mirror of https://github.com/fluxcd/flagger.git
354 lines
12 KiB
Markdown
354 lines
12 KiB
Markdown
# Canary Deployments with Helm Charts and GitOps
|
|
|
|
This guide shows you how to package a web app into a Helm chart, trigger canary deployments on Helm upgrade
|
|
and automate the chart release process with Weave Flux.
|
|
|
|
### Packaging
|
|
|
|
You'll be using the [podinfo](https://github.com/stefanprodan/k8s-podinfo) chart.
|
|
This chart packages a web app made with Go, it's configuration, a horizontal pod autoscaler (HPA)
|
|
and the canary configuration file.
|
|
|
|
```
|
|
├── Chart.yaml
|
|
├── README.md
|
|
├── templates
|
|
│ ├── NOTES.txt
|
|
│ ├── _helpers.tpl
|
|
│ ├── canary.yaml
|
|
│ ├── configmap.yaml
|
|
│ ├── deployment.yaml
|
|
│ └── hpa.yaml
|
|
└── values.yaml
|
|
```
|
|
|
|
You can find the chart source [here](https://github.com/stefanprodan/flagger/tree/master/charts/podinfo).
|
|
|
|
### Install
|
|
|
|
Create a test namespace with Istio sidecar injection enabled:
|
|
|
|
```bash
|
|
export REPO=https://raw.githubusercontent.com/stefanprodan/flagger/master
|
|
|
|
kubectl apply -f ${REPO}/artifacts/namespaces/test.yaml
|
|
```
|
|
|
|
Add Flagger Helm repository:
|
|
|
|
```bash
|
|
helm repo add flagger https://flagger.app
|
|
```
|
|
|
|
Install podinfo with the release name `frontend` (replace `example.com` with your own domain):
|
|
|
|
```bash
|
|
helm upgrade -i frontend flagger/podinfo \
|
|
--namespace test \
|
|
--set nameOverride=frontend \
|
|
--set backend=http://backend.test:9898/echo \
|
|
--set canary.enabled=true \
|
|
--set canary.istioIngress.enabled=true \
|
|
--set canary.istioIngress.gateway=public-gateway.istio-system.svc.cluster.local \
|
|
--set canary.istioIngress.host=frontend.istio.example.com
|
|
```
|
|
|
|
Flagger takes a Kubernetes deployment and a horizontal pod autoscaler (HPA),
|
|
then creates a series of objects (Kubernetes deployments, ClusterIP services and Istio virtual services).
|
|
These objects expose the application on the mesh and drive the canary analysis and promotion.
|
|
|
|
```bash
|
|
# generated by Helm
|
|
configmap/frontend
|
|
deployment.apps/frontend
|
|
horizontalpodautoscaler.autoscaling/frontend
|
|
canary.flagger.app/frontend
|
|
|
|
# generated by Flagger
|
|
configmap/frontend-primary
|
|
deployment.apps/frontend-primary
|
|
horizontalpodautoscaler.autoscaling/frontend-primary
|
|
service/frontend
|
|
service/frontend-canary
|
|
service/frontend-primary
|
|
virtualservice.networking.istio.io/frontend
|
|
```
|
|
|
|
When the `frontend-primary` deployment comes online,
|
|
Flagger will route all traffic to the primary pods and scale to zero the `frontend` deployment.
|
|
|
|
Open your browser and navigate to the frontend URL:
|
|
|
|
|
|
|
|
Now let's install the `backend` release without exposing it outside the mesh:
|
|
|
|
```bash
|
|
helm upgrade -i backend flagger/podinfo \
|
|
--namespace test \
|
|
--set nameOverride=backend \
|
|
--set canary.enabled=true \
|
|
--set canary.istioIngress.enabled=false
|
|
```
|
|
|
|
Check if Flagger has successfully deployed the canaries:
|
|
|
|
```
|
|
kubectl -n test get canaries
|
|
|
|
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
|
backend Initialized 0 2019-02-12T18:53:18Z
|
|
frontend Initialized 0 2019-02-12T17:50:50Z
|
|
```
|
|
|
|
Click on the ping button in the `frontend` UI to trigger a HTTP POST request
|
|
that will reach the `backend` app:
|
|
|
|
|
|
|
|
We'll use the `/echo` endpoint (same as the one the ping button calls)
|
|
to generate load on both apps during a canary deployment.
