
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 63. 不同路径 II +# 63. 不同路径 II [力扣题目链接](https://leetcode-cn.com/problems/unique-paths-ii/) @@ -22,23 +22,22 @@  -输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]] -输出:2 +* 输入:obstacleGrid = [[0,0,0],[0,1,0],[0,0,0]] +* 输出:2 解释: -3x3 网格的正中间有一个障碍物。 -从左上角到右下角一共有 2 条不同的路径: -1. 向右 -> 向右 -> 向下 -> 向下 -2. 向下 -> 向下 -> 向右 -> 向右 +* 3x3 网格的正中间有一个障碍物。 +* 从左上角到右下角一共有 2 条不同的路径: + 1. 向右 -> 向右 -> 向下 -> 向下 + 2. 向下 -> 向下 -> 向右 -> 向右 示例 2:  -输入:obstacleGrid = [[0,1],[0,0]] -输出:1 +* 输入:obstacleGrid = [[0,1],[0,0]] +* 输出:1 提示: - * m == obstacleGrid.length * n == obstacleGrid[i].length * 1 <= m, n <= 100 @@ -153,8 +152,41 @@ public: }; ``` -* 时间复杂度:$O(n × m)$,n、m 分别为obstacleGrid 长度和宽度 -* 空间复杂度:$O(n × m)$ +* 时间复杂度:O(n × m),n、m 分别为obstacleGrid 长度和宽度 +* 空间复杂度:O(n × m) + + +同样我们给出空间优化版本: +```CPP +class Solution { +public: + int uniquePathsWithObstacles(vector参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 96.不同的二叉搜索树 +# 96.不同的二叉搜索树 [力扣题目链接](https://leetcode-cn.com/problems/unique-binary-search-trees/) @@ -163,7 +163,7 @@ public: ## 其他语言版本 -Java: +### Java ```Java class Solution { public int numTrees(int n) { @@ -184,7 +184,7 @@ class Solution { } ``` -Python: +### Python ```python class Solution: def numTrees(self, n: int) -> int: @@ -196,7 +196,7 @@ class Solution: return dp[-1] ``` -Go: +### Go ```Go func numTrees(n int)int{ dp:=make([]int,n+1) @@ -210,7 +210,7 @@ func numTrees(n int)int{ } ``` -Javascript: +### Javascript ```Javascript const numTrees =(n) => { let dp = new Array(n+1).fill(0); @@ -227,7 +227,34 @@ const numTrees =(n) => { }; ``` +C: +```c +//开辟dp数组 +int *initDP(int n) { + int *dp = (int *)malloc(sizeof(int) * (n + 1)); + int i; + for(i = 0; i <= n; ++i) + dp[i] = 0; + return dp; +} +int numTrees(int n){ + //开辟dp数组 + int *dp = initDP(n); + //将dp[0]设为1 + dp[0] = 1; + + int i, j; + for(i = 1; i <= n; ++i) { + for(j = 1; j <= i; ++j) { + //递推公式:dp[i] = dp[i] + 根为j时左子树种类个数 * 根为j时右子树种类个数 + dp[i] += dp[j - 1] * dp[i - j]; + } + } + + return dp[n]; +} +``` -----------------------  +```CPP
+//版本二:
+//原理同版本1,更简洁实现。
+class Solution {
+public:
+ void reverse(string& s, int start, int end){ //翻转,区间写法:闭区间 []
+ for (int i = start, j = end; i < j; i++, j--) {
+ swap(s[i], s[j]);
+ }
+ }
+ void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
+ int slow = 0; //整体思想参考Leetcode: 27. 移除元素:https://leetcode-cn.com/problems/remove-element/
+ for (int i = 0; i < s.size(); ++i) { //
+ if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
+ if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
+ while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
+ s[slow++] = s[i++];
+ }
+ }
+ }
+ s.resize(slow); //slow的大小即为去除多余空格后的大小。
+ }
+
+ string reverseWords(string s) {
+ removeExtraSpaces(s); //去除多余空格,保证单词之间之只有一个空格,且字符串首尾没空格。
+ reverse(s, 0, s.size() - 1);
+ int start = 0; //removeExtraSpaces后保证第一个单词的开始下标一定是0。
+ for (int i = 0; i <= s.size(); ++i) {
+ if (i == s.size() || s[i] == ' ') { //到达空格或者串尾,说明一个单词结束。进行翻转。
+ reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
+ start = i + 1; //更新下一个单词的开始下标start
+ }
+ }
+ return s;
+ }
+};
+```
## 其他语言版本
@@ -438,6 +475,38 @@ class Solution:
```
+```python
+class Solution:
+ def reverseWords(self, s: str) -> str:
+ # method 1 - Rude but work & efficient method.
+ s_list = [i for i in s.split(" ") if len(i) > 0]
+ return " ".join(s_list[::-1])
+
+ # method 2 - Carlo's idea
+ def trim_head_tail_space(ss: str):
+ p = 0
+ while p < len(ss) and ss[p] == " ":
+ p += 1
+ return ss[p:]
+
+ # Trim the head and tail space
+ s = trim_head_tail_space(s)
+ s = trim_head_tail_space(s[::-1])[::-1]
+
+ pf, ps, s = 0, 0, s[::-1] # Reverse the string.
+ while pf < len(s):
+ if s[pf] == " ":
+ # Will not excede. Because we have clean the tail space.
+ if s[pf] == s[pf + 1]:
+ s = s[:pf] + s[pf + 1:]
+ continue
+ else:
+ s = s[:ps] + s[ps: pf][::-1] + s[pf:]
+ ps, pf = pf + 1, pf + 2
+ else:
+ pf += 1
+ return s[:ps] + s[ps:][::-1] # Must do the last step, because the last word is omit though the pointers are on the correct positions,
+```
Go:
@@ -553,6 +622,65 @@ function reverse(strArr, start, end) {
}
```
+TypeScript:
+
+```typescript
+function reverseWords(s: string): string {
+ /** Utils **/
+ // 删除多余空格, 如' hello world ' => 'hello world'
+ function delExtraSpace(arr: string[]): void {
+ let left: number = 0,
+ right: number = 0,
+ length: number = arr.length;
+ while (right < length && arr[right] === ' ') {
+ right++;
+ }
+ while (right < length) {
+ if (arr[right] === ' ' && arr[right - 1] === ' ') {
+ right++;
+ continue;
+ }
+ arr[left++] = arr[right++];
+ }
+ if (arr[left - 1] === ' ') {
+ arr.length = left - 1;
+ } else {
+ arr.length = left;
+ }
+ }
+ // 翻转字符串,如:'hello' => 'olleh'
+ function reverseWords(strArr: string[], start: number, end: number) {
+ let temp: string;
+ while (start < end) {
+ temp = strArr[start];
+ strArr[start] = strArr[end];
+ strArr[end] = temp;
+ start++;
+ end--;
+ }
+ }
+
+ /** Main code **/
+ let strArr: string[] = s.split('');
+ delExtraSpace(strArr);
+ let length: number = strArr.length;
+ // 翻转整个字符串
+ reverseWords(strArr, 0, length - 1);
+ let start: number = 0,
+ end: number = 0;
+ while (start < length) {
+ end = start;
+ while (strArr[end] !== ' ' && end < length) {
+ end++;
+ }
+ // 翻转单个单词
+ reverseWords(strArr, start, end - 1);
+ start = end + 1;
+ }
+ return strArr.join('');
+};
+```
+
Swift:
```swift
diff --git a/problems/0188.买卖股票的最佳时机IV.md b/problems/0188.买卖股票的最佳时机IV.md
index 7db75f06..61c558a1 100644
--- a/problems/0188.买卖股票的最佳时机IV.md
+++ b/problems/0188.买卖股票的最佳时机IV.md
@@ -271,7 +271,7 @@ class Solution:
return dp[-1][2*k]
```
版本二
-```python3
+```python
class Solution:
def maxProfit(self, k: int, prices: List[int]) -> int:
if len(prices) == 0: return 0
diff --git a/problems/0189.旋转数组.md b/problems/0189.旋转数组.md
index bbe152a2..3ffed877 100644
--- a/problems/0189.旋转数组.md
+++ b/problems/0189.旋转数组.md
@@ -12,7 +12,7 @@
进阶:
尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
-你可以使用空间复杂度为 $O(1)$ 的 原地 算法解决这个问题吗?
+你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
示例 1:
@@ -41,7 +41,7 @@
本题其实和[字符串:剑指Offer58-II.左旋转字符串](https://programmercarl.com/剑指Offer58-II.左旋转字符串.html)就非常像了,剑指offer上左旋转,本题是右旋转。
-注意题目要求是**要求使用空间复杂度为 $O(1)$ 的 原地 算法**
+注意题目要求是**要求使用空间复杂度为 O(1) 的 原地 算法**
那么我来提供一种旋转的方式哈。
@@ -124,6 +124,19 @@ class Solution:
## Go
```go
+func rotate(nums []int, k int) {
+ l:=len(nums)
+ index:=l-k%l
+ reverse(nums)
+ reverse(nums[:l-index])
+ reverse(nums[l-index:])
+}
+func reverse(nums []int){
+ l:=len(nums)
+ for i:=0;i
+```CPP
+//版本二:
+//原理同版本1,更简洁实现。
+class Solution {
+public:
+ void reverse(string& s, int start, int end){ //翻转,区间写法:闭区间 []
+ for (int i = start, j = end; i < j; i++, j--) {
+ swap(s[i], s[j]);
+ }
+ }
+ void removeExtraSpaces(string& s) {//去除所有空格并在相邻单词之间添加空格, 快慢指针。
+ int slow = 0; //整体思想参考Leetcode: 27. 移除元素:https://leetcode-cn.com/problems/remove-element/
+ for (int i = 0; i < s.size(); ++i) { //
+ if (s[i] != ' ') { //遇到非空格就处理,即删除所有空格。
+ if (slow != 0) s[slow++] = ' '; //手动控制空格,给单词之间添加空格。slow != 0说明不是第一个单词,需要在单词前添加空格。
+ while (i < s.size() && s[i] != ' ') { //补上该单词,遇到空格说明单词结束。
+ s[slow++] = s[i++];
+ }
+ }
+ }
+ s.resize(slow); //slow的大小即为去除多余空格后的大小。
+ }
+
+ string reverseWords(string s) {
+ removeExtraSpaces(s); //去除多余空格,保证单词之间之只有一个空格,且字符串首尾没空格。
+ reverse(s, 0, s.size() - 1);
+ int start = 0; //removeExtraSpaces后保证第一个单词的开始下标一定是0。
+ for (int i = 0; i <= s.size(); ++i) {
+ if (i == s.size() || s[i] == ' ') { //到达空格或者串尾,说明一个单词结束。进行翻转。
+ reverse(s, start, i - 1); //翻转,注意是左闭右闭 []的翻转。
+ start = i + 1; //更新下一个单词的开始下标start
+ }
+ }
+ return s;
+ }
+};
+```
## 其他语言版本
@@ -438,6 +475,38 @@ class Solution:
```
+```python
+class Solution:
+ def reverseWords(self, s: str) -> str:
+ # method 1 - Rude but work & efficient method.
+ s_list = [i for i in s.split(" ") if len(i) > 0]
+ return " ".join(s_list[::-1])
+
+ # method 2 - Carlo's idea
+ def trim_head_tail_space(ss: str):
+ p = 0
+ while p < len(ss) and ss[p] == " ":
+ p += 1
+ return ss[p:]
+
+ # Trim the head and tail space
+ s = trim_head_tail_space(s)
+ s = trim_head_tail_space(s[::-1])[::-1]
+
+ pf, ps, s = 0, 0, s[::-1] # Reverse the string.
+ while pf < len(s):
+ if s[pf] == " ":
+ # Will not excede. Because we have clean the tail space.
+ if s[pf] == s[pf + 1]:
+ s = s[:pf] + s[pf + 1:]
+ continue
+ else:
+ s = s[:ps] + s[ps: pf][::-1] + s[pf:]
+ ps, pf = pf + 1, pf + 2
+ else:
+ pf += 1
+ return s[:ps] + s[ps:][::-1] # Must do the last step, because the last word is omit though the pointers are on the correct positions,
+```
Go:
@@ -553,6 +622,65 @@ function reverse(strArr, start, end) {
}
```
+TypeScript:
+
+```typescript
+function reverseWords(s: string): string {
+ /** Utils **/
+ // 删除多余空格, 如' hello world ' => 'hello world'
+ function delExtraSpace(arr: string[]): void {
+ let left: number = 0,
+ right: number = 0,
+ length: number = arr.length;
+ while (right < length && arr[right] === ' ') {
+ right++;
+ }
+ while (right < length) {
+ if (arr[right] === ' ' && arr[right - 1] === ' ') {
+ right++;
+ continue;
+ }
+ arr[left++] = arr[right++];
+ }
+ if (arr[left - 1] === ' ') {
+ arr.length = left - 1;
+ } else {
+ arr.length = left;
+ }
+ }
+ // 翻转字符串,如:'hello' => 'olleh'
+ function reverseWords(strArr: string[], start: number, end: number) {
+ let temp: string;
+ while (start < end) {
+ temp = strArr[start];
+ strArr[start] = strArr[end];
+ strArr[end] = temp;
+ start++;
+ end--;
+ }
+ }
+
+ /** Main code **/
+ let strArr: string[] = s.split('');
+ delExtraSpace(strArr);
+ let length: number = strArr.length;
+ // 翻转整个字符串
+ reverseWords(strArr, 0, length - 1);
+ let start: number = 0,
+ end: number = 0;
+ while (start < length) {
+ end = start;
+ while (strArr[end] !== ' ' && end < length) {
+ end++;
+ }
+ // 翻转单个单词
+ reverseWords(strArr, start, end - 1);
+ start = end + 1;
+ }
+ return strArr.join('');
+};
+```
+
Swift:
```swift
diff --git a/problems/0188.买卖股票的最佳时机IV.md b/problems/0188.买卖股票的最佳时机IV.md
index 7db75f06..61c558a1 100644
--- a/problems/0188.买卖股票的最佳时机IV.md
+++ b/problems/0188.买卖股票的最佳时机IV.md
@@ -271,7 +271,7 @@ class Solution:
return dp[-1][2*k]
```
版本二
-```python3
+```python
class Solution:
def maxProfit(self, k: int, prices: List[int]) -> int:
if len(prices) == 0: return 0
diff --git a/problems/0189.旋转数组.md b/problems/0189.旋转数组.md
index bbe152a2..3ffed877 100644
--- a/problems/0189.旋转数组.md
+++ b/problems/0189.旋转数组.md
@@ -12,7 +12,7 @@
进阶:
尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。
-你可以使用空间复杂度为 $O(1)$ 的 原地 算法解决这个问题吗?
+你可以使用空间复杂度为 O(1) 的 原地 算法解决这个问题吗?
