16 KiB
| title | authors | reviewers | approvers | creation-date | update-date | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Service discovery with native Kubernetes naming and resolution |
|
|
|
2023-06-22 | 2023-08-19 |
Service discovery with native Kubernetes naming and resolution
Summary
In multi-cluster scenarios, there is a need to access services across clusters. Currently, Karmada support this by creating derived service(with derived- prefix, ) in other clusters to access the service.
This Proposal propose a method for multi-cluster service discovery using Kubernetes native Service, to modify the current implementation of Karmada's MCS. This approach does not add a derived- prefix when accessing services across clusters.
Motivation
Having a derived- prefix for Service resources seems counterintuitive when thinking about service discovery:
- Assuming the pod is exported as the service
foo - Another pod that wishes to access it on the same cluster will simply call
fooand Kubernetes will bind to the correct one - If that pod is scheduled to another cluster, the original service discovery will fail as there's no service by the name
foo - To find the original pod, the other pod is required to know it is in another cluster and use
derived-footo work properly
If Karmada supports service discovery using native Kubernetes naming and resolution (without the derived- prefix), users can access the service using its original name without needing to modify their code to accommodate services with the derived- prefix.
Goals
- Remove the "derived-" prefix from the service
- User-friendly and native service discovery
Non-Goals
- Multi cluster connectivity
Proposal
Following are flows to support the service import proposal:
DeploymentandServiceare created on cluster member1 and theServiceimported to cluster member2 usingMultiClusterService(described below as user story 1)DeploymentandServiceare created on cluster member1 and both propagated to cluster member2.Servicefrom cluster member1 is imported to cluster member2 usingMultiClusterService(described below as user story 2)
The proposal for this flow is what can be referred to as local-and-remote service discovery. In the process handling, it can be simply distinguished into the following scenarios:
- Local only - In case there's a local service by the name
fooKarmada never attempts to import the remote service and doesn't create anEndPointSlice - Local and Remote - Users accessing the
fooservice will reach either member1 or member2 - Remote only - in case there's a local service by the name
fooKarmada will remove the localEndPointSliceand will create anEndPointSlicepointing to the other cluster (e.g. instead of resolving member2 cluster is will reach member1)
Based on the above three scenarios, we think there is two reasonable strategies(Users can utilize PP to propagate the Service and implement the Local scenario, it's not necessary to implement it with MultiClusterService):
- RemoteAndLocal - When accessing Service, the traffic will be evenly distributed between the local cluster and remote cluster's Service.
- LocalFirst - When accessing Services, if the local cluster Service can provide services, it will directly access the Service of the local cluster. If a failure occurs in the Service on the local cluster, it will access the Service on remote clusters.
Note: How can we detect the failure? Maybe we need to watch the EndpointSlices resources of the relevant Services in the member cluster. If the EndpointSlices resource becomes non-existent or the statue become not ready, we need to synchronize it with other clusters.
This proposal suggests using the MultiClusterService API to enable cross-cluster service discovery.
This proposal focuses on the RemoteAndLocal strategy, and we will subsequently iterate on the LocalFirst strategy.
User Stories (Optional)
Story 1
As a user of a Kubernetes cluster, I want to be able to access a service whose corresponding pods are located in another cluster. I hope to communicate with the service using its original name.
Scenario:
- Given that the
Servicenamedfooexists on cluster member1 - When I try to access the service inside member2, I can access the service using the name
foo.myspace.svc.cluster.local
Story 2
As a user of a Kubernetes cluster, I want to access a service that has pods located in both this cluster and another. I expect to communicate with the service using its original name, and have the requests routed to the appropriate pods across clusters.
Scenario:
- Given that the
Servicenamedfooexists on cluster member1 - And there is already a conflicting
Servicenamed foo on cluster member2 - When I attempt to access the service in cluster member2 using
foo.myspace.svc.cluster.local - Then the requests round-robin between the local
fooservice and the importedfooservice (member1 and member2)
Notes/Constraints/Caveats (Optional)
Risks and Mitigations
Adding a Service that resolve to a remote cluster will add a network latency of communication between clusters.
Design Details
API changes
This proposal proposes two new fields ServiceProvisionClusters and ServiceConsumptionClusters in MultiClusterService API.
type MultiClusterServiceSpec struct {
...
// ServiceProvisionClusters specifies the clusters which will provision the service backend.
// If leave it empty, we will collect the backend endpoints from all clusters and sync
// them to the ServiceConsumptionClusters.
// +optional
ServiceProvisionClusters []string `json:"serviceProvisionClusters,omitempty"`
// ServiceConsumptionClusters specifies the clusters where the service will be exposed, for clients.
