589 lines
18 KiB
Markdown
589 lines
18 KiB
Markdown
<p align="center">
|
||
<a href="https://www.programmercarl.com/xunlian/xunlianying.html" target="_blank">
|
||
<img src="../pics/训练营.png" width="1000"/>
|
||
</a>
|
||
<p align="center"><strong><a href="./qita/join.md">参与本项目</a>,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们受益!</strong></p>
|
||
|
||
|
||
|
||
# 1002. 查找常用字符
|
||
|
||
[力扣题目链接](https://leetcode.cn/problems/find-common-characters/)
|
||
|
||
给你一个字符串数组 words ,请你找出所有在 words 的每个字符串中都出现的共用字符( 包括重复字符),并以数组形式返回。你可以按 任意顺序 返回答案。
|
||
|
||
示例 1:
|
||
|
||
输入:words = ["bella","label","roller"]
|
||
输出:["e","l","l"]
|
||
|
||
示例 2:
|
||
|
||
输入:words = ["cool","lock","cook"]
|
||
输出:["c","o"]
|
||
|
||
提示:
|
||
|
||
1 <= words.length <= 100
|
||
1 <= words[i].length <= 100
|
||
words[i] 由小写英文字母组成
|
||
|
||
|
||
|
||
## 思路
|
||
|
||
这道题意一起就有点绕,不是那么容易懂,其实就是26个小写字符中有字符 在所有字符串里都出现的话,就输出,重复的也算。
|
||
|
||
例如:
|
||
|
||
输入:["ll","ll","ll"]
|
||
输出:["l","l"]
|
||
|
||
这道题目一眼看上去,就是用哈希法,**“小写字符”,“出现频率”, 这些关键字都是为哈希法量身定做的啊**
|
||
|
||
首先可以想到的是暴力解法,一个字符串一个字符串去搜,时间复杂度是$O(n^m)$,n是字符串长度,m是有几个字符串。
|
||
|
||
可以看出这是指数级别的时间复杂度,非常高,而且代码实现也不容易,因为要统计 重复的字符,还要适当的替换或者去重。
|
||
|
||
那我们还是哈希法吧。如果对哈希法不了解,可以看这篇:[关于哈希表,你该了解这些!](https://programmercarl.com/哈希表理论基础.html)。
|
||
|
||
如果对用数组来做哈希法不了解的话,可以看这篇:[把数组当做哈希表来用,很巧妙!](https://programmercarl.com/0242.有效的字母异位词.html)。
|
||
|
||
了解了哈希法,理解了数组在哈希法中的应用之后,可以来看解题思路了。
|
||
|
||
整体思路就是统计出搜索字符串里26个字符的出现的频率,然后取每个字符频率最小值,最后转成输出格式就可以了。
|
||
|
||
如图:
|
||
|
||
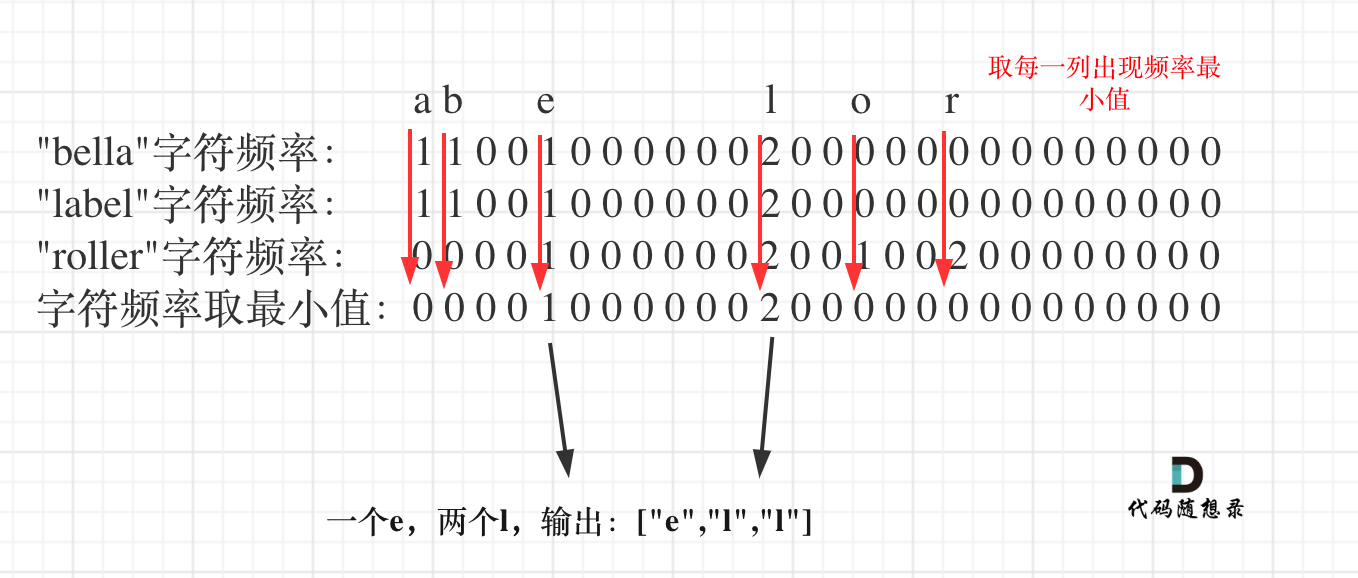
|
||
|
||
先统计第一个字符串所有字符出现的次数,代码如下:
|
||
|
||
```cpp
|
||
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
|
||
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
|
||
hash[A[0][i] - 'a']++;
|
||
}
|
||
```
|
||
|
||
接下来,把其他字符串里字符的出现次数也统计出来一次放在hashOtherStr中。
|
||
|
||
然后hash 和 hashOtherStr 取最小值,这是本题关键所在,此时取最小值,就是 一个字符在所有字符串里出现的最小次数了。
|
||
|
||
代码如下:
|
||
|
||
```cpp
|
||
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
|
||
for (int i = 1; i < A.size(); i++) {
|
||
memset(hashOtherStr, 0, 26 * sizeof(int));
|
||
for (int j = 0; j < A[i].size(); j++) {
|
||
hashOtherStr[A[i][j] - 'a']++;
|
||
}
|
||
// 这是关键所在
|
||
for (int k = 0; k < 26; k++) { // 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||
hash[k] = min(hash[k], hashOtherStr[k]);
|
||
}
|
||
}
|
||
```
|
||
此时hash里统计着字符在所有字符串里出现的最小次数,那么把hash转成题目要求的输出格式就可以了。
|
||
|
||
代码如下:
|
||
|
||
```cpp
|
||
// 将hash统计的字符次数,转成输出形式
|
||
for (int i = 0; i < 26; i++) {
