
欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
## 647. 回文子串 题目链接:https://leetcode-cn.com/problems/palindromic-substrings/ 给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。 具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被视作不同的子串。 示例 1: 输入:"abc" 输出:3 解释:三个回文子串: "a", "b", "c" 示例 2: 输入:"aaa" 输出:6 解释:6个回文子串: "a", "a", "a", "aa", "aa", "aaa" 提示: 输入的字符串长度不会超过 1000 。 ## 暴力解法 两层for循环,遍历区间起始位置和终止位置,然后判断这个区间是不是回文。 时间复杂度:O(n^3) ## 动态规划 动规五部曲: 1. 确定dp数组(dp table)以及下标的含义 布尔类型的dp[i][j]:表示区间范围[i,j] (注意是左闭右闭)的子串是否是回文子串,如果是dp[i][j]为true,否则为false。 2. 确定递推公式 在确定递推公式时,就要分析如下几种情况。 整体上是两种,就是s[i]与s[j]相等,s[i]与s[j]不相等这两种。 当s[i]与s[j]不相等,那没啥好说的了,dp[i][j]一定是false。 当s[i]与s[j]相等时,这就复杂一些了,有如下三种情况 * 情况一:下标i 与 j相同,同一个字符例如a,当然是回文子串 * 情况二:下标i 与 j相差为1,例如aa,也是文子串 * 情况三:下标:i 与 j相差大于1的时候,例如cabac,此时s[i]与s[j]已经相同了,我们看i到j区间是不是回文子串就看aba是不是回文就可以了,那么aba的区间就是 i+1 与 j-1区间,这个区间是不是回文就看dp[i + 1][j - 1]是否为true。 以上三种情况分析完了,那么递归公式如下: ```C++ if (s[i] == s[j]) { if (j - i <= 1) { // 情况一 和 情况二 result++; dp[i][j] = true; } else if (dp[i + 1][j - 1]) { // 情况三 result++; dp[i][j] = true; } } ``` result就是统计回文子串的数量。 注意这里我没有列出当s[i]与s[j]不相等的时候,因为在下面dp[i][j]初始化的时候,就初始为false。 3. dp数组如何初始化 dp[i][j]可以初始化为true么? 当然不行,怎能刚开始就全都匹配上了。 所以dp[i][j]初始化为false。 4. 确定遍历顺序 遍历顺序可有有点讲究了。 首先从递推公式中可以看出,情况三是根据dp[i + 1][j - 1]是否为true,在对dp[i][j]进行赋值true的。 dp[i + 1][j - 1] 在 dp[i][j]的左下角,如图: 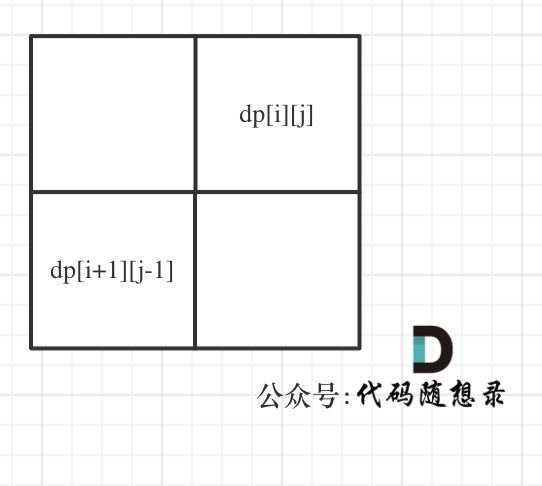 如果这矩阵是从上到下,从左到右遍历,那么会用到没有计算过的dp[i + 1][j - 1],也就是根据不确定是不是回文的区间[i+1,j-1],来判断了[i,j]是不是回文,那结果一定是不对的。 **所以一定要从下到上,从左到右遍历,这样保证dp[i + 1][j - 1]都是经过计算的**。 有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证dp[i + 1][j - 1]都是经过计算的。 代码如下: ```C++ for (int i = s.size() - 1; i >= 0; i--) { // 注意遍历顺序 for (int j = i; j < s.size(); j++) { if (s[i] == s[j]) { if (j - i <= 1) { // 情况一 和 情况二 result++; dp[i][j] = true; } else if (dp[i + 1][j - 1]) { // 情况三 result++; dp[i][j] = true; } } } } ``` 5. 举例推导dp数组 举例,输入:"aaa",dp[i][j]状态如下:  图中有6个true,所以就是有6个回文子串。 **注意因为dp[i][j]的定义,所以j一定是大于等于i的,那么在填充dp[i][j]的时候一定是只填充右上半部分**。 以上分析完毕,C++代码如下: ```C++ class Solution { public: int countSubstrings(string s) { vector