参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!
# 99. 岛屿数量
[卡码网题目链接(ACM模式)](https://kamacoder.com/problempage.php?pid=1171)
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
```
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
```
输出示例:
3
提示信息
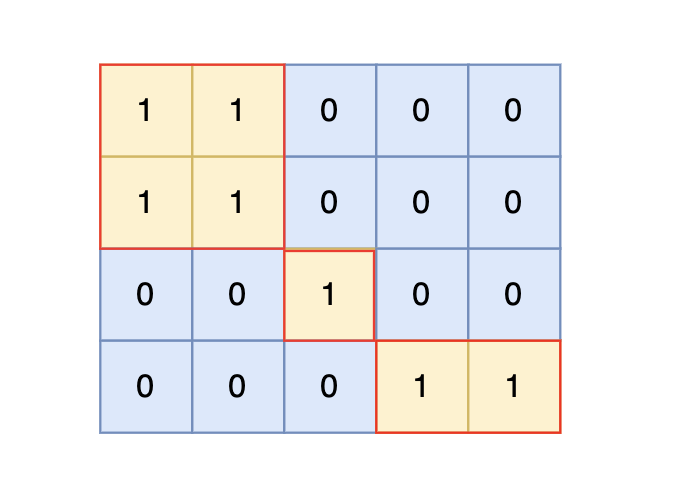
根据测试案例中所展示,岛屿数量共有 3 个,所以输出 3。
数据范围:
* 1 <= N, M <= 50
## 思路
注意题目中每座岛屿只能由**水平方向和/或竖直方向上**相邻的陆地连接形成。
也就是说斜角度链接是不算了, 例如示例二,是三个岛屿,如图:

这道题题目是 DFS,BFS,并查集,基础题目。
本题思路:遇到一个没有遍历过的节点陆地,计数器就加一,然后把该节点陆地所能遍历到的陆地都标记上。
再遇到标记过的陆地节点和海洋节点的时候直接跳过。 这样计数器就是最终岛屿的数量。
那么如果把节点陆地所能遍历到的陆地都标记上呢,就可以使用 DFS,BFS或者并查集。
### 广度优先搜索
如果不熟悉广搜,建议先看 [广搜理论基础](./图论广搜理论基础.md)。
不少同学用广搜做这道题目的时候,超时了。 这里有一个广搜中很重要的细节:
根本原因是**只要 加入队列就代表 走过,就需要标记,而不是从队列拿出来的时候再去标记走过**。
很多同学可能感觉这有区别吗?
如果从队列拿出节点,再去标记这个节点走过,就会发生下图所示的结果,会导致很多节点重复加入队列。
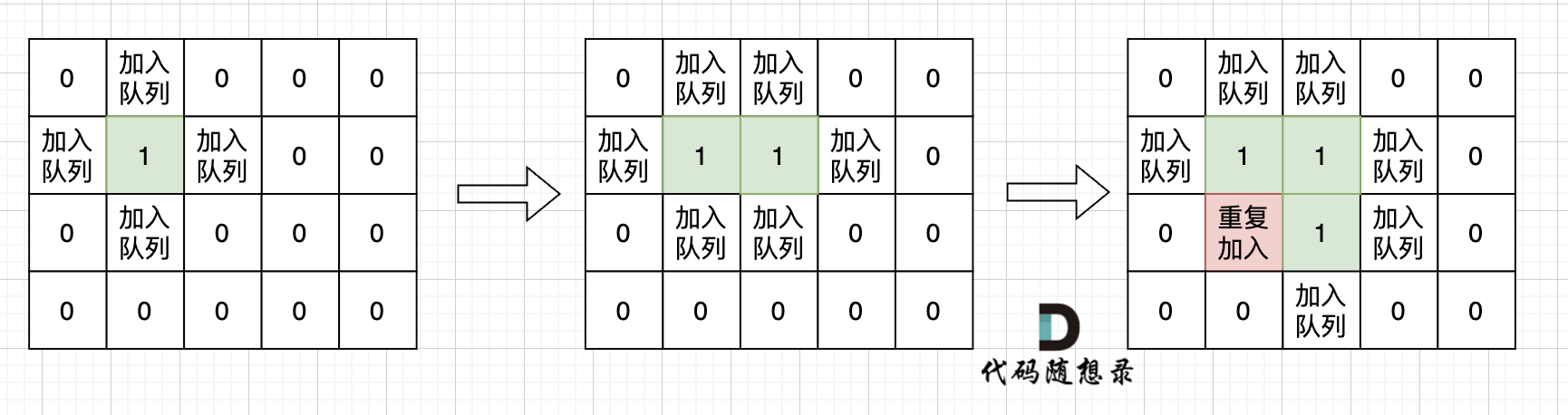
超时写法 (从队列中取出节点再标记,注意代码注释的地方)
```CPP
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector>& grid, vector>& visited, int x, int y) {
queue> que;
que.push({x, y});
while(!que.empty()) {
pair cur = que.front(); que.pop();
int curx = cur.first;
int cury = cur.second;
visited[curx][cury] = true; // 从队列中取出在标记走过
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') {
que.push({nextx, nexty});
}
}
}
}
```
加入队列 就代表走过,立刻标记,正确写法: (注意代码注释的地方)
```CPP
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(vector>& grid, vector>& visited, int x, int y) {
queue> que;
que.push({x, y});
visited[x][y] = true; // 只要加入队列,立刻标记
while(!que.empty()) {
pair cur = que.front(); que.pop();
int curx = cur.first;
int cury = cur.second;
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == '1') {
que.push({nextx, nexty});
visited[nextx][nexty] = true; // 只要加入队列立刻标记
}
}
}
}
```
以上两个版本其实,其实只有细微区别,就是 `visited[x][y] = true;` 放在的地方,这取决于我们对 代码中队列的定义,队列中的节点就表示已经走过的节点。 **所以只要加入队列,立即标记该节点走过**。
本题完整广搜代码:
```CPP
#include
#include
#include
using namespace std;
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 四个方向
void bfs(const vector>& grid, vector>& visited, int x, int y) {
queue> que;
que.push({x, y});
visited[x][y] = true; // 只要加入队列,立刻标记
while(!que.empty()) {
pair cur = que.front(); que.pop();
int curx = cur.first;
int cury = cur.second;
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 越界了,直接跳过
if (!visited[nextx][nexty] && grid[nextx][nexty] == 1) {
que.push({nextx, nexty});
visited[nextx][nexty] = true; // 只要加入队列立刻标记
}
}
}
}
int main() {
int n, m;
cin >> n >> m;
vector> grid(n, vector(m, 0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
cin >> grid[i][j];
}
}
vector> visited(n, vector(m, false));
int result = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (!visited[i][j] && grid[i][j] == 1) {
result++; // 遇到没访问过的陆地,+1
bfs(grid, visited, i, j); // 将与其链接的陆地都标记上 true
}
}
}
cout << result << endl;
}
```
## 其他语言版本
### Java
### Python
### Go
### Rust
### Javascript
### TypeScript
### PhP
### Swift
### Scala
### C#
### Dart
### C