|
||
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
|
||
string s(1, i + 'a'); // char -> string
|
||
result.push_back(s);
|
||
hash[i]--;
|
||
}
|
||
}
|
||
```
|
||
|
||
整体C++代码如下:
|
||
|
||
```CPP
|
||
class Solution {
|
||
public:
|
||
vector<string> commonChars(vector<string>& A) {
|
||
vector<string> result;
|
||
if (A.size() == 0) return result;
|
||
int hash[26] = {0}; // 用来统计所有字符串里字符出现的最小频率
|
||
for (int i = 0; i < A[0].size(); i++) { // 用第一个字符串给hash初始化
|
||
hash[A[0][i] - 'a']++;
|
||
}
|
||
|
||
int hashOtherStr[26] = {0}; // 统计除第一个字符串外字符的出现频率
|
||
for (int i = 1; i < A.size(); i++) {
|
||
memset(hashOtherStr, 0, 26 * sizeof(int));
|
||
for (int j = 0; j < A[i].size(); j++) {
|
||
hashOtherStr[A[i][j] - 'a']++;
|
||
}
|
||
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||
for (int k = 0; k < 26; k++) {
|
||
hash[k] = min(hash[k], hashOtherStr[k]);
|
||
}
|
||
}
|
||
// 将hash统计的字符次数,转成输出形式
|
||
for (int i = 0; i < 26; i++) {
|
||
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
|
||
string s(1, i + 'a'); // char -> string
|
||
result.push_back(s);
|
||
hash[i]--;
|
||
}
|
||
}
|
||
|
||
return result;
|
||
}
|
||
};
|
||
```
|
||
|
||
## 其他语言版本
|
||
|
||
### Java:
|
||
|
||
```Java
|
||
class Solution {
|
||
public List<String> commonChars(String[] A) {
|
||
List<String> result = new ArrayList<>();
|
||
if (A.length == 0) return result;
|
||
int[] hash= new int[26]; // 用来统计所有字符串里字符出现的最小频率
|
||
for (int i = 0; i < A[0].length(); i++) { // 用第一个字符串给hash初始化
|
||
hash[A[0].charAt(i)- 'a']++;
|
||
}
|
||
// 统计除第一个字符串外字符的出现频率
|
||
for (int i = 1; i < A.length; i++) {
|
||
int[] hashOtherStr= new int[26];
|
||
for (int j = 0; j < A[i].length(); j++) {
|
||
hashOtherStr[A[i].charAt(j)- 'a']++;
|
||
}
|
||
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||
for (int k = 0; k < 26; k++) {
|
||
hash[k] = Math.min(hash[k], hashOtherStr[k]);
|
||
}
|
||
}
|
||
// 将hash统计的字符次数,转成输出形式
|
||
for (int i = 0; i < 26; i++) {
|
||
while (hash[i] != 0) { // 注意这里是while,多个重复的字符
|
||
char c= (char) (i+'a');
|
||
result.add(String.valueOf(c));
|
||
hash[i]--;
|
||
}
|
||
}
|
||
return result;
|
||
}
|
||
}
|
||
```
|
||
### Python
|
||
|
||
```python
|
||
class Solution:
|
||
def commonChars(self, words: List[str]) -> List[str]:
|
||
if not words: return []
|
||
result = []
|
||
hash = [0] * 26 # 用来统计所有字符串里字符出现的最小频率
|
||
for i, c in enumerate(words[0]): # 用第一个字符串给hash初始化
|
||
hash[ord(c) - ord('a')] += 1
|
||
