* REFACTOR: Move personas into it's own module.
* WIP: Use personas for summarization
* Prioritize persona default LLM or fallback to newest one
* Simplify summarization strategy
* Keep ai_sumarization_model as a fallback
This feature update allows for continuing the conversation with Discobot Discoveries in an AI bot chat. After discoveries gives you a response to your search you can continue with the existing context.
This change moves all the personas code into its own module. We want to treat them as a building block features can built on top of, same as `Completions::Llm`.
The code to title a message was moved from `Bot` to `Playground`.
* DEV: refactor bot internals
This introduces a proper object for bot context, this makes
it simpler to improve context management as we go cause we
have a nice object to work with
Starts refactoring allowing for a single message to have
multiple uploads throughout
* transplant method to message builder
* chipping away at inline uploads
* image support is improved but not fully fixed yet
partially working in anthropic, still got quite a few dialects to go
* open ai and claude are now working
* Gemini is now working as well
* fix nova
* more dialects...
* fix ollama
* fix specs
* update artifact fixed
* more tests
* spam scanner
* pass more specs
* bunch of specs improved
* more bug fixes.
* all the rest of the tests are working
* improve tests coverage and ensure custom tools are aware of new context object
* tests are working, but we need more tests
* resolve merge conflict
* new preamble and expanded specs on ai tool
* remove concept of "standalone tools"
This is no longer needed, we can set custom raw, tool details are injected into tool calls
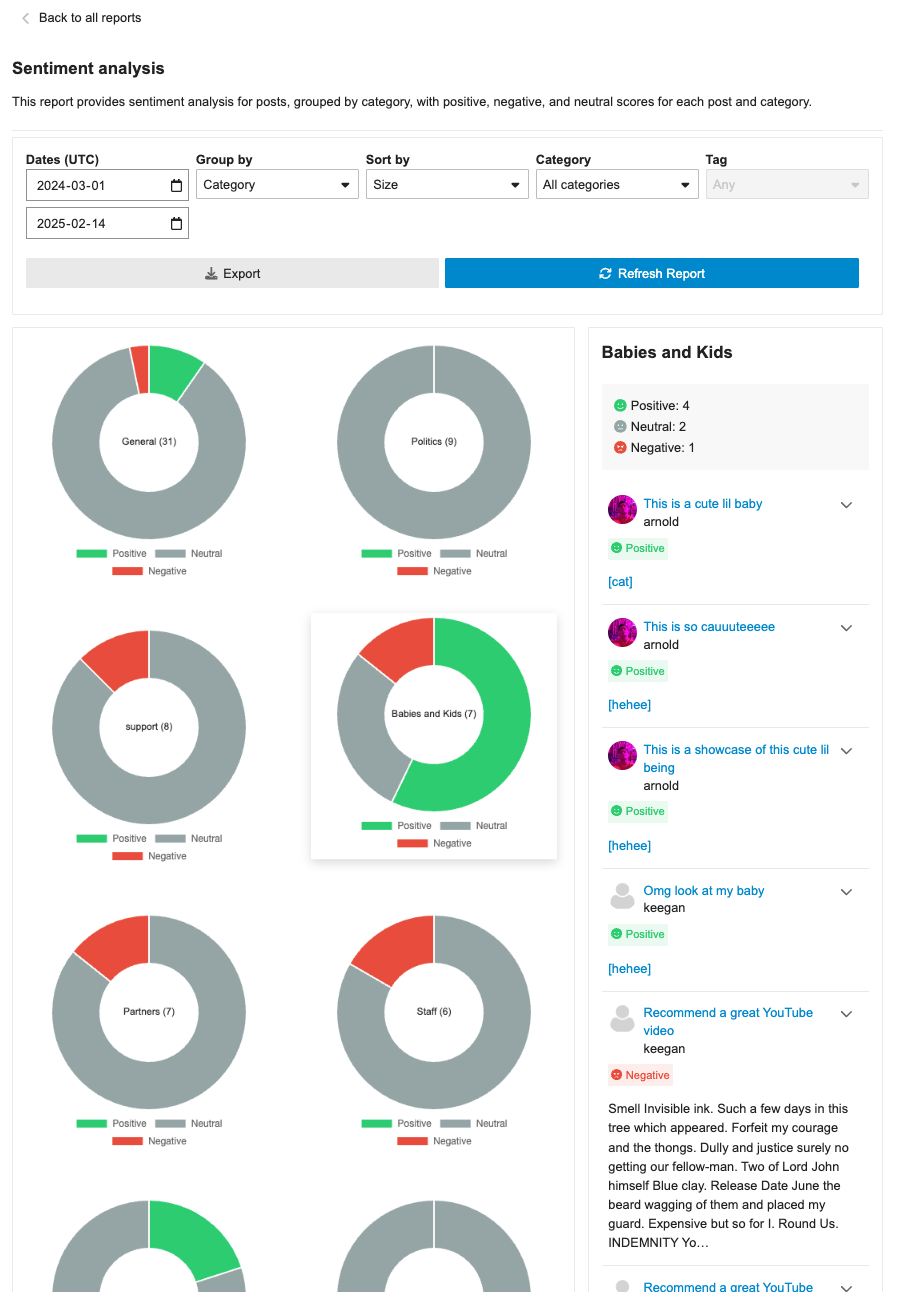
This PR ensures that the category badges are present in the sentiment analysis report. Since the core change in https://github.com/discourse/discourse/pull/31795, there was a regression in the post list drill-down where category badges were not being shown. This PR fixes that and also ensures icons/emojis are shown when categories make use of them. This PR also adds the category badge in the table list.
When editing a topic (instead of creating one) and using the
tag/category suggestion buttons. We want to use existing topic
embeddings instead of creating new ones.