|
|
|
|
### Upgrade
|
|
|
|
First let's install a load testing service that will generate traffic during analysis:
|
|
|
|
```bash
|
|
helm upgrade -i flagger-loadtester flagger/loadtester \
|
|
--namespace=test
|
|
```
|
|
|
|
Enable the load tester and deploy a new `frontend` version:
|
|
|
|
```bash
|
|
helm upgrade -i frontend flagger/podinfo/ \
|
|
--namespace test \
|
|
--reuse-values \
|
|
--set canary.loadtest.enabled=true \
|
|
--set image.tag=1.4.1
|
|
```
|
|
|
|
Flagger detects that the deployment revision changed and starts the canary analysis along with the load test:
|
|
|
|
```
|
|
kubectl -n istio-system logs deployment/flagger -f | jq .msg
|
|
|
|
New revision detected! Scaling up frontend.test
|
|
Halt advancement frontend.test waiting for rollout to finish: 0 of 2 updated replicas are available
|
|
Starting canary analysis for frontend.test
|
|
Advance frontend.test canary weight 5
|
|
Advance frontend.test canary weight 10
|
|
Advance frontend.test canary weight 15
|
|
Advance frontend.test canary weight 20
|
|
Advance frontend.test canary weight 25
|
|
Advance frontend.test canary weight 30
|
|
Advance frontend.test canary weight 35
|
|
Advance frontend.test canary weight 40
|
|
Advance frontend.test canary weight 45
|
|
Advance frontend.test canary weight 50
|
|
Copying frontend.test template spec to frontend-primary.test
|
|
Halt advancement frontend-primary.test waiting for rollout to finish: 1 old replicas are pending termination
|
|
Promotion completed! Scaling down frontend.test
|
|
```
|
|
|
|
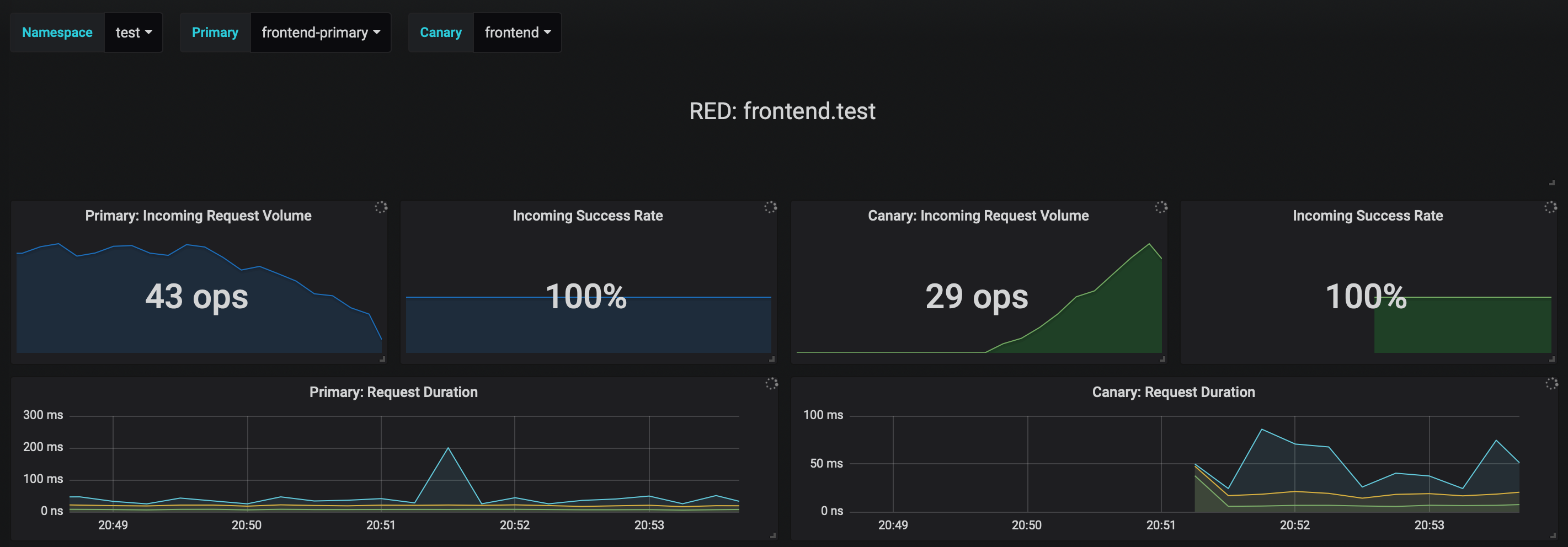
You can monitor the canary deployment with Grafana. Open the Flagger dashboard,
|
|
select `test` from the namespace dropdown, `frontend-primary` from the primary dropdown and `frontend` from the
|
|
canary dropdown.
