20 KiB
Pod Preemption in Kubernetes
Status: Draft
Author: @bsalamat
- Pod Preemption in Kubernetes
- Objectives
- Background
- Overview
- Detailed Design
- Alternatives Considered
- References
Objectives
- Define the concept of preemption in Kubernetes.
- Define how priority and other metrics affect preemption.
- Define scenarios under which a pod may get preempted.
- Define the interaction between scheduler preemption and Kubelet evictions.
- Define mechanics of preemption.
Non-Goals
- How eviction works in Kubernetes. (Please see Background for the definition of "eviction".)
- How quota management works in Kubernetes.
Background
Running various types of workloads with different priorities is a common practice in medium and large clusters to achieve higher resource utilization. In such scenarios, the amount of workload can be larger than what the total resources of the cluster can handle. If so, the cluster chooses the most important workloads and runs them. The importance of workloads are specified by a combination of priority, QoS, or other cluster-specific metrics. The potential to have more work than what cluster resources can handle is called "overcommitment". Overcommitment is very common in on-prem clusters where the number of nodes is fixed, but it can similarly happen in cloud as cloud customers may choose to run their clusters overcommitted/overloaded at times in order to save money. For example, a cloud customer may choose to run at most 100 nodes, knowing that all of their critical workloads fit on 100 nodes and if there is more work, they won't be critical and can wait until cluster load decreases.
Terminology
When a new pod has certain scheduling requirements that makes it infeasible on any node in the cluster, scheduler may choose to kill lower priority pods to satisfy the scheduling requirements of the new pod. We call this operation "preemption". Preemption is distinguished from "eviction" where kubelet kills a pod on a node because that particular node is running out of resources.
Overview
This document describes how preemption in Kubernetes works. Preemption is the action taken when an important pod requires resources or conditions which are not available in the cluster. So, one or more pods need to be killed to make room for the important pod.
Detailed Design
Preemption scenario
In this proposal, the only scenario under which a group of pods in Kubernetes may be preempted is when a higher priority pod cannot be scheduled due to various unmet scheduling requirements, such as lack of resources, unsatisfied affinity or anti-affinity rules, etc., and the preemption of the lower priority pods allows the higher priority pod to be scheduled. So, if the preemption of the lower priority pods does not help with scheduling of the higher priority pod, those lower priority pods will keep running and the higher priority pod will stay pending.
Please note the terminology here. The above scenario does not include "evictions" that are performed by the Kubelet when a node runs out of resources.
Please also note that scheduler may preempt a pod on one node in order to meet the scheduling requirements of a pending pod on another node. For example, if there is a low-priority pod running on node N in rack R, and there is a high-priority pending pod, and one or both of the pods have a requiredDuringScheduling anti-affinity rule saying they can't run on the same rack, then the lower-priority pod might be preempted to enable the higher-priority pod to schedule onto some node M != N on rack R (or, of course, M == N, which is the more standard same-node preemption scenario).
Scheduler performs preemption
We propose preemption to be done by the scheduler -- it does it by deleting the being preempted pods. The component that performs the preemption must have the logic to find the right nodes for the pending pod. It must also have the logic to check whether preempting the chosen pods allows scheduling of the pending pod. These require the component to have the knowledge of predicate and priority functions.
We believe having scheduler perform preemption has the following benefits:
- Avoids replicating all of the scheduling logic in another component.
- Reduces the risk of race condition between pod preemption and pending pod scheduling. If both of these are performed by the scheduler, scheduler can perform them serially (although currently not atomically). However, if a different component performs preemption, scheduler may schedule a different pod (than the preemptor) on the node whose pods are preempted.
The race condition will still exist if we have multiple schedulers. More on this below.
Preemption order
When scheduling a pending pod, scheduler tries to place the pod on a node that does not require preemption. If there is no such a node, scheduler may favor a node where the number and/or priority of victims (preempted pods) is smallest. After choosing the node, scheduler considers the lowest priority pods for preemption first. Scheduler starts from the lowest priority and considers enough pods that should be preempted to allow the pending pod to schedule. Scheduler only considers pods that have lower priority than the pending pod.
Important notes
- When ordering the pods from lowest to highest priority for considering which pod(s) to preempt, among pods with equal priority the pods are ordered by their QoS class: Best Effort, Burstable, Guaranteed.
- Scheduler respects pods' disruption budget when considering them for preemption.
- Scheduler will try to minimize the number of preempted pods. As a result, it may preempt a pod while leaving lower priority pods running if preemption of those lower priority pods is not enough to schedule the pending pod while preemption of the higher priority pod(s) is enough to schedule the pending pod. For example, if node capacity is 10, and pending pod is priority 10 and requires 5 units of resource, and the running pods are {priority 0 request 3, priority 1 request 1, priority 2 request 5, priority 3 request 1}, scheduler will preempt the priority 2 pod only and leaves priority 1 and priority 0 running.
- Scheduler does not have the knowledge of resource usage of pods. It makes scheduling decisions based on the requested resources ("requests") of the pods and when it considers a pod for preemption, it assumes the "requests" to be freed on the node.