示例 1:
@@ -41,7 +41,7 @@
本题其实和[字符串:剑指Offer58-II.左旋转字符串](https://programmercarl.com/剑指Offer58-II.左旋转字符串.html)就非常像了,剑指offer上左旋转,本题是右旋转。
-注意题目要求是**要求使用空间复杂度为 $O(1)$ 的 原地 算法**
+注意题目要求是**要求使用空间复杂度为 O(1) 的 原地 算法**
那么我来提供一种旋转的方式哈。
@@ -124,6 +124,19 @@ class Solution:
## Go
```go
+func rotate(nums []int, k int) {
+ l:=len(nums)
+ index:=l-k%l
+ reverse(nums)
+ reverse(nums[:l-index])
+ reverse(nums[l-index:])
+}
+func reverse(nums []int){
+ l:=len(nums)
+ for i:=0;i 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-## 343. 整数拆分 +# 343. 整数拆分 [力扣题目链接](https://leetcode-cn.com/problems/integer-break/) 给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。 示例 1: -输入: 2 -输出: 1 - -\解释: 2 = 1 + 1, 1 × 1 = 1。 +* 输入: 2 +* 输出: 1 +* 解释: 2 = 1 + 1, 1 × 1 = 1。 示例 2: -输入: 10 -输出: 36 -解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。 -说明: 你可以假设 n 不小于 2 且不大于 58。 +* 输入: 10 +* 输出: 36 +* 解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。 +* 说明: 你可以假设 n 不小于 2 且不大于 58。 ## 思路 @@ -120,8 +119,8 @@ public: }; ``` -* 时间复杂度:$O(n^2)$ -* 空间复杂度:$O(n)$ +* 时间复杂度:O(n^2) +* 空间复杂度:O(n) ### 贪心 @@ -149,8 +148,8 @@ public: }; ``` -* 时间复杂度:$O(n)$ -* 空间复杂度:$O(1)$ +* 时间复杂度:O(n) +* 空间复杂度:O(1) ## 总结 @@ -193,18 +192,21 @@ public: ## 其他语言版本 -Java: +### Java ```Java class Solution { public int integerBreak(int n) { - //dp[i]为正整数i拆分结果的最大乘积 - int[] dp = new int[n+1]; - dp[2] = 1; - for (int i = 3; i <= n; ++i) { - for (int j = 1; j < i - 1; ++j) { - //j*(i-j)代表把i拆分为j和i-j两个数相乘 - //j*dp[i-j]代表把i拆分成j和继续把(i-j)这个数拆分,取(i-j)拆分结果中的最大乘积与j相乘 - dp[i] = Math.max(dp[i], Math.max(j * (i - j), j * dp[i - j])); + //dp[i] 为正整数 i 拆分后的结果的最大乘积 + int[]dp=new int[n+1]; + dp[2]=1; + for(int i=3;i<=n;i++){ + for(int j=1;j<=i-j;j++){ + // 这里的 j 其实最大值为 i-j,再大只不过是重复而已, + //并且,在本题中,我们分析 dp[0], dp[1]都是无意义的, + //j 最大到 i-j,就不会用到 dp[0]与dp[1] + dp[i]=Math.max(dp[i],Math.max(j*(i-j),j*dp[i-j])); + // j * (i - j) 是单纯的把整数 i 拆分为两个数 也就是 i,i-j ,再相乘 + //而j * dp[i - j]是将 i 拆分成两个以及两个以上的个数,再相乘。 } } return dp[n]; @@ -212,7 +214,7 @@ class Solution { } ``` -Python: +### Python ```python class Solution: def integerBreak(self, n: int) -> int: @@ -226,7 +228,8 @@ class Solution: dp[i] = max(dp[i], max(j * (i - j), j * dp[i - j])) return dp[n] ``` -Go: + +### Go ```golang func integerBreak(n int) int { /** @@ -256,7 +259,7 @@ func max(a,b int) int{ } ``` -Javascript: +### Javascript ```Javascript var integerBreak = function(n) { let dp = new Array(n + 1).fill(0) @@ -271,5 +274,40 @@ var integerBreak = function(n) { }; ``` +C: +```c +//初始化DP数组 +int *initDP(int num) { + int* dp = (int*)malloc(sizeof(int) * (num + 1)); + int i; + for(i = 0; i < num + 1; ++i) { + dp[i] = 0; + } + return dp; +} + +//取三数最大值 +int max(int num1, int num2, int num3) { + int tempMax = num1 > num2 ? num1 : num2; + return tempMax > num3 ? tempMax : num3; +} + +int integerBreak(int n){ + int *dp = initDP(n); + //初始化dp[2]为1 + dp[2] = 1; + + int i; + for(i = 3; i <= n; ++i) { + int j; + for(j = 1; j < i - 1; ++j) { + //取得上次循环:dp[i],原数相乘,或j*dp[]i-j] 三数中的最大值 + dp[i] = max(dp[i], j * (i - j), j * dp[i - j]); + } + } + return dp[n]; +} +``` + -----------------------
- * 入站元素要和当前栈内栈首元素进行比较
- * 若大于栈首则 则与元素下标做差
- * 若大于等于则放入
- *
- * @param temperatures
- * @return
- */
- public static int[] dailyTemperatures(int[] temperatures) {
- Stack 参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益! 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益! 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
- 欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
+
+
-
+
-
+
-
+
-
+
-
+
-
+
-
+
参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益! diff --git a/problems/二叉树总结篇.md b/problems/二叉树总结篇.md
index d1332e09..73faffa6 100644
--- a/problems/二叉树总结篇.md
+++ b/problems/二叉树总结篇.md
@@ -152,7 +152,7 @@
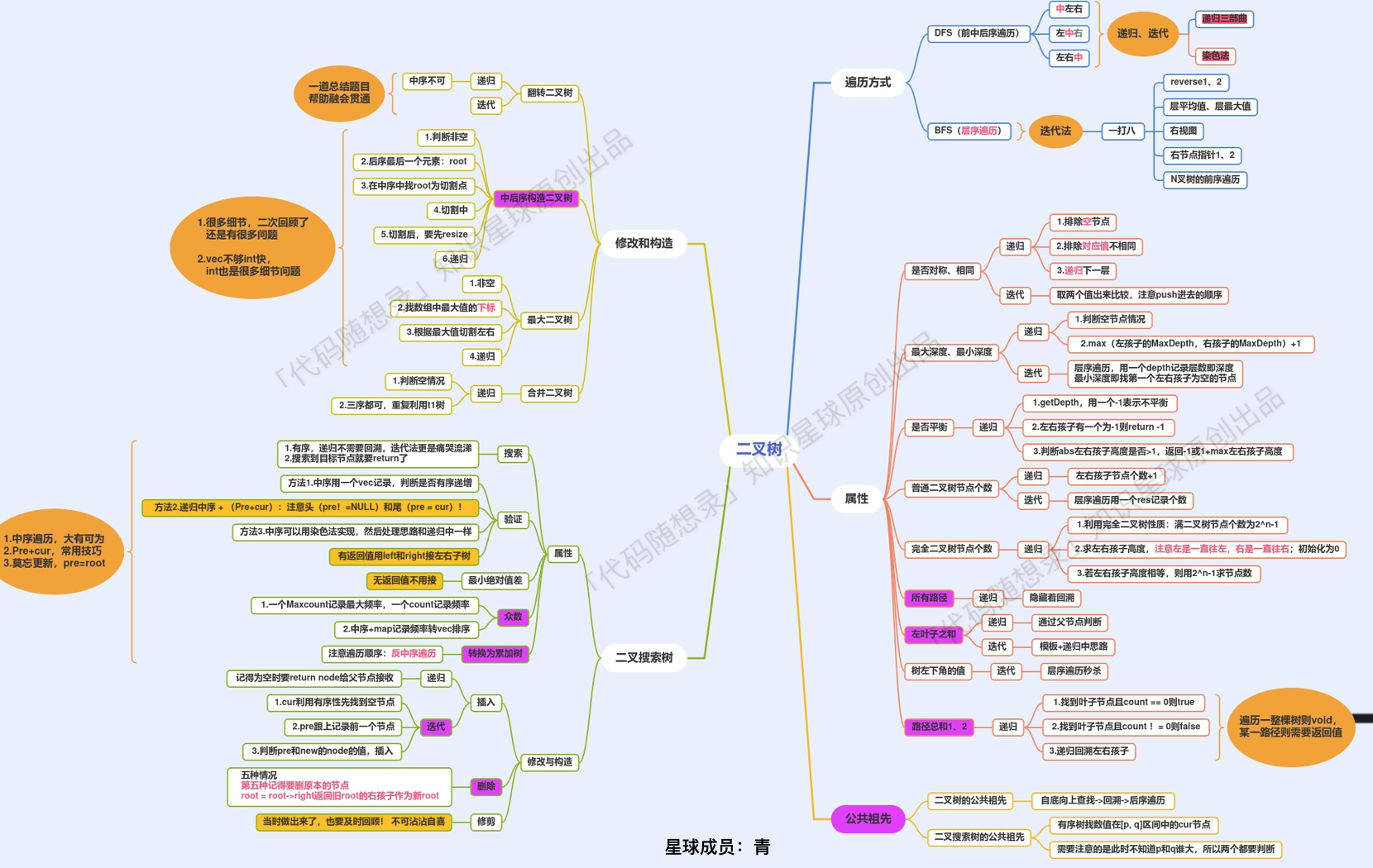
-这个图是 [代码随想录知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 成员:[青](https://wx.zsxq.com/dweb2/index/footprint/185251215558842),所画,总结的非常好,分享给大家。
+这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[青](https://wx.zsxq.com/dweb2/index/footprint/185251215558842),所画,总结的非常好,分享给大家。
**最后,二叉树系列就这么完美结束了,估计这应该是最长的系列了,感谢大家33天的坚持与陪伴,接下来我们又要开始新的系列了「回溯算法」!**
diff --git a/problems/二叉树理论基础.md b/problems/二叉树理论基础.md
index cc899850..9c151e32 100644
--- a/problems/二叉树理论基础.md
+++ b/problems/二叉树理论基础.md
@@ -33,7 +33,7 @@
什么是完全二叉树?
-完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^h -1 个节点。
+完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
**大家要自己看完全二叉树的定义,很多同学对完全二叉树其实不是真正的懂了。**
@@ -154,7 +154,7 @@
C++代码如下:
-```
+```cpp
struct TreeNode {
int val;
TreeNode *left;
@@ -163,7 +163,7 @@ struct TreeNode {
};
```
-大家会发现二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右孩子.
+大家会发现二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右孩子。
这里要提醒大家要注意二叉树节点定义的书写方式。
@@ -177,7 +177,7 @@ struct TreeNode {
本篇我们介绍了二叉树的种类、存储方式、遍历方式以及定义,比较全面的介绍了二叉树各个方面的重点,帮助大家扫一遍基础。
-**说道二叉树,就不得不说递归,很多同学对递归都是又熟悉又陌生,递归的代码一般很简短,但每次都是一看就会,一写就废。**
+**说到二叉树,就不得不说递归,很多同学对递归都是又熟悉又陌生,递归的代码一般很简短,但每次都是一看就会,一写就废。**
## 其他语言版本
@@ -227,7 +227,23 @@ function TreeNode(val, left, right) {
}
```
+TypeScript:
+
+```typescript
+class TreeNode {
+ public val: number;
+ public left: TreeNode | null;
+ public right: TreeNode | null;
+ constructor(val?: number, left?: TreeNode, right?: TreeNode) {
+ this.val = val === undefined ? 0 : val;
+ this.left = left === undefined ? null : left;
+ this.right = right === undefined ? null : right;
+ }
+}
+```
+
Swift:
+
```Swift
class TreeNode
diff --git a/problems/二叉树的迭代遍历.md b/problems/二叉树的迭代遍历.md
index 4cb94cb5..8164724b 100644
--- a/problems/二叉树的迭代遍历.md
+++ b/problems/二叉树的迭代遍历.md
@@ -390,7 +390,7 @@ func inorderTraversal(root *TreeNode) []int {
}
```
-javaScript
+javaScript:
```js
@@ -454,77 +454,118 @@ var postorderTraversal = function(root, res = []) {
};
```
-Swift:
+TypeScript:
-> 迭代法前序遍历
-```swift
-func preorderTraversal(_ root: TreeNode?) -> [Int] {
- var res = [Int]()
- if root == nil {
- return res
+```typescript
+// 前序遍历(迭代法)
+function preorderTraversal(root: TreeNode | null): number[] {
+ if (root === null) return [];
+ let res: number[] = [];
+ let helperStack: TreeNode[] = [];
+ let curNode: TreeNode = root;
+ helperStack.push(curNode);
+ while (helperStack.length > 0) {
+ curNode = helperStack.pop()!;
+ res.push(curNode.val);
+ if (curNode.right !== null) helperStack.push(curNode.right);
+ if (curNode.left !== null) helperStack.push(curNode.left);
}
- var stack = [TreeNode]()
- stack.append(root!)
- while !stack.isEmpty {
- let node = stack.popLast()!
- res.append(node.val)
- if node.right != nil {
- stack.append(node.right!)
- }
- if node.left != nil {
- stack.append(node.left!)
- }
- }
- return res
-}
-```
+ return res;
+};
-> 迭代法中序遍历
-```swift
-func inorderTraversal(_ root: TreeNode?) -> [Int] {
- var res = [Int]()
- if root == nil {
- return res
- }
- var stack = [TreeNode]()
- var cur: TreeNode? = root
- while cur != nil || !stack.isEmpty {
- if cur != nil {
- stack.append(cur!)
- cur = cur!.left
+// 中序遍历(迭代法)
+function inorderTraversal(root: TreeNode | null): number[] {
+ let helperStack: TreeNode[] = [];
+ let res: number[] = [];
+ if (root === null) return res;
+ let curNode: TreeNode | null = root;
+ while (curNode !== null || helperStack.length > 0) {
+ if (curNode !== null) {
+ helperStack.push(curNode);
+ curNode = curNode.left;
} else {
- cur = stack.popLast()
- res.append(cur!.val)
- cur = cur!.right
+ curNode = helperStack.pop()!;
+ res.push(curNode.val);
+ curNode = curNode.right;
}
}
- return res
-}
+ return res;
+};
+
+// 后序遍历(迭代法)
+function postorderTraversal(root: TreeNode | null): number[] {
+ let helperStack: TreeNode[] = [];
+ let res: number[] = [];
+ let curNode: TreeNode;
+ if (root === null) return res;
+ helperStack.push(root);
+ while (helperStack.length > 0) {
+ curNode = helperStack.pop()!;
+ res.push(curNode.val);
+ if (curNode.left !== null) helperStack.push(curNode.left);
+ if (curNode.right !== null) helperStack.push(curNode.right);
+ }
+ return res.reverse();
+};
```
-> 迭代法后序遍历
+Swift:
+
```swift
-func postorderTraversal(_ root: TreeNode?) -> [Int] {
- var res = [Int]()
- if root == nil {
- return res
- }
- var stack = [TreeNode]()
- stack.append(root!)
- // res 存储 中 -> 右 -> 左
+// 前序遍历迭代法
+func preorderTraversal(_ root: TreeNode?) -> [Int] {
+ var result = [Int]()
+ guard let root = root else { return result }
+ var stack = [root]
while !stack.isEmpty {
- let node = stack.popLast()!
- res.append(node.val)
- if node.left != nil {
- stack.append(node.left!)
+ let current = stack.removeLast()
+ // 先右后左,这样出栈的时候才是左右顺序
+ if let node = current.right { // 右
+ stack.append(node)
}
- if node.right != nil {
- stack.append(node.right!)