|
|
|
|
|
|
|
|
Now trigger a canary deployment for the `backend` app, but this time you'll change a value in the configmap:
|
|
|
|
```bash
|
|
helm upgrade -i backend flagger/podinfo/ \
|
|
--namespace test \
|
|
--reuse-values \
|
|
--set canary.loadtest.enabled=true \
|
|
--set httpServer.timeout=25s
|
|
```
|
|
|
|
Generate HTTP 500 errors:
|
|
|
|
```bash
|
|
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
|
|
|
watch curl http://backend-canary:9898/status/500
|
|
```
|
|
|
|
Generate latency:
|
|
|
|
```bash
|
|
kubectl -n test exec -it flagger-loadtester-xxx-yyy sh
|
|
|
|
watch curl http://backend-canary:9898/delay/1
|
|
```
|
|
|
|
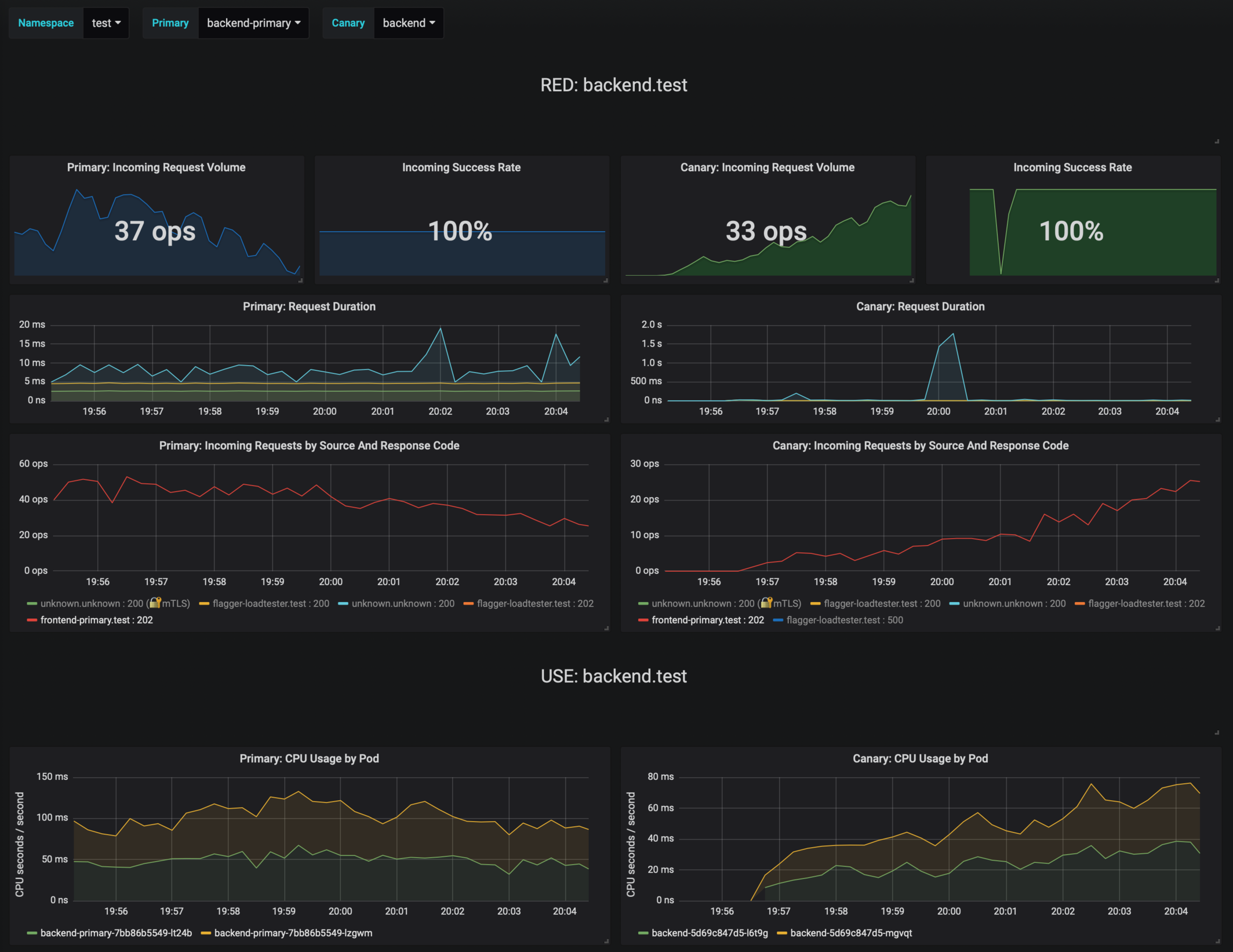
Flagger detects the config map change and starts a canary analysis. Flagger will pause the advancement
|
|
when the HTTP success rate drops under 99% or when the average request duration in the last minute is over 500ms:
|
|
|
|
```
|
|
kubectl -n test describe canary backend
|
|
|
|
Events:
|
|
|
|
ConfigMap backend has changed
|
|
New revision detected! Scaling up backend.test
|
|
Starting canary analysis for backend.test
|
|
Advance backend.test canary weight 5
|
|
Advance backend.test canary weight 10
|
|
Advance backend.test canary weight 15
|
|
Advance backend.test canary weight 20
|
|
Advance backend.test canary weight 25
|
|
Advance backend.test canary weight 30
|
|
Advance backend.test canary weight 35
|
|
Halt backend.test advancement success rate 62.50% < 99%
|
|
