11 KiB
Introduction
- It causes power-off of GCP VM instances filtered by a label before bringing it back to the running state after the specified chaos duration.
- It helps to check the performance of the application/process running on the VM instance.
- When the
MANAGED_INSTANCE_GROUPisenablethen the experiment will not try to start the instances post chaos, instead it will check the addition of new instances to the instance group.
!!! tip "Scenario: stop the gcp vm"
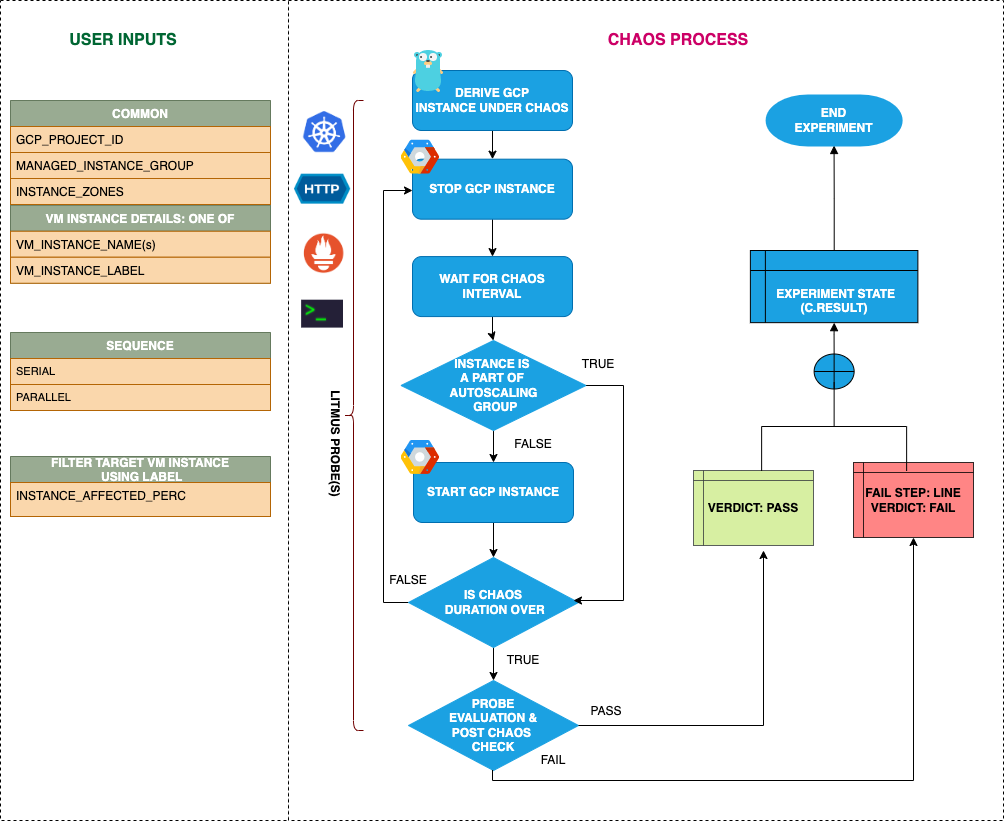
Uses
??? info "View the uses of the experiment" coming soon
Prerequisites
??? info "Verify the prerequisites"
- Ensure that Kubernetes Version > 1.16
- Ensure that the Litmus Chaos Operator is running by executing kubectl get pods in operator namespace (typically, litmus).If not, install from here
- Ensure that the gcp-vm-instance-stop-by-label experiment resource is available in the cluster by executing kubectl get chaosexperiments in the desired namespace. If not, install from here
- Ensure that you have sufficient GCP permissions to stop and start the GCP VM instances.
- Ensure to create a Kubernetes secret having the GCP service account credentials in the default namespace. A sample secret file looks like:
```yaml
apiVersion: v1
kind: Secret
metadata:
name: cloud-secret
type: Opaque
stringData:
type:
project_id:
private_key_id:
private_key:
client_email:
client_id:
auth_uri:
token_uri:
auth_provider_x509_cert_url:
client_x509_cert_url:
```
Default Validations
??? info "View the default validations" - All the VM instances having the target label are in a healthy state
Minimal RBAC configuration example (optional)
!!! tip "NOTE"
If you are using this experiment as part of a litmus workflow scheduled constructed & executed from chaos-center, then you may be making use of the litmus-admin RBAC, which is pre installed in the cluster as part of the agent setup.