+ if let node = current.left { // 左
+ stack.append(node)
+ }
+ result.append(current.val) // 中
+ }
+ return result
+}
+
+// 后序遍历迭代法
+func postorderTraversal(_ root: TreeNode?) -> [Int] {
+ var result = [Int]()
+ guard let root = root else { return result }
+ var stack = [root]
+ while !stack.isEmpty {
+ let current = stack.removeLast()
+ // 与前序相反,即中右左,最后结果还需反转才是后序
+ if let node = current.left { // 左
+ stack.append(node)
+ }
+ if let node = current.right { // 右
+ stack.append(node)
+ }
+ result.append(current.val) // 中
+ }
+ return result.reversed()
+}
+
+// 中序遍历迭代法
+func inorderTraversal(_ root: TreeNode?) -> [Int] {
+ var result = [Int]()
+ var stack = [TreeNode]()
+ var current: TreeNode! = root
+ while current != nil || !stack.isEmpty {
+ if current != nil { // 先访问到最左叶子
+ stack.append(current)
+ current = current.left // 左
+ } else {
+ current = stack.removeLast()
+ result.append(current.val) // 中
+ current = current.right // 右
}
}
- // res 翻转
- res.reverse()
- return res
+ return result
}
```
diff --git a/problems/二叉树的递归遍历.md b/problems/二叉树的递归遍历.md
index 45b576e7..35d19d7b 100644
--- a/problems/二叉树的递归遍历.md
+++ b/problems/二叉树的递归遍历.md
@@ -34,19 +34,19 @@
1. **确定递归函数的参数和返回值**:因为要打印出前序遍历节点的数值,所以参数里需要传入vector在放节点的数值,除了这一点就不需要在处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
-```
+```cpp
void traversal(TreeNode* cur, vector
diff --git a/problems/二叉树总结篇.md b/problems/二叉树总结篇.md
index d1332e09..73faffa6 100644
--- a/problems/二叉树总结篇.md
+++ b/problems/二叉树总结篇.md
@@ -152,7 +152,7 @@

-这个图是 [代码随想录知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 成员:[青](https://wx.zsxq.com/dweb2/index/footprint/185251215558842),所画,总结的非常好,分享给大家。
+这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[青](https://wx.zsxq.com/dweb2/index/footprint/185251215558842),所画,总结的非常好,分享给大家。
**最后,二叉树系列就这么完美结束了,估计这应该是最长的系列了,感谢大家33天的坚持与陪伴,接下来我们又要开始新的系列了「回溯算法」!**
diff --git a/problems/二叉树理论基础.md b/problems/二叉树理论基础.md
index cc899850..9c151e32 100644
--- a/problems/二叉树理论基础.md
+++ b/problems/二叉树理论基础.md
@@ -33,7 +33,7 @@
什么是完全二叉树?
-完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^h -1 个节点。
+完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
**大家要自己看完全二叉树的定义,很多同学对完全二叉树其实不是真正的懂了。**
@@ -154,7 +154,7 @@
C++代码如下:
-```
+```cpp
struct TreeNode {
int val;
TreeNode *left;
@@ -163,7 +163,7 @@ struct TreeNode {
};
```
-大家会发现二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右孩子.
+大家会发现二叉树的定义 和链表是差不多的,相对于链表 ,二叉树的节点里多了一个指针, 有两个指针,指向左右孩子。
这里要提醒大家要注意二叉树节点定义的书写方式。
@@ -177,7 +177,7 @@ struct TreeNode {
本篇我们介绍了二叉树的种类、存储方式、遍历方式以及定义,比较全面的介绍了二叉树各个方面的重点,帮助大家扫一遍基础。
-**说道二叉树,就不得不说递归,很多同学对递归都是又熟悉又陌生,递归的代码一般很简短,但每次都是一看就会,一写就废。**
+**说到二叉树,就不得不说递归,很多同学对递归都是又熟悉又陌生,递归的代码一般很简短,但每次都是一看就会,一写就废。**
## 其他语言版本
@@ -227,7 +227,23 @@ function TreeNode(val, left, right) {
}
```
+TypeScript:
+
+```typescript
+class TreeNode {
+ public val: number;
+ public left: TreeNode | null;
+ public right: TreeNode | null;
+ constructor(val?: number, left?: TreeNode, right?: TreeNode) {
+ this.val = val === undefined ? 0 : val;
+ this.left = left === undefined ? null : left;
+ this.right = right === undefined ? null : right;
+ }
+}
+```
+
Swift:
+
```Swift
class TreeNode
diff --git a/problems/二叉树的迭代遍历.md b/problems/二叉树的迭代遍历.md
index 4cb94cb5..8164724b 100644
--- a/problems/二叉树的迭代遍历.md
+++ b/problems/二叉树的迭代遍历.md
@@ -390,7 +390,7 @@ func inorderTraversal(root *TreeNode) []int {
}
```
-javaScript
+javaScript:
```js
@@ -454,77 +454,118 @@ var postorderTraversal = function(root, res = []) {
};
```
-Swift:
+TypeScript:
-> 迭代法前序遍历
-```swift
-func preorderTraversal(_ root: TreeNode?) -> [Int] {
- var res = [Int]()
- if root == nil {
- return res
+```typescript
+// 前序遍历(迭代法)
+function preorderTraversal(root: TreeNode | null): number[] {
+ if (root === null) return [];
+ let res: number[] = [];
+ let helperStack: TreeNode[] = [];
+ let curNode: TreeNode = root;
+ helperStack.push(curNode);
+ while (helperStack.length > 0) {
+ curNode = helperStack.pop()!;
+ res.push(curNode.val);
+ if (curNode.right !== null) helperStack.push(curNode.right);
+ if (curNode.left !== null) helperStack.push(curNode.left);
}
- var stack = [TreeNode]()
- stack.append(root!)
- while !stack.isEmpty {
- let node = stack.popLast()!
- res.append(node.val)
- if node.right != nil {
- stack.append(node.right!)
- }
- if node.left != nil {
- stack.append(node.left!)
- }
- }
- return res
-}
-```
+ return res;
+};
-> 迭代法中序遍历
-```swift
-func inorderTraversal(_ root: TreeNode?) -> [Int] {
- var res = [Int]()
- if root == nil {
- return res
- }
- var stack = [TreeNode]()
- var cur: TreeNode? = root
- while cur != nil || !stack.isEmpty {
- if cur != nil {
- stack.append(cur!)
- cur = cur!.left
+// 中序遍历(迭代法)
+function inorderTraversal(root: TreeNode | null): number[] {
+ let helperStack: TreeNode[] = [];
+ let res: number[] = [];
+ if (root === null) return res;
+ let curNode: TreeNode | null = root;
+ while (curNode !== null || helperStack.length > 0) {
+ if (curNode !== null) {
+ helperStack.push(curNode);
+ curNode = curNode.left;
} else {
- cur = stack.popLast()
- res.append(cur!.val)
- cur = cur!.right
+ curNode = helperStack.pop()!;
+ res.push(curNode.val);
+ curNode = curNode.right;
}
}
- return res
-}
+ return res;
+};
+
+// 后序遍历(迭代法)
+function postorderTraversal(root: TreeNode | null): number[] {
+ let helperStack: TreeNode[] = [];
+ let res: number[] = [];
+ let curNode: TreeNode;
+ if (root === null) return res;
+ helperStack.push(root);
+ while (helperStack.length > 0) {
+ curNode = helperStack.pop()!;
+ res.push(curNode.val);
+ if (curNode.left !== null) helperStack.push(curNode.left);
+ if (curNode.right !== null) helperStack.push(curNode.right);
+ }
+ return res.reverse();
+};
```
-> 迭代法后序遍历
+Swift:
+
```swift
-func postorderTraversal(_ root: TreeNode?) -> [Int] {
- var res = [Int]()
- if root == nil {
- return res
- }
- var stack = [TreeNode]()
- stack.append(root!)
- // res 存储 中 -> 右 -> 左
+// 前序遍历迭代法
+func preorderTraversal(_ root: TreeNode?) -> [Int] {
+ var result = [Int]()
+ guard let root = root else { return result }
+ var stack = [root]
while !stack.isEmpty {
- let node = stack.popLast()!
- res.append(node.val)
- if node.left != nil {
- stack.append(node.left!)
+ let current = stack.removeLast()
+ // 先右后左,这样出栈的时候才是左右顺序
+ if let node = current.right { // 右
+ stack.append(node)
}
- if node.right != nil {
- stack.append(node.right!)
+ if let node = current.left { // 左
+ stack.append(node)
+ }
+ result.append(current.val) // 中
+ }
+ return result
+}
+
+// 后序遍历迭代法
+func postorderTraversal(_ root: TreeNode?) -> [Int] {
+ var result = [Int]()
+ guard let root = root else { return result }
+ var stack = [root]
+ while !stack.isEmpty {
+ let current = stack.removeLast()
+ // 与前序相反,即中右左,最后结果还需反转才是后序
+ if let node = current.left { // 左
+ stack.append(node)
+ }
+ if let node = current.right { // 右
+ stack.append(node)
+ }
+ result.append(current.val) // 中
+ }
+ return result.reversed()
+}
+
+// 中序遍历迭代法
+func inorderTraversal(_ root: TreeNode?) -> [Int] {
+ var result = [Int]()
+ var stack = [TreeNode]()
+ var current: TreeNode! = root
+ while current != nil || !stack.isEmpty {
+ if current != nil { // 先访问到最左叶子
+ stack.append(current)
+ current = current.left // 左
+ } else {
+ current = stack.removeLast()
+ result.append(current.val) // 中
+ current = current.right // 右
}
}
- // res 翻转
- res.reverse()
- return res
+ return result
}
```
diff --git a/problems/二叉树的递归遍历.md b/problems/二叉树的递归遍历.md
index 45b576e7..35d19d7b 100644
--- a/problems/二叉树的递归遍历.md
+++ b/problems/二叉树的递归遍历.md
@@ -34,19 +34,19 @@
1. **确定递归函数的参数和返回值**:因为要打印出前序遍历节点的数值,所以参数里需要传入vector在放节点的数值,除了这一点就不需要在处理什么数据了也不需要有返回值,所以递归函数返回类型就是void,代码如下:
-```
+```cpp
void traversal(TreeNode* cur, vector
-
-
-
-
diff --git a/problems/前序/BAT级别技术面试流程和注意事项都在这里了.md b/problems/前序/BAT级别技术面试流程和注意事项都在这里了.md
index c5797739..27940f1b 100644
--- a/problems/前序/BAT级别技术面试流程和注意事项都在这里了.md
+++ b/problems/前序/BAT级别技术面试流程和注意事项都在这里了.md
@@ -1,12 +1,5 @@
-
-
-
-
-
diff --git a/problems/前序/On的算法居然超时了,此时的n究竟是多大?.md b/problems/前序/On的算法居然超时了,此时的n究竟是多大?.md
index 9a56937c..20a48e19 100644
--- a/problems/前序/On的算法居然超时了,此时的n究竟是多大?.md
+++ b/problems/前序/On的算法居然超时了,此时的n究竟是多大?.md
@@ -1,18 +1,12 @@
-
-
-
-
-
diff --git a/problems/前序/上海互联网公司总结.md b/problems/前序/上海互联网公司总结.md
index 08c15895..6309ef58 100644
--- a/problems/前序/上海互联网公司总结.md
+++ b/problems/前序/上海互联网公司总结.md
@@ -1,11 +1,3 @@
-
-
-
-
-
diff --git a/problems/前序/什么是核心代码模式,什么又是ACM模式?.md b/problems/前序/什么是核心代码模式,什么又是ACM模式?.md
index 3c5fb4e4..0b9d230f 100644
--- a/problems/前序/什么是核心代码模式,什么又是ACM模式?.md
+++ b/problems/前序/什么是核心代码模式,什么又是ACM模式?.md
@@ -1,11 +1,5 @@
-
-
-
-
-
diff --git a/problems/前序/代码风格.md b/problems/前序/代码风格.md
index b48665e5..4ab94a51 100644
--- a/problems/前序/代码风格.md
+++ b/problems/前序/代码风格.md
@@ -1,13 +1,3 @@
-
-
-
-
-
diff --git a/problems/前序/关于时间复杂度,你不知道的都在这里!.md b/problems/前序/关于时间复杂度,你不知道的都在这里!.md
index cfcbed1a..f19984e6 100644
--- a/problems/前序/关于时间复杂度,你不知道的都在这里!.md
+++ b/problems/前序/关于时间复杂度,你不知道的都在这里!.md
@@ -1,11 +1,5 @@
-
-
-
-
-
diff --git a/problems/前序/关于空间复杂度,可能有几个疑问?.md b/problems/前序/关于空间复杂度,可能有几个疑问?.md
index 95ffe597..19384fd9 100644
--- a/problems/前序/关于空间复杂度,可能有几个疑问?.md
+++ b/problems/前序/关于空间复杂度,可能有几个疑问?.md
@@ -1,24 +1,16 @@
-
-
-
-
-
diff --git a/problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md b/problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md
index 3fccfb22..f4aa4b6e 100644
--- a/problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md
+++ b/problems/前序/刷了这么多题,你了解自己代码的内存消耗么?.md
@@ -1,13 +1,6 @@
-
-
-
-
-
diff --git a/problems/前序/力扣上的代码想在本地编译运行?.md b/problems/前序/力扣上的代码想在本地编译运行?.md
index c4899a20..bcef3886 100644
--- a/problems/前序/力扣上的代码想在本地编译运行?.md
+++ b/problems/前序/力扣上的代码想在本地编译运行?.md
@@ -1,10 +1,4 @@
-
-
-
-
-
diff --git a/problems/前序/北京互联网公司总结.md b/problems/前序/北京互联网公司总结.md
index 0e22dad6..a10cab06 100644
--- a/problems/前序/北京互联网公司总结.md
+++ b/problems/前序/北京互联网公司总结.md
@@ -1,15 +1,8 @@
-
-
-
-
-
diff --git a/problems/前序/广州互联网公司总结.md b/problems/前序/广州互联网公司总结.md
index ae41c899..b8b1641b 100644
--- a/problems/前序/广州互联网公司总结.md
+++ b/problems/前序/广州互联网公司总结.md
@@ -1,19 +1,14 @@
-
-
-
-
-
diff --git a/problems/前序/成都互联网公司总结.md b/problems/前序/成都互联网公司总结.md
index d44800cd..f6a575f6 100644
--- a/problems/前序/成都互联网公司总结.md
+++ b/problems/前序/成都互联网公司总结.md
@@ -1,15 +1,7 @@
-
-
-
-
-
diff --git a/problems/前序/杭州互联网公司总结.md b/problems/前序/杭州互联网公司总结.md
index 326a176b..6154cfe5 100644
--- a/problems/前序/杭州互联网公司总结.md
+++ b/problems/前序/杭州互联网公司总结.md
@@ -1,15 +1,8 @@
-
-
-
-
-
diff --git a/problems/前序/深圳互联网公司总结.md b/problems/前序/深圳互联网公司总结.md
index 9e089315..3d548abb 100644
--- a/problems/前序/深圳互联网公司总结.md
+++ b/problems/前序/深圳互联网公司总结.md
@@ -1,14 +1,8 @@
-
-
-
-
-
diff --git a/problems/前序/程序员写文档工具.md b/problems/前序/程序员写文档工具.md
index b76fb036..a2f6ee3b 100644
--- a/problems/前序/程序员写文档工具.md
+++ b/problems/前序/程序员写文档工具.md
@@ -1,16 +1,10 @@
-
-
-
-
-
diff --git a/problems/前序/程序员简历.md b/problems/前序/程序员简历.md
index f47516dc..e64f547a 100644
--- a/problems/前序/程序员简历.md
+++ b/problems/前序/程序员简历.md
@@ -1,16 +1,5 @@
-
-
-
-
-
diff --git a/problems/前序/编程素养部分的吹毛求疵.md b/problems/前序/编程素养部分的吹毛求疵.md
index 3f18f9d1..6099747a 100644
--- a/problems/前序/编程素养部分的吹毛求疵.md
+++ b/problems/前序/编程素养部分的吹毛求疵.md
@@ -13,7 +13,7 @@
- 左孩子和右孩子的下标不太好理解。我给出证明过程:
- 如果父节点在第$k$层,第$m,m \in [0,2^k]$个节点,则其左孩子所在的位置必然为$k+1$层,第$2*(m-1)+1$个节点。
+ 如果父节点在第k层,第$m,m \in [0,2^k]$个节点,则其左孩子所在的位置必然为$k+1$层,第$2*(m-1)+1$个节点。
- 计算父节点在数组中的索引:
$$
diff --git a/problems/前序/递归算法的时间与空间复杂度分析.md b/problems/前序/递归算法的时间与空间复杂度分析.md
index 4dd340a6..142358da 100644
--- a/problems/前序/递归算法的时间与空间复杂度分析.md
+++ b/problems/前序/递归算法的时间与空间复杂度分析.md
@@ -1,11 +1,3 @@
-
-
-
-
-
diff --git a/problems/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.md b/problems/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.md
index 8780122f..b2db92f5 100644
--- a/problems/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.md
+++ b/problems/前序/通过一道面试题目,讲一讲递归算法的时间复杂度!.md
@@ -1,13 +1,3 @@
-
-
-
-
-
diff --git a/problems/剑指Offer05.替换空格.md b/problems/剑指Offer05.替换空格.md
index d0f382c8..037bd427 100644
--- a/problems/剑指Offer05.替换空格.md
+++ b/problems/剑指Offer05.替换空格.md
@@ -29,7 +29,7 @@ i指向新长度的末尾,j指向旧长度的末尾。
有同学问了,为什么要从后向前填充,从前向后填充不行么?