Halt backend.test advancement success rate 88.24% < 99%
|
|
Advance backend.test canary weight 40
|
|
Advance backend.test canary weight 45
|
|
Halt backend.test advancement request duration 2.415s > 500ms
|
|
Halt backend.test advancement request duration 2.42s > 500ms
|
|
Advance backend.test canary weight 50
|
|
ConfigMap backend-primary synced
|
|
Copying backend.test template spec to backend-primary.test
|
|
Promotion completed! Scaling down backend.test
|
|
```
|
|
|
|
|
|
|
|
If the number of failed checks reaches the canary analysis threshold, the traffic is routed back to the primary,
|
|
the canary is scaled to zero and the rollout is marked as failed.
|
|
|
|
```bash
|
|
kubectl -n test get canary
|
|
|
|
NAME STATUS WEIGHT LASTTRANSITIONTIME
|
|
backend Succeeded 0 2019-02-12T19:33:11Z
|
|
frontend Failed 0 2019-02-12T19:47:20Z
|
|
```
|
|
|
|
If you've enabled the Slack notifications, you'll receive an alert with the reason why the `backend` promotion failed.
|
|
|
|
### GitOps automation
|
|
|
|
Instead of using Helm CLI from a CI tool to perform the install and upgrade,
|
|
you could use a Git based approach. GitOps is a way to do Continuous Delivery,
|
|
it works by using Git as a source of truth for declarative infrastructure and workloads.
|
|
In the [GitOps model](https://www.weave.works/technologies/gitops/),
|
|
any change to production must be committed in source control
|
|
prior to being applied on the cluster. This way rollback and audit logs are provided by Git.