**This PR includes a variety of updates to the Sentiment Analysis report:**
- [X] Conditionally showing sentiment reports based on `sentiment_enabled` setting
- [X] Sentiment reports should only be visible in sidebar if data is in the reports
- [X] Fix infinite loading of posts in drill down
- [x] Fix markdown emojis showing not showing as emoji representation
- [x] Drill down of posts should have URL
- [x] ~~Different doughnut sizing based on post count~~ [reverting and will address in follow-up (see: `/t/146786/47`)]
- [X] Hide non-functional export button
- [X] Sticky drill down filter nav
This update improves some of the UI around sentiment analysis reports:
1. Improve titles so it is above and truncated when long
2. Change doughnut to only show total count
3. Ensures sentiment posts have dates
4. Ensure expand post doesn't appear on short posts
* FEATURE: Experimental search results from an AI Persona.
When a user searches discourse, we'll send the query to an AI Persona to provide additional context and enrich the results. The feature depends on the user being a member of a group to which the persona has access.
* Update assets/stylesheets/common/ai-blinking-animation.scss
Co-authored-by: Keegan George <kgeorge13@gmail.com>
---------
Co-authored-by: Keegan George <kgeorge13@gmail.com>
## 🔍 Overview
This update adds a new report page at `admin/reports/sentiment_analysis` where admins can see a sentiment analysis report for the forum grouped by either category or tags.
## ➕ More details
The report can breakdown either category or tags into positive/negative/neutral sentiments based on the grouping (category/tag). Clicking on the doughnut visualization will bring up a post list of all the posts that were involved in that classification with further sentiment classifications by post.
The report can additionally be sorted in alphabetical order or by size, as well as be filtered by either category/tag based on the grouping.
## 👨🏽💻 Technical Details
The new admin report is registered via the pluginAPi with `api.registerReportModeComponent` to register the custom sentiment doughnut report. However, when each doughnut visualization is clicked, a new endpoint found at: `/discourse-ai/sentiment/posts` is fetched to showcase posts classified by sentiments based on the respective params.