-从前向后填充就是$O(n^2)$的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
+从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
**其实很多数组填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。**
@@ -74,8 +74,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
此时算上本题,我们已经做了七道双指针相关的题目了分别是:
@@ -121,6 +121,37 @@ for (int i = 0; i < a.size(); i++) {
## 其他语言版本
+C:
+```C
+char* replaceSpace(char* s){
+ //统计空格数量
+ int count = 0;
+ int len = strlen(s);
+ for (int i = 0; i < len; i++) {
+ if (s[i] == ' ') {
+ count++;
+ }
+ }
+
+ //为新数组分配空间
+ int newLen = len + count * 2;
+ char* result = malloc(sizeof(char) * newLen + 1);
+ //填充新数组并替换空格
+ for (int i = len - 1, j = newLen - 1; i >= 0; i--, j--) {
+ if (s[i] != ' ') {
+ result[j] = s[i];
+ } else {
+ result[j--] = '0';
+ result[j--] = '2';
+ result[j] = '%';
+ }
+ }
+ result[newLen] = '\0';
+
+ return result;
+}
+```
+
Java:
```Java
@@ -260,8 +291,24 @@ class Solution:
```
+```python
+class Solution:
+ def replaceSpace(self, s: str) -> str:
+ # method 1 - Very rude
+ return "%20".join(s.split(" "))
+
+ # method 2 - Reverse the s when counting in for loop, then update from the end.
+ n = len(s)
+ for e, i in enumerate(s[::-1]):
+ print(i, e)
+ if i == " ":
+ s = s[: n - (e + 1)] + "%20" + s[n - e:]
+ print("")
+ return s
+```
javaScript:
+
```js
/**
* @param {string} s
@@ -298,6 +345,33 @@ javaScript:
};
```
+TypeScript:
+
+```typescript
+function replaceSpace(s: string): string {
+ let arr: string[] = s.split('');
+ let spaceNum: number = 0;
+ let oldLength: number = arr.length;
+ for (let i = 0; i < oldLength; i++) {
+ if (arr[i] === ' ') {
+ spaceNum++;
+ }
+ }
+ arr.length = oldLength + 2 * spaceNum;
+ let cur: number = oldLength - 1;
+ for (let i = arr.length - 1; i >= 0; i--, cur--) {
+ if (arr[cur] !== ' ') {
+ arr[i] = arr[cur]
+ } else {
+ arr[i] = '0';
+ arr[--i] = '2';
+ arr[--i] = '%';
+ }
+ }
+ return arr.join('');
+};
+```
+
Swift:
```swift
diff --git a/problems/剑指Offer58-II.左旋转字符串.md b/problems/剑指Offer58-II.左旋转字符串.md
index c391d661..fec83e1d 100644
--- a/problems/剑指Offer58-II.左旋转字符串.md
+++ b/problems/剑指Offer58-II.左旋转字符串.md
@@ -86,7 +86,7 @@ public:
# 题外话
一些同学热衷于使用substr,来做这道题。
-其实使用substr 和 反转 时间复杂度是一样的 ,都是$O(n)$,但是使用substr申请了额外空间,所以空间复杂度是$O(n)$,而反转方法的空间复杂度是$O(1)$。
+其实使用substr 和 反转 时间复杂度是一样的 ,都是O(n),但是使用substr申请了额外空间,所以空间复杂度是O(n),而反转方法的空间复杂度是O(1)。
**如果想让这套题目有意义,就不要申请额外空间。**
@@ -209,6 +209,61 @@ var reverseLeftWords = function(s, n) {
};
```
+版本二(在原字符串上操作):
+
+```js
+/**
+ * @param {string} s
+ * @param {number} n
+ * @return {string}
+ */
+var reverseLeftWords = function (s, n) {
+ /** Utils */
+ function reverseWords(strArr, start, end) {
+ let temp;
+ while (start < end) {
+ temp = strArr[start];
+ strArr[start] = strArr[end];
+ strArr[end] = temp;
+ start++;
+ end--;
+ }
+ }
+ /** Main code */
+ let strArr = s.split('');
+ let length = strArr.length;
+ reverseWords(strArr, 0, length - 1);
+ reverseWords(strArr, 0, length - n - 1);
+ reverseWords(strArr, length - n, length - 1);
+ return strArr.join('');
+};
+```
+
+TypeScript:
+
+```typescript
+function reverseLeftWords(s: string, n: number): string {
+ /** Utils */
+ function reverseWords(strArr: string[], start: number, end: number): void {
+ let temp: string;
+ while (start < end) {
+ temp = strArr[start];
+ strArr[start] = strArr[end];
+ strArr[end] = temp;
+ start++;
+ end--;
+ }
+ }
+ /** Main code */
+ let strArr: string[] = s.split('');
+ let length: number = strArr.length;
+ reverseWords(strArr, 0, length - 1);
+ reverseWords(strArr, 0, length - n - 1);
+ reverseWords(strArr, length - n, length - 1);
+ return strArr.join('');
+};
+```
+
Swift:
```swift
diff --git a/problems/动态规划-股票问题总结篇.md b/problems/动态规划-股票问题总结篇.md
index e1fb477b..47a9b34b 100644
--- a/problems/动态规划-股票问题总结篇.md
+++ b/problems/动态规划-股票问题总结篇.md
@@ -72,8 +72,8 @@ public:
}
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
使用滚动数组,代码如下:
@@ -95,8 +95,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
## 买卖股票的最佳时机II
@@ -121,8 +121,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
【动态规划】
@@ -162,8 +162,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 买卖股票的最佳时机III
@@ -226,8 +226,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n × 5)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n × 5)
当然,大家可以看到力扣官方题解里的一种优化空间写法,我这里给出对应的C++版本:
@@ -251,8 +251,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
**这种写法看上去简单,其实思路很绕,不建议大家这么写,这么思考,很容易把自己绕进去!** 对于本题,把版本一的写法研究明白,足以!
@@ -404,8 +404,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 买卖股票的最佳时机含手续费
@@ -456,8 +456,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
## 总结
diff --git a/problems/动态规划总结篇.md b/problems/动态规划总结篇.md
index 699d4435..cc973b23 100644
--- a/problems/动态规划总结篇.md
+++ b/problems/动态规划总结篇.md
@@ -118,7 +118,7 @@

-这个图是 [代码随想录知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 成员:[青](https://wx.zsxq.com/dweb2/index/footprint/185251215558842),所画,总结的非常好,分享给大家。
+这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[青](https://wx.zsxq.com/dweb2/index/footprint/185251215558842),所画,总结的非常好,分享给大家。
这已经是全网对动规最深刻的讲解系列了。
diff --git a/problems/动态规划理论基础.md b/problems/动态规划理论基础.md
index e94295a5..66971fce 100644
--- a/problems/动态规划理论基础.md
+++ b/problems/动态规划理论基础.md
@@ -16,7 +16,7 @@
所以动态规划中每一个状态一定是由上一个状态推导出来的,**这一点就区分于贪心**,贪心没有状态推导,而是从局部直接选最优的,
-在[关于贪心算法,你该了解这些!](https://mp.weixin.qq.com/s/A9MHJi1a5uugFaqp8QJFWg)中我举了一个背包问题的例子。
+在[关于贪心算法,你该了解这些!](https://programmercarl.com/%E8%B4%AA%E5%BF%83%E7%AE%97%E6%B3%95%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80.html)中我举了一个背包问题的例子。
例如:有N件物品和一个最多能背重量为W 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。**每件物品只能用一次**,求解将哪些物品装入背包里物品价值总和最大。
diff --git a/problems/双指针总结.md b/problems/双指针总结.md
index e866aa66..06752cac 100644
--- a/problems/双指针总结.md
+++ b/problems/双指针总结.md
@@ -22,7 +22,7 @@ for (int i = 0; i < array.size(); i++) {
}
```
-这个代码看上去好像是$O(n)$的时间复杂度,其实是$O(n^2)$的时间复杂度,因为erase操作也是$O(n)$的操作。
+这个代码看上去好像是O(n)的时间复杂度,其实是O(n^2)的时间复杂度,因为erase操作也是O(n)的操作。
所以此时使用双指针法才展现出效率的优势:**通过两个指针在一个for循环下完成两个for循环的工作。**
@@ -30,7 +30,7 @@ for (int i = 0; i < array.size(); i++) {
在[字符串:这道题目,使用库函数一行代码搞定](https://programmercarl.com/0344.反转字符串.html)中讲解了反转字符串,注意这里强调要原地反转,要不然就失去了题目的意义。
-使用双指针法,**定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。**,时间复杂度是$O(n)$。
+使用双指针法,**定义两个指针(也可以说是索引下标),一个从字符串前面,一个从字符串后面,两个指针同时向中间移动,并交换元素。**,时间复杂度是O(n)。
在[替换空格](https://programmercarl.com/剑指Offer05.替换空格.html) 中介绍使用双指针填充字符串的方法,如果想把这道题目做到极致,就不要只用额外的辅助空间了!
@@ -38,13 +38,13 @@ for (int i = 0; i < array.size(); i++) {
有同学问了,为什么要从后向前填充,从前向后填充不行么?
-从前向后填充就是$O(n^2)$的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
+从前向后填充就是O(n^2)的算法了,因为每次添加元素都要将添加元素之后的所有元素向后移动。
**其实很多数组(字符串)填充类的问题,都可以先预先给数组扩容带填充后的大小,然后在从后向前进行操作。**
-那么在[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中,我们使用双指针法,用$O(n)$的时间复杂度完成字符串删除类的操作,因为题目要产出冗余空格。
+那么在[字符串:花式反转还不够!](https://programmercarl.com/0151.翻转字符串里的单词.html)中,我们使用双指针法,用O(n)的时间复杂度完成字符串删除类的操作,因为题目要产出冗余空格。
-**在删除冗余空格的过程中,如果不注意代码效率,很容易写成了$O(n^2)$的时间复杂度。其实使用双指针法$O(n)$就可以搞定。**
+**在删除冗余空格的过程中,如果不注意代码效率,很容易写成了O(n^2)的时间复杂度。其实使用双指针法O(n)就可以搞定。**
**主要还是大家用erase用的比较随意,一定要注意for循环下用erase的情况,一般可以用双指针写效率更高!**
@@ -74,22 +74,22 @@ for (int i = 0; i < array.size(); i++) {
去重的过程不好处理,有很多小细节,如果在面试中很难想到位。
-时间复杂度可以做到$O(n^2)$,但还是比较费时的,因为不好做剪枝操作。
+时间复杂度可以做到O(n^2),但还是比较费时的,因为不好做剪枝操作。
所以这道题目使用双指针法才是最为合适的,用双指针做这道题目才能就能真正体会到,**通过前后两个指针不算向中间逼近,在一个for循环下完成两个for循环的工作。**
-只用双指针法时间复杂度为$O(n^2)$,但比哈希法的$O(n^2)$效率高得多,哈希法在使用两层for循环的时候,能做的剪枝操作很有限。
+只用双指针法时间复杂度为O(n^2),但比哈希法的O(n^2)效率高得多,哈希法在使用两层for循环的时候,能做的剪枝操作很有限。
在[双指针法:一样的道理,能解决四数之和](https://programmercarl.com/0018.四数之和.html)中,讲到了四数之和,其实思路是一样的,**在三数之和的基础上再套一层for循环,依然是使用双指针法。**
-对于三数之和使用双指针法就是将原本暴力$O(n^3)$的解法,降为$O(n^2)$的解法,四数之和的双指针解法就是将原本暴力$O(n^4)$的解法,降为$O(n^3)$的解法。
+对于三数之和使用双指针法就是将原本暴力O(n^3)的解法,降为O(n^2)的解法,四数之和的双指针解法就是将原本暴力O(n^4)的解法,降为O(n^3)的解法。
同样的道理,五数之和,n数之和都是在这个基础上累加。
# 总结
-本文中一共介绍了leetcode上九道使用双指针解决问题的经典题目,除了链表一些题目一定要使用双指针,其他题目都是使用双指针来提高效率,一般是将$O(n^2)$的时间复杂度,降为$O(n)$。
+本文中一共介绍了leetcode上九道使用双指针解决问题的经典题目,除了链表一些题目一定要使用双指针,其他题目都是使用双指针来提高效率,一般是将O(n^2)的时间复杂度,降为$O(n)$。
建议大家可以把文中涉及到的题目在好好做一做,琢磨琢磨,基本对双指针法就不在话下了。
diff --git a/problems/周总结/20200927二叉树周末总结.md b/problems/周总结/20200927二叉树周末总结.md
index 60f02205..ff8f67d4 100644
--- a/problems/周总结/20200927二叉树周末总结.md
+++ b/problems/周总结/20200927二叉树周末总结.md
@@ -44,7 +44,7 @@ a->right = NULL;
在介绍前中后序遍历的时候,有递归和迭代(非递归),还有一种牛逼的遍历方式:morris遍历。
-morris遍历是二叉树遍历算法的超强进阶算法,morris遍历可以将非递归遍历中的空间复杂度降为$O(1)$,感兴趣大家就去查一查学习学习,比较小众,面试几乎不会考。我其实也没有研究过,就不做过多介绍了。
+morris遍历是二叉树遍历算法的超强进阶算法,morris遍历可以将非递归遍历中的空间复杂度降为O(1),感兴趣大家就去查一查学习学习,比较小众,面试几乎不会考。我其实也没有研究过,就不做过多介绍了。
## 周二
diff --git a/problems/周总结/20201003二叉树周末总结.md b/problems/周总结/20201003二叉树周末总结.md
index a0b8c2dd..18bbf37f 100644
--- a/problems/周总结/20201003二叉树周末总结.md
+++ b/problems/周总结/20201003二叉树周末总结.md
@@ -34,8 +34,8 @@ public:
// 此时就是:左右节点都不为空,且数值相同的情况
// 此时才做递归,做下一层的判断
- bool outside = compare(left->left, right->right); // 左子树:左、 右子树:左 (相对于求对称二叉树,只需改一下这里的顺序)
- bool inside = compare(left->right, right->left); // 左子树:右、 右子树:右
+ bool outside = compare(left->left, right->left); // 左子树:左、 右子树:左 (相对于求对称二叉树,只需改一下这里的顺序)
+ bool inside = compare(left->right, right->right); // 左子树:右、 右子树:右
bool isSame = outside && inside; // 左子树:中、 右子树:中 (逻辑处理)
return isSame;
diff --git a/problems/周总结/20201112回溯周末总结.md b/problems/周总结/20201112回溯周末总结.md
index c61de4bb..af08097b 100644
--- a/problems/周总结/20201112回溯周末总结.md
+++ b/problems/周总结/20201112回溯周末总结.md
@@ -76,7 +76,7 @@
* 空间复杂度:$O(n)$,递归深度为n,所以系统栈所用空间为$O(n)$,每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为$O(n)$。
排列问题分析:
-* 时间复杂度:$O(n!)$,这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。
+* 时间复杂度:$O(n!)$,这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。每个叶子节点都会有一个构造全排列填进数组的操作(对应的代码:`result.push_back(path)`),该操作的复杂度为$O(n)$。所以,最终时间复杂度为:n * n!,简化为$O(n!)$。
* 空间复杂度:$O(n)$,和子集问题同理。
组合问题分析:
diff --git a/problems/周总结/20201126贪心周末总结.md b/problems/周总结/20201126贪心周末总结.md
index 02fccc25..e310c0f8 100644
--- a/problems/周总结/20201126贪心周末总结.md
+++ b/problems/周总结/20201126贪心周末总结.md
@@ -41,7 +41,7 @@
一些录友不清楚[贪心算法:分发饼干](https://programmercarl.com/0455.分发饼干.html)中时间复杂度是怎么来的?