|
|
|
|
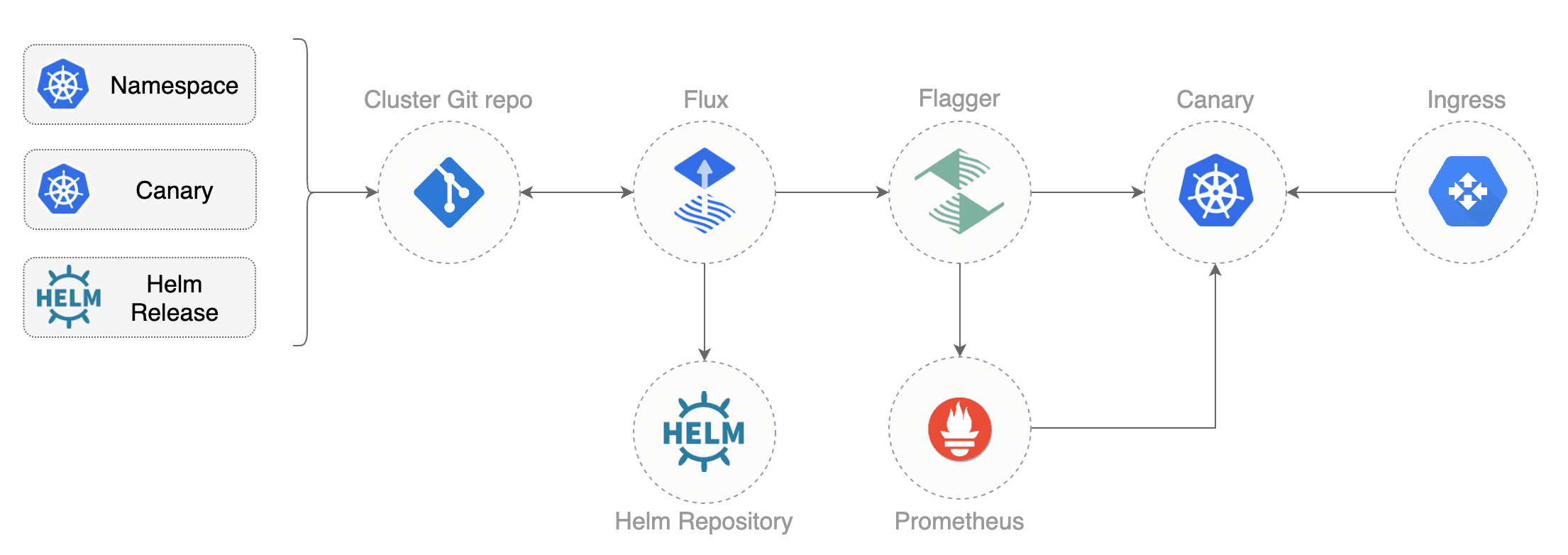
|
|
|
|
In order to apply the GitOps pipeline model to Flagger canary deployments you'll need
|
|
a Git repository with your workloads definitions in YAML format,
|
|
a container registry where your CI system pushes immutable images and
|
|
an operator that synchronizes the Git repo with the cluster state.
|
|
|
|
Create a git repository with the following content:
|
|
|
|
```
|
|
├── namespaces
|
|
│ └── test.yaml
|
|
└── releases
|
|
└── test
|
|
├── backend.yaml
|
|
├── frontend.yaml
|
|
└── loadtester.yaml
|
|
```
|
|
|
|
You can find the git source [here](https://github.com/stefanprodan/flagger/tree/master/artifacts/cluster).