??? note "View the Minimal RBAC permissions"
```yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: gcp-vm-instance-stop-by-label-sa
namespace: default
labels:
name: gcp-vm-instance-stop-by-label-sa
app.kubernetes.io/part-of: litmus
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: gcp-vm-instance-stop-by-label-sa
labels:
name: gcp-vm-instance-stop-by-label-sa
app.kubernetes.io/part-of: litmus
rules:
# Create and monitor the experiment & helper pods
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update", "deletecollection"]
# Performs CRUD operations on the events inside chaosengine and chaosresult
- apiGroups: [""]
resources: ["events"]
verbs: ["create","get","list","patch","update"]
# Fetch configmaps & secrets details and mount it to the experiment pod (if specified)
- apiGroups: [""]
resources: ["secrets","configmaps"]
verbs: ["get","list",]
# Track and get the runner, experiment, and helper pods log
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
# for configuring and monitor the experiment job by the chaos-runner pod
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["create","list","get","delete","deletecollection"]
# for creation, status polling and deletion of litmus chaos resources used within a chaos workflow
- apiGroups: ["litmuschaos.io"]
resources: ["chaosengines","chaosexperiments","chaosresults"]
verbs: ["create","list","get","patch","update","delete"]
# for experiment to perform node status checks
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get","list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: gcp-vm-instance-stop-by-label-sa
labels:
name: gcp-vm-instance-stop-by-label-sa
app.kubernetes.io/part-of: litmus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: gcp-vm-instance-stop-by-label-sa
subjects:
- kind: ServiceAccount
name: gcp-vm-instance-stop-by-label-sa
namespace: default
```
Use this sample RBAC manifest to create a chaosServiceAccount in the desired (app) namespace. This example consists of the minimum necessary role permissions to execute the experiment.
Experiment tunables
??? info "check the experiment tunables"
Mandatory Fields
<table>
<tr>
<th> Variables </th>
<th> Description </th>
<th> Notes </th>
</tr>
<tr>
<td> GCP_PROJECT_ID </td>
<td> GCP project ID to which the VM instances belong </td>
<td> All the VM instances must belong to a single GCP project </td>
</tr>
<tr>
<td> INSTANCE_LABEL </td>
<td> Name of target VM instances </td>
<td> The <code>INSTANCE_LABEL</code> should be provided as <code>key:value</code> or <code>key</code> if the corresponding value is empty ex: <code>vm:target-vm</code> </td>
</tr>
<tr>
<td> ZONES </td>
<td> The zone of the target VM instances </td>
<td> Only one zone can be provided i.e. all target instances should lie in the same zone </td>
</tr>
</table>
<h2>Optional Fields</h2>
<table>
<tr>
<th> Variables </th>
<th> Description </th>
<th> Notes </th>
</tr>
<tr>
<td> TOTAL_CHAOS_DURATION </td>
<td> The total time duration for chaos insertion (sec) </td>
<td> Defaults to 30s </td>
</tr>
<tr>
<td> CHAOS_INTERVAL </td>
<td> The interval (in sec) between successive instance termination </td>
<td> Defaults to 30s </td>
</tr>
<tr>
<td> MANAGED_INSTANCE_GROUP </td>
<td> Set to <code>enable</code> if the target instance is the part of a managed instance group </td>
<td> Defaults to <code>disable</code> </td>
</tr>
<tr>
<td> INSTANCE_AFFECTED_PERC </td>
<td> The percentage of total VMs filtered using the label to target </td>
<td> Defaults to 0 (corresponds to 1 instance), provide numeric value only </td>
</tr>
<tr>
<td> SEQUENCE </td>
<td> It defines sequence of chaos execution for multiple instance </td>
<td> Default value: parallel. Supported: serial, parallel </td>
</tr>
<tr>
<td> RAMP_TIME </td>
<td> Period to wait before and after injection of chaos in sec </td>
<td> </td>
</tr>
</table>
Experiment Examples
Common Experiment Tunables
Refer the common attributes to tune the common tunables for all the experiments.
Target GCP Instances
It will stop all the instances with filtered by the label INSTANCE_LABEL and corresponding ZONES zone in GCP_PROJECT_ID project.
NOTE: The INSTANCE_LABEL accepts only one label and ZONES also accepts only one zone name. Therefore, all the instances must lie in the same zone.
Use the following example to tune this:
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: gcp-vm-instance-stop-by-label-sa
experiments:
- name: gcp-vm-instance-stop-by-label
spec:
components:
env:
- name: INSTANCE_LABEL
value: 'vm:target-vm'
- name: ZONES
value: 'us-east1-b'
- name: GCP_PROJECT_ID
value: 'my-project-4513'
- name: TOTAL_CHAOS_DURATION
value: '60'
Manged Instance Group
If vm instances belong to a managed instance group then provide the MANAGED_INSTANCE_GROUP as enable else provided it as disable, which is the default value.
Use the following example to tune this:
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: gcp-vm-instance-stop-by-label-sa
experiments:
- name: gcp-vm-instance-stop-by-label
spec:
components:
env:
- name: MANAGED_INSTANCE_GROUP
value: 'enable'
- name: INSTANCE_LABEL
value: 'vm:target-vm'
- name: ZONES
value: 'us-east1-b'
- name: GCP_PROJECT_ID
value: 'my-project-4513'
- name: TOTAL_CHAOS_DURATION
value: '60'
Mutiple Iterations Of Chaos
The multiple iterations of chaos can be tuned via setting CHAOS_INTERVAL ENV. Which defines the delay between each iteration of chaos.
Use the following example to tune this:
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: engine-nginx
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: gcp-vm-instance-stop-by-label-sa
experiments:
- name: gcp-vm-instance-stop-by-label
spec:
components:
env:
- name: CHAOS_INTERVAL
value: '15'
- name: TOTAL_CHAOS_DURATION
value: '60'
- name: INSTANCE_LABEL
value: 'vm:target-vm'
- name: ZONES
value: 'us-east1-b'
- name: GCP_PROJECT_ID
value: 'my-project-4513'