-就是快排$O(n\log n)$,遍历$O(n)$,加一起就是还是$O(n\log n)$。
+就是快排O(nlog n),遍历O(n),加一起就是还是O(nlogn)。
## 周三
diff --git a/problems/周总结/20201210复杂度分析周末总结.md b/problems/周总结/20201210复杂度分析周末总结.md
index 1b404bf0..5e5f696d 100644
--- a/problems/周总结/20201210复杂度分析周末总结.md
+++ b/problems/周总结/20201210复杂度分析周末总结.md
@@ -70,9 +70,9 @@
# 周三
-在[$O(n)$的算法居然超时了,此时的n究竟是多大?](https://programmercarl.com/前序/On的算法居然超时了,此时的n究竟是多大?.html)中介绍了大家在leetcode上提交代码经常遇到的一个问题-超时!
+在[O(n)的算法居然超时了,此时的n究竟是多大?](https://programmercarl.com/前序/On的算法居然超时了,此时的n究竟是多大?.html)中介绍了大家在leetcode上提交代码经常遇到的一个问题-超时!
-估计很多录友知道算法超时了,但没有注意过 $O(n)$的算法,如果1s内出结果,这个n究竟是多大?
+估计很多录友知道算法超时了,但没有注意过 O(n)的算法,如果1s内出结果,这个n究竟是多大?
文中从计算机硬件出发,分析计算机的计算性能,然后亲自做实验,整理出数据如下:
@@ -95,7 +95,7 @@
文中给出了四个版本的代码实现,并逐一分析了其时间复杂度。
-此时大家就会发现,同一道题目,同样使用递归算法,有的同学会写出了$O(n)$的代码,有的同学就写出了$O(\log n)$的代码。
+此时大家就会发现,同一道题目,同样使用递归算法,有的同学会写出了O(n)的代码,有的同学就写出了$O(\log n)$的代码。
其本质是要对递归的时间复杂度有清晰的认识,才能运用递归来有效的解决问题!
diff --git a/problems/周总结/20201217贪心周末总结.md b/problems/周总结/20201217贪心周末总结.md
index e9d22d6e..4d12f92a 100644
--- a/problems/周总结/20201217贪心周末总结.md
+++ b/problems/周总结/20201217贪心周末总结.md
@@ -8,7 +8,7 @@
在[贪心算法:加油站](https://programmercarl.com/0134.加油站.html)中给出每一个加油站的汽油和开到这个加油站的消耗,问汽车能不能开一圈。
-这道题目咋眼一看,感觉是一道模拟题,模拟一下汽车从每一个节点出发看看能不能开一圈,时间复杂度是$O(n^2)$。
+这道题目咋眼一看,感觉是一道模拟题,模拟一下汽车从每一个节点出发看看能不能开一圈,时间复杂度是O(n^2)。
即使用模拟这种情况,也挺考察代码技巧的。
diff --git a/problems/周总结/20210225动规周末总结.md b/problems/周总结/20210225动规周末总结.md
index 0bf9dbdb..21cc53ad 100644
--- a/problems/周总结/20210225动规周末总结.md
+++ b/problems/周总结/20210225动规周末总结.md
@@ -211,8 +211,8 @@ public:
};
```
-* 时间复杂度:$O(n^2)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n^2)
+* 空间复杂度:O(1)
贪心解法代码如下:
@@ -233,8 +233,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
动规解法,版本一,代码如下:
@@ -256,8 +256,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(n)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(n)
从递推公式可以看出,dp[i]只是依赖于dp[i - 1]的状态。
@@ -282,8 +282,8 @@ public:
};
```
-* 时间复杂度:$O(n)$
-* 空间复杂度:$O(1)$
+* 时间复杂度:O(n)
+* 空间复杂度:O(1)
建议先写出版本一,然后在版本一的基础上优化成版本二,而不是直接就写出版本二。
diff --git a/problems/哈希表理论基础.md b/problems/哈希表理论基础.md
index 40a8d0ca..3b6c5ce5 100644
--- a/problems/哈希表理论基础.md
+++ b/problems/哈希表理论基础.md
@@ -22,7 +22,7 @@
例如要查询一个名字是否在这所学校里。
-要枚举的话时间复杂度是$O(n)$,但如果使用哈希表的话, 只需要$O(1)$就可以做到。
+要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
@@ -88,17 +88,17 @@
|集合 |底层实现 | 是否有序 |数值是否可以重复 | 能否更改数值|查询效率 |增删效率|
|---|---| --- |---| --- | --- | ---|
-|std::set |红黑树 |有序 |否 |否 | $O(\log n)$|$O(\log n)$ |
-|std::multiset | 红黑树|有序 |是 | 否| $O(\log n)$ |$O(\log n)$ |
-|std::unordered_set |哈希表 |无序 |否 |否 |$O(1)$ | $O(1)$|
+|std::set |红黑树 |有序 |否 |否 | O(log n)|O(log n) |
+|std::multiset | 红黑树|有序 |是 | 否| O(logn) |O(logn) |
+|std::unordered_set |哈希表 |无序 |否 |否 |O(1) | O(1)|
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
|映射 |底层实现 | 是否有序 |数值是否可以重复 | 能否更改数值|查询效率 |增删效率|
|---|---| --- |---| --- | --- | ---|
-|std::map |红黑树 |key有序 |key不可重复 |key不可修改 | $O(\log n)$|$O(\log n)$ |
-|std::multimap | 红黑树|key有序 | key可重复 | key不可修改|$O(\log n)$ |$O(\log n)$ |
-|std::unordered_map |哈希表 | key无序 |key不可重复 |key不可修改 |$O(1)$ | $O(1)$|
+|std::map |红黑树 |key有序 |key不可重复 |key不可修改 | O(logn)|O(logn) |
+|std::multimap | 红黑树|key有序 | key可重复 | key不可修改|O(log n) |O(log n) |
+|std::unordered_map |哈希表 | key无序 |key不可重复 |key不可修改 |O(1) | O(1)|
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的(这个问题也经常作为面试题,考察对语言容器底层的理解)。
diff --git a/problems/回溯总结.md b/problems/回溯总结.md
index af171243..54ac485b 100644
--- a/problems/回溯总结.md
+++ b/problems/回溯总结.md
@@ -302,11 +302,11 @@ if (startIndex >= nums.size()) { // 终止条件可以不加
**而使用used数组在时间复杂度上几乎没有额外负担!**
-**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是$O(n)$,但如果使用set去重,空间复杂度就变成了$O(n^2)$,因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
+**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
-那有同学可能疑惑 用used数组也是占用$O(n)$的空间啊?
+那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
-used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是$O(n + n)$,最终空间复杂度还是$O(n)$。
+used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是O(n + n),最终空间复杂度还是O(n)。
# 重新安排行程(图论额外拓展)
@@ -380,24 +380,24 @@ used数组可是全局变量,每层与每层之间公用一个used数组,所
以下在计算空间复杂度的时候我都把系统栈(不是数据结构里的栈)所占空间算进去。
子集问题分析:
-* 时间复杂度:$O(2^n)$,因为每一个元素的状态无外乎取与不取,所以时间复杂度为$O(2^n)$
-* 空间复杂度:$O(n)$,递归深度为n,所以系统栈所用空间为$O(n)$,每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为$O(n)$
+* 时间复杂度:O(2^n),因为每一个元素的状态无外乎取与不取,所以时间复杂度为O(2^n)
+* 空间复杂度:O(n),递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n)
排列问题分析:
-* 时间复杂度:$O(n!)$,这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。
-* 空间复杂度:$O(n)$,和子集问题同理。
+* 时间复杂度:O(n!),这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。
+* 空间复杂度:O(n),和子集问题同理。
组合问题分析:
-* 时间复杂度:$O(2^n)$,组合问题其实就是一种子集的问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
-* 空间复杂度:$O(n)$,和子集问题同理。
+* 时间复杂度:O(2^n),组合问题其实就是一种子集的问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
+* 空间复杂度:O(n),和子集问题同理。
N皇后问题分析:
-* 时间复杂度:$O(n!)$ ,其实如果看树形图的话,直觉上是$O(n^n)$,但皇后之间不能见面所以在搜索的过程中是有剪枝的,最差也就是O(n!),n!表示n * (n-1) * .... * 1。
-* 空间复杂度:$O(n)$,和子集问题同理。
+* 时间复杂度:O(n!) ,其实如果看树形图的话,直觉上是O(n^n),但皇后之间不能见面所以在搜索的过程中是有剪枝的,最差也就是O(n!),n!表示n * (n-1) * .... * 1。
+* 空间复杂度:O(n),和子集问题同理。
解数独问题分析:
-* 时间复杂度:$O(9^m)$ , m是'.'的数目。
-* 空间复杂度:$O(n^2)$,递归的深度是n^2
+* 时间复杂度:O(9^m) , m是'.'的数目。
+* 空间复杂度:O(n^2),递归的深度是n^2
**一般说道回溯算法的复杂度,都说是指数级别的时间复杂度,这也算是一个概括吧!**
@@ -432,7 +432,7 @@ N皇后问题分析:
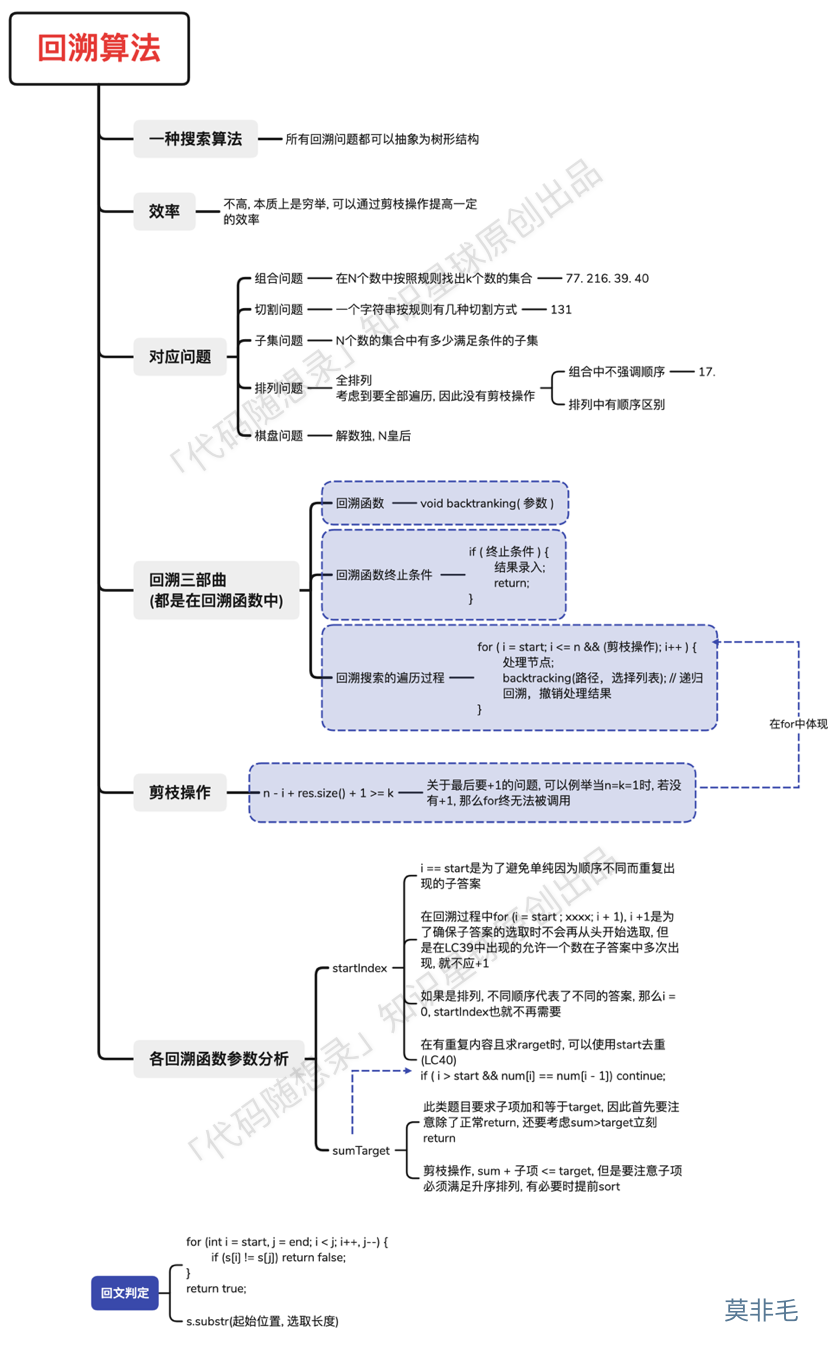
-这个图是 [代码随想录知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 成员:[莫非毛](https://wx.zsxq.com/dweb2/index/footprint/828844212542),所画,总结的非常好,分享给大家。
+这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[莫非毛](https://wx.zsxq.com/dweb2/index/footprint/828844212542),所画,总结的非常好,分享给大家。
**回溯算法系列正式结束,新的系列终将开始,录友们准备开启新的征程!**
diff --git a/problems/回溯算法去重问题的另一种写法.md b/problems/回溯算法去重问题的另一种写法.md
index 7a601493..f48097e1 100644
--- a/problems/回溯算法去重问题的另一种写法.md
+++ b/problems/回溯算法去重问题的另一种写法.md
@@ -226,11 +226,11 @@ public:
**而使用used数组在时间复杂度上几乎没有额外负担!**
-**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是$O(n)$,但如果使用set去重,空间复杂度就变成了$O(n^2)$,因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
+**使用set去重,不仅时间复杂度高了,空间复杂度也高了**,在[本周小结!(回溯算法系列三)](https://programmercarl.com/周总结/20201112回溯周末总结.html)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
-那有同学可能疑惑 用used数组也是占用$O(n)$的空间啊?
+那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
-used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是$O(n + n)$,最终空间复杂度还是$O(n)$。
+used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是O(n + n),最终空间复杂度还是O(n)。
## 总结
@@ -365,6 +365,87 @@ class Solution:
return res
```
+TypeScript:
+
+**90.子集II**
+
+```typescript
+function subsetsWithDup(nums: number[]): number[][] {
+ nums.sort((a, b) => a - b);
+ const resArr: number[][] = [];
+ backTraking(nums, 0, []);
+ return resArr;
+ function backTraking(nums: number[], startIndex: number, route: number[]): void {
+ resArr.push(route.slice());
+ const helperSet: Set
diff --git a/problems/栈与队列理论基础.md b/problems/栈与队列理论基础.md
index b9811b29..8c76614f 100644
--- a/problems/栈与队列理论基础.md
+++ b/problems/栈与队列理论基础.md
@@ -15,7 +15,7 @@
那么我这里在列出四个关于栈的问题,大家可以思考一下。以下是以C++为例,相信使用其他编程语言的同学也对应思考一下,自己使用的编程语言里栈和队列是什么样的。
1. C++中stack 是容器么?
-2. 我们使用的stack是属于那个版本的STL?
+2. 我们使用的stack是属于哪个版本的STL?
3. 我们使用的STL中stack是如何实现的?
4. stack 提供迭代器来遍历stack空间么?