// If leave it empty, the service will be exposed to all clusters.
// +optional
ServiceConsumptionClusters []string `json:"serviceConsumptionClusters,omitempty"`
}
With this API, we will:
- Use
ServiceProvisionClustersto specify the member clusters which will provision the service backend, if leave it empty, we will collect the backend endpoints from all clusters and sync them to theServiceConsumptionClusters. - Use
ServiceConsumptionClustersto specify the clusters where the service will be exposed. If leave it empty, the service will be exposed to all clusters.
For example, if we want access `foo`` service which are located in member2 from member3 , we can use the following yaml:
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: foo
---
apiVersion: networking.karmada.io/v1alpha1
kind: MultiClusterService
metadata:
name: foo
spec:
types:
- CrossCluster
serviceProvisionClusters:
- member2
serviceConsumptionClusters:
- member3
Implementation workflow
Service propagation
The process of propagating Service from Karmada control plane to member clusters is as follows:
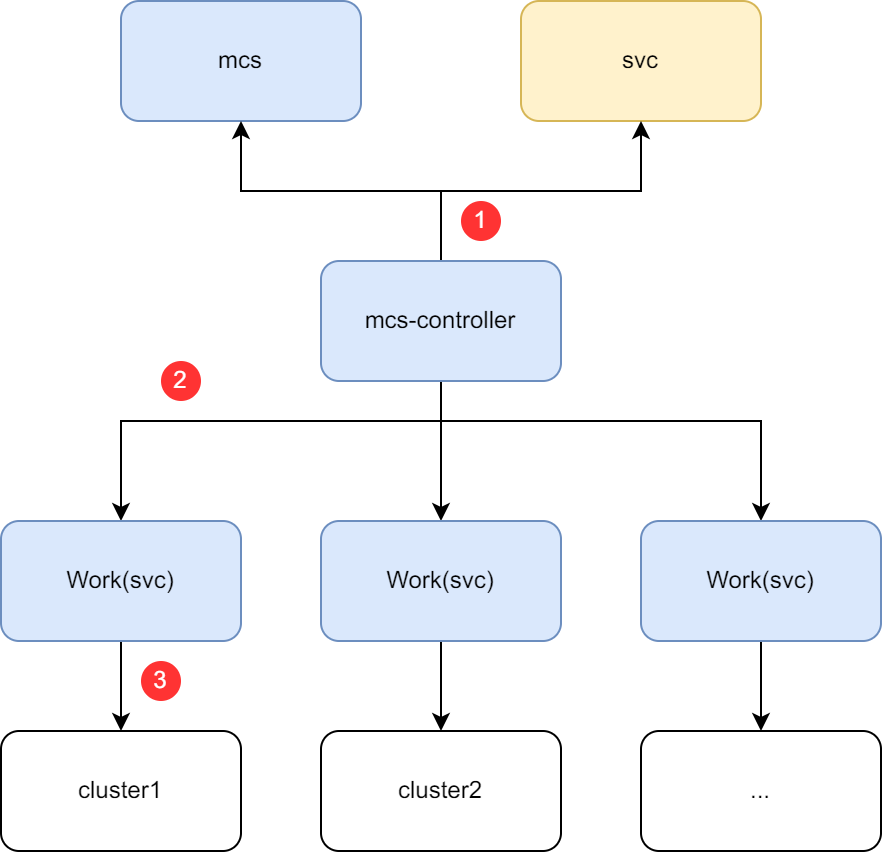
multiclusterservicecontroller will list&watchServiceandMultiClusterServiceresources from Karmada control plane.- Once there is same name
MultiClusterServiceandService,multiclusterservicewill create the Work(corresponding toService), the target cluster namespace is all the clusters in filedspec.serviceProvisionClustersandspec.serviceConsumptionClusters. - The Work will be synchronized with the member clusters. After synchronization,
EndpointSlicewill be created in member clusters.