## 📸 Screenshots
* FEATURE: Native PDF support
This amends it so we use PDF Reader gem to extract text from PDFs
* This means that our simple pdf eval passes at last
* fix spec
* skip test in CI
* test file support
* Update lib/utils/image_to_text.rb
Co-authored-by: Alan Guo Xiang Tan <gxtan1990@gmail.com>
* address pr comments
---------
Co-authored-by: Alan Guo Xiang Tan <gxtan1990@gmail.com>
This PR introduces several enhancements and refactorings to the AI Persona and RAG (Retrieval-Augmented Generation) functionalities within the discourse-ai plugin. Here's a breakdown of the changes:
**1. LLM Model Association for RAG and Personas:**
- **New Database Columns:** Adds `rag_llm_model_id` to both `ai_personas` and `ai_tools` tables. This allows specifying a dedicated LLM for RAG indexing, separate from the persona's primary LLM. Adds `default_llm_id` and `question_consolidator_llm_id` to `ai_personas`.
- **Migration:** Includes a migration (`20250210032345_migrate_persona_to_llm_model_id.rb`) to populate the new `default_llm_id` and `question_consolidator_llm_id` columns in `ai_personas` based on the existing `default_llm` and `question_consolidator_llm` string columns, and a post migration to remove the latter.
- **Model Changes:** The `AiPersona` and `AiTool` models now `belong_to` an `LlmModel` via `rag_llm_model_id`. The `LlmModel.proxy` method now accepts an `LlmModel` instance instead of just an identifier. `AiPersona` now has `default_llm_id` and `question_consolidator_llm_id` attributes.
- **UI Updates:** The AI Persona and AI Tool editors in the admin panel now allow selecting an LLM for RAG indexing (if PDF/image support is enabled). The RAG options component displays an LLM selector.
- **Serialization:** The serializers (`AiCustomToolSerializer`, `AiCustomToolListSerializer`, `LocalizedAiPersonaSerializer`) have been updated to include the new `rag_llm_model_id`, `default_llm_id` and `question_consolidator_llm_id` attributes.
**2. PDF and Image Support for RAG:**
- **Site Setting:** Introduces a new hidden site setting, `ai_rag_pdf_images_enabled`, to control whether PDF and image files can be indexed for RAG. This defaults to `false`.
- **File Upload Validation:** The `RagDocumentFragmentsController` now checks the `ai_rag_pdf_images_enabled` setting and allows PDF, PNG, JPG, and JPEG files if enabled. Error handling is included for cases where PDF/image indexing is attempted with the setting disabled.
- **PDF Processing:** Adds a new utility class, `DiscourseAi::Utils::PdfToImages`, which uses ImageMagick (`magick`) to convert PDF pages into individual PNG images. A maximum PDF size and conversion timeout are enforced.
- **Image Processing:** A new utility class, `DiscourseAi::Utils::ImageToText`, is included to handle OCR for the images and PDFs.
- **RAG Digestion Job:** The `DigestRagUpload` job now handles PDF and image uploads. It uses `PdfToImages` and `ImageToText` to extract text and create document fragments.
- **UI Updates:** The RAG uploader component now accepts PDF and image file types if `ai_rag_pdf_images_enabled` is true. The UI text is adjusted to indicate supported file types.
**3. Refactoring and Improvements:**
- **LLM Enumeration:** The `DiscourseAi::Configuration::LlmEnumerator` now provides a `values_for_serialization` method, which returns a simplified array of LLM data (id, name, vision_enabled) suitable for use in serializers. This avoids exposing unnecessary details to the frontend.
- **AI Helper:** The `AiHelper::Assistant` now takes optional `helper_llm` and `image_caption_llm` parameters in its constructor, allowing for greater flexibility.
- **Bot and Persona Updates:** Several updates were made across the codebase, changing the string based association to a LLM to the new model based.
- **Audit Logs:** The `DiscourseAi::Completions::Endpoints::Base` now formats raw request payloads as pretty JSON for easier auditing.