- This means that scheduler will never preempt a Best Effort pod to make more resources available. That's because the requests of Best Effort pods is zero and therefore, preempting them will not release any resources on the node from the scheduler's point of view.
- The scheduler may still preempt Best Effort pods for reasons other than releasing their resources. For example, it may preempt a Best Effort pod in order to satisfy affinity rules of the pending pod.
- The amount that needs to be freed (when the issue is resources) is request of the pending pod.
Preemption - Eviction workflow
"Eviction" is the act of killing one or more pods on a node when the node is under resource pressure. Kubelet performs eviction. The eviction process is described in separate document by sig-node, but since it is closely related to the "preemption", we explain it briefly here.
Kubelet uses a function of priority, usage, and requested resources to determine
which pod(s) should be evicted. When pods with the same priority are considered for eviction, the one with the highest percentage of usage over "requests" is the one that is evicted first.
This implies that Best Effort pods are more likely to be evicted among a set of pods with the same priority. The reason is that any amount of resource usage by Best Effort pods translates into a very large percentage of usage over "requests", as Best Effort pods have zero requests for resources. So, while scheduler does not preempt Best Effort pods for releasing resources on a node, it is likely that these pods are evicted by the Kubelet after scheduler schedules a higher priority pod on the node.
Here is an example:
- Assume we have a node with 2GB of usable memory by pods.
- The node is running a burstable pod that uses 1GB of memory and 500MB memory request. It also runs a best effort pod that uses 1GB of memory (and 0 memory request). Both of the pods have priority of 100.
- A new pod with priority 200 arrives and asks for 2GB of memory.
- Scheduler knows that it has to preempt the burstable pod. From scheduler's point of view, the best effort pod needs no resources and its preemption will not release any resources.
- Scheduler preempts the burstable pod and schedules the high priority pending pod on the node.
- The high priority pod uses more than 1GB of memory. Kubelet detects the resource pressure and kills the best effort pod.
So, best effort pods may be killed to make room for higher priority pods, although the scheduler does not preempt them directly.
Now, assume everything in the above example, but the best effort pod has priority 2000. In this scenario, scheduler schedules the pending pod with priority 200 on the node, but it may be evicted by the Kubelet, because Kubelet's eviction function may determine that the best effort pod should stay given its high priority and despite its usage above request. Given this scenario, scheduler should avoid the node and should try scheduling the pod on a different node if the pod is evicted by the Kubelet. This is an optimization to prevent possible ping-pong behavior between Kubelet and Scheduler.
Race condition in multi-scheduler clusters
Kubernetes allows a cluster to have more than one scheduler. This introduces a race condition where one scheduler (scheduler A) may perform preemption of one or more pods and another scheduler (scheduler B) schedules a different pod than the initial pending pod in the space opened after the preemption of pods and before the scheduler A has the chance to schedule the initial pending pod. In this case, scheduler A goes ahead and schedules the initial pending pod on the node thinking that the space is still available. However, the pod from A will be rejected by the kubelet admission process if there are not enough free resources on the node after the pod from B has been bound (or any other predicate that kubelet admission checks fails). This is not a major issue, as schedulers will try again to schedule the rejected pod.
Our assumption is that multiple schedulers cooperate with one another. If they don't, scheduler A may schedule pod A. Scheduler B preempts pod A to schedule pod B which is then preempted by scheduler A to schedule pod A and we go in a loop.
Preemption mechanics
As explained above, evicting victim(s) and binding the pending pod are not transactional. Preemption victims may have "TerminationGracePeriodSeconds" which will create even a larger time gap between the eviction and binding points. When a victim with termination grace period receives its termination signal, it keeps running on the node until it terminates successfully or its grace period is over. In the meantime the node resources won't be available to another pod. So, the scheduler cannot bind the pending pod right away. Scheduler should mark the pending pod as assigned and move on to schedule other pods. To do so, we propose adding a new field to PodSpec called "NominatedNodeName". When this field is set, scheduler knows that the pod is destined to run on the given node and takes it into account when making scheduling decisions for other pods.
Here are all the steps taken in the process:
-
Scheduler sets "
deletionTimestamp" of the victims and sets "NominatedNodeName" of the pending pod. -
Kubelet sees the
deletionTimestampand the victims enter their graceful termination period. -
When any pod is terminated (whether victims or not), Scheduler starts from the beginning of its queue which is sorted by descending priority of pods to see if it can schedule them.
- Scheduler skips a pod in its queue when there is no node for scheduling the pod.
- Scheduler evaluates the "future" feasibility of a pending pod in the queue as if the preemption victims are already gone and the pods which are ahead in the queue and have that node as "
NominatedNodeName" are already bound. See example 1 below. - When a scheduler pass is triggered, scheduler reevaluates all the pods from the head of the queue and updates their "
NominatedNodeName" if needed. See example 4.
-
When a node becomes available, scheduler binds the pending pod to the node. The node may or may not be the same as "
NominatedNodeName". Scheduler sets the "NodeName" field of PodSpec, but it does not clear "NominatedNodeName". See example 2 to find our reasons.
Example 1

- There is only 1 node (other than the master) in the cluster. The node capacity is 10 units of resources.
