8.1 KiB
| title | keywords | description |
|---|---|---|
| Get Started, Part 5: Stacks | stack, data, persist, dependencies, redis, storage, volume, port | Learn how to create a multi-container application that uses all the machines in a cluster. |
{% include_relative nav.html selected="5" %}
Prerequisites
-
Read the orientation in Part 1.
-
Learn how to create containers in Part 2.
-
Make sure you have pushed the container you created to a registry, as instructed; we'll be using it here.
-
Ensure your image is working by running this and visiting
http://localhost/(slotting in your info forusername,repo, andtag):docker run -p 80:80 username/repo:tag -
Have a copy of your
docker-compose.ymlfrom Part 3 handy. -
Have the swarm you created in part 4 running and ready.
Introduction
In part 4, you learned how to set up a swarm, which is a cluster of machines running Docker, and deployed an application to it, with containers running in concert on multiple machines.
Here in part 5, you'll reach the top of the hierarchy of distributed applications: the stack. A stack is a group of interrelated services that share dependencies, and can be orchestrated and scaled together. A single stack is capable of defining and coordinating the functionality of an entire application (though very complex applications may want to use multiple stacks).
Some good news is, you have technically been working with stacks since part 3,
when you created a Compose file and used docker stack deploy. But that was a
single service stack running on a single host, which is not usually what takes
place in production. Here, you're going to take what you've learned and make
multiple services relate to each other, and run them on multiple machines.
This is the home stretch, so congratulate yourself!
Adding a new service and redeploying.
It's easy to add services to our docker-compose.yml file. First, let's add
a free visualizer service that lets us look at how our swarm is scheduling
containers. Open up docker-compose.yml in an editor and replace its contents
with the following:
version: "3"
services:
web:
image: username/repo:tag
deploy:
replicas: 5
restart_policy:
condition: on-failure
resources:
limits:
cpus: "0.1"
memory: 50M
ports:
- "80:80"
networks:
- webnet
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager]
networks:
- webnet
networks:
webnet:
The only thing new here is the peer service to web, named visualizer. You'll
see two new things here: a volumes key, giving the visualizer access to the
host's socket file for Docker, and a placement key, ensuring that this service
only ever runs on a swarm manager -- never a worker. That's because this
container, built from an open source project created by
Docker, displays Docker
services running on a swarm in a diagram.
We'll talk more about placement constraints and volumes in a moment. But for
now, copy this new docker-compose.yml file to the swarm manager, myvm1:
docker-machine scp docker-compose.yml myvm1:~
Now just re-run the docker stack deploy command on the manager, and whatever
services need updating will be updated:
$ docker-machine ssh myvm1 "docker stack deploy -c docker-compose.yml getstartedlab"
Updating service getstartedlab_web (id: angi1bf5e4to03qu9f93trnxm)
Updating service getstartedlab_visualizer (id: l9mnwkeq2jiononb5ihz9u7a4)
You saw in the Compose file that visualizer runs on port 8080. Get the IP
address of the one of your nodes by running docker-machine ls. Go to either IP
address @ port 8080 and you will see the visualizer running:
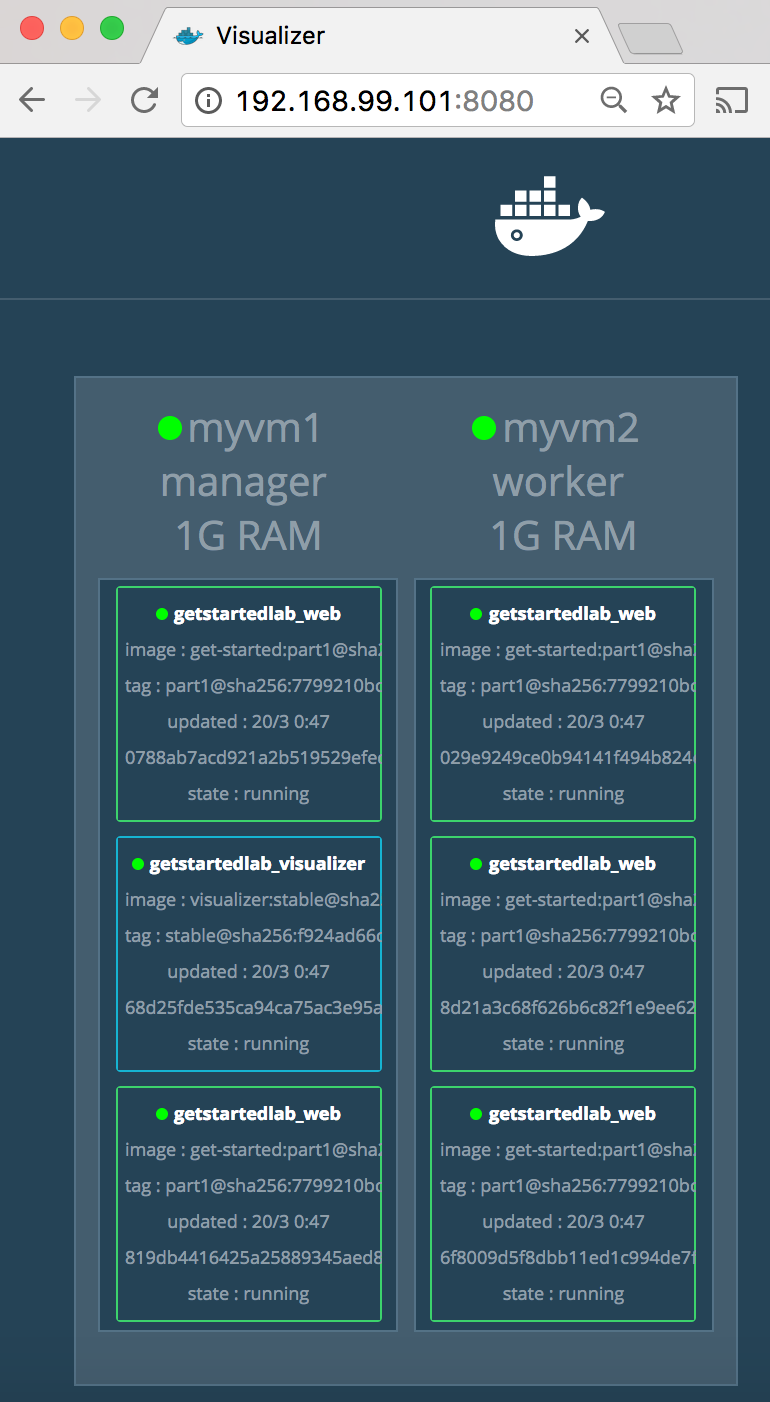