EndpointSlice synchronization
The process of synchronizing EndpointSlice from ServiceProvisionClusters to ServiceConsumptionClusters is as follows:
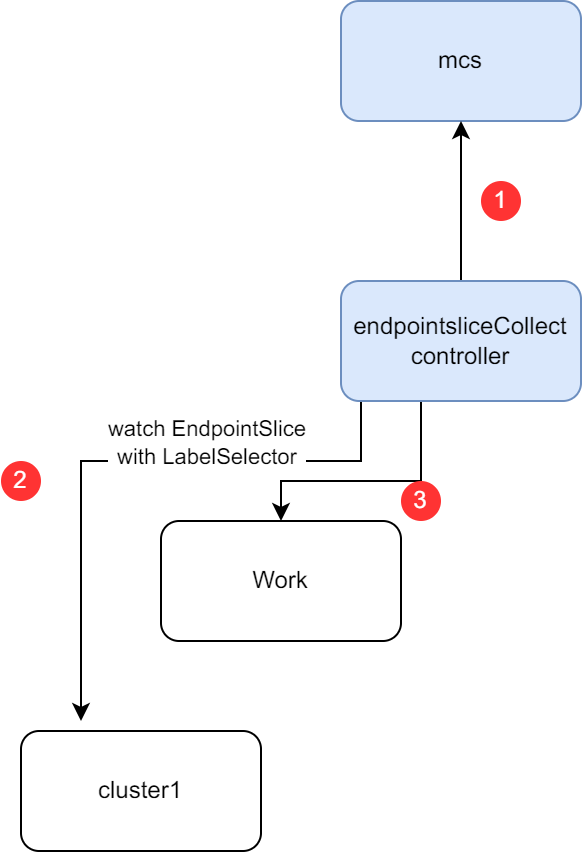
endpointsliceCollectcontroller will list&watchMultiClusterService.endpointsliceCollectcontroller will build the informer to list&watch the target service's EndpointSlice fromServiceProvisionClusters.endpointsliceCollectcontroller will create the corresponding Work for eachEndpointSlicein the cluster namespace. When creating the Work, in order to delete the corresponding work whenMultiClusterServicedeletion, we should add following labels:endpointslice.karmada.io/name: the service name of the originalEndpointSlice.endpointslice.karmada.io/namespace: the service namespace of the originalEndpointSlice.
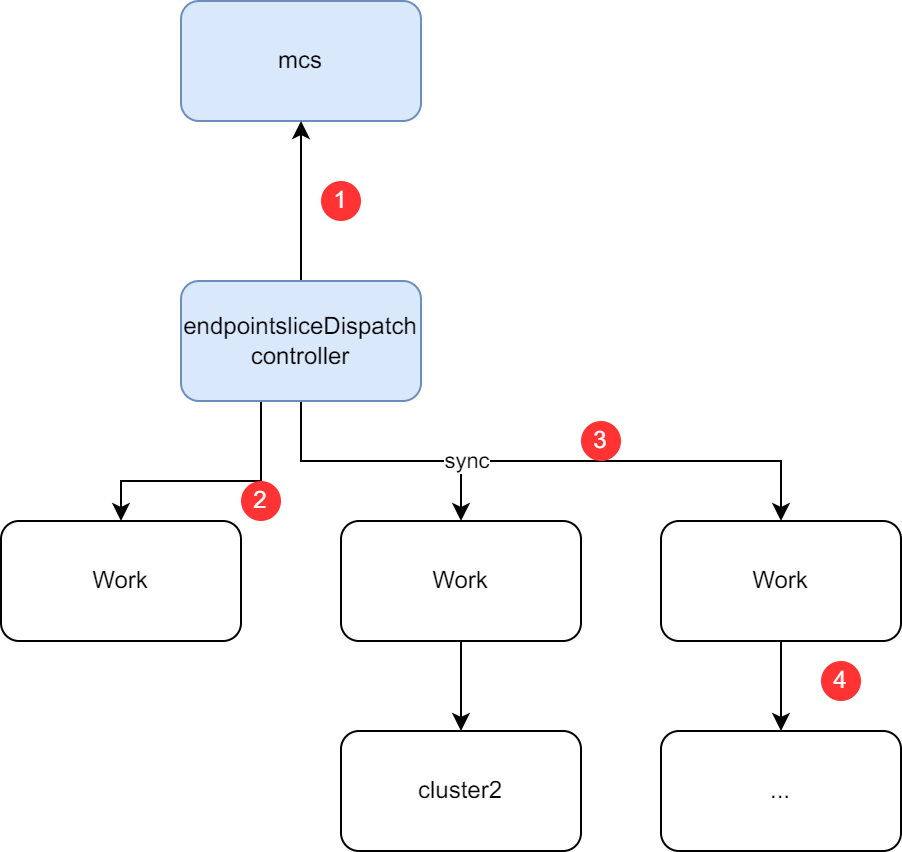
endpointsliceDispatchcontroller will list&watchMultiClusterService.endpointsliceDispatchcontroller will list&watchEndpointSlicefromMultiClusterService'sspec.serviceProvisionClusters.endpointsliceDispatchcontroller will create the corresponding Work for eachEndpointSlicein the cluster namespace ofMultiClusterService'sspec.serviceConsumptionClusters. When creating the Work, in order to facilitate problem investigation, we should add following annotation to record the originalEndpointSliceinformation:endpointslice.karmada.io/work-provision-cluster: the cluster name of the originalEndpointSlice. Also, we should add the following annotation to the syncedEndpointSlicerecord the original information:endpointslice.karmada.io/endpointslice-generation: the resource generation of theEndpointSlice, it could be used to check whether theEndpointSliceis the newest version.endpointslice.karmada.io/provision-cluster: the cluster location of the originalEndpointSlice.