- There are two pods, A and B, running on the node. Both have priority 100 and each use 5 units of resources. Pod A has 60 seconds of graceful termination period and pod B has 30 seconds.
- Scheduler has two pods, C and D, in its queue. Pod C needs 10 units of resources and its priority is 1000. Pod D needs 2 units of resources and its priority is 50.
- Given that pod C's priority is 1000, scheduler preempts both of pods A and B and sets the future node name of C to Node 1. Pod D cannot be scheduled anywhere.
- After 30 seconds (or less) pod B terminates and 5 units of resources become available. Scheduler looks at pod C, but it cannot be bound yet. Pod C can still be scheduled on the node, so its future node remains the same. Scheduler tries to schedule pod D, but since pod C is ahead of pod D in the queue, scheduler assumes that it is bound to Node 1 when it evaluates feasibility of pod D. With this assumption, scheduler determines that the node does not have enough resources for pod D.
- After 60 seconds (or less) pod A also terminates and scheduler schedules pod C on the node. Scheduler then looks at pod D, but it cannot be scheduled.
Example 2
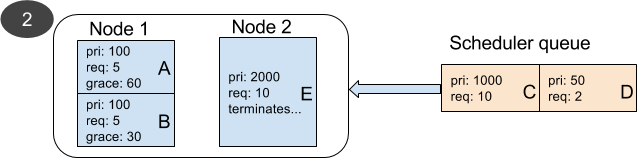
- Everything is similar to the previous example, but here we have two nodes. Node 2 is running pod E with priority 2000 and request of 10 units.
- Similar to example 1, scheduler preempts pods A and B on Node 1 and sets the future node of pod C to Node 1. Pod D cannot be scheduled anywhere.
- While waiting for the graceful termination of pods A and B, pod E terminates on Node 2.
- Termination of pod E triggers a scheduler pass and scheduler finds Node 2 available for pod C. It schedules pod C on Node 2.
- After 30 seconds (or less) pod B terminates. A scheduler pass is triggered and scheduler schedules pod D on Node 1.
- Important note: This may make an observer think that scheduler preempted pod B to schedule pod D which has a lower priority. Looking at the sequence of events and the fact that pod D's future node name is not set to Node 1 may help remove the confusion.
Example 3

- Everything is similar to example 2, but pod E uses 8 units of resources. So, 2 units of resources are available on Node 2.
- Similar to example 2, scheduler preempts pods A and B and sets the future node of pod C to Node 1.
- Scheduler looks at pod D in the queue. Pod D can fit on Node 2.
- Scheduler goes ahead and binds pod D to Node 2 while pods A and B are in their graceful termination period and pod C is not bound yet.
Example 4

- Everything is similar to example 1, but while scheduler is waiting for pods A and B to gracefully terminate, a new higher priority pod F is created and goes to the head of the queue.
- Scheduler evaluates the feasibility of pod F and determines that it can be scheduled on Node 1. So, it sets the future node of pod F to Node 1.
- Scheduler looks at pod C and assumes that pod F is already bound to Node 1, so pod C can no longer run on Node 1. Scheduler clears the future node of pod C.
- Eventually when pods A and B terminate, pod F is bound to Node 1 and pods C and D remain pending.
Alternatives Considered
Rescheduler or Kubelet performs preemption
There are two potential alternatives for the component that performs preemption: rescheduler and Kubelet.
Kubernetes has a "rescheduler" that performs a rudimentary form of preemption today. The more sophisticated form of preemption that is proposed in this document would require many changes to the current rescheduler. The main drawbacks of using the rescheduler for preemption are
- requires replicating the scheduler logic in another component. In particular, the rescheduler is responsible for choosing which node the pending pod should schedule onto, which requires it to know the predicate and priority functions.
- increases the race condition between pod preemption and pending pod scheduling.
Another option is for the scheduler to send the pending pod to a node without doing any preemption, and relying on the kubelet to do the preemption(s). Similar to the rescheduler option, this option requires replicating the preemption and scheduling logic. Kubelet already has the logic to evict pods when a node is under resource pressure, but this logic is much simpler than the whole scheduling logic that considers various scheduling parameters, such as affinity, anti-affinity, PodDisruptionBudget, etc. That is why we believe the scheduler is the right component to perform preemption.
Preemption order
An alternative to preemption by priority and breaking ties with QoS which was proposed earlier, is to preempt by QoS first and break ties with priority. We believe this could cause confusion for users and might reduce cluster utilization. Imagine the following scenario:
- User runs a web server with a very high priority and is willing to give as much resources as possible to this web server. So, the users chooses a reasonable "requests" for resources and does not set any "limits" to let the web server use as much resources as it needs.
If scheduler uses QoS as the first metric for preemption, the web server will be preempted by lower priority "Guaranteed" pods. This can be counter intuitive to users, as they probably don't expect a lower priority pod to preempt a higher priority one.
To solve the problem, the user might try running his web server as Guaranteed, but in that case, the user might have to set much higher "requests" than the web server normally uses. This would prevent other Guaranteed pods from being scheduled on the node running the web server and therefore, would lower resource utilization of the node.