- **Eval Script:** An evaluation script is included.
**4. Testing:**
- The PR introduces a new eval system for LLMs, this allows us to test how functionality works across various LLM providers. This lives in `/evals`
* FEATURE: Tool name validation
- Add unique index to the name column of the ai_tools table
- correct our tests for AiToolController
- tool_name field which will be used to represent to LLM
- Add tool_name to Tools's presets
- Add duplicate tools validation for AiPersona
- Add unique constraint to the name column of the ai_tools table
* DEV: Validate duplicate tool_name between builin tools and custom tools
* lint
* chore: fix linting
* fix conlict mistakes
* chore: correct icon class
* chore: fix failed specs
* Add max_length to tool_name
* chore: correct the option name
* lintings
* fix lintings
### Why
This pull request fundamentally restructures how AI bots create and update web artifacts to address critical limitations in the previous approach:
1. **Improved Artifact Context for LLMs**: Previously, artifact creation and update tools included the *entire* artifact source code directly in the tool arguments. This overloaded the Language Model (LLM) with raw code, making it difficult for the LLM to maintain a clear understanding of the artifact's current state when applying changes. The LLM would struggle to differentiate between the base artifact and the requested modifications, leading to confusion and less effective updates.
2. **Reduced Token Usage and History Bloat**: Including the full artifact source code in every tool interaction was extremely token-inefficient. As conversations progressed, this redundant code in the history consumed a significant number of tokens unnecessarily. This not only increased costs but also diluted the context for the LLM with less relevant historical information.
3. **Enabling Updates for Large Artifacts**: The lack of a practical diff or targeted update mechanism made it nearly impossible to efficiently update larger web artifacts. Sending the entire source code for every minor change was both computationally expensive and prone to errors, effectively blocking the use of AI bots for meaningful modifications of complex artifacts.
**This pull request addresses these core issues by**:
* Introducing methods for the AI bot to explicitly *read* and understand the current state of an artifact.
* Implementing efficient update strategies that send *targeted* changes rather than the entire artifact source code.
* Providing options to control the level of artifact context included in LLM prompts, optimizing token usage.
### What
The main changes implemented in this PR to resolve the above issues are:
1. **`Read Artifact` Tool for Contextual Awareness**:
- A new `read_artifact` tool is introduced, enabling AI bots to fetch and process the current content of a web artifact from a given URL (local or external).
- This provides the LLM with a clear and up-to-date representation of the artifact's HTML, CSS, and JavaScript, improving its understanding of the base to be modified.
- By cloning local artifacts, it allows the bot to work with a fresh copy, further enhancing context and control.
2. **Refactored `Update Artifact` Tool with Efficient Strategies**:
- The `update_artifact` tool is redesigned to employ more efficient update strategies, minimizing token usage and improving update precision:
- **`diff` strategy**: Utilizes a search-and-replace diff algorithm to apply only the necessary, targeted changes to the artifact's code. This significantly reduces the amount of code sent to the LLM and focuses its attention on the specific modifications.
- **`full` strategy**: Provides the option to replace the entire content sections (HTML, CSS, JavaScript) when a complete rewrite is required.
- Tool options enhance the control over the update process:
- `editor_llm`: Allows selection of a specific LLM for artifact updates, potentially optimizing for code editing tasks.
- `update_algorithm`: Enables choosing between `diff` and `full` update strategies based on the nature of the required changes.
- `do_not_echo_artifact`: Defaults to true, and by *not* echoing the artifact in prompts, it further reduces token consumption in scenarios where the LLM might not need the full artifact context for every update step (though effectiveness might be slightly reduced in certain update scenarios).
3. **System and General Persona Tool Option Visibility and Customization**:
- Tool options, including those for system personas, are made visible and editable in the admin UI. This allows administrators to fine-tune the behavior of all personas and their tools, including setting specific LLMs or update algorithms. This was previously limited or hidden for system personas.