# 统计除第一个字符串外字符的出现频率
|
||
for i in range(1, len(words)):
|
||
hashOtherStr = [0] * 26
|
||
for j in range(len(words[i])):
|
||
hashOtherStr[ord(words[i][j]) - ord('a')] += 1
|
||
# 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||
for k in range(26):
|
||
hash[k] = min(hash[k], hashOtherStr[k])
|
||
# 将hash统计的字符次数,转成输出形式
|
||
for i in range(26):
|
||
while hash[i] != 0: # 注意这里是while,多个重复的字符
|
||
result.extend(chr(i + ord('a')))
|
||
hash[i] -= 1
|
||
return result
|
||
```
|
||
|
||
Python 3 使用collections.Counter
|
||
```python
|
||
class Solution:
|
||
def commonChars(self, words: List[str]) -> List[str]:
|
||
tmp = collections.Counter(words[0])
|
||
l = []
|
||
for i in range(1,len(words)):
|
||
# 使用 & 取交集
|
||
tmp = tmp & collections.Counter(words[i])
|
||
|
||
# 剩下的就是每个单词都出现的字符(键),个数(值)
|
||
for j in tmp:
|
||
v = tmp[j]
|
||
while(v):
|
||
l.append(j)
|
||
v -= 1
|
||
return l
|
||
```
|
||
|
||
### JavaScript
|
||
|
||
```js
|
||
var commonChars = function (words) {
|
||
let res = []
|
||
let size = 26
|
||
let firstHash = new Array(size).fill(0) // 初始化 hash 数组
|
||
|
||
let a = "a".charCodeAt()
|
||
let firstWord = words[0]
|
||
for (let i = 0; i < firstWord.length; i++) { // 第 0 个单词的统计
|
||
let idx = firstWord[i].charCodeAt()
|
||
firstHash[idx - a] += 1
|
||
}
|
||
|
||
let otherHash = new Array(size).fill(0) // 初始化 hash 数组
|
||
for (let i = 1; i < words.length; i++) { // 1-n 个单词统计
|
||
for (let j = 0; j < words[i].length; j++) {
|
||
let idx = words[i][j].charCodeAt()
|
||
otherHash[idx - a] += 1
|
||
}
|
||
|
||
for (let i = 0; i < size; i++) {
|
||
firstHash[i] = Math.min(firstHash[i], otherHash[i])
|
||
}
|
||
otherHash.fill(0)
|
||
}
|
||
|
||
for (let i = 0; i < size; i++) {
|
||
while (firstHash[i] > 0) {
|
||
res.push(String.fromCharCode(i + a))
|
||
firstHash[i]--
|
||
}
|
||
}
|
||
return res
|
||
};
|
||
|
||
// 方法二:map()
|
||
var commonChars = function(words) {
|
||
let min_count = new Map()
|
||
// 统计字符串中字符出现的最小频率,以第一个字符串初始化
|
||
for(let str of words[0]) {
|
||
min_count.set(str, ((min_count.get(str) || 0) + 1))
|
||
}
|
||
// 从第二个单词开始统计字符出现次数
|
||
for(let i = 1; i < words.length; i++) {
|
||
let char_count = new Map()
|
||
for(let str of words[i]) { // 遍历字母
|
||
char_count.set(str, (char_count.get(str) || 0) + 1)
|
||
}
|
||
// 比较出最小的字符次数
|
||
for(let value of min_count) { // 注意这里遍历min_count!而不是单词
|
||
min_count.set(value[0], Math.min((min_count.get(value[0]) || 0), (char_count.get(value[0]) || 0)))
|
||
}
|
