日期时间)
diff --git a/docs/java/new-features/java9.md b/docs/java/new-features/java9.md
index bc6eb28d..48aaa6ee 100644
--- a/docs/java/new-features/java9.md
+++ b/docs/java/new-features/java9.md
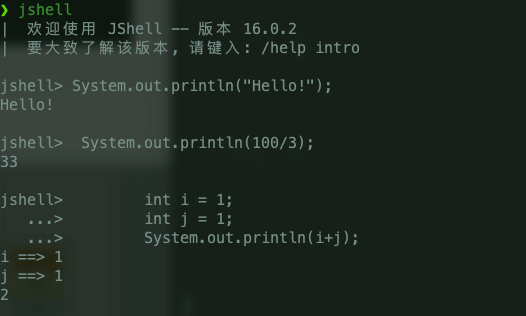
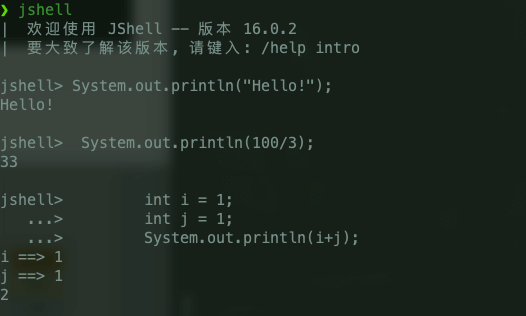
@@ -23,7 +23,7 @@ JShell 是 Java 9 新增的一个实用工具。为 Java 提供了类似于 Pyth
在 JShell 中可以直接输入表达式并查看其执行结果。
-
+
**JShell 为我们带来了哪些好处呢?**
@@ -50,7 +50,7 @@ JShell 是 Java 9 新增的一个实用工具。为 Java 提供了类似于 Pyth
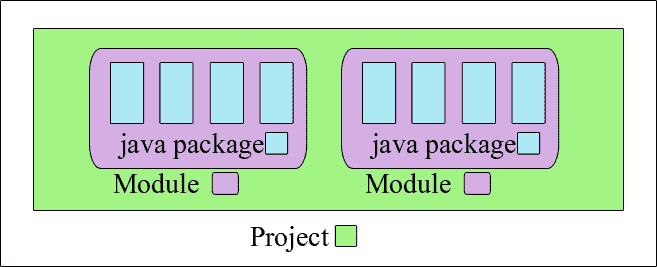
任意一个 jar 文件,只要加上一个模块描述文件(`module-info.java`),就可以升级为一个模块。
-
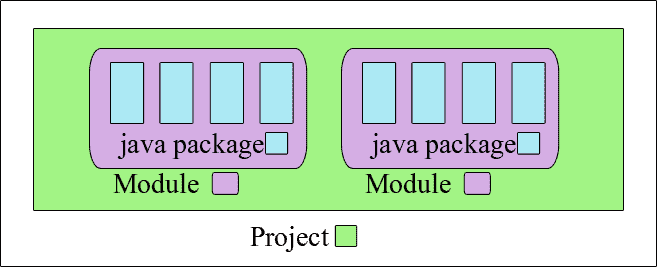
+
在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 **[jlink](http://openjdk.java.net/jeps/282) 工具** (Jlink 是随 Java 9 一起发布的新命令行工具。它允许开发人员为基于模块的 Java 应用程序创建自己的轻量级、定制的 JRE),创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。
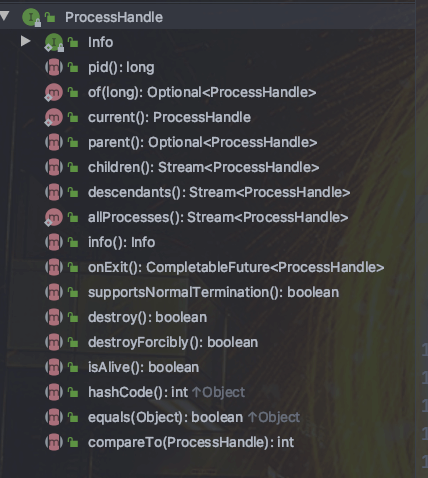
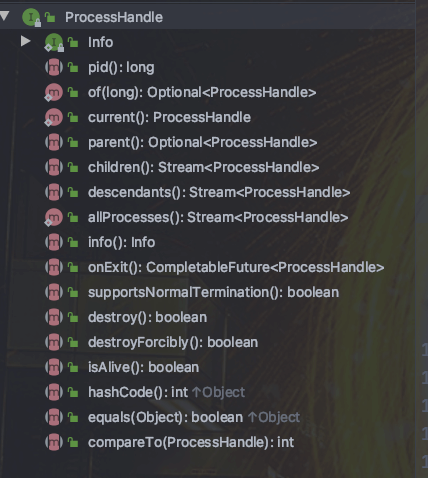
@@ -223,7 +223,7 @@ System.out.println(currentProcess.info());
`ProcessHandle` 接口概览:
-
+
## 响应式流 ( Reactive Streams )
diff --git a/docs/javaguide/faq.md b/docs/javaguide/faq.md
index 5df8e87e..f2d5c578 100644
--- a/docs/javaguide/faq.md
+++ b/docs/javaguide/faq.md
@@ -10,7 +10,7 @@ category: 走近项目
《JavaGuide 面试突击版》在我的公众号后台回复“**PDF**”即可获取,免费的。除了 《JavaGuide 面试突击版》之外,还会免费送你多本优质面试 PDF 手册。
-

+

 +
+ 
 -
-  -
-  -
-  +
+ 
 +
+ 
 +
+ 
 +
+ 