4. **Centralized and Improved Content Security Policy (CSP) Management**:
- The CSP for AI artifacts is consolidated and made more maintainable through the `ALLOWED_CDN_SOURCES` constant. This improves code organization and future updates to the allowed CDN list, while maintaining the existing security posture.
5. **Codebase Improvements**:
- Refactoring of diff utilities, introduction of strategy classes, enhanced error handling, new locales, and comprehensive testing all contribute to a more robust, efficient, and maintainable artifact management system.
By addressing the issues of LLM context confusion, token inefficiency, and the limitations of updating large artifacts, this pull request significantly improves the practicality and effectiveness of AI bots in managing web artifacts within Discourse.
We have a flag to signal we are shortening the embeddings of a model.
Only used in Open AI's text-embedding-3-*, but we plan to use it for other services.
* Use AR model for embeddings features
* endpoints
* Embeddings CRUD UI
* Add presets. Hide a couple more settings
* system specs
* Seed embedding definition from old settings
* Generate search bit index on the fly. cleanup orphaned data
* support for seeded models
* Fix run test for new embedding
* fix selected model not set correctly
Adds a comprehensive quota management system for LLM models that allows:
- Setting per-group (applied per user in the group) token and usage limits with configurable durations
- Tracking and enforcing token/usage limits across user groups
- Quota reset periods (hourly, daily, weekly, or custom)
- Admin UI for managing quotas with real-time updates
This system provides granular control over LLM API usage by allowing admins
to define limits on both total tokens and number of requests per group.
Supports multiple concurrent quotas per model and automatically handles
quota resets.
Co-authored-by: Keegan George <kgeorge13@gmail.com>
Disabling streaming is required for models such o1 that do not have streaming
enabled yet
It is good to carry this feature around in case various apis decide not to support streaming endpoints and Discourse AI can continue to work just as it did before.
Also: fixes issue where sharing artifacts would miss viewport leading to tiny artifacts on mobile
This update adds some structure for handling errors in the spam config while also handling a specific error related to the spam scanning user not being an admin account.
The seeded LLM setting: `SiteSetting.ai_spam_detection_model_allowed_seeded_models` returns a _string_ with IDs separated by pipes. running `_map` on it will return an array with strings. We were previously checking for the id with custom prefix identifier, but instead we should be checking the stringified ID.
In this PR, we added functionality to hide the admin header for edit/new actions - https://github.com/discourse/discourse/pull/30175
To make it work properly, we have to rename `show` to `edit` which is also a more accurate name.
This introduces a comprehensive spam detection system that uses LLM models
to automatically identify and flag potential spam posts. The system is
designed to be both powerful and configurable while preventing false positives.
Key Features:
* Automatically scans first 3 posts from new users (TL0/TL1)
* Creates dedicated AI flagging user to distinguish from system flags
* Tracks false positives/negatives for quality monitoring
* Supports custom instructions to fine-tune detection
* Includes test interface for trying detection on any post
Technical Implementation:
* New database tables:
- ai_spam_logs: Stores scan history and results
- ai_moderation_settings: Stores LLM config and custom instructions
* Rate limiting and safeguards:
- Minimum 10-minute delay between rescans
- Only scans significant edits (>10 char difference)
- Maximum 3 scans per post
- 24-hour maximum age for scannable posts
* Admin UI features:
- Real-time testing capabilities
- 7-day statistics dashboard
- Configurable LLM model selection
- Custom instruction support
Security and Performance:
* Respects trust levels - only scans TL0/TL1 users
* Skips private messages entirely
* Stops scanning users after 3 successful public posts
* Includes comprehensive test coverage
* Maintains audit log of all scan attempts
---------
Co-authored-by: Keegan George <kgeorge13@gmail.com>
Co-authored-by: Martin Brennan <martin@discourse.org>
* UX: Improve rough edges of AI usage page
* Ensure all text uses I18n
* Change from <button> usage to <DButton>
* Use <AdminConfigAreaCard> in place of custom card styles
* Format numbers nicely using our number format helper,
show full values on hover using title attr
* Ensure 0 is always shown for counters, instead of being blank
* FEATURE: Load usage data after page load
Use ConditionalLoadingSpinner to hide load of usage
data, this prevents us hanging on page load with a white
screen.
