|
…
|
||
|---|---|---|
| .. | ||
| configs | ||
| datasets | ||
| losses | ||
| modeling | ||
| tasks | ||
| README.md | ||
| train.py | ||
README.md
Contextualized Spatial-Temporal Contrastive Learning with Self-Supervision
This repository contains the official implementation of Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision in TF2.
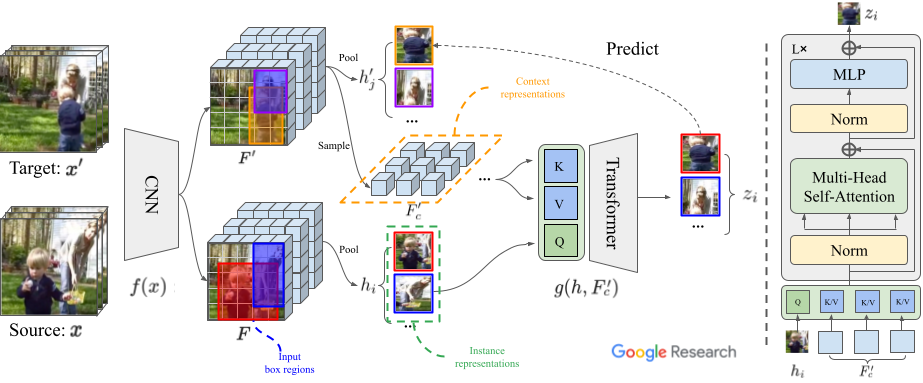
Description
Most of existing video-language pre-training methods focus on instance-level alignment between video clips and captions via global contrastive learning but neglect rich fine-grained local information, which is of importance to downstream tasks requiring temporal localization and semantic reasoning. In this work, we propose a simple yet effective video-language pre-training framework, namely G-ViLM, to learn discriminative spatiotemporal features. Two novel designs involving spatiotemporal grounding and temporal grouping promote learning local region-noun alignment and temporal-aware features simultaneously. Specifically, spatiotemporal grounding aggregates semantically similar video tokens and aligns them with noun phrases extracted from the caption to promote local region-noun correspondences. Moreover, temporal grouping leverages cut-and-paste to manually create temporal scene changes and then learns distinguishable features from different scenes. Comprehensive evaluations demonstrate that G-ViLM performs favorably against existing approaches on four representative downstream tasks, covering text-video retrieval, video question answering, video action recognition and temporal action localization. G-ViLM performs competitively on all evaluated tasks and in particular achieves R@10 of 65.1 on zero-shot MSR-VTT retrieval, over 9% higher than the state-of-the-art method.
Pre-trained Model Performance
All models are pre-trained from scratch with region_generator = RANDOM and context_length = 5 as described in the paper.
We report the mean average precision on AVA v2.2 and AVA-Kinetics validation set and precision/success rate on Object Tracking Benchmark 2015.
| Method | Parameters | Dataset | Pretrain Steps | AVA(mAP) | AVAK(mAP) | OTB(P/S) |
|---|---|---|---|---|---|---|
| CVRL | 31.7M | Kinetics-400 | 200k | 18.4% | 24.1% | 75.4/53.7 |
| ConST-CL | 31.7M | Kinetics-400 | 100k | 22.1% | 28.0% | 77.4/54.3 |
| ConST-CL | 31.7M | Kinetics-400 | 200k | 24.1% | 30.5% | 78.1/55.2 |
Citation
@inproceedings{yuan2022constcl,
title={Contexualized Spatio-Temporal Contrastive Learning with Self-Supervision},
author={Yuan, Liangzhe and Qian, Rui and Cui, Yin and Gong, Boqing and Schroff, Florian and Yang, Ming-Hsuan and Adam, Hartwig and Liu, Ting},
journal={CVPR},
year={2022}
}