||
}
|
||
// 遍历map
|
||
let res = []
|
||
min_count.forEach((value, key) => {
|
||
if(value) {
|
||
for(let i=0; i<value; i++) {
|
||
res.push(key)
|
||
}
|
||
}
|
||
})
|
||
return res
|
||
}
|
||
```
|
||
|
||
### TypeScript
|
||
|
||
```ts
|
||
console.time("test")
|
||
let str: string = ""
|
||
//设置一个用字母组成的map字典
|
||
let map = new Map<string, number>()
|
||
//给所有map设置初始值为0
|
||
let wordInitial: [string, number][] = words[0]
|
||
.split("")
|
||
.map((item) => [item, 0])
|
||
//如果有重复字母,就把重复字母的数量加1
|
||
for (let word of words[0]) {
|
||
map.set(word, map.has(word) ? map.get(word) + 1 : 1)
|
||
}
|
||
for (let i = 1; i < words.length; i++) {
|
||
const mapWord = new Map<string, number>(wordInitial)
|
||
for (let j = 0; j < words[i].length; j++) {
|
||
if (!map.has(words[i][j])) continue
|
||
//mapWord中的字母的个数不能高于当前map的个数,多于则不能添加
|
||
if (map.get(words[i][j]) > mapWord.get(words[i][j])) {
|
||
mapWord.set(
|
||
words[i][j],
|
||
mapWord.has(words[i][j]) ? mapWord!.get(words[i][j]) + 1 : 1
|
||
)
|
||
}
|
||
}
|
||
//每次重新初始化map
|
||
map = mapWord
|
||
}
|
||
for (let [key, value] of map) {
|
||
str += key.repeat(value)
|
||
}
|
||
console.timeEnd("test")
|
||
return str.split("")
|
||
```
|
||
|
||
### GO
|
||
|
||
```golang
|
||
func commonChars(A []string) []string {
|
||
var result []string
|
||
if len(A) == 0 {
|
||
return result
|
||
}
|
||
|
||
hash := make([]int, 26) // 用来统计所有字符串里字符出现的最小频率
|
||
for _, c := range A[0] { // 用第一个字符串给hash初始化
|
||
hash[c-'a']++
|
||
}
|
||
|
||
for i := 1; i < len(A); i++ {
|
||
hashOtherStr := make([]int, 26) // 统计除第一个字符串外字符的出现频率
|
||
for _, c := range A[i] {
|
||
hashOtherStr[c-'a']++
|
||
}
|
||
// 更新hash,保证hash里统计26个字符在所有字符串里出现的最小次数
|
||
for k := 0; k < 26; k++ {
|
||
hash[k] = min(hash[k], hashOtherStr[k])
|
||
}
|
||
}
|
||
|
||
// 将hash统计的字符次数,转成输出形式
|
||
for i := 0; i < 26; i++ {
|
||
for hash[i] > 0 {
|
||
s := string('a' + i) // rune -> string
|
||
result = append(result, s)
|
||
hash[i]--
|
||
}
|
||
}
|
||
|
||
return result
|
||
}
|
||
|
||
func min(a, b int) int {
|
||
if a < b {
|
||
return a
|
||
}
|
||
return b
|
||
}
|
||
```
|
||
|
||
### Swift:
|
||
|
||
```swift
|
||
func commonChars(_ words: [String]) -> [String] {
|
||
var res = [String]()
|
||
if words.count < 1 {
|
||
return res
|
||
}
|
||
let aUnicodeScalarValue = "a".unicodeScalars.first!.value
|
||
let lettersMaxCount = 26
|
||
// 用于统计所有字符串每个字母出现的 最小 频率
|
||
var hash = Array(repeating: 0, count: lettersMaxCount)
|
||