@@ -67,7 +67,7 @@ deque是一个双向队列,只要封住一段,只开通另一端就可以实
我们也可以指定vector为栈的底层实现,初始化语句如下:
-```
+```cpp
std::stack
@@ -8,7 +8,7 @@
不少录友都是非科班转程序员,或者进军互联网的,但有一些HR在HR面的时候特意刁难大家。
-正如[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,这位录友所遭受的情景。
+正如[知识星球](https://programmercarl.com/other/kstar.html)里,这位录友所遭受的情景。

diff --git a/problems/知识星球精选/HR面注意事项.md b/problems/知识星球精选/HR面注意事项.md
index 6a0a26f1..5dba672c 100644
--- a/problems/知识星球精选/HR面注意事项.md
+++ b/problems/知识星球精选/HR面注意事项.md
@@ -1,12 +1,12 @@
# HR面注意事项
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里已经有一些录友开始准备HR面。
+[知识星球](https://programmercarl.com/other/kstar.html)里已经有一些录友开始准备HR面。

@@ -86,4 +86,4 @@ HR朋友的回答是:你不说真相,我会认为你可能对技术有追求
---------------
-加入「代码随想录」知识星球,[点击这里](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)
+加入「代码随想录」知识星球,[点击这里](https://programmercarl.com/other/kstar.html)
diff --git a/problems/知识星球精选/offer对比-决赛圈.md b/problems/知识星球精选/offer对比-决赛圈.md
index 1f91730f..081ae5ec 100644
--- a/problems/知识星球精选/offer对比-决赛圈.md
+++ b/problems/知识星球精选/offer对比-决赛圈.md
@@ -1,5 +1,5 @@
@@ -7,7 +7,7 @@
秋招已经结束了,该开奖的差不多都陆续开奖了,很多录友的也进入了offer决赛圈。
-我每天都在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,回答十几个offer对比的问题,我也是结合自己过来人的经验给大家做做分析,我也选几个案例,在公众号上也给大家分享一下,希望对大家有所启发。
+我每天都在[知识星球](https://programmercarl.com/other/kstar.html)里,回答十几个offer对比的问题,我也是结合自己过来人的经验给大家做做分析,我也选几个案例,在公众号上也给大家分享一下,希望对大家有所启发。
以下是知识星球里的部分问答:
diff --git a/problems/知识星球精选/offer总决赛,何去何从.md b/problems/知识星球精选/offer总决赛,何去何从.md
index 01745ae3..e22c5d4a 100644
--- a/problems/知识星球精选/offer总决赛,何去何从.md
+++ b/problems/知识星球精选/offer总决赛,何去何从.md
@@ -1,12 +1,12 @@
# offer总决赛,何去何从!
-最近在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)上,给至少300位录友做了offer选择,准对大家的情况,结合我的经验做一做分析。
+最近在[知识星球](https://programmercarl.com/other/kstar.html)上,给至少300位录友做了offer选择,准对大家的情况,结合我的经验做一做分析。
希望可以给大家带来不一样的分析视角,帮大家少走弯路。
diff --git a/problems/知识星球精选/offer的选择.md b/problems/知识星球精选/offer的选择.md
index b9b40dea..106bc5f8 100644
--- a/problems/知识星球精选/offer的选择.md
+++ b/problems/知识星球精选/offer的选择.md
@@ -1,6 +1,6 @@
@@ -10,7 +10,7 @@
不过大部分同学应该拿到的是 两个大厂offer,或者说拿到两个小厂offer,还要考虑岗位,业务,公司前景,那么就要纠结如何选择了。
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,我已经给很多录友提供了选择offer的建议,这里也分享出来,希望对大家在选择offer上有所启发。
+在[知识星球](https://programmercarl.com/other/kstar.html)里,我已经给很多录友提供了选择offer的建议,这里也分享出来,希望对大家在选择offer上有所启发。
## 保研与工作
diff --git a/problems/知识星球精选/不一样的七夕.md b/problems/知识星球精选/不一样的七夕.md
index a670e078..40d15ecd 100644
--- a/problems/知识星球精选/不一样的七夕.md
+++ b/problems/知识星球精选/不一样的七夕.md
@@ -1,11 +1,11 @@
# 特殊的七夕
-昨天在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)发了一个状态:
+昨天在[知识星球](https://programmercarl.com/other/kstar.html)发了一个状态:
diff --git a/problems/知识星球精选/不喜欢写代码怎么办.md b/problems/知识星球精选/不喜欢写代码怎么办.md
index 9bc624bb..84d372f0 100644
--- a/problems/知识星球精选/不喜欢写代码怎么办.md
+++ b/problems/知识星球精选/不喜欢写代码怎么办.md
@@ -1,7 +1,7 @@
# 看到代码就抵触!怎么办?
-最近在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,看到了不少录友,其实是不喜欢写代码,看到 哪些八股文都是很抵触的。
+最近在[知识星球](https://programmercarl.com/other/kstar.html)里,看到了不少录友,其实是不喜欢写代码,看到 哪些八股文都是很抵触的。
其实是一个普遍现象,我在星球里分享了一下,我对这一情况的一些想法。
diff --git a/problems/知识星球精选/不少录友想放弃秋招.md b/problems/知识星球精选/不少录友想放弃秋招.md
index 721a9313..81c99503 100644
--- a/problems/知识星球精选/不少录友想放弃秋招.md
+++ b/problems/知识星球精选/不少录友想放弃秋招.md
@@ -1,5 +1,5 @@
@@ -7,7 +7,7 @@
马上就要九月份了,互联网大厂的秋招的序幕早已拉开。
-发现[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里有一部分录友想放弃秋招,直接准备明年的春招,估计关注公众号的录友也有不少有这种想法的。
+发现[知识星球](https://programmercarl.com/other/kstar.html)里有一部分录友想放弃秋招,直接准备明年的春招,估计关注公众号的录友也有不少有这种想法的。

@@ -50,7 +50,7 @@
所以也给明年找工作的录友们(2023届)提一个醒,现在就要系统性的准备起来了,因为明年春季实习招聘 是一个很好的进大厂的机会,剩下的时间也不是很多了。
-来看看[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,一位准大三的录友准备的情况
+来看看[知识星球](https://programmercarl.com/other/kstar.html)里,一位准大三的录友准备的情况

@@ -60,7 +60,7 @@
**我已经预感到 这两位 等到秋招的时候就是稳稳的offer收割机**。
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)还有很多已经开始提前准备,或者看了 星球发文状态就开始着手准备的录友了。
+[知识星球](https://programmercarl.com/other/kstar.html)还有很多已经开始提前准备,或者看了 星球发文状态就开始着手准备的录友了。
所以 **所谓的大牛,都是 很早就规划自己要学的东西,很早就开始向过来人请教应该如何找工作,很早就知道自己应该学哪些技术,看哪些书, 这样等到找工作的时候,才是剑锋出鞘的时候**。
diff --git a/problems/知识星球精选/专业技能可以这么写.md b/problems/知识星球精选/专业技能可以这么写.md
index dd616713..a1b7ba3a 100644
--- a/problems/知识星球精选/专业技能可以这么写.md
+++ b/problems/知识星球精选/专业技能可以这么写.md
@@ -1,5 +1,5 @@
@@ -8,7 +8,7 @@
# 你简历里的「专业技能」写的够专业么?
-其实我几乎每天都要看一些简历,有一些写的不错的,我都会在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里分享一下。
+其实我几乎每天都要看一些简历,有一些写的不错的,我都会在[知识星球](https://programmercarl.com/other/kstar.html)里分享一下。

这次呢,我再专门说一说简历中的【专业技能】这一栏应该怎么写。
diff --git a/problems/知识星球精选/入职后担心代码能力跟不上.md b/problems/知识星球精选/入职后担心代码能力跟不上.md
index c2704525..58b8c32c 100644
--- a/problems/知识星球精选/入职后担心代码能力跟不上.md
+++ b/problems/知识星球精选/入职后担心代码能力跟不上.md
@@ -1,12 +1,12 @@
# 入职后担心代码能力跟不上
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)上,很多录友已经担心自己去了公司工作以后,代码能力跟不上,会压力很大。
+在[知识星球](https://programmercarl.com/other/kstar.html)上,很多录友已经担心自己去了公司工作以后,代码能力跟不上,会压力很大。

diff --git a/problems/知识星球精选/关于实习大家的疑问.md b/problems/知识星球精选/关于实习大家的疑问.md
index 5d4e695b..88de4436 100644
--- a/problems/知识星球精选/关于实习大家的疑问.md
+++ b/problems/知识星球精选/关于实习大家的疑问.md
@@ -1,11 +1,11 @@
# 关于实习,大家可能有点迷茫!
-我在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里回答了很多关于实习相关的问题,其实很多录友可能都有这么样的疑问,主要关于实习的问题有如下四点:
+我在[知识星球](https://programmercarl.com/other/kstar.html)里回答了很多关于实习相关的问题,其实很多录友可能都有这么样的疑问,主要关于实习的问题有如下四点:
* 秋招什么时候开始准备
* 要不要准备实习
diff --git a/problems/知识星球精选/关于提前批的一些建议.md b/problems/知识星球精选/关于提前批的一些建议.md
index 415a8b2f..6a316bd2 100644
--- a/problems/知识星球精选/关于提前批的一些建议.md
+++ b/problems/知识星球精选/关于提前批的一些建议.md
@@ -1,5 +1,5 @@
@@ -9,7 +9,7 @@
以前提前批,都是 8月份,8月份中序左右,而不少大厂现在就已经提前批了。
-不少录友在 公众号留言,和[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,表示提前批来的还是有点快。
+不少录友在 公众号留言,和[知识星球](https://programmercarl.com/other/kstar.html)里,表示提前批来的还是有点快。

diff --git a/problems/知识星球精选/写简历的一些问题.md b/problems/知识星球精选/写简历的一些问题.md
index af42cea1..426eb2a6 100644
--- a/problems/知识星球精选/写简历的一些问题.md
+++ b/problems/知识星球精选/写简历的一些问题.md
@@ -1,11 +1,11 @@
# 程序员应该这么写简历!
-自运营[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)以来,我已经给星球里的录友们看了 一百多份简历,并准对大家简历上的问题都给出了对应的详细建议。
+自运营[知识星球](https://programmercarl.com/other/kstar.html)以来,我已经给星球里的录友们看了 一百多份简历,并准对大家简历上的问题都给出了对应的详细建议。
社招,校招,实习的都有,其实大家的简历看多了,发现有很多共性的问题,这里就和大家分享一下。
diff --git a/problems/知识星球精选/初入大三选择考研VS工作.md b/problems/知识星球精选/初入大三选择考研VS工作.md
index ba675761..f602e9e9 100644
--- a/problems/知识星球精选/初入大三选择考研VS工作.md
+++ b/problems/知识星球精选/初入大三选择考研VS工作.md
@@ -1,6 +1,6 @@
@@ -8,7 +8,7 @@
9月份开学季,已过,一些录友也升入大三了,升入大三摆在自己面前最大的问题就是,考研还是找工作?
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里就有录友问我这样一个问题, 其实每个人情况不一样,做出的选择也不一样,这里给大家分享一下,相信对你也会有启发。
+在[知识星球](https://programmercarl.com/other/kstar.html)里就有录友问我这样一个问题, 其实每个人情况不一样,做出的选择也不一样,这里给大家分享一下,相信对你也会有启发。

diff --git a/problems/知识星球精选/刷力扣用不用库函数.md b/problems/知识星球精选/刷力扣用不用库函数.md
index 73f2a2d5..c8e2f5c6 100644
--- a/problems/知识星球精选/刷力扣用不用库函数.md
+++ b/problems/知识星球精选/刷力扣用不用库函数.md
@@ -1,11 +1,11 @@
# 究竟什么时候用库函数,什么时候要自己实现
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里有录友问我,刷题究竟要不要用库函数? 刷题的时候总是禁不住库函数的诱惑,如果都不用库函数一些题目做起来还很麻烦。
+在[知识星球](https://programmercarl.com/other/kstar.html)里有录友问我,刷题究竟要不要用库函数? 刷题的时候总是禁不住库函数的诱惑,如果都不用库函数一些题目做起来还很麻烦。
估计不少录友都有这个困惑,我来说一说对于库函数的使用。
@@ -27,7 +27,7 @@
使用库函数最大的忌讳就是不知道这个库函数怎么实现的,也不知道其时间复杂度,上来就用,这样写出来的算法,时间复杂度自己都掌握不好的。
-例如for循环里套一个字符串的insert,erase之类的操作,你说时间复杂度是多少呢,很明显是$O(n^2)$的时间复杂度了。
+例如for循环里套一个字符串的insert,erase之类的操作,你说时间复杂度是多少呢,很明显是O(n^2)的时间复杂度了。
在刷题的时候本着我说的标准来使用库函数,详细对大家回有所帮助!
diff --git a/problems/知识星球精选/刷题攻略要刷两遍.md b/problems/知识星球精选/刷题攻略要刷两遍.md
index 1f4fd7f9..285a5728 100644
--- a/problems/知识星球精选/刷题攻略要刷两遍.md
+++ b/problems/知识星球精选/刷题攻略要刷两遍.md
@@ -1,5 +1,5 @@
@@ -27,7 +27,7 @@
第三遍基本就得心应手了。
-在[「代码随想录」知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)中,我都是强调大家要至少刷两遍,有时间的话刷三遍,
+在[「代码随想录」知识星球](https://programmercarl.com/other/kstar.html)中,我都是强调大家要至少刷两遍,有时间的话刷三遍,
可以看看星球里录友们的打卡:
diff --git a/problems/知识星球精选/博士转行计算机.md b/problems/知识星球精选/博士转行计算机.md
index 66769264..4da79e97 100644
--- a/problems/知识星球精选/博士转行计算机.md
+++ b/problems/知识星球精选/博士转行计算机.md
@@ -1,11 +1,11 @@
# 本硕非计算机博士,如果找计算机相关工作
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,有一位博士录友,本硕都不是计算机,博士转的计算机,问了这样一个问题
+在[知识星球](https://programmercarl.com/other/kstar.html)里,有一位博士录友,本硕都不是计算机,博士转的计算机,问了这样一个问题

diff --git a/problems/知识星球精选/合适自己的就是最好的.md b/problems/知识星球精选/合适自己的就是最好的.md
index fda51afa..dc31f5a7 100644
--- a/problems/知识星球精选/合适自己的就是最好的.md
+++ b/problems/知识星球精选/合适自己的就是最好的.md
@@ -1,5 +1,5 @@
@@ -7,7 +7,7 @@
秋招已经进入下半场了,不少同学也拿到了offer,但不是说非要进大厂,每个人情况都不一样,**合适自己的,就是最好的!**。
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里有一位录友,就终于拿到了合适自己的offer,并不是大厂,是南京的一家公司,**但很合适自己,其实就非常值得开心**。
+[知识星球](https://programmercarl.com/other/kstar.html)里有一位录友,就终于拿到了合适自己的offer,并不是大厂,是南京的一家公司,**但很合适自己,其实就非常值得开心**。

@@ -33,5 +33,5 @@
我在发文的时候 看了一遍她这几个月完整的打卡过程,还是深有感触的。
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里还有很多很多这样的录友在每日奋斗着,**我相信 等大家拿到offer之后,在回头看一下当初星球里曾经每日打卡的点点滴滴,不仅会感动自己 也会感动每一位见证者**。
+[知识星球](https://programmercarl.com/other/kstar.html)里还有很多很多这样的录友在每日奋斗着,**我相信 等大家拿到offer之后,在回头看一下当初星球里曾经每日打卡的点点滴滴,不仅会感动自己 也会感动每一位见证者**。
diff --git a/problems/知识星球精选/备战2022届秋招.md b/problems/知识星球精选/备战2022届秋招.md
index 207a5e2a..55c2a3bf 100644
--- a/problems/知识星球精选/备战2022届秋招.md
+++ b/problems/知识星球精选/备战2022届秋招.md
@@ -1,11 +1,11 @@
# 要开始准备2022届的秋招了
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里准备秋招的录友还真不少,也会回答过不少关于秋招的问题。
+在[知识星球](https://programmercarl.com/other/kstar.html)里准备秋招的录友还真不少,也会回答过不少关于秋招的问题。

diff --git a/problems/知识星球精选/大厂新人培养体系.md b/problems/知识星球精选/大厂新人培养体系.md
index ccd2f1c2..0e905e42 100644
--- a/problems/知识星球精选/大厂新人培养体系.md
+++ b/problems/知识星球精选/大厂新人培养体系.md
@@ -1,11 +1,11 @@
# 大厂的新人培养体系是什么样的
-之前我一直在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)和大家讲,能进大厂一定要进大厂,大厂有比较好的培养体系。
+之前我一直在[知识星球](https://programmercarl.com/other/kstar.html)和大家讲,能进大厂一定要进大厂,大厂有比较好的培养体系。
也有录友在星球里问我,究竟培养体系应该是什么样的呢? 大厂都会这么培养新人么?