The single copy of visualizer is running on the manager as you expect, and the
five instances of web are spread out across the swarm. You can corroborate
this visualization by running docker stack ps <stack>:
docker-machine ssh myvm1 "docker stack ps getstartedlab"
The visualizer is a standalone service that can run in any app that includes it in the stack. It doesn't depend on anything else. Now let's create a service that does have a dependency: the Redis service that will provide a visitor counter.
Persisting data
Go through the same workflow once more. Save this new docker-compose.yml file,
which finally adds a Redis service.
version: "3"
services:
web:
image: username/repo:tag
deploy:
replicas: 5
restart_policy:
condition: on-failure
resources:
limits:
cpus: "0.1"
memory: 50M
ports:
- "80:80"
networks:
- webnet
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager]
networks:
- webnet
redis:
image: redis
ports:
- "6379:6379"
volumes:
- ./data:/data
deploy:
placement:
constraints: [node.role == manager]
networks:
- webnet
networks:
webnet:
Redis has an official image in the Docker library and has been granted the short
image name of just redis, so no username/repo notation here. The Redis
port, 6379, has been pre-configured by Redis to be exposed from the container to
the host, and here in our Compose file we expose it from the host to the world,
so you can actually enter the IP for any of your nodes into Redis Desktop
Manager and manage this Redis instance, if you so choose.
Most importantly, there are a couple of things in the redis specification that
make data persist between deployments of this stack:
redisalways runs on the manager, so it's always using the same filesystem.redisaccesses an arbitrary directory in the host's file system as/datainside the container, which is where Redis stores data.
Together, this is creating a "source of truth" in your host's physical
filesystem for the Redis data. Without this, Redis would store its data in
/data inside the container's filesystem, which would get wiped out if that
container were ever redeployed.
This source of truth has two components:
- The placement constraint you put on the Redis service, ensuring that it always uses the same host.
- The volume you created that lets the container access
./data(on the host) as/data(inside the Redis container). While containers come and go, the files stored on./dataon the specified host will persist, enabling continuity.
To deploy your new Redis-using stack, create ./data on the manager, copy over
the new docker-compose.yml file with docker-machine scp, and run
docker stack deploy one more time.
$ docker-machine ssh myvm1 "mkdir ./data"
$ docker-machine scp docker-compose.yml myvm1:~
$ docker-machine ssh myvm1 "docker stack deploy -c docker-compose.yml getstartedlab"
Check the results on http://localhost and you'll see that a visitor counter is now live and storing information on Redis.
On to Part 6 >>{: class="button outline-btn" style="margin-bottom: 30px"}
Recap (optional)
Here's a terminal recording of what was covered on this page:
You learned that stacks are inter-related services all running in concert, and that -- surprise! -- you've been using stacks since part three of this tutorial. You learned that to add more services to your stack, you insert them in your Compose file. Finally, you learned that by using a combination of placement constraints and volumes you can create a permanent home for persisting data, so that your app's data survives when the container is torn down and redeployed.