// 统计第一个字符串每个字母出现的次数
|
||
for unicodeScalar in words.first!.unicodeScalars {
|
||
hash[Int(unicodeScalar.value - aUnicodeScalarValue)] += 1
|
||
}
|
||
// 统计除第一个字符串每个字母出现的次数
|
||
for idx in 1 ..< words.count {
|
||
var hashOtherStr = Array(repeating: 0, count: lettersMaxCount)
|
||
for unicodeScalar in words[idx].unicodeScalars {
|
||
hashOtherStr[Int(unicodeScalar.value - aUnicodeScalarValue)] += 1
|
||
}
|
||
// 更新hash,保证hash里统计的字母为出现的最小频率
|
||
for k in 0 ..< lettersMaxCount {
|
||
hash[k] = min(hash[k], hashOtherStr[k])
|
||
}
|
||
}
|
||
// 将hash统计的字符次数,转成输出形式
|
||
for i in 0 ..< lettersMaxCount {
|
||
while hash[i] != 0 { // 注意这里是while,多个重复的字符
|
||
let currentUnicodeScalarValue: UInt32 = UInt32(i) + aUnicodeScalarValue
|
||
let currentUnicodeScalar: UnicodeScalar = UnicodeScalar(currentUnicodeScalarValue)!
|
||
let outputStr = String(currentUnicodeScalar) // UnicodeScalar -> String
|
||
res.append(outputStr)
|
||
hash[i] -= 1
|
||
}
|
||
}
|
||
return res
|
||
}
|
||
```
|
||
|
||
### C:
|
||
|
||
```c
|
||
//若两个哈希表定义为char数组(每个单词的最大长度不会超过100,因此可以用char表示),可以提高时间和空间效率
|
||
void updateHashTable(int* hashTableOne, int* hashTableTwo) {
|
||
int i;
|
||
for(i = 0; i < 26; i++) {
|
||
hashTableOne[i] = hashTableOne[i] < hashTableTwo[i] ? hashTableOne[i] : hashTableTwo[i];
|
||
}
|
||
}
|
||
|
||
char ** commonChars(char ** words, int wordsSize, int* returnSize){
|
||
//用来统计所有字母出现的最小频率
|
||
int hashTable[26] = { 0 };
|
||
//初始化返回的char**数组以及返回数组长度
|
||
*returnSize = 0;
|
||
char** ret = (char**)malloc(sizeof(char*) * 100);
|
||
|
||
//如果输入数组长度为0,则返回NULL
|
||
if(!wordsSize)
|
||
return NULL;
|
||
|
||
int i;
|
||
//更新第一个单词的字母频率
|
||
for(i = 0; i < strlen(words[0]); i++)
|
||
hashTable[words[0][i] - 'a']++;
|
||
//更新从第二个单词开始的字母频率
|
||
for(i = 1; i < wordsSize; i++) {
|
||
//创建新的哈希表,记录新的单词的字母频率
|
||
int newHashTable[26] = { 0 };
|
||
int j;
|
||
for(j = 0; j < strlen(words[i]); j++) {
|
||
newHashTable[words[i][j] - 'a']++;
|
||
}
|
||
//更新原哈希表
|
||
updateHashTable(hashTable, newHashTable);
|
||
}
|
||
|
||
//将哈希表中的字符变为字符串放入ret中
|
||
for(i = 0; i < 26; i++) {
|
||
if(hashTable[i]) {
|
||
int j;
|
||
for(j = 0; j < hashTable[i]; j++) {
|
||
char* tempString = (char*)malloc(sizeof(char) * 2);
|
||
tempString[0] = i + 'a';
|
||
tempString[1] = '\0';
|
||
ret[(*returnSize)++] = tempString;
|
||
}
|
||
}
|
||
}
|
||
return ret;
|
||
}
|
||
```
|
||
### Scala:
|
||
|
||
```scala
|
||
object Solution {
|
||
def commonChars(words: Array[String]): List[String] = {