diff --git a/problems/知识星球精选/天下乌鸦一般黑.md b/problems/知识星球精选/天下乌鸦一般黑.md
index 29543747..ccd1c326 100644
--- a/problems/知识星球精选/天下乌鸦一般黑.md
+++ b/problems/知识星球精选/天下乌鸦一般黑.md
@@ -1,6 +1,6 @@
@@ -8,7 +8,7 @@
相信大家应该经常在 各大论坛啊之类的 看到对各个互联网公司的评价,有风评好的,也有风评不好的。
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里有录友问我这样一个问题:
+在[知识星球](https://programmercarl.com/other/kstar.html)里有录友问我这样一个问题:

diff --git a/problems/知识星球精选/如何权衡实习与秋招复习.md b/problems/知识星球精选/如何权衡实习与秋招复习.md
index 275588df..07e2bba6 100644
--- a/problems/知识星球精选/如何权衡实习与秋招复习.md
+++ b/problems/知识星球精选/如何权衡实习与秋招复习.md
@@ -1,11 +1,11 @@
# 已经在实习的录友如何准备秋招?
-最近在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)一位录友问了实习生如何权衡工作和准备秋招的问题。
+最近在[知识星球](https://programmercarl.com/other/kstar.html)一位录友问了实习生如何权衡工作和准备秋招的问题。

diff --git a/problems/知识星球精选/客三消.md b/problems/知识星球精选/客三消.md
index 8a7b5fc6..6b81ab2c 100644
--- a/problems/知识星球精选/客三消.md
+++ b/problems/知识星球精选/客三消.md
@@ -1,5 +1,5 @@
@@ -17,7 +17,7 @@
然后朋友圈就炸了,上百条的留言,问我这是为啥。
-其实这个问题在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里也有录友问过我。
+其实这个问题在[知识星球](https://programmercarl.com/other/kstar.html)里也有录友问过我。

@@ -87,7 +87,7 @@
# 总结
-以上就是我在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里的详细回答。
+以上就是我在[知识星球](https://programmercarl.com/other/kstar.html)里的详细回答。
注意我这里说的一般情况,当然各个岗位都有佼佼者,或者说大牛,客户端也有大牛,也很香,不过这是极少数,就不在讨论范围内了。
diff --git a/problems/知识星球精选/技术不好如何选择技术方向.md b/problems/知识星球精选/技术不好如何选择技术方向.md
index dd13f46b..4ad4659b 100644
--- a/problems/知识星球精选/技术不好如何选择技术方向.md
+++ b/problems/知识星球精选/技术不好如何选择技术方向.md
@@ -1,11 +1,11 @@
# 技术不太好,也不知道对技术有没有兴趣,我该怎么选?
-最近在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里解答了不少录友们的疑惑,其实发现一个挺普遍的问题:
+最近在[知识星球](https://programmercarl.com/other/kstar.html)里解答了不少录友们的疑惑,其实发现一个挺普遍的问题:
* 我技术很一般
* 对技术也没有什么追求
diff --git a/problems/知识星球精选/提前批已经开始了.md b/problems/知识星球精选/提前批已经开始了.md
index ba05b5a9..3e255746 100644
--- a/problems/知识星球精选/提前批已经开始了.md
+++ b/problems/知识星球精选/提前批已经开始了.md
@@ -1,5 +1,5 @@
@@ -7,7 +7,7 @@
最近华为提前批已经开始了,不少同学已经陆续参加了提前批的面试。
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)上就有录友问我这么个问题:
+在[知识星球](https://programmercarl.com/other/kstar.html)上就有录友问我这么个问题:

diff --git a/problems/知识星球精选/秋招下半场依然没offer.md b/problems/知识星球精选/秋招下半场依然没offer.md
index 829f82ba..5862dd32 100644
--- a/problems/知识星球精选/秋招下半场依然没offer.md
+++ b/problems/知识星球精选/秋招下半场依然没offer.md
@@ -1,11 +1,11 @@
# 秋招下半场依然没offer,怎么办?
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里一些录友拿到了满意的offer,也有一些录友,依然没有offer,每天的状态已经不能用焦虑来形容了。
+[知识星球](https://programmercarl.com/other/kstar.html)里一些录友拿到了满意的offer,也有一些录友,依然没有offer,每天的状态已经不能用焦虑来形容了。
在星球里就有录友向我提问了这样一个问题:
@@ -52,7 +52,7 @@
## 在学点技术,冲春招?
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里还有一位录友,也是类似的情况,秋招感觉很艰难,要不要在学一学微服务分布式之类的,再冲春招。
+[知识星球](https://programmercarl.com/other/kstar.html)里还有一位录友,也是类似的情况,秋招感觉很艰难,要不要在学一学微服务分布式之类的,再冲春招。

@@ -71,13 +71,13 @@
## 给参加明年秋招录友的劝告
-其实我在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,**看到了太多太多 参加今年秋招的录友 埋怨自己 准备的太晚了,没想到要看的东西这么多,没想到竞争这么激烈**。
+其实我在[知识星球](https://programmercarl.com/other/kstar.html)里,**看到了太多太多 参加今年秋招的录友 埋怨自己 准备的太晚了,没想到要看的东西这么多,没想到竞争这么激烈**。
所以明年参加秋招的录友,要提前就开始准备,明确自己的岗位,知道岗位的要求,制定自己的计划,然后按计划执行。
**其实多早开始准备,都不算早!**
-很多在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里的准大三,研一的录友,都能在星球里感受到 秋招的竞争与激烈。
+很多在[知识星球](https://programmercarl.com/other/kstar.html)里的准大三,研一的录友,都能在星球里感受到 秋招的竞争与激烈。
所以他们也就早早的开始准备了。
@@ -87,7 +87,7 @@
估计大多数准大三或者准研一的同学都还没有这种意识。
-**但在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,通过每天录友们的打卡,每天都能感受到这种紧迫感**。
+**但在[知识星球](https://programmercarl.com/other/kstar.html)里,通过每天录友们的打卡,每天都能感受到这种紧迫感**。
正如一位星球里的录友这么说:
diff --git a/problems/知识星球精选/秋招开奖.md b/problems/知识星球精选/秋招开奖.md
index 368596b6..82686785 100644
--- a/problems/知识星球精选/秋招开奖.md
+++ b/problems/知识星球精选/秋招开奖.md
@@ -1,6 +1,6 @@
@@ -8,7 +8,7 @@
最近秋招的录友已经陆续开奖了,同时开奖多少,也是offer选择的一个重要因素,毕竟谁能和钱过意不去呢。
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里这位录友拿到的百度offer薪资确实很高
+[知识星球](https://programmercarl.com/other/kstar.html)里这位录友拿到的百度offer薪资确实很高

diff --git a/problems/知识星球精选/秋招总结1.md b/problems/知识星球精选/秋招总结1.md
index efec67ee..2aec24dc 100644
--- a/problems/知识星球精选/秋招总结1.md
+++ b/problems/知识星球精选/秋招总结1.md
@@ -1,5 +1,5 @@
@@ -11,7 +11,7 @@
时间总是过得很快,但曾经焦虑的小伙,现在也拿到几个offer了,不一定人人都要冲大厂,卷算法,卷后端,合适自己就好,要不然会把自己搞的很累。
-以下是他的秋招总结,**写的很用心,说了很多面试中使用的方法,发在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里,立刻就引来星球小伙伴们的围观**,算是给星球里明年要秋招的录友做了一个参考。
+以下是他的秋招总结,**写的很用心,说了很多面试中使用的方法,发在[知识星球](https://programmercarl.com/other/kstar.html)里,立刻就引来星球小伙伴们的围观**,算是给星球里明年要秋招的录友做了一个参考。

diff --git a/problems/知识星球精选/秋招总结2.md b/problems/知识星球精选/秋招总结2.md
index 7f4b6770..897a7ec3 100644
--- a/problems/知识星球精选/秋招总结2.md
+++ b/problems/知识星球精选/秋招总结2.md
@@ -1,10 +1,10 @@
-
# 倒霉透顶,触底反弹!
-星球里不少录友秋招已经陆续结束了,很多录友都在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里写下了自己的秋招总结,但今天这位录友很特殊,甚至我给她修改简历的时候我都“有点愁”。
+星球里不少录友秋招已经陆续结束了,很多录友都在[知识星球](https://programmercarl.com/other/kstar.html)里写下了自己的秋招总结,但今天这位录友很特殊,甚至我给她修改简历的时候我都“有点愁”。
他的秋招过程也是极其坎坷,**逼签、被养鱼最后收到感谢信、校招流程收到实习offer,还有数不清的简历挂……**,可能是太倒霉了,最后触底反弹,接到了百度的offer,虽然是白菜价,但真的很不错了。
diff --git a/problems/知识星球精选/秋招总结3.md b/problems/知识星球精选/秋招总结3.md
index 895c1b8c..05a677ed 100644
--- a/problems/知识星球精选/秋招总结3.md
+++ b/problems/知识星球精选/秋招总结3.md
@@ -1,4 +1,4 @@
-
@@ -6,7 +6,7 @@
其实无论社招,还是校招,心态都很重要,例如,别人那个一堆offer,自己陷入深深的焦虑。 面试分明感觉自己表现的不错,结果就是挂了。面试中遇到了面试官的否定,然后就开始自我怀疑,等等等。
-如果你也遇到这些问题,可以认真读完[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里一位录友的总结,他是非科班,机械转码,今年5月份加入的星球,坚持打卡几个月,如果也获得自己心仪的offer,他的心路历程对大家会很有启发。
+如果你也遇到这些问题,可以认真读完[知识星球](https://programmercarl.com/other/kstar.html)里一位录友的总结,他是非科班,机械转码,今年5月份加入的星球,坚持打卡几个月,如果也获得自己心仪的offer,他的心路历程对大家会很有启发。

diff --git a/problems/知识星球精选/秋招的上半场.md b/problems/知识星球精选/秋招的上半场.md
index f404e611..6c817577 100644
--- a/problems/知识星球精选/秋招的上半场.md
+++ b/problems/知识星球精选/秋招的上半场.md
@@ -1,11 +1,11 @@
# 秋招上半场的总结
-八月份已经接近尾声,不少录友已经在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 已经总结了秋招的上半场。
+八月份已经接近尾声,不少录友已经在[知识星球](https://programmercarl.com/other/kstar.html) 已经总结了秋招的上半场。

diff --git a/problems/知识星球精选/秋招进行中的迷茫与焦虑.md b/problems/知识星球精选/秋招进行中的迷茫与焦虑.md
index 6083c7b1..24e7760c 100644
--- a/problems/知识星球精选/秋招进行中的迷茫与焦虑.md
+++ b/problems/知识星球精选/秋招进行中的迷茫与焦虑.md
@@ -1,5 +1,5 @@
@@ -9,7 +9,7 @@
特别是大三的同学吧,同时面临这找工作和考研两个方向的诱惑。
-一位录友就在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)问了我这个问题:
+一位录友就在[知识星球](https://programmercarl.com/other/kstar.html)问了我这个问题:

diff --git a/problems/知识星球精选/英语到底重不重要.md b/problems/知识星球精选/英语到底重不重要.md
index 32e6a39b..5ee7fc2d 100644
--- a/problems/知识星球精选/英语到底重不重要.md
+++ b/problems/知识星球精选/英语到底重不重要.md
@@ -1,11 +1,11 @@
# 对程序员来说,英语到底重不重要
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)有一位录友问了我这么一个问题。
+在[知识星球](https://programmercarl.com/other/kstar.html)有一位录友问了我这么一个问题。

diff --git a/problems/知识星球精选/要不要考研.md b/problems/知识星球精选/要不要考研.md
index a5f2dfa0..180e5d13 100644
--- a/problems/知识星球精选/要不要考研.md
+++ b/problems/知识星球精选/要不要考研.md
@@ -1,11 +1,11 @@
# 到底要不要读研
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里讨论了一下关于要不要读研的问题。
+在[知识星球](https://programmercarl.com/other/kstar.html)里讨论了一下关于要不要读研的问题。

diff --git a/problems/知识星球精选/逼签.md b/problems/知识星球精选/逼签.md
index 90e4e67d..f75e3642 100644
--- a/problems/知识星球精选/逼签.md
+++ b/problems/知识星球精选/逼签.md
@@ -7,7 +7,7 @@
如果是心仪的公司要求三天内签三方,我相信大家就没有被逼签的感觉了,哈哈哈
-[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)里很多录友都问我,XX公司又要逼签了,怎么办。 我在公众号也分享一下,希望对大家有所帮助。
+[知识星球](https://programmercarl.com/other/kstar.html)里很多录友都问我,XX公司又要逼签了,怎么办。 我在公众号也分享一下,希望对大家有所帮助。

diff --git a/problems/知识星球精选/非科班2021秋招总结.md b/problems/知识星球精选/非科班2021秋招总结.md
index c2c7ed33..b92420ad 100644
--- a/problems/知识星球精选/非科班2021秋招总结.md
+++ b/problems/知识星球精选/非科班2021秋招总结.md
@@ -1,6 +1,6 @@
@@ -10,7 +10,7 @@
其中一位录友写的很好,所以想分享出来 给公众号上的录友也看一看,相信对大家有所启发,特别是明年要找工作的录友,值得好好看一看。
-这篇总结首发在代码随想录[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)上,立刻就获得了60个赞,很多评论,我这里放出一个截图:
+这篇总结首发在代码随想录[知识星球](https://programmercarl.com/other/kstar.html)上,立刻就获得了60个赞,很多评论,我这里放出一个截图:

diff --git a/problems/知识星球精选/非科班的困扰.md b/problems/知识星球精选/非科班的困扰.md
index d5fea532..470b233b 100644
--- a/problems/知识星球精选/非科班的困扰.md
+++ b/problems/知识星球精选/非科班的困扰.md
@@ -1,11 +1,11 @@
# 非科班的困扰!
-在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ) 里很多录友都是非科班转码的,也是要准备求职,或者准备明年秋招,非科班的录友其实对 准备找工作所需要的知识不太清楚,对其难度也不太清楚,所有总感觉准备起来心里没有底。
+在[知识星球](https://programmercarl.com/other/kstar.html) 里很多录友都是非科班转码的,也是要准备求职,或者准备明年秋招,非科班的录友其实对 准备找工作所需要的知识不太清楚,对其难度也不太清楚,所有总感觉准备起来心里没有底。
例如星球里有这位录友的提问:
diff --git a/problems/知识星球精选/面试中发散性问题.md b/problems/知识星球精选/面试中发散性问题.md
index 7fb9150f..5cade944 100644
--- a/problems/知识星球精选/面试中发散性问题.md
+++ b/problems/知识星球精选/面试中发散性问题.md
@@ -1,11 +1,11 @@
# 面试中遇到发散性问题,应该怎么办?
-这周在[知识星球](https://mp.weixin.qq.com/s/QVF6upVMSbgvZy8lHZS3CQ)有一位录友问了我这么一个问题,我感觉挺有代表性的,应该不少录友在面试中不论是社招还是校招都会遇到这一类的问题。
+这周在[知识星球](https://programmercarl.com/other/kstar.html)有一位录友问了我这么一个问题,我感觉挺有代表性的,应该不少录友在面试中不论是社招还是校招都会遇到这一类的问题。
问题如下:
diff --git a/problems/算法模板.md b/problems/算法模板.md
index a4136511..789d8f80 100644
--- a/problems/算法模板.md
+++ b/problems/算法模板.md
@@ -394,7 +394,7 @@ var postorder = function (root, list) {
```javascript
var preorderTraversal = function (root) {
let res = [];
- if (root === null) return rs;
+ if (root === null) return res;
let stack = [root],
cur = null;
while (stack.length) {
@@ -536,6 +536,269 @@ function backtracking(参数) {
}
```
+TypeScript:
+
+## 二分查找法
+
+使用左闭右闭区间
+
+```typescript
+var search = function (nums: number[], target: number): number {
+ let left: number = 0, right: number = nums.length - 1;
+ // 使用左闭右闭区间
+ while (left <= right) {
+ let mid: number = left + Math.floor((right - left)/2);
+ if (nums[mid] > target) {
+ right = mid - 1; // 去左面闭区间寻找
+ } else if (nums[mid] < target) {
+ left = mid + 1; // 去右面闭区间寻找
+ } else {
+ return mid;
+ }
+ }
+ return -1;
+};
+```
+
+使用左闭右开区间
+
+```typescript
+var search = function (nums: number[], target: number): number {
+ let left: number = 0, right: number = nums.length;
+ // 使用左闭右开区间 [left, right)
+ while (left < right) {
+ let mid: number = left + Math.floor((right - left)/2);
+ if (nums[mid] > target) {
+ right = mid; // 去左面闭区间寻找
+ } else if (nums[mid] < target) {
+ left = mid + 1; // 去右面闭区间寻找
+ } else {
+ return mid;
+ }
+ }
+ return -1;
+};
+```
+
+## KMP
+
+```typescript
+var kmp = function (next: number[], s: number): void {
+ next[0] = -1;
+ let j: number = -1;
+ for(let i: number = 1; i < s.length; i++){
+ while (j >= 0 && s[i] !== s[j + 1]) {
+ j = next[j];
+ }
+ if (s[i] === s[j + 1]) {
+ j++;
+ }
+ next[i] = j;
+ }
+}
+```
+
+## 二叉树
+
+### 深度优先遍历(递归)
+
+二叉树节点定义:
+
+```typescript
+class TreeNode {
+ val: number
+ left: TreeNode | null
+ right: TreeNode | null
+ constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null) {
+ this.val = (val===undefined ? 0 : val)
+ this.left = (left===undefined ? null : left)
+ this.right = (right===undefined ? null : right)
+ }
+}
+```
+
+前序遍历(中左右):
+
+```typescript
+var preorder = function (root: TreeNode | null, list: number[]): void {
+ if (root === null) return;
+ list.push(root.val); // 中
+ preorder(root.left, list); // 左
+ preorder(root.right, list); // 右
+}
+```
+
+中序遍历(左中右):
+
+```typescript
+var inorder = function (root: TreeNode | null, list: number[]): void {
+ if (root === null) return;
+ inorder(root.left, list); // 左
+ list.push(root.val); // 中
+ inorder(root.right, list); // 右
+}
+```
+
+后序遍历(左右中):
+
+```typescript
+var postorder = function (root: TreeNode | null, list: number[]): void {
+ if (root === null) return;
+ postorder(root.left, list); // 左
+ postorder(root.right, list); // 右
+ list.push(root.val); // 中
+}
+```
+
+### 深度优先遍历(迭代)
+
+前序遍历(中左右):
+
+```typescript
+var preorderTraversal = function (root: TreeNode | null): number[] {
+ let res: number[] = [];
+ if (root === null) return res;
+ let stack: TreeNode[] = [root],
+ cur: TreeNode | null = null;
+ while (stack.length) {
+ cur = stack.pop();
+ res.push(cur.val);
+ cur.right && stack.push(cur.right);
+ cur.left && stack.push(cur.left);
+ }
+ return res;
+};
+```
+
+中序遍历(左中右):
+
+```typescript
+var inorderTraversal = function (root: TreeNode | null): number[] {
+ let res: number[] = [];
+ if (root === null) return res;
+ let stack: TreeNode[] = [];
+ let cur: TreeNode | null = root;
+ while (stack.length !== 0 || cur !== null) {
+ if (cur !== null) {
+ stack.push(cur);
+ cur = cur.left;
+ } else {
+ cur = stack.pop();
+ res.push(cur.val);
+ cur = cur.right;
+ }
+ }
+ return res;
+};
+```
+
+后序遍历(左右中):
+
+```typescript
+var postorderTraversal = function (root: TreeNode | null): number[] {
+ let res: number[] = [];
+ if (root === null) return res;
+ let stack: TreeNode[] = [root];
+ let cur: TreeNode | null = null;
+ while (stack.length) {
+ cur = stack.pop();
+ res.push(cur.val);
+ cur.left && stack.push(cur.left);
+ cur.right && stack.push(cur.right);
+ }
+ return res.reverse()
+};
+```
+
+### 广度优先遍历(队列)
+
+```typescript
+var levelOrder = function (root: TreeNode | null): number[] {
+ let res: number[] = [];
+ if (root === null) return res;
+ let queue: TreeNode[] = [root];
+ while (queue.length) {
+ let n: number = queue.length;
+ let temp: number[] = [];
+ for (let i: number = 0; i < n; i++) {
+ let node: TreeNode = queue.shift();
+ temp.push(node.val);
+ node.left && queue.push(node.left);
+ node.right && queue.push(node.right);
+ }
+ res.push(temp);
+ }
+ return res;
+};
+```
+
+### 二叉树深度
+
+```typescript
+var getDepth = function (node: TreNode | null): number {
+ if (node === null) return 0;
+ return 1 + Math.max(getDepth(node.left), getDepth(node.right));
+}
+```
+
+### 二叉树节点数量
+
+```typescript
+var countNodes = function (root: TreeNode | null): number {
+ if (root === null) return 0;
+ return 1 + countNodes(root.left) + countNodes(root.right);
+}
+```
+
+## 回溯算法
+
+```typescript
+function backtracking(参数) {
+ if (终止条件) {
+ 存放结果;
+ return;
+ }
+
+ for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
+ 处理节点;
+ backtracking(路径,选择列表); // 递归
+ 回溯,撤销处理结果
+ }
+}
+
+```
+
+## 并查集
+
+```typescript
+ let n: number = 1005; // 根据题意而定
+ let father: number[] = new Array(n).fill(0);
+
+ // 并查集初始化
+ function init () {
+ for (int i: number = 0; i < n; ++i) {
+ father[i] = i;
+ }
+ }
+ // 并查集里寻根的过程
+ function find (u: number): number {
+ return u === father[u] ? u : father[u] = find(father[u]);
+ }
+ // 将v->u 这条边加入并查集
+ function join(u: number, v: number) {
+ u = find(u);
+ v = find(v);
+ if (u === v) return ;
+ father[v] = u;
+ }
+ // 判断 u 和 v是否找到同一个根
+ function same(u: number, v: number): boolean {
+ u = find(u);
+ v = find(v);
+ return u === v;
+ }
+```
+
Java:
diff --git a/problems/背包总结篇.md b/problems/背包总结篇.md
index f80bcf29..a7852de3 100644
--- a/problems/背包总结篇.md
+++ b/problems/背包总结篇.md
@@ -82,6 +82,7 @@
## 总结
+
**这篇背包问题总结篇是对背包问题的高度概括,讲最关键的两部:递推公式和遍历顺序,结合力扣上的题目全都抽象出来了**。
**而且每一个点,我都给出了对应的力扣题目**。
@@ -90,7 +91,11 @@
如果把我本篇总结出来的内容都掌握的话,可以说对背包问题理解的就很深刻了,用来对付面试中的背包问题绰绰有余!
+背包问题总结:
+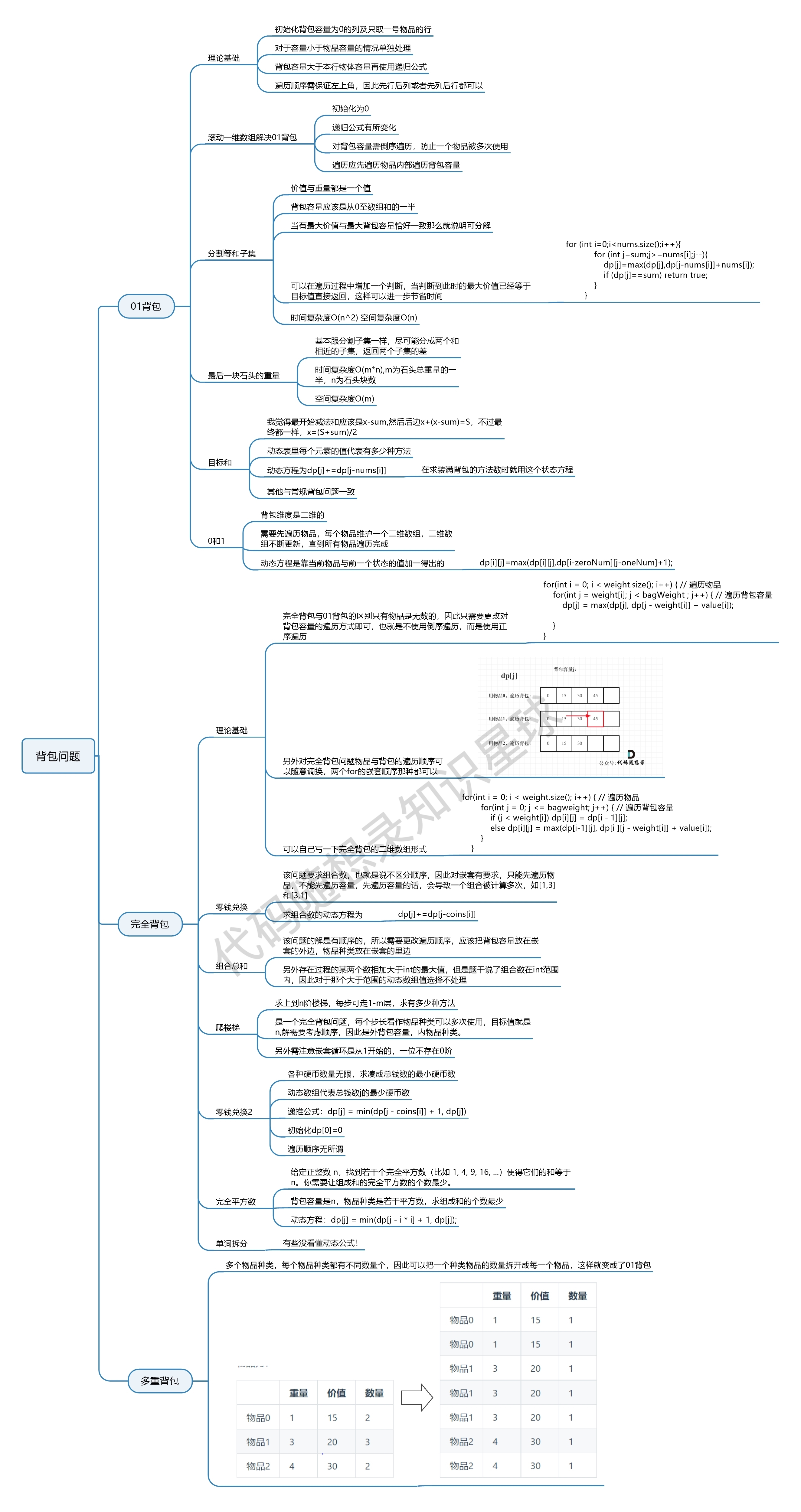
+
+这个图是 [代码随想录知识星球](https://programmercarl.com/other/kstar.html) 成员:[海螺人](https://wx.zsxq.com/dweb2/index/footprint/844412858822412),所画结的非常好,分享给大家。
diff --git a/problems/背包理论基础01背包-1.md b/problems/背包理论基础01背包-1.md
index 4367aff9..fe940b4c 100644
--- a/problems/背包理论基础01背包-1.md
+++ b/problems/背包理论基础01背包-1.md
@@ -3,11 +3,12 @@
+在pa指向链表A时,即pa为空之前,pa经过链表A不相交部分和相交部分,走过的长度为a+c;
+pa指向链表B后,在移动相交节点之前经过链表B不相交部分,走过的长度为b,总合为a+c+b。
+同理,pb走过长度的总合为b+c+a。二者相等,即pa与pb可同时到达相交起始节点。
+该方法可避免计算具体链表长度。
+```cpp
+class Solution {
+public:
+ ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
+ //链表为空时,返回空指针
+ if(headA == nullptr || headB == nullptr) return nullptr;
+ ListNode* pa = headA;
+ ListNode* pb = headB;
+ //pa与pb在遍历过全部节点后,同时指向结尾空节点时退出循环
+ while(pa != nullptr || pb != nullptr){
+ //pa为空时,将pa指向headB
+ if(pa == nullptr){
+ pa = headB;
+ }
+ //pa为空时,将pb指向headA
+ if(pb == nullptr){
+ pb = headA;
+ }
+ //pa与pb相等时,返回相交起始节点
+ if(pa == pb){
+ return pa;
+ }
+ pa = pa->next;
+ pb = pb->next;
+ }
+ return nullptr;
+ }
+};
+```
diff --git a/problems/面试题02.07.链表相交.md b/problems/面试题02.07.链表相交.md
index e8198aa0..2e7226de 100644
--- a/problems/面试题02.07.链表相交.md
+++ b/problems/面试题02.07.链表相交.md
@@ -224,12 +224,14 @@ var getIntersectionNode = function(headA, headB) {
lenA = getListLen(headA),
lenB = getListLen(headB);
if(lenA < lenB) {
+ // 下面交换变量注意加 “分号” ,两个数组交换变量在同一个作用域下时
+ // 如果不加分号,下面两条代码等同于一条代码: [curA, curB] = [lenB, lenA]
[curA, curB] = [curB, curA];
[lenA, lenB] = [lenB, lenA];
}
let i = lenA - lenB;
while(i-- > 0) {
- curA = curA.next
+ curA = curA.next;
}
while(curA && curA !== curB) {
curA = curA.next;
@@ -239,6 +241,43 @@ var getIntersectionNode = function(headA, headB) {
};
```
+TypeScript:
+
+```typescript
+function getIntersectionNode(headA: ListNode | null, headB: ListNode | null): ListNode | null {
+ let sizeA: number = 0,
+ sizeB: number = 0;
+ let curA: ListNode | null = headA,
+ curB: ListNode | null = headB;
+ while (curA) {
+ sizeA++;
+ curA = curA.next;
+ }
+ while (curB) {
+ sizeB++;
+ curB = curB.next;
+ }
+ curA = headA;
+ curB = headB;
+ if (sizeA < sizeB) {
+ [sizeA, sizeB] = [sizeB, sizeA];
+ [curA, curB] = [curB, curA];
+ }
+ let gap = sizeA - sizeB;
+ while (gap-- && curA) {
+ curA = curA.next;
+ }
+ while (curA && curB) {
+ if (curA === curB) {
+ return curA;
+ }
+ curA = curA.next;
+ curB = curB.next;
+ }
+ return null;
+};
+```
+
C:
```c