|
|
|
|
Define the `frontend` release using Flux `HelmRelease` custom resource:
|
|
|
|
```yaml
|
|
apiVersion: flux.weave.works/v1beta1
|
|
kind: HelmRelease
|
|
metadata:
|
|
name: frontend
|
|
namespace: test
|
|
annotations:
|
|
flux.weave.works/automated: "true"
|
|
flux.weave.works/tag.chart-image: semver:~1.4
|
|
spec:
|
|
releaseName: frontend
|
|
chart:
|
|
repository: https://stefanprodan.github.io/flagger/
|
|
name: podinfo
|
|
version: 2.0.0
|
|
values:
|
|
image:
|
|
repository: quay.io/stefanprodan/podinfo
|
|
tag: 1.4.0
|
|
backend: http://backend-podinfo:9898/echo
|
|
canary:
|
|
enabled: true
|
|
istioIngress:
|
|
enabled: true
|
|
gateway: public-gateway.istio-system.svc.cluster.local
|
|
host: frontend.istio.example.com
|
|
loadtest:
|
|
enabled: true
|
|
```
|
|
|
|
In the `chart` section I've defined the release source by specifying the Helm repository (hosted on GitHub Pages), chart name and version.
|
|
In the `values` section I've overwritten the defaults set in values.yaml.
|
|
|
|
With the `flux.weave.works` annotations I instruct Flux to automate this release.
|
|
When an image tag in the sem ver range of `1.4.0 - 1.4.99` is pushed to Quay,
|
|
Flux will upgrade the Helm release and from there Flagger will pick up the change and start a canary deployment.
|
|
|
|
Install [Weave Flux](https://github.com/weaveworks/flux) and its Helm Operator by specifying your Git repo URL:
|
|
|
|
```bash
|
|
helm repo add weaveworks https://weaveworks.github.io/flux
|
|
|
|
helm install --name flux \
|
|
--set helmOperator.create=true \
|
|
--set git.url=git@github.com:<USERNAME>/<REPOSITORY> \
|
|
--namespace flux \
|
|
weaveworks/flux
|
|
```
|
|
|
|
At startup Flux generates a SSH key and logs the public key. Find the SSH public key with:
|
|
|
|
```bash
|
|
kubectl -n flux logs deployment/flux | grep identity.pub | cut -d '"' -f2
|
|
```
|
|
|
|
In order to sync your cluster state with Git you need to copy the public key and create a
|
|
deploy key with write access on your GitHub repository.
|
|
|
|
Open GitHub, navigate to your fork, go to _Setting > Deploy keys_ click on _Add deploy key_,
|
|
check _Allow write access_, paste the Flux public key and click _Add key_.
|
|
|
|
After a couple of seconds Flux will apply the Kubernetes resources from Git and Flagger will
|
|
launch the `frontend` and `backend` apps.
|
|
|
|
A CI/CD pipeline for the `frontend` release could look like this:
|
|
|
|
* cut a release from the master branch of the podinfo code repo with the git tag `1.4.1`
|
|
* CI builds the image and pushes the `podinfo:1.4.1` image to the container registry
|
|
* Flux scans the registry and updates the Helm release `image.tag` to `1.4.1`
|
|
* Flux commits and push the change to the cluster repo
|
|
* Flux applies the updated Helm release on the cluster
|
|
* Flux Helm Operator picks up the change and calls Tiller to upgrade the release
|
|
* Flagger detects a revision change and scales up the `frontend` deployment
|
|
* Flagger starts the load test and runs the canary analysis
|
|
* Based on the analysis result the canary deployment is promoted to production or rolled back
|
|
* Flagger sends a Slack notification with the canary result
|
|
|
|
If the canary fails, fix the bug, do another patch release eg `1.4.2` and the whole process will run again.
|
|
|
|
A canary deployment can fail due to any of the following reasons:
|
|
|
|
* the container image can't be downloaded
|
|
* the deployment replica set is stuck for more then ten minutes (eg. due to a container crash loop)
|
|
* the webooks (acceptance tests, load tests, etc) are returning a non 2xx response
|
|
* the HTTP success rate (non 5xx responses) metric drops under the threshold
|
|
* the HTTP average duration metric goes over the threshold
|
|
* the Istio telemetry service is unable to collect traffic metrics
|
|
* the metrics server (Prometheus) can't be reached
|
|
|
|
If you want to find out more about managing Helm releases with Flux here is an in-depth guide
|
|
[github.com/stefanprodan/gitops-helm](https://github.com/stefanprodan/gitops-helm).
|