|
||
// 声明返回结果的不可变List集合,因为res要重新赋值,所以声明为var
|
||
var res = List[String]()
|
||
var hash = new Array[Int](26) // 统计字符出现的最小频率
|
||
// 统计第一个字符串中字符出现的次数
|
||
for (i <- 0 until words(0).length) {
|
||
hash(words(0)(i) - 'a') += 1
|
||
}
|
||
// 统计其他字符串出现的频率
|
||
for (i <- 1 until words.length) {
|
||
// 统计其他字符出现的频率
|
||
var hashOtherStr = new Array[Int](26)
|
||
for (j <- 0 until words(i).length) {
|
||
hashOtherStr(words(i)(j) - 'a') += 1
|
||
}
|
||
// 更新hash,取26个字母最小出现的频率
|
||
for (k <- 0 until 26) {
|
||
hash(k) = math.min(hash(k), hashOtherStr(k))
|
||
}
|
||
}
|
||
// 根据hash的结果转换输出的形式
|
||
for (i <- 0 until 26) {
|
||
for (j <- 0 until hash(i)) {
|
||
res = res :+ (i + 'a').toChar.toString
|
||
}
|
||
}
|
||
res
|
||
}
|
||
}
|
||
```
|
||
|
||
### Rust:
|
||
|
||
```rust
|
||
impl Solution {
|
||
pub fn common_chars(words: Vec<String>) -> Vec<String> {
|
||
if words.is_empty() {
|
||
return vec![];
|
||
}
|
||
let mut res = vec![];
|
||
let mut hash = vec![0; 26];
|
||
for i in words[0].bytes() {
|
||
hash[(i - b'a') as usize] += 1;
|
||
}
|
||
for i in words.iter().skip(1) {
|
||
let mut other_hash_str = vec![0; 26];
|
||
for j in i.bytes() {
|
||
other_hash_str[(j - b'a') as usize] += 1;
|
||
}
|
||
for k in 0..26 {
|
||
hash[k] = hash[k].min(other_hash_str[k]);
|
||
}
|
||
}
|
||
|
||
for (i, v) in hash.iter_mut().enumerate() {
|
||
while *v > 0 {
|
||
res.push(((i as u8 + b'a') as char).to_string());
|
||
*v -= 1;
|
||
}
|
||
}
|
||
|
||
res
|
||
}
|
||
}
|
||
```
|
||
|
||
Ruby:
|
||
```ruby
|
||
def common_chars(words)
|
||
result = []
|
||
#统计所有字符串里字符出现的最小频率
|
||
hash = {}
|
||
#初始化标识
|
||
is_first = true
|
||
|
||
words.each do |word|
|
||
#记录共同字符
|
||
chars = []
|
||
word.split('').each do |chr|
|
||
#第一个字符串初始化
|
||
if is_first
|
||
chars << chr
|
||
else
|
||
#字母之前出现过的最小次数
|
||
if hash[chr] != nil && hash[chr] > 0
|
||
hash[chr] -= 1
|
||
chars << chr
|
||
end
|
||
end
|
||
end
|
||
|
||
is_first = false
|
||
#清除hash,更新字符最小频率
|
||
hash.clear
|
||
chars.each do |chr|
|
||
if hash[chr] != nil
|
||
hash[chr] += 1
|
||
else
|
||
hash[chr] = 1
|
||
end
|
||
end
|
||
end
|
||
|
||
#字符最小频率hash转换为字符数组
|
||
hash.keys.each do |key|
|
||
for i in 0..hash[key] - 1
|
||
result << key
|
||
end
|
||
end
|
||
|
||
return result
|
||
end
|
||
```
|
||
|
||
|
||
<p align="center">
|
||
<a href="https://programmercarl.com/other/kstar.html" target="_blank">
|
||
<img src="../pics/网站星球宣传海报.jpg" width="1000"/>
|
||
</a>
|