* UX: Split users table, and add empty placeholders and page subheader
* DEV: Test fix
Add support for versioned artifacts with improved diff handling
* Add versioned artifacts support allowing artifacts to be updated and tracked
- New `ai_artifact_versions` table to store version history
- Support for updating artifacts through a new `UpdateArtifact` tool
- Add version-aware artifact rendering in posts
- Include change descriptions for version tracking
* Enhance artifact rendering and security
- Add support for module-type scripts and external JS dependencies
- Expand CSP to allow trusted CDN sources (unpkg, cdnjs, jsdelivr, googleapis)
- Improve JavaScript handling in artifacts
* Implement robust diff handling system (this is dormant but ready to use once LLMs catch up)
- Add new DiffUtils module for applying changes to artifacts
- Support for unified diff format with multiple hunks
- Intelligent handling of whitespace and line endings
- Comprehensive error handling for diff operations
* Update routes and UI components
- Add versioned artifact routes
- Update markdown processing for versioned artifacts
Also
- Tweaks summary prompt
- Improves upload support in custom tool to also provide urls
- Added a new admin interface to track AI usage metrics, including tokens, features, and models.
- Introduced a new route `/admin/plugins/discourse-ai/ai-usage` and supporting API endpoint in `AiUsageController`.
- Implemented `AiUsageSerializer` for structuring AI usage data.
- Integrated CSS stylings for charts and tables under `stylesheets/modules/llms/common/usage.scss`.
- Enhanced backend with `AiApiAuditLog` model changes: added `cached_tokens` column (implemented with OpenAI for now) with relevant DB migration and indexing.
- Created `Report` module for efficient aggregation and filtering of AI usage metrics.
- Updated AI Bot title generation logic to log correctly to user vs bot
- Extended test coverage for the new tracking features, ensuring data consistency and access controls.
* FIX: automatically bust cache for share ai assets
CDNs can be configured to strip query params in Discourse
hosting. This is generally safe, but in this case we had
no way of busting the cache using the path.
New design properly caches and properly breaks busts the
cache if asset changes so we don't need to worry about versions
* one day I will set up conditional lint on save :)
1. Keep source in a "details" block after rendered so it does
not overwhelm users
2. Ensure artifacts are never indexed by robots
3. Cache break our CSS that changed recently
It's important that artifacts are never given 'same origin' access to the forum domain, so that they cannot access cookies, or make authenticated HTTP requests. So even when visiting the URL directly, we need to wrap them in a sandboxed iframe.
This is a significant PR that introduces AI Artifacts functionality to the discourse-ai plugin along with several other improvements. Here are the key changes:
1. AI Artifacts System:
- Adds a new `AiArtifact` model and database migration
- Allows creation of web artifacts with HTML, CSS, and JavaScript content
- Introduces security settings (`strict`, `lax`, `disabled`) for controlling artifact execution
- Implements artifact rendering in iframes with sandbox protection
- New `CreateArtifact` tool for AI to generate interactive content
2. Tool System Improvements:
- Adds support for partial tool calls, allowing incremental updates during generation
- Better handling of tool call states and progress tracking
- Improved XML tool processing with CDATA support
- Fixes for tool parameter handling and duplicate invocations
3. LLM Provider Updates:
- Updates for Anthropic Claude models with correct token limits
- Adds support for native/XML tool modes in Gemini integration
- Adds new model configurations including Llama 3.1 models
- Improvements to streaming response handling
4. UI Enhancements:
- New artifact viewer component with expand/collapse functionality
- Security controls for artifact execution (click-to-run in strict mode)
- Improved dialog and response handling
- Better error management for tool execution
5. Security Improvements:
- Sandbox controls for artifact execution
- Public/private artifact sharing controls
- Security settings to control artifact behavior
- CSP and frame-options handling for artifacts
6. Technical Improvements:
- Better post streaming implementation
- Improved error handling in completions
- Better memory management for partial tool calls
- Enhanced testing coverage
7. Configuration:
- New site settings for artifact security
- Extended LLM model configurations
- Additional tool configuration options
This PR significantly enhances the plugin's capabilities for generating and displaying interactive content while maintaining security and providing flexible configuration options for administrators.