- Karmada will sync the
EndpointSlice's work to the member clusters.
But, there is one point to note that, assume I have following configuration:
apiVersion: v1
kind: Service
metadata:
name: foo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: foo
---
apiVersion: networking.karmada.io/v1alpha1
kind: MultiClusterService
metadata:
name: foo
spec:
types:
- CrossCluster
serviceProvisionClusters:
- member1
- member2
serviceConsumptionClusters:
- member2
When create the corresponding Work, Karmada should only sync the exists EndpointSlice in member1 to member2.
Components change
karmada-controller
- Add
multiclusterservicecontroller to support reconcileMultiClusterServiceand Clusters, including creation/deletion/updating. - Add
endpointsliceCollectcontroller to support reconcileMultiClusterServiceand Clusters, collectEndpointSlicefromServerClustersas work. - Add
endpointsliceDispatchcontroller to support reconcileMultiClusterServiceand Clusters, dispatchEndpointSlicework fromserviceProvisionClusterstoserviceConsumptionClusters.
Status Record
We should have following Condition in MultiClusterService:
MCSServiceAppliedConditionType = "ServiceApplied"
MCSEndpointSliceCollectedConditionType = "EndpointSliceCollected"
MCSEndpointSliceAppliedConditionType = "EndpointSliceApplied"
MCSServiceAppliedConditionType is used to record the status of Service propagation, for example:
status:
conditions:
- lastTransitionTime: "2023-11-20T02:30:49Z"
message: Service is propagated to target clusters.
reason: ServiceAppliedSuccess
status: "True"
type: ServiceApplied
MCSEndpointSliceCollectedConditionType is used to record the status of EndpointSlice collection, for example:
status:
conditions:
- lastTransitionTime: "2023-11-20T02:30:49Z"
message: Failed to list&watch EndpointSlice in member3.
reason: EndpointSliceCollectedFailed
status: "False"
type: EndpointSliceCollected
MCSEndpointSliceAppliedConditionType is used to record the status of EndpointSlice synchronization, for example:
status:
conditions:
- lastTransitionTime: "2023-11-20T02:30:49Z"
message: EndpointSlices are propagated to target clusters.
reason: EndpointSliceAppliedSuccess
status: "True"
type: EndpointSliceApplied
Metrics Record
For better monitoring, we should have following metrics:
mcs_sync_svc_duration_seconds- The duration of syncingServicefrom Karmada control plane to member clusters.mcs_sync_eps_duration_seconds- The time it takes from detecting the EndpointSlice to creating/updating the corresponding Work in a specific namespace.
Development Plan
- API definition, including API files, CRD files, and generated code. (1d)
- For
multiclusterservicecontroller, List&watch mcs and service, reconcile the work in execution namespace. (5d) - For
multiclusterservicecontroller, List&watch cluster creation/deletion, reconcile the work in corresponding cluster execution namespace. (10) - For
endpointsliceCollectcontroller, List&watch mcs, collect the corresponding EndpointSlice fromserviceProvisionClusters, andendpointsliceDispatchcontroller should sync the corresponding Work. (5d) - For
endpointsliceCollectcontroller, List&watch cluster creation/deletion, reconcile the EndpointSlice's work in corresponding cluster execution namespace. (10d) - If cluster gets unhealthy, mcs-eps-controller should delete the EndpointSlice from all the cluster execution namespace. (5d)
Test Plan
- UT cover for new add code
- E2E cover for new add case
Alternatives
One alternative approach to service discovery with native Kubernetes naming and resolution is to rely on external DNS-based service discovery mechanisms. However, this approach may require additional configuration and management overhead, as well as potential inconsistencies between different DNS implementations. By leveraging the native Kubernetes naming and resolution capabilities, the proposed solution simplifies service discovery and provides a consistent user experience.
Another alternative approach could be to enforce a strict naming convention for imported services, where a specific prefix or suffix is added to the service name to differentiate it from local services. However, this approach may introduce complexity for users and require manual handling of naming collisions. The proposed solution aims to provide a more user-friendly experience by removing the "derived-" prefix and allowing services to be accessed using their original names.