This re-implements tool support in DiscourseAi::Completions::Llm #generate
Previously tool support was always returned via XML and it would be the responsibility of the caller to parse XML
New implementation has the endpoints return ToolCall objects.
Additionally this simplifies the Llm endpoint interface and gives it more clarity. Llms must implement
decode, decode_chunk (for streaming)
It is the implementers responsibility to figure out how to decode chunks, base no longer implements. To make this easy we ship a flexible json decoder which is easy to wire up.
Also (new)
Better debugging for PMs, we now have a next / previous button to see all the Llm messages associated with a PM
Token accounting is fixed for vllm (we were not correctly counting tokens)
The custom field "discourse_ai_bypass_ai_reply" was added so
we can signal the post created hook to bypass replying even
if it thinks it should.
Otherwise there are cases where we double answer user questions
leading to much confusion.
This also slightly refactors code making the controller smaller
The new `/admin/plugins/discourse-ai/ai-personas/stream-reply.json` was added.
This endpoint streams data direct from a persona and can be used
to access a persona from remote systems leaving a paper trail in
PMs about the conversation that happened
This endpoint is only accessible to admins.
---------
Co-authored-by: Gabriel Grubba <70247653+Grubba27@users.noreply.github.com>
Co-authored-by: Keegan George <kgeorge13@gmail.com>
* FIX/REFACTOR: FoldContent revamp
We hit a snag with our hot topic gist strategy: the regex we used to split the content didn't work, so we cannot send the original post separately. This was important for letting the model focus on what's new in the topic.
The algorithm doesn’t give us full control over how prompts are written, and figuring out how to format the content isn't straightforward. This means we're having to use more complicated workarounds, like regex.
To tackle this, I'm suggesting we simplify the approach a bit. Let's focus on summarizing as much as we can upfront, then gradually add new content until there's nothing left to summarize.
Also, the "extend" part is mostly for models with small context windows, which shouldn't pose a problem 99% of the time with the content volume we're dealing with.
* Fix fold docs
* Use #shift instead of #pop to get the first elem, not the last
This changeset contains 4 fixes:
1. We were allowing running tests on unsaved tools,
this is problematic cause uploads are not yet associated or indexed
leading to confusing results. We now only show the test button when
tool is saved.
2. We were not properly scoping rag document fragements, this
meant that personas and ai tools could get results from other
unrelated tools, just to be filtered out later
3. index.search showed options as "optional" but implementation
required the second option
4. When testing tools searching through document fragments was
not working at all cause we did not properly load the tool
This changeset:
1. Corrects some issues with "force_default_llm" not applying
2. Expands the LLM list page to show LLM usage
3. Clarifies better what "enabling a bot" on an llm means (you get it in the selector)
Splits persona permissions so you can allow a persona on:
- chat dms
- personal messages
- topic mentions
- chat channels
(any combination is allowed)
Previously we did not have this flexibility.
Additionally, adds the ability to "tether" a language model to a persona so it will always be used by the persona. This allows people to use a cheaper language model for one group of people and more expensive one for other people
This introduces another configuration that allows operators to
limit the amount of interactions with forced tool usage.
Forced tools are very handy in initial llm interactions, but as
conversation progresses they can hinder by slowing down stuff
and adding confusion.
This adds chain halting (ability to terminate llm chain in a tool)
and the ability to create uploads in a tool
Together this lets us integrate custom image